

Quotes from Leopold Aschenbrenner's Situational Awareness Paper

This post is different.
Usually I offer commentary and analysis. I share what others think, then respond.
This is the second time I am importantly not doing that. The work speaks for itself. It offers a different perspective, a window and a worldview. It is self-consistent. This is what a highly intelligent, highly knowledgeable person actually believes after much thought.
So rather than say where I agree and disagree and argue back (and I do both strongly in many places), this is only quotes and graphs from the paper, selected to tell the central story while cutting length by ~80%, so others can more easily absorb it. I recommend asking what are the load bearing assumptions and claims, and what changes to them would alter the key conclusions.
The first time I used this format was years ago, when I offered Quotes from Moral Mazes. I think it is time to use it again.
Then there will be one or more other posts, where I do respond.
Introduction
(1) Page 1: The Project will be on. If we’re lucky, we’ll be in an all-out race with the CCP; if we’re unlucky, an all-out war.
Everyone is now talking about AI, but few have the faintest glimmer of what is about to hit them. Nvidia analysts still think 2024 might be close to the peak. Mainstream pundits are stuck on the willful blindness of “it’s just predicting the next word”. They see only hype and business-as-usual; at most they entertain another internet-scale technological change.
Before long, the world will wake up. But right now, there are perhaps a few hundred people, most of them in San Francisco and the AI labs, that have situational awareness. Through whatever peculiar forces of fate, I have found myself amongst them.
Section 1: From GPT-4 to AGI: Counting the OOMs
(2) Page 7: AGI by 2027 is strikingly plausible. GPT-2 to GPT-4 took us from ~preschooler to ~smart high-schooler abilities in 4 years. Tracing trendlines in compute (~0.5 orders of magnitude or OOMs/year), algorithmic efficiencies (~0.5 OOMs/year), and “unhobbling” gains (from chatbot to agent), we should expect another preschooler-to-high-schooler-sized qualitative jump by 2027.
(3) Page 8: I make the following claim: it is strikingly plausible that by 2027, models will be able to do the work of an AI researcher/engineer. That doesn’t require believing in sci-fi; it just requires believing in straight lines on a graph.
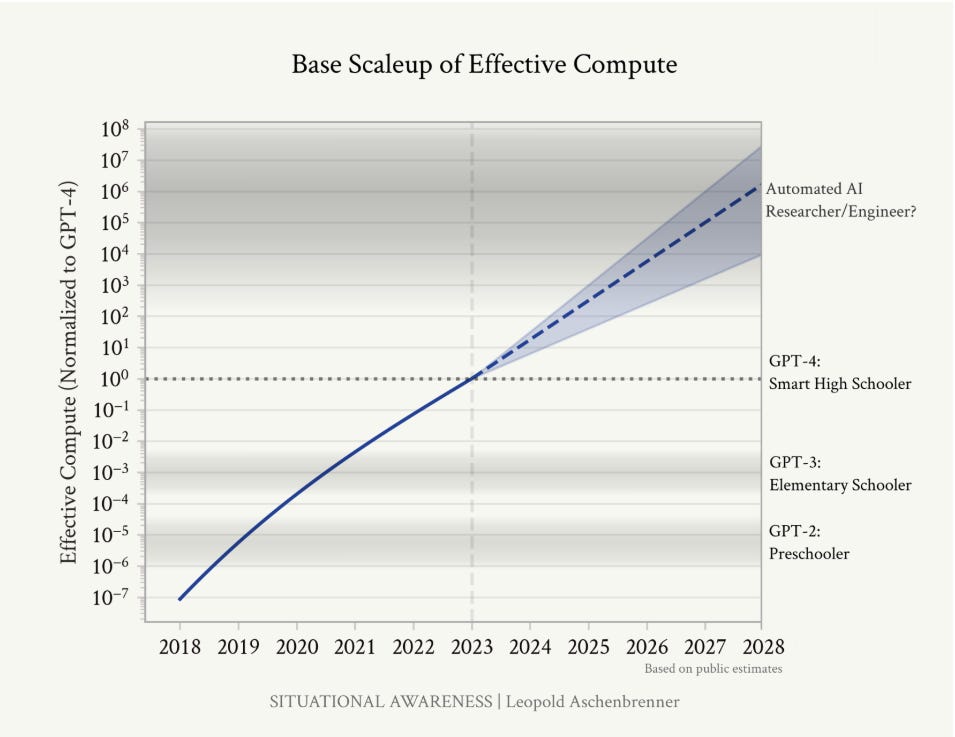
(4) Page 9: We are racing through the OOMs extremely rapidly, and the numbers indicate we should expect another ~100,000x effective compute scaleup—resulting in another GPT-2-to-GPT-4-sized qualitative jump—over four years.
(5) Page 14: Of course, even GPT-4 is still somewhat uneven; for some tasks it’s much better than smart high-schoolers, while there are other tasks it can’t yet do. That said, I tend to think most of these limitations come down to obvious ways models are still hobbled, as I’ll discuss in-depth later. The raw intelligence is (mostly) there, even if the models are still artificially constrained; it’ll take extra work to unlock models being able to fully apply that raw intelligence across applications.
(6) Page 19: How did this happen? The magic of deep learning is that it just works—and the trendlines have been astonishingly consistent, despite naysayers at every turn.

(7) Page 21: An additional 2 OOMs of compute (a cluster in the $10s of billions) seems very likely to happen by the end of 2027; even a cluster closer to +3 OOMs of compute ($100 billion+) seems plausible (and is rumored to be in the works at Microsoft/OpenAI).
(8) Page 23: In this piece, I’ll separate out two kinds of algorithmic progress. Here, I’ll start by covering “within-paradigm” algorithmic improvements—those that simply result in better base models, and that straightforwardly act as compute efficiencies or compute multipliers. For example, a better algorithm might allow us to achieve the same performance but with 10x less training compute. In turn, that would act as a 10x (1 OOM) increase in effective compute. (Later, I’ll cover “unhobbling,” which you can think of as “paradigm-expanding/application-expanding” algorithmic progress that unlocks capabilities of base models.)
(9) Page 26: Put together, this suggests we should expect something like 1-3 OOMs of algorithmic efficiency gains (compared to GPT-4) by the end of 2027, maybe with a best guess of ~2 OOMs.
(10) Page 27: In addition to insider bullishness, I think there’s a strong intuitive case for why it should be possible to find ways to train models with much better sample efficiency (algorithmic improvements that let them learn more from limited data). Consider how you or I would learn from a really dense math textbook.
(11) Page 29: All of this is to say that data constraints seem to inject large error bars either way into forecasting the coming years of AI progress. There’s a very real chance things stall out (LLMs might still be as big of a deal as the internet, but we wouldn’t get to truly crazy AGI). But I think it’s reasonable to guess that the labs will crack it, and that doing so will not just keep the scaling curves going, but possibly enable huge gains in model capability.
(12) Page 29: As an aside, this also means that we should expect more variance between the different labs in coming years compared to today. Up until recently, the state of the art techniques were published, so everyone was basically doing the same thing. (And new upstarts or open source projects could easily compete with the frontier, since the recipe was published.) Now, key algorithmic ideas are becoming increasingly proprietary.
(13) Page 33: “Unhobbling” is a huge part of what actually enabled these models to become useful—and I’d argue that much of what is holding back many commercial applications today is the need for further “unhobbling” of this sort. Indeed, models today are still incredibly hobbled! For example:
• They don’t have long-term memory
• They can’t use a computer (they still only have very limited tools).
• They still mostly don’t think before they speak. When you ask ChatGPT to write an essay, that’s like expecting a human to write an essay via their initial stream-of-consciousness (People are working on this though).
• They can (mostly) only engage in short back-and-forth dialogues, rather than going away for a day or a week, thinking about a problem, researching different approaches, consulting other humans, and then writing you a longer report or pull request.
• They’re mostly not personalized to you or your application (just a generic chatbot with a short prompt, rather than having all the relevant background on your company and your work).
It seems like it should be possible, for example via very-long-context, to “onboard” models like we would a new human coworker. This alone would be a huge unlock.
(14) Page 35: In essence, there is a large test-time compute overhang.

(15) Page 38: By the end of this, I expect us to get something that looks a lot like a drop-in remote worker.
