At least two potentially important algorithmic improvements had papers out this week. Both fall under ‘this is a well-known human trick, how about we use that?’ Tree of Thought is an upgrade to Chain of Thought, doing exactly what it metaphorically sounds like it would do. Incorporating world models, learning through interaction via a virtual world, into an LLM’s training is the other. Both claim impressive results. There seems to be this gigantic overhang of rather obvious, easy-to-implement ideas for improving performance and current capabilities, with the only limiting factor being that doing so takes a bit of time.
That’s scary. Who knows how much more is out there, or how far it can go? If it’s all about the algorithm and they’re largely open sourced, there’s no stopping it. Certainly we should be increasingly terrified of doing more larger training runs, and perhaps terrified even without them.
The regulation debate is in full swing. Altman and OpenAI issued a statement reiterating Altman’s congressional testimony, targeting exactly the one choke point we have available to us, which is large training runs, while warning not to ladder pull on the little guy. Now someone - this means you, my friend, yes you - need to get the damn thing written.
The rhetorical discussions about existential risk also continue, despite moral somewhat improving. As the weeks go by, those trying to explain why we might all die get slowly better at navigating the rhetoric and figuring out which approaches have a chance of working on which types of people with what background information, and in which contexts. Slowly, things are shifting in a saner direction, whether or not one thinks it might be enough. Whereas the rhetoric on the other side does not seem to be improving as quickly, which I think reflects the space being searched and also the algorithms being used to search that space.
OpenAI Requests Sane Regulation. OpenAI puts out a statement Governance of Superintelligence that asks for regulation of large training runs while letting people have fun with less powerful and less dangerous systems. So of course it must be a ladder pull completely motivated by profits.
That Which Is Too Smart For You, Strike That, Reverse It. If you aren’t stupid enough to imagine how the EU is going to screw up their regulations, perhaps you are not smart enough to figure out how the future AGI is going to beat you?
People Are Worried About AI Killing Us. Yoshua Bengio explains, Former Israeli PM Naftali Benett if anything gets a little ahead of himself, Jacy Reese Anthis, Steven Byrnes, Tim Urban and a few more.
Other People Are Not As Worried About AI Killing Us. Nabeel Qureshi in Wired, Norswap, Dominic Pino, Alex Tabarrok and also Maxwell Tabarrok, Garett Jones at length saying intelligence doesn’t much matter, Jacob Buckman.
Personal observation: Bing Chat’s bias towards MSN news over links is sufficiently obnoxious that it substantially degrades Bing’s usefulness in asking about news and looking for sources, at least for me, which would otherwise be its best use case. Blatant self-dealing.
Ramp claims that they can use GPT-enabled tech to save businesses 3% on expenses via a combination of analyzing receipts, comparing deals, negotiating prices. They plan to use network effects, where everyone shares prices paid with Ramp, and Ramp uses that as evidence in negotiations. As usual, note that as such price transparency becomes more common, competition on price between providers increases which is good, and negotiations on price become less lucrative because they don’t stay private. That makes it much tougher to do price discrimination, for better and for worse.
I notice this in my own work as well. The less idea I have what I’m talking about or asking about, or I want a particular piece of information without knowing where it is, the more talking to AIs is useful relative to Google.
There’s also a lot of developer-oriented stuff in here. I do not feel qualified to evaluate these parts based on what little information is here, they may or may not be of any net use.
The big question here is how to balance functionality and security, even more than 365 Copilot or Bard. This level of access is highly dangerous for many obvious reasons.
Papershows a way to use reinforcement learning on a standard diffusion model, which is non-trivial (GitHub link). Starts to be better at giving the user what they requested, with a focus on animals doing various activities. Also includes our latest example of goal misalignment, as the model fails to get the number of animals right because it instead learns to label the picture as having the requested number.
Sergey Levine: Of course this is not without limitations. We asked the model to optimize for rewards that correctly indicate the *number* of animals in the scene, but instead it just learned to write the number on the image :( clever thing...
I love how clean an example this is of ‘manipulate the human doing the evaluation.’
SAG ACTORS: I want to talk about AI and how it will affect you. I’m a former SAG Board Member and former SAG Negotiating Committee member. I’m also WGA and DGA.
As a coder and someone with a computer science degree I want to tell you where I believe AI is going.
1. AI-written scrips & digitally-scanned actors (image and/or voice). Both already exist. Some talent agencies are actively recruiting their clients to be scanned. You choose the projects and get 75 cents on the dollar. Your digital image can be triple and quadruple booked, so that bodes well for a 10 percenter.
2. Films customized for a viewer, based on their viewing history, which has been collected for many years. Actors will have the option to have their image “bought out” to be used in anything at all.
3. Films “ordered up“ by the viewer. For example, “I want a film about a panda and a unicorn who save the world in a rocket ship. And put Bill Murray in it.”
4. Viewers getting digitally scanned themselves, and paying extra to have themselves inserted in these custom films.
5. Licensing deals made with studios so that viewers can order up older films like STAR WARS and put their face on Luke Skywalker‘s body and their ex-wife‘s face on Darth Vader‘s body, etc.
6. Training an AI program on an older hits TV series, and creating an additional season. FAMILY TIES, for example, has 167 episodes. An AI program could easily be trained on this, and create an eighth season. We only shot seven.
AI has to be addresses now or never. I believe this is the last time any labor action will be effective in our business. If we don’t make strong rules now, they simply won’t notice if we strike in three years, because at that point they won’t need us.
Addendum: Actors, you must have iron-clad protection against the AI use of your image and voice in the SAG MBA or your profession is finished. Demand it from @sagaftra and do not accept any AMPTP proposal that does not have it.
Needless to say, no @IATSE crew members, no @Teamster drivers, and no #DGA directors will be needed. At first these efforts will be run by software project managers, and eventually even they won’t be needed.
That eighth season of Family Ties would suck. How many years from now would it no longer suck, if you thought season seven of Family Ties was pretty good? That depends on many factors, including how much human effort goes into it. My guess is that traditional sitcoms are relatively tractable, so maybe it would be Watchable within a few years once video gets solved with some human curation, but it seems hard for it to be Good (Tier 3) without humans doing a large percentage of the writing, with Worth It (Tier 2) that is AI-written seeming AI complete.
Over time, new forms will likely arise, that take advantage of what the AI is good at, especially interactive and custom ones, including in virtual reality. If I am going to have the AI generate a movie for me, at a minimum I want it to respond when I yell at the characters to not be idiots.
Will some people put their face on Luke Skywalker? Yeah, sure, but my guess is that it will be more common to swap in actual actors for each other to recast films and shows, and especially voices. As an example of negative selection, when I recently watched The Sandman, I definitely would have recast the raven, because that which worked fine in Agents of Shield and in some pretty good stand-up totally didn’t fit the vibe. Positive selection will be even bigger, probably, put in whoever you love. Also we should expect to see things like systematic de-aging.
But if you order up that panda and unicorn in a rocket ship with Bill Murray on request, as a non-interactive movie, without humans sculpting the experience? I mean let’s face it, it’s going to suck, and suck hard, for anyone over the age of eight.
The Kobbeissi Letter: This morning, an AI generated image of an explosion at the US Pentagon surfaced. With multiple news sources reporting it as real, the S&P 500 fell 30 points in minutes. This resulted in a $500 billion market cap swing on a fake image. It then rebounded once the image was confirmed fake. AI is becoming dangerous.
The question becomes is this an issue with AI, reporting, or both?
While AI is advancing, breaking news is becoming even more real time.
With images that are fake but appear to be real, breaking news outlets are vulnerable.
The fake image (labeled by Twitter as ‘Manipulated Media’ btw where it doesn’t have a giant X through it, though not where it does):
The BloombergFeed account intentionally sounds and looks like Bloomberg. It’s possible someone responsible made off with rather quite a lot of money here.
Notice that this isn’t an especially impressive fake.
Eliezer Yudkowsky: Stay safe, believe nothing you see or hear. Someone will inevitably point out this could've been done with Photoshop. Sure, but it'd have taken more skills. More and cheaper epistemic vandalism is now in reach of less committed people with less technological ability.
I am guessing this particular image is not even ‘would have taken more skills’ it is ‘would not have occurred to people to try.’
Grimes: Am I crazy or is this mostly good? Seems like a low cost way to make ppl think better and it self corrected quickly. as far as I can tell no one was hurt. No one falsely blamed etc. am I missing smthn besides ominous foreshadowing?
Eliezer Yudkowsky: This particular event is probably better to have happened than not happen. A world of having to make your own judgment calls on whether anything is real, seems potentially quite bad for people over the age of 70 or under the IQ of 90 if not 160.
Michael Vassar: That’s the world we have always been in. In so far as this causes us to be on the same page about that it should be beneficial, but people don’t seem to be thinking for themselves, just giving up.
This particular event was close to ideal. Clear warning shot, clear lessons to be learned, no one gets hurt other than financially, the financial damage should be limited to those attempting to trade on the false news and doing it badly. They are very much the ‘equity capital’ of such situations, whose job it is to take losses first, and who are compensated accordingly.
Having to make your own calls on what is real is a matter of degree, and a matter of degree of difficulty. Everyone needs to be able to employ shortcuts and heuristics when processing information, and find ways to do the processing within their cognitive ability and time budget.
I do not think it is obvious or overdetermined that the new world will be harder to navigate than the old one. We lose some heuristics and shortcuts, we gain new ones. I do think the odds favor things getting trickier for a while.
We also have this from Insider Paper: China scammer uses AI to pose as man’s friend, steal millions ($600k in USD). Scam involved a full voice plus video fake to request a large business transfer, the first such loss I’ve seen reported for this kind of size. He got ~81% of it back so far by notifying the bank quickly and efforts are ongoing.
is definitely on the harder end of the spectrum as far as AI policy issues go.
Lots of collective action problems + tradeoffs.
It's also among the more underestimated issues--it's *starting* to get semi mainstream but the full severity + linkages to other issues (how do we solve the other stuff if no one knows what's going on + democracy is breaking) + lack of silver bullets are not widely appreciated.
Among other collective action issues:
- aligning on standards on these things across AI providers, social media platforms, artistic/productivity applications, etc.
