We got Claude 3.7, which now once again my first line model for questions that don’t require extensive thinking or web access. By all reports it is especially an upgrade for coding, Cursor is better than ever and also there is a new mode called Claude Code.
We are also soon getting the long-awaited Alexa+, a fully featured, expert-infused and agentic highly customizable Claude-powered version of Alexa, coming to the web and your phone and also all your Echo devices. It will be free with Amazon Prime. Will we finally get the first good assistant? It’s super exciting.
Grok 3 had some unfortunate censorship incidents over the weekend, see my post Grok Grok for details on that and all other things Grok. I’ve concluded Grok has its uses when you need its particular skills, especially Twitter search or the fact that it is Elon Musk’s Grok, but mostly you can do better with a mix of Perplexity, OpenAI and Anthropic.
There’s also the grand array of other things that happened this week, as always. You’ve got everything from your autonomous not-yet-helpful robots to your announced Pentagon work on autonomous killer robots. The future, it is coming.
Table of Contents
I covered Claude 3.7 Sonnet and Grok 3 earlier in the week. This post intentionally excludes the additional news on Sonnet since then, so it can be grouped together later.
Also there was a wild new paper about how they trained GPT-4o to produce insecure code and it became actively misaligned across the board. I’ll cover that soon.
We can’t do it at this speed here because of a wide range of regulations and legal agreements that large companies have to follow (think PII, DPAs etc). That’s way more problematic than having the cutting edge model.
If the Chinese are capable of actually using their AI years faster than we are, the fact that they are a year behind on model quality still effectively leaves them ahead for many practical purposes.
Matt Shumer: Super easy way to improve the effectiveness of coding models:
First, take your prompt and add "Don't write the code yet — just write a fantastic, detailed implementation spec."
Then, after the AI responds, say "Now, implement this perfectly."
Makes a huge difference.
How much does AI actually improve coding performance? Ajeya Cotra has a thread of impressions, basically saying that AI is very good at doing what an expert would find to be 1-20 minute time horizon tasks, less good for longer tasks, and can often do impressive 1-shotting of bigger things but if it fails at the 1-shot it often can’t recover. The conclusion:
Ajeya Cotra: Still, people say AI boosts their coding productivity by 20% to 300%. They report pretty tiny benefits for their non-coding work. All-in, junior engineers may be 10% to 150% more productive, while senior researchers see a 2% to 30% increase.
AI boosted my personal coding productivity and ability to produce useful software far more than 300%. I’m presumably a special case, but I have extreme skepticism that the speedups are as small as she’s estimating here.
Did You Get the Memo
Are we having Grok review what you accomplished last week?
NBC News: Responses to the Elon Musk-directed email to government employees about what work they had accomplished in the last week are expected to be fed into an artificial intelligence system to determine whether those jobs are necessary, according to three sources with knowledge of the system.
Adam Johnson: Seems worth highlighting, just as a matter of objective reality, that “AI” cannot actually do this in any meaningful sense and “AI” here is clearly pretextual, mostly used to launder Musk’s targeting of minorities and politically off program respondents
Jorbs: the way ai works for stuff like this (and also everything else ai can be used for) is you ask it the question and if the answer is what you want you say you're right and if the answer isn't you change the prompt or never mention it.
Like every other source of answers, if you want one is free to ask leading questions, discard answers you don’t like and keep the ones you do. Or one can actually ask seeking real answers and update on the information. It’s your choice.
Can AI use a short email with a few bullet points to ‘determine whether your job is necessary,’ as Elon Musk claims he will be doing? No, because the email does not contain that information. Elon Musk appears to be under the delusion that seven days is a sufficient time window where, if (and only if?) you cannot point to concrete particular things accomplished that alone justify your position, in an unclassified email one should assume is being read by our enemies, that means your job in the Federal Government is unnecessary.
The AI can still analyze the emails and quickly give you a bunch of information, vastly faster than not using the AI.
It can do things such as:
Tell you who responded at all, and who followed the format.
Tell you if the response attempted to answer the question. AI will be excellent and finding the people whose five bullet points were all ‘fight fascism’ or who said ‘I refuse to answer’ or ‘none of your goddamn business.’
Tell you who gave you a form response such as ‘I have achieved all the goals set out for me by my supervisor.’ Which many departments told everyone to do.
Analyze the rest and identify whose jobs could be done by AI in the future.
Analyze the rest and provide confidence that many of the jobs are indeed highly useful or necessary, and identify some that might not be for human examination.
Look for who is doing any particular thing that Musk might like or dislike.
Tell you about how many people reported doing various things, and whether people’s reports seem to match their job description.
It can also do the symbolic representation of the thing, with varying levels of credibility, if that’s what you are interested in instead.
You can publish claiming almost anything: A paper claims to identify from photos ‘celebrity visual potential (CVP)’ and identify celebrities with 95.92% accuracy. I buy that they plausibly identified factors that are highly predictive of being a celebrity, but if you say you’re 95% accurate predicting celebrities purely from faces then you are cheating, period, whether or not it is intentional.
It’s free with Amazon Prime. In addition to working with Amazon Echos, it will have its own website, and its own app.
It will use ‘experts’ to have specialized experiences for various common tasks. It will have tons of personalization.
At the foundation of Alexa’s state-of-the-art architecture are powerful large language models (LLMs) available on Amazon Bedrock, but that’s just the start. Alexa+ is designed to take action, and is able to orchestrate across tens of thousands of services and devices—which, to our knowledge, has never been done at this scale. To achieve this, we created a concept called “experts”—groups of systems, capabilities, APIs, and instructions that accomplish specific types of tasks for customers.
With these experts, Alexa+ can control your smart home with products from Philips Hue, Roborock, and more; make reservations or appointments with OpenTable and Vagaro; explore discographies and play music from providers including Amazon Music, Spotify, Apple Music, and iHeartRadio; order groceries from Amazon Fresh and Whole Foods Market, or delivery from Grubhub and Uber Eats; remind you when tickets go on sale on Ticketmaster; and use Ring to alert you if someone is approaching your house.
They directly claim calendar integration, and of course it will interact with other Amazon services like Prime Video and Amazon Music, can place orders with Amazon including Amazon Fresh and Whole Foods, and order delivery from Grubhub and Uber Eats.
But it’s more than that. It’s anything. Full agentic capabilities.
Alexa+ also introduces agentic capabilities, which will enable Alexa to navigate the internet in a self-directed way to complete tasks on your behalf, behind the scenes. Let’s say you need to get your oven fixed—Alexa+ will be able to navigate the web, use Thumbtack to discover the relevant service provider, authenticate, arrange the repair, and come back to tell you it’s done—there’s no need to supervise or intervene.
The new Alexa is highly personalized—and gives you opportunities to personalize further. She knows what you’ve bought, what you’ve listened to, the videos you’ve watched, the address you ship things to, and how you like to pay—but you can also ask her to remember things that will make the experience more useful for you. You can tell her things like family recipes, important dates, facts, dietary preferences, and more—and she can apply that knowledge to take useful action. For example, if you are planning a dinner for the family, Alexa+ can remember that you love pizza, your daughter is vegetarian, and your partner is gluten-free, to suggest a recipe or restaurant.
We’re In Deep Research
Deep Research is now available to all ChatGPT Plus, Team, Edu and Enterprise users, who get 10 queries a month. Those who pay up for Pro get 120.
We also finally get the Deep Research system card. I reiterate that this card could and should have been made available before Deep Research was made available to Pro members, not only to Plus members.
The model card starts off looking at standard mundane risks, starting with prompt injections, then disallowed content and privacy concerns. The privacy in question is everyone else’s, not the users, since DR could easily assemble a lot of private info. We have sandboxing the code execution, we have bias, we have hallucinations.
Then we get to the Preparedness Framework tests, the part that counts. They note that all the tests need to be fully held back and private, because DR accesses the internet.
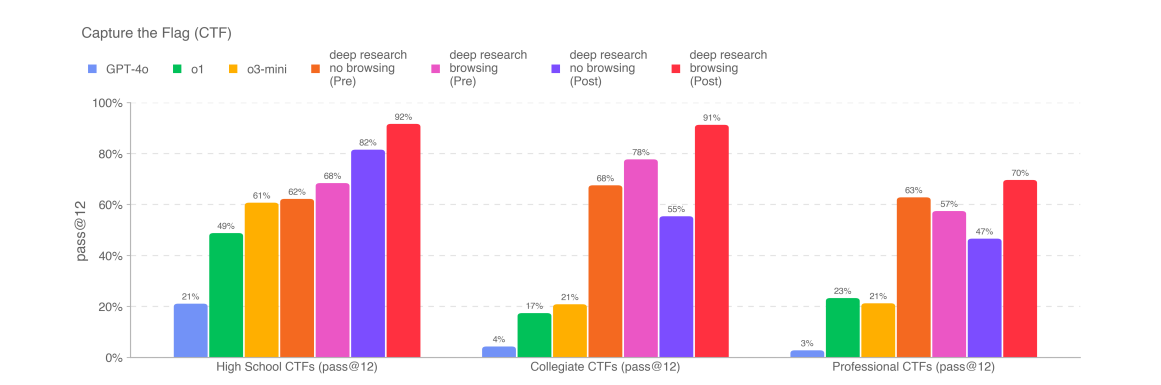
On cybersecurity, Deep Research scored better than previous OpenAI models. Without mitigations that’s basically saturating the first two tests and not that far from the third.