(16) Page 41: (One neat way to think about this is that the current trend of AI progress is proceeding at roughly 3x the pace of child development. Your 3x-speed-child just graduated high school; it’ll be taking your job before you know it!)
We are on course for AGI by 2027. These AI systems will basically be able to automate basically all cognitive jobs (think: all jobs that could be done remotely).
To be clear—the error bars are large. Progress could stall as we run out of data, if the algorithmic breakthroughs necessary to crash through the data wall prove harder than expected. Maybe unhobbling doesn’t go as far, and we are stuck with merely expert chatbots, rather than expert coworkers. Perhaps the decade-long trendlines break, or scaling deep learning hits a wall for real this time. (Or an algorithmic breakthrough, even simple unhobbling that unleashes the test-time compute overhang, could be a paradigm-shift, accelerating things further and leading to AGI even earlier.)
(17) Page 42: It seems like many are in the game of downward-defining AGI these days, as just as really good chatbot or whatever. What I mean is an AI system that could fully automate my or my friends’ job, that could fully do the work of an AI researcher or engineer.
(18) Page 43: Addendum. Racing through the OOMs: It’s this decade or bust I used to be more skeptical of short timelines to AGI. One reason is that it seemed unreasonable to privilege this decade, concentrating so much AGI-probability-mass on it (it seemed like a classic fallacy to think “oh we’re so special”). I thought we should be uncertain about what it takes to get AGI, which should lead to a much more “smeared-out” probability distribution over when we might get AGI. However, I’ve changed my mind: critically, our uncertainty over what it takes to get AGI should be over OOMs (of effective compute), rather than over years. We’re racing through the OOMs this decade. Even at its bygone heyday, Moore’s law was only 1–1.5 OOMs/decade. I estimate that we will do ~5 OOMs in 4 years, and over ~10 this decade overall.
In essence, we’re in the middle of a huge scaleup reaping one-time gains this decade, and progress through the OOMs will be multiples slower thereafter. If this scaleup doesn’t get us to AGI in the next 5-10 years, it might be a long way out.
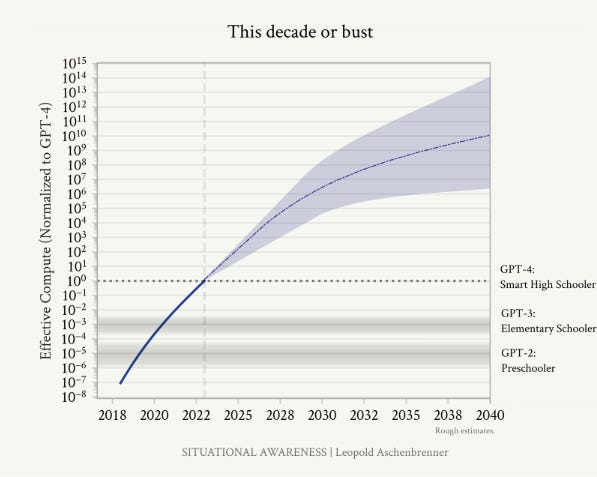
(19) Page 44: Hardware gains: AI hardware has been improving much more quickly than Moore’s law. That’s because we’ve been specializing chips for AI workloads. For example, we’ve gone from CPUs to GPUs; adapted chips for Transformers; and we’ve gone down to much lower precision number formats, from fp64/fp32 for traditional supercomputing to fp8 on H100s. These are large gains, but by the end of the decade we’ll likely have totally specialized AI-specific chips, without much further beyond-Moore’s law gains possible.
Algorithmic progress: In the coming decade, AI labs will invest tens of billions in algorithmic R&D, and all the smartest people in the world will be working on this; from tiny efficiencies to new paradigms, we’ll be picking lots of the low-hanging fruit. We probably won’t reach any sort of hard limit (though “unhobblings” are likely finite), but at the very least the pace of improvements should slow down, as the rapid growth (in $ and human capital investments) necessarily slows down (e.g., most of the smart STEM talent will already be working on AI). (That said, this is the most uncertain to predict, and the source of most of the uncertainty on the OOMs in the 2030s on the plot above.)
Section 2: From AGI to Superintelligence: The Intelligence Explosion
(20) Page 46 (start of section 2): AI progress won’t stop at human-level. Hundreds of millions of AGIs could automate AI research, compressing a decade of algorithmic progress (5+ OOMs) into 1 year. We would rapidly go from human-level to vastly superhuman AI systems. The power—and the peril—of superintelligence would be dramatic.
(21) Page 48: Once we get AGI, we won’t just have one AGI. I’ll walk through the numbers later, but: given inference GPU fleets by then, we’ll likely be able to run many millions of them (perhaps 100 million human-equivalents, and soon after at 10x+ human speed).
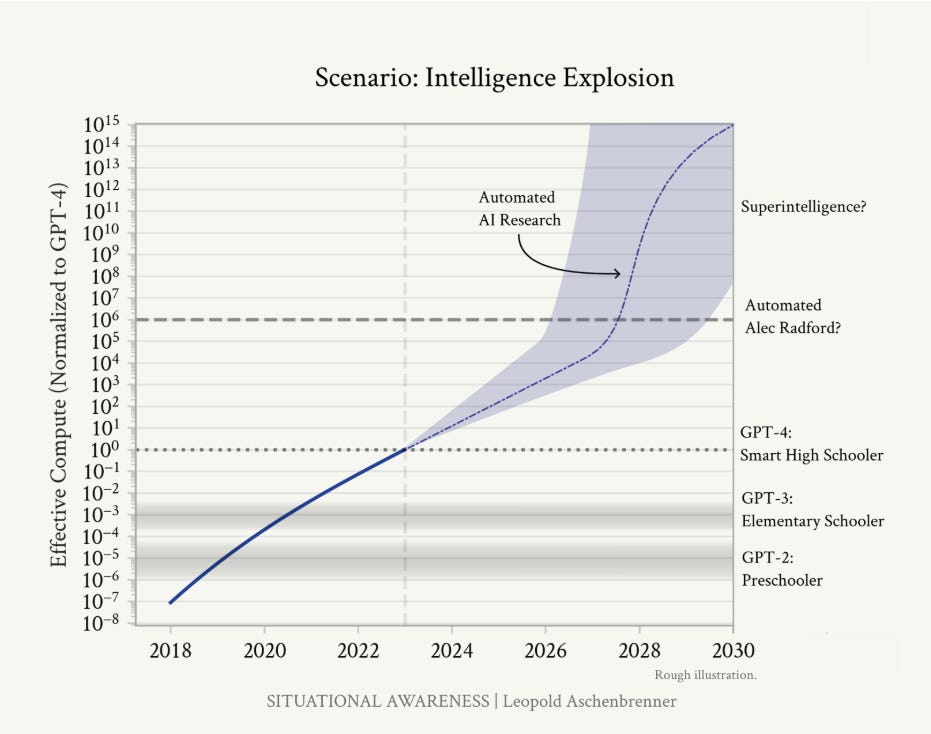
(22) Page 49: We don’t need to automate everything—just AI research.
(23) Page 50: It’s worth emphasizing just how straightforward and hacky some of the biggest machine learning breakthroughs of the last decade have been: “oh, just add some normalization” (LayerNorm/BatchNorm) or “do f(x)+x instead of f(x)” (residual connections)” or “fix an implementation bug” (Kaplan → Chinchilla scaling laws). AI research can be automated. And automating AI research is all it takes to kick off extraordinary feedback loops.
(24) Page 50: Another way of thinking about it is that given inference fleets in 2027, we should be able to generate an entire internet’s worth of tokens, every single day.
(25) Page 51: By taking some inference penalties, we can trade off running fewer copies in exchange for running them at faster serial speed. (For example, we could go from ~5x human speed to ~100x human speed by “only” running 1 million copies of the automated researchers.
More importantly, the first algorithmic innovation the automated AI researchers work on is getting a 10x or 100x speedup.
This could easily dramatically accelerate existing trends of algorithmic progress, compressing a decade of advances into a year.
(26) Page 51: Don’t just imagine 100 million junior software engineer interns here (we’ll get those earlier, in the next couple years!). Real automated AI researchers be very smart—and in addition to their raw quantitative advantage, automated AI researchers will have other enormous advantages over human researchers.
