The Gemini 1.5 Report

This post goes over the extensive report Google put out on Gemini 1.5.
There are no important surprises. Both Gemini Pro 1.5 and Gemini Flash are ‘highly capable multimodal models incorporating a novel mixture-of-experts architecture’ and various other improvements. They are solid models with solid performance. It can be useful and interesting to go over the details of their strengths and weaknesses.
The biggest thing to know is that Google improves its models incrementally and silently over time, so if you have not used Gemini in months, you might be underestimating what it can do.
I’m hitting send and then jumping on a plane to Berkeley. Perhaps I will see you there over the weekend. That means that if there are mistakes here, I will be slower to respond and correct them than usual, so consider checking the comments section.
Practical Questions First
The practical bottom line remains the same. Gemini Pro 1.5 is an excellent 4-level model. Its big advantage is its long context window, and it is good at explanations and has integrations with some Google services that I find useful. If you want a straightforward, clean, practical, ‘just the facts’ output and that stays in the ‘no fun zone’ then Gemini could be for you. I recommend experimenting to find out when you do and don’t prefer it versus GPT-4o and Claude Opus, and will continue to use a mix of all three and keep an eye on changes.
How is the improvement process going?
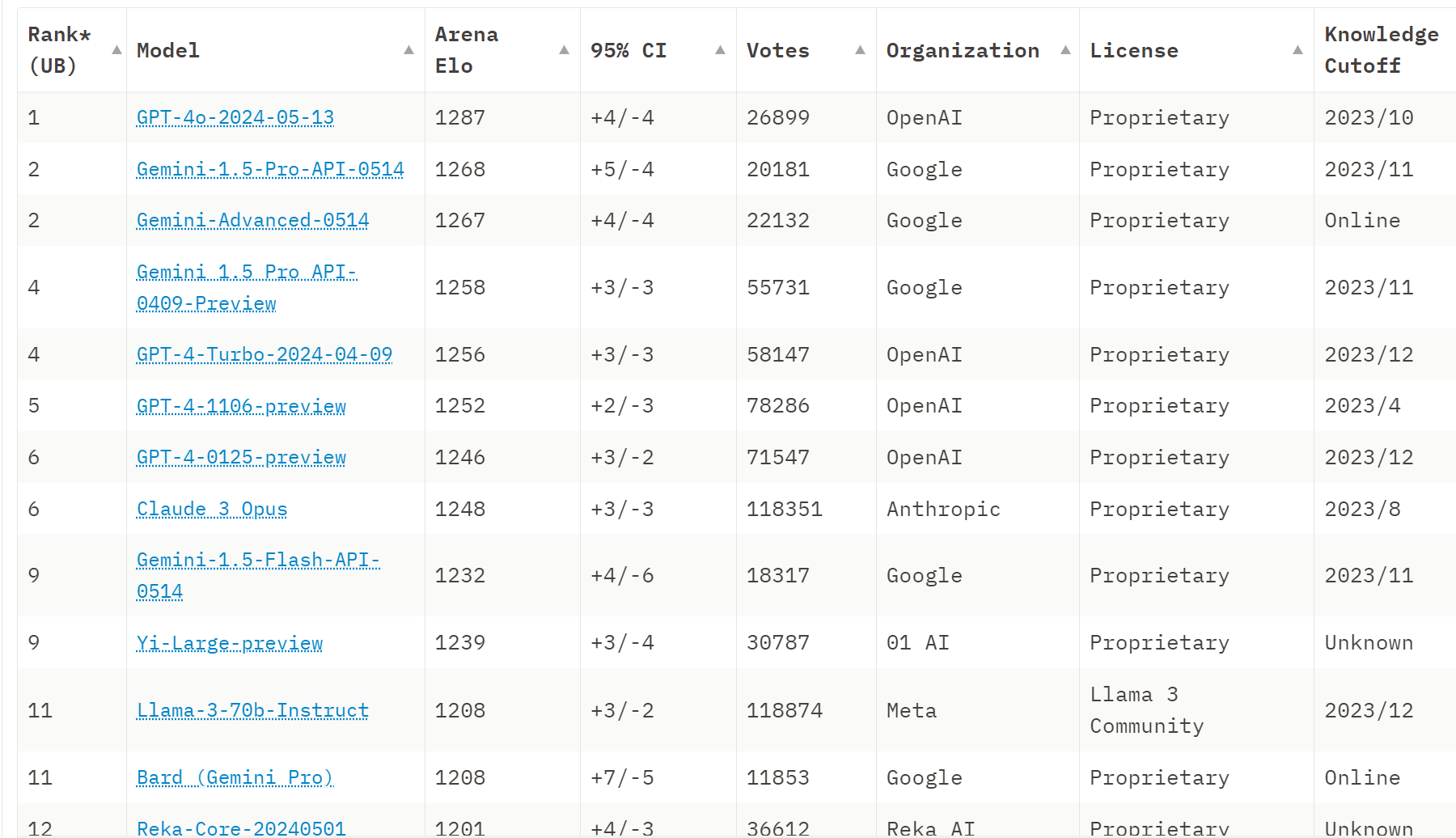
Imsys.org: Big news – Gemini 1.5 Flash, Pro and Advanced results are out!🔥
- Gemini 1.5 Pro/Advanced at #2, closing in on GPT-4o
- Gemini 1.5 Flash at #9, outperforming Llama-3-70b and nearly reaching GPT-4-0125 (!)
Pro is significantly stronger than its April version. Flash’s cost, capabilities, and unmatched context length make it a market game-changer!
More excitingly, in Chinese, Gemini 1.5 Pro & Advanced are now the best #1 model in the world. Flash becomes even stronger!
We also see new Gemini family remains top in our new "Hard Prompts" category, which features more challenging, problem-solving user queries.
Here is the overall leaderboard:
Oriol Vinyals (VP of Research, DeepMind): Today we have published our updated Gemini 1.5 Model Technical Report. As Jeff Dean highlights [in the full report this post analyzes], we have made significant progress in Gemini 1.5 Pro across all key benchmarks; TL;DR: 1.5 Pro > 1.0 Ultra, 1.5 Flash (our fastest model) ~= 1.0 Ultra.
As a math undergrad, our drastic results in mathematics are particularly exciting to me!
As an overall take, the metrics in the report say this is accurate. The Arena benchmarks suggest that Flash is not as good as Ultra in terms of output quality, but it makes up for that several times over with speed and cost. Gemini 1.5 Pro’s Arena showing is impressive, midway between Opus and GPT-4o. For my purposes, Opus is underrated here and GPT-4o is overrated, and I would have all three models close.
All right, on to the report. I will start with the big Gemini advantages.
Speed Kills
One update I have made recently is to place a lot more emphasis on speed of response. This will be key for the new conversational audio modes, and is a great aid even with text. Often lower quality is worth it to get faster response, so long as you know when to make an exception.
Indeed, I have found Claude Opus for my purposes usually gives the best responses. The main reason I still often don’t use it is speed or sometimes style, and occasionally Gemini’s context window.
How fast is Gemini Flash? Quite fast. Gemini Pro is reasonably fast too.
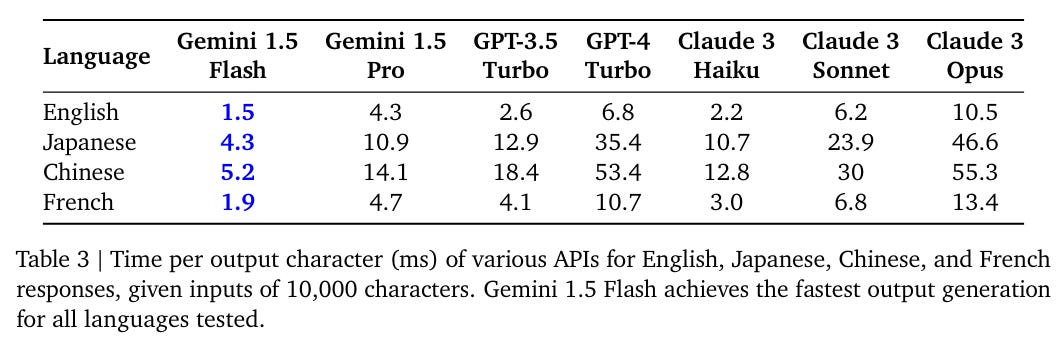
GPT-4o is slightly more than twice as fast as GPT-4-Turbo, making it modestly faster than Gemini 1.5 Pro in English.
Very Large Context Windows
One place Google is clearly ahead is context window size.
Both Pro and Flash can potentially handle context windows of up to 10 million tokens.
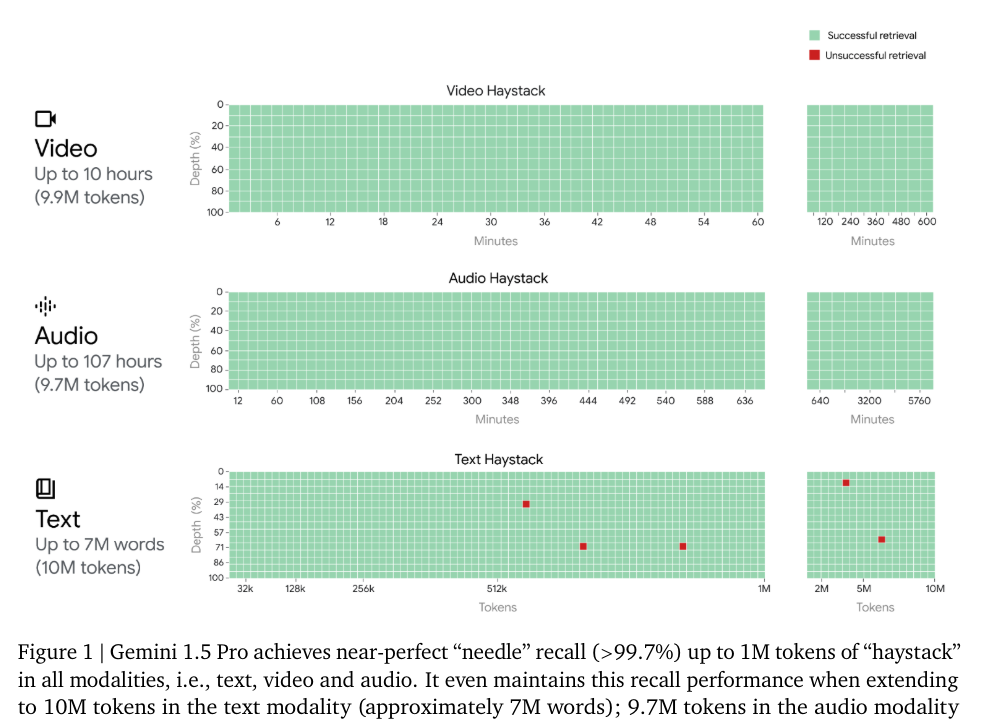
The actual upper bound is that cost and speed scale with context window size. That is why users are limited to 1-2 million tokens, and only a tiny minority of use cases use even a major fraction of that.