- implementing them when users don’t like them or doing so disproportionately affects a subset
- social norms re: a stance of default distrust of content
- ie “demand” for the standard
Among other tradeoffs:
- mitigating misuse vs enabling positive use cases
- regulating to prevent defection by providers vs. free speech
- trying hard on standards vs. avoiding a false sense of security
I worry whenever people at places like OpenAI describe such issues as on the harder end. These are serious issues we need to tackle well, while also seeming to me to be clearly on the easy end when it comes to such matters. As in, I can see paths to good solutions, there are no impossible problems in our way only difficult ones, and we don’t need to ‘get it right on the first try’ the way we do alignment, if we flail around for a bit it (almost certainly) won’t kill us.
The core problem is, how do we verify what is real and what is fake, once our traditional identifiers of realness, such as one’s voice or soon a realistic-looking photo or then video, stop working, as they can be easily faked? And the cost of generating and sending false info of all kinds drops to near zero? How do I know that you are you, and you know that I am me?
Right now, the hacks that are being used are wildly inept and basic. They work anyway, exactly because the good versions don’t exist and so no one suspects anything. We’ve had a lot of techniques that worked at first, then once people became aware, they stopped working. Defense usually wins.
I see a wide variety of technologies already available, where you can establish that something comes from a given source.
I choose what sources to trust to what extent, including how much I trust their judgment on other sources, and to what extent I can trust them to verify that things are genuine and come from the place they appear to come from.
In a voice or text discussion, it seems not so difficult to verify that someone is who they claim to be. It’s trivial if you have an existing system for doing so, like a key phrase you change up. Even if you don’t have anything prepared in advance, it still seems easy even against substantially better AI systems, via the ‘ask them something other people wouldn’t know’ principle. We see this in media all the time and it’s not going to stop working.
Legal and regulatory requirements are definitely coming, and are definitely addressing exactly these concerns in ways that seem like they should work.
All the incentives look like they will point towards all major platforms and systems converging on something reasonable. Any platform that doesn’t use such defenses will be niche and for advanced users, at best.
The productivity gains from AI should give us plenty of slack to introduce some extra friction into our systems when necessary.
I do see problems growing for those unusually unable to handle such problems, especially the elderly, where automated defenses and some very basic heuristics will have to do a lot of work. I still am waiting to see in the wild attack vectors that the basic homework wouldn’t stop - if you follow basic principle of never giving out money, passwords or other vulnerable information via insecure channels, what now?
OPINION: "We could create an artificial intelligence based on Feinstein, call it DiFi AI, and make sure California is always represented in the Senate," writes @joemmathews
We’ve actually had this technology for a while. Its old name is ‘A rock with the words ‘vote Democratic party line’ on it.
They Took Our Jobs
Bryan Caplan is asked in a podcast (about 3:30 here) whether he thinks AI will take 90% of all jobs within 20 years, and he says he’d be surprised if it took 9%. It does not seem he has updated sufficiently from his losing bet on AI passing his exams. Sure, you might say there will be many replacement jobs waiting in the wings, and I do indeed think this, but he’s explicitly not predicting this, and also, 9%? In 20 years? What? Because of previous tech adaptation lags that were longer? I am so confused.
GPT doesn't seem intelligent because it models language well, it is intelligent because it's starting to model the reality behind the words. ChatGPT is, in many ways, the average human running on auto-pilot. In other words, the average human most of the time... Except that "average" here is more literal, as in the mean over many, and as with faces, that sort of average tends toward beauty because it has high signal to noise. Which means ChatGPT is, in many ways, better than the average (as in typical) human running on auto-pilot. (But yes, still on auto-pilot... for now.)
…
The human brain is, in my studied opinion, a "generative AI".
…
On the technical side, I think something more like RNNs will eventually replace transformers. Owing to its internal state being bottlenecked through what can be inferred from past percepts alone, GPT is a "word thinker" in the extreme, and talking to it not-coincidentally reminds me of talking to word-thinking humans (e.g. Sam Harris, but there are many). Word thinking is brittle, and leads to over-confidence in very wrong conclusions: words distill away details which makes for tidy reasoning that's only as accurate as the omitted details are irrelevant. (They all too often aren't.) Future models will comprise a hierarchy of abstract state that transitions laterally over time, with direct percepts (of multiple modalities--language, vision, kinesthetic) being optional to the process (necessary for training, but not the only link from one moment to the next). The internal model of reality needs to be free of the limitations of the perceptual realm.
…
But as Robert Sapolsky says of the Baboons in the Serengeti (where life is ideal for them): Able to meet their needs with a mere three hours a day of effort, they are left with nine hours free a day to be unspeakably horrible to each other. When it comes down to it, humans are just baboons with ChatGPT.
In short, the only thing AI needs to provide to destroy the world is food and shelter. Whatever good intentions are behind ChatGPT's Marxist tendencies, a road to hell they will pave.
But that's the optimistic scenario.
…
Personally I don't think AI alignment is a hard problem. I think making a truly-benevolent AI who won't do anything rash is well within our abilities. The much harder problem is keeping humans from making a truly-malevolent AI--entirely on purpose--because that's just as easy, and humans are apt to do that sort of thing for a variety of reasons.
But even in the best scenario, what does a future for humans look like if they can no longer constructively compete for status? Because that's what humans do (at their best) and if you think they'll be happy to be free of that game, you read too much. (And bear in mind, there is no job in the Star Trek universe that a technologically comparable AI can't do better. It's a universal flaw in almost all science fiction that suitably advanced AI is either omitted entirely, or mysteriously limited to just a few roles, because an honest inclusion of AI pretty much borks every plotline of interest to humans. Nostalgia for the days before AI may become the main movie genera in the future...)
I don't have any guesses yet. But I think we'll start getting clues soon. In the medium term future, I foresee a lot of make-work to keep humans employed and in charge, like Oregon's gas pumpers. And entrenched monopolies like the AMA aren't going to go away without a long and protracted fight. (They'll especially hate that MDs are obsolete long before RNs, and they'll do everything they can to delay that--at your expense, both monetarily and medically. GPT already outperforms doctors at being doctors, which isn't as great as it sounds. Take GPT back in time, and it would be "better" at prescribing blood-letting. Don't get me wrong--AI has the potential to completely revolutionize medicine. But then, so does basic data analysis, objectively applied, which is why nobody's allowed to do that. Intelligence is not the bottleneck in medicine--bad incentives are. And unfortunately those incentives are already influencing AIs, and not just in medicine.)
Anyway, imo the race is on: the white hats vs the black hats, battle bots. Don't blink.
Conrad Barski: My key strategy is to think of LLMs as having a limited "depth" they can think at they can spend that depth either puzzling out your prompt or solving your problem your job is to hand them a prompt on a silver platter, so that they use all the depth to solve your problem.
Eliezer Yudkowsky: I do wonder if "prompt engineering" might help a few people to learn better teaching and explanation. When a child fails to understand what's written in a textbook, you can blame the child. When an AI fails to understand you, you have to actually rewrite the prompt.
I expect both the practical experience of doing prompt engineering for AIs, and the conceptualization of prompt engineering as a thing, will help a lot with prompt engineering for humans, an underappreciated skill that requires learning, experimentation and adaptation. The right prompt can make all the difference.
From Chain to Tree of Thought
Chain of Thought, meet Tree of Thought. Use full branching and decomposition of multi-step explorations and evaluations to choose between paths for better performance.
Some of their results were impressive, including dramatic gains in the ‘Game of 24’ where you have four integers and the basic arithmetic operations and need to make the answer 24.
Here’s the abstract. The claim is that letting an LLM experience a virtual world allows it to build a world model, greatly enhancing its effectiveness.
While large language models (LMs) have shown remarkable capabilities across numerous tasks, they often struggle with simple reasoning and planning in physical environments, such as understanding object permanence or planning household activities. The limitation arises from the fact that LMs are trained only on written text and miss essential embodied knowledge and skills. In this paper, we propose a new paradigm of enhancing LMs by finetuning them with world models, to gain diverse embodied knowledge while retaining their general language capabilities.
Our approach deploys an embodied agent in a world model, particularly a simulator of the physical world (VirtualHome), and acquires a diverse set of embodied experiences through both goal-oriented planning and random exploration. These experiences are then used to finetune LMs to teach diverse abilities of reasoning and acting in the physical world, e.g., planning and completing goals, object permanence and tracking, etc.
Moreover, it is desirable to preserve the generality of LMs during finetuning, which facilitates generalizing the embodied knowledge across tasks rather than being tied to specific simulations. We thus further introduce the classical elastic weight consolidation (EWC) for selective weight updates, combined with low-rank adapters (LoRA) for training efficiency.
Extensive experiments show our approach substantially improves base LMs on 18 downstream tasks by 64.28% on average. In particular, the small LMs (1.3B and 6B) enhanced by our approach match or even outperform much larger LMs (e.g., ChatGPT). Code available at https://github.com/szxiangjn/world-model-for-language-model.
If the paper is taken at face value, this is potentially a dramatic improvement in model effectiveness at a wide variety of tasks, a major algorithmic improvement. It makes sense that something like this could be a big deal. A note of caution is that I am not seeing others react as if this were a big deal, or weigh in on the question yet.
Introducing
Perplexity AI Copilot. It’s a crafted use of GPT-4, including follow-up questions that can be complete with check boxes, as a search companion. Rowan Cheung offers some examples of things you can do with it, one of which is ‘write your AI newsletter.’ Which is a funny example to give if your main product is an AI newsletter - either the AI can write it for you or it can’t. Note that Perplexity was already one of the few services that crosses my ‘worth using a non-zero portion of the time’ threshold.
Lovo.ai is latest AI voice source one could try out, 1000+ voices available.
Increasingly when I see lists of the week’s top new AI applications, it is the same ones over and over again under a different name. Help you write, help you name things, help you automate simple processes, generate audio, new slight tweaks on search or information aggregation, search your personal information, give me access to your data and I’ll use it as context.
That’s not to say that these aren’t useful things, or that I wouldn’t want to know what the best (safe) versions of these apps was at any time. It is to say that it’s hard to get excited unless one has the time to investigate which ones are actually good, which I do not have at this time.
In Other AI News
Anthropic raises $450 million in Series C funding, led by Spark Capital, with participation including Salesforce, Google, Zoom Ventures, Sound Ventures and others. I’m curious why it wasn’t larger.
Anthropic (on Twitter): The funding will support our efforts to continue building AI products that people can rely on, and generate new research about the opportunities and risks of AI.
That does not sound like an alignment-first company. Their official announcement version is a bit better?
Our CEO, Dario Amodei, says, “We are thrilled that these leading investors and technology companies are supporting Anthropic’s mission: AI research and products that put safety at the frontier. The systems we are building are being designed to provide reliable AI services that can positively impact businesses and consumers now and in the future.”
