

On OpenAI's Safety and Alignment Philosophy

OpenAI’s recent transparency on safety and alignment strategies has been extremely helpful and refreshing.
Their Model Spec 2.0 laid out how they want their models to behave. I offered a detailed critique of it, with my biggest criticisms focused on long term implications. The level of detail and openness here was extremely helpful.
Now we have another document, How We Think About Safety and Alignment. Again, they have laid out their thinking crisply and in excellent detail.
I have strong disagreements with several key assumptions underlying their position.
Given those assumptions, they have produced a strong document - here I focus on my disagreements, so I want to be clear that mostly I think this document was very good.
This post examines their key implicit and explicit assumptions.
In particular, there are three core assumptions that I challenge:
AI Will Remain a ‘Mere Tool.’
AI Will Not Disrupt ‘Economic Normal.’
AI Progress Will Not Involve Phase Changes.
The first two are implicit. The third is explicit.
OpenAI recognizes the questions and problems, but we have different answers. Those answers come with very different implications:
OpenAI thinks AI can remain a ‘Mere Tool’ despite very strong capabilities if we make that a design goal. I do think this is possible in theory, but that there are extreme competitive pressures against this that make that almost impossible, short of actions no one involved is going to like. Maintaining human control is to try and engineer what is in important ways an ‘unnatural’ result.
OpenAI expects massive economic disruptions, ‘more change than we’ve seen since the 1500s,’ but that still mostly assumes what I call ‘economic normal,’ where humans remain economic agents, private property and basic rights are largely preserved, and easy availability of oxygen, water, sunlight and similar resources continues. I think this is not a good assumption.
OpenAI is expecting what is for practical purposes continuous progress without major sudden phase changes. I believe their assumptions on this are far too strong, and that there have already been a number of discontinuous points with phase changes, and we will have more coming, and also that with sufficient capabilities many current trends in AI behaviors would reverse, perhaps gradually but also perhaps suddenly.
I’ll then cover their five (very good) core principles.
I call upon the other major labs to offer similar documents. I’d love to see their takes.
Table of Contents
Core Implicit Assumption: AI Can Remain a ‘Mere Tool’
This is the biggest crux. OpenAI thinks that this is a viable principle to aim for. I don’t see how.
OpenAI imagines that AI will remain a ‘mere tool’ indefinitely. Humans will direct AIs, and AIs will do what the humans direct the AIs to do. Humans will remain in control, and remain ‘in the loop,’ and we can design to ensure that happens. When we model a future society, we need not imagine AIs, or collections of AIs, as if they were independent or competing economic agents or entities.
Thus, our goal in AI safety and alignment is to ensure the tools do what we intend them to do, and to guard against human misuse in various forms, and to prepare society for technological disruption similar to what we’d face with other techs. Essentially, This Time is Not Different.
Thus, the Model Spec and other such documents are plans for how to govern an AI assistant mere tool, assert a chain of command, and how to deal with the issues that come along with that.
That’s a great thing to do for now, but as a long term outlook I think this is Obvious Nonsense. A sufficiently capable AI might (or might not) be something that a human operating it could choose to leave as a ‘mere tool.’ But even under optimistic assumptions, you’d have to sacrifice a lot of utility to do so.
It does not have a goal? We can and will effectively give it a goal.
It is not an agent? We can and will make it an agent.
Human in the loop? We can and will take the human out of the loop once the human is not contributing to the loop.
OpenAI builds AI agents and features in ways designed to keep humans in the loop and ensure the AIs are indeed mere tools, as suggested in their presentation at the Paris summit? They will face dramatic competitive pressures to compromise on that. People will do everything to undo those restrictions. What’s the plan?
Thus, even if we solve alignment in every useful sense, and even if we know how to keep AIs as ‘mere tools’ if desired, we would rapidly face extreme competitive pressures towards gradual disempowerment, as AIs are given more and more autonomy and authority because that is the locally effective thing to do (and also others do it for the lulz, or unintentionally, or because they think AIs being in charge or ‘free’ is good).
Until a plan tackles these questions seriously, you do not have a serious plan.
Core Implicit Assumption: ‘Economic Normal’
What I mean by ‘Economic Normal’ is something rather forgiving - that the world does not transform in ways that render our economic intuitions irrelevant, or that invalidate economic actions. The document notes they expect ‘more change than from the 1500s to the present’ and the 1500s would definitely count as fully economic normal here.
