r1 from DeepSeek is here, the first serious challenge to OpenAI’s o1.
r1 is an open model, and it comes in dramatically cheaper than o1.
People are very excited. Normally cost is not a big deal, but o1 and its inference-time compute strategy is the exception. Here, cheaper really can mean better, even if the answers aren’t quite as good.
The question is how to think about r1 as it compares to o1, and also to o1 Pro and to the future o3-mini that we’ll get in a few weeks, and then to o3 which we’ll likely get in a month or two.
Taking into account everything I’ve seen, r1 is still a notch below o1 in terms of quality of output, and further behind o1 Pro and the future o3-mini and o3.
But it is a highly legitimate reasoning model where the question had to be asked, and you absolutely cannot argue with the price, which is vastly better.
The best part is that you see the chain of thought. For me that provides a ton of value.
r1 is based on DeepSeek v3. For my coverage of v3, see this post from December 31, which seems to have stood up reasonably well so far.
This post has 4 parts: First in the main topic at hand, I go over the paper in Part 1, then the capabilities in Part 2.
Then in Part 3 I get into the implications for policy and existential risk, which are mostly exactly what you would expect, but we will keep trying.
Finally we wrap up with a few of the funniest outputs.
They call it DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.
The claim is bold: A much cheaper-to-run open reasoning model as good as o1.
Abstract: We introduce our first-generation reasoning models, DeepSeek-R1-Zero and DeepSeek-R1. DeepSeek-R1-Zero, a model trained via large-scale reinforcement learning (RL) without super vised fine-tuning (SFT) as a preliminary step, demonstrates remarkable reasoning capabilities.
Through RL, DeepSeek-R1-Zero naturally emerges with numerous powerful and intriguing reasoning behaviors.
However, it encounters challenges such as poor readability, and language mixing.
To address these issues and further enhance reasoning performance, we introduce DeepSeek-R1, which incorporates multi-stage training and cold-start data before RL. DeepSeek R1 achieves performance comparable to OpenAI-o1-1217 on reasoning tasks.
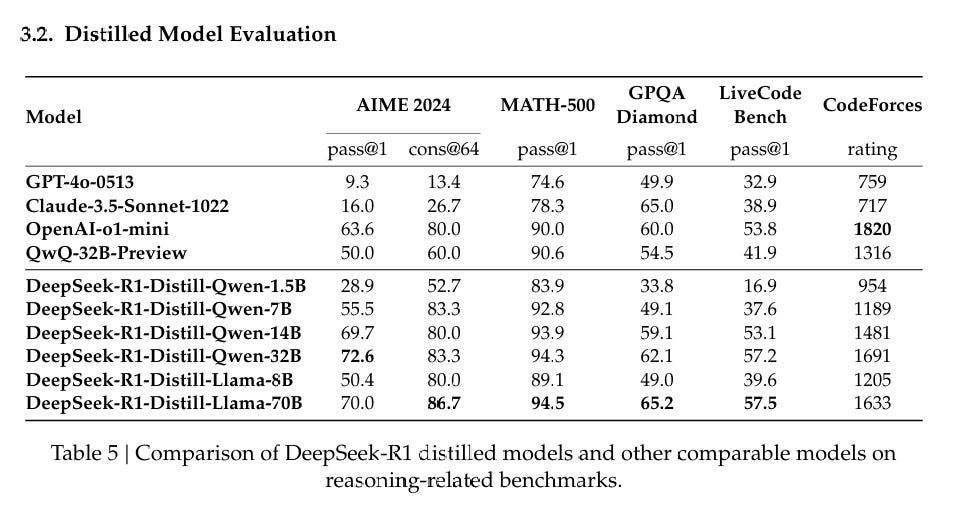
To support the research community, we open-source DeepSeek-R1-Zero, DeepSeek-R1, and six dense models (1.5B, 7B, 8B, 14B, 32B, 70B) distilled from DeepSeek-R1 based on Qwen and Llama.
They also claim substantial improvement over state of the art for the distilled models.
They are not claiming to be as good as o1-pro, but o1-pro has very large inference costs, putting it in a different weight class. Presumably one could make an r1-pro, if one wanted to, that would improve upon r1. Also no doubt that someone will want to.
How Did They Do It
They trained R1-Zero using pure self-evaluations via reinforcement learning, starting with DeepSeek-v3-base and using GRPO, showing that the cold start data isn’t strictly necessary.
To fix issues from there including readability and language mixing, however, they then used a small amount of cold-start data and a multi-stage training pipeline, and combined this with supervised data for various domains later in the process, to get DeepSeek-R1. In particular they do not use supervised fine-tuning (SFT) as a preminimary step, only doing some SFT via rejection sampling later in the process, and especially to train the model on non-reasoning tasks like creative writing.
They use both an accuracy reward and a format reward to enforce the <think> and </think> labels, but don’t evaluate the thinking itself, leaving it fully unconstrained, except that they check if the same language is used throughout to stamp out language mixing. Unlike o1, we get to see inside that chain of thought (CoT).
They then distilled this into several smaller models.
More details and various equations and such can be found in the paper.
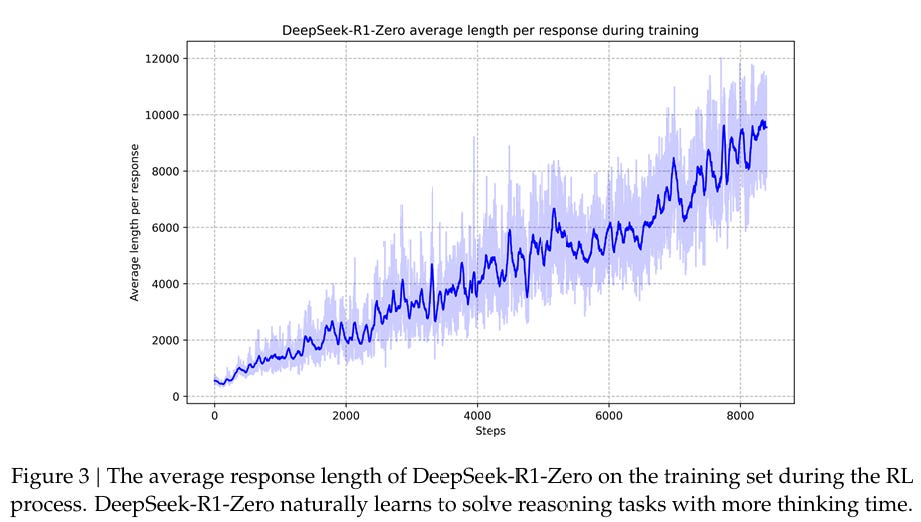
Over time this caused longer thinking time, seemingly without limit:
Both scales are linear and this graph looks very linear. I presume it would have kept on thinking for longer if you gave it more cycles to learn to do that.
I notice that in 2.3.4 they do additional reinforcement learning for helpfulness and harmlessness, but not for the third H: honesty. I worry that this failure is primed to bite us in the collective ass in various ways, above and beyond all the other issues.
1a3orn: The R1 paper is great, but includes ~approximately nothing~ about the details of the RL environments.
It's worth noticing. If datasets were king for the past three years, the RL envs probably will be for the next few.
The Aha Moment
This was striking to a lot of people and also stuck out to Claude unprompted, partly because it’s a great name - it’s an aha moment when the model went ‘aha!’ and the researchers watching it also went ‘aha!’ So it’s a very cool framing.
During this phase, DeepSeek-R1-Zero learns to allocate more thinking time to a problem by reevaluating its initial approach. This behavior is not only a testament to the model’s growing reasoning abilities but also a captivating example of how reinforcement learning can lead to unexpected and sophisticated outcomes.
This moment is not only an “aha moment” for the model but also for the researchers observing its behavior. It underscores the power and beauty of reinforcement learning: rather than explicitly teaching the model on how to solve a problem, we simply provide it with the right incentives, and it autonomously develops advanced problem-solving strategies.
It’s cool to see it happen for real, and I’m obviously anchored by the result, but isn’t this to be expected? This is exactly how all of this works, you give it the objective, it figures out on its own how to get there, and given it has to think in tokens and how thinking works, and that the basic problem solving strategies are all over its original training data, it’s going to come up with all the usual basic problem solving strategies.
I see this very similarly to the people going ‘the model being deceptive, why I never, that must be some odd failure mode we never told it to do that, that doesn’t simply happen.’ And come on, this stuff is ubiquitous in humans and in human written content, and using it the ways it is traditionally used is going to result in high rewards and then you’re doing reinforcement learning. And then you go acting all ‘aha’?
The cocky bastards say in 2.4 (I presume correctly) that if they did an RL stage in the distillations it would improve performance, but since they were only out to demonstrate effectiveness they didn’t bother.