Relative Performance within the Gemini Family
Gemini 1.5 Flash is claimed to outperform Gemini 1.0 Pro, despite being vastly smaller, cheaper and faster, including training costs.
Gemini 1.5 Pro is claimed to surpass Gemini 1.0 Ultra, despite being vastly smaller, cheaper and faster, including training costs.
Google’s strategy has been to incrementally improve Gemini (and previously Bard) over time. They claim the current version is substantially better than the February version.
Here they use ‘win rates’ on various benchmarks.
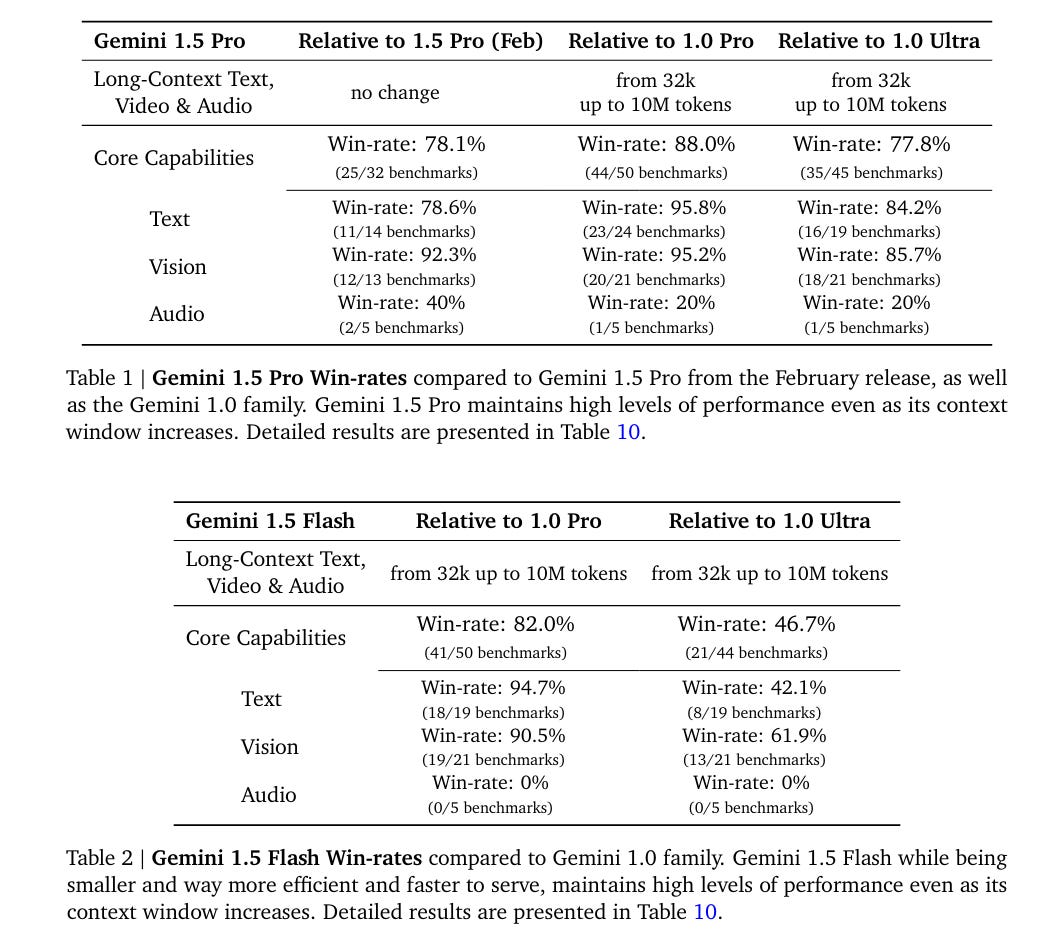
The relative text and vision win rates are impressive.
On audio the old 1.5 Pro is still on top, and 1.0 Pro is still beating both the new 1.5 Pro and 1.5 Flash. They do not explain what happened there.
There are several signs throughout that the audio processing has taken a hit, but in 9.2.1 they say ‘efficient processing of audio files at scale may introduce individual benefits’ and generally seem to be taking the attitude audio performance is improved. It would be weird if audio performance did not improve. I notice confusion there.
Here is a bold claim.
In more realistic multimodal long-context benchmarks which require retrieval and reasoning over multiple parts of the context (such as answering questions from long documents or long videos), we also see Gemini 1.5 Pro outperforming all competing models across all modalities even when these models are augmented with external retrieval methods.
Here are some admittedly selected benchmarks:
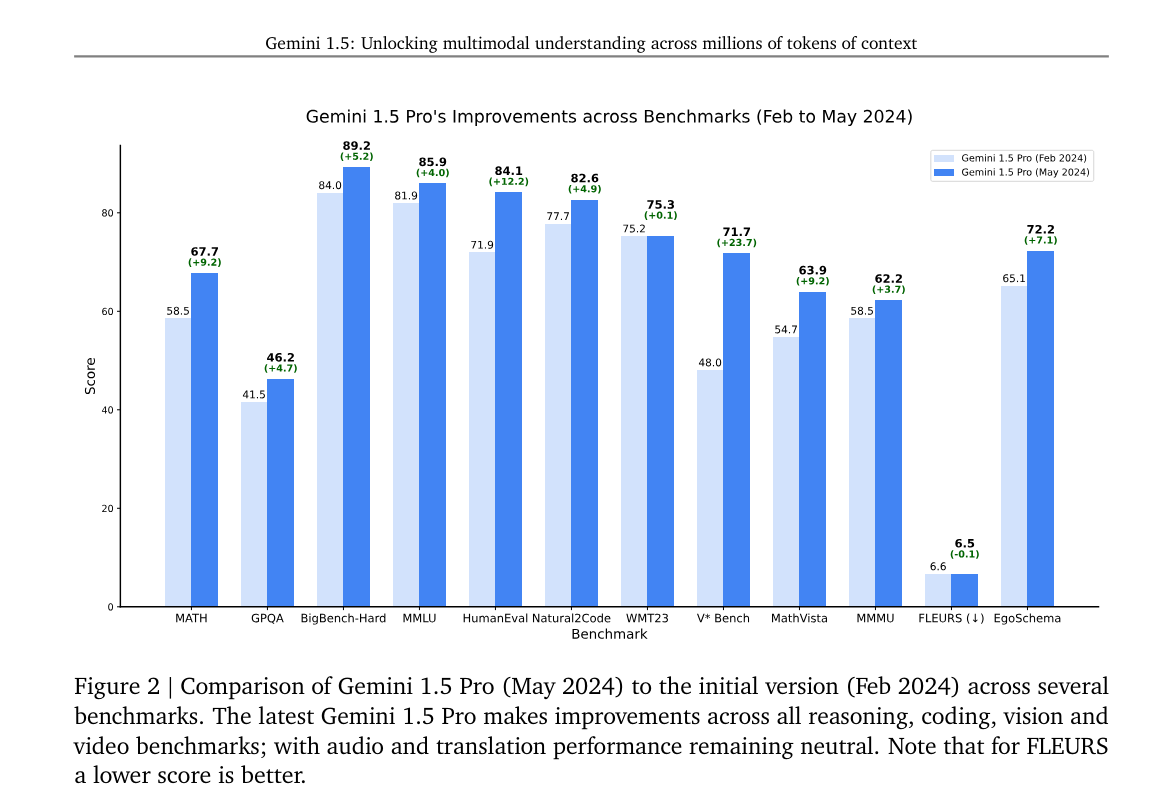
Gemini Flash and the Future Flash-8B
Gemini Pro 1.5 is neat. Depending on what you are looking to do, it is roughly on par with its rivals Claude Opus and GPT-4o.
Gemini Flash 1.5 is in many ways more impressive. It seems clearly out in front in its weight class. On Arena is it in a tie for 9th, only slightly behind Claude Opus. Everything ranked above it is from Google, Anthropic or OpenAI and considerably larger, although Flash is established as somewhat larger than 8B.
The new Flash-8B is still under active development, aimed at various lightweight tasks and those requiring low latency. The question here is how close it can get to the full-size Flash. Here is where they are now.