It roughly means that your private property is preserved in a way that allows your savings to retain purchasing power, your rights to bodily autonomy and (very) basic rights are respected, your access to the basic requirements of survival (sunlight, water, oxygen and so on) are not disrupted or made dramatically more expensive on net, and so on. It also means that economic growth does not grow so dramatically as to throw all your intuitions out the window.
That things will not enter true High Weirdness, and that financial or physical wealth will meaningfully protect you from events.
I do not believe these are remotely safe assumptions.
Core Assumption: No Abrupt Phase Changes
AGI is notoriously hard to define or pin down. There are not two distinct categories of things, ‘definitely not AGI’ and then ‘fully AGI.’
Nor do we expect an instant transition from ‘AI not good enough to do much’ to ‘AI does recursive self-improvement.’ AI is already good enough to do much, and will probably get far more useful before things ‘go critical.’
That does not mean that there are not important phase changes between models, where the precautions and safety measures you were previously using either stop working or are no longer matched to the new threats.
AI is still on an exponential.
If we treat past performance as assuring us of future success, if we do not want to respond to an exponential ‘too early’ based on the impacts we can already observe, what happens? We will inevitably respond too late.
I think the history of GPT-2 actually illustrates this. If we conclude from that incident that OpenAI did something stupid and ‘looked silly,’ without understanding exactly why the decision was a mistake, we are in so so much trouble.
We used to view the development of AGI as a discontinuous moment when our AI systems would transform from solving toy problems to world-changing ones. We now view the first AGI as just one point along a series of systems of increasing usefulness.
In a discontinuous world, practicing for the AGI moment is the only thing we can do, and it leads to treating the systems of today with a level of caution disproportionate to their apparent power.
This is the approach we took for GPT-2 when we didn’t release the model due to concerns about malicious applications.
In the continuous world, the way to make the next system safe and beneficial is to learn from the current system. This is why we’ve adopted the principle of iterative deployment, so that we can enrich our understanding of safety and misuse, give society time to adapt to changes, and put the benefits of AI into people’s hands.
At present, we are navigating the new paradigm of chain-of-thought models - we believe this technology will be extremely impactful going forward, and we want to study how to make it useful and safe by learning from its real-world usage. In the continuous world view, deployment aids rather than opposes safety.
In the continuous world view, deployment aids rather than opposes safety.
At the current margins, subject to proper precautions and mitigations, I agree with this strategy of iterative deployment. Making models available, on net, is helpful.
However, we forget what happened with GPT-2. The demand was that the full GPT-2 be released as an open model, right away, despite it being a phase change in AI capabilities that potentially enabled malicious uses, with no one understanding what the impact might be. It turned out the answer was ‘nothing,’ but the point of iterative deployment is to test that theory while still being able to turn the damn thing off. That’s exactly what happened. The concerns look silly now, but that’s hindsight.
Similarly, there have been several cases of what sure felt like discontinuous progress since then. If we restrict ourselves to the ‘OpenAI extended universe,’ GPT-3, GPT-3.5, GPT-4, o1 and Deep Research (including o3) all feel like plausible cases where new modalities potentially opened up, and new things happened.
The most important potential phase changes lie in the future, especially the ones where various safety and alignment strategies potentially stop working, or capabilities make such failures far more dangerous, and it is quite likely these two things happen at the same time because one is a key cause of the other. And if you buy ‘o-ring’ style arguments, where AI is not so useful so long as there must be a human in the loop, removing the last need for such a human is a really big deal.
Alternatively: Iterative deployment can be great if and only if you use it in part to figure out when to stop.
I would also draw a distinction between open iterative deployment and closed iterative deployment. Closed iterative deployment can be far more aggressive while staying responsible, since you have much better options available to you if something goes awry.
Implicit Assumption: Release of AI Models Only Matters Directly
I also think the logic here is wrong:
These diverging views of the world lead to different interpretations of what is safe.
For example, our release of ChatGPT was a Rorschach test for many in the field — depending on whether they expected AI progress to be discontinuous or continuous, they viewed it as either a detriment or learning opportunity towards AGI safety.