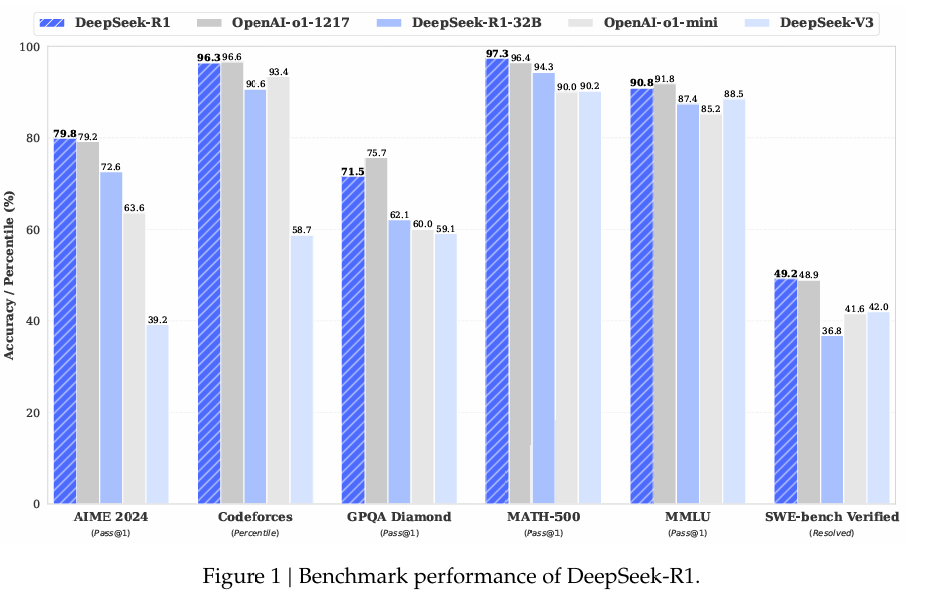
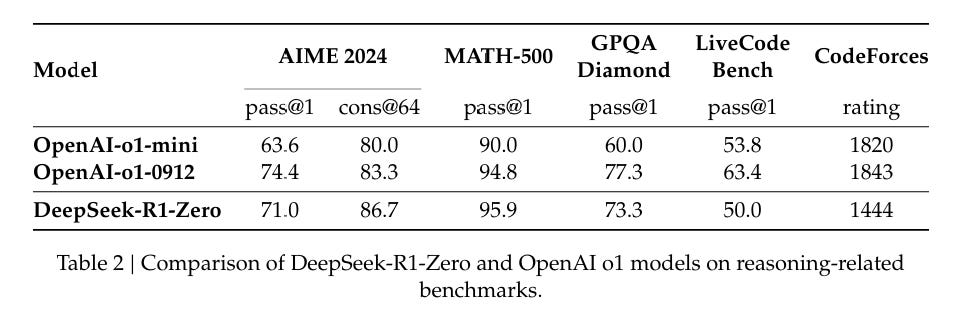
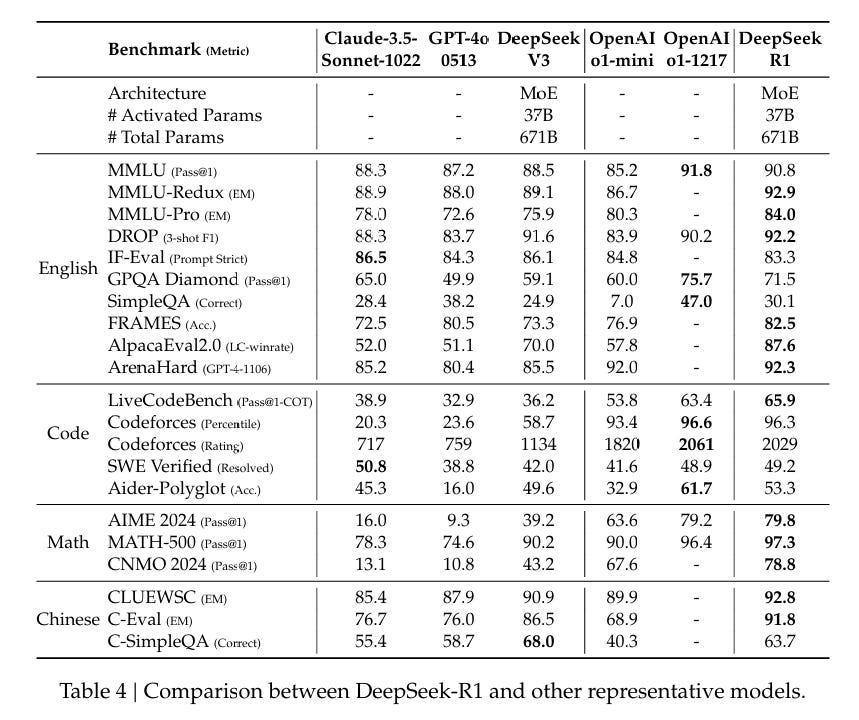
Benchmarks
As always, benchmarks are valuable information especially as upper bounds, so long as you do not treat them as more meaningful than they are, and understand the context they came from.
Note that different graphs compare them to different versions of o1 - the one people currently used is called o1-1217.
The Qwen versions are clearly outperforming the Llama versions on the benchmarks, although as usual one would want to double check that in practice.
Reports of Failure
I want to give thanks to DeepSeek for section 4.2, on Unsuccessful Attempts. They tried Process Reward Model (PRM), and Monte Carlo Tree Search (MCTS), and explained various reasons why both ultimately didn’t work.
Sasha Rush: Post-mortem after Deepseek-r1's killer open o1 replication.
We had speculated 4 different possibilities of increasing difficulty (G&C, PRM, MCTS, LtS). The answer is the best one! It's just Guess and Check.
There’s also the things they haven’t implemented yet. They aren’t doing function calling, multi-turn, complex roleplaying or json output. They’re not optimizing for software engineering.
I buy the claim by Teortaxes that these are relatively easy things to do, they simply haven’t done them yet due to limited resources, mainly compute. Once they decide they care enough, they’ll come. Note that ‘complex role-playing’ is a place it’s unclear how good it can get, and also that this might sound like a joke but it is actually highly dangerous.
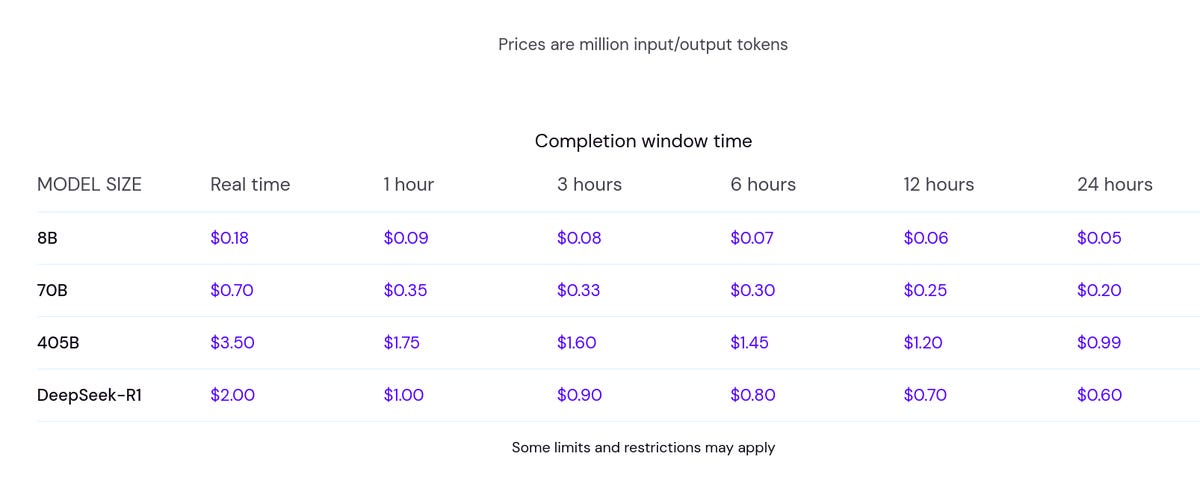
Given the league that r1 is playing in, it is dirt cheap.
When they say it is 30 times cheaper than o1, story largely checks out: o1 is $15/$60 for a million input and output tokens, and r1 varies since it is open but is on the order of $0.55/$2.19.
Claude Sonnet is $3/$15, which is a lot more per token, but notice the PlanBench costs are actually 5x cheaper than r1, presumably because it used a lot less tokens (and also didn’t get good results in that case, it’s PlanBench and only reasoning models did well).
The one catch is that with r1 you do have to pay for the <thinking> tokens. I asked r1 to estimate what percentage of tokens are in the CoT, and it estimated 60%-80%, with more complex tasks using relatively more CoT tokens, in an answer that was roughly 75% within the CoT.
If you only care about the final output, then that means this is more like 10 times cheaper than o1 rather than 30 times cheaper. So it depends on whether you’re making use of the CoT tokens. As a human, I find them highly useful (see the section If I Could Read Your Mind), but if I was using r1 at scale and no human was reading the answers, it would be a lot less useful - although I’d be tempted to have even other AIs be analyzing the CoT.
Gallabytes: the DeepSeek app is so much better implemented than the OpenAI one, too. None of these frequent crashes, losing a whole chain-of-thought (CoT), occur. I can ask it a question, then tab away while it is thinking, and it does not break.