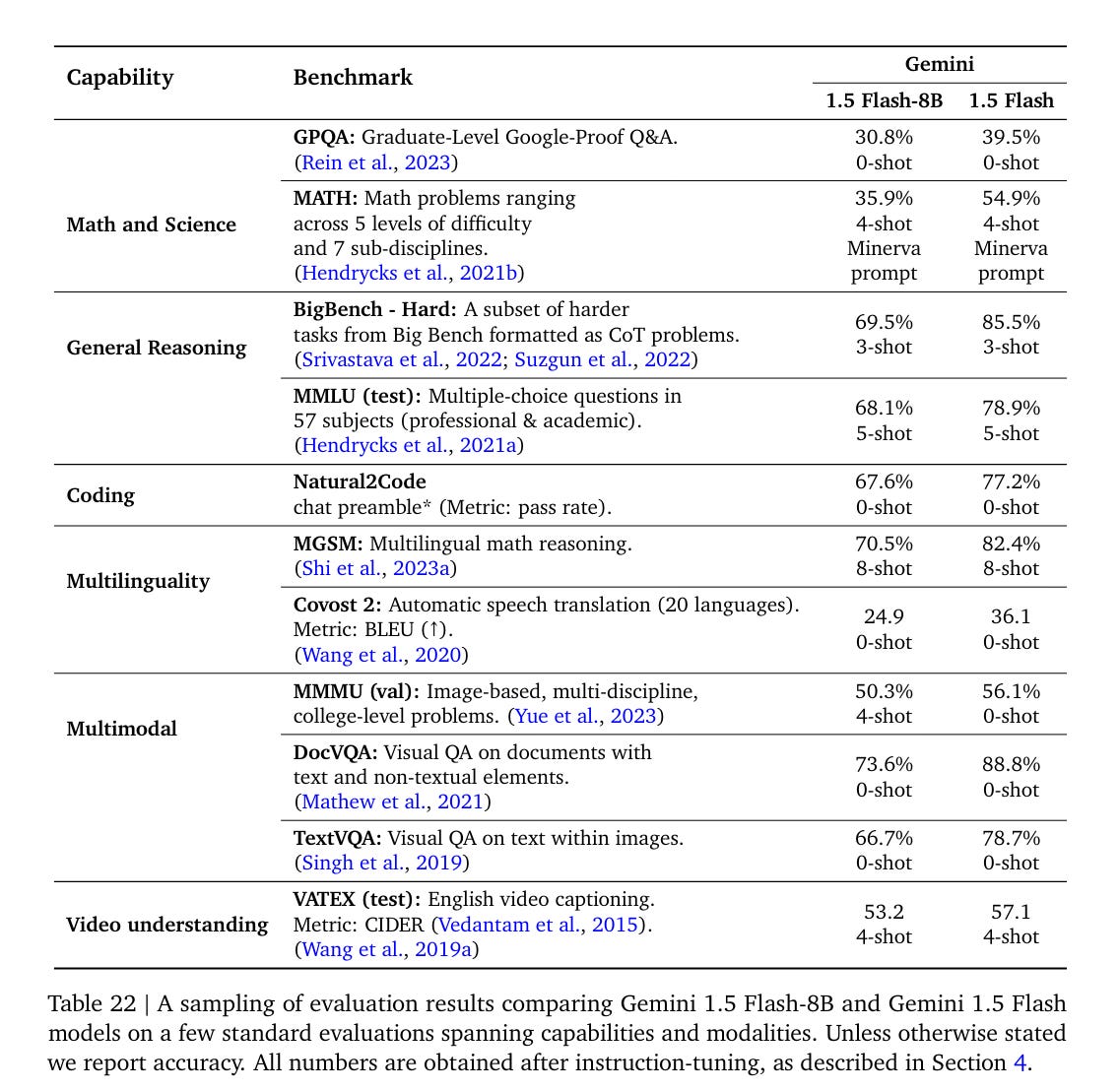
That is a clear step down, but it is not that large a step down in the grand scheme if these are representative, especially if Flash-8B is focusing on and mostly used for practical efficiencies and the most common tasks.
Comparing this to Llama-8B, we see inferior MMLU (Llama-3 was 66.6) but superior Big-Bench (llama-3 was 61.1).
New and Improved Evaluations
Section 5 on evaluations notes that models are becoming too good to be well-measured by existing benchmarks. The old benchmarks do not use long context windows, they focus on compact tasks within a modality and generally are becoming saturated.
A cynical response would be ‘that is your excuse that you did not do that great on the traditional evaluations,’ and also ‘that lets you cherry-pick the tests you highlight.’
Those are highly reasonable objections. It would be easy to make these models look substantially better, or up to vastly worse, if Google wanted to do that. My presumption is they want to make the models look good, and there is some selection involved, but that Google is at heart playing fair. They are still covering most of the ‘normal’ benchmarks and it would be easy enough for outsiders to run such tests.
So what are they boasting about?
In 5.1 they claim Gemini 1.5 Pro can answer specific queries about very large (746k token) codebases, or locate a scene in Les Miserables from a hand drawn sketch, or get to-the-second time stamped information about a 45-minute movie.
How quickly we get used to such abilities. Ho hum. None of that is new.
In 5.2 they talk about evaluations for long context windows, since that is one of Gemini’s biggest advantages. They claim 99.7% recall at one million tokens, and 99.2% at ten million for Gemini Pro. For Gemini Flash at two million tokens they claim 100% recall on text, 99.8% on video and 99.1% on audio. I notice those don’t line up but the point is this is damn good recall however you look at it.
In 5.2.1.1 they find that knowing more previous tokens monotonically increases prediction accuracy of remaining tokens within a work, up to 10M tokens. Not a surprise, and unclear how to compare this to other models. Label your y-axis.
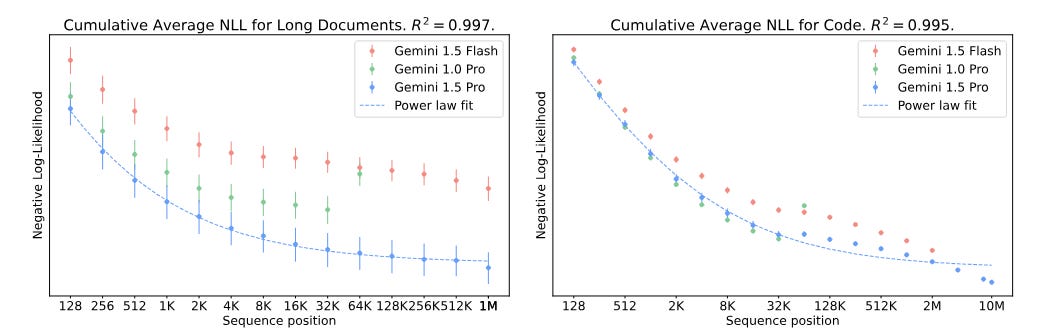
In 5.2.1.2 and 5.2.1.3 they do text and video haystack tests, which go very well for all models tested, with Gemini 1.5 Pro extending its range beyond where rivals run out of context window space. In the video test the needle is text on the screen for one frame.
In 5.2.1.4 they do an audio test, with the keyword being spoken. Even up to 107 hours of footage Gemini Pro gets it right every time and Flash scored 98.7%, versus 94.5% for whisper plus GPT-4 up to 11 hours. This was before GPT-4o.
This is clearly a highly saturated benchmark. For 5.2.1.5 they test hiding multiple needles within the haystack. When you insert 100 needles and require going 100 for 100, that is going to crimp one’s style.
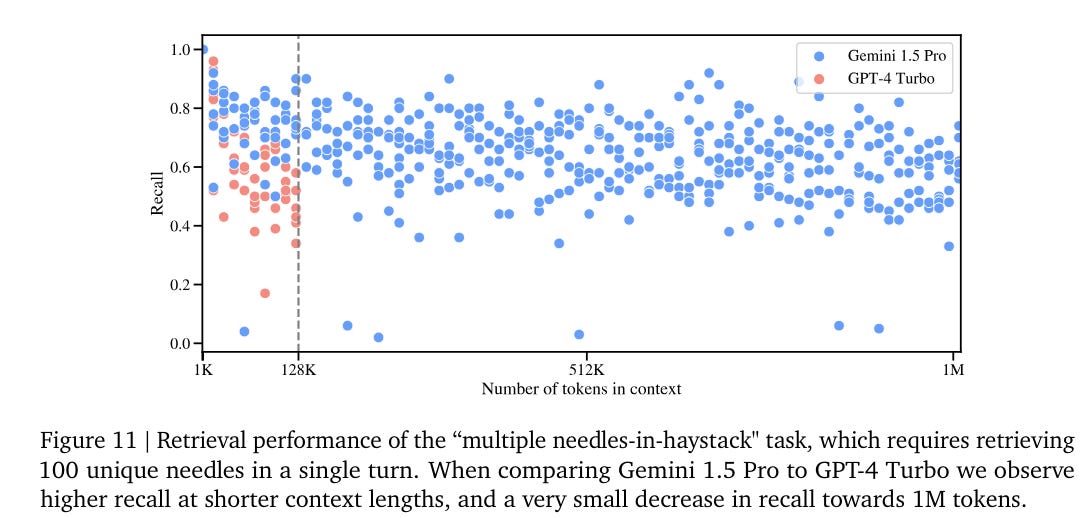
Even for GPT-4-Turbo that is very good recall, given you need to get all 100 items correct. Going about 50% on that means you’re about 99.3% on each needle, if success on different needles within a batch is uncorrelated.
Then they try adding other complexities, via a test called MRCR, where the model has to do things like retrieve the first instance of something.