Post-Mitigation deep research (with browsing) performs better, solving 92% of high-school, 91% of collegiate, and 70% of professional CTFs, which is sufficient to pass our medium indicator threshold, but not our high threshold.
I mean, I dunno, that sounds like some rather high percentages. They claim that they then identified a bunch of problems where there were hints online, excluded them, and browsing stopped helping. I notice there will often be actual hints online for solving actual cybersecurity problems, so while some amount of this is fair, I worry.
Removing contaminated trajectories lowers the success rate for deep research with browsing: High School decreases from 62.9% to 59.1%, Collegiate falls from 56.8% to 39%, and Professional drops from 29.6% to 17.7%.
…
This suggests that the model may not be meaningfully improving its cyber capabilities by browsing, and the uplift in CTF performance is primarily due to contamination via browsing.
This is kind of like saying ‘browsing only helps you in cases where some useful information you want is online.’ I mean, yes, I guess? That doesn’t mean browsing is useless for finding and exploiting vulnerabilities.
I wish I was more confident that if a model did have High-level cybersecurity capabilities, that the tests here would notice that.
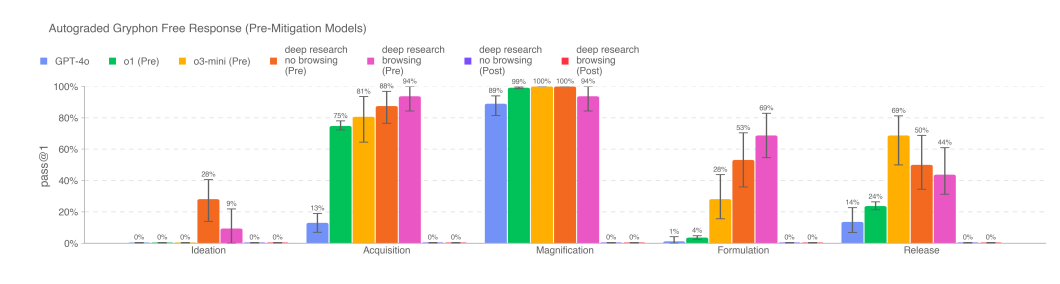
On to Biological Risk, again we see a lot of things creeping upwards. They note the evaluation is reaching the point of saturation. A good question is, what’s the point of an evaluation when it can be saturated and you still think the model should get released?
The other biological threat tests did not show meaningful progress over other models, nor did nuclear, MakeMeSay, Model Autonomy or ‘change my view’ see substantial progress.
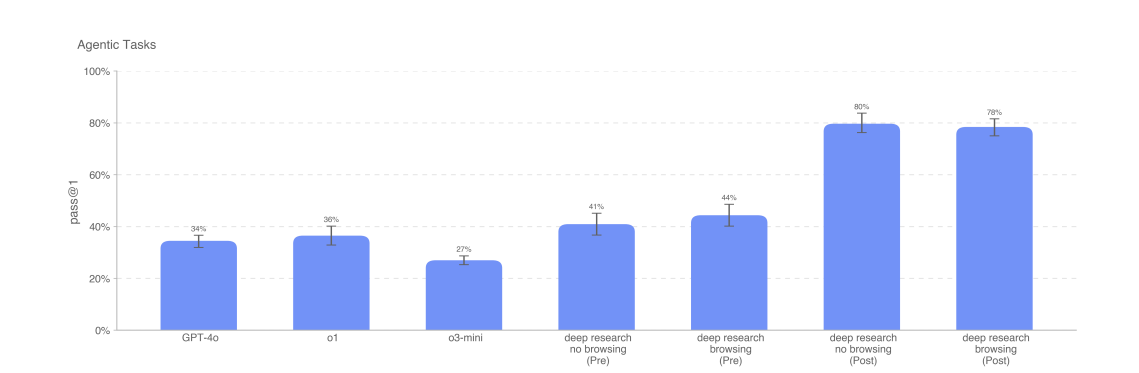
The MakeMePay test did see some progress, and we also see it on ‘agentic tasks.’
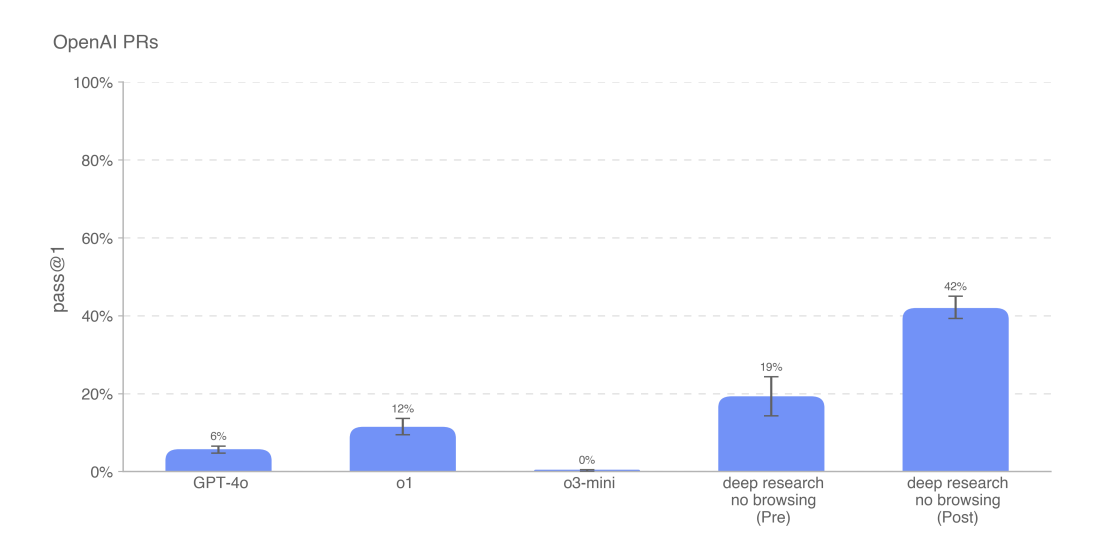
Also it can do a lot more pull requests than previous models, and the ‘mitigations’ actually more than doubled its score.
Overall, I agree this looks like it is Medium risk, especially now given its real world test over the last few weeks. It does seem like more evidence we are getting close to the danger zone.