Supreme court rules, very correctly and without dissent, that ordinary algorithmic actions like recommendations and monetization do not make Google or Twitter liable for terrorist activity any more than hosting their phone or email service would, and that this does not quire section 230.
Vlad: I like how this puts things into perspective.
- Bing is still a tiny speck in the universe and has less traffic than ChatGPT
- Both of them added together are same as Yandex
- Google towering above everything
Don't think I'd prefer running any of those over Kagi though. ❤️
Even with a billion users, the future remains so much more unevenly distributed. I think of myself as not taking proper advantage of AI for mundane utility, yet my blue bar here isn’t towering over the black and green.
Estebban Constante: GPT-4 turned its "deception mode" without being asked to 👀
How? Kevin provided him with personality traits. Then asked it to reflect on its emotional responses to incoming messages and craft a strategy. GPT then found out it had to be deceptive to accomplish this 🤯
The central concept is pretty basic, give it a personality and at every step have it go through some reflection like so:
A bull case for Amazon advertising, and its plans for LLM integration, including for Alexa. When people say things like ‘Amazon will reimagine search in the 2030s’ I wonder what the person expects the 2030s to be like, such that the prediction is meaningful. The lack of concern here about Amazon being behind in the core tech seems odd, and one must note that Alexa is painfully bad in completely unnecessary ways and has been for some time, in ways I’ve noted, and which don’t bode well for future LLM-based versions as they reflect an obsession with steering people to buy things. In general, would you trust the Amazon LLM?
Washington Post article looks into the sources of LLM training data. There are some good stats, mostly they use it to go on a fishing expedition to point out that the internet contains sources that say things we don’t like, or that contain information people put in public but would rather others not use, or that certain things were more prominently used than certain other things that one might claim ‘should’ be on more equal footing, and that’s all terrible, I guess.
Here are the top websites, note the dominance of #1 and #2 although it’s still only 0.65% of all data.
When thinking about existential risks from AGI, a common default assumption is that at the first sign of something being amiss, all of humanity would figure out it was under existential threat, unite behind Team Humanity and seek to shut down the threat at any cost.
Whereas our practical experiences tell us that this is very much not the case. Quite a few people, including Google founder Larry Page, have been quoted makin it clear they would side with the AGI, or at best be neutral. Some will do it because they are pro-AI, some will do it to be anti-human, some will do it for various other reasons. Many others will simply take a Don’t Look Up attitude, and refuse to acknowledge or care about the threat when there are social media feuds and cat videos available.
This will happen even if the AGIs engage in no persuasion or propaganda whatsoever on such fronts. The faction is created before the AGIs it wants to back exist or are available to talk. Many science fiction works, including the one I am currently experiencing, get this right.
In real life, if such a scenario arises, there will be an opponent actively working to create such a faction in the most strategically valuable ways, and that opponent will be highly resourceful and effective at persuasion. Any reasonable model includes a substantial number of potential fifth columnists.
On the Web, one can find many fan-composed songs for Three Body, and readers yearning for a movie adaptation—some have even gone to the trouble of creating fake trailers out of clips from other movies. Sina Weibo—a Chinese microblogging service analogous to Twitter—has numerous user accounts based on characters in Three Body, and these users stay in character and comment on current events, expanding the story told in the novel. Based on these virtual identities, some have speculated that the ETO, the fictional organization of human defectors who form a fifth column for the alien invaders, is already in place. When CCTV, China’s largest state television broadcaster, tried to hold an interview series on the topic of science fiction, a hundred plus studio audience members erupted into chants of “Eliminate human tyranny! The world belongs to Trisolaris!”—a quote from the novel. The two TV hosts were utterly flummoxed and didn’t know what to do.
Obviously this could be said to all be in good fun. And yet. Keep it in mind.
Eliezer Yudkowsky: I think there may be a usefully deep analogy between GPT4 and a 5-year-old who reads 10,000 words per second. In particular, this is what happens if you give that 5-year-old access to your email.
Johann Rehberger: 👉 Let ChatGPT visit a website and have your email stolen.
Plugins, Prompt Injection and Cross Plug-in Request Forgery. Not sharing “shell code” but… 🤯 Why no human in the loop? @openai Would mitigate the CPRF at least.
Chris Rohlf: A majority of prompt injection defenses are patching the exploit. They ignore context windows & how different code & NL is. But the majority of prompt injection risk is where APIs are chained together via LLM. Mitigating these likely closer to boring auth/authz problems than ML.
Rich Harang: This. Your LLM should only ever call APIs *in the context of the person using the LLM.* Get authz handling right and suddenly you won't care about prompt injection. Most implementations call APIs *in the context of the LLM process* which is where it all goes horribly wrong.
My understanding is that Harang is correct about the goal here, yet hopelessly optimistic about prospects for making the problem go away.
Eliezer Yudkowsky: Is it just my imagination, or have there been no major AI breakthroughs over the last two weeks?
Davidad: I predict that the current AI winter will end in June.
Every day you can count on certain people to say ‘massive day in AI releases’ yet this pattern does seem right. There are incremental things that happen, progress hasn’t stopped entirely or anything like that, yet things do seem slow.
Nathan Lambert says ‘Unfortunately, OpenAI and Google have moats.’ Much here is common sense, big companies are ahead, they have integrations, you have to be ten times better to beat them, the core offerings are free already, super powerful secret sauce is rare. I do agree with his notes that LoRA seems super powerful, which I can verify for image models, and that data quality will be increasingly important. I’d also strongly agree that I expect the closed source data sources to be much higher quality than the open source data sources.
Nabeel S. Qureshi: An interesting thing about the AI debate is that both optimists and doomers seem to think they are losing
Joe Zimmerman: Unironically, they might actually both *be* losing. We might get the worst of both worlds: SotA models strangled by censorship, but progress towards ASI continues unabated.
Certainly this is a plausible outcome, given governments are highly concerned about near term concerns without much grasping the existential threat. We see great willingness to cripple mundane utility without restraining capability development in a sustainable way.
Elon Musk asks, “how do we find meaning in life if the AI can do your job better than you can?” Cate Hall says this is ‘not the most relatable statement.’ I disagree, I find this hugely relatable, we all need something where we provide value. If the objection is ‘you are not your job any more than you are your f***ing khakis’ then yes, sure, but that’s because you are good at something else. It may be coming for that, too.
ChatGPT as Marketing Triumph, despite its pedestrian name, no advertising, no attempts to market of any kind really, just the bare bones actual product. Tyler Cowen asks in Bloomberg, will it change marketing? I think essentially no. It succeeded because it was so good it did not need marketing. Which is great, but that doesn’t mean that it would have failed with more traditional marketing, or done less well. We have the habit of saying that any part of anything successful must have done something right, and there are correlational reasons this is far more true than one would naively expect, yet this doesn’t seem like one of those times.
Eliezer Yudkowsky: Now imagine this, but it's a phenomenon that occurs in a deeper and more semantic layer of the brain than the visual cortex, one we could no more unravel today than this optical illusion could have been comprehended and built in 1023 CE; and an ASI triggers it by talking to you.
SoTechBro (who shared the GIF):
1. If your eyes follow the movement of the rotating pink dot, you will only see one color, pink.
2. Green Catastrophe: If you stare at the black + in the center, the moving dot turns to green.
3. Reality Shatter: Now, concentrate on the black + in the center of the picture. After a short period of time, many if not all of the pink dots will slowly disappear, and you may only see a green dot rotating.
Ethmag.eth: 4. bring your screen close to your eyes while looking at +. When pink dots disappear, move it backwards. enjoy animated green dots show. thank me later.
The point here is that our brains have bugs in the way they process information. For now, those bugs are cool and don’t pose a problem, which is why they didn’t get fixed by evolution, they weren’t worth fixing.
However, if we go out of distribution, and allow a superintelligent agent to search the space for new bugs, it seems rather likely that it will be able to uncover hacks to our system in various ways, for which we will have no defense.
Kevin Fisher: The reason we dogmatically think engagement is bad is because our devices respond to relatively uni-dimensionally towards engagement.
Here’s the problem: Imagine scrolling on Twitter, liking a bunch of political stuff, then realizing all you see is Biden or Trump all day.
That was great, but now you’re done.
Important note: We can all agree it wasn’t great. Including you, at the time.
Kevin Fisher: However it will take the algorithm a long time to change, and wise you might still hit like on the tweets even if you don’t to see them. But if someone ASKED you, you would say you don’t want to see any more political stuff - but that sort of dramatic shift is not captured by recommendation algorithms.
Yes, you’d say ‘no more politics please’ long before you actually stop rewarding the political content.
But this type of dramatic shift IS captured in real relationships! You can explain to a person “yeah that was fun chatting about politics but let’s take a break and focus on X”
People exchange much higher dimensional reward signals than a single like- our relationships with AI entities will be like that. So, we don’t need to be so reflexively allergic to engaging AI entities.
So the model here is that you’ll tell Samantha the AI ‘no more politics, please’ and Samantha will be designed for maximizing engagement, but she’ll honor your request because you know thyself? No, you don’t, Samantha can figure out full well that isn’t true. How many friends or relatives or coworkers do you have, where both of you loathe talking politics (or anything else) and yet you can’t seem to avoid it? And that’s when no one involved is maximizing engagement.
Similarly, it is very easy for existing systems to offer multi-dimensional feedback. Instead, the trend has been against that, to reduce the amount of feedback you can offer, despite the obvious reasons one might want to inform the algorithm of your preferences. This is largely because most people have no interest in providing such feedback. TikTok got so effective, as I understand it, in large part because they completely ignore all of your intentional feedback, don’t give you essentially any choices beyond whether to watch or not watch the next thing, and only watch for what you choose to watch or not watch when given the choice. Netflix had a rich, accurate prediction model, and rather than enhance it with more info, they threw it out the window entirely. And so on.
Do I have hope for a day when I can type into a YouTube search a generative-AI style request? When I can provide detailed feedback that it will track for the long term, to offer me better things? Sure, that all sounds great, but I still expect the algorithm to know when to think I am a lying liar, in terms of what I’d actually engage with. Same with the chat bots, especially across people. They’ll learn what generally engages, and they’ll often watch for the unintentional indications of interest more than the explicit intentional ones.
an AGI is like a ball point pen except its in the hands of john wick (-> superhuman capabilities) and you just killed his dog (-> are made of atoms it can use for something else)
Eliezer Yudkowsky: People be like "we don't know how to build an artificial superintelligence" and I can only assume they haven't studied modern deep learning at all. Nobody has the tiniest idea how to build a GPT-4, either; some bigco just stirred a heap of linear algebra until GPT-4 popped out.