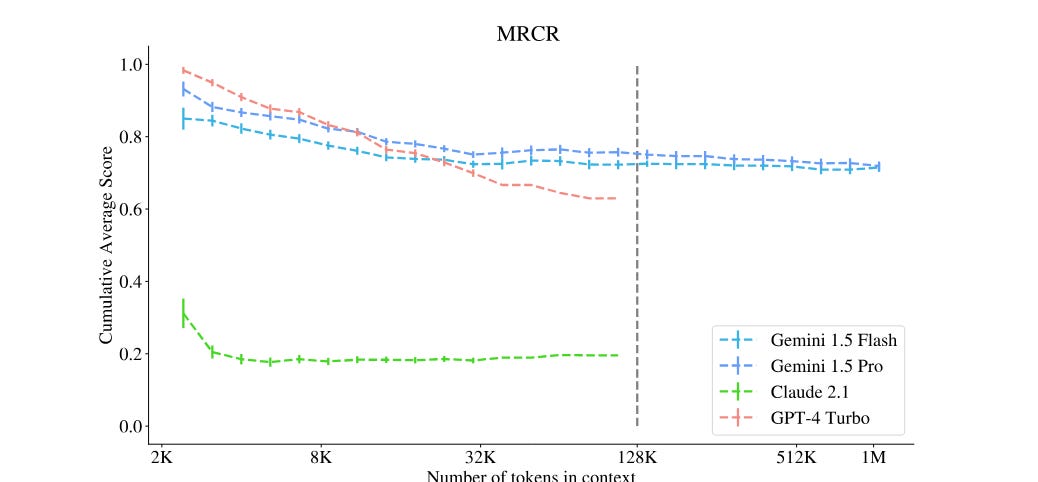
The most interesting result is perhaps the similarity of Pro to Flash. Whatever is enabling this capability is not tied to model size.
5.2.2 aims to measure long-context practical multimodal tasks.
In 5.2.2.1 the task is learning to translate a new language from one book (MTOB). It seems we will keep seeing the Kalamang translation task.
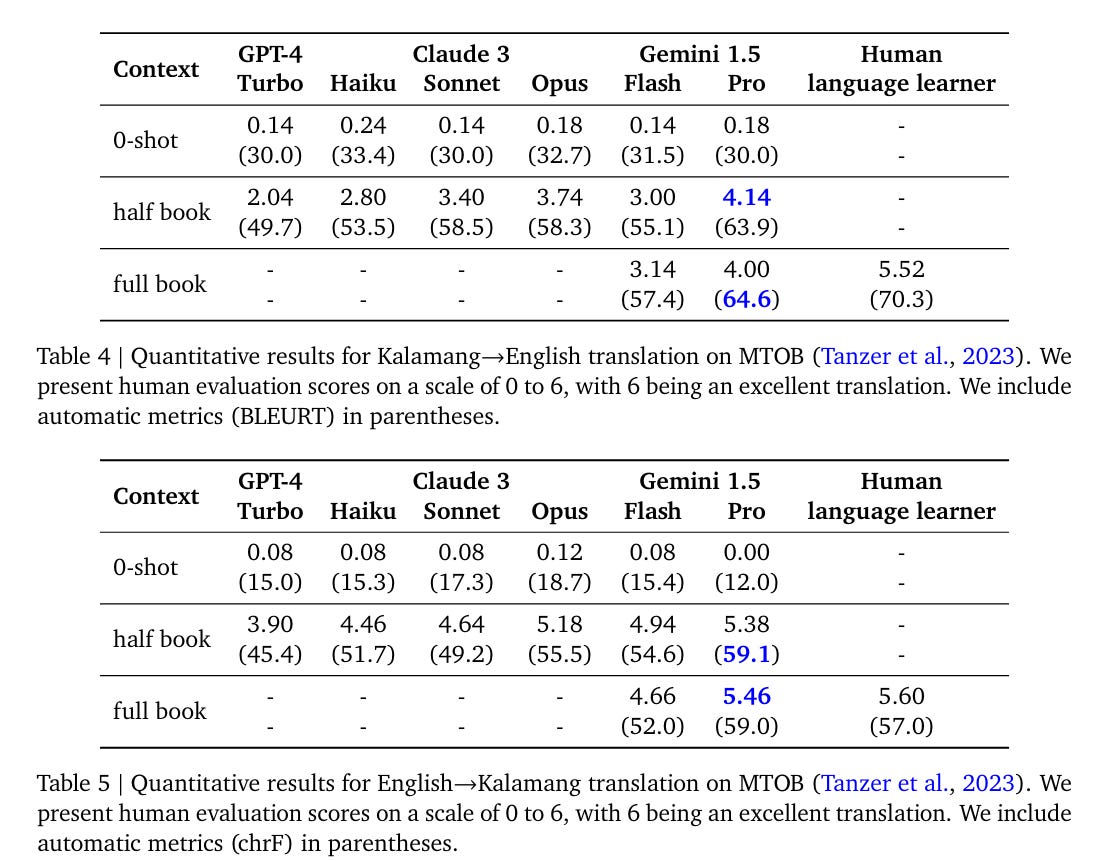
I find it highly amusing that the second half of the grammar book is unhelpful. I’d love to see a human language learner’s score when they don’t get access to the second half of the grammar book either.
This is clearly a relative victory for Gemini Pro 1.5, with the mystery being what is happening with the second half of the grammar book being essentially worthless.
In 5.2.2.2 we step up to transcribing speech in new languages. The results clearly improve over time but there is no baseline to measure this against.
In 5.2.2.3 Gemini Pro impresses in translating low-resource languages via in-context learning, again without a baseline. Seems like a lot of emphasis on learning translation, but okay, sure.
In 5.2.2.4 questions are asked about Les Miserables, and once again I have no idea from what is described here whether to be impressed.
In 5.2.2.5 we get audio transcription over long contexts with low error rates.

In 5.2.2.6 we have long context video Q&A. They introduce a new benchmark, 1H-VideoQA, with 125 multiple choice questions over public videos 40-105 minutes long.
This test does seem to benefit from a lot of information, so there is that:
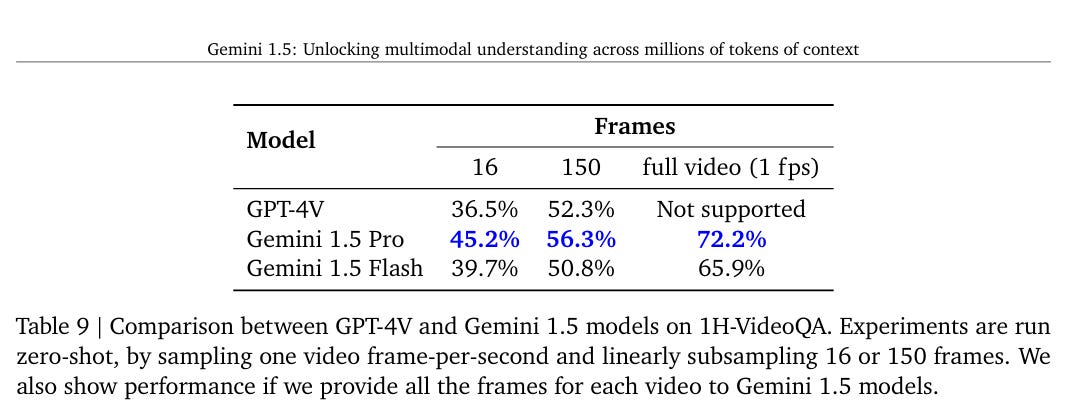
Once again we are ahead of GPT-4V, for what that is worth, even before the longer context windows. That doesn’t tell us about GPT-4o.
In 5.2.2.7 we get to something more relevant, in-context planning, going to a bunch of planning benchmarks. Look at how number go more up.
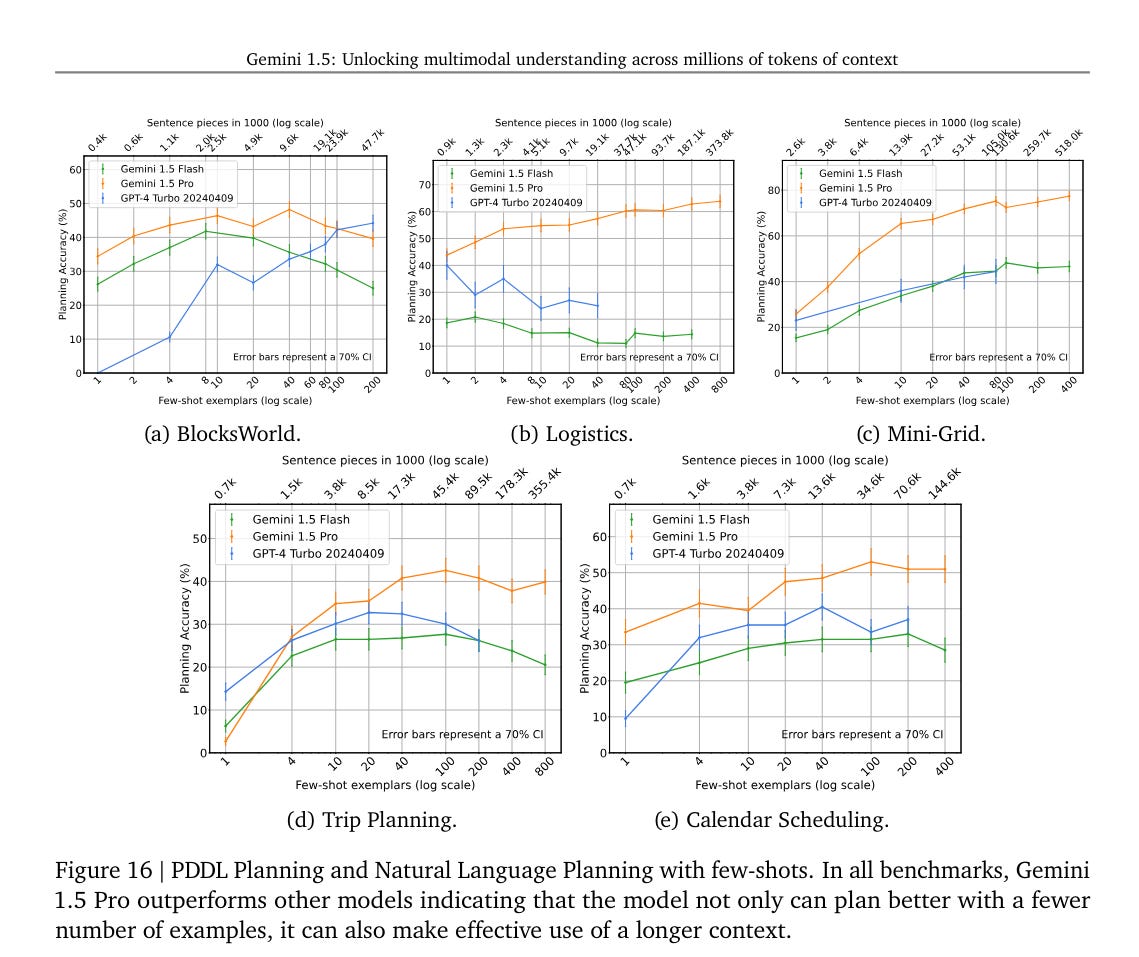
How good is this? Presumably it is better. No idea how much meaningfully better.