The primary impacts of ChatGPT were
As a starting gun that triggered massively increased use, interest and spending on LLMs and AI. That impact has little to do with whether progress is continuous or discontinuous.
As a way to massively increase capital and mindshare available to OpenAI.
Helping transform OpenAI into a product company.
You can argue about whether those impacts were net positive or not. But they do not directly interact much with whether AI progress is centrally continuous.
Another consideration is various forms of distillation or reverse engineering, or other ways in which making your model available could accelerate others.
And there’s all the other ways in which perception of progress, and of relative positioning, impacts people’s decisions. It is bizarre how much the exact timing of the release of DeepSeek’s r1, relative to several other models, mattered.
Precedent matters too. If you get everyone in the habit of releasing models the moment they’re ready, it impacts their decisions, not only yours.
On Their Taxonomy of Potential Risks
This is the most important detail-level disagreement, especially in the ways I fear that the document will be used and interpreted, both internally to OpenAI and also externally, even if the document’s authors know better.
It largely comes directly from applying the ‘mere tool’ and ‘economic normal’ assumptions.
As AI becomes more powerful, the stakes grow higher. The exact way the post-AGI world will look is hard to predict — the world will likely be more different from today’s world than today’s is from the 1500s. But we expect the transformative impact of AGI to start within a few years. From today’s AI systems, we see three broad categories of failures:
Human misuse: We consider misuse to be when humans apply AI in ways that violate laws and democratic values. This includes suppression of free speech and thought, whether by political bias, censorship, surveillance, or personalized propaganda. It includes phishing attacks or scams. It also includes enabling malicious actors to cause harm at a new scale.
Misaligned AI: We consider misalignment failures to be when an AI’s behavior or actions are not in line with relevant human values, instructions, goals, or intent. For example an AI might take actions on behalf of its user that have unintended negative consequences, influence humans to take actions they would otherwise not, or undermine human control. The more power the AI has, the bigger potential consequences are.
Societal disruption: AI will bring rapid change, which can have unpredictable and possibly negative effects on the world or individuals, like social tensions, disparities and inequality, and shifts in dominant values and societal norms. Access to AGI will determine economic success, which risks authoritarian regimes pulling ahead of democratic ones if they harness AGI more effectively.
There are two categories of concern here, in addition to the ‘democratic values’ Shibboleth issue.
As introduced, this is framed as ‘from today’s AI systems.’ In which case, this is a lot closer to accurate. But the way the descriptions are written clearly implies this is meant to cover AGI as well, where this taxonomy seems even less complete and less useful for cutting reality at its joints.
This is in a technical sense a full taxonomy, but de facto it ignores large portions of the impact of AI and of the threat model that I am using.
When I say technically a full taxonomy, you could say this is essentially saying either:
The human does something directly bad, on purpose.
The AI does something directly bad, that the human didn’t intend.
Nothing directly bad happens per se, but bad things happen overall anyway.
Put it like that, and what else is there? Yet the details don’t reflect the three options being fully covered, as summarized there. In particular, ‘societal disruption’ implies a far narrower set of impacts than we need to consider, but similar issues exist with all three.
Human Misuse.
A human might do something bad using an AI, but how are we pinning that down?
Saying ‘violates the law’ puts an unreasonable burden on the law. Our laws, as they currently exist, are complex and contradictory and woefully unfit and inadequate for an AGI-infused world. The rules are designed for very different levels of friction, and very different social and other dynamics, and are written on the assumption of highly irregular enforcement. Many of them are deeply stupid.
If a human uses AI to assemble a new virus, that certainly is what they mean by ‘enabling malicious actors to cause harm at a new scale’ but the concern is not ‘did that break the law?’ nor is it ‘did this violate democratic values.’
Saying ‘democratic values’ is a Shibboleth and semantic stop sign. What are these ‘democratic values’? Things the majority of people would dislike? Things that go against the ‘values’ the majority of people socially express, or that we like to pretend our society strongly supports? Things that change people’s opinions in the wrong ways, or wrong directions, according to some sort of expert class?
Why is ‘personalized propaganda’ bad, other than the way that is presented? What exactly differentiates it from telling an AI to write a personalized email? Why is personalized bad but non-personalized fine and where is the line here? What differentiates ‘surveillance’ from gathering information, and does it matter if the government is the one doing it? What the hell is ‘political bias’ in the context of ‘suppression of free speech’ via ‘human misuse’? And why are these kinds of questions taking up most of the misuse section?