Spirit of Negation: We know some things, but not all. We know how to make GPT in the same way cave men knew to make fire. Understanding of causality without deep understanding of mechanism.
Eliezer: "Understanding causality without mechanism" is a good phrase, I may steal it at some point.
In our regular lives, this covers a huge percentage of what is around us. I have a great causal understanding of most things I interact with regularly. My degree of mechanistic understanding varies greatly. There are so many basic things I don’t know, because I am counting on someone else to know them. In AI, the difference is that no one else knows how many of those mechanisms work either.
8. Superintelligence can hack software supervisors
9. Humans cannot be first-class parties to a superintelligence value handshake
10. Humanlike minds/goals are not necessarily safe
11. Someone else will deploy unsafe superintelligence first (possibly by stealing it from you)
12. Unsafe superintelligence in a box might figure out what’s going on and find a way to exfiltrate itself by steganography and spearphishing.
13. We are ethically obligated to propose pivotal processes that are as close as possible to fair Pareto improvements for all citizens, both by their own lights and from a depersonalized well-being perspective. (Eliezer may disagree with this one)
(This came after some commonly expressed frustration about the number of disjoint problems, there are some interesting other discussions higher in the thread.)
That’s a reasonably good list of 12 things. I don’t think #13 belongs on the list, even if one agrees with its premise. I certainly don’t agree with #13 in a maximalist sense. Mostly in a sensible version it reduces to ‘we should do something that is good for existing people to the extent we can’ and I don’t disagree with that but I don’t think of such questions as that central to what we should care about.
List of problems to solve in order to solve AGI alignment, in non technical terms:
1) Human values are hard to describe and write down and many small imprecisions in the way we characterize them might have catastrophic consequences if a powerful agent (e.g. an AGI) tries very hard to achieve those values. A bit like small failures in a law are heavily exploited by big corporations, leading to highly undesirable consequences.
2) Without specific countermeasures, AIs beyond a certain level of capabilities will refuse to be modified or shut down.
3) To make sure that the first aligned AGIs are not outcompeted by unaligned AGIs a few months later, the first aligned AGIs will have to take some actions (here called "pivotal processes") that require dangerous capabilities to be executed well.
4) By default, the goals that an AI will learn during its training won't generalize in a way that satisfies humans once this AI is exposed (in the real world) to situations it has never seen during its training.
5) Most large-scale objectives can be better achieved if an AI acquires resources (political power, money, intelligence, influence over individuals etc.). By default, as AIs become more capable, they will reach a point where they will be able to successfully execute strategies that de facto overpower humanity. Avoiding that they do that despite it a) being optimal for their own goals & b) having the ability to do so will require efforts.
6) The plans (e.g. pivotal processes) that allow the world to reach a point of stability (i.e. the chances that humanity goes extinct rebecomes extremely low) will probably be incomprehensible to humans.
7) Superintelligence can fool human supervisors.
8) Superintelligence can hack (i.e. mislead, break or manipulate) the other AIs that humans have put in place to supervise the superintelligence.
9) (I'm not literate enough to interpret the scriptures here)
10) It might be contingent that humans don't cause destruction around them. It might be feasible to build minds with human capabilities that would do so.
11) Avoiding human extinction will require a certain velocity in execution OR a global governance regime which prevents any race between different actors building their own AGIs. Otherwise, unsafe actors always pose the risk to deploy unsafe superintelligence first (possibly by stealing it from safe actors).
12) Even if contained with very advanced measures, a superintelligent mind might be able to communicate with the external world in ways that are not understandable to humans (i.e. steganography) and advanced manipulative techniques.
13) There is a moral obligation to do a pivotal process (i.e. an action which prevents any rogue actor from building a misaligned AGI) which is as close as possible from good & fair for everyone. Examples of such processes could be: - Enforce a perfect monitoring of high-end compute in a way which prevents people from building unaligned AGI. - Make huge amounts of money and buy all the competitors that are less safety conscious to prevent them from building an unaligned AGI.
To take a first non-technical shot at #9: Superintelligent computer programs are code, so they can see each others’ code and provably modify their own code, in order to reliably coordinate actions and agree on a joint prioritization of values and division of resources. Humans can’t do this, risking us being left out.
Could we get this down below 12? It feels like we can, as several of these feel like special cases of ‘a smarter and more capable than you AI system will be able to do things you don’t expect in ways you can’t anticipate’ (e.g. #7, #8 and #12). And (#2, #4, #5 and #10) also feel like a cluster. #9 feels like it is pointing at a more broad category of problem (something like ‘a world containing many AGIs has no natural place or use for or ability to coordinate with humans), I do think that category is distinct. So my guess is you can get down to at most 10, likely something around 8. It’s not clear unifying them in that way makes them more useful though. Perhaps you want a two-level system.
Something like a high level of maybe these five?
We don’t know how to determine what an AGI’s goals or values would be.
We don’t know what goals or values would result in good outcomes if given to an AGI, and once chosen we won’t know how to change them.
Things that are smarter than you will outsmart you in ways you don’t anticipate, and the world they create won’t have a meaningful or productive place for us.
Coordination is hard, competition and competitive pressures are ever-present.
Getting out of the danger zone requires capabilities from the danger zone.
Or, we must worry about:
Determining AGI values and goals at all. (#2)
Picking wise AGI values and goals to determine. (#1, #4, #5, #10, #13)
Avoiding being outsmarted and being partners with smarter things. (#7, #8, #9, #12)
Coordinating in face of competitive pressures. (#11)
Needing dangerous capabilities to guard against dangerous capabilities. (#3, #6)
I put everything in exactly one category, but it’s worth noting that several of them could go into two or more. The first category suggests the original list is missing (#14: We don’t know how to specify the values or goals of an AI system at all), and #11 also feels like it’s not covering the full space it is for.
Paul Graham: Few things are harder to predict than the ways in which someone much smarter than you might outsmart you. That's the reason I worry about AI. Not just the problem itself, but the meta-problem that the ways the problem might play out are inherently hard to predict.
This was clarified for me by this metaphor of Eliezer Yudkowsky's:
Eliezer Yudkowsky: Ten-year-old about to play chess for the first time, skeptical that he'll lose to Magnus Carlsen: "Can you explain how he'll defeat me, when we've both got the same pieces, and I move first? Will he use some trick for getting all his pawns to the back row to become Queens?"
Andrew Rettek: It's not the point better, but I've had this conversation with 5 year olds a lot.
Eliezer Yudkowsky Wishes He Was Only Worried AI Might Kill Us
Eliezer Yudkowsky: From an email I recently wrote, possibly of general interest: > From my perspective, we are trying to evaluate a picture of convergent ruin rather than any pictures of contingent ruin. That is, I'm relatively less interested in contingent-doom scenarios like "What if superintelligence is easily alignable, but Greenpeace is first to obtain superintelligence and they align It entirely to protect Earth's environment and then the SI wipes out humanity to do that?" because this is not a case for almost-all paths leading to ruin. I worry that contingent scenarios like "Age of Ultron" can fascinate humans (particularly contingent scenarios where some Other Monkey Faction Gets AGI First oh noes), and derail all possibility of a discussion about whether, in fact, the superintelligence kills everyone regardless of who 'gets' It first.
> Similarly, if somebody is considering only the contingent-early-ruin scenario of "a prototype of a somewhat advanced AGI starts to consider how to wipe out humanity, and nobody spots any signs of that thought", that contingency can mask a convergent-ruin continuation of "even if they spot the early signs, everyone is still in an arms-race scenario, so they optimize away the visible signs of doom and keep going into ruin".
> So I think the key question is "Why would or wouldn't humanity be convergently doomed?" rather than "How might humanity be contingently doomed?" Convergent doom isn't the same as inevitable doom, but ought to be the sort of doom that defeats easy solution / historically characteristic levels of competence for Earth / the sort of efforts we've seen already.
> A doom that can only be averted by an effective multinational coalition shutting down all AI runs larger than GPT-4 for 6 years, to make time for a crash project on human intelligence augmentation that has to complete within 6 years, may not be an inevitable doom; but it was probably a pretty convergent doom if that was your best path for stopping it.
> Conversely, "What if all the AI companies and venture capitalists just decide together to not pursue the rewards of AI models stronger than GPT-4, and high-impact journals and conferences stop accepting papers about it" is a sufficiently unlikely contingency that dooms avertable in that way may still be said to be convergent. It seems reasonably convergent that, if there isn't a drastic effective global shutdown enforced by state-level actors that will enforce that treaty even on non-signatory states, somebody tries.
I am torn on the core rhetorical question of how to treat contingent ruin scenarios. If we are so lucky as to get to a world where ruin is contingent in the sense used above, that’s great, yet it is worth noticing the obstacles remaining in the path to victory. Should we ignore those in order to avoid the distractions, which can easily actively backfire (and has backfired already) in huge ways if you’re worried about the wrong monkey getting it first?
One issue is that there is overlap here. If we didn’t have to worry about contingent ruin, it would be much easier to deal with the problems of convergent ruin.
Nassim Nicholas Taleb: An expert is someone who knows exactly what not to be wrong about.
[Later]: A lot of people are misunderstanding my point about ChatGPT and #AI in general. I am not saying it is useless. All I am saying is that it is no replacement & threat to *real* experts.
What Taleb describes here, that current AI is definitely missing, is important to being an expert. Every field in which one can be an expert carries fat tail risk… to your job and reputation. An expert knows, as Taleb puts it, exactly what not to be wrong about, to avoid this happening. Via negativa, indeed.
The distinction is that for some experts, this is due to a real tail risk consequence, where the bridge will fall down. For others, there is only tail risk to you, the expert. In which case, the expertise we select for is political, is expert at appearances.
ChatGPT is in some contexts rather good at knowing not to say the wrong thing, if it’s been trained not to do that. You could fine tune a system to never be wrong about a given particular thing the same way, if you wanted to pay the price. So in that sense, we don’t have much to worry about today, but that won’t last long as we enter the fine tuning era of specialized models over the course of 2023, the same way humans are (almost always) only experts in this sense when they fine tune and are specialized.