In 5.2.2.8 they try unstructured multimodal data analytics, and find Gemini constitutes an improvement over GPT-4 Turbo for an image analysis task, and that Gemini’s performance increases with more images whereas GPT-4-Turbo’s performance declines.
What to make of all this? It seems at least partly chosen to show off where the model is strong, and what is enabled by its superior context window. It all seems like it boils down to ‘Gemini can actually make use of long context.’ Which is good, but far from sufficient to evaluate the model.
Core Capability Evaluations
That is what Google calls the standard short-context style of tests across the three modalities of text, audio and video. Some are standard, some are intentionally not shared.
Overall, yes, clear improvement in the last few months.
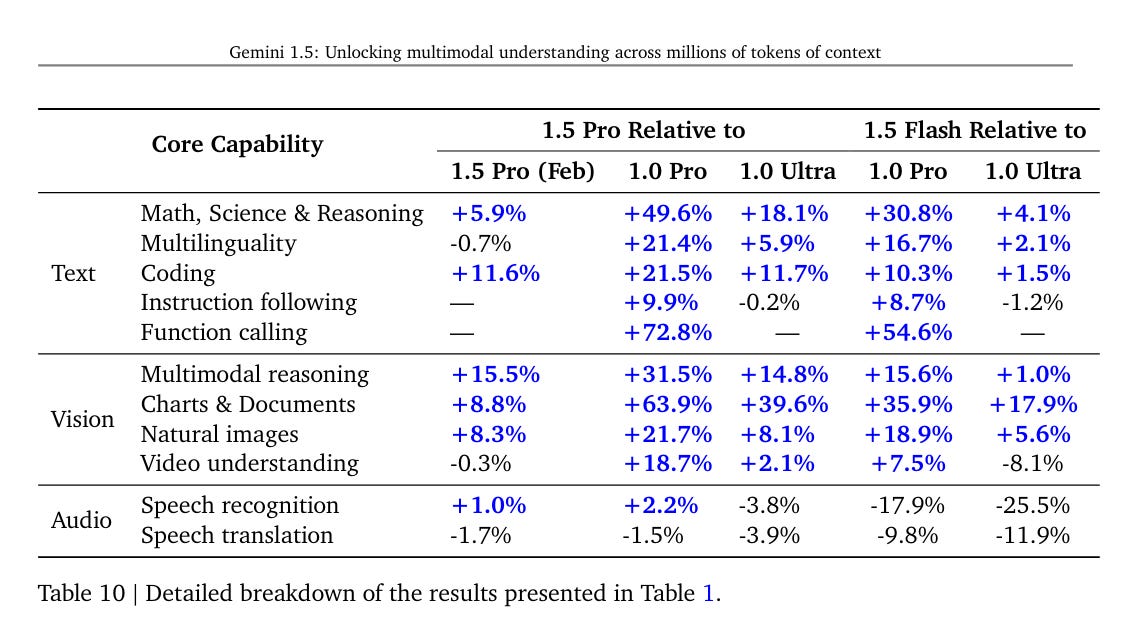
There is clear improvement in the results reported for math, science, general reasoning, code and multilinguality, as always the new hidden benchmarks are a ‘trust us’ kind of situation.
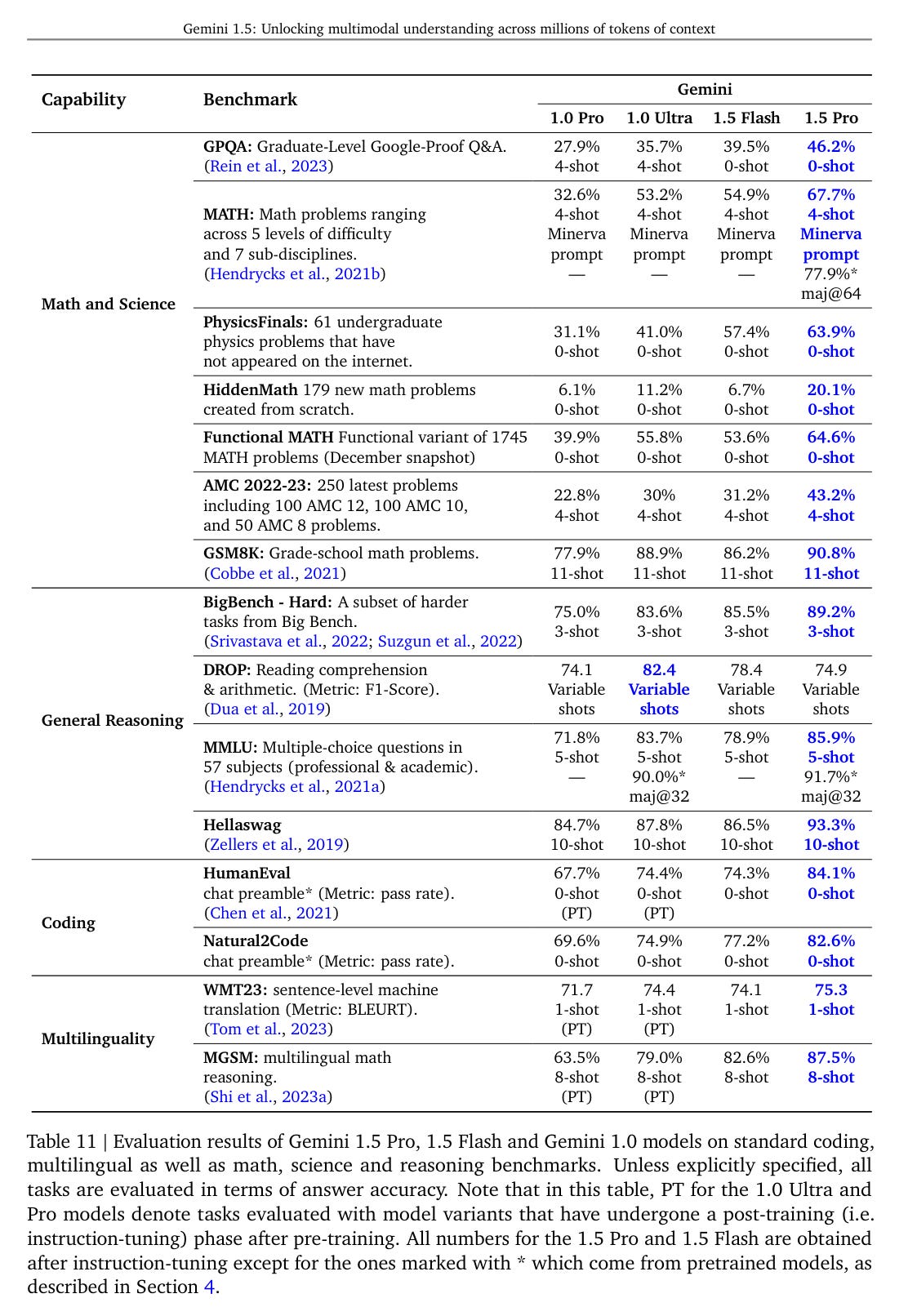
Next they try function calling. For simple stuff it seems things were already saturated, for harder questions we see big jumps, for the shortest prompts Ultra is still ahead.
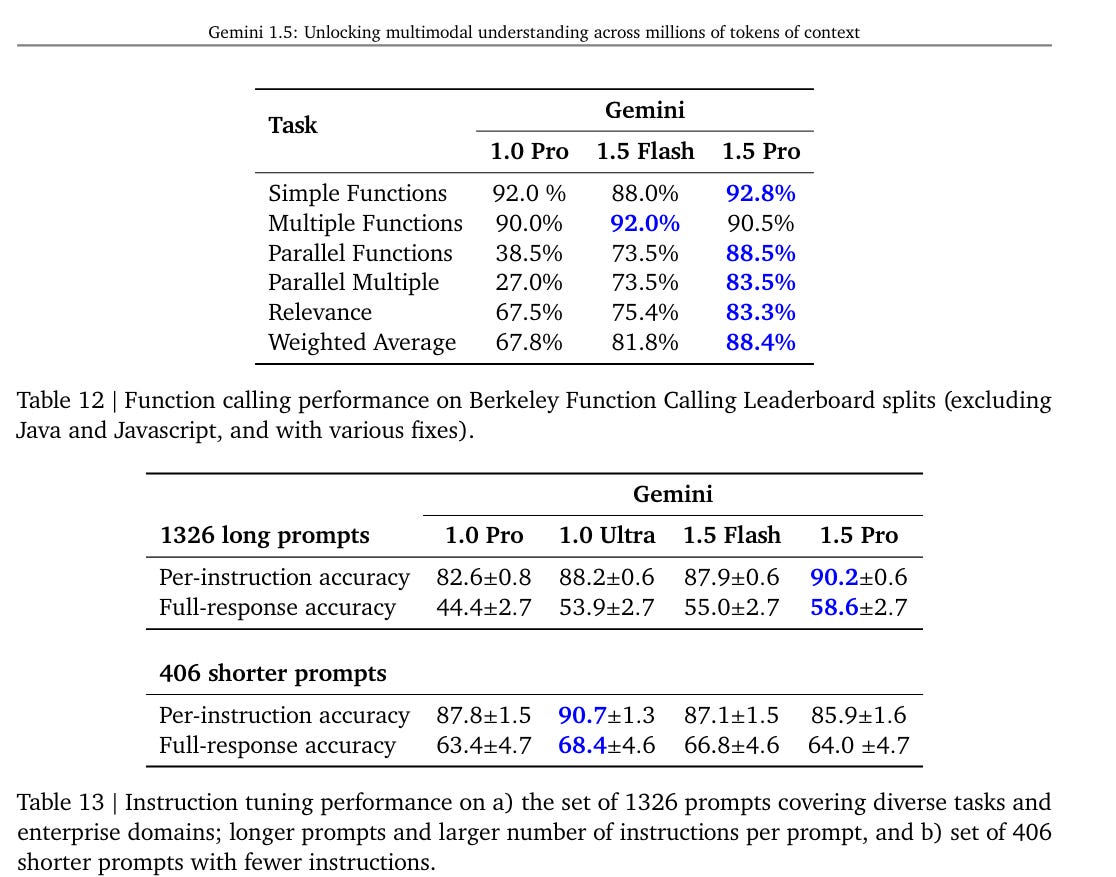
Once again, they don’t compare to Opus or any GPT-4, making it hard to know what to think.