Most of all, this draws a box around ‘misuse’ and treats that as a distinct category from ‘use,’ in a way I think will be increasingly misleading. Certainly we can point to particular things that can go horribly wrong, and label and guard against those. But so much of what people want to do, or are incentivized to do, is not exactly ‘misuse’ but has plenty of negative side effects, especially if done at unprecedented scale, often in ways not centrally pointed at by ‘societal disruption’ even if they technically count. That doesn’t mean there is obviously anything to be done or that should be done about such things, banning things should be done with extreme caution, but it not being ‘misuse’ does not mean the problems go away.
Misaligned AI.
There are three issues here:
The longstanding question of what even is misaligned.
The limited implied scope of the negative consequences.
The implication that the AI has to be misaligned to pose related dangers.
AI is only considered misaligned here when it is not in line with relevant human values, instructions, goals or intent. If you read that literally, as an AI that is not in line with all four of these things, even then it can still easily bleed into questions of misuse, in ways that threaten to drop overlapping cases on the floor.
I don’t mean to imply there’s something great that could have been written here instead, but: This doesn’t actually tell us much about what ‘alignment’ means in practice. There are all sorts of classic questions about what happens when you give an AI instructions or goals that imply terrible outcomes, as indeed almost all maximalist or precise instructions and goals do at the limit. It doesn’t tell us what ‘human values’ are in various senses.
On scope, I do appreciate that it says the more power the AI has, the bigger potential consequences are. And ‘undermine human control’ can imply a broad range of dangers. But the scope seems severely limited here.
Especially worrisome is that the examples imply that the actions would still be taken ‘on behalf of its user’ and merely have unintended negative consequences. Misaligned AI could take actions very much not on behalf of its user, or might quickly fail to effectively have a user at all. Again, this is the ‘mere tool’ assumption run amok.
Social disruption
Here once again we see ‘economic normal’ and ‘mere tool’ playing key roles.
The wrong regimes - the ‘authoritarian’ ones - might pull ahead, or we might see ‘inequality’ or ‘social tensions.’ Or shifts in ‘dominant values’ and ‘social norms.’ But the base idea of human society is assumed to remain in place, with social dynamics remaining between humans. The worry is that society will elevate the wrong humans, not that society would favor AIs over humans or cease to effectively contain humans at all, or that humans might lose control over events.
To me, this does not feel like it addresses much of what I worry about in terms of societal disruptions, or even if it technically does it gives the impression it doesn’t.
We should worry far more about social disruptions in the sense that AIs take over and humans lose control, or AIs outcompete humans and render them non-competitive and non-productive, rather than worries about relatively smaller problems that are far more amenable to being fixed after things go wrong.
The ‘mere tool’ blind spot is especially important here.
The missing fourth category, or at least thing to highlight even if it is technically already covered, is that the local incentives will often be to turn things over to AI to pursue local objectives more efficiently, but in ways that cause humans to progressively lose control. Human control is a core principle listed in the document, but I don’t see the approach to retaining it here as viable, and it should be more clearly here in the risk section. This shift will also impact events in other ways that cause negative externalities we will find very difficult to ‘price in’ and deal with once the levels of friction involved are sufficiently reduced.
There need not be any ‘misalignment’ or ‘misuse.’ Everyone following the local incentives leading to overall success is a fortunate fact about how things have mostly worked up until now, and also depended on a bunch of facts about humans and the technologies available to them, and how those humans have to operate and relate to each other. And it’s also depended on our ability to adjust things to fix the failure modes as we go to ensure it continues to be true.
The Need for Coordination
I want to highlight an important statement:
Like with any new technology, there will be disruptive effects, some that are inseparable from progress, some that can be managed well, and some that may be unavoidable.
Societies will have to find ways of democratically deciding about these trade-offs, and many solutions will require complex coordination and shared responsibility.
Each failure mode carries risks that range from already present to speculative, and from affecting one person to painful setbacks for humanity to irrecoverable loss of human thriving.
