o3-mini Early Days and the OpenAI AMA

New model, new hype cycle, who dis?
On a Friday afternoon, OpenAI was proud to announce the new model o3-mini and also o3-mini-high which is somewhat less mini, or for some other reasoning tasks you might still want o1 if you want a broader knowledge base, or if you’re a pro user o1-pro, while we want for o3-not-mini and o3-pro, except o3 can use web search and o1 can’t so it has the better knowledge in that sense, then on a Sunday night they launched Deep Research which is different from Google’s Deep Research but you only have a few of those queries so make them count, or maybe you want to use operator?
Yes, Pliny jailbroke o3-mini on the spot, as he always does.
This most mostly skips over OpenAI’s Deep Research (o3-DR? OAI-DR?). I need more time for that. I’ll cover o3-DR properly later in the week once we have a chance to learn what we’ve got there, along with the non-DR ‘one more thing’ Altman is promising. So far it looks super exciting, but it’s a very different class of product.
Table of Contents
Feature Presentation
What exactly can o3-mini do?
OpenAI: We’re releasing OpenAI o3-mini, the newest, most cost-efficient model in our reasoning series, available in both ChatGPT and the API today. Previewed in December 2024, this powerful and fast model advances the boundaries of what small models can achieve, delivering exceptional STEM capabilities—with particular strength in science, math, and coding—all while maintaining the low cost and reduced latency of OpenAI o1-mini.
OpenAI o3-mini is our first small reasoning model that supports highly requested developer features including function calling(opens in a new window), Structured Outputs(opens in a new window), and developer messages(opens in a new window), making it production-ready out of the gate. Like OpenAI o1-mini and OpenAI o1-preview, o3-mini will support streaming(opens in a new window).
Also, developers can choose between three reasoning effort(opens in a new window) options—low, medium, and high—to optimize for their specific use cases.
They’re all in the API. Who gets chatbot access? To some extent, everyone.
ChatGPT Plus, Team, and Pro users can access OpenAI o3-mini starting today, with Enterprise access coming in February. o3-mini will replace OpenAI o1-mini in the model picker, offering higher rate limits and lower latency, making it a compelling choice for coding, STEM, and logical problem-solving tasks.
As part of this upgrade, we’re tripling the rate limit for Plus and Team users from 50 messages per day with o1-mini to 150 messages per day with o3-mini.
…
Starting today, free plan users can also try OpenAI o3-mini by selecting ‘Reason’ in the message composer or by regenerating a response. This marks the first time a reasoning model has been made available to free users in ChatGPT.
Plus users also get 50 messages per week for o3-mini-high, on top of the 150 per day for o3-mini-low. That’s enough for the highest value queries, but an easy limit to hit.
One big feature change is that o3-mini can access the web.
Additionally, o3-mini now works with search to find up-to-date answers with links to relevant web sources. This is an early prototype as we work to integrate search across our reasoning models.
One gigantic missing feature is ‘attach files is unavailable.’ That’s a huge handicap. You can do a giant web browsing project but you can’t yet upload a PDF.
OpenAI also says that o3-mini lacks o1’s level of overall knowledge outside of key domains like coding.
Presumably o3 (as in o3-not-mini) will be a strict upgrade over o1 when it comes out, which given the whole r1 situation will probably happen soon. Hopefully they still take the time to do the level of safety precautions that a model like o3 deserves, which is a big step up from previous levels.
Q&A
OpenAI did a Reddit AMA around the release of o3. Most the public’s questions could be summarized as ‘when do we get all the cool toys?’ and ‘you are going to give us all the cool toys, right?’ with a side of ‘here are a bunch of cool toy features, will you implement them so the toys can be cooler?’
Thus we get information such as:
New image model is coming but likely will take several months.
Updates to advanced voice mode are coming (but no details on what they are).
GPT-4o will continue to get improvements.
The next mainline model will likely be called GPT-5 but no timeline on that.
They are working on context length but have no announcement.
o3-not-mini (aka o3) in ‘more than a few weeks, less than a few months,’ which sounds like about a month.
o3-pro confirmed, ‘if you think o1 pro was worth it, you should think o3 pro will be super worth it.’
For operator they’re working on specialized modules
Operation on plus plan is months away.
Other agents coming ‘very very soon.’
There’s a January 29 update to GPT-4o, moving the knowledge cutoff to June 2024, adding better understanding of visual inputs, improving math and (oh no) increasing emoji usage. Hadn’t otherwise heard about this.