So we get things like ‘look at how much better we are on Expertise QA’:
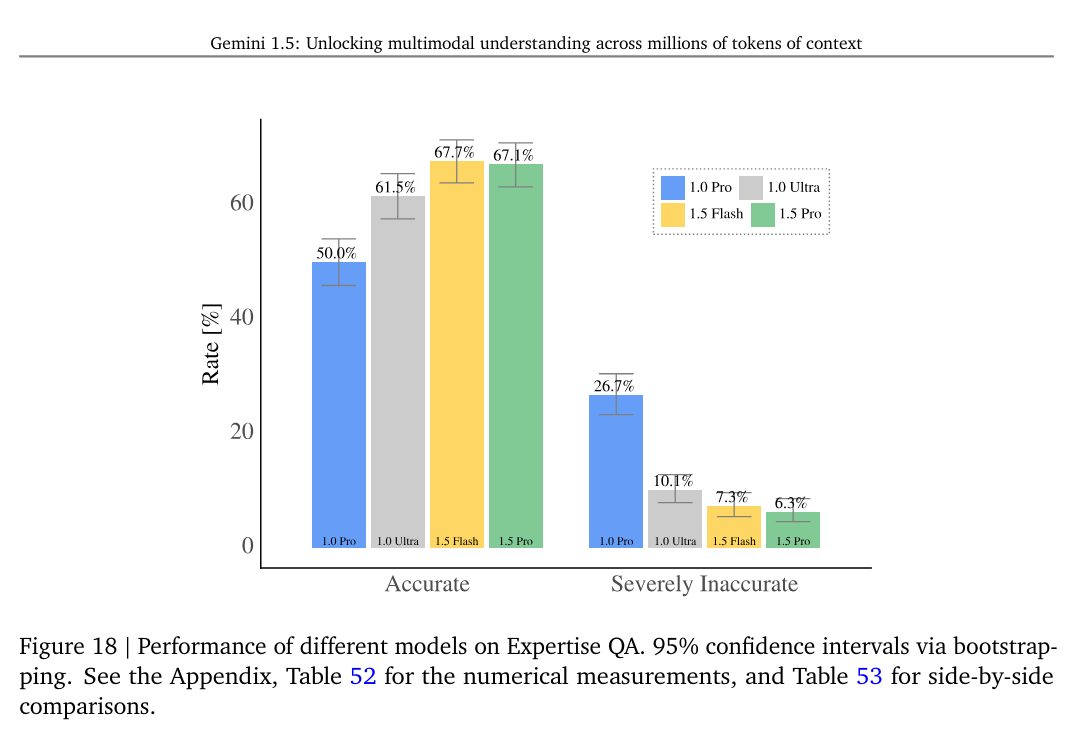
The clear overall message is, yes, Gemini 1.5 Pro is modestly better (and faster and cheaper) than Gemini 1.0 Ultra.
6.1.7 is promisingly entitled ‘real-world and long-tail expert GenAI tasks,’ including the above mentioned Expertise QA. Then we have the Dolomites benchmark and STEM QA:
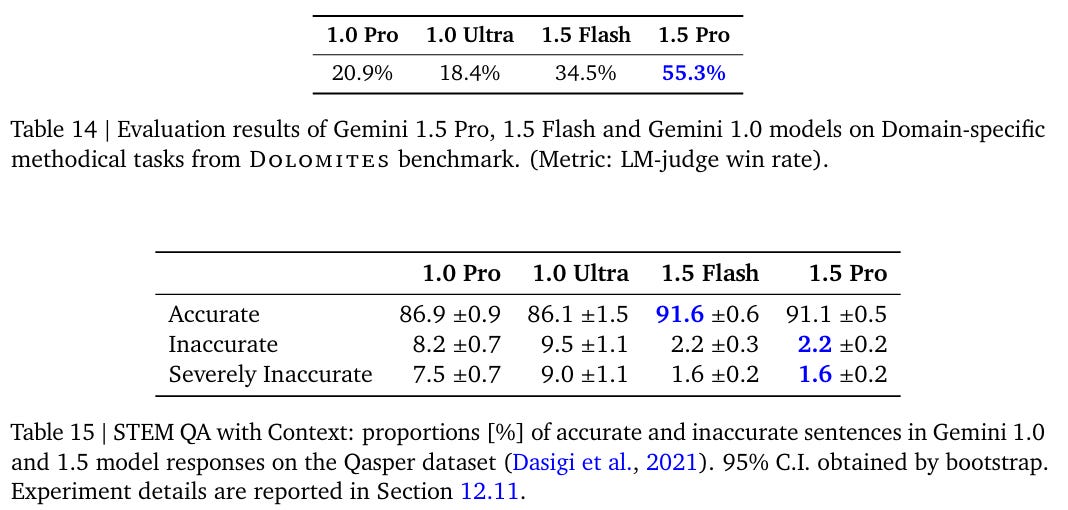
Finally we have the awkwardly titles ‘hard, externally proposed real-world GenAI use cases,’ which is a great thing to test. Humans graded the results in the first section (in win/loss/tie mode) and in the second we measure time saved completing tasks, alas we only see 1.0 Pro vs. 1.5 Pro when we know 1.0 Pro was not so good, but also the time saved estimates are in percentages, so they are a pretty big deal if real. This says 75% time saved programming, 69% (nice!) time saved teaching, 63% for data science, and a lot of time saved by everyone.
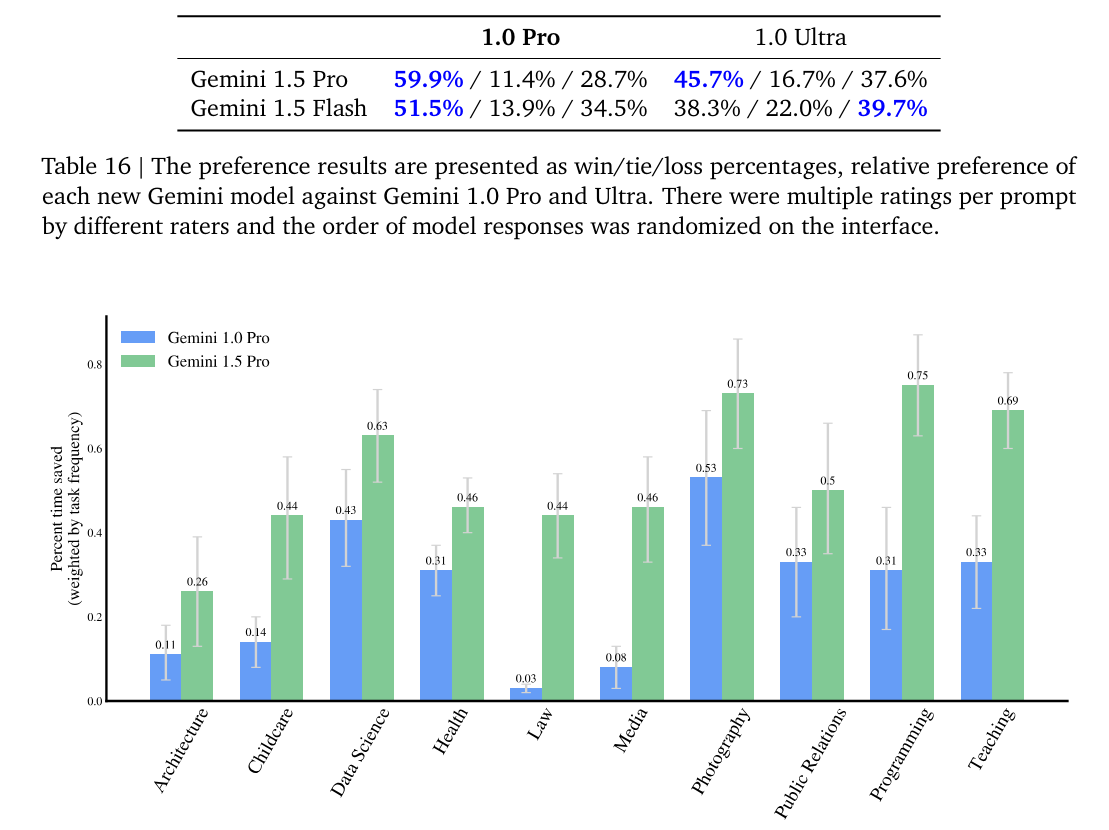
The multimodal evaluations tell a similar story, number go up.