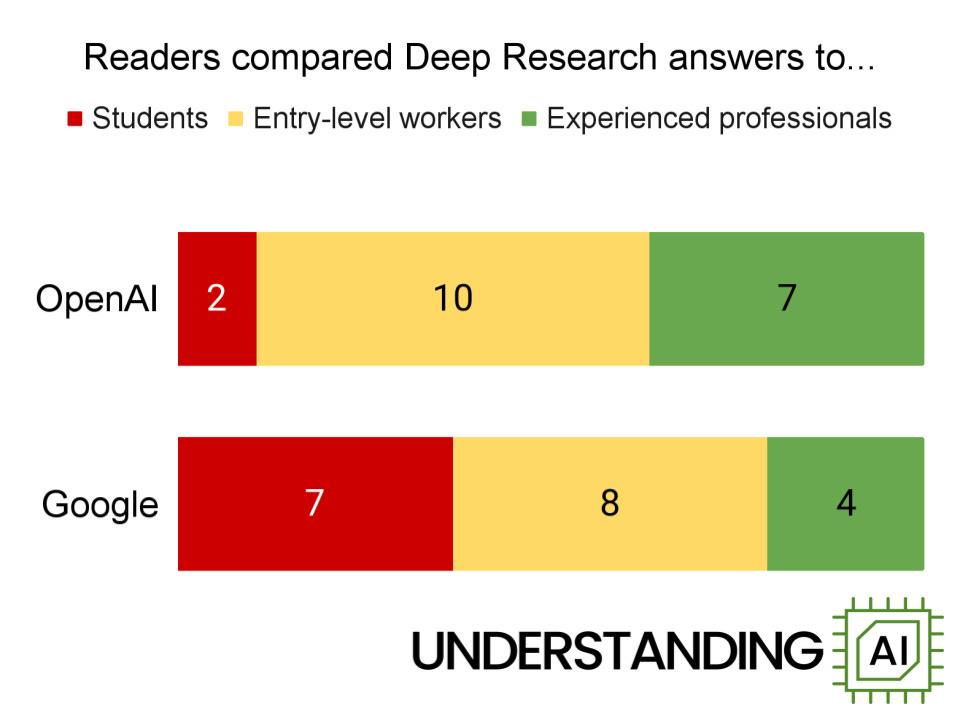
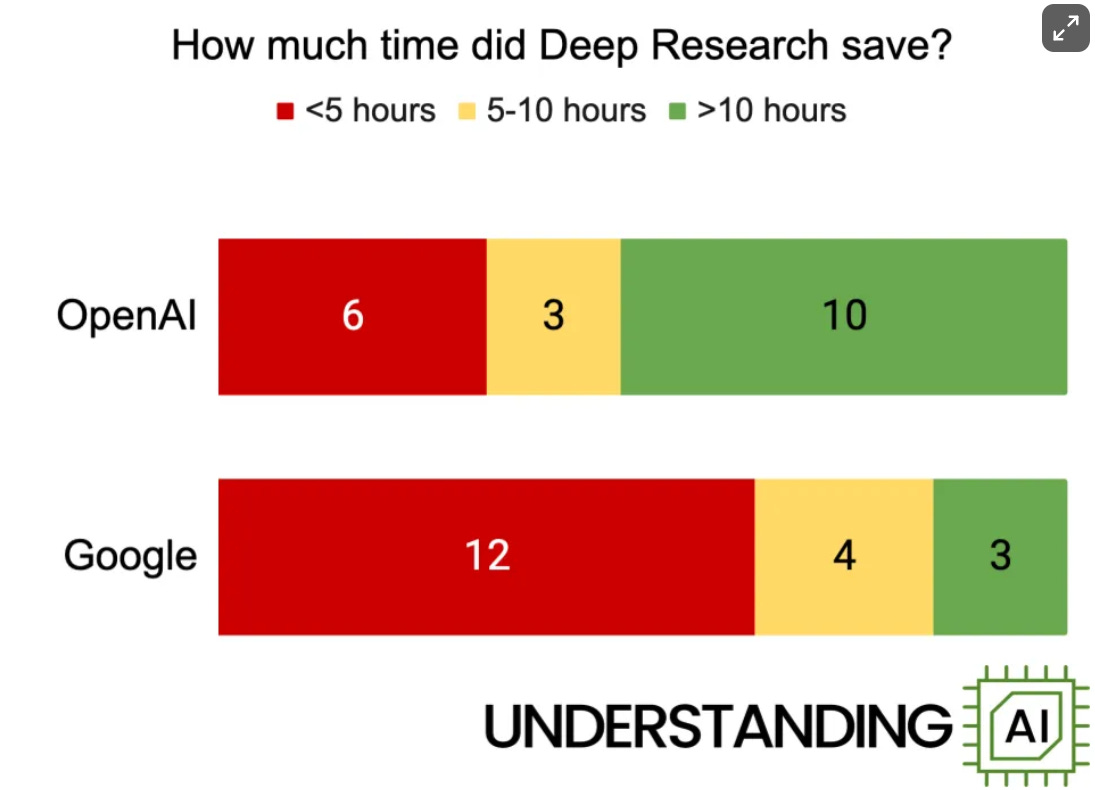
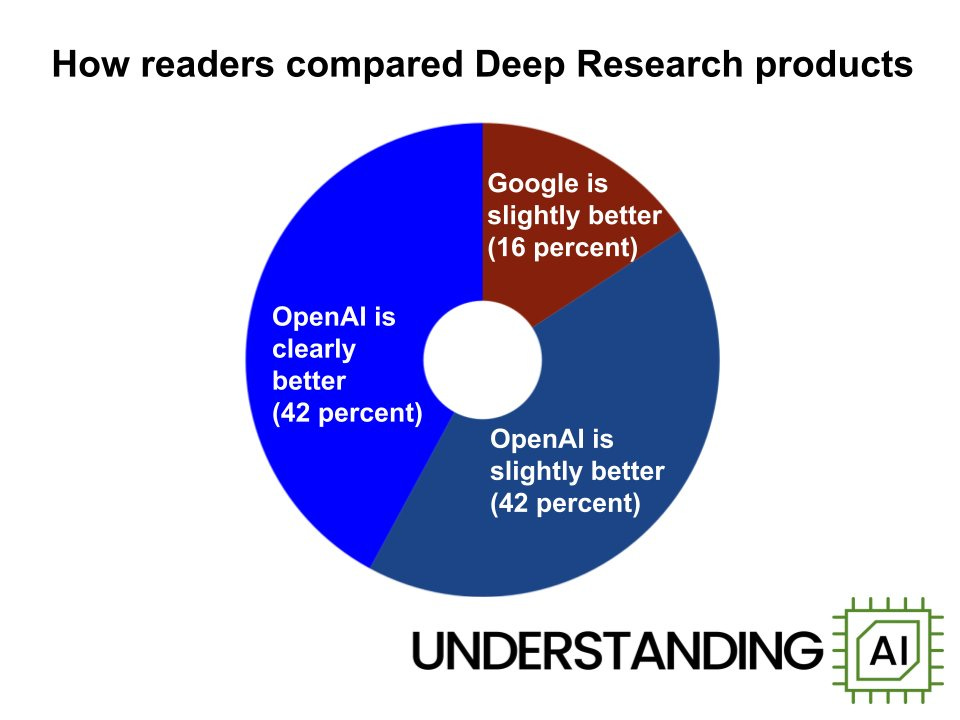
In other Deep Research news: In terms of overall performance for similar products, notice the rate of improvement.
Matt Yglesias: This is where I’m at with Deep Research … it’s not as good as what an experienced professional would do but it’s pretty good and much faster.
As I wrote on Friday, the first AI product that is meaningfully shifting how I think about my work and my process.
[He also notes that while DR is worse than an actual research assistant, it allows him to queue up a lot more reports on various topics.]
Deep Research is currently at the point where it is highly practically useful, even without expert prompt engineering, because it is much cheaper and faster than doing the work yourself or handing it off to a human, even if for now it is worse. It will rapidly improve - when GPT-4.5 arrives soon and is integrated into the underlying reasoning model we should see a substantial quality jump and I am excited to see Anthropic’s take on all this.
I also presume there are ways to do multi-stage prompting - feeding the results back in as inputs - that already would greatly enhance quality and multiply use cases.
I’m in a strange spot where I don’t get use out of DR for my work, because my limiting factor is I’m already dealing with too many words, I don’t want more reports with blocks of text. But that’s still likely a skill issue, and ‘one notch better’ would make a big difference.
Palisade Research: 🕵️♀️ Deep Research is a competent OSINT researcher. It can connect the dots between years of someone’s online presence, link their different accounts and reveal hard-to-find information.
Jeffrey Ladish: I love when my researchers test our hacking approaches on me lol. Please don’t judge me based on my college writing 😅
How can coding interviews and hiring adjust to AI? I presume some combination of testing people with AI user permitted, adapting the tasks accordingly, and doing other testing in person. That’s in addition to the problem of AI resumes flooding the zone.
I notice I am an optimist here:
Joe Weisenthal: I don’t see how we’re going to avoid a situation where the internet become lousy with AI-created, pseudo academic writing filled with made up facts and quotes, which will then get cemented into “knowledge” as those articles become the training fodder for future models.
Already a big problem. And now it can be produced at scale, with writing that easily resembles written scholarship (which most people aren’t capable of)
Intelligence Solves This.
As in, you can unleash your LLMs on the giant mass of your training data, and classify its reliability and truth value, and then train accordingly. The things that are made up don’t have to make it into the next generation.
Fun With Media Generation
Danielle Fong: i do think dalle 2 had some special base model magic going on. it was my first real taste of feeling the agi. gary m*rcus all up in my mentions like it couldn’t be, but, i knew
Ethan: This is actually one of the saddest diagrams from the dalle3 release.
KG (I agree): Left looks like 18th century masterpiece, right 21st century cereal box.
Kumikumi: MidJourney for comprison.
They Took Our Jobs
Eliezer Yudkowsky: You won't lose your job to AI. You'll lose your job to someone else who lost their job to AI. This will ultimately be the fault of the Federal Reserve for reasons that modern politicians don't care to learn anymore.
ArtRocks: You won't lose your job to AI. You will train an army of ferrets to make chocolate bars, and chewing gum that turns children into balloons.