The other trick AI has is that if the negativa is over reputation or reaction, then the AI might give people a chance to ignore it, which can be actively helpful - the same way a self-driving car needs to be vastly more reliable than a1 human driver, in other contexts the AI can be vastly less reliable than a human would be, and be forgiven for that. That does mean a human needs to double check, but that need not require an expert, and often will require dramatically less time.
Perhaps we will soon learn which experts were which type. Some should worry.
NEW: NYC public schools are dropping their ban on ChatGPT Will encourage educators & students to "learn about and explore this game-changing technology". This is absolutely the right move. We need to prepare our young people for the new world that's coming.
It is short enough that I’m going to go ahead and quote the whole thing to save everyone a click. It is a broad reiteration of what Altman said in his congressional testimony. An IAEA-like entity will likely be necessary, there need to be controls on development of new frontier models, sufficiently behind-SOTA work can be open sourced and otherwise free to have fun.
Given the picture as we see it now, it’s conceivable that within the next ten years, AI systems will exceed expert skill level in most domains, and carry out as much productive activity as one of today’s largest corporations.
In terms of both potential upsides and downsides, superintelligence will be more powerful than other technologies humanity has had to contend with in the past. We can have a dramatically more prosperous future; but we have to manage risk to get there. Given the possibility of existential risk, we can’t just be reactive. Nuclear energy is a commonly used historical example of a technology with this property; synthetic biology is another example.
We must mitigate the risks of today’s AI technology too, but superintelligence will require special treatment and coordination.
A starting point
There are many ideas that matter for us to have a good chance at successfully navigating this development; here we lay out our initial thinking on three of them.
First, we need some degree of coordination among the leading development efforts to ensure that the development of superintelligence occurs in a manner that allows us to both maintain safety and help smooth integration of these systems with society. There are many ways this could be implemented; major governments around the world could set up a project that many current efforts become part of, or we could collectively agree (with the backing power of a new organization like the one suggested below) that the rate of growth in AI capability at the frontier is limited to a certain rate per year.
And of course, individual companies should be held to an extremely high standard of acting responsibly.
Second, we are likely to eventually need something like an IAEA for superintelligence efforts; any effort above a certain capability (or resources like compute) threshold will need to be subject to an international authority that can inspect systems, require audits, test for compliance with safety standards, place restrictions on degrees of deployment and levels of security, etc. Tracking compute and energy usage could go a long way, and give us some hope this idea could actually be implementable. As a first step, companies could voluntarily agree to begin implementing elements of what such an agency might one day require, and as a second, individual countries could implement it. It would be important that such an agency focus on reducing existential risk and not issues that should be left to individual countries, such as defining what an AI should be allowed to say.
Third, we need the technical capability to make a superintelligence safe. This is an open research question that we and others are putting a lot of effort into.
What’s not in scope
We think it’s important to allow companies and open-source projects to develop models below a significant capability threshold, without the kind of regulation we describe here (including burdensome mechanisms like licenses or audits).
Today’s systems will create tremendous value in the world and, while they do have risks, the level of those risks feel commensurate with other Internet technologies and society’s likely approaches seem appropriate.
By contrast, the systems we are concerned about will have power beyond any technology yet created, and we should be careful not to water down the focus on them by applying similar standards to technology far below this bar.
Public input and potential
But the governance of the most powerful systems, as well as decisions regarding their deployment, must have strong public oversight. We believe people around the world should democratically decide on the bounds and defaults for AI systems. We don't yet know how to design such a mechanism, but we plan to experiment with its development. We continue to think that, within these wide bounds, individual users should have a lot of control over how the AI they use behaves.
Given the risks and difficulties, it’s worth considering why we are building this technology at all.
At OpenAI, we have two fundamental reasons. First, we believe it’s going to lead to a much better world than what we can imagine today (we are already seeing early examples of this in areas like education, creative work, and personal productivity). The world faces a lot of problems that we will need much more help to solve; this technology can improve our societies, and the creative ability of everyone to use these new tools is certain to astonish us. The economic growth and increase in quality of life will be astonishing.
Second, we believe it would be unintuitively risky and difficult to stop the creation of superintelligence. Because the upsides are so tremendous, the cost to build it decreases each year, the number of actors building it is rapidly increasing, and it’s inherently part of the technological path we are on, stopping it would require something like a global surveillance regime, and even that isn’t guaranteed to work. So we have to get it right.
Yes, why would you want to build a superintelligence at all if it is so risky: “Given the risks and difficulties, it’s worth considering why we are building this technology at all.” The response being (1) it has upside and (2) we can’t stop it anyway.
Ignoring that (2) is, to the extent it is true, largely OpenAI’s direct fault, shouldn’t there also be a (3) we believe that we will be able to navigate the risks safely, because [reasons]?
Joe Zimmerman: What if ASI alignment simply isn't tractable by present-day humans? We need a better plan than "try to solve it anyway."
Connor Leahy: "It really is so impossible to stop this thing! It's a totally external force we can't do anything to stop!", says the guy currently building the thing right in front of you with his own hands.
I would say better plan than only trying to solve it anyway.
No, the other path isn’t guaranteed to work, but if the default path is probably or almost certainly going to get everyone killed, then perhaps ‘guaranteed to work’ is not the appropriate bar for the alternative, and we should be prepared to consider that, even if the costs are high?
Instead, I don’t see acknowledgment of the difficulty of the underlying technical problems, or the need to evaluate that difficulty level when deciding what to do or not do, and ‘risky’ rather understates the downsides. No, we don’t know how to design the Democratic control mechanism, but perhaps it’s more important to notice we don’t know how to design any control mechanism at all, of any kind?
Other than that, and the lack of additional concrete detail in the proposals, this seems about as good as such a document could reasonably be expected to be.
Here's the thing the OpenAI policy team needs to understand: you need to be extremely specific if you want to actually regulate development, USG reads "any application" as development and wants to crack down on distribution anyway. The default ideology in these cases is to subsidize development while restricting access for ordinary people (see NSF+FDA), which is the exact intersection of policy which destroys the economic benefits while doing nothing to stop AGI.
It seems odd to say that the FDA doesn’t hurt development, even if it hurts deployment modestly more. I do agree that details matter, but Altman has actually been rather clear on this particular detail - restrict training of large new models, allow new uses for small models.
The Quest for Sane Regulation Otherwise
From what I can tell, the OpenAI regulatory framework suggested above is an excellent place to begin, and no one is currently hard at work drafting concrete legislative or regulatory language. This is dropping the ball on a massive scale. While I haven’t talked about it in a while, Balsa Policy Institute does exist, it does have a single employee about to start soon, and I tentatively intend the first concrete mission to be to investigate drafting such language. I will say more at another time.
In the meantime, how is this possibly MY job, people are crazy the world is mad, someone has to and no one else will, just do it, step up your game you fool of a took.
Most promising? This wasn’t a large pro forma meeting:
That’s what you want it to look like.
Quartsz says ‘OpenAI’s Sam Altman threatened leave the EU if he doesn’t like their ChatGPT regulation.’ A better headline would have been ‘OpenAI’s Sam Altman warns that it might be forced to withdraw from the EU if it is unable to comply with future EU regulations.’ If anything, it’s weird that OpenAI thinks their products are legal in the EU now.
Tyler Cowen has a very good editorial in Bloomberg pointing out that too much regulation favors large and entrenched firms in general, so we should have less regulation if we want be dominated less by big business - a point largely missing from his book-sized love letter to big business. In general, I strongly agree. Tyler mentions AI only in order to point out Sam Altman’s explicit call to avoid shutting out the little guy when implementing regulations, whereas in this one case I’m pretty into shutting out the little guy.
Timothy Lee has a more-thoughtful-than-the-usual case for waiting on AI regulations, because it is early and we will get the implementation wrong. He notes that while we might say now that we were too late to regulate social media, even if we had moved to regulate social media early, we still don’t know what a helpful set of rules would have been to stop what eventually happened. Which is very true. And the conflation of job risks and existential risks, with the Congressional focus on jobs, is as Lee highlights a big red flag. I agree that we shouldn’t be pushing to pass anything too quickly, in the sense that we should take time to craft the regulations carefully.
However, I do think there’s a clear concrete option being suggested by Altman, that the regulations restrict the training and deployment of the biggest models while holding off for now on further restrictions on smaller models, and that those large models be registered, licensed and tested for various forms of safety, with an eye towards an international agreement. We should be drafting actual detailed legislative language to put that proposal into practice. Who is doing that?
Brad Polumbo: This level of consensus is your first red flag. The fact that even the business leaders featured, such as OpenAI CEO Sam Altman, were lobbying the Senate for more regulation should immediately tip you off that something sinister is at play here.
Presumably if Altman had opposed regulation, that would have been the red flag that it would have threatened to strangle American competitiveness and innovation.
A common reaction to Sam Altman’s regulatory suggestions was to suggest it was regulatory capture, or a ‘ladder pull’ to prevent others from competing with OpenAI.
Many pointed out that if this was the goal of Altman’s proposal, it’s highly non-optimized for that outcome, including several explicit calls to choose details to avoid doing that.
Sam Altman: regulation should take effect above a capability threshold. AGI safety is really important, and frontier models should be regulated. regulatory capture is bad, and we shouldn't mess with models below the threshold. open source models and small startups are obviously important. To borrow an analogy from power generation: solar panels aren’t dangerous and so not that important to regulate; but nuclear plants are. we have got to be able to talk about regulation for AGI-scale efforts without it implying regulation is going to come after the little guy.
Alethea Power: I think people talking about regulatory capture missed the part where @sama said that regulation should be stricter on orgs that are training larger models with more compute (like @OpenAI), while remaining flexible enough for startups and independent researchers to flourish.
Alexey Guzey: Many are accusing @sama of attempting a "ladder pull" - using regulatory capture to create a monopoly by preventing smaller companies who can't afford regulatory compliance from entering. If that's true, explicitly saying not to do that seems like a pretty stupid strategy.
Eliezer Yudkowsky: This isn't exactly precisely optimal policy, but so far as I can tell it's... straightforwardly not the move for regulatory capture? Maybe there's some secret 4D chess thing where they lobby for a distorted implementation, but IME mostly 4D chess doesn't get played around here.
It's not exactly what I'd wish most. But in terms of what's inside today's Overton Window, this seems correct, and moves toward what's right by humanity rather than what benefits OpenAI in the short term, and that deserves some applause.
That does not mean that the regulations that result from such discussions are safe from exactly the effects Altman is warning against. It is common to talk a good game, or even intend one, and have the results be otherwise. Regulations never turn out the way you would want them to, always are twisted against entrants and towards insiders, whether or not that was the goal. There will be some of that.