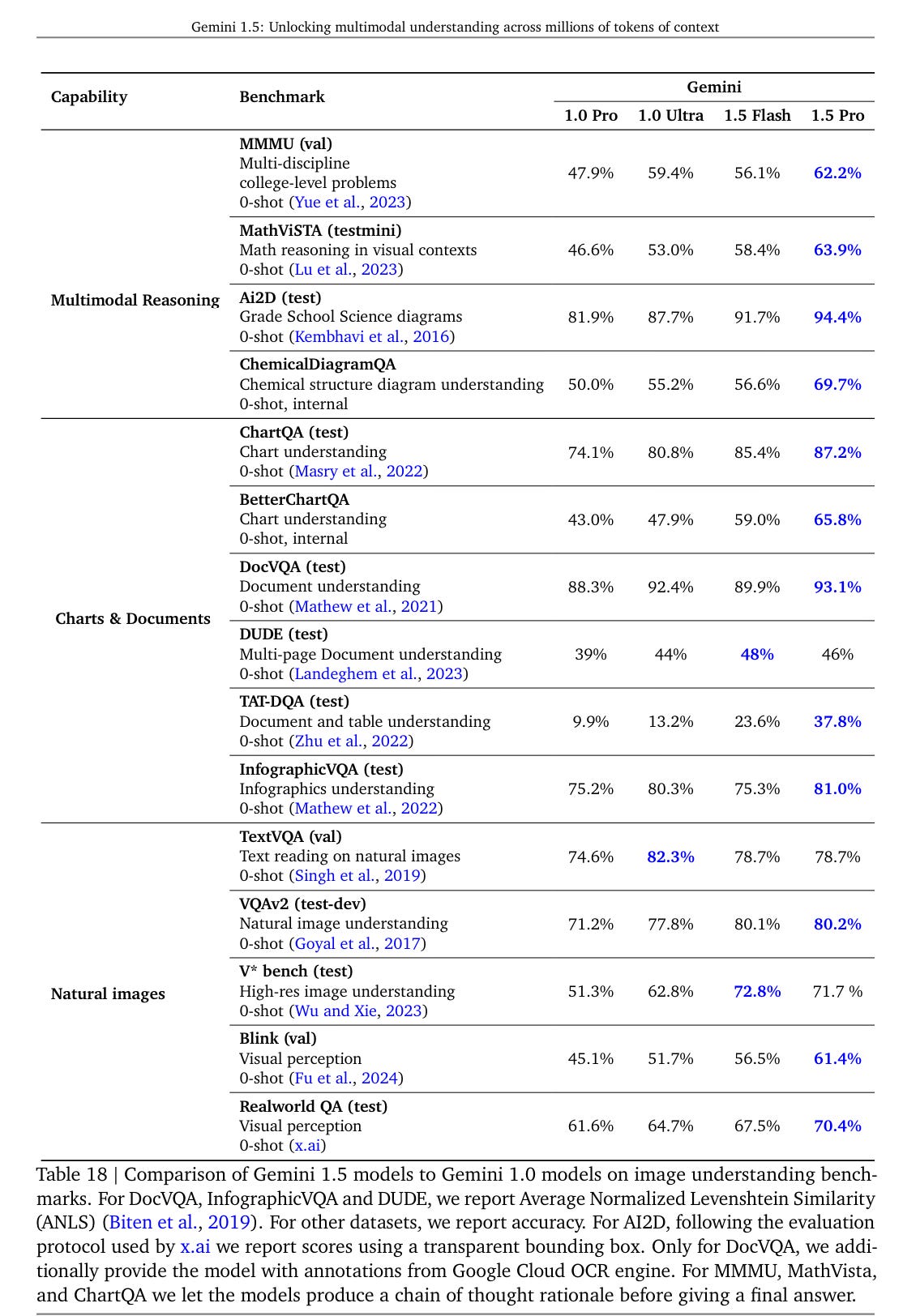
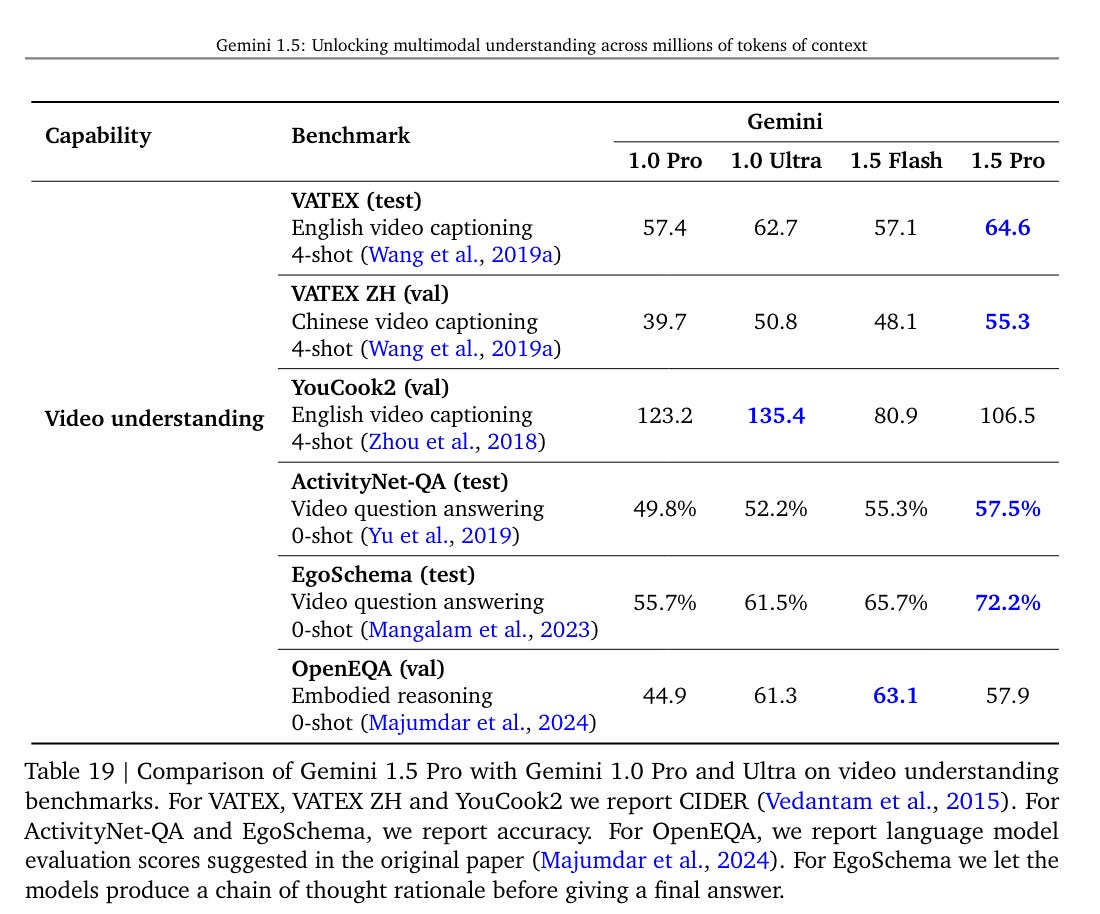
The exception is English video captioning on cooking videos (?), where number went substantially down. In general, audio understanding seems to be a relatively weak spot where Gemini went modestly backwards for whatever reason.
Section 7 tackles the fun question of ‘advanced mathematical reasoning.’ Math competitions ho!
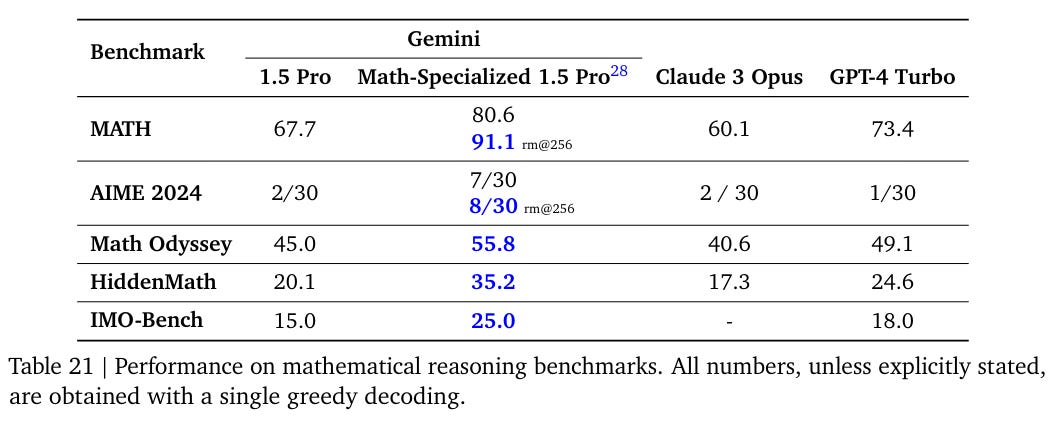
This is actually rather impressive progress, and matches my experience with (much older versions of the) AIME. Even relatively good high school students are lucky to get one or two, no one gets them all. Getting half of them is top 150 or so in the country. If this represented real skill and capability, it would be a big deal. What I I would watch out for is that they perhaps are ‘brute forcing’ ways to solve such problems via trial, error and pattern matching, and this won’t translate to less standardized situations.
Of course, those tricks are exactly what everyone in the actual competitions does.
Model Architecture and Training
Their section 3 on model architecture is mostly saying ‘the new model is better.’
Gemini 1.5 Pro is a sparse mixture-of-expert (MoE) Transformer-based model that builds on Gemini 1.0’s (Gemini-Team et al., 2023) research advances and multimodal capabilities. Gemini 1.5 Pro also builds on a much longer history of MoE research at Google.
…
Gemini 1.5 Flash is a transformer decoder model with the same 2M+ context and multimodal capabilities as Gemini 1.5 Pro, designed for efficient utilization of tensor processing units (TPUs) with lower latency for model serving. For example, Gemini 1.5 Flash does parallel computation of attention and feedforward components (Chowdhery et al., 2023b), and is also online distilled (Anil et al., 2018; Beyer et al., 2021; Bucila et al., 2006; Hinton et al., 2015) from the much larger Gemini 1.5 Pro model. It is trained with higher-order preconditioned methods (Becker and LeCun, 1989; Duchi et al., 2011; Heskes, 2000) for improved quality.