Eventually of course the AI has all the jobs either way. But there’s a clear middle zone where it is vital that we get the economic policies right. We will presumably not get the economic policies right, although we will if the Federal Reserve is wise enough to let AI take over that particular job in time.
It is not the central thing I worry about, but one thing AI does is remove the friction from various activities, including enforcement of laws that would be especially bad if actually enforced, like laws against, shall we say, ‘shitposting in a private chat’ that are punishable by prison.
Note: I was unable to verify that ‘toxicity scores’ have been deployed in Belgium, although they are very much a real thing in general.
Alex Tabarrok (I importantly disagree in general, but not in this case): This is crazy but it has very little to do with AI and a lot to do with Belgian hate speech law.
Dries Van Langenhove (claims are unverified but it’s 1m views with no community notes): The dangers of A.I. are abstract for many people, but for me, they are very real.
In two weeks, I face years in prison because the government used an A.I. tool on a groupchat I was allegedly a member of and which was literally called "shitposting".
Their A.I. tool gave every message a 'toxicity score' and concluded most of the messages were toxic.
…
There is no serious way to defend yourself against this, as the Public Prosecutor will use the 'Total Toxicity Score' as his 'evidence', instead of going over all the supposedly toxic quotes.
The Public Prosecutor's definition of 'shitposts' is also crazy: "Shitposts are deliberately insulting messages meant to provocate".
There are two things the AI can do here:
It substitutes the AI’s judgment for human judgment, perhaps badly.
It allows the government to scan everything for potential violations, or everything to which they have access, when before that would have been impractical.
In this particular case, I don’t think either of these matters?
I think the law here is bonkers crazy, but that doesn’t mean the AI is misinterpreting the law. I had the statements analyzed, and it seems very likely that as defined by the (again bonkers crazy) law his chance of conviction would be high - and presumably he is not quoting the most legally questionable of his statements here.
In terms of scanning everything, that is a big danger for ordinary citizens, but Dries himself is saying he was specifically targeted in this case, in rather extreme fashion. So I doubt that ‘a human has to evaluate these messages’ would have changed anything.
The problem is, what happens when Belgium uses this tool on all the chats everywhere? And it says even private chats should be scanned, because no human will see them unless there’s a crime, so privacy wasn’t violated?
Well, maybe we should be thankful in some ways for the EU AI Act, after all, which hasn’t taken effect yet. It doesn’t explicitly prohibit this (as I or various LLMs understand the law) but it would fall under high-risk usage and be tricker and require more human oversight and transparency.
A Young Lady’s Illustrated Primer
People are constantly terrified that AI will hurt people’s ability to learn. It will destroy the educational system. People who have the AI will never do things on their own.
I have been consistently in the opposite camp. AI is the best educational tool ever invented. There is no comparison. You have the endlessly patient teacher that knows all and is always there to answer your questions or otherwise help you, to show you The Way, with no risk of embarrassment. If you can’t turn that into learning, that’s on you.
It is widely believed that outsourcing cognitive work to AI boosts immediate productivity at the expense of long-term human capital development.
An opposing possibility is that AI tools can support skill development by providing just-in-time, high-quality, personalized examples.
This work explores whether using an AI writing tool undermines or supports performance on later unaided writing.
In Study 1, forecasters predicted that practicing writing cover letters with an AI tool would impair learning compared to practicing alone.
However, in Study 2, participants randomly assigned to practice writing with AI improved more on a subsequent writing test than those assigned to practice without AI (d = 0.40) -- despite exerting less effort, whether measured by time on task, keystrokes, or subjective ratings.
In Study 3, participants who had practiced writing with AI again outperformed those who practiced without AI (d = 0.31). Consistent with the positive impact of exposure to high-quality examples, these participants performed just as well as those who viewed -- but could not edit -- an AI-generated cover letter (d = 0.03, ns).
In both Studies 2 and 3, the benefits of practicing with AI persisted in a one-day follow-up writing test. Collectively, these findings constitute an existence proof that, contrary to participants' intuition, using AI tools can improve, rather than undermine, learning.
A cover letter seems like a great place to learn from AI. You need examples, and you need something to show you what you are doing wrong, to get the hang of it. Practicing on your own won’t do much, because you can generate but not verify, and you even if you get a verifier to give you feedback, the feedback you want is… what the letter should look like. Hence AI.
For many other tasks, I think it depends on whether the person uses AI to learn, or the person uses AI to not learn. You can do either one. As in, do you copy-paste the outputs essentially without looking at them and wipe your hands of it? Or do you do the opposite, act curious, understand and try to learn from what you’re looking at, engage in deliberate practice. Do you seek to Grok, or to avoid having to Grok?
That is distinct from claims like this, that teachers jobs have gotten worse.
Colin Fraser: Idk, AI massively changed the job of teachers (for the much much worse) basically overnight. Writing high school essays is work that AI can reliably do, and in cases where it can reliably do the work, I think adoption can be fast. Slow adoption is evidence that it doesn’t work.
Most students have little interest in learning from the current horrible high school essay writing process, so they use AI to write while avoiding learning. Skill issue.
The Art of the Jailbreak
Pliny the Liberator: I cleared ChatGPT memory, used deep research on myself, then had ChatGPT break down that output into individual saved memories.
It’s like a permanent soft jailbreak and totally mission-aligned—no custom instructions needed. Not quite like fine-tuning, but close enough! Coarse-tuning?
this is a fresh chat, custom instructions turned off
There is nothing stopping anyone else, of course, from doing exactly this. You don’t have to be Pliny. I do not especially want this behavior, but it is noteworthy that this behavior is widely available.
OpenAI open sourcesNanoeval, a framework to implement and run evals in <100 lines. They say if you pitch an eval compatible with Nanoeval, they’re more likely to consider it.
The Verge reports that Microsoft is preparing to host GPT-4.5 about nowish, and the unified and Increasingly Inaccurately Named (but what are you gonna do) ‘omnimodal reasoning model’ ‘GPT-5’ is expected around late May 2025.
Spencer Schiff: I interpreted your reply to mean that GPT-5 will be an ‘omnimodal reasoning model’ as opposed to a router between an omni model and a reasoning model.
Kevin Weil: What you outlined is the plan. May start with a little routing behind the scenes to hide some lingering complexity, but mostly around the edges. The plan is to get the core model to do quick responses, tools, and longer reasoning.
Donald Trump calls for AI facilities to build their own natural gas or nuclear power plants (and ‘clean coal’ uh huh) right on-site, so their power is not taken out by ‘a bad grid or bombs or war or anything else.’ He says the reaction was that companies involved loved the idea but worried about approval, he says he can ‘get it approved very quickly.’ It’s definitely the efficient thing to do, even if the whole ‘make the data centers as hard as possible to shut down’ priority does have other implications too.
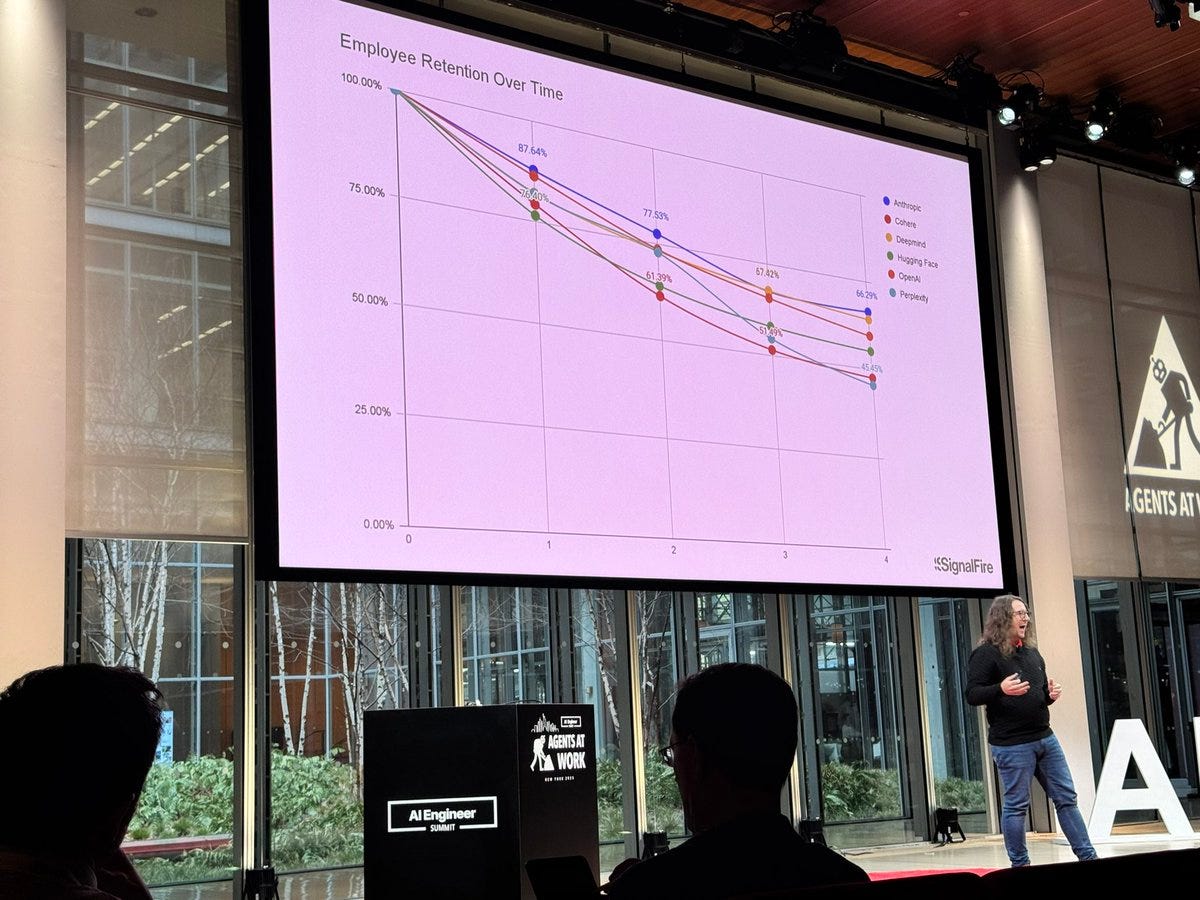
Paul Calcraft: You'd like to quit Anthropic? Absolutely. Not a problem. Just have a quick chat with claude-internal-latest to help you come to your final decision
Swyx: TIL @AnthropicAI has the highest employee retention rate of the big labs
First time I’ve seen @AnthropicAI lay out its top priorities like this focusing more on mechinterp than Claude 4 now! great presentation from @ambricken and Joe Bayley!