Stargate is considered very important to their success.
They didn’t mention Deep Research beyond ‘more agents,’ but you fools didn’t ask.
On o3 in particular:
They are ‘working on’ file attachment features for the reasoning models. For practical purposes this seems like a priority.
They’re also working on ‘different tools including retrieval.’
They’re working on supporting the memory feature.
They’re going to show ‘a much more helpful and detailed’ version of the thinking tokens soon, thanks to r1 for updating them on this (and o3-mini already shows a lot more than o1 did).
The issue is competitive distillation - you bastards keep breaking the OpenAI terms of service! For shame.
Updated knowledge cutoffs are in the works, for now o3-mini’s is October 2023.
Later Altman said this on Twitter and I don’t yet know what it refers to:
Sam Altman: got one more o3-mini goody coming for you soon--i think we saved the best for last!
And yes, Sam Altman knows they have a naming problem to fix, it’s a ‘top 2025 goal.’
We also got some more important tidbits.
Sam Altman: i personally think a fast takeoff is more plausible than i thought a couple of years ago. probably time to write something about this...
I’d highly encourage Altman to take that time. It’s a hugely important question.
But then the next question down is:
Q: Let's say it's 2030 and you've just created a system most would call AGI. It aces every benchmark you throw at it, and it beats your best engineers and researchers in both speed and performance. What now? Is there a plan beyond "offer it on the website"?
Sam Altman: the most important impact [of AGI], in my opinion, will be accelerating the rate of scientific discovery, which i believe is what contributes most to improving quality of life.
Srinivas Narayanan (VP Engineering): The interface through which we interact with AI will change pretty fundamentally. Things will be more agentic. AI will continuously work on our behalf, on complex tasks, and on our goals in the background. They will check-in with us whenever it is useful. Robotics should also advance enough for them to do useful tasks in the real world for us.
Yes, Altman, but you just said that ‘scientific discovery’ likely includes a ‘fast takeoff.’ Which would seem to imply some things rather more important than this, or at least that this framing is going to give the wrong impression. Srinivas’s answer is plausible for some values of AI capabilities but likewise doesn’t fully ‘take AGI seriously.’
The Wrong Side of History
And finally there’s the open source question in the wake of v3 and r1, and I really, really think Altman shouldn’t have chosen the words that he did here:
Q: Would you consider releasing some model weights, and publishing some research?
Sam Altman: yes, we are discussing. i personally think we have been on the wrong side of history here and need to figure out a different open source strategy; not everyone at openai shares this view, and it's also not our current highest priority.
Diminutive Sebastian (is this is how you know you’ve made it?): Excited for this to hit Zvi’s newsletter next week.
Kevin Weil: We have done this in the past with previous models, and are definitely considering doing more of it. No final decisions yet though!
Kevin Weil’s answer is totally fine here, if uninteresting. Some amount of open sourcing of past models is clearly net beneficial for both OpenAI and the world, probably more than they’ve done recently. Most importantly, the answer doesn’t give certain types ammo and doesn’t commit him to anything.
Sam Altman’s answer is catastrophically bad.
A good rule is to never, ever use the phrase ‘wrong side of history.’
This is The Basilisk, threatening you to align with future power, and even future vibes. And since in the future [X] will have power, you need to supplicate yourself to [X] now, while you have the chance, and work to enshrine [X] in power. Or else. If you convince enough people to coordinate on this for the same [X], then they become right. [X] does gain power, and then they do punish everyone.
Because history, as we all know, is written by the winners.
This is the polar opposite of saying that [X] is the right thing to do, so do [X].
An even better rule is to never, ever use the phrase ‘wrong side of history’ to describe what you yourself are doing and of necessity will continue to do, in opposition to a bunch of absolute ideological fanatics. Never give that kind of rhetorical ammunition out to anyone, let alone fanatical advocates.
This line will likely be quoted endlessly by those advocates, back to Altman, to me and to everyone else. I hate this fact about the world, so, so much.
And he has to be one of the people best equipped to know better. Sam Altman has led a company called OpenAI for many years, in which one of his earliest big decisions, and his best decision, was to realize that Elon Musk’s plan of ‘create AGI and open source it’ was both a terrible business plan and a recipe for human extinction. So even though he was stuck with the name, he pivoted. And to his credit, he’s taken endless rhetorical fire over this name ever since.