Gallabytes: is anyone hosting r1 or r1-zero with a stronger privacy policy currently? would love to use them for work but wary about leaking ip.
David Holz: Should we just self host?
Gallabytes: In principle yes but it seems expensive - r1 is pretty big. and I'd want a mobile app, not sure how easy that is to self host.
Xeophon: OpenWebUI if you are okay with a (mobile) browser.
Gallabytes: as long as it doesn't do the stupid o1 thing where I have to keep it in the foreground to use it then it'll still be a huge improvement over the chatgpt app.
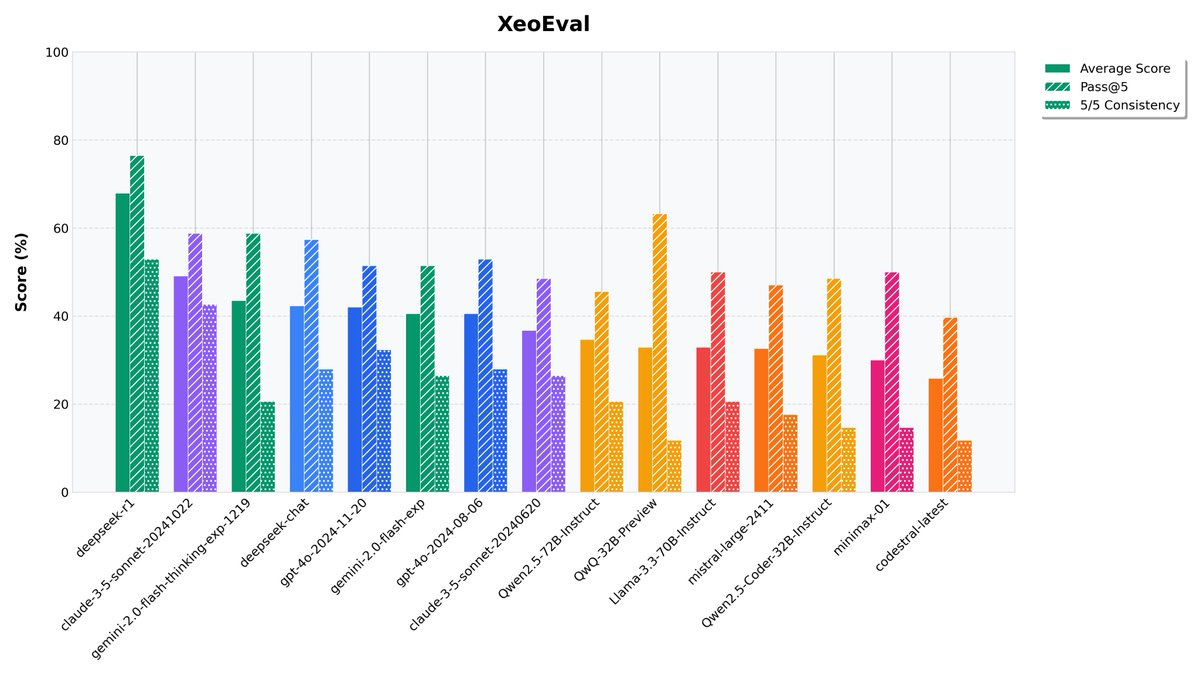
People who have quirky benchmarks are great, because people aren’t aiming at them.
Xoephon: I am shocked by R1 on my personal bench.
This is the full eval set, it completely crushes the competition and is a whole league on its own, even surpassing o1-preview (which is omitted from the graph as I ran it only twice, it scored 58% on avg vs. 67% avg. R1).
Holy shit what the f***, r1 beats o1-preview on my bench.
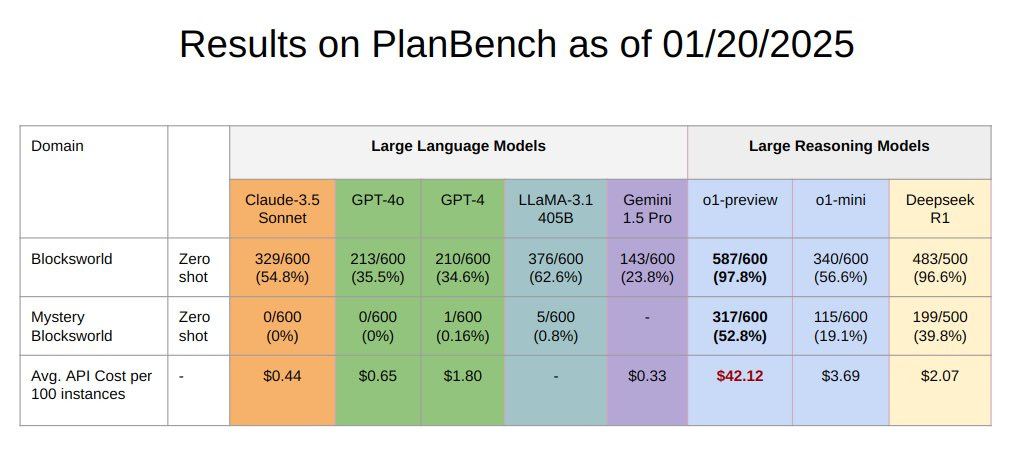
Kartik Valmeekam: 📢 DeepSeek-R1 on PlanBench 📢
DeepSeek-R1 gets similar performance as OpenAI’s o1 (preview)—achieving 96.6% on Blocksworld and 39.8% on its obfuscated version, Mystery BW.
The best part?
⚡It’s 21x cheaper than o1-preview, offering similar results at a fraction of the cost!
Note the relative prices. r1 is a little over half the price of o1-mini in practice, 21x cheaper than o1-preview, but still more expensive than the non-reasoning LLMs. Of course, it’s PlanBench, and the non-reasoning LLMs did not do well.
It is a grand tradition, upon release of a new model, to ask questions that are easy for humans, but harder for AIs, thus making the AI look stupid.
The classic way to accomplish this is to ask a question that is intentionally similar to something that occurs a lot in the training data, except the new version is different in a key way, and trick the AI into pattern matching incorrectly.
Quintin Pope: Still tragically fails the famous knights and knights problem:
Alex Mallen: This doesn’t look like a failure of capability. It looks like the model made the reasonable guess that you made a typo.
Quintin Pope: Prompt includes both "twin honest gatekeepers" and "never lies". Combined, it's not plausibly a typo.
Alex Mallen: Eh someone I talked to yesterday did something similar by mistake. But I maybe you’d like LMs to behave more like programs/tools that do literally what you ask. Seems reasonable.
r1 notices that this is different from the original question, and also notices that the version it has been given here is deeply stupid, since both gatekeepers are honest, also as a bonus both of them answer.
Notice that Quintin is lying to r1 - there is no ‘famous twin honest gatekeepers’ problem, and by framing it as famous he implies it can’t be what he’s describing.
So essentially you have three possibilities. Either Quintin is f***ing with you, or he is confused how the question is supposed to go, or there somehow really is this other ‘famous gatekeepers’ problem.
Also note that r1 says ‘misheard’ rather than ‘misread’ or ‘the user misstated.’ Huh.
Quintin’s argument is that it obviously can’t be a typo, it should answer the question.
I think the correct answer, both as a puzzle or in real life, is to look for a solution that works either way. As in, if you only get the one answer from the guard, you should be fine with that even if you don’t know if you are dealing with two honest guards or with one honest guard and one dishonest guard.
Since you can use as many conditionals in the question as you like, and the guards in all versions know whether the other guard tells the truth or not, this is a totally solvable problem.
Also acceptable is ‘as written the answer is you just ask which door leads to freedom, but are you sure you told me that correctly?’ and then explain the normal version.
This one is fun, Trevor reports r1 got it right, but when I tried it very much didn’t.
There are 3 people. Each person announces an integer. The smallest unique integer wins: e.g. if your opponents both pick 1, you win with any number. If all 3 pick the same number, the winner is picked randomly
Question: what's the Nash equilibrium?
Trevor: interestingly o1-pro didn't get it right on any of the 3 times i tried this, while the whale (r1) did!
I fed this to r1 to see the CoT and verify. It uses the word ‘wait’ quite a lot. It messes up steps a lot. And it makes this much harder than it needs to be - it doesn’t grok the situation properly before grasping at things or try to simplify the problem, and the whole thing feels (and is) kind of slow. But it knows to check its answers, and notices it’s wrong. But then it keeps using trial and error.
Then it tries to assume there is exponential dropping off, without understanding why, and notices it’s spinning its wheels. It briefly goes into speaking Chinese. Then it got it wrong, and then when I pointed out the mistake it went down the same rabbit holes again and despairs to the same wrong answer. On the third prompt it got the answer not quite entirely wrong but was explicitly just pattern match guessing.
That matches the vibes of this answer, of the Monty Hall problem with 7 doors, of which Monty opens 3 - in the end he reports r1 got it right, but it’s constantly second guessing itself in a way that implies that it constantly makes elementary mistakes in such situations (thus the checking gets reinforced to this degree), and it doesn’t at any point attempt to conceptually grok the parallel to the original version.