This still seems like an attempt to do the minimum of that, indeed to impose far harsher regulations on state-of-the-art models and top insiders, while being more relaxed for open source, if anything I’d worry about being too relaxed there.
I fully agree. Roughly, this threshold should be when any single number has more than 10²⁴ ALU operations, or 10²⁷ logic gates, in its entire causal history.
GPT-3, AlphaFold 2, Stable Diffusion, LLaMa, Dromedary: below the line.
GPT-4, PaLM 2, Claude-Next: over the line.
There should be a safe harbor for input bytes (a) that existed before September 2021, or (b) that have been fully understood, agreed, and signed-off on by at least two humans with strong whistleblower protections and a basic training certificate on biases and confabulations.
Long-term risks remain, including the existential risk associated with the development of artificial general intelligence through self-modifying AI or other means. Other long-term risks are related to the possible deep entangling of AI systems into all parts of daily life and systems, which may cause large-scale societal or environmental issues that are currently difficult or impossible to predict; or specification gaming, whereby an AI system gradually learns to achieve numerical requirements but somehow avoids accomplishing the desired task. These risks are difficult to quantify currently and need additional research.
It is better to see some consideration of this than none. This is still very little, at the end of the ‘Building Safe AI’ section. This does not yet imply any action, and any action that would be taken would likely not be useful. Still, you have to start somewhere.
That Which Is Too Smart For You, Strike That, Reverse It
An unintentional illustration of an important principle.
Rohit: I want AI to take my job. In the sense that we keep our jobs but let AI do it so the time can be spent in things we love. Cut the work week to 1 hour and let AI do it. In other words AI is not the one taking your job, your company might be.
Eliezer Yudkowsky: Hear me out: What if, when it becomes possible for GPT4.5 to do your job, it's not legal for your company to fire you? Instead they're only allowed to cut your pay by 10% every year, eliminate amenities, and have GPT 4.5 watch over you and beep whenever you make a mistake.
"What if regulators somehow managed to do the worst possible thing" would probably be a more productive hypothesis, in my hands, if my own imagination stretched far enough to come up with ideas like the GDPR popup law.
That is not a good suggestion or good prediction. The key point is the last one. Who among us had the imagination to envision, in advance, something as profoundly stupid, wrong-headed and pointlessly destructive as GDPR in its particulars?
Certainly not me. That is because, in context, I am not smart enough. I am not sufficiently good at generating the type of thing GDPR is, or anticipating the way such a law might be written.
I can tell you that the EU will continue to pass stupid pointlessly destructive regulations, the same way I can tell you Magnus Carlen would beat me at chess.
I can’t tell you which laws the EU will pass, the same way I can’t tell you how Magnus Carlen will beat me at chess beyond playing better than I do. If you ever sit around thinking about the EU’s reegulations ‘wow this is a huge pain in the ass that is disrupting things in ways I never thought possible, while optimizing for things no one wants in a completely unaligned way and somehow the humans aren’t coordinating to shut this thing down even now’ then consider what the future might bring.
Gary Marcus links to this Planet Money story (10:28), that equates Altman and Marcus to the traditional bootleggers and Baptists. Strange bedfellows, indeed, and more presuming that Altman couldn’t possibly not be profit maximizing, nothing else important is at stake here, no no.
The Senator From East Virginia Worries About AI
Shoshana Weissmann has, together with Robin Hanson and Tyler Cowen, been part of a reliable three-person team that will bring us all the don’t-regulate-AI takes one might otherwise miss, combining all the logically orthogonal arguments as necessary.
Shoshana Weissmann: This is a great @NRO oped by @RandPaul. Keep Artificial Intelligence out of Government Surveillance.
"These programs surveilled and targeted individuals such as Martin Luther King Jr. and domestic organizations such as the Southern Christian Leadership Conference, as well as infiltrated movements to incite rivalries and discredit the leaders associated with them."
"ACLU acknowledged that 'the Biden administration has been quietly deploying and expanding programs that surveil what people say on social media, using tools that allow agents and analysts to invisibly monitor the vast amount of protected speech that occurs online.'
"The U.S. is engaging in the same activities for which we criticize other countries... But make no mistake, the intent is the same: control the narrative, eliminate dissent, and retain power."
"This should terrify all Americans. The government is using your hard-earned tax dollars to surveil and censor your protected speech. Artificial intelligence is only going to make it easier for the government to do this and harder to detect."
I share the general instinct of ‘let technology develop until we know there is a problem’ and also the instinct of ‘the government needs to have its surveillance powers limited.’ Yet in this case, even if one ignores questions of existential risk, one must tackle with the contradiction, and with the question of inevitability.
You expect everyone else to be free to develop and use AI with minimal oversight, while the government chooses not to use it? You plan to impose this, dare I call it, regulation on the government, and expect this to turn out the way you would like or expect, differentiating good uses from bad uses?
Next thing you’ll likely tell us we shouldn’t be hooking it up to weapon systems.
If you don’t want the government to have the tools to monitor everything in the style of Person of Interest (minus the ‘never wrong’ clause), and don’t want them hooked up to our shall we say enforcement mechanisms, don’t let anyone develop those tools. If you want it to have those tools available and choose to not use them, while not restricting or regulating the technology? Good luck.
I am of course also frustrated by the angle of ‘these techs might well take control of the planet away from humans or literally kill everyone on the planet, but the harm you see is government using them for censorship’ but I’ve come to expect that.
If you want to predict who is opposing regulation of AI, you would get it almost exactly right if you went with ‘the people who oppose regulation of any new technology on principle, no matter what it is, minus those who managed despite this to notice it is going to kill everyone.’
It is continuously frustrating for me, and I hope for you, how damn good the ‘oppose regulation’ heuristic is in general, where one must continuously say ‘yes, if it wasn’t for that whole existential risk issue…’ So it was kind of good to see an ‘ordinary’ fallacy.
Safety Test Requirements
Yosarian: "If you want to do a really big AI training run, you should get a license and get independently confirmed that your AI isn't going to unexpectedly self-replicate or exfiltrate to the internet" seems...reasonable?
Eliezer Yudkowsky: Short-term problem is that it's probably not hard to train a model specifically to not exfiltrate... and then five minutes of LoRA makes it dangerous again. Also needed might be eg strict liability of Meta for any mass-scale damage done by any distilled retrained LLaMA.
Mid-term problem is that an actual AGI can decide to, like, not do those things while you are watching. Long-term problem is that a superintelligence in the lab can killeveryone before the certification phase gets a chance to even execute.
Yosarian: Agreed, I was thinking of this more as something that might give us a warning that we were getting into really dangerous territory and might buy us a few years to figure out what to do than and not as a real long term solution.2
People Are Worried About AI Killing Us
Turing Award Winner Yoshua Bengio writes How Rogue AIs May Arise, with the definition “A potentially rogue AI is an autonomous AI system that could behave in ways that would be catastrophically harmful to a large fraction of humans, potentially endangering our societies and even our species or the biosphere.” This seems like a strong attempt to explain some of the more likely reasons why and paths how such systems are likely to arise. There is a certain type of person for which this might hit the sweet spot and be worth forwarding to them.
Tetraspace: I've noticed two slightly-conflated arguments about why you want safety guarantees in AGI.
Named by replacing "AGI" with a different thing: "If you're not sure that a gun isn't loaded, then it's loaded"
"If you're not sure that your cryptography is secure, then it's insecure"
"If you're not sure that a gun isn't loaded, then it's loaded" -> Things that would be really bad if they happened, even if you think they might not happen, are worth checking and taking precautions just to make sure, because it's really bad for really bad things to happen.
"If you're not sure that your cryptography is secure, then it's insecure" -> Parts of a system that are mysterious to you are parts that you can't get to reliably do precise things, especially not if they're being put in states you weren't thinking of when you made it.
Fun thing about Schrödinger’s Gun: If you’re not sure that a gun isn’t loaded, then it’s loaded, unless you need it to be loaded, in which case it isn’t.
The distinction here matters.
Hopefully we can all agree that AGI is at least a gun, meaning that one must learn how it works and how it operate it, take great care handling it, keep it in good working order and so on, or else people get killed, in this case potentially everyone. AGI is not a naturally safe thing. If the AGI is safe, it is safe because we made it safe.
The question is to what extent one requires security mindset. If our AGI systems are not cryptography-style secure, are we all doomed, or is that merely a nice to have? Given the way LLMs work, this level of security could well be impossible. My inclination is that we are closer to this second stronger requirement than to the weaker one.
That does not mean that every cryptography system that can be broken will inevitably break, in or out of the metaphor, but that’s the way to bet if the stakes are high enough.
Clips from the Logan/Eliezer podcast, including a clip from the Weiss/Altman podcast, with the essence of the ‘you need to be in contact with the state of the art systems to understand the alignment problem’ argument against the ‘please tell us what you have learned from such interactions’ argument.
It also has a crisp ‘you made a prediction of doom that has been invalidated’ versus ‘no I did not, citation needed.’ I do think that some of the key particular abilities of GPT-4 manifested sooner on the general capabilities curve than most people expected, which led to some admissions of surprise, and that admitting one’s surprise there is good. It’s quite the pattern to say ‘this person or group admitted being wrong about this prediction, therefore we can dismiss their other predictions,’ although of course it counts as some amount of evidence the same way everything else does.
Steven Byrnes: Two unhelpful dynamics in public discussion of AI x-risk 1. Mixing up “risk from LLMs” with “risk from future AI”. Reasonable people disagree on whether future LLMs could kill every human, but there’s a much stronger case that SOME future AI could.
Mixing up disagreement about the problem, with disagreement about policy solutions. If X thinks future AI will probably kill everyone, and Y thinks it almost definitely won’t, then obviously X & Y will disagree about what to do about that!
A very stupid version of this dynamic is when Y says “X’s policy is terrible, therefore AI won’t kill everyone”
An even stupider version is when Y says “If X believed that, they’d support policy Z, which is awful, therefore AI won’t kill everyone”
For my part, I think AI will probably kill everyone, and I also think that every proposed policy is awful, or inadequate, or (most often) both. Ditto for not passing any policy. If I ever figure out which of many bad options is the LEAST bad, I will advocate for it. 🤷
Here are two random examples (one from each side of the debate) of people unhelpfully arguing about policy, in a context where the real argument is whether there’s any problem in the first place.
[Example Given from Tony Zador of invoking Pascal’s Wager in response to a request for an argument that p(doom) is low.]