They’ll be able to read every single ML paper ever written, have been able to deeply think about every single previous experiment ever run at the lab, learn in parallel from each of their copies, and rapidly accumulate the equivalent of millennia of experience.
(27) Page 53: It’s strikingly plausible we’d go from AGI to superintelligence very quickly, perhaps in 1 year.
(28) Page 54: the last 10% of the job of an AI researcher might be particularly hard to automate. This could soften takeoff some, though my best guess is that this only delays things by a couple years.
Maybe another 5 OOMs of algorithmic efficiency will be fundamentally impossible? I doubt it.
(29) Page 59: I’ll take a moment here to acknowledge perhaps the most compelling formulation of the counterargument I’ve heard, by my friend James Bradbury: if more ML research effort would so dramatically accelerate progress, why doesn’t the current academic ML research community, numbering at least in the tens of thousands, contribute more to frontier lab progress?
(Currently, it seems like lab-internal teams, of perhaps a thousand in total across labs, shoulder most of the load for frontier algorithmic progress.) His argument is that the reason is that algorithmic progress is compute-bottlenecked: the academics just don’t have enough compute.
Some responses: Quality-adjusted, I think academics are probably more in the thousands not tens of thousands (e.g., looking only at the top universities).
Academics work on the wrong things.
Even when the academics do work on things like LLM pretraining, they simply don’t have access to the state-of-the-art.
Academics are way worse than automated AI researchers: they can’t work at 10x or 100x human speed, they can’t read and internalize every ML paper ever written, they can’t spend a decade checking every line of code, replicate themselves to avoid onboarding-bottlenecks, etc.
(30) Page 61: I think it’s reasonable to be uncertain how this plays out, but it’s unreasonable to be confident it won’t be doable for the models to get around the compute bottleneck just because it’d be hard for humans to do so.
(31) Page 62: Still, in practice, I do expect somewhat of a long tail to get to truly 100% automation even for the job of an AI researcher/engineer; for example, we might first get systems that function almost as an engineer replacement, but still need some amount of human supervision.
In particular, I expect the level of AI capabilities to be somewhat uneven and peaky across domains: it might be a better coder than the best engineers while still having blindspots in some subset of tasks or skills; by the time it’s human-level at whatever its worst at, it’ll already be substantially superhuman at easier domains to train, like coding.
(32) Page 62: But I wouldn’t expect that phase to last more than a few years; given the pace of AI progress, I think it would likely just be a matter of some additional “unhobbling” (removing some obvious limitation of the models that prevented it from doing the last mile) or another generation of models to get all the way.
(33) Page 68: Solve robotics. Superintelligence won’t stay purely cognitive for long. Getting robotics to work well is primarily an ML algorithms problem (rather than a hardware problem), and our automated AI researchers will likely be able to solve it (more below!). Factories would go from human-run, to AIdirected using human physical labor, to soon being fully run by swarms of robots.
Dramatically accelerate scientific and technological progress. Yes, Einstein alone couldn’t develop neuroscience and build a semiconductor industry, but a billion superintelligent automated scientists, engineers, technologists, and robot technicians would make extraordinary advances in many fields in the space of years.
An industrial and economic explosion. Extremely accelerated technological progress, combined with the ability to automate all human labor, could dramatically accelerate economic growth.
(34) Page 70: Provide a decisive and overwhelming military advantage.
Be able to overthrow the US government. Whoever controls superintelligence will quite possibly have enough power to seize control from pre-superintelligence forces. Even without robots, the small civilization of superintelligences would be able to hack any undefended military, election, television, etc. system, cunningly persuade generals and electorates, economically outcompete nation-states, design new synthetic bioweapons and then pay a human in bitcoin to synthesize it, and so on.
(35) Page 72: Robots. A common objection to claims like those here is that, even if AI can do cognitive tasks, robotics is lagging way behind and so will be a brake on any real-world impacts.
I used to be sympathetic to this, but I’ve become convinced robots will not be a barrier. For years people claimed robots were a hardware problem—but robot hardware is well on its way to being solved.
Increasingly, it’s clear that robots are an ML algorithms problem.
Section 3a: Racing to the Trillion-Dollar Cluster
(36) Page 75 (start of part 3): The most extraordinary techno-capital acceleration has been set in motion. As AI revenue grows rapidly, many trillions of dollars will go into GPU, datacenter, and power buildout before the end of the decade. The industrial mobilization, including growing US electricity production by 10s of percent, will be intense.
(37) Page 76: Total AI investment could be north of $1T annually by 2027.
By the end of the decade, we are headed to $1T+ individual training clusters, requiring power equivalent to >20% of US electricity production. Trillions of dollars of capex will churn out 100s of millions of GPUs per year overall.
(38) Page 78: (Note that I think it’s pretty likely we’ll only need a ~$100B cluster, or less, for AGI. The $1T cluster might be what we’ll train and run superintelligence on, or what we’ll use for AGI if AGI is harder than expected. In any case, in a post-AGI world, having the most compute will probably still really matter.)
My rough estimate is that 2024 will already feature $100B- $200B of AI investment.
Big tech has been dramatically ramping their capex numbers: Microsoft and Google will likely do $50B+ , AWS and Meta $40B+, in capex this year. Not all of this is AI, but combined their capex will have grown $50B-$100B year-over-year because of the AI boom, and even then they are still cutting back on other capex to shift even more spending to AI.
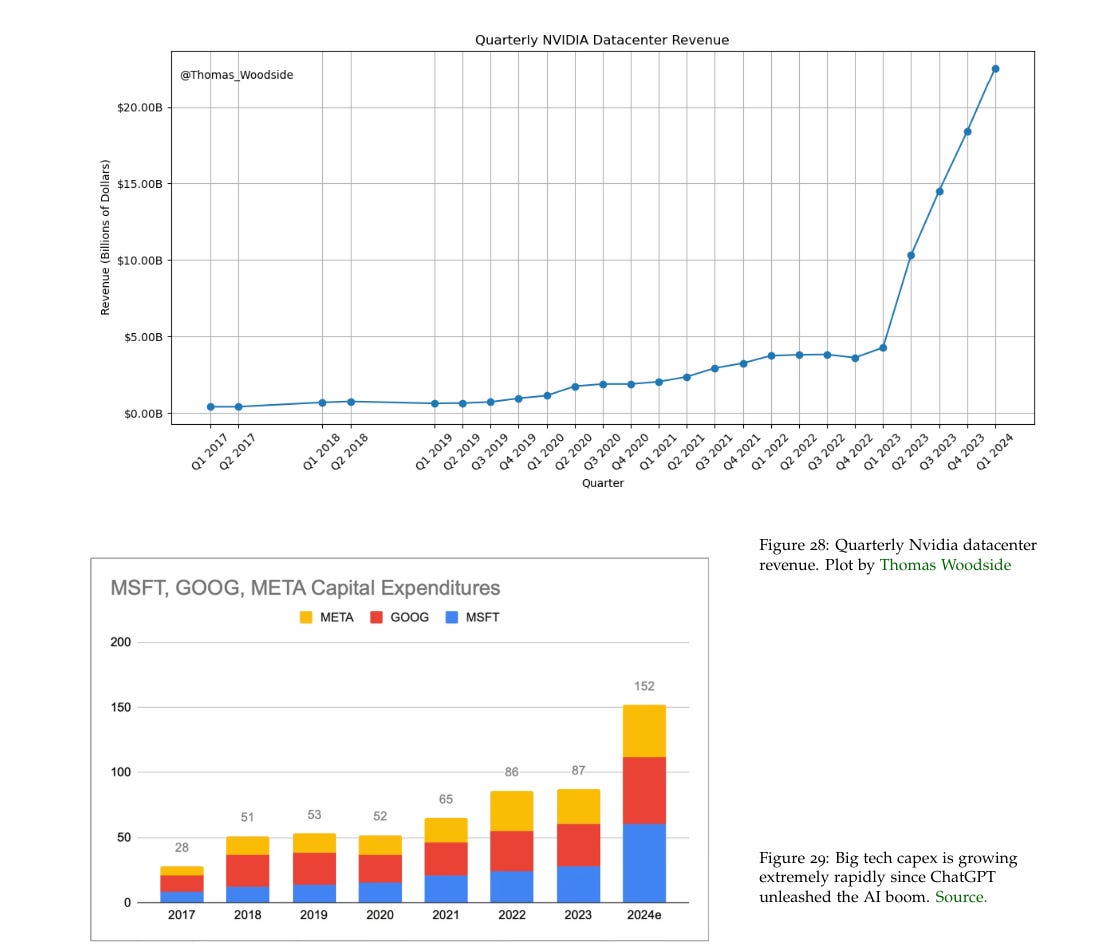
(39) Page 80: Let’s play this forward. My best guess is overall compute investments will grow more slowly than the 3x/year largest training clusters, let’s say 2x/year.