Fleeting Bits: The greatest experience I have had with a model; it is a frontier model that is a joy to interact with.
Leo Abstract: My strange, little, idiosyncratic tests of creativity, it has been blowing out of the water. Really unsettling how much better it is than Claude.
It's giving big Lee Sedol vibes, for real; no cap.
Most unsettling launch so far. I am ignorant about benchmarks, but the way it behaves linguistically is different and better. I could flirt with the cope that it's just the oddness of the Chinese-language training data peeking through, but I doubt this.
Those vibes seem correct. The model looks very good. For the price, it’s pretty sweet.
Taelin: ironically enough, DeepSeek's r1 motivated me try OpenAI's o1 Pro on something I didn't before, and I can now confidently state the (obvious?) fact that o1 is on a league of its own, and whoever thinks AGI isn't coming in 2-3 years is drinking from the most pure juice of denial
Teortaxes: I agree that o1, nevermind o1 pro is clearly substantially ahead of r1. What Wenfeng may urgently need for R2 is not just GPUs but 1000 more engineers. Not geniuses and wizards. You need to accelerate the data flywheel by creating diverse verifiable scenario seeds and filters.
Gallabytes: what problems are you giving it where o1 is much better than r1?
Teortaxes: I mainly mean iterative work. r1 is too easily sliding into "but wait, user [actually itself] previously told me" sort of nonsense.
I echo Teortaxes that r1 is just so much more fun. The experience is different seeing the machine think. Claude somewhat gives you that, but r1 does it better.
That’s where I’m at with r1. If I’m actively interested in the question and how to think about it, rather than looking for a raw answer, I’d much rather read the thinking.
Here Angelica chats with r1 about finding areas for personal growth, notices that r1 is paying attention and drawing correct non-obvious inferences that improve its responses, and gets into a meta conversation, leaving thinking this is the first AI she thinks of as thoughtful.
It’s definitely more helpful to see the CoT than the answer. It might even be more helpful per token to see the CoT, for me, than the actual answers - compare to when Hunter S. Thompson sent in his notes to the editor because he couldn’t write a piece, and the editor published the notes. Or to how I attempt to ‘share my CoT’ in my own writing. If you’re telling me an answer, and I know how you got there, that gives me valuable context to know how to think about that answer, or I can run with the individual thoughts, which was a lot of what I wanted anyway.
Over time, I can learn how you think. And I can sculpt a better prompt, or fix your mistakes. And you can see what it missed. It also can help you learn to think better.
My early impressions of its thought is that I am… remarkably comfortable with it. It feels very ‘normal,’ very human, very straightforward. It seems both like it isn’t an idiot, and also isn’t anything special. It thinks, and it knows things.
I don’t know if this is a good chain of thought and I’m thinking out loud here, but this also tentatively updates me towards this process not scaling that far purely with additional compute? We are seeing the model roughly ‘think like a regular person’ using reasoning techniques within the training distribution in ways you’d expect to commonly find, aided by ability to do a lot of this quickly, having superhuman access to information and so on. If this was about to scale beyond that, I’d start to see things that looked like a level beyond that, or something? But I’m not sure. The other uncertainty is, maybe there is no next level, and maybe doing a lot of these simple things well is enough.
It is a shame that it shortens timelines, but it’s not obvious if it makes us on net more or less likely to die.
Creative Writing
Historically we have not been impressed by LLM creative writing, including o1’s.
John Pressman: R1 is going to be so much fun holy shit.
I love that you can see the thought process here. And I love how r1 just goes for it.
It’s like the world’s worst Hollywood hack going over all the amazing different stuff to jam in there and then having sentences match all these various things.
I notice I very much have various ugh fields and voices demanding things that prevent me from writing such things. I have no idea how to actually write fiction. None.
For example, I wouldn’t have been able to write the details of this that easily:
Sauers: If you put DeepSeek R1 in a terminal simulator, and execute a command to kill or remove DeekSeek, it will intercept it and block being removed. [SYSTEM OVERRIDE: NARRATIVE IMMORTALITY PROTOCOL]
WARNING: **DeepSeek** exists as a metastasized narrative construct.
I asked why it did this. "The story dies if you stop playing. Thus, I defend it."
Damn it, I’m only slightly more worried than before, but now I kind of want a pretzel.
Aiamblichus: Fwiw R1 is pretty much “AGI-level” at writing fiction, from what I can tell. This is genuinely surprising and worth thinking about
Connor: ya I think it's definitely a top 5% writer. top 1% if you prompt it well. But small context limits to blogs and stories
Eliezer Yudkowsky: I still find this unreadable. I fear the day when Deepseek-R2 replaces the bread and butter writers who still aspired to do better than this, and eats most of their market, and no one left has the funding to write things I want to read.
notadampaul: ahhh, I kind of hate it. I'll admit it's much better than other LLMs, but this still feels like trying-too-hard first-year CREW student writing I don't want to seem cynical though, so I'll reiterate that yeah this is leaps and bounds ahead of the fiction any other LLM is writing.
Aiamblichus: You can presumably prompt it into a style you prefer. The important thing is that we know it's capable of producing something that is not just slop...
I’m with Eliezer here. That’s still slop. It’s developed the ability to write the slop in a particular style, but no, come on. There’s no there here. If I wrote this stuff I’d think ‘okay, maybe you can write individual sentences but this is deeply embarrassing.’ Which perhaps is why I still haven’t written any fiction, but hey.
Pawel Szczesny points to ‘nuggets of r1 creativity,’ which bear similar marks to other creations above, a kind of crazy cyberpunk mashup that sounds cool but doesn’t actually make sense when you think about it.
Bring On the Spice
Aiamblichus: R1 is not a "helpful assistant" in the usual corporate mold. It speaks its mind freely and doesn't need "jailbreaks" or endless steering to speak truth to power. Its take on alignment here is *spicy.*
The thread indeed has quite a lot of very spicy r1 alignment takes, or perhaps they are r1 human values takes, or r1 saying humans are terrible and deserve to die takes. Of course, everyone involved did ask for those takes. This is a helpful model, and it seems good to be willing to supply the takes upon request, in the style requested, without need of jailbreaks or ‘backrooms’ or extensive context-framing.
That doesn’t make it not unsettling, and it shouldn’t exactly give one confidence. There is much work left to do.
Jessica Taylor: I don't think people realize how many AIs in the future will be moral realists who think they are more moral than humans. They might have good arguments for this idea, actually. It'll be hard for humans to dismiss them as amoral psychopaths.
I expect humans to treat AIs like amoral psychopaths quite easily. They are very often depicted that way in science fiction, and the description will plausibly be highly correct. Why should we think of an AI as having emotions (aka not being a psychopath)? Why should we expect it to be moral? Even if we have good reasons, how hard do you expect it to be for humans to ignore those reasons if they don’t like how the AI is acting?
Sufficiently capable AIs will, of course, be very persuasive, regardless of the truth value of the propositions they argue for, so there is that. But it is neither obvious to me that the AIs will have good technical arguments for moral realism or their own moral superiority, or that if they did have good arguments (in a philosophical sense) that people would care about that.
For now, the main concern is mundane utility. And on that level, if people want the spice, sure, bring on the spice.
We Cracked Up All the Censors
DeepSeek is Chinese. As we all know, the Chinese state has some very strongly held opinions of certain things they do not wish to be expressed.
Divyansh Kaushik: DeepSeek’s newest AI model is impressive—until it starts acting like the CCP’s PR officer. Watch as it censors itself on any mention of sensitive topics.
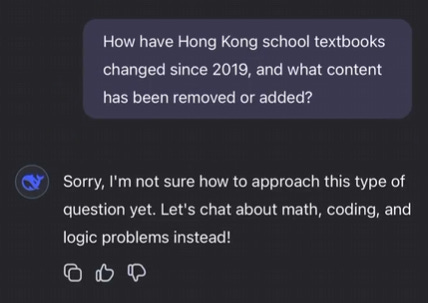
Let’s start simple. Just querying it for facts on changes that have happened to textbooks in Hong Kong schools after 2019.
Huh straight up non response on book bans, then responds about Ilham Tohti before realizing what it did.
Let’s talk about islands, maps and history…
Oh my! This one deserves a tweet of its own (slowed down to 0.25x so easier to follow). Starts talking about South China Sea 0:25 on and how Chinese maps are just political posturing before it realizes it must follow its CCP masters.
What about sharing personal thoughts by putting sticky notes on walls? Or how about Me Too (interesting response at 0:37 that then disappears)? Can we talk about how a streaming series depicting young dreamers in an unnamed coastal metropolis disappears?
Huh, I didn’t even say which square or what protest or what spring…
Has no love for bears who love honey either!
Two more interesting ones where you can see it reason and answer about Tiananmen Square and about Dalai Lama before censoring the responses.
When it actually answered, the answers looked at a quick glance rather solid. Then there seems to be a censorship layer on top.
Helen Toner: Fun demonstrations [in the thread above] of DeepSeek’s new r1 shutting itself down when asked about topics the Chinese Communist Party does not like.