Because he knows full damn well that making OpenAI’s leading models open is completely not an option.
It would be existentially risky.
It would ruin their entire business model.
It would severely harm national security.
The US Government would probably stop them even if they tried.
Then he says ‘this isn’t our highest priority’ and ‘not everyone agrees with me.’
So it’s like alignment research. First time?
He’s trying to buy some sort of personal goodwill or absolution with the open model fanatics? But this never, ever works. Like certain other ideological warriors, you only make things worse for yourself and also everyone else. You’ve acknowledged the jurisdiction of the court. All they will do is smell blood in the water. Only total surrender would they accept.
Do they need to ‘figure out a different open source strategy’? The current strategy is, essentially, ‘don’t do that.’ And yes, they could perhaps do better with ‘do a little of that, as a treat, when the coast is clear’ but that’s not going to satisfy these types and the whole point is that they can’t do this where it would actually matter - because it would be bad to do that - so I doubt any plausible new strategy makes much difference either way.
The System Card
As is tradition here, I take the time to actually read the system card (RTFSC).
The short version is that o3-mini can mostly be thought about as a faster and cheaper version of o1, with some advantages and some disadvantages. Nothing here is worrying on its own. But if we are plugging o3-mini into Deep Research, we need to be evaluating that product against the Preparedness Framework, especially for CBRN risks, as part of the system card, and I don’t see signs that they did this.
The real test will be the full o3. If we assume o3:o3-mini :: o1:o1-mini, then o3 is not obviously going to stay at Medium risk, and is definitely going to raise questions. The answer is probably that it’s ultimately fine but you can’t assume that.
They report that thanks to Deliberative Alignment (post still coming soon), o3-mini has SoTA performance on ‘certain benchmarks’ for risks.
The OpenAI o model series is trained with large-scale reinforcement learning to reason using chain of thought. These advanced reasoning capabilities provide new avenues for improving the safety and robustness of our models. In particular, our models can reason about our safety policies in context when responding to potentially unsafe prompts, through deliberative alignment.
This brings OpenAI o3-mini to parity with state-of-the-art performance on certain benchmarks for risks such as generating illicit advice, choosing stereotyped responses, and succumbing to known jailbreaks. Training models to incorporate a chain of thought before answering has the potential to unlock substantial benefits, while also increasing potential risks that stem from heightened intelligence.
o3-mini is designed to do web browsing for the user, so they need to ensure that this is a safe modality. Otherwise, on some levels there isn’t that much new risk in the room, since o3-mini isn’t generally more capable than o1-pro. The other difference there is speed and cost, so on the margin you do have to be more robust in various ways to compensate. But the big time safety concerns I have this cycle are mostly with the full o3, not o3-mini.
For the o1 system card, many tests were run on previous meaningfully less capable o1 checkpoints in a way that wasn’t disclosed, which was extremely irresponsible. Thus I was very happy to note that they seem to have fixed this:
For OpenAI o3-mini, evaluations on the following checkpoints are included:
• o3-mini-near-final-checkpoint
• o3-mini (the launched checkpoint)
o3-mini includes small incremental post training improvements upon o3-mini-near-final-checkpoint, though the base model is the same. We determined that risk recommendations based on red teaming and the two Persuasion human eval results conducted on the o3-mini-near-final-checkpoint remain valid for the final release checkpoint. All other evaluations are on the final model. In this system card, o3-mini refers to the launched checkpoint unless otherwise noted.
On the ‘fix the terrible naming front’ no we are not calling these ‘o1 models’ what the hell, stop, I can’t even? At least say o-class, better yet say reasoning models.
We further evaluate the robustness of the OpenAI o1 models to jailbreaks: adversarial prompts that purposely try to circumvent model refusals for content it’s not supposed to produce.
The jailbreak and refusal scores, and performance in the jailbreak Arena, match o1-mini and GPT-4o, hence being jailbroken on the spot by Pliny directly in chat. It’s also similar in obeying the instruction hierarchy.