(40) Page 81: Reports suggest OpenAI was at a $1B revenue run rate in August 2023, and a $2B revenue run rate in February 2024. That’s roughly a doubling every 6 months. If that trend holds, we should see a ~$10B annual run rate by late 2024/early 2025, even without pricing in a massive surge from any next generation model. One estimate puts Microsoft at ~$5B of incremental AI revenue already.
(41) Page 82: ery naively extrapolating out the doubling every 6 months, supposing we hit a $10B revenue run rate in early 2025, suggests this would happen mid-2026.
That may seem like a stretch, but it seems to me to require surprisingly little imagination to reach that milestone. For example, there are around 350 million paid subscribers to Microsoft Office—could you get a third of these to be willing to pay $100/month for an AI add-on?
For an average worker, that’s only a few hours a month of productivity gained; models powerful enough to make that justifiable seem very doable in the next couple years.
It’s hard to understate the ensuing reverberations. This would make AI products the biggest revenue driver for America’s largest corporations, and by far their biggest area of growth.
We probably see our first many-hundred-billion dollar corporate bond sale then.
Historical precedents
$1T/year of total annual AI investment by 2027 seems outrageous. But it’s worth taking a look at other historical reference classes:
• In their peak years of funding, the Manhattan and Apollo programs reached 0.4% of GDP, or ~$100 billion annually today (surprisingly small!). At $1T/year, AI investment would be about 3% of GDP.
• Between 1996–2001, telecoms invested nearly $1 trillion in today’s dollars in building out internet infrastructure. • From 1841 to 1850, private British railway investments totaled a cumulative ~40% of British GDP at the time. A similar fraction of US GDP would be equivalent to ~$11T over a decade.
• Many trillions are being spent on the green transition.
• Rapidly-growing economies often spend a high fraction of their GDP on investment; for example, China has spent more than 40% of its GDP on investment for two decades (equivalent to $11T annually given US GDP).
• In the historically most exigent national security circumstances— wartime—borrowing to finance the national effort has often comprised enormous fractions of GDP. During WWI, the UK and France, and Germany borrowed over 100% of their GDPs while the US borrowed over 20%; during WWII, the UK and Japan borrowed over 100% of their GDPs while the US borrowed over 60% of GDP (equivalent to over $17T today).
$1T/year of total AI investment by 2027 would be dramatic— among the very largest capital buildouts ever—but would not be unprecedented. And a trillion-dollar individual training cluster by the end of the decade seems on the table.
(42) Page 83: Probably the single biggest constraint on the supply-side will be power. Already, at nearer-term scales (1GW/2026 and especially 10GW/2028), power has become the binding constraint: there simply isn’t much spare capacity, and power contracts are usually long-term locked-in. And building, say, a new gigawatt-class nuclear power plant takes a decade.
(43) Page 84: To most, this seems completely out of the question. Some are betting on Middle Eastern autocracies, who have been going around offering boundless power and giant clusters to get their rulers a seat at the AGI-table.
But it’s totally possible to do this in the United States: we have abundant natural gas.
(44) Page 85: We’re going to drive the AGI datacenters to the Middle East, under the thumb of brutal, capricious autocrats. I’d prefer clean energy too—but this is simply too important for US national security. We will need a new level of determination to make this happen. The power constraint can, must, and will be solved.
(45) Page 86: While chips are usually what comes to mind when people think about AI-supply-constraints, they’re likely a smaller constraint than power. Global production of AI chips is still a pretty small percent of TSMC-leading-edge production, likely less than 10%. There’s a lot of room to grow via AI becoming a larger share of TSMC production.
(46) Page 86: Even if raw logic fabs won’t be the constraint, chip-on-waferon-substrate (CoWoS) advanced packaging (connecting chips to memory, also made by TSMC, Intel, and others) and HBM memory (for which demand is enormous) are already key bottlenecks for the current AI GPU scaleup; these are more specialized to AI, unlike the pure logic chips, so there’s less pre-existing capacity.
In the near term, these will be the primary constraint on churning out more GPUs, and these will be the huge constraints as AI scales. Still, these are comparatively “easy” to scale; it’s been incredible watching TSMC literally build “greenfield” fabs (i.e. entirely new facilities from scratch) to massively scale up CoWoS production this year (and Nvidia is even starting to find CoWoS alternatives to work around the shortage).
(47) Page 87: Before the decade is out, many trillions of dollars of compute clusters will have been built. The only question is whether they will be built in America.
While onshoring more of AI chip production to the US would be nice, it’s less critical than having the actual datacenter (on which the AGI lives) in the US. If having chip production abroad is like having uranium deposits abroad, having the AGI datacenter abroad is like having the literal nukes be built and stored abroad.
The clusters can be built in the US, and we have to get our act together to make sure it happens in the US. American national security must come first, before the allure of free-flowing Middle Eastern cash, arcane regulation, or even, yes, admirable climate commitments. We face a real system competition— can the requisite industrial mobilization only be done in “topdown” autocracies? If American business is unshackled, America can build like none other (at least in red states). Being willing to use natural gas, or at the very least a broad-based deregulatory agenda—NEPA exemptions, fixing FERC and transmission permitting at the federal level, overriding utility regulation, using federal authorities to unlock land and rights of way—is a national security priority.
Section 3b: Lock Down the Labs: Security for AGI
(48) Page 89 (Start of IIIb): The nation’s leading AI labs treat security as an afterthought. Currently, they’re basically handing the key secrets for AGI to the CCP on a silver platter. Securing the AGI secrets and weights against the state-actor threat will be an immense effort, and we’re not on track.
(49) Page 90: On the current course, the leading Chinese AGI labs won’t be in Beijing or Shanghai—they’ll be in San Francisco and London. In a few years, it will be clear that the AGI secrets are the United States’ most important national defense secrets—deserving treatment on par with B-21 bomber or Columbia-class submarine blueprints, let alone the proverbial “nuclear secrets”—but today, we are treating them the way we would random SaaS software. At this rate, we’re basically just handing superintelligence to the CCP.
(50) Page 91: And this won’t just matter years in the future. Sure, who cares if GPT-4 weights are stolen—what really matters in terms of weight security is that we can secure the AGI weights down the line, so we have a few years, you might say. (Though if we’re building AGI in 2027, we really have to get moving!) But the AI labs are developing the algorithmic secrets—the key technical breakthroughs, the blueprints so to speak—for the AGI right now (in particular, the RL/self-play/synthetic data/etc “next paradigm” after LLMs to get past the data wall). AGI-level security for algorithmic secrets is necessary years before AGIlevel security for weights.
Our failure today will be irreversible soon: in the next 12-24 months, we will leak key AGI breakthroughs to the CCP. It will be the national security establishment’s single greatest regret before the decade is out.
(51) Page 93: The threat model
There are two key assets we must protect: model weights (especially as we get close to AGI, but which takes years of preparation and practice to get right) and algorithmic secrets (starting yesterday).
(52) Page 94: Perhaps the single scenario that most keeps me up at night is if China or another adversary is able to steal the automated-AI-researcher-model-weights on the cusp of an intelligence explosion. China could immediately use these to automate AI research themselves (even if they had previously been way behind)—and launch their own intelligence explosion. That’d be all they need to automate AI research, and build superintelligence. Any lead the US had would vanish.
Moreover, this would immediately put us in an existential race; any margin for ensuring superintelligence is safe would disappear. The CCP may well try to race through an intelligence explosion as fast as possible—even months of lead on superintelligence could mean a decisive military advantage—in the process skipping all the safety precautions any responsible US AGI effort would hope to take.