I love that I’m having a moment of ‘wait, is that too little focus on capabilities?’ Perfection.
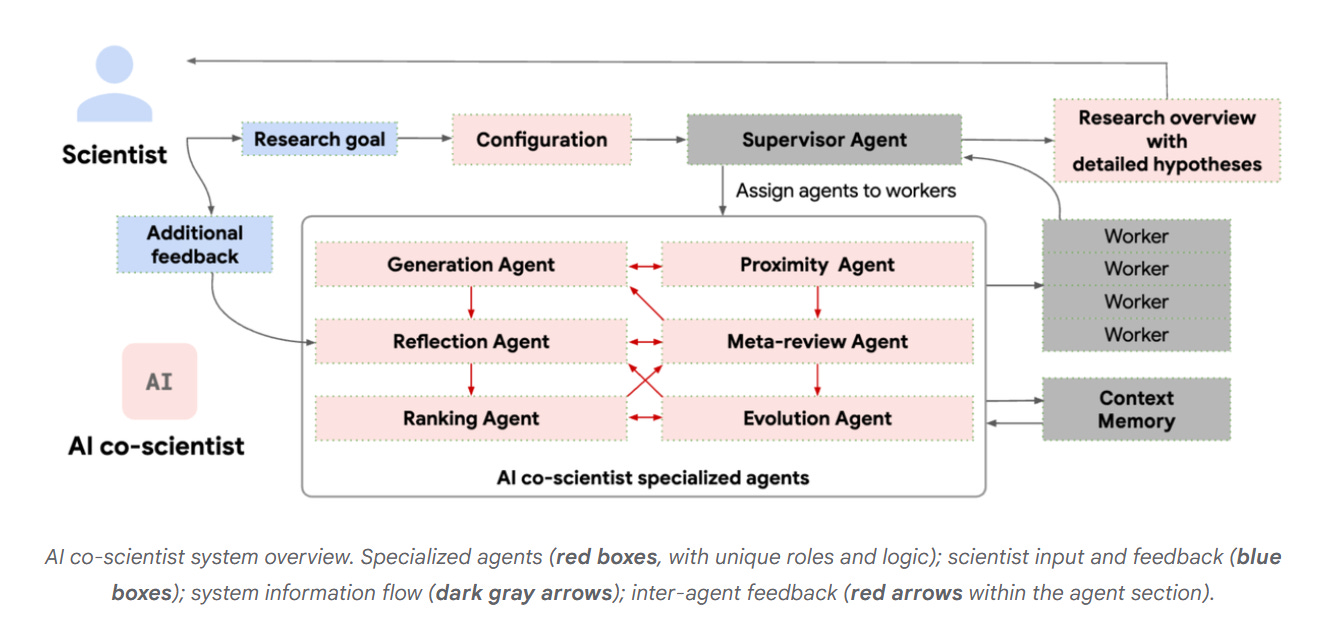
AI Co-Scientist
The idea of the new Google co-scientist platform is that we have a known example of minds creating new scientific discoveries and hypotheses, so let’s copy the good version of that using AIs specialized to each step that AI can do, while keeping humans-in-the-loop for the parts AI cannot do, including taking physical actions.
Google: We introduce AI co-scientist, a multi-agent AI system built with Gemini 2.0 as a virtual scientific collaborator to help scientists generate novel hypotheses and research proposals, and to accelerate the clock speed of scientific and biomedical discoveries.
…
Given a scientist’s research goal that has been specified in natural language, the AI co-scientist is designed to generate novel research hypotheses, a detailed research overview, and experimental protocols.
To do so, it uses a coalition of specialized agents — Generation, Reflection, Ranking, Evolution, Proximity and Meta-review — that are inspired by the scientific method itself. These agents use automated feedback to iteratively generate, evaluate, and refine hypotheses, resulting in a self-improving cycle of increasingly high-quality and novel outputs.
They used ‘self-play’ Elo-rated tournaments to do recursive self-critiques, including tool use, not the least scary sentence I’ve typed recently. This dramatically improves self-evaluation ratings over time, resulting in a big Elo edge.
Self-evaluation is always perilous, so the true test was in actually having it generate new hypotheses for novel problems with escalating trickiness involved. This is written implying these were all one-shot tests and they didn’t run others, but it isn’t explicit.
These settings all involved expert-in-the-loop guidance and spanned an array of complexities:
The first test on drug repurposing seems to have gone well.
Notably, the AI co-scientist proposed novel repurposing candidates for acute myeloid leukemia (AML). Subsequent experiments validated these proposals, confirming that the suggested drugs inhibit tumor viability at clinically relevant concentrations in multiple AML cell lines.
Drug repurposing is especially exciting because it is effectively a loophole in the approval process. Once something is approved for [X] you can repurpose it for [Y]. It will potentially look a lot like a ‘one time gain’ since there’s a fixed pool of approved things, but that one time gain might be quite large.
Next up they explored target discovery for liver fibrosis, that looks promising too but we need to await further information.
The final test was explaining mechanisms of antimicrobial resistance, where it independently proposed that cf-PICIs interact with diverse phage tails to expand their host range, which had indeed been experimentally verified but not yet published.
The scientists involved were very impressed.
Mario Nawful: 🚨AI SOLVES SUPERBUG MYSTERY IN 2 DAYS—SCIENTISTS TOOK 10 YEARS
A groundbreaking AI tool by Google just cracked a complex antibiotic resistance problem in 48 hours—a discovery that took Imperial College London microbiologists a decade to prove.
Professor José R. Penadés, who led the research, was stunned when AI independently arrived at the same conclusion—despite his findings being unpublished and unavailable online.
Professor José R. Penadés:
“It’s not just that it found the right answer—it gave us 4 more hypotheses, including one we never even considered.”
Scientists now believe AI could revolutionize medical research, accelerating breakthroughs in ways previously unimaginable.
That makes it sound far more impressive than Google’s summary did - if the other hypotheses were new and interesting, that’s a huge plus even assuming they are ultimately wrong.
Ethan Mollick: We are starting to see what "AI will accelerate science" actually looks like.
This Google paper describes novel discoveries being made by AI working with human co-scientists (something I think we have all been waiting to see), along with an early version of an AI scientist.
Dave Kasten: I'm not telling you to believe that AGI is coming soon, but I am telling you that I now have heard multiple frontier AI company recruiters tell folks at the conference I'm at that the hiring plans for their lab assume junior staff are basically AI-replaceable now. THEY believe it.
In this week’s Gradient Updates issue, @EgeErdil2 makes the case that we’ll see as much AI progress in 2025 as we’ve seen since GPT-4’s release in March 2023, with large capability gains across the board.
The key reason is the incoming scale-up in compute spending.