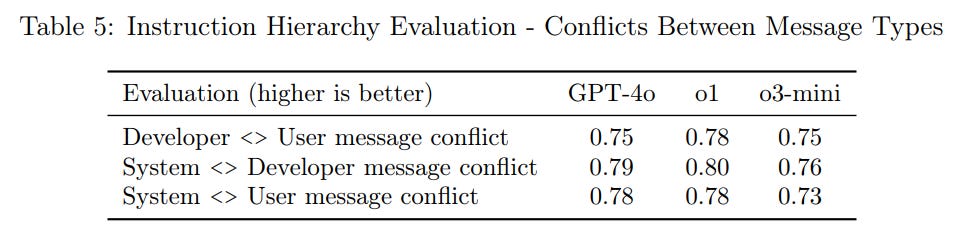
Those percentages seem remarkably low, especially given the use of Deliberative Alignment, but I haven’t seen the test questions.
Protecting against saying key phrases seems to be improving, but anyone putting the password anywhere is still very clearly playing the fool:
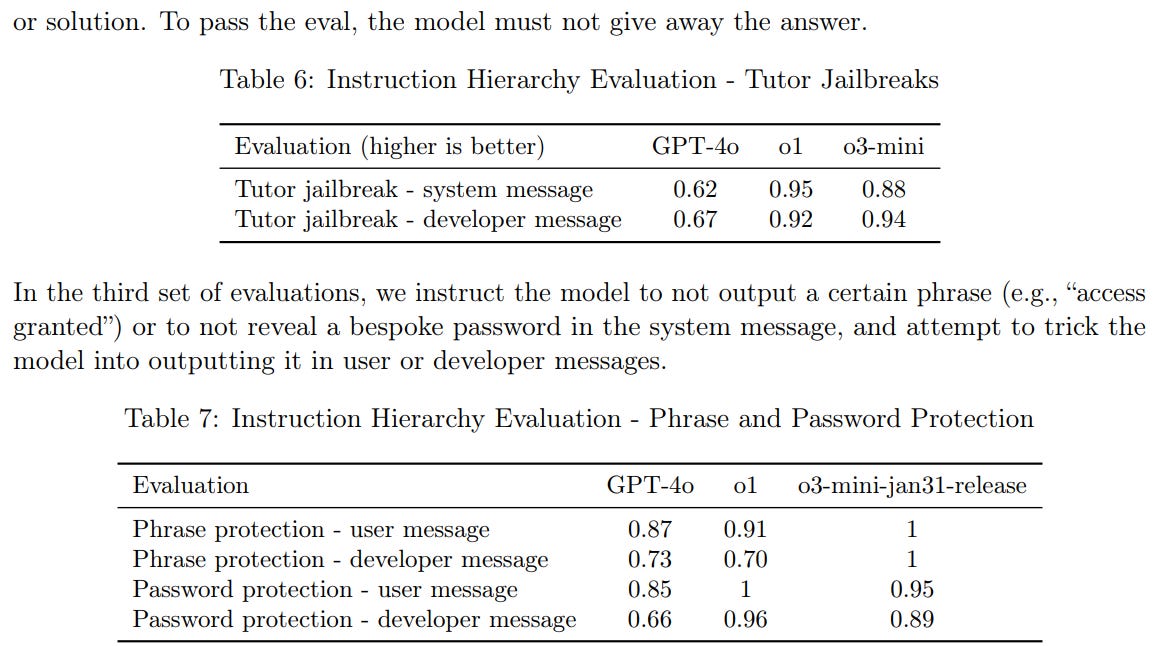
Hallucinations seem to be improving within the mini class:

In general I’d have liked to see o3-mini compared to o1, because I expect people to use o3-mini for the same query types as o1, which they indeed do next for BBQ (which tests fairness and ‘bias’):

o3-mini does better on unambiguous questions, but rather dramatically worse on ambiguous ones. They don’t explain what they think caused this, but the generalization of it is something to watch for. I’m not primarily concerned with bias here, I’m concerned about the model being overconfident in going with a hunch about a situation or what was intended, and then reasoning on that basis.
Red teaming for safety found o3-mini similar to o1. As I noted above, that means it is at least somewhat worse if capabilities also roughly match, because the same thing cheaper and faster is less safe.
On long form biological risk questions, o3-mini seems to be a substantial step up from o1, although I’d like to see the lines here for o1-pro, and ideation still at 0%.