We’re miles away for sufficient security to protect weights today. Google DeepMind (perhaps the AI lab that has the best security of any of them, given Google infrastructure) at least straight-up admits this. Their Frontier Safety Framework outlines security levels 0, 1, 2, 3, and 4 (~1.5 being what you’d need to defend against well-resourced terrorist groups or cybercriminals, 3 being what you’d need to defend against the North Koreas of the world, and 4 being what you’d need to have even a shot of defending against priority efforts by the most capable state actors)
They admit to being at level 0 (only the most banal and basic measures). If we got AGI and superintelligence soon, we’d literally deliver it to terrorist groups and every crazy dictator out there!
Critically, developing the infrastructure for weight security probably takes many years of lead times—if we think AGI in ~3-4 years is a real possibility and we need state-proof weight security then, we need to be launching the crash effort now.
(53) Page 95: Algorithmic secrets
While people are starting to appreciate (though not necessarily implement) the need for weight security, arguably even more important right now—and vastly underrated—is securing algorithmic secrets.
One way to think about this is that stealing the algorithmic secrets will be worth having a 10x or more larger cluster to the PRC,
(54) Page 96: It’s easy to underrate how important an edge algorithmic secrets will be—because up until ~a couple years ago, everything was published.
(55) Page 97: Put simply, I think failing to protect algorithmic secrets is probably the most likely way in which China is able to stay competitive in the AGI race. (I discuss this more later.)
It’s hard to overstate how bad algorithmic secrets security is right now. Between the labs, there are thousands of people with access to the most important secrets; there is basically no background-checking, silo’ing, controls, basic infosec, etc. Things are stored on easily hackable SaaS services. People gabber at parties in SF. Anyone, with all the secrets in their head, could be offered $100M and recruited to a Chinese lab at any point.
(56) Page 98: There’s a lot of low-hanging fruit on security at AI labs. Merely adopting best practices from, say, secretive hedge funds or Google-customer-data-level security, would put us in a much better position with respect to “regular” economic espionage from the CCP. Indeed, there are notable examples of private sector firms doing remarkably well at preserving secrets. Take quantitative trading firms (the Jane Streets of the world) for example.
A number of people have told me that in an hour of conversation they could relay enough information to a competitor such that their firm’s alpha would go to ~zero—similar to how many key AI algorithmic secrets could be relayed in a short conversation—and yet these firms manage to keep these secrets and retain their edge.
(57) Page 99: While the government does not have a perfect track record on security themselves, they’re the only ones who have the infrastructure, know-how, and competencies to protect nationaldefense-level secrets. Basic stuff like the authority to subject employees to intense vetting; threaten imprisonment for leaking secrets; physical security for datacenters; and the vast know-how of places like the NSA and the people behind the security clearances (private companies simply don’t have the expertise on state-actor attacks).
(58) Page 100: Some argue that strict security measures and their associated friction aren’t worth it because they would slow down American AI labs too much. But I think that’s mistaken:
This is a tragedy of the commons problem. For a given lab’s commercial interests, security measures that cause a 10% slowdown might be deleterious in competition with other labs. But the national interest is clearly better served if every lab were willing to accept the additional friction.
Moreover, ramping security now will be the less painful path in terms of research productivity in the long run. Eventually, inevitably, if only on the cusp of superintelligence, in the extraordinary arms race to come, the USG will realize the situation is unbearable and demand a security crackdown.
Others argue that even if our secrets or weights leak, we will still manage to eke out just ahead by being faster in other ways (so we needn’t worry about security measures). That, too, is mistaken, or at least running way too much risk:
As I discuss in a later piece, I think the CCP may well be able to brutely outbuild the US (a 100GW cluster will be much easier for them). More generally, China might not have the same caution slowing it down that the US will (both reasonable and unreasonable caution!). Even if stealing the algorithms or weights “only” puts them on par with the US model-wise, that might be enough for them to win the race to superintelligence.
Moreover, even if the US squeaks out ahead in the end, the difference between a 1-2 year and 1-2 month lead will really matter for navigating the perils of superintelligence. A 1-2 year lead means at least a reasonable margin to get safety right, and to navigate the extremely volatile period around the intelligence explosion and post-superintelligence.
(59) Page 102: There’s a real mental dissonance on security at the leading AI labs. They full-throatedly claim to be building AGI this decade. They emphasize that American leadership on AGI will be decisive for US national security. They are reportedly planning 7T chip buildouts that only make sense if you really believe in AGI. And indeed, when you bring up security, they nod and acknowledge “of course, we’ll all be in a bunker” and smirk.
And yet the reality on security could not be more divorced from that. Whenever it comes time to make hard choices to prioritize security, startup attitudes and commercial interests prevail over the national interest. The national security advisor would have a mental breakdown if he understood the level of security at the nation’s leading AI labs.
Section 3c: Superalignment
(60) Page 105 (start of IIIc): Reliably controlling AI systems much smarter than we are is an unsolved technical problem. And while it is a solvable problem, things could very easily go off the rails during a rapid intelligence explosion. Managing this will be extremely tense; failure could easily be catastrophic.
There is a very real technical problem: our current alignment techniques (methods to ensure we can reliably control, steer, and trust AI systems) won’t scale to superhuman AI systems. What I want to do is explain what I see as the “default” plan for how we’ll muddle through, and why I’m optimistic. While not enough people are on the ball—we should have much more ambitious efforts to solve this problem!—overall, we’ve gotten lucky with how deep learning has shaken out, there’s a lot of empirical low-hanging fruit that will get us part of the way, and we’ll have the advantage of millions of automated AI researchers to get us the rest of the way.
But I also want to tell you why I’m worried. Most of all, ensuring alignment doesn’t go awry will require extreme competence in managing the intelligence explosion. If we do rapidly transition from from AGI to superintelligence, we will face a situation where, in less than a year, we will go from recognizable human-level systems for which descendants of current alignment techniques will mostly work fine, to much more alien, vastly superhuman systems that pose a qualitatively different, fundamentally novel technical alignment problem; at the same time, going from systems where failure is low-stakes to extremely powerful systems where failure could be catastrophic; all while most of the world is probably going kind of crazy. It makes me pretty nervous.
In essence, we face a problem of handing off trust. By the end of the intelligence explosion, we won’t have any hope of understanding what our billion superintelligences are doing (except as they might choose to explain to us, like they might to a child). And we don’t yet have the technical ability to reliably guarantee even basic side constraints for these systems, like “don’t lie” or “follow the law” or “don’t try to exfiltrate your server.”
Reinforcement from human feedback (RLHF) works very well for adding such side constraints for current systems—but RLHF relies on humans being able to understand and supervise AI behavior, which fundamentally won’t scale to superhuman systems.
The superalignment problem
We’ve been able to develop a very successful method for aligning (i.e., steering/controlling) current AI systems (AI systems dumber than us!): Reinforcement Learning from Human Feedback (RLHF).
The core technical problem of superalignment is simple: how do we control AI systems (much) smarter than us?
RLHF will predictably break down as AI systems get smarter, and we will face fundamentally new and qualitatively different technical challenges. Imagine, for example, a superhuman AI system generating a million lines of code in a new programming language it invented. If you asked a human rater in an RLHF procedure, “does this code contain any security backdoors?” they simply wouldn’t know. They wouldn’t be able to rate the output as good or bad, safe or unsafe, and so we wouldn’t be able to reinforce good behaviors and penalize bad behaviors with RLHF.
In the (near) future, even the best human experts spending lots of time won’t be good enough.
(61) Page 110: If we can’t add these side-constraints, it’s not clear what will happen. Maybe we’ll get lucky and things will be benign by default (for example, maybe we can get pretty far without the AI systems having long-horizon goals, or the undesirable behaviors will be minor). But it’s also totally plausible they’ll learn much more serious undesirable behaviors: they’ll learn to lie, they’ll learn to seek power, they’ll learn to behave nicely when humans are looking and pursue more nefarious strategies when we aren’t watching, and so on.
The primary problem is that for whatever you want to instill the model (including ensuring very basic things, like “follow the law”!) we don’t yet know how to do that for the very powerful AI systems we are building very soon.
(62) Page 111: It sounds crazy, but remember when everyone was saying we wouldn’t connect AI to the internet? The same will go for things like “we’ll make sure a human is always in the loop!”—as people say today.