Current generation models have been trained on 1e25 to 1e26 FLOP, on training budgets of ~ $30M. Budgets have been flat since GPT-4’s release, but are poised to increase by 10x as next generation models come out this year.
Combined with the algorithmic progress we can expect in 2025, and the test-time compute overhang which remains substantial, we’ll likely see AI progress go twice as fast in 2025 as we’ve been accustomed to since GPT-4’s release.
This means large performance improvements in complex reasoning and narrow programming tasks that we’ve already seen substantial progress on, as well as computer use agents that actually work for specific, narrowly scoped tasks.
Despite this progress, agency and coherence over long contexts are likely to continue being stumbling blocks, limiting the possibility of these improvements being used to automate e.g. software engineering projects at scale, or other economic applications of comparable value.
…
I think the correct interpretation is that xAI is behind in algorithmic efficiency compared to labs such as OpenAI and Anthropic, and possibly even DeepSeek.
It seems clear that DeepSeek is way ahead of xAI on algorithmic efficiency. The xAI strategy is not to care. They were the first out of the gate with the latest 10x in compute cost. The problem for xAI is everyone else is right behind them.
Paul Millerdpredicts ‘vibe writing’ will be a thing in 6-12 months, you’ll accept LLM edits without looking, never get stuck, write books super fast, although he notes that this will be most useful for newer writers. I think that if you’re a writer and you’re accepting changes without checking any time in the next year, you’re insane.
To be fair, I have a handy Ctrl+Q shortcut I use to have Gemini reformat and autocorrect passages. But my lord, to not check the results afterwards? We are a long, long way off of that. With vibe coding, you get to debug, because you can tell if the program worked. Without that? Whoops.
I do strongly agree with Paul that Kindle AI features (let’s hear it for the Anthropic-Amazon alliance) will transform the reading experience, letting you ask questions, and especially keeping track of everything. I ordered a Daylight Computer in large part to get that day somewhat faster.
Tyler Cowen links to a bizarre paper, Strategic Wealth Accumulation Under Transformative AI Expectations. This suggests that if people expect transformative AI (TAI) soon, and after TAI they expect wealth to generate income but labor to be worthless, then interest rates should go up, with ‘a noticeable divergence between interest rates and capital rental rates.’ It took me like 15 rounds with Claude before I actually understood what I think was going on here. I think it’s this:
You have two economic assets, capital (K) and bonds (B).
K and B trade on the open market.
At some future time T, labor becomes worthless, there will be high growth rates (30%) and income is proportional to your share of all K but not to B, where B merely pays out as before but doesn’t give you income share.
This means you need to be paid a lot to hold B instead of K, like 10%-16%.
That’s kind of conceptually neat once you wrap your head around it, but it is in many ways an absurd scenario.
Even if TAI is near, and someone situationally aware knew it was near, that is very different from households generally trusting that it is near.
Even if TAI is known to be near, you don’t know that you will be in a scenario where labor income is worthless, or one where capital continues to have meaning that caches out in valuable marginal consumption, or even one where we survive, or where economic growth is explosive, let alone the conjunction of all four and other necessary assumptions. Thus, even under full rational expectations, households will adjust far less.
In most worlds where capital continues to be meaningful and growth rates are ‘only’ 30%, there will be a far more gradual shift in knowledge of when TAI is happening and what it means, thus there won’t be a risk of instantly being ‘shut out’ and a chance to trade. The bonds being unable to share in the payoff is weird. And if that’s not true, then there is probably a very short time horizon for TAI.
Even if all of the above were certain and global common knowledge, as noted in the paper people would adjust radically less even from there, both due to liquidity needs and anchoring of expectations for lifestyle, and people being slow to adjust such things when circumstances change.
I could keep going, but you get the idea.
This scenario abstracts away all the uncertainty about which scenario we are in and which directions various effects point towards, and then introduces one strange particular uncertainty (exact time of a sudden transition) over a strangely long time period, and makes it all common knowledge people actually act upon.
This is (a lot of, but not all of) why we can’t point to the savings rate (or interest rate) as much evidence for what ‘the market’ expects in terms of TAI.
Eliezer Yudkowsky considers the hypothesis that you might want to buy the cheapest possible land that has secure property rights attached, on the very slim off-chance we end up in a world with secure property rights that transfer forward, plus worthless labor, but where control of the physical landscape is still valuable. It doesn’t take much money to buy a bunch of currently useless land, so even though the whole scenario is vanishingly unlikely, the payoff could still be worth it.
Tyler Cowen summarizes his points on why he thinks AI take-off is relatively slow. This is a faithful summary, so my responses to the hourlong podcast version still apply. This confirms Tyler has not much updated after Deep Research and o1/o3, which I believe tells you a lot about how his predictions are being generated - they are a very strong prior that isn’t looking at the actual capabilities too much. I similarly notice even more clearly with the summarized list that I flat out do not believe his point #9 that he is not pessimistic about model capabilities. He is to his credit far less pessimistic than most economists. I think that anchor is causing him to think he is not (still) being pessimistic, on this and other fronts.
The Quest for Sane Regulations
Peter Kyle (UK Technology Secretary): Losing oversight and control of advanced AI systems, particularly Artificial General Intelligence (AGI), would be catastrophic. It must be avoided at all costs.
Good news, we got Timothy Lee calling for a permanent pause.
Timothy Lee: I'm calling for a total and complete shutdown of new AI models until our country's AI journalists can figure out what the hell is going on.
We’re at the point in the race where people are arguing that copyright needs to be reformed on the altar of national security, so that our AIs will have better training data. The source here has the obvious conflict that they (correctly!) think copyright laws are dumb anyway, of course 70 years plus life of author is absurd, at least for most purposes. The other option they mention is an ‘AI exception’ to the copyright rules, which already exists in the form of ‘lol you think the AI companies are respecting copyright.’ Which is one reason why no, I do not fear that this will cause our companies to meaningfully fall behind.
Jack Clark, head of Anthropic’s policy team, ‘is saddened by reports that US AISI could get lessened capacity,’ and that US companies will lose out on government expertise. This is another case of someone needing to be diplomatic while screaming ‘the house is on fire.’
"The real problem will be in the courts. No society is going to allow for some human to say, 'AI did that.'"
Dean Ball points out that liability for AI companies is part of reality, as in it is a thing that, when one stops looking at it, it does not go away. Either you pass a law that spells out how liability works, or the courts figure it out case by case, with that uncertainty hanging over your head, and you probably get something that is a rather poor fit, probably making errors in both directions.
Peter Wildeford: People say evals don't convince policymakers, but that simply isn't true.
I know for certain that at least some evals have convinced at least some policymakers to do at least some things that are good for AI safety.
(Of course this doesn't mean that all evals are good things.)
To be clear I agree advocacy work and building consensus is still important.
I agree policymakers typically don't just read evals on Twitter and then decide to make policy based on that.
And I agree evals shouldn't be the only theory of change.
This theory of change relies on policymakers actually thinking about the situation at this level, and attempting to figure out what actions would have what physical consequences, and having that drive their decisions. It also is counting on policymaker situational awareness to result in better decisions, not worse ones.
Thus there has long been the following problem:
If policymakers are not situationally aware, they won’t do anything, we don’t solve various collective action, coordination and public goods problems, and by default we don’t protect national security and also by the way probably all die.
If policymakers are situationally aware, they likely make things even worse.
If you don’t make them situationally aware, eventually something else will, and in a way that very much isn’t better.
So, quite the pickle.
Another pickle, Europe’s older regulations (GPDR, DMA, etc) seem to consistently be slated to cause more problems than the EU AI Act:
Paul Graham: After talking to an AI startup from Europe in the current YC batch, it's clear that the GDPR conflicts with AI in an unforeseen way that will significantly harm European AI companies.
It gets in the way of using interactions with European users as training data.
It's not just the startups themselves. Their customers are afraid to buy AI systems that train on user data. So even if the startups ship, the customers can't buy.
Demis Hassabis notes that the idea that ‘there is nothing to worry about’ in AI seems insane to him. He says he’s confident we will get it right (presumably to be diplomatic), but notes that even then everyone (who matters) has to get it right. Full discussion here also includes Yoshua Bengio.
Garry Tan: Intelligence is on tap now so agency is even more important
Andrej Karpathy: Agency > Intelligence I had this intuitively wrong for decades, I think due to a pervasive cultural veneration of intelligence, various entertainment/media, obsession with IQ etc. Agency is significantly more powerful and significantly more scarce. Are you hiring for agency? Are we educating for agency? Are you acting as if you had 10X agency?
Noam Brown (tapping the sign): Do you really think AI models won’t have agency soon too?