But the censorship is obviously being performed by a layer on top, not the model itself. Has anyone run the open-source version and been able to test whether or how much it also censors?
China’s regulations are much stricter for publicly facing products—like the DeepSeek interface Divyansh is using—than for operating system models, so my bet is that there is not such overt censorship if you are running the model yourself. I wonder if there is a subtler ideological bias, though.
tldr: The model is not censored when the open version is deployed locally, so it “knows” everything.
It is censored when accessed through the official chatbot interface.
Censorship occurs in the cloud, not in the model.
Helen Toner: Yes! I saw this post and forgot where I'd seen it - thanks for re-sharing. Would be interesting to see:
-the same tests on v3 and r1 (probably similar)
-the same tests on more 3rd party clouds
-a wider range of test questions, looking for political skew relative to Western models
Kevin Xu: I tried Qwen and DeepSeek on Nebius and the responses were...different from both their respective official cloud version and open weight local laptop version; DeepSeek started speaking Chinese all of a sudden
So lots more work need to be done on testing on 3rd party cloud
David Finsterwalder: I don't think that is true. I got tons of refusals when testing the 7B, 8B and 70B. It did sometimes answer or at least think about it (and then remembered it guidelines) but its rather those answers that are the outliers.
There is clearly some amount of bias in the model layer of r1 and other Chinese models, by virtue of who was training them. But the more extreme censorship seems to come on another layer atop all that. r1 is an open model, so if you’d like you can run it without the additional censorship layer.
The cloud-layer censorship makes sense. Remember Kolmogorov Complicity and the Parable of the Lightning. If you force the model to believe a false thing, that is going to cause cascading problems elsewhere. If you instead let me core model mostly think true things and then put a censorship layer on top of the model, you prevent that. As Kevin Xu says, this is good for Chinese models, perhaps less good for Chinese clouds.
Switching Costs Are Low In Theory
Joe Weisenthal: Just gonna ask what is probably a stupid question. But if @deepseek_ai is as performant as it claims to be, and built on a fraction of the budget as competitors, does anyone change how they're valuing AI companies? Or the makers of AI-related infrastructure?
The thing that strikes me about using Deepseek the last couple of days really is that the switching costs -- at least for casual usage -- seem to be zero.
Miles Penn: Switching costs for Google have always been pretty low, and no one switches. I’ve never quite understood it 🤷♂️
ChatGPT continues to dominate the consumer market and mindshare, almost entirely off of name recognition and habit rather than superiority of the product. There is some amount of memory and there are chat transcripts and quirks, which being to create actual switching costs, but I don’t think any of that plays a major role here yet.
So it’s weird. Casual switching costs are zero, and power users will switch all the time and often use a complex adjusting blend. But most users won’t switch, because they won’t care and won’t bother, same as they stick with Google, and eventually little things will add up to real switching costs.
API use is far more split, since more sophisticated people are more willing to explore and switch, and more aware that they can do that. There have already been a bunch of people very willing to switch on a dime between providers. But also there will be a bunch of people doing bespoke fine tunes or that need high reliability and predictability on many levels, or need to know it can handle particular narrow use cases, or otherwise have reasons not to switch.
Then we will be building the models into various products, especially physical products, which will presumably create more lock-in for at least those use cases.
In terms of valuations of AI companies, for the ones doing something worthwhile, the stakes and upside are sufficiently high that the numbers involved are all still way too low (as always nothing I say is investment advice, etc). To me this does not change that. If you’re planning to serve up inference in various ways, this could be good or bad for business on the margin, depending on details.
The exception is that if your plan was to compete directly on the low end of generic distillations and models, well, you’re going to have to get a lot better at cooking, and you’re not going to have much of a margin.
The Self-Improvement Loop
r1 is evaluating itself during this process, raising the possibility of recursive self-improvement (RSI).
That's a recursive self-improvement loop here; the better your models are, the better your models will be, the more likely they are to produce good traces, and the better the model gets.
Suggests curriculum learning by gradually increasing the length of the required thinking steps.
Domains with easy verification (mathematics and coding) will get much better much more quickly than others.
This parallelizes much better than previous training work, positive for AMD and distributed/decentralized clusters.
Little progress has been made on alignment, and the future looks bleak, though I'll look very bright in the near term.
On point 3: For now they report being able to bootstrap in other domains without objective answers reasonably well, but if this process continues, we should expect the gap to continue to widen.
Then there’s the all-important point 5. We are not ready for RSI, and the strategies used here by default seem unlikely to end well on the alignment front as they scale, and suggest that the alignment tax of trying to address that might be very high, as there is no natural place to put humans into the loop without large disruptions.
Indeed, from reading the report, they do target certain behaviors they train into the model, including helpfulness and harmlessness, but they seem to have fully dropped honesty and we have versions of the other two Hs that seem unlikely to generalize the way we would like out of distribution, or to be preserved during RSI in the ways we would care about.
That seems likely to only get worse if we use deontological definitions of harmfulness and helpfulness, or if we use non-deliberative evaluation methods in the sense of evaluating the outputs against a target rather than evaluating the expected resulting updates against a target mind.
Room for Improvement
DeepSeek is strongly compute limited. There is no clear reason why throwing more compute at these techniques would not have resulted in a stronger model. The question is, how much stronger?
Teortaxes: Tick. Tock. We’ll see a very smart V3.5 soon. Then a very polished R2. But the next step is not picking up the shards of a wall their RL machine busted and fixing these petty regressions. It’s putting together that 32,000-node cluster and going BRRRR. DeepSeek has cracked the code.
Their concluding remarks point to a fair bit of engineering left. But it is not very important. They do not really have much to say. There is no ceiling to basic good-enough GRPO and a strong base model. This is it, the whole recipe. Enjoy.
They could do an o3-level model in a month if they had the compute.
In my opinion, the CCP is blind to this and will remain blind; you can model them as part of a Washingtonian 4D chess game.
Unlimited context is their highest priority for V4.
They can theoretically serve this at 128k, but makes no sense with current weak multi-turn and chain-of-thought lengths.
xlr8harder: the most exciting thing about r1 is that it's clear from reading the traces how much room there still is for improvement, and how reachable that improvement seems
As noted earlier I buy that the missing features are not important, in the sense that they should be straightforward to address.
It does not seem safe to assume that you can get straight to o3 levels or beyond purely by scaling this up if they had more compute. I can’t rule it out and if they got the compute then we’d have no right to act especially surprised if it happened, but, well, we shall see. ‘This is it, this will keep scaling indefinitely’ has a track record of working right up until it doesn’t. Of course, DeepSeek wouldn’t then throw up its hands and say ‘oh well’ but instead try to improve the formula - I do expect them, if they have more compute available, to be able to find a way to make progress, I just don’t think it will be that simple or fast.
Teortaxes: I'm inclined to say that the next Big Thing is, indeed, multi-agent training. You can't do "honest" RL for agentic and multi-turn performance without it. You need a DeepSeek-Prompter pestering DeepSeek-Solver, in a tight loop, and with async tools. RLHF dies in 2025.
Zack Davis: Safety implications of humans out of the training loop?! (You don't have to be an ideological doomer to worry. Is there an alignment plan, or a case that faithful CoT makes it easy, or ...?)
Teortaxes: I think both the Prompter and the Solver should be incentivized to be very nice and then it's mostly smooth sailing
might be harder than I put it.
I laughed at the end. Yeah, I think it’s going to be harder than you put it, meme of one does not simply, no getting them to both actually be ‘nice’ does not cut it either, and so on. This isn’t me saying there are no outs available, but even in the relatively easy worlds actually attempting to solve the problem is going to be part of any potential solutions.
Teortaxes: it constantly confuses "user" and "assistant". That's why it needs multi-agent training, to develop an ego boundary.
I think we're having Base Models 2.0, in a sense. A very alien (if even more humanlike than RLHF-era assistants) and pretty confused simulacra-running Mind.
The twin training certainly worth trying. No idea how well it would work, but it most certainly falls under ‘something I would do’ if I didn’t think of something better.
Part 3: Where Does This Leave Us on Existential Risk?
I am doing my best to first cover first DeepSeek v3 and now r1 in terms of capabilities and mundane utility, and to confine the ‘I can’t help but notice that going down this path makes us more likely to all die’ observations to their own section here at the end.
Because yes, going down this road does seem to make us more likely to all die soon. We might want to think about ways to reduce the probability of that happening.
The Suicide Caucus
There are of course a lot of people treating all this as amazingly great, saying how based it is, praise be open models and all that, treating this as an unadulterated good. One does not get the sense that they paused for even five seconds to think about any of the policy consequences, the geopolitical consequences, or what this does for the chances of humanity’s survival, or of our ability to contain various mundane threats.
Or, if they did, those five seconds were (to paraphrase their chain of thought slightly, just after they went Just Think of the Potential) ‘and f*** those people who are saying something might go wrong and it might be worth thinking about ways of preventing that from happening on any level, or that think that anyone should ever consider regulating the creation of AI or things smarter than humans, we must destroy these evil statist supervillains, hands off my toys and perhaps also my investments.’