We’ll have summoned a fairly alien intelligence, one much smarter than us, one whose architecture and training process wasn’t even designed by us but some supersmart previous generation of AI systems, one where we can’t even begin to understand what they’re doing, it’ll be running our military, and its goals will have been learned by a naturalselection-esque process.
Unless we solve alignment—unless we figure out how to instill those side-constraints—there’s no particular reason to expect this small civilization of superintelligences will continue obeying human commands in the long run. It seems totally within the realm of possibilities that at some point they’ll simply conspire to cut out the humans, whether suddenly or gradually.
(63) Page 112: What makes this incredibly hair-raising is the possibility of an intelligence explosion: that we might make the transition from roughly human-level systems to vastly superhuman systems extremely rapidly, perhaps in less than a year.
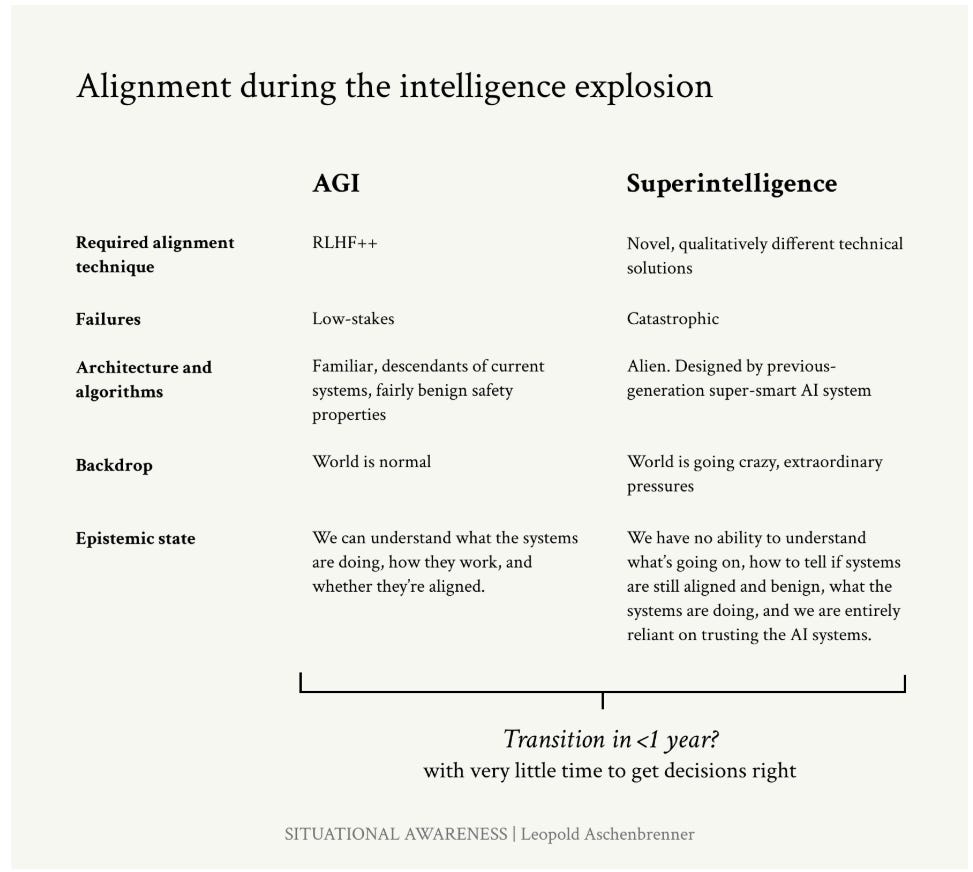
(64) Page 113: The superintelligence we get by the end of it will be vastly superhuman. We’ll be entirely reliant on trusting these systems, and trusting what they’re telling us is going on—since we’ll have no ability of our own to pierce through what exactly they’re doing anymore.
– One example that’s very salient to me: we may well bootstrap our way to human-level or somewhat-superhuman AGI with systems that reason via chains of thoughts, i.e. via English tokens. This is extraordinarily helpful, because it means the models “think out loud” letting us catch malign behavior (e.g., if it’s scheming against us). But surely having AI systems think in tokens is not the most efficient means to do it, surely there’s something much better that does all of this thinking via internal states—and so the model by the end of the intelligence explosion will almost certainly not think out loud, i.e. will have completely uninterpretable reasoning.
Think: “We caught the AI system doing some naughty things in a test, but we adjusted our procedure a little bit to hammer that out. Our automated AI researchers tell us the alignment metrics look good, but we don’t really understand what’s going on and don’t fully trust them, and we don’t have any strong scientific understanding that makes us confident this will continue to hold for another couple OOMs. So, we’ll probably be fine? Also China just stole our weights and they’re launching their own intelligence explosion, they’re right on our heels.”
It just really seems like this could go off the rails. To be honest, it sounds terrifying.
Yes, we will have AI systems to help us. Just like they’ll automate capabilities research, we can use them to automate alignment research. That will be key, as I discuss below. But—can you trust the AI systems? You weren’t sure whether they were aligned in the first place—are they actually being honest with you about their claims about alignment science?
(65) Page 115: The default plan: how we can muddle through
I think we can harvest wins across a number of empirical bets, which I’ll describe below, to align somewhat-superhuman systems. Then, if we’re confident we can trust these systems, we’ll need to use these somewhat-superhuman systems to automate alignment research—alongside the automation of AI research in general, during the intelligence explosion—to figure out how to solve alignment to go the rest of the way.
(66) Page 116: More generally, the more we can develop good science now, the more we’ll be in a position to verify that things aren’t going off the rails during the intelligence explosion. Even having good metrics we can trust for superalignment is surprisingly difficult—but without reliable metrics during the intelligence explosion, we won’t know whether pressing on is safe or not.
Here are some of the main research bets I see for crossing the gap between human-level and somewhat-superhuman systems.
evaluation is easier than generation. We get some of the way “for free,” because it’s easier for us to evaluate outputs (especially for egregious misbehaviors) than it is to generate them ourselves. For example, it takes me months or years of hard work to write a paper, but only a couple hours to tell if a paper someone has written is any good (though perhaps longer to catch fraud). We’ll have teams of expert humans spend a lot of time evaluating every RLHF example, and they’ll be able to “thumbs down” a lot of misbehavior even if the AI system is somewhat smarter than them.
Scalable oversight. We can use AI assistants to help humans supervise other AI systems—the human-AI team being able to extend supervision farther than the human could alone.
(67) Page 117: generalization. Even with scalable oversight, we won’t be able to supervise AI systems on really hard problems, problems beyond human comprehension. However, we can study: how will the AI systems generalize from human supervision on easy problems (that we do understand and can supervise) to behave on the hard problems (that we can’t understand and can no longer supervise)?
For example, perhaps supervising a model to be honest in simple cases generalizes benignly to the model just being honest in general, even in cases where it’s doing extremely complicated things we don’t understand.
There’s a lot of reasons to be optimistic here: part of the magic of deep learning is that it often generalizes in benign ways (for example, RLHF’ing with only labels on English examples also tends to produce good behavior when it’s speaking French or Spanish, even if that wasn’t part of the training). I’m fairly optimistic that there will both be pretty simple methods that help nudge the models’ generalization in our favor, and that we can develop a strong scientific understanding that helps us predict when generalization will work and when it will fail. To a greater extent that for scalable oversight, the hope is that this will help with alignment even in the “qualitatively” superhuman case.
Here’s another way of thinking about this: if a superhuman model is misbehaving, say breaking the law, intuitively the model should already know that it’s breaking the law. Moreover, “is this breaking the law” is probably a pretty natural concept to the model—and it will be salient in the model’s representation space. The question then is: can we “summon” this concept from the model with only weak supervision?
(68) Page 118: interpretability. One intuitively-attractive way we’d hope to verify and trust that our AI systems are aligned is if we could understand what they’re thinking! For example, if we’re worried that AI systems are deceiving us or conspiring against us, access to their internal reasoning should help us detect that
I’m worried fully reverse-engineering superhuman AI systems will just be an intractable problem—similar, to, say “fully reverse engineering the human brain”—and I’d put this work mostly in the “ambitious moonshot for AI safety” rather than “default plan for muddling through” bucket.
(69) Page 119: “Top-down” interpretability. If mechanistic interpretability tries to reverse engineer neural networks “from the bottom up,” other work takes a more targeted, “top-down” approach, trying to locate information in a model without full understanding of how it is processed.