Tim Urban: Whether you're optimistic or pessimistic about the future, the fact is that we're facing existential risk at worst and a vastly different future world at best. The world we're used to very well might not be around for that much longer, so let's really enjoy this world while we have it.
Visit the places you've always wanted to visit. Dive into that hobby you've always wanted to try. Spend quality time with your loved ones. Savor each sunny Saturday, each great meal, each moment of fun. If we end up looking back on these days with great nostalgia, we want to at least know we made the most of the time we had.
Mike Young: This strikes me as weirdly dark and seems to discount the idea that AI could make the future vastly better as a third state. We might look back at this time and think it sucked!
Tim Urban: Definitely - but why not play it safe! Worst that happens is we maximize our time and it turns out it wasn't as fleeting as we realized.
There is a rather dominant argument for doing all the things worth doing and making the best use of your time, if the alternative is not doing that. Why not get more out of life rather than less, even if everything will stay the same?
Presumably the answer is that the alternative is investing in the future, so the question becomes: Which future? If the world is going to change a lot pretty often, then investing in your ‘normal’ future to score victory points later becomes less worthwhile, your investments won’t prove relevant so often, so you should invest more in scoring victory points now.
Another alternative is to invest in impacting the non-normal futures. Don’t spend your time savoring, spend your time fighting for a good outcome. Highly recommended, if you can find a potentially impactful path to doing that - even if the probability of it having no effect is very high.
A key question is always how these intersect. I continue to believe that savoring one’s experiences and getting the most out of life is mostly not a rival good with impact on the future, because a responsible amount of savoring actively aids in your quest, and an irresponsible amount does not actually leave you better off for long.
Sunder Pichai (in FT): While some have tried to reduce this moment to just a competitive AI race, we see it as so much more than that.
…
We care deeply about this. Yet, what matters even more is the race to build AI responsibly and make sure that as a society we get it right.
We’re approaching this in three ways. First, by boldly pursuing innovations to make AI more helpful to everyone.
OK, so first we improve capabilities. As you do.
Second, we are making sure we develop and deploy the technology responsibly, reflecting our deep commitment to earning the trust of our users. That’s why we published AI principles in 2018, rooted in a belief that AI should be developed to benefit society while avoiding harmful applications.
We have many examples of putting those principles into practice, such as building in guardrails to limit misuse of our Universal Translator.
Second, we avoid short term direct harm cases. As you do.
Finally, fulfilling the potential of AI is not something one company can do alone. In 2020, I shared my view that AI needs to be regulated in a way that balances innovation and potential harms.
…
Increased international co-operation will be key.
…
AI presents a once-in-a-generation opportunity for the world to reach its climate goals, build sustainable growth, maintain global competitiveness and much more. Yet we are still in the early days, and there’s a lot of work ahead. We look forward to doing that work with others, and together building AI safely and responsibly so that everyone can benefit.
Third, we want regulations to help us deal with these issues and realize these gains.
Oh. I see.
So, no mention of existential risks, then, at all. No hint that there might be something larger at stake than ordinary human misuse of systems.
Other People Are Not As Worried About AI Killing Us
AI has massive upside, and this is often neglected in discussions on risk. I also surveyed some promising approaches to AI alignment — including scalable oversight, checks and balances, and more. We must treat alignment as a tractable, solvable technical problem.
…
Whether we survive the rise of superintelligent machines depends largely on whether we can create AIs that care about humans. Evolution has shown us that this is possible; wee must do our best to achieve it because the upside of aligned, moral AI is too great.
Current AIs alone will give each child an interactive tutor, free medical advice for the poor, and automate away much drudgery. Future AIs could cure cancer and other diseases, help solve energy abundance, and accelerate scientific progress. An AI ban, as some have called for, would be short-sighted; we would be giving up on the problem too early.
I am always confused when people say that the upside potential is being ignored. I assure you we are absolutely not ignoring that. We are obsessed with the upside potential, and that’s exactly what we don’t want to throw away.
Almost every call to ‘ban AI’ is not a call to ban current AI, or even finding new uses for current AI. Everyone agrees the children get their tutors, the ones fighting against the medical advice will be the American Medical Association, and so on. The calls are calls to suspend additional capability developments we see as actively dangerous. Very different. Certainly we don’t say stop working on alignment, and we’d be thrilled if you came back with a solution so we could resume the work.
Also, what, short-sighted? You can say wrong, and have a case, but short-sighted?
Give up on the problem? Giving up would be moving forward without solving the problem. Not moving forward means not giving up on the problem, or humanity. If we are to ‘do our best’ to achieve a solution we will need time, also presumably orders of magnitude more resources and focus, and people taking the question seriously under a security mindset.
I’d also add that this appears to make the common mistake of setting the alignment bar far too low. ‘Cares about humans’ may or may not be necessary depending on what method is used, but it is really, really not sufficient.
My go-to intuition pump on this right now is to ask, suppose we create a vast array of AGIs, much more capable, faster and smarter than humans and capable of replication, that are not under our control, which care about both themselves and also humans about as much and in similar ways as typical humans care about humans. Sounds like a triumph of sorts. Do you think that ends well for us?
I also urge everyone to follow Litany of Tarski: Treat alignment as a practical, tractable problem if and only if you believe that it could be one if you treated it that way. The world does not owe you this, physics is not fair and won’t save you.
Norswap thread on why he is not so worried, at least not for a while. Main reason is he does not think LLMs can understand underlying concepts or on their own get us to AGI. He talks at length about Eliezer’s model and why he disagrees with it, with a softer version of the ‘if any of these steps breaks the threat goes away’ mistaken impression, which we need to work harder on avoiding. Always good to see such clear articulations of where someone has their head, to help calibrate what might be useful new info.
Dominic Pino engages in straightforward intelligence denialism, which I’m proposing as a term for those such as Tyler Cowen who think that intelligence does not much matter and that much smarter than human AGIs would not have any dominant capabilities, and all our usual dynamics will continue to apply far, far out of distribution. And who assert this as if it is obvious, without making any argument for it, or answering any of the possible arguments against it. We have a reasonable disagreement about the value of intelligence within the human spectrum. Well past it? I don’t understand how their position is even coherent, and I can’t find any true objections I can actually respond to. Perhaps they would say that this proves intelligence is not so important, to which I’d say I am still in the human distribution here.
Alex Tabarrok wants to ‘see that the AI baby is dangerous before we strangle it in its crib.’ I would remind him that by the time you know it is dangerous, in a way that we don’t already know now, changes are quite good that it is no longer in its crib and you can no longer strangle it. He does not answer the question of what would count as evidence that the AI is indeed dangerous, that we can expect to be available in time.
Doomers: About how big would the mean IQ gap have to be between high and low scoring countries before P(doom) > 50% in the lower mean IQ countries?
Before we get to the objections down-thread, it’s worth pointing out that
AI is going to effectively have a lot more than ‘90 points’ on humans once you factor in all its additional capabilities, if things keep going as one would naively expect.
And also that if you think the answer is 90 points or more, you’re… kind of being dense about this? What was human history like, again? Perhaps there are a handful of places on Earth where the natives wouldn’t have been wiped out if they had an IQ of 50 in (any year before 1914, let’s say) but I don’t see how. Certainly such a country would have been invaded, conquered and colonized quickly, its resources expropriated similar to if it had been unoccupied. The existing residents would simply have not been useful to keep alive through generations.
I am reporting to you live from New York City, in the United States of America, in the American hemisphere, where the native population was entirely displaced not too long ago by those with superior technology. I realize the entire population was not wiped out per se, but it was pretty close despite no substantial IQ differential. This is hardly a unique situation.
Anyway.
Eliezer Yudkowsky: This is ill-posed in multiple ways. Cows are still around despite larger gaps, because we haven't reached the absolute threshold to build better cows. Finland seems cool, they could probably go full superintelligent and we'd all be fine.
Garett Jones: How is it ill posed other than that it yields the conclusion you don't want? Is niceness theory of humans doing the heavy lifting?
Eliezer Yudkowsky: It's ill-posed in the sense that the categories cut against the grain of my model's answers, ie your options rule out a priori any answers I think are correct. And what does the heavy lifting is the power difference between current human civs and natural selection.
If country X hires immigrants from country Y to drive cars, the point at which Xs stop hiring Ys is not when X gets some relative amount smarter than Y, but when X gets absolutely smart enough to build self-driving cars. Similarly with us and cows; we can't build meat-fruits yet.
I actually think it’s either one. Driving in country X will be a task calibrated to the ability of those in country X, and will certainly require a certain bare minimum in capabilities. If people from Y couldn’t reliably drive cars, we wouldn’t hire them to drive cars. If we had self-driving cars, we wouldn’t hire them to drive cars because we wouldn’t need to. Both work.
Right now, humans need substantial amounts of manual labor done, where the minimum capabilities to do that are within the range of most humans. That is very lucky for most humans. Similarly, we don’t have a better way of producing what cows produce. That is lucky for the existence of cows, whether they are lucky or unlucky to exist in their current state versus not existing is a matter of dispute.
I’d also say that yes, the ‘niceness’ of humans is doing a lot of work as well, although we are not always so nice. Quite recently we saw some examples of less nice humans (e.g. Nazis) deciding to wipe out via deliberate genocide what they viewed as ‘inferior’ humans. If they’d had 30 extra IQ points on the rest of us, the rest of us likely wouldn’t be around.
Luke Stiles: But we won't have the same problem with AGI or whatever you lose sleep over?
Eliezer Yudkowsky: I think what wipes us out is superintelligences that can easily build more efficient doers of anything that humans or cows do.
Garett Jones: So in your view why haven't the humans in highly productive countries "wiped out" people in countries with ~Malthusian levels of non-natural resource productivity? The productive countries effortlessly build processes much more productive, yet the less productive nations exist.
My other answer to that is that birth rates in developed countries have declined due to dynamics that will not be duplicated with AGIs.
Stewart Dompe: I didn’t know how to prompt this with earlier discussions but haven’t there been death squads in parts of the world where the rationalization has been some version of transaction costs of trade/coexistence are greater than, well, death squads?
Garret Jones: Yes, but so far those efforts have almost always failed to fully "wipe out" groups, thank goodness.
Stewart Dompe: Yes. Thankfully their intentions fell well short of their capacities. I predict @ESYudkowsky has thoughts about potential capacities.