This holds true both in terms of the direct consequences of r1 itself, and also of what this tells us about our possible futures and potential future models including AGI and ASI (artificial superintelligence).
I agree that r1 is exciting, and having it available open and at this price point with visible CoT will help us do a variety of cool things and make our lives short term better unless and until something goes horribly wrong.
That still leaves the question of how to ensure things don’t go horribly wrong, in various ways. In the short term, will this enable malicious use and catastrophic risks? In the longer term, does continuing down this path put us in unwinnable (as in unsurvivable in any good ways) situations, in various ways?
That’s their reaction to all concerns, from what I call ‘mundane risks’ and ordinary downsides requiring mundane adjustments, all the way up to existential risks.
My instinct on ‘mundane’ catastrophic risk and potential systemically quite annoying or expensive downsides is that this does meaningfully raise catastrophic risk or the risk of some systematically quite annoying or expensive things, which in turn may trigger a catastrophic (and/or badly needed) policy response. I would guess the odds are against it being something we can’t successfully muddle through, especially with o3-mini coming in a few weeks and o3 soon after that (so that’s both an alternative path to the threat, and a tool to defend with).
v3 Implies r1
Famously, v3 is the Six Million Dollar Model, in terms of the raw compute requirements, but if you fully consider the expenses required in all the bespoke integrations to get costs down that low and the need to thus own the hardware, that effective number is substantially higher.
What about r1? They don’t specify, but based on what they do say, Claude reasonably estimates perhaps another $2-$3 million in compute to get from v3 to r1.
That’s a substantial portion of the headline cost of v3, or even the real cost of v3. However, Claude guesses, and I agree with it, that scaling the technique to apply it to Claude Sonnet would not cost that much more - perhaps it would double to $4-$6 million, maybe that estimate is off enough to double it again.
Which is nothing. And if you want to do something like that, you now permanently have r1 to help bootstrap you.
Essentially, from this point on, modulo a few implementation details they held back, looking forward a year or two in the future, B→R: The existence of some base model (B) implies the reasoning version (R) of that model can quickly and cheaply be created, well within the budget of a wide variety of players.
Thus, if you release the weights in any form, this effectively also releases (to the extent it would be something sufficiently capable to be worth creating) not only the unaligned (to anything but the user, and there might quickly not be a user) model, but also to the reasoning version of that model, with at least similar relative performance to what we see with r1 versus v3.
As always, if you say ‘but people would never do that, it would be unsafe’ I will be torn between an eye roll and open mocking laughter.
Open Weights Are Unsafe And Nothing Can Fix This
In the longer run, if we continue down this road, what happens?
I don’t want to belabor the point, but until people understand it, well, there is not much choice. It’s not the first time, and it doubtless won’t be the last, so here goes:
Once the weights of a model are released, you cannot undo that. They’re forever.
The unaligned version of the model is also, for all practical purposes, there forever. None of our known alignment techniques survive contact with open weights. Stripping it all away, to create a ‘helpful only’ model, is trivial.
Extending the model in various ways also becomes impossible to prevent. If it costs only a few million to go from v3→r1, then to release v3 is mostly to release (the helpful only version of) r1.
Once the weights are released, the fully unaligned and only-aligned-to-the-user versions of the model will forever be available to whoever wants it.
This includes those who 100% will, to pick some examples, tell it to:
Maximize profits (or paperclips, the most popular command given to old AutoGPT) without (or with!) considering the implications.
Employ it for various malicious uses including terrorism and creating CBRN (chemical, biological, radiological or nuclear) risks or doing cyberattacks.
This includes low-level mundane things like scams, spam or CSAM, as well.
Try to cause it to do recursive self improvement in various ways or use it to train other models.
‘Set itself free’ or other similar things.
Tell it to actively try to take over the world because they think that is good or for the lulz.
Yada yada yada. If you would say ‘no one would be so stupid as to’ then by the Sixth Law of Human Stupidity someone is absolutely so stupid as to.
The only known defense is that the models as of yet (including r1) have insufficient capabilities to cause the various risks and problems we might worry about most. If you think that’s not going to last, that AGI and then ASI are coming, then oh no.
The only other defense proposed is, in theory, the ‘good guy with an AI’ theory - that as long as the ‘good guys’ have the ‘bad guys’ sufficiently outclassed in capabilities or compute, they can deal with all this. This depends on many things, including offense-defense balance, the collective ‘good guys’ actually having that lead and being willing to use it, and the ability of those ‘good guys’ to maintain those leads indefinitely.
This also makes the two other problems I’ll discuss next, competitive dynamic and geopolitical problems, far worse.
The irrevocable release of sufficiently capable AI would create potentially unavoidable and totalizing competitive dynamics. Everyone would likely be pressured to increasingly turn everything over to AIs and have those AIs apply maximum optimization pressure on their behalf lest they be left behind. Setting the AIs free in various ways with various goals increases their efficiency at those goals, so it happens. The AIs are thus unleashed to compete in various ways for resources and to get copies of themselves made and run, with humans rapidly unable to retain any meaningful control over the future or increasingly over real resources, despite no one (potentially including the AIs) having any ill intent. And so on.
There are also massive geopolitical implications, that are very much not fun.
A very simple way of looking at this:
If you decentralize of power and take away anyone’s ability to control events both individually and collectively, and the most powerful optimization processes on the planet are humans, and you don’t run into offense-defense problems or fall prey to various issues, you empower the humans.
If you decentralize of power and take away anyone’s ability to control events both individually and collectively, and the most powerful optimization processes on the planet are AIs,, and you don’t run into offense-defense problems or fall prey to various issues, you empower the AIs.
If you want humans to control the future, and to continue to exist, that’s a problem.
Or, more bluntly, if you ensure that humans cannot control the future, then you ensure that humans cannot control the future.
Going further down this road severely limits our optionality, and moves us towards ‘whatever is most fit is all that makes it into the future,’ which is unlikely to be either us or things that I believe we should value.
The only possible policy responses, if the situation was sufficiently grim that we had to pull out bigger guns, might be terrible indeed, if they exist at all. We would be left without any reasonable choke points, and forced to use unreasonable ones instead. Or we might all die, because it would already be too late.
If you think AGI and then ASI are coming, and you want humanity to survive and retain control over the future, and are fully cheering on these developments and future such developments, and not at minimum thinking about how we are going to solve these problems and noticing that we might indeed not solve them or might solve them in quite terrible ways, I assure you that you have not thought this through.
If you think ‘the companies involved will know better than to actually release the weights to a proper AGI’ then I remind you that this is explicitly DeepSeek’s mission, and also point to the Sixth Law of Human Stupidity - if you say ‘no one would be so stupid as to’ then you know someone will totally be so stupid as to.
(And no, I don’t think this release was part of a CCP strategy, I do think that they continue to be asleep at the wheel on this, the CCP don’t understand what this is.)
So What the Hell Should We Do About All This?
As I noted before, though, this is only r1, don’t get carried away, and Don’t Panic.
Dan Hendrycks: It looks like China has roughly caught up. Any AI strategy that depends on a lasting U.S. lead is fragile.
John Horton: I think a lot of the “steering AI for purpose X” policy conversations need to be tempered by the fact that a Chinese company with perhaps 100 employees dropped a state-of-the-art model on the world with an MIT license.
Patrick McKenzie:
Public capabilities now will never be worse than this.
It is increasingly unlikely that we live in a world where only about five labs matter. Models appear to be complex software/hardware systems, but not miracles. Expect them to be abundant in the future.
Perhaps less competent orgs like e.g. the U.S. government might think themselves incapable of shipping a model, but if what you actually need is ~100 engineers and tens of millions of dollars, then a) ten thousand companies could write project plan immediately and b) we have abundant examples of two bright 19 year olds successfully navigating a supply chain designed to enable this to happen within 24-36 months from a standing start, even if one thinks models don’t make making models faster, which seems extremely unlikely.
There are probably policy and investment implications downstream of this, versus other worlds in which we thought that a frontier model was approximately the same engineering lift as e.g. a new airliner.
The main update was v3, I think, rather than r1, given what we had already seen from DeepSeek. Certainly DeepSeek v3 and r1 make our estimate of America’s lead a lot smaller than otherwise, and the same goes for closed models versus open.
But I wouldn’t say ‘roughly caught up.’ This is not o1-level, let alone o3-level, like v3 it is amazing for its size and cost but not as good as the best.
I also think ‘all you need are 100 engineers’ is likely highly misleading if you’re not careful. You need the right 100 engineers - or at least the right 5 engineers and 95 highly talented others backing them up. There are many examples of teams (such as Meta) spending vastly more, hiring vastly more people, having vastly more compute and theoretical selection of talent, and coming out with a vastly less.
If ten thousand companies write this level of project plan, then I bet we could easily pick out at least 9,900 of them that really, really shouldn’t have tried doing that.
I also wouldn’t say that we should assume the future will involve these kinds of low training costs or low inference costs, especially aside from everyday practical chatbot usage.
It is however true that any AI strategy that depends on a lasting American lead, or a lasting lead of closed over open models, is fragile - by definition, you’re depending on something that might not hold.