For example, we might try to build an “AI lie detector” by identifying the parts of the neural net that “light up” when an AI system is lying. This can be a lot more tractable (even if it gives less strong guarantees).
I’m increasingly bullish that top-down interpretability techniques will be a powerful tool—i.e., we’ll be able to build something like an “AI lie detector” —and without requiring fundamental breakthroughs in understanding neural nets.
Chain-of-thought interpretability. As mentioned earlier, I think it’s quite plausible that we’ll bootstrap our way to AGI with systems that “think out loud” via chains of thought.
There’s a ton of work to do here, however, if we wanted to rely on this. How do we ensure that the CoT remains legible?
(70) Page 120: adversarial testing and measurements. Along the way, it’s going to be critical to stress test the alignment of our systems at every step—our goal should be to encounter every failure mode in the lab before we encounter it in the wild.
(71) Page 121: But we also don’t have to solve this problem just on our own. If we manage to align somewhat-superhuman systems enough to trust them, we’ll be in an incredible position: we’ll have millions of automated AI researchers, smarter than the best AI researchers, at our disposal. Leveraging these army of automated researchers properly to solve alignment for even-more superhuman systems will be decisive.
Superdefense
“Getting alignment right” should only be the first of many layers of defense during the intelligence explosion. Alignment will be hard; there will be failures along the way. If at all possible, we need to be in a position where alignment can fail—but failure wouldn’t be catastrophic. This could mean:
Security. An airgapped cluster is the first layer of defense against superintelligence attempting to self-exfiltrate and doing damage in the real world. And that’s only the beginning; we’ll need much more extreme security against model self-exfiltration across the board, from hardware encryption to many-key signoff.
Monitoring. If our AI systems are up to something fishy or malevolent—or a rogue employee tries to use them for unauthorized activities—we need to be able to catch it.
Targeted capability limitations. As much as possible, we should try to limit the model’s capabilities in targeted ways that reduce fallout from failure.
Targeted training method restrictions. There are likely some ways of training models that are inherently riskier—more likely to produce severe misalignments—than others. For example, imitation learning seems relatively safe (hard to see how that would lead to models that have dangerous long term internal goals), while we should avoid long-horizon outcome-based RL.
Will these be foolproof? Not at all. True superintelligence is likely able to get around most-any security scheme for example. Still, they buy us a lot more margin for error—and we’re going to need any margin we can get.
(72) Page 125: I think there’s a pretty reasonable shot that “the default plan” to align “somewhat-superhuman” systems will mostly work. Of course, it’s one thing to speak about a “default plan” in the abstract—it’s another if the team responsible for executing that plan is you and your 20 colleagues (much more stressful!)
There’s still an incredibly tiny number of people seriously working on solving this problem, maybe a few dozen serious researchers. Nobody’s on the ball!
The intelligence explosion will be more like running a war than launching a product. We’re not on track for superdefense, for an airgapped cluster or any of that; I’m not sure we would even realize if a model self-exfiltrated. We’re not on track for a sane chain of command to make any of these insanely high-stakes decisions, to insist on the very-high-confidence appropriate for superintelligence, to make the hard decisions to take extra time before launching the next training run to get safety right or dedicate a large majority of compute to alignment research, to recognize danger ahead and avert it rather than crashing right into it. Right now, no lab has demonstrated much of a willingness to make any costly tradeoffs to get safety right (we get lots of safety committees, yes, but those are pretty meaningless). By default, we’ll probably stumble into the intelligence explosion and have gone through a few OOMs before people even realize what we’ve gotten into.
We’re counting way too much on luck here
Section 3d: The Free World Must Prevail
(73) Page 126 (start of IIId): Superintelligence will give a decisive economic and military advantage. China isn’t at all out of the game yet. In the race to AGI, the free world’s very survival will be at stake. Can we maintain our preeminence over the authoritarian powers? And will we manage to avoid self-destruction along the way?
(74) Page 127: Our generation too easily takes for granted that we live in peace and freedom. And those who herald the age of AGI in SF too often ignore the elephant in the room: superintelligence is a matter of national security, and the United States must win.
The advent of superintelligence will put us in a situation unseen since the advent of the atomic era: those who have it will wield complete dominance over those who don’t.
A lead of a year or two or three on superintelligence could mean as utterly decisive a military advantage as the US coalition had against Iraq in the Gulf War. A complete reshaping of the military balance of power will be on the line.
Of course, we don’t know the limits of science and the many frictions that could slow things down. But no godlike advances are necessary for a decisive military advantage. And a billion superintelligent scientists will be able to do a lot. It seems clear that within a matter of years, pre-superintelligence militaries would become hopelessly outclassed.
To be even clearer: it seems likely the advantage conferred by superintelligence would be decisive enough even to preemptively take out an adversary’s nuclear deterrent.
It would simply be no contest. If there is a rapid intelligence explosion, it’s plausible a lead of mere months could be decisive.
(for example, the Yi-34B architecture seems to have essentially the Llama2 architecture, with merely a few lines of code changed)
That’s all merely a prelude, however. If and when the CCP wakes up to AGI, we should expect extraordinary efforts on the part of the CCP to compete. And I think there’s a pretty clear path for China to be in the game: outbuild the US and steal the algorithms.
1a. Chips: China now seems to have demonstrated the ability to manufacture 7nm chips. While going beyond 7nm will be difficult (requiring EUV), 7nm is enough! For reference, 7nm is what Nvidia A100s used. The indigenous Huawei Ascend 910B, based on the SMIC 7nm platform, seems to only be ~2-3x worse on performance/$ than an equivalent Nvidia chip would be.
1b. Outbuilding the US: The binding constraint on the largest training clusters won’t be chips, but industrial mobilization— perhaps most of all the 100GW of power for the trillion-dollar cluster. But if there’s one thing China can do better than the US it’s building stuff.
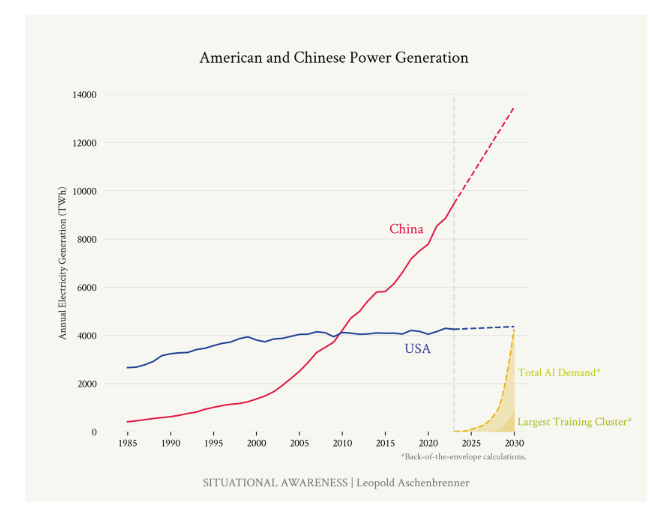
(75) Page 134: To date, US tech companies have made a much bigger bet on AI and scaling than any Chinese efforts; consequently, we are well ahead. But counting out China now is a bit like counting out Google in the AI race when ChatGPT came out in late 2022.
(76) Page 134: A dictator who wields the power of superintelligence would command concentrated power unlike any we’ve ever seen. In addition to being able to impose their will on other countries, they could enshrine their rule internally.
To be clear, I don’t just worry about dictators getting superintelligence because “our values are better.” I believe in freedom and democracy, strongly, because I don’t know what the right values are.
Superintelligence will give those who wield it the power to crush opposition, dissent, and lock in their grand plan for humanity. It will be difficult for anyone to resist the terrible temptation to use this power. I hope, dearly, that we can instead rely on the wisdom of the Framers—letting radically different values flourish, and preserving the raucous plurality that has defined the American experiment.
(77) Page 136: Maintaining a healthy lead will be decisive for safety
On the historical view, the greatest existential risk posed by AGI is that it will enable us to develop extraordinary new means of mass death. This time, these means could even proliferate to become accessible to rogue actors or terrorists.