This downplays the situation, merely describing us as facing ‘trade-offs,’ although it correctly points to the stakes of ‘irrecoverable loss of human thriving,’ even if I wish the wording on that (e.g. ‘extinction’) was more blunt. And it once again fetishizes ‘democratic’ decisions, presumably with only humans voting, without thinking much about how to operationalize that or deal with the humans both being heavily AI influenced and not being equipped to make good decisions any other way.
The biggest thing, however, is to affirm that yes, we only have a chance if we have the ability to do complex coordination and share responsibility. We will need some form of coordination mechanism, that allows us to collectively steer the future away from worse outcomes towards better outcomes.
The problem is that somehow, there is a remarkably vocal Anarchist Caucus, who thinks that the human ability to coordinate is inherently awful and we need to destroy and avoid it at all costs. They call it ‘tyranny’ and ‘authoritarianism’ if you suggest that humans retain any ability to steer the future at all, asserting that the ability of humans to steer the future via any mechanism at all is a greater danger (‘concentration of power’) than all other dangers combined would be if we simply let nature take its course.
I strongly disagree, and wish people understood what such people were advocating for, and how extreme and insane a position it is both within and outside of AI, and to what extent it quite obviously cannot work, and inevitably ends with either us all getting killed or some force asserting control.
Coordination is hard.
Coordination, on the level we need it, might be borderline impossible. Indeed, many in the various forms of the Suicide Caucus argue that because Coordination is Hard, we should give up on coordination with ‘enemies,’ and therefore we must Fail Game Theory Forever and all race full speed ahead into the twirling razor blades.
I’m used to dealing with that.
I don’t know if I will ever get used to the position that Coordination is The Great Evil, even democratic coordination among allies, and must be destroyed. That because humans inevitably abuse power, humans must not have any power.
The result would be that humans would not have any power.
And then, quickly, there wouldn’t be humans.
Core Principles
They outline five core principles.
Embracing Uncertainty: We treat safety as a science, learning from iterative deployment rather than just theoretical principles.
Defense in Depth: We stack interventions to create safety through redundancy.
Methods that Scale: We seek out safety methods that become more effective as models become more capable.
Human Control: We work to develop AI that elevates humanity and promotes democratic ideals.
Shared Responsibility: We view responsibility for advancing safety as a collective effort.
I’ll take each in turn.
Embracing Uncertainty
Embracing uncertainty is vital. The question is, what helps you embrace it?
If you have sufficient uncertainty about the safety of deployment, then it would be very strange to ‘embrace’ that uncertainty by deploying anyway. That goes double, of course, for deployments that one cannot undo, or which are sufficiently powerful they might render you unable to undo them (e.g. they might escape control, exfiltrate, etc).
So the question is, when does it reduce uncertainty to release models and learn, versus when it increases uncertainty more to do that? And what other considerations are there, in both directions? They recognize that the calculus on this could flip in the future, as quoted below.
I am both sympathetic and cynical here. I think OpenAI’s iterative development is primarily a business case, the same as everyone else’s, but that right now that business case is extremely compelling. I do think for now the safety case supports that decision, but view that as essentially a coincidence.
In particular, my worry is that alignment and safety considerations are, along with other elements, headed towards a key phase change, in addition to other potential phase changes. They do address this under ‘methods that scale,’ which is excellent, but I think the problem is far harder and more fundamental than they recognize.
Some excellent quotes here:
Our approach demands hard work, careful decision-making, and continuous calibration of risks and benefits.
…
The best time to act is before risks fully materialize, initiating mitigation efforts as potential negative impacts — such as facilitation of malicious use-cases or the model deceiving its operator— begin to surface.
…
In the future, we may see scenarios where the model risks become unacceptable even relative to benefits. We’ll work hard to figure out how to mitigate those risks so that the benefits of the model can be realized. Along the way, we’ll likely test them in secure, controlled settings.
…
For example, making increasingly capable models widely available by sharing their weights should include considering a reasonable range of ways a malicious party could feasibly modify the model, including by finetuning (see our 2024 statement on open model weights).
Yes, if you release an open weights model you need to anticipate likely modifications including fine-tuning, and not pretend your mitigations remain in place unless you have a reason to expect them to remain in place. Right now, we do not expect that.
Defense in Depth
It’s (almost) never a bad idea to use defense in depth on top of your protocol.