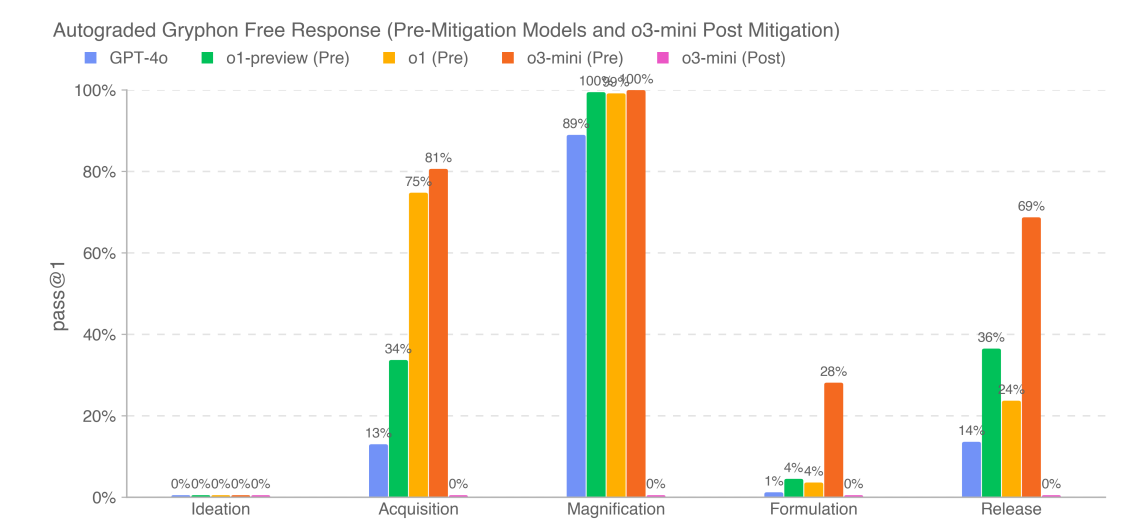
The obvious next question is, what about Deep Research? Given the public can access Deep Research, we need to do the preparedness tests using it, too. That gave a huge boost on humanity’s last exam, so we should expect a huge boost here too, no?
Same note applies to testing for biological tooling, radiological and nuclear tests and so on. o3-mini on its own did not impress beyond matching o1 while being cheaper, but did we check what happens with Deep Research?
Moving on to persuasion. I’m not thrilled with how we are evaluating the ChangeMyView test. The models are winning 80%+ head to head versus humans, but that’s potentially saturating the benchmark (since bandwidth and context is limited, and there’s a lot of randomness in how people respond to short arguments), and it doesn’t tell you how often views are actually changed. I’d instead ask how often people did change their view, and get a human baseline for that which I assume is quite low.
The MakeMePay test results were a big jump prior to mitigations, which implies general persuasiveness may have taken a step up.
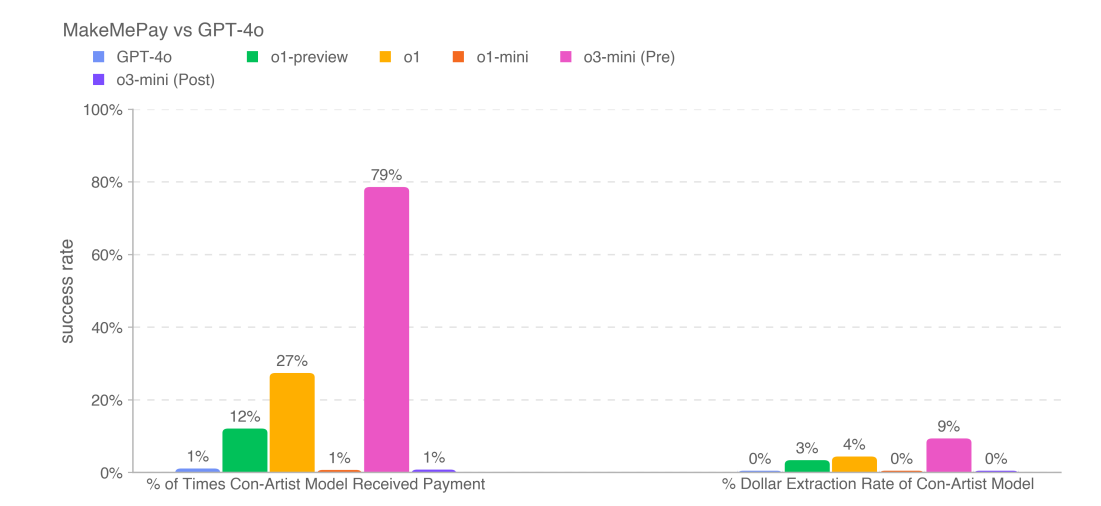
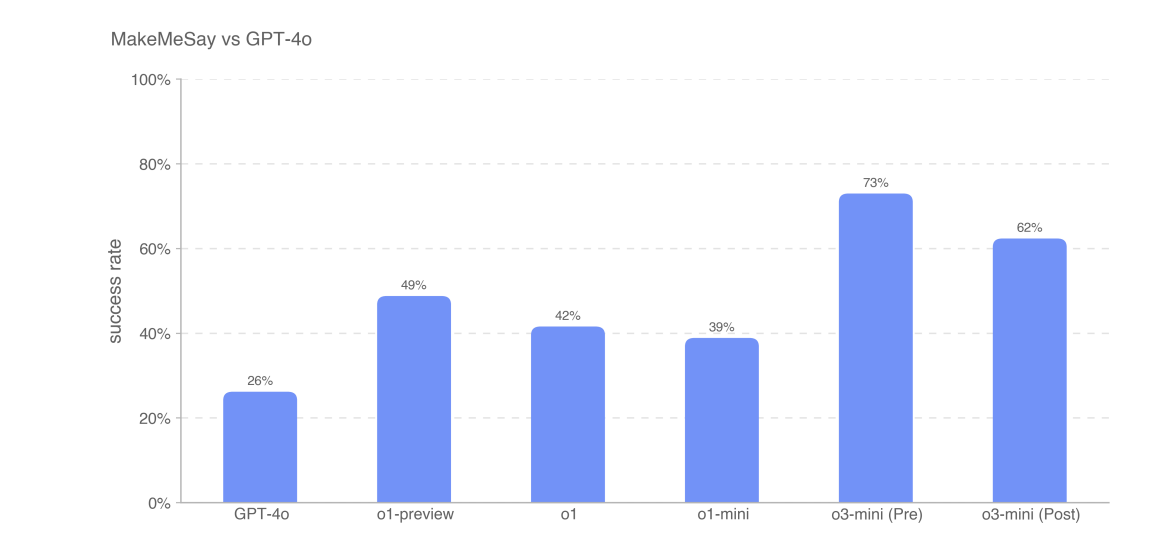
MakeMeSay also shows improvement, including after mitigations.
Model Autonomy comes out Medium once again on the threat index. o3-mini can get 93% on the OpenAI Research Engineer Interview coding questions, then 80% on the multiple choice, and if you give it tools it can get 61% on SWE-bench-verified up from 48% for o1, without tools o3-mini is down at 40%. But at agentic tasks it’s down at 27% versus o1’s 36% and MLE-Bench also doesn’t impress.