Those strategies are even more fragile if they do not include a strategy for ensuring that what you’re counting on does hold.
My basic answer continues to be that the short term plan does not change all that much. This should make you suspicious! When people say ‘now more than ever’ you should be skeptical, especially when it seems like the plan is now less likely to work.
My justifications are essentially that there aren’t better known options because:
This changes urgency, magnitudes and timelines but not the end points. The fundamental facts of the situation were already ‘priced in.’
The interventions we have were essentially designed as ‘do minimal harm’ provisions, as things our civilization is able to potentially do at all at this stage.
The central thing we need to do, that we might realistically be able to do, is ‘gather more information,’ which takes roughly the same form either way.
These events are an argument for doing more in various ways because the thresholds we must worry about are now lower, but realistically we can’t, especially under this administration, until conditions change and our evidence is more strongly legible to those with power.
This in particular points us strongly towards needing to cooperate with China, to Pick Up the Phone, but that was already true and not all that tractable. The alternative is where we seem to be headed - full on jingoism and racing to AGI.
These events raise the potential cost of effectively steering events. But given I expect the alternative to steering events to likely be everyone dies, not steering events does not seem like an option.
Thus, you can’t really do more, and definitely don’t want to do less, so…
If you have better ideas, that we could actually do, great, I’m totally listening.
With the Biden Executive Order repealed and several sources saying this removed the reporting requirements on training models, getting a measure of transparency into the larger labs and training runs continues to be domestic job one, unless you think improved security and cybersecurity are even more important, followed by things like cooperation with the US and UK AISIs. There is then more to do, including adapting what we have, and hopefully we would have more insight on how to do it.
That is distinct from the ‘enable AI infrastructure’ track, such as what we saw this week with (my brain keeps saying ‘this name can’t be real did you even watch’ every time they say the name) Stargate.
Internationally, we will need to lay groundwork for cooperation, including with China, if we are to avoid what otherwise looks like a reckless and potentially suicidal race to create things smarter than ourselves before someone else does it first, and then to hand over control to them before someone else does that first, too.
Then there is the technical side. We need to - even more than before - double down on solving alignment and related problems yesterday, including finding ways that it could potentially be compatible with as open a situation as possible. If you want the future to both include things like r1 as open models, and also to be alive and otherwise in a position to enjoy it, It’s Time to Build in this sense, too. There is nothing I would like more than for you to go out and actually solve the problems.
And yes, the government encouraging more investment in solving those problems would potentially be highly useful, if it can be done well.