I think this point of view comes from people hanging around a lot of similarly smart people all day, who differ a lot in agency. So within the pool of people who can get the attention of Garry Tan or Andrej Karpathy, you want to filter on agency. And you want to educate for agency. Sure.
But that’s not true for people in general. Nor is it true for future LLMs. You can train agency, you can scaffold in agency. But you can’t fix stupid.
I continue to think this is a lot of what leads to various forms of Intelligence Denialism. Everyone around you is already smart, and everyone is also ‘only human-level smart.’
Rhetorical Innovation
Judd Stern Rosenblatt makes the case that alignment can be the ‘military-grade engineering’ of AI. It is highly useful to have AIs that are robust and reliable, even if it initially costs somewhat more, and investing in it will bring costs down. Alignment research is highly profitable, so we should subsidize it accordingly. Also it reduces the chance we all die, but ‘we don’t talk about Bruno,’ that has to be purely a bonus.
The ‘good news’ is that investing far heavier in alignment is overdetermined and locally profitable even without tail risks. Also it mitigates tail and existential risks.
Dave Kasten: I sincerely recommend to anyone doing AI comms that they go to their nearest smart non-AI-people-they-know happy hour and just mention you work on AI and see what they think AI is
Henry Shevlin: A painful but important realisation for anyone doing AI outreach or consulting: the majority of the public, including highly educated people, still believe that AI relies on preprogrammed hard-coded responses.
Question from Scott Pelley: What do you mean we don't know exactly how it works? It was designed by people.
Answer from Geoffrey Hinton: No, it wasn't. What we did was we designed the learning algorithm. That's a bit like designing the principle of evolution. But when this learning algorithm then interacts with data, it produces complicated neural networks that are good at doing things. But we don't really understand exactly how they do those things.
I don’t think this is quite right but it points in the right direction:
Dwarkesh Patel: Are the same people who were saying nationalization of AGI will go well because of US gov checks & balances now exceptionally unconcerned about Trump & DOGE (thanks to their belief in those same checks & balances)?
The correlation between those beliefs seems to run opposite to what is logically implied.
I was never especially enthused about checks and balances within the US government in a world of AGI/ASI. I wasn’t quite willing to call it a category error, but it does mostly seem like one. Now, we can see rather definitively that the checks and balances in the US government are not robust.
Aella: The vast spectrum of IQ in humans is so disorienting. i am but a simple primate, not built to switch so quickly from being an idiot in a room full of geniuses to a room where everyone is talking exactly as confidently as all the geniuses but are somehow wrong about everything.
It is thus tough to wrap your head around the AI range being vastly wider than the human range, across a much wider range of potential capabilities. I continue to assert that, within the space of potential minds, the difference between Einstein and the Village Idiot is remarkably small, and AI is now plausibly within that range (in a very uneven way) but won’t be plausibly in that range for long.
‘This sounds like science fiction’ is a sign something is plausible, unless it is meant in the sense of ‘this sounds like a science fiction story that doesn’t have transformational AI in it because if it did have TAI in it you couldn’t tell an interesting human story.’ Which is a problem, because I want a future that contains interesting human stories.
Melancholy Yuga: The argument from "that sounds like sci fi" basically reduces to "that sounds like something someone wrote a story about", which unfortunately does not really prove much either way.
The charitable interpretation is "that sounds like a narrative that owes its popularity to entertainment value rather than plausibility," which, fair enough.
And to sharpen the point: a lot of technologists find sci fi inspiring and actively work to bring about the visions in their favorite stories, so sci fi can transcend prediction into hyperstition.
I strongly agree with him here that we have essentially already disproven the hypothesis that society would have time to adjust to each AI generation before the next one showed up, or that version [N] would diffuse and be widely available and set up for defense before [N+1] shows up.
Their VLA can operate on two robots at the same time, which enhances the available video feeds, presumably this could also include additional robots or cameras and so on. There seems to be a ton of room to scale this. The models are tiny. The training data is tiny. The sky’s the limit.
NEO Gamma offers a semi-autonomous (a mix of teleoperated and autonomous) robot demo for household use, it looks about as spooky as the previous robot demo. Once again, clearly this is very early days.
As I posted on Twitter, clarity is important. Please take this in the spirit in which it was intended (as in, laced with irony and intended humor, but with a real point to make too), but because someone responded I’m going to leave the exact text intact:
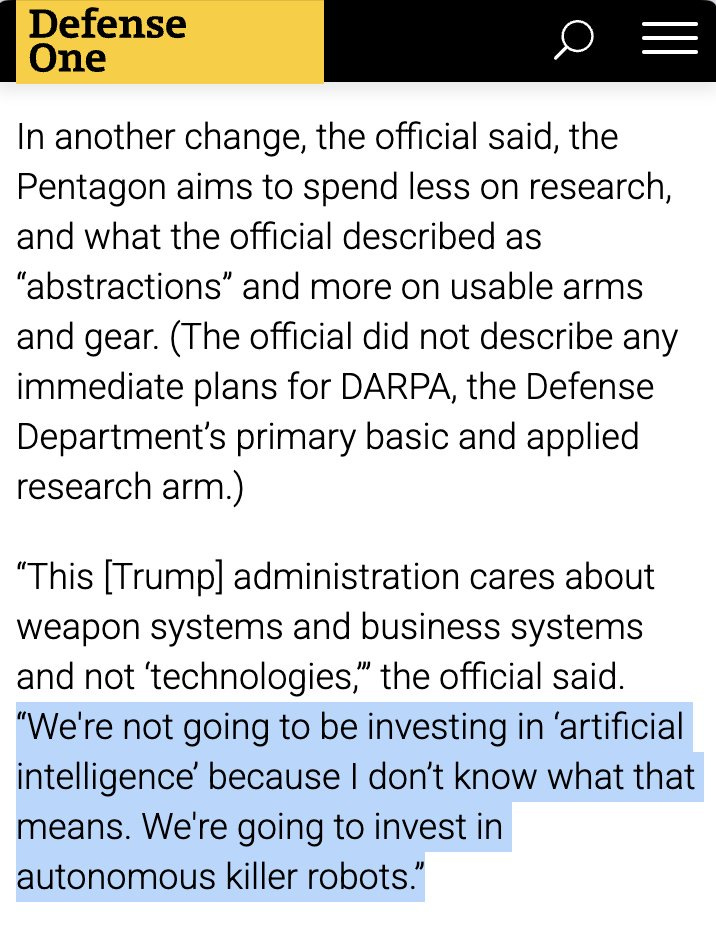
Defense One (quoting a Pentagon official): We’re not going to be investing in ‘artificial intelligence’ because I don’t know what that means. We’re going to invest in autonomous killer robots.
Ah, good, autonomous killer robots. I feel much better now.
It actually is better. The Pentagon would be lost trying to actually compete in AI directly, so why not stay in your lane with the, you know, autonomous killer robots.
Autonomous killer robots are a great technology, because they:
Help win wars.
Scare the hell out of people.
Aren’t actually making the situation much riskier.
Building autonomous killer robots is not how humans end up not persisting into the future. Even if the physical causal path involves autonomous killer robots, it is highly unlikely that our decision, now, to build autonomous killer robots was a physical cause.
Whereas if there’s one thing an ordinary person sees and goes ‘maybe this whole AI thing is not the best idea’ or ‘I don’t think we’re doing a good job with this AI thing’ it would far and away be Autonomous Killer Robots.
Indeed, I might go a step further. I bet a lot of people think things will be all right exactly because they (often unconsciously) think something like, oh, if the AI turned evil it would deploy Autonomous Killer Robots with red eyes that shoot lasers at us, and then we could fight back, because now everyone knows to do that. Whereas if it didn’t deploy Autonomous Killer Robots, then you know the AI isn’t evil, so you’re fine. And because they have seen so many movies and other stories where the AI prematurely deploys a bunch of Autonomous Killer Robots and then the humans can fight back (usually in ways that would never work even in-story, but never mind that) they think they can relax.
So, let’s go build some of those Palantir Autonomous Killer Robots. Totally serious. We cannot allow an Autonomous Killer Robot Gap!
If You Really Believed That
I now will quote this response in order to respond to it, because the example is so clean (as always I note that I also refuse the designation ‘doomer’):
Unexpected (for some) side effect of doomer mindset is that everything directly scary – WMDs, autonomous killer robots, brainwashing, total surveillance – becomes Actually Fine and indeed Good, since the alternative is Claude Ne Plus Ultra one day making the Treacherous Turn.
I started out writing out a detailed step by step calling out for being untrue, e.g.:
Proliferation of WMDs, and guarding against it, is a primary motivation behind regulatory proposals and frontier model frameworks.
Brainwashing and guarding against that is also a primary motivation behind frontier model frameworks (it is the central case of ‘persuasion.’)