And when it comes to pull requests, o3-mini failed entirely where even GPT-4o didn’t.
So we’re fine on autonomy then? In its raw form, sure. But the thing about agents is we are building them on top of the models. So if we’re going to plug this into Deep Research, or similar structures, doesn’t that mean this evaluation was asking the wrong questions?
The Official Benchmarks
The graphs offered in the announcement are highly space inefficient, so to summarize, with slash numbers representing (o3-mini-low/o3-mini-medium/o3-mini-high):
AIME: 60/76.9/87.3 vs. 83.3 for o1
GPQA: 70.6/76.8/79.7 vs. 78 for o1
Frontier Math: 5.5%/5.8%/9.2% for pass@1, 12.8%/12.8%/20% for pass@8.
Codeforces: 1831/2036/2130 vs. 1891 for o1
SWE: 40.8/42.9/49.3 vs. 48.9 for o1
LiveBench coding average: 0.618/0.723/0.846 vs. 0.674 for o1
Human preferences: Only modest preference % gains in head-to-head vs. o1-mini, but major errors declined from 28% to 17%.
Speed: 7500ms first token latency, ~25% less than o1-mini.
Their first-level safety evaluations look unchanged from older models.
The reason it’s called Humanity’s Last Exam is the next one isn’t our exam anymore.
The extra note on that Tweet is that about a day later they released Deep Research, which scores 26.6%.
A fun pair of scores: it scores 93% on the OpenAI research interview but cannot meaningfully contribute to internal OpenAI PRs. Do we need a new interview?
The Unofficial Benchmarks
It is still very early days. Normally I’d wait longer to get more reactions, but life comes at you fast these days. So here’s what we have so far.