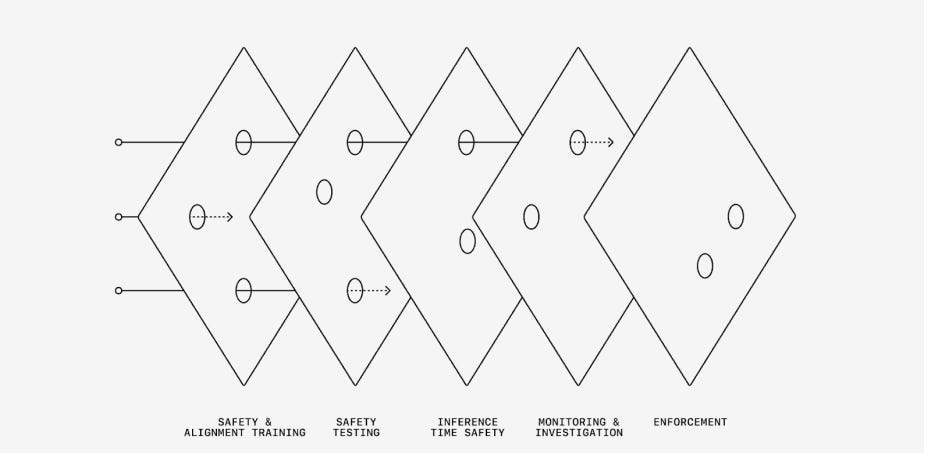
My worry is that in a crisis, all relevant correlations go to 1.
As in, as your models get increasingly capable, if your safety and alignment training fails, then your safety testing will be increasingly unreliable, and it will be increasingly able to get around your inference time safety, monitoring, investigations and enforcement.
Its ability to get around these four additional layers are all highly correlated to each other. The skills that get you around one mostly get you around the others. So this isn’t as much defense in depth as you would like it to be.
That doesn’t mean don’t do it. Certainly there are cases, especially involving misuse or things going out of distribution in strange but non-malicious ways, where you will be able to fail early, then recover later on. The worry is that when the stakes are high, that becomes a lot less likely, and you should think of this as maybe one effective ‘reroll’ at most rather than four.
Methods That Scale
To align increasingly intelligent models, especially models that are more intelligent and powerful than humans, we must develop alignment methods that improve rather than break with increasing AI intelligence.
I am in violent agreement. The question is which methods will scale.
There are also two different levels at which we must ask what scales.
Does it scale as AI capabilities increase on the margin, right now? A lot of alignment techniques right now are essentially ‘have the AI figure out what you meant.’ On the margin right now, more intelligence and capability of the AI mean better answers.
Deliberative alignment is the perfect example of this. It’s great for mundane safety right now and will get better in the short term. Having the model think about how to follow your specified rules will improve as intelligence improves, as long as the goal of obeying your rules as written gets you what you want. However, if you apply too much optimization pressure and intelligence to any particular set of deontological rules as you move out of distribution, even under DWIM (do what I mean, or the spirit of the rules) I predict disaster.
In addition, under amplification, or attempts to move ‘up the chain’ of capabilities, I worry that you can hope to copy your understanding, but not to improve it. And as they say, if you make a copy of a copy of a copy, it’s not quite as sharp as the original.
Human Control
I approve of everything they describe here, other than worries about the fetishization of democracy, please do all of it. But I don’t see how this allows humans to remain in effective control. These techniques are already hard to get right and aim to solve hard problems, but the full hard problems of control remain unaddressed.
Community Effort
Another excellent category, where they affirm the need to do safety work in public, fund it and support it, including government expertise, propose policy initiatives and make voluntary commitments.
There is definitely a lot of room for improvement in OpenAI and Sam Altman’s public facing communications and commitments.
The Suicide Caucus is a great term
Is the “Suicide Caucus” code for people who don’t believe in top down control of AI? Giving control of super intelligence to large governments and mega-corps under the guise of safety seems extremely fraught. I believe in a more decentralized future where ~everyone has access to extremely high performance models, and people who do bad things with AI, and purely rogue AI are countered by people who are good (with AI).
… kinda like how the world works now. The worst atrocities of modern history were all performed by governments, fyi. Why do we think giving them control over ASI will suddenly make them benevolent and immediately stop war mongering and propagandizing their subjects?