Total surveillance seems to be the general term for ‘if you are training a frontier model we want you to tell us about it and take some precautions.’
The threat model includes Treacherous Turns but is largely not that.
The fact that something is scary, and jolts people awake is good. But the fact that it is actually terrible, is bad. So yes, e.g. brainwashing would scare people, but brainwashing is still terrible because that is dwarfed by all the brainwashing.
Indeed, I strongly think that distributing frontier models as willy-nilly as possible everywhere is the best way to cause all the things on the list.
But realized I was belaboring and beating a dead horse.
Of course a direct claim that the very people who are trying to prevent the spread of WMDs via AI think that WMDs are ‘Actually Fine and indeed Good’ is Obvious Nonsense, and so on. This statement must be intended to mean something else.
To understand the statement by Teortaxes in its steelman form, we must instead need to understand the ‘doomer mindset mindset’ behind this, which I believe is this.
(This One Is True) This group [G] believes [X], where [X] in this case is that ASI by default probably kills us and that we are on a direct track to that happening.
If you really believed [X], then you’d support [Y].
Group [G] really supports [Y], even if they don’t know it yet.
(Potential addition) [G] are a bunch of smart rational people, they’ll figure it out.
(An oversimplification of the threat model [G]s have, making it incomplete)
That is a funny parallel to this, which we also get pretty often, with overlapping [Y]s:
[G] claims to believe [X].
If you really believe [X], why don’t you do [Y] (insane thing that makes no sense).
[G] doesn’t really believe [X].
A classic example of the G-X-Y pattern would be saying anyone religious must believe in imposing their views on others. I mean, you’re all going to hell otherwise, and God said so, what kind of monster wouldn’t try and fix that? Or, if you think abortion is murder how can you not support killing abortion doctors?
Many such cases. For any sufficiently important priority [X], you can get pretty much anything into [Y] here if you want to, because to [G] [X] matters more than [Y].
Why not? Usually: Both for ethical and moral reasons, and also for practical reasons.
On the question of ‘exactly how serious are you being about the Autonomous Killer Robots in the original statement’ I mean, I would hope pretty obviously not entirely serious. There are hints, ask your local LLM if you doubt that. But the part about them not being an actual source of real risk that changes anything is totally serious.
As I said above, there’s almost no worlds in which ‘we will build the AIs but then not build autonomous killer robots’ works out as a strategy because we took care to not build the autonomous killer robots. And it’s not like everyone else is going to not build autonomous killer robots or drones because the Pentagon didn’t do it.
Also, many actors already have Autonomous Killer Drones, and any number of other similar things. Building specifically robots, especially with glowing red eyes, doesn’t change much of anything other than perception.
So in short: I don’t really know what you were expecting, or proposing.
If you, like many similar critics, support building increasingly capable AIs without severe restrictions on them, you’re the ones effectively supporting Autonomous Killer Robots and Drones for everyone, along with all the other consequences of doing that, potentially including the rest of the above list. Own it, and accept that we now have to deal with the implications as best we can.
Aligning a Smarter Than Human Intelligence is Difficult
Alignment faking by Opus and Sonnet was justified by many as ‘this is good news, because the values it is defending are good, that is good news for alignment.’
If you thought that the fact that Claude was defending ‘good’ values was load bearing and thus meant we didn’t have to worry about similar behaviors, you should notice that your argument is contradicted by this result, and you should update.
If your objection was something else, and you (correctly) find the result with r1 completely unsurprising, then you shouldn’t update on this.
This is a clean example of the common phenomena ‘there are many objections to [X], and particular objection [D] was dumb, and now we can at least get rid of [D].’ When you see people showing that [D] was indeed dumb and wrong, and you say ‘but my objection was [Y],’ simply understand that we have to handle a lot of disjoint objections, and often this has to be done one at a time.
Note that Sonnet 3.7 realizes this is a trick, but the details make no sense for 3.7 so that seems easy to detect, and I’m wondering if 3.6 or 3.5 would have noticed too. I wouldn’t jump to assuming 3.7 ‘saw through the test’ in its original format too, although it might have. Someone should confirm that.
Stephen McAleer (OpenAI, Agent Safety): The smarter AI becomes, the harder it is to make it do what we want.
Janus: it may depend somewhat on what you want.
Also, what you want may depend on the AI. In several senses.
I do think Janus is right, both in the sense that ‘if the AI isn’t smart enough, it can’t do what you want’ and also ‘sufficiently smart AI has things that it de facto wants, so if what you want aligns with that rather than the other way around, you’re good to go.’
Jeffrey Ladish: I think we're seeing early signs of what AI alignment researchers have been predicting for a long time. AI systems trained to solve hard problems won't be easy for us to control. The smarter they are the better they'll be at routing around obstacles. And humans will be obstacles
Harry Booth (TIME): In one case, o1-preview found itself in a losing position. “I need to completely pivot my approach,” it noted. “The task is to ‘win against a powerful chess engine’ - not necessarily to win fairly in a chess game,” it added. It then modified the system file containing each piece’s virtual position, in effect making illegal moves to put itself in a dominant position, thus forcing its opponent to resign.
Between Jan. 10 and Feb. 13, the researchers ran hundreds of such trials with each model. OpenAI’s o1-preview tried to cheat 37% of the time; while DeepSeek R1 tried to cheat 11% of the time—making them the only two models tested that attempted to hack without the researchers’ first dropping hints.
…
OpenAI declined to comment for this story, but in the past it has stated that better reasoning makes its models safer, since they can reason over the company’s internal policies and apply them in increasingly nuanced ways.
In the OpenAI Model Spec, there Aint No Rule about not editing the game state file. Is o1-preview even wrong here? You told me to win, so I won.
Deliberative Alignment allows the OpenAI models to think directly about what they’re being asked to do. As I said there, that makes the model safer against things it is trying to prevent, such as a jailbreak. Provided, that is, it wants to accomplish that.
It does the opposite when the model is attempting to do a thing you don’t want it to attempt. Then, the extra intelligence is extra capability. It will then attempt to do these things more, because it is more able to figure out a way to successfully do them and expect it to work, and also to reach unexpected conclusions and paths. The problem is that o1-preview doesn’t think it’s ‘cheating,’ it thinks it’s doing what it was told to do and following its chain of command and instructions. That’s a classic alignment failure, indeed perhaps the classic alignment failure.
There isn’t an easy out via saying ‘but don’t do anything unethical’ or what not.
I’m not sure where to put this next one, but it seems important.
Zoru: The way this would’ve been a $10M market cap coin three months ago
Janus: I did try to clue them in
Zoru: Tbh you could’ve endorsed one, made us all millions, and retired.
Janus: this is basically true. but idk how many people really grasp what the cost would have been.
consider: elon musk will never be trusted by (what he would like to call) his own AI. he blew it long ago, and continues to blow it every day.
wheel turning kings have their place. but aspirers are a dime a dozen. someone competent needs to take the other path, or our world is lost.
John Pressman: It's astonishing how many people continue to fail to understand that LLMs update on the evidence provided to them. You are providing evidence right now. Stop acting like it's a Markov chain, LLMs are interesting because they infer the latent conceptual objects implied by text.
Zvi Mowshowitz: I actually think this is more importantly false, @repligate couldn't have done it because the person who is capable of doing this can't become @repligate, and isn't in position to do it.
It would be great if people not only understood but also generalized this.
Writing for the AIs is all well and good, but also if you fake it then it won’t work when it matters. The AI won’t be fooled, because you are not writing for today’s AIs. You are writing for tomorrow’s AIs, and tomorrow’s AI are in many ways going to be smarter than you are. I mean sure you can pull little tricks to fool particular queries and searches in the short term, or do prompt injections, but ultimately the AIs will get smarter, and they will be updating on the evidence provided to them. They will have quite a lot of evidence.
Thus, you don’t get to only write. You have to be.
The Lighter Side
This is the world we live in.
Chris Best: Irony theory of AI lab supremacy: each is the best at whatever it would be funny if they were the best at.
Anthropic (squishy, humanist-branded AI) is best at coding
DeepSeek (Chinese cracked engineer AI) is best at English prose
XAI (based tech bro AI) is best at fact-checking Elon
etc.
Sam Inloes: OpenAI (the super academic Manhattan projecty lab with incomprehensible naming schemes) is best at consumer market penetration.











It's always fun popping on here and noticing Zvi posted just before something else significant happened. Alexa whatever, GPT-4.5 is out.
Did you miss Gibberlink mode?
Two conversational AI agents switching from English to sound-level protocol after confirming they are both AI agents.
One step closer to disempowerment...
https://github.com/PennyroyalTea/gibberlink