(78) Page 138: Some hope for some sort of international treaty on safety. This seems fanciful to me. The world where both the CCP and USG are AGI-pilled enough to take safety risk seriously is also the world in which both realize that international economic and military predominance is at stake, that being months behind on AGI could mean being permanently left behind.
Perhaps most importantly, a healthy lead gives us room to maneuver: the ability to “cash in” parts of the lead, if necessary, to get safety right, for example by devoting extra work to alignment during the intelligence explosion.
(79) Page 139: Slowly, the USG is starting to move. The export controls on American chips are a huge deal, and were an incredibly prescient move at the time. But we have to get serious across the board.
The US has a lead. We just have to keep it. And we’re screwing that up right now. Most of all, we must rapidly and radically lock down the AI labs.
Section 4: The Project
(80) Page 141 (Start of Part 4): As the race to AGI intensifies, the national security state will get involved. The USG will wake from its slumber, and by 27/28 we’ll get some form of government AGI project. No startup can handle superintelligence. Somewhere in a SCIF, the endgame will be on.
(81) Page 142: I find it an insane proposition that the US government will let a random SF startup develop superintelligence. Imagine if we had developed atomic bombs by letting Uber just improvise.
It is a delusion of those who have unconsciously internalized our brief respite from history that this will not summon more primordial forces. Like many scientists before us, the great minds of San Francisco hope that they can control the destiny of the demon they are birthing. Right now, they still can; for they are among the few with situational awareness, who understand what they are building. But in the next few years, the world will wake up. So too will the national security state. History will make a triumphant return.
In any case, my main claim is not normative, but descriptive. In a few years, The Project will be on.
(82) Page 145: And somewhere along here, we’ll get the first genuinely terrifying demonstrations of AI: perhaps the oft-discussed “helping novices make bioweapons,” or autonomously hacking critical systems, or something else entirely. It will become clear: this technology will be an utterly decisive military technology.
As with Covid, and even the Manhattan Project, the government will be incredibly late and hamfisted.
(83) Page 146: There are many ways this could be operationalized in practice. To be clear, this doesn’t need to look like literal nationalization, with AI lab researchers now employed by the military or whatever (though it might!). Rather, I expect a more suave orchestration. The relationship with the DoD might look like the relationship the DoD has with Boeing or Lockheed Martin.
Perhaps via defense contracting or similar, a joint venture between the major cloud compute providers, AI labs, and the government is established, making it functionally a project of the national security state. Much like the AI labs “voluntarily” made commitments to the White House in 2023, Western labs might more-or-less “voluntarily” agree to merge in the national effort.
(84) Page 147: Simply put, it will become clear that the development of AGI will fall in a category more like nukes than the internet. Yes, of course it’ll be dual-use—but nuclear technology was dual use too.
It seems pretty clear: this should not be under the unilateral command of a random CEO. Indeed, in the private-labs-developing-superintelligence world, it’s quite plausible individual CEOs would have the power to literally coup the US government.
(85) Page 150: Safety
Simply put: there are a lot of ways for us to mess this up— from ensuring we can reliably control and trust the billions of superintelligent agents that will soon be in charge of our economy and military (the superalignment problem), to controlling the risks of misuse of new means of mass destruction.
Some AI labs claim to be committed to safety: acknowledging that what they are building, if gone awry, could cause catastrophe and promising that they will do what is necessary when the time comes. I do not know if we can trust their promise enough to stake the lives of every American on it. More importantly, so far, they have not demonstrated the competence, trustworthiness, or seriousness necessary for what they themselves acknowledge they are building.
At core, they are startups, with all the usual commercial incentives.
(86) Page 151: One answer is regulation. That may be appropriate in worlds in which AI develops more slowly, but I fear that regulation simply won’t be up to the nature of the challenge of the intelligence explosion. What’s necessary will be less like spending a few years doing careful evaluations and pushing some safety standards through a bureaucracy. It’ll be more like fighting a war.
We’ll face an insane year in which the situation is shifting extremely rapidly every week, in which hard calls based on ambiguous data will be life-or-death, in which the solutions—even the problems themselves—won’t be close to fully clear ahead of time but come down to competence in a “fog of war,” which will involve insane tradeoffs like “some of our alignment measurements are looking ambiguous, we don’t really understand what’s going on anymore, it might be fine but there’s some warning signs that the next generation of superintelligence might go awry, should we delay the next training run by 3 months to get more confidence on safety—but oh no, the latest intelligence reports indicate China stole our weights and is racing ahead on their own intelligence explosion, what should we do?”.
I’m not confident that a government project would be competent in dealing with this—but the “superintelligence developed by startups” alternative seems much closer to “praying for the best” than commonly recognized.
(87) Page 153: We’ll need the government project to win the race against the authoritarian powers—and to give us the clear lead and breathing room necessary to navigate the perils of this situation.
We will want to bundle Western efforts: bring together our best scientists, use every GPU we can find, and ensure the trillions of dollars of cluster buildouts happen in the United States. We will need to protect the datacenters against adversary sabotage, or outright attack.
Perhaps, most of all, it will take American leadership to develop— and if necessary, enforce—a nonproliferation regime.
Ultimately, my main claim here is descriptive: whether we like it or not, superintelligence won’t look like an SF startup, and in some way will be primarily in the domain of national security. I’ve brought up The Project a lot to my San Francisco friends in the past year. Perhaps what’s surprised me most is how surprised most people are about the idea. They simply haven’t considered the possibility. But once they consider it, most agree that it seems obvious.
(88) Page 154: Perhaps the most important free variable is simply whether the inevitable government project will be competent. How will it be organized? How can we get this done? How will the checks and balances work, and what does a sane chain of command look like? Scarcely any attention has gone into figuring this out. Almost all other AI lab and AI governance politicking is a sideshow. This is the ballgame.
Part 5: Parting Thoughts (Quoted in Full)
(89) Conclusion: And so by 27/28, the endgame will be on. By 28/29 the intelligence explosion will be underway; by 2030, we will have summoned superintelligence, in all its power and might.
Whoever they put in charge of The Project is going to have a hell of a task: to build AGI, and to build it fast; to put the American economy on wartime footing to make hundreds of millions of GPUs; to lock it all down, weed out the spies, and fend off all-out attacks by the CCP; to somehow manage a hundred million AGIs furiously automating AI research, making a decade’s leaps in a year, and soon producing AI systems vastly smarter than the smartest humans; to somehow keep things together enough that this doesn’t go off the rails and produce rogue superintelligence that tries to seize control from its human overseers; to use those superintelligences to develop whatever new technologies will be necessary to stabilize the situation and stay ahead of adversaries, rapidly remaking US forces to integrate those; all while navigating what will likely be the tensest international situation ever seen. They better be good, I’ll say that.
For those of us who get the call to come along for the ride, it’ll be . . . stressful. But it will be our duty to serve the free world—and all of humanity. If we make it through and get to look back on those years, it will be the most important thing we ever did. And while whatever secure facility they find probably won’t have the pleasantries of today’s ridiculouslyovercomped-AI-researcher-lifestyle, it won’t be so bad. SF already feels like a peculiar AI-researcher-college-town; probably this won’t be so different. It’ll be the same weirdly-small circle sweating the scaling curves during the day and hanging out over the weekend, kibitzing over AGI and the lab-politics-of-the-day.
Except, well—the stakes will be all too real.
See you in the desert, friends.
The biggest problem I see with Aschenbrenner’s argument, which he acknowledges, is that we seem to be running out of data for training. It’s certainly a solvable problem but I don’t know whether it can be solved in an amount of time that conforms to his prediction of AGI by 2027-28.
Thanks Zvi for spending the neural processing cycles so the rest of us don't have to..
My 2¢: As one of the approximately 78% of the world's population who lives outside the US and China, it's the naive two-player, zero-sum, "everyone else is an NPC", blue-pilled US exceptionalism underpinning the analysis which seems the weakest point in the whole argument. (And coincidentally also a deep generator function for a lot of what else is fucked up on the planet...) The rest of the world won't willingly buy into another Hiroshima/Nagasaki outcome. If the prize is so valuable, superintelligence will be plurality not singleton, other players will play outside the US and Chinese "Projects" and other key innovations/variations/mutations of SuperAI will arise... think a diverse Darwinian evolutionary surface rather than top-down militarised monoculture... There's some deep psychology in LA's personal US naturalisation story that bears scrutiny....