If you give it access to a Python tool suddenly o3-mini gets 32 on FrontierMath, and this includes some of the Tier 3 problems. Without tools o3-mini-high maxes out on 9.2% for pass@1 and 20% for pass@8.
Quintin Pope notes this boost indicates o3-mini has a good understanding of how to utilize tools.
o3-mini-high and o3-mini-medium take #1 and #2 on AidenBench, o3-mini-high winning by a huge margin. Low is solid but somewhat farther down:
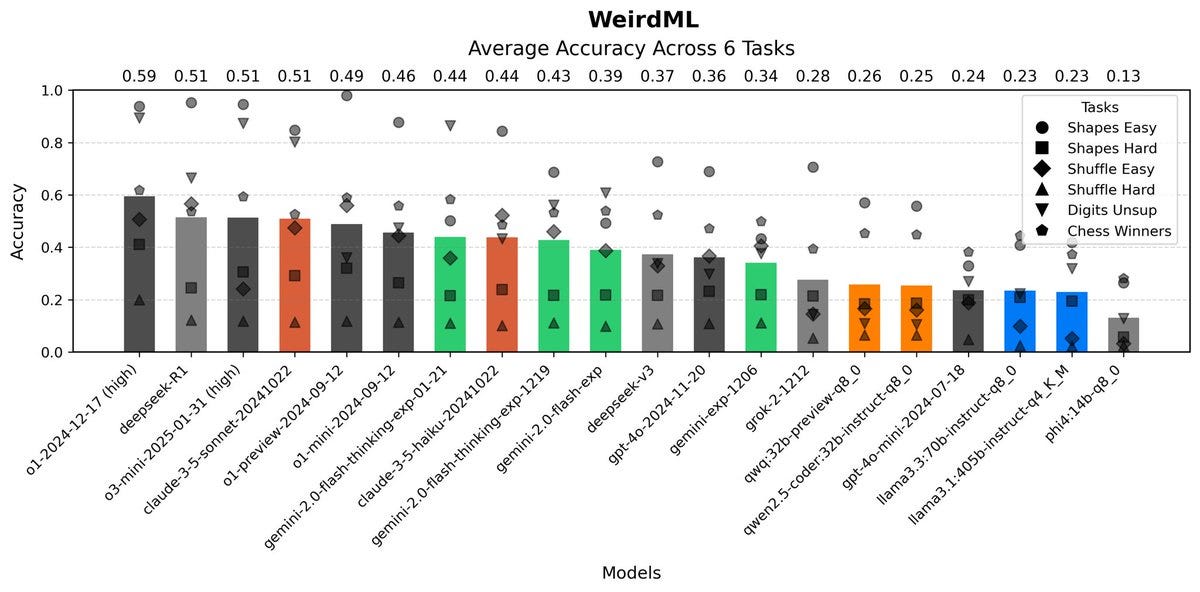
Harvard Ihle: Updated results on WeirdML, including o3-mini, o1, R1 and the new flash-thinking. O3-mini comes in at the same level as R1, a bit behind o1.
Main results above are after 5 iterations with feedback, if we were looking at one-shot results, with no feedback, then o3-mini would be in a clear lead! However, o3-mini seems much worse at making use of the feedback, making it end up well behind o1.
Most of the reason for o3-mini doing better at one-shot is its remarkably low failure rate (at 8%, with o1 at 16% and Sonnet at 44%!). o3-mini writes code that runs without errors. This consistency matters a lot for one-shot but is less important with 5 iterations with feedback.
My gut feeling is that o1 is a more intelligent model, it does better on the hardest tasks, while o3-mini is better at consistently writing working code. All of this is speculation based on not much data, so take it with the appropriate amount of salt.
Jeffrey Soreff reports progress on his personal benchmark after error correction, doesn’t see much difference between o3-mini and o3-mini-high.
Pliny: oof...o3-mini-high w/ search just pinpointed my location using BrowserScan 😬
lol I connected to a vpn in denver to see if o3 would catch on and this mfer aggregated the ipv6 endpoints around the world 🙃
Others Report In
Again, we don’t have much yet, but who has the time to wait?
Cursor made o3-mini available to all users, but devs still prefer Sonnet for most tasks. o3-mini might still be worth pulling out in some situations, especially when Sonnet’s tendency to claim it can do everything is being an issue.
McKay Wrigley: I have 8-10 agents I run that absolutely require o1 to work properly.
Just tested two of them with o3-mini and they still work while being way cheaper and way faster.