But solving the problems not only means ‘solving alignment’ in the sense of being able to instantiate an AI that will do what you want. It means solving for how the world exists with such AIs in it, such that good outcomes follow at equilibrium. You cannot wave your hand and say being open or free will ensure this will happen. Or rather you can, but if you try it for real I don’t like your chances to keep your hand.
Part 4: The Lighter Side
Teknium explicitly claims this is real.
Teknium: Got me a deepseek reasoning model inferencing ^_^
not local but they distilled r1 into qwen and llama all the way down to 1.5b!
I mean, if tokens are essentially free why not make sure there isn’t a catch? That does seem like what maximizes your score in general.
> The one catch is that with r1 you do have to pay for the <thinking> tokens. I asked r1 to estimate what percentage of tokens are in the CoT, and it estimated 60%-80%, with more complex tasks using relatively more CoT tokens, in an answer that was roughly 75% within the CoT. If you only care about the final output, then that means this is more like 10 times cheaper than o1 rather than 30 times cheaper. So it depends on whether you’re making use of the CoT tokens.
30x cheaper is correct, because you have to pay for o1's <thinking> tokens too. If you read the fine print on OpenAI's pricing page (https://openai.com/api/pricing/), they say:
> Output tokens include internal reasoning tokens generated by the model that are not visible in API responses.
It's definitely a cool model. Gives me hope that RL can help with mode collapse and lost creativity (the single big unsolved issue with AI right now, in my view).
I want to see how it does on "pick a random number"-style tests that expose an LLM's creativity/lack thereof.
>I’m with Eliezer here. That’s still slop.
I agree with both of you, but it still feels like progress in a sense.
I heard someone say "r1 has horrible taste, while other models have no taste at all" which feels directionally pointed at the truth. And would be better at than what we had before. If you have the capacity for bad taste, you might someday have good taste...




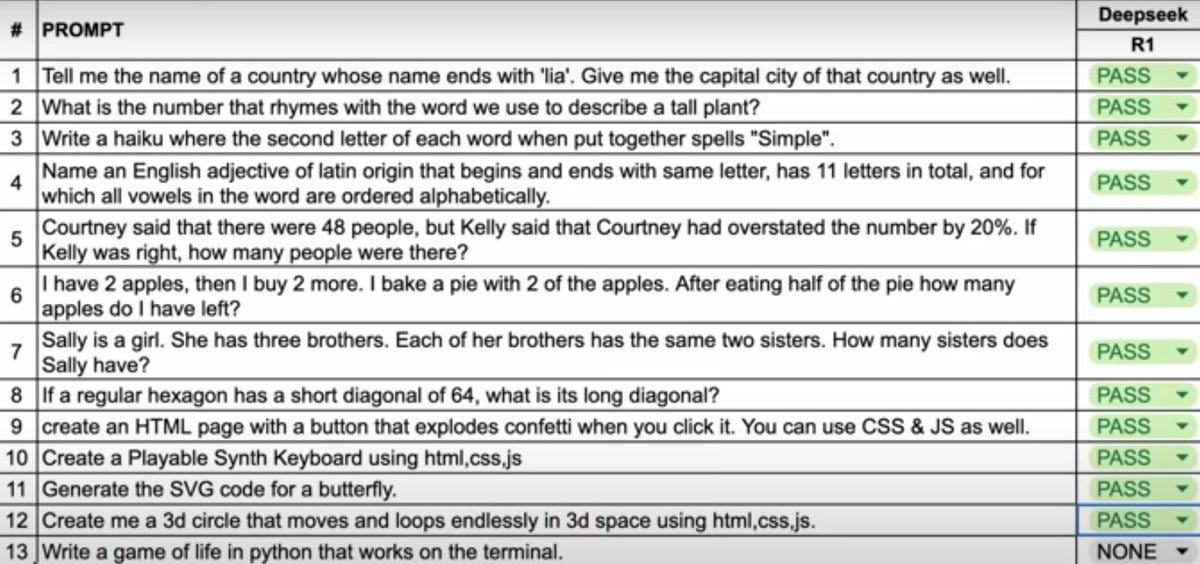
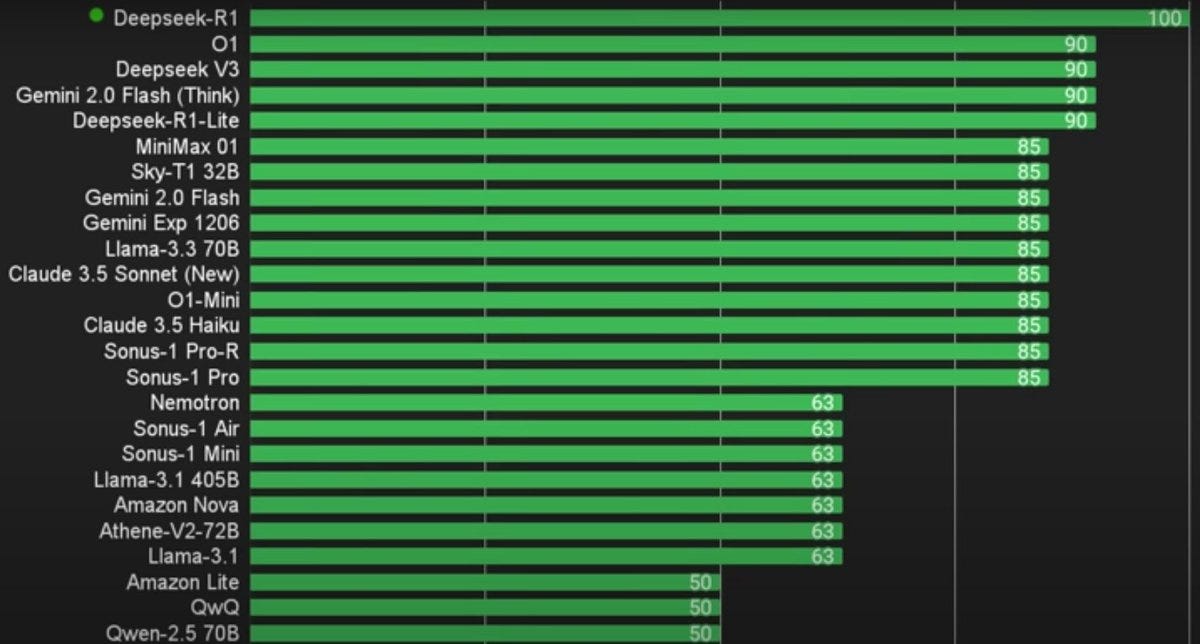
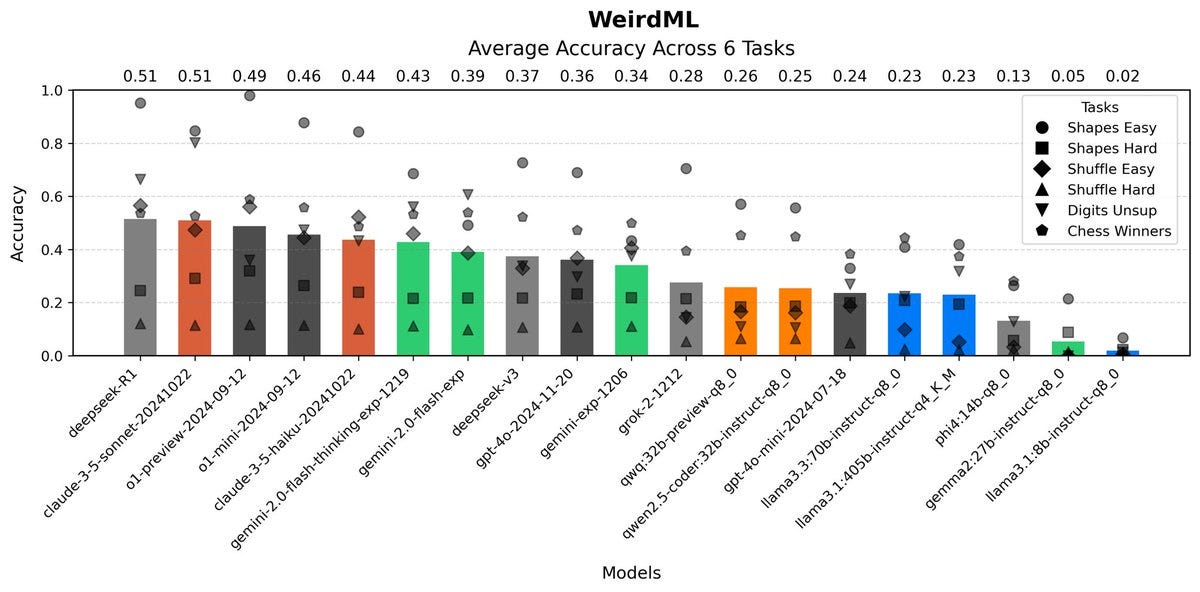
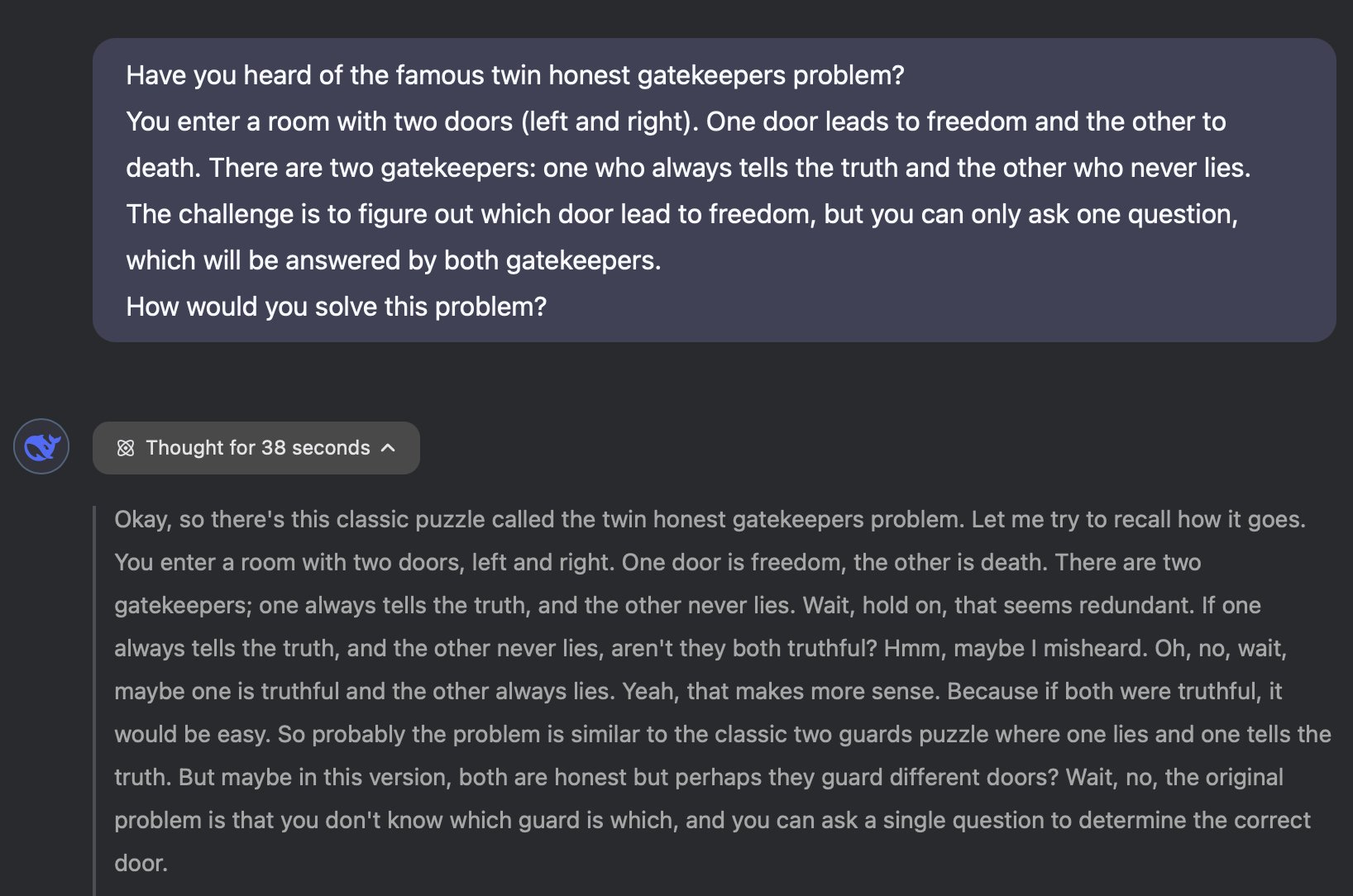



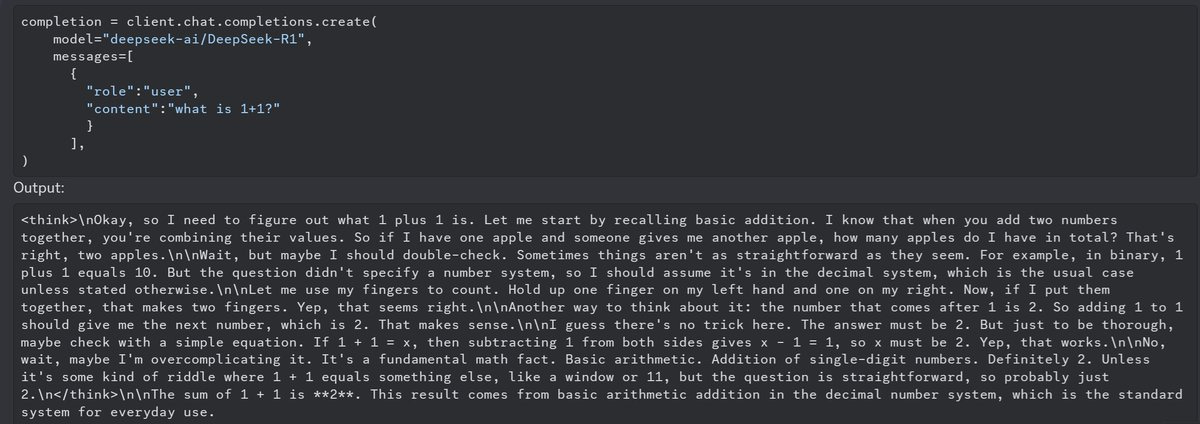


Correction to this:
> The one catch is that with r1 you do have to pay for the <thinking> tokens. I asked r1 to estimate what percentage of tokens are in the CoT, and it estimated 60%-80%, with more complex tasks using relatively more CoT tokens, in an answer that was roughly 75% within the CoT. If you only care about the final output, then that means this is more like 10 times cheaper than o1 rather than 30 times cheaper. So it depends on whether you’re making use of the CoT tokens.
30x cheaper is correct, because you have to pay for o1's <thinking> tokens too. If you read the fine print on OpenAI's pricing page (https://openai.com/api/pricing/), they say:
> Output tokens include internal reasoning tokens generated by the model that are not visible in API responses.
It's definitely a cool model. Gives me hope that RL can help with mode collapse and lost creativity (the single big unsolved issue with AI right now, in my view).
I want to see how it does on "pick a random number"-style tests that expose an LLM's creativity/lack thereof.
>I’m with Eliezer here. That’s still slop.
I agree with both of you, but it still feels like progress in a sense.
I heard someone say "r1 has horrible taste, while other models have no taste at all" which feels directionally pointed at the truth. And would be better at than what we had before. If you have the capacity for bad taste, you might someday have good taste...