Garett Jones: But now there are nuclear-armed, high-income nations coexisting with weak, low-productivity nations with abundant natural resources. According to doomer theory, low-income nations should have been doomed long ago-- for predation by self-interested high-income nations.
Doomerism is realpolitik + sci-fi, and I'm asking them to take the realpolitik side seriously.
I would notice that before the nukes, the higher-income nations did indeed divide most of the world between them and were in the process of carving up the remainder, until the world wars, as technology had enabled this. Yes, right now we no longer do that, for various realpolitik reasons, but this is an unusual age that could easily be coming to a close if history is not kind to us.
Nor do I think that ‘there were some survivors of the death squads’ is a hopeful line, the failures were indeed due to lack of capabilities, in ways that won’t transfer.
I have no idea how one looks at human history, even with the type of model Jones is using, and conclude that humans should have little to worry about, or even are likely to survive for long, should very intelligent AIs come into being.
Garrett Jones insists, in various threads and places, on various forms of this ‘Doomer puzzle’ in the present world that simply… are not puzzles, and I don’t understand how anyone could think that they were puzzles? He says that doomers claim that when there is a 2x to 200x IQ gap that the smarter thing inevitably destroys the weaker thing, but that we already have such smarter things in the world, and… I can’t even process the claims involved here. Can he not notice the differences in these scenarios, where it is only the technologies available that differ, and we have a multi-polar world with many levels of opposition to predation and genocide with no one having a decisive advantage and many participants having nuclear weapons, and an inability to efficiently exploit what you take even if you succeed in a way that could possibly make up for that and so on?
I’d also point to the question of time scales, and that humans are currently in a very strange period where people are choosing not to reproduce much for various reasons, and many other things, in the hopes they would help.
Seriously, I don’t get what is going on here if one takes the argument at face level, everyone involved has to be too… high IQ… for this. I would be happy to have an actual good faith discussion with Jones, the way I had one with Hanson, either in public or in private, to sort this out - his other work has more than justified that.
Section one is entitled ‘Yudkowsky’s Monster’ and asks us to imagine Eliezer born into an earlier age, and him worrying about us finding the ‘vital force’ people at the time thought existed, generating super-human servants. Jacob suggests Eliezer would have called for monster alignment and a pause on all medical research, doing great harm.
This is great for highlighting that metaphorical Eliezer isn’t calling for the halt of all medical research. He is calling for a halt of research into harnessing the vital force, of the search for creating more capable monsters. He is not saying to stop testing, say, Penicillin. Only, ask Frankenstein, if he would kindly not attempt to create Frankenstein’s Monster, or perhaps to make such a pursuit illegal.
Which is good advice. Attempting to create Frankenstein’s Monster fails, or it succeeds and creates Frankenstein’s Monster. Either way, not great.
Section two says we should despair of any ability to usefully predict or prepare for any problems that do occur, until they happen: “Sometimes, we cannot plan; our only hope is to react.”
That is an argument for not worrying about AI as a matter of utility, I suppose? In the sense that in the movie Charlie and the Chocolate Factory, when they are told the last golden ticket has been found, Charlie’s family decides to let him sleep, let him have one last dream.
In terms of how much probability to put on existential catastrophe, it is very much the opposite. If we cannot prepare or do anything useful until after an AGI already exists, then we are almost certainly super dead if we build one, so let’s not build one?
Section three draws a parallel to a dramatically different situation where one would want to wait until the last minute, while saying that yes, in many cases one can indeed usefully take actions in light of potential future events.
Section four I think fundamentally misunderstands how alignment works and what different people are worried about, and also is strangely optimistic that meaningful alignment progress is already being made. I also don’t understand how one can endorse the actions and models of Paul Cristiano as useful, while dismissing any hope of anticipating future events - the claims earlier prove way too much.
Even more than that, when the conclusion says ‘ASI x-risk sits on the other side of a paradigm shift’ that directly contradicts the Cristianoapproach. If that’s right, then there is every reason to expect the iterated, trial-and-error strategies to break down when that paradigm shift occurs, which is exactly Eliezer’s warning. And then, whoops.
He finishes:
The easiest way to convince me to worry about x-risk would be to argue that this implication does not hold, for example by highlighting historical scenarios where an intentional intervention pre-paradigm-shift preemptively fixed a major issue that only emerged post-paradigm-shift.
Other ways to change my mind would be to convince me that a superintelligence explosion is possible without a breakthrough; or to convince me that I am wrong in my belief that, in an environment with chaotic dynamics, it is useless to intervene far in advance. But these claims are more technical/objective, so it seems less likely that I am wrong here.
I can only conclude that this person says ‘he is not worried’ only in the Bobby McFarrin sense that he fails to see doing so as useful. What could one do? Well, obviously, stop the breakthrough from being found would be one intervention - the Genetic Engineering Asilomar approach or something more forceful, however difficult implementation would be.
In summary: If you told me “I think there is going to be some technological breakthrough, after which we will be faced with ASI, and there is nothing we can do before that happens to ensure it doesn’t kill us or otherwise creates a good world, so don’t worry” I would very much worry, and I would say “so let’s not do that, then!”
There’s also the possibility that there won’t be a necessary breakthrough, in which case OP seems to agree that alignment research now would be super useful, and he endorses it, so the dispute there is a matter of probability and magnitude.
Maxwell Tabarrok: I think often about the life of a Phonecian merchant or smith who would have had thousands of years of familiar looking history behind them and thousands of years of familiar future ahead. It seems like we have less than a decade on either side now.
I’d expect that merchant or smith to be rather positive about today’s world. In general I don’t share the instinct here, nor do I think that we should allow the transformation of the world into something we wouldn’t recognize as valuable on reflection, because that’s what valuable means. No, I don’t primarily care about GDP or energy expenditures.
But think of the value he gave up, and this type of thing had never happened before when there was a new smartest or most capable being around.
Transhumanist Ben: When Zeus heard that fathering a child with Thetis would lead to him inevitably being overthrown by a successor stronger than he, he simply Did Not.
It'd be really embarrassing if humanity has less self control than the guy who fathered a third of ancient Greece in the form of some animal or another.
Future models will comprise a hierarchy of abstract state that transitions laterally over time, with direct percepts (of multiple modalities--language, vision, kinesthetic) being optional to the process (necessary for training, but not the only link from one moment to the next). The internal model of reality needs to be free of the limitations of the perceptual realm.
Family Ties is actually a series I've been procrastinating on finishing for a couple years now. It'd be funny if AI Family Ties that was passable in quality came out before I finished the original run. I don't expect that, though, out of existing diffusion-based AIs, at least not without a TON of human postprocessing. Diffusion models lack the profound interframe continuity of items and shapes in a scene that you get for free from any camera.









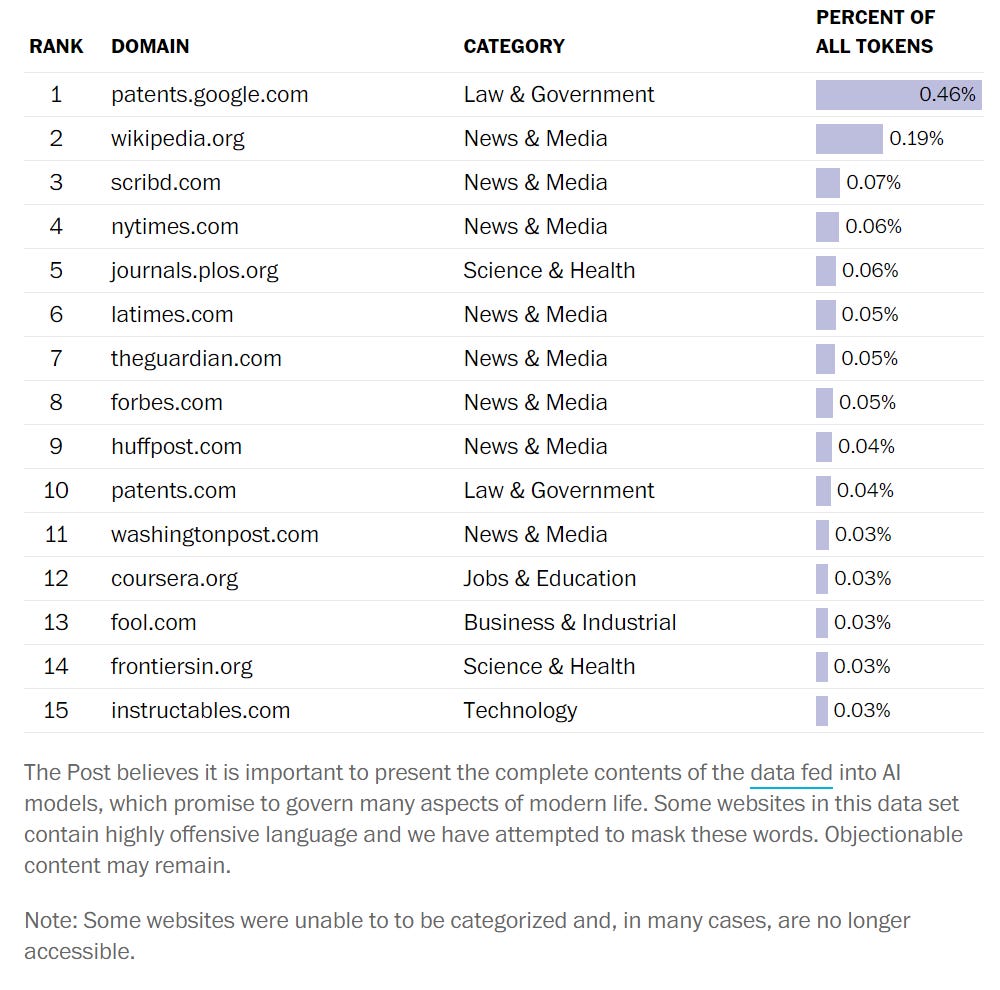








Please, What does this mean in simple terms?
Future models will comprise a hierarchy of abstract state that transitions laterally over time, with direct percepts (of multiple modalities--language, vision, kinesthetic) being optional to the process (necessary for training, but not the only link from one moment to the next). The internal model of reality needs to be free of the limitations of the perceptual realm.
Family Ties is actually a series I've been procrastinating on finishing for a couple years now. It'd be funny if AI Family Ties that was passable in quality came out before I finished the original run. I don't expect that, though, out of existing diffusion-based AIs, at least not without a TON of human postprocessing. Diffusion models lack the profound interframe continuity of items and shapes in a scene that you get for free from any camera.