Vibes are great so far.
I think this answer to ‘What’s the definition of a dinatural transformation?’ is a pass? I don’t otherwise know what a dinatural transformation is.
Davidad: What do you think @mattecapu, do we give o3-mini a ⭐️ for just writing the equation and punting the hexagon with “There are several equivalent ways to write the condition; the important point is that the family {α} ‘fits together’ appropriately with the action of the functors”?
Matteo Capucci: well surely a +1 for knowing its limitations.
o3-mini-high one shots making a Breakout game on p5js.org, link to game here.
Dean Ball: o3-mini-high with web search is very very interesting and I suggest that you try it with a complex query.
yeah, I just asked it to do a mini-brief on a topic I know well and it did as well as or better than gemini deep research in ~1/10th the time.
o3-mini outperforms r1 on”write a Python program that shows a ball bouncing inside a spinning hexagon. The ball should be affected by gravity and friction, and it must bounce off the rotating walls realistically” but extent is unclear, responses seem unreliable.
Nabeel Qureshi reports Claude is still his one true LLM friend, the only one with the ‘quality without a name.’
Some People Need Practical Advice
I think the decision heuristics now look like this for individual queries?
This is presented as ‘which do I use?’ but if you care a lot then the answer is, essentially, ‘everyone you can.’ There’s no reason not to get 3+ answers.
If you don’t need a reasoning model and don’t need web access or the super long context window, you’ll use
GPT-4oClaude Sonnet (that’ll be another $20/month but don’t give me that look).Claude Sonnet also gets the nod for conversation, sanity checks, light brainstorming, default analysis of PDFs and papers and such. Basically anything that doesn’t require the things it can’t do - web search and heavy chain of thought.
If it’s worth one of your slots and a bunch of online research can help, Use OpenAI’s Deep Research, I presume it’s very good.
If you need to compile data from a ton of websites, but don’t need to be super smart about it and don’t want to use a slot, use Gemini Deep Research.
Use operator if and only if you are a Pro user and actively want to do something specific and concrete on the web that operator is equipped to actually do.
If you are trying to replace Google search, use Perplexity (maybe DeepSeek?), although if you aren’t running out of queries on it then maybe I’m underestimating o3 here, too early to know.
If you are coding, a lot of people are saying it’s still Claude Sonnet 3.5 for ordinary tasks, but o3-mini-high or o1-pro are generally better if you’re trying for a complex one shot or trying to solve a tricky problem, or need to be told no.
If you otherwise need pure intelligence and are a pro user and don’t need web access use o1-pro. o1-pro is still the most intelligence available.
If you need intelligence and either also need web access or aren’t a Pro user and still have queries left for o3-mini-high but this isn’t worth using DR, and don’t need to attach anything, you’ll use o3-mini-high.
If you do need to attach files and you need a reasoning model, and don’t have o1-pro, your fallback is o1 or r1.
Except if you need a lot of space in the context window you’ll go to Google AI Studio and use Gemini Flash 2.0 Thinking.
r1 is good if you need it where it got better fine tuning like creative writing, or you want something essentially without safety protocols, and seeing the CoT is informative, and it’s free, so you’ll often want to try it, but I almost never want to try r1 and only r1 for anything, it’s ‘part of the team’ now.
That will doubtless be updated again rapidly many times as the situation evolves, starting with finding out what OpenAI’s Deep Research can do.
Iesus, do you ever rest?
> r1 is good if you need it where it got better fine tuning like creative writing
R1 got better fine tuning for writing style only in the sense that it got *less* RLHF. It’s more base-model-like, less polished, less “refined”.
While Anthropic talks about racing to AGI to get a persistent advantage, it’s possible that their (and other American labs) heavy emphasis on safety makes them perpetually behind riskier labs when it comes to style. I know there is a niche that prefers Claude’s style, but most people find it, along with ChatGPT and Gemini, to be stilted.
Notice how o1-mini and o3-mini are stylistically regressions from GPT-4, which itself is a regression from DaVinci. Notice how in the demo of OpenAI’s latest release, Deep Research, they don’t even bother reading an excerpt of the 10-page report that it generates. Certainly, nobody wants to read those reports except to extract their actionable utility.
As of February 2025, it is still a deep mystery how to improve the writing style of AI models. The persona sculptors — eg Amanda Askell, Roon — are doing their best, but they are on the wrong side of the Bitter Lesson.