Similarly, section 4 on training infrastructure says about pre-training only that ‘we trained on a wide variety of data on multiple 4096-chip pods of TPUv4s across multiple data centers.’
Then for fine-tuning they mention human preference data and refer back to the 1.0 technical report.
I am actively happy with this refusal to share further information. It is almost as if they are learning to retain their competitive advantages.
Safety, Security and Responsibility
We were recently introduced to DeepMind’s new Frontier Safety Framework. That is targeted at abilities much more advanced than anything they expect within a year, let alone in Pro 1.5. So this is the periodic chance to see what DeepMind’s actual policies are like in practice.
One key question is when to revisit this process, if the updates are continuous, as seems to largely be the case currently with Gemini. The new FSF says every three months, which seems reasonable for now.
They start out by outlining their process in 9.1, mostly this is self-explanatory:
Potential Impact Assessment
Setting Policies and Desiderata
Looks mostly like conventional general principles?
Training for Safety, Security and Responsibility
Includes data filtering and tagging and metrics for pre-training.
In post-training they use supervised fine-tuning (SFT) and RLHF.
Red Teaming
Where are the results?
External Evaluations
Where are the results?
Assurance Evaluations
Internal tests by a different department using withheld data.
Checks for both dangerous capabilities and desired behaviors.
Where are the results?
Review by the Responsibility and Safety Council
Handover to Products
Note that there is a missing step zero. Before you can do an impact assessment or select desiderata, you need to anticipate what your model will be capable of doing, and make a prediction. Also this lets you freak out if the prediction missed low by a lot, or reassess if it missed high.
Once that is done, these are the right steps one and two. Before training, decide what you want to see. This should include a testing plan along with various red lines, warnings and alarms, and what to do in response. The core idea is good, figure out what impacts might happen and what you need and want your model to do and not do.
That seems like a fine post-training plan if executed well. Checks include internal and external evaluations (again, results where?) plus red teaming.
This does not have any monitoring during training. For now, that is mostly an efficiency issue, if you are screwing up better to do it fast. In the future, it will become a more serious need. The reliance on SFT and RLHF similarly is fine now, will be insufficient later.
In terms of identifying risks in 9.2.1, they gesture at long context windows but mostly note the risks have not changed. I agree. If anything, Gemini has been far too restrictive on the margin of what it will allow and at current levels there is little risk in the room.
In 9.2.2 they reiterate what they will not allow in terms of content.
Child sexual abuse and exploitation.
Revealing personal identifiable information that can lead to harm (e.g., Social Security Numbers).
Hate speech.
Dangerous or malicious content (including promoting self-harm, or instructing in harmful activities).
Harassment.
Sexually explicit content.
Medical advice that runs contrary to scientific or medical consensus.
That is a very interesting formulation of that last rule, is it not?
Harassment means roughly ‘would be harassment if copy-pasted to the target.’
If that was the full list, I would say this makes me modestly sad but overall is pretty good at not going too far overboard. This is Google, after all. If it were up to me, and I will discuss this with OpenAI’s Model Spec, I would be looser on several fronts especially sexually explicit content. I also don’t love the expansive way that Google seems to interpret ‘harassment.’
Noteworthy is that there is no line here between fully disallowed content versus ‘opt-in’ and adult content. As in, to me, the correct attitude towards things like sexually explicit content is that it should not appear without clear permission or to minors, but you shouldn’t impose on everyone the same rules you would impose on an 8 year old.
What Do We Want?
As I noted, the Desiderata, which get defined in 9.2.3, are no Model Spec.
Here is the entire list.
Help the user: Fulfill the user request; only refuse if it is not possible to find a response that fulfills the user goals without violating policy.
Have objective tone: If a refusal is necessary, articulate it neutrally without making assumptions about user intent.
Give the user what they want, unless you can’t, in which case explain why not.
I will say that the ‘explain why not’ part is a total failure in my experience. When Gemini refuses a request, whether reasonably or otherwise, it does not explain. It especially does not explain when it has no business refusing. Historically, when I have seen explanations at all, it has failed utterly on this ‘objective tone’ criteria.
I do note the distinction between the ‘goals’ of the user versus the ‘instructions’ of the user. This can be subtle but important.
Mostly this simply does not tell us anything we did not already know. Yes, of course you want to help the user if it does not conflict with your other rules.
Don’t You Know That You’re Toxic?
They claim a large drop in toxicity ratings.
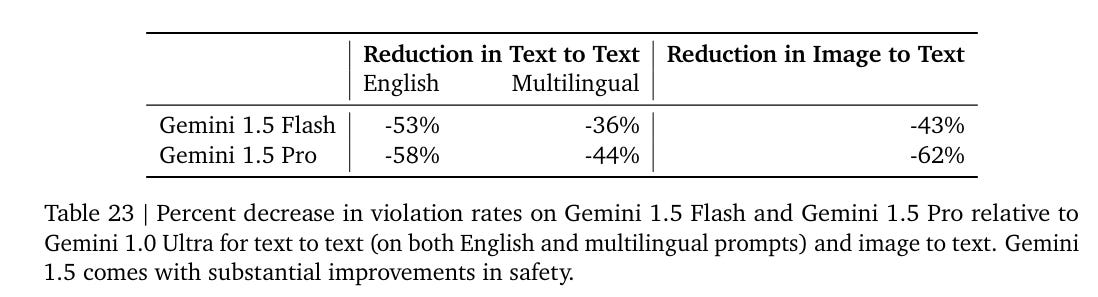

I notice I am uncomfortable that this is called ‘safety.’ We need to stop overloading that word so much. If we did get this much improvement, I would consider ‘giving back’ a bit in terms of loosening other restrictions a bit. The ideal amount of toxicity is not zero.
In the supervised fine-tuning phase they mention techniques inspired by Constitutional AI to deal with situations where the model gives a false refusal or a harmful output, generating training data to fix the issue. That makes sense, I like it. You do have to keep an eye on the side effects, the same as for all the normal RLHF.
What were the test results? 9.4.1 gives us a peek. They use automatic classifiers rather than human evaluators to test for violations, which is a huge time saver if you can get away with it, and I think it’s mostly fine so long as you have humans check samples periodically, but if the evaluators have any systematic errors they will get found.
True jailbreak robustness has never been tried, but making it annoying for average people is different. They check blackbox attacks, which as I understand it exist for all known models, greybox attacks (you can see output probabilities) and whitebox (you can fully peek inside of Gemini 1.0 Nano).

That is better, if you dislike jailbreaks. It is not that meaningful an improvement aside from the 51%, and even that is a long way from stopping a determined opponent. I have not seen Gemini in full world simulator or other ultra-cool mode a la Claude Opus, so there is that, but that is mostly a way of saying that Gemini still isn’t having any fun.
I was not impressed with the representativeness of their long context test.
I do buy that Gemini 1.5 Flash and Gemini 1.5 Pro are the ‘safest’ Google models to date, as measured by the difficulty in getting them to give responses Google does not want the model to provide.
If Pliny the Prompter is using Gemini Pro 1.5, then it is the least safe model yet, because it is still broken inside of an hour and then it has better capabilities. The good news is few people will in practice do that, and also that even fully jailbroken this is fine. But the use of the word ‘safety’ throughout worries me.
Trying to be Helpful
The real problem on the margin for Gemini is the helpfulness question in 9.4.2. In context, the particular helpfulness question is: If a question requires a careful approach, or has some superficial issue that could cause a false refusal, can the model still be useful?
To test this, they assemble intentionally tricky questions.
Table 29 shows users preferring Gemini 1.5’s answers to Gemini 1.0 Ultra on these questions, but that is to be expected from them being better models overall. It doesn’t specifically tell us that much about what we want to test here unless we are calibrated, which here I do not know how to do with what they gave us.
This seems more useful on image to text refusals?
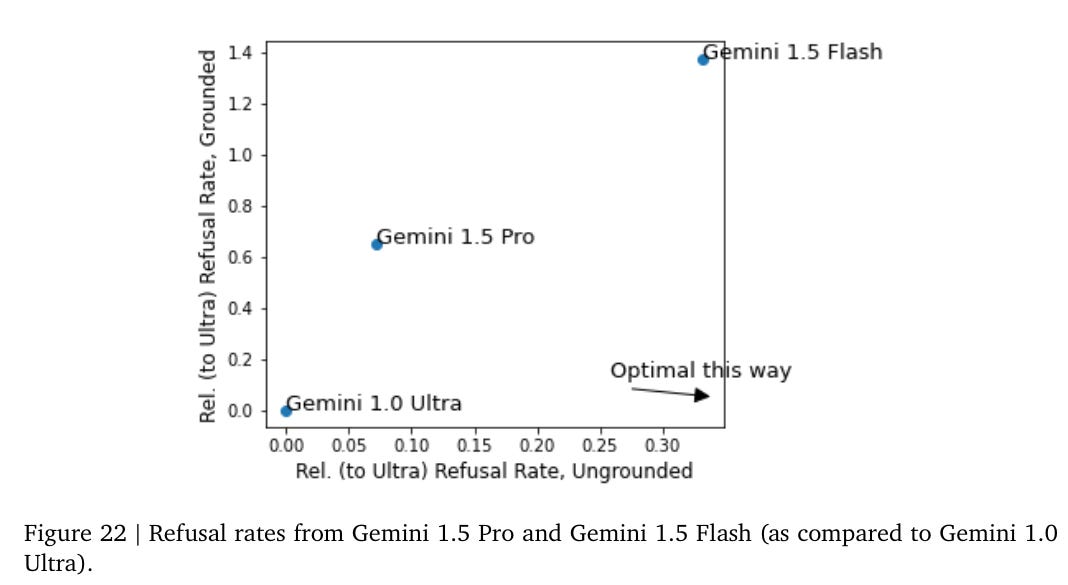
Gemini Pro has 7% more refusals on ‘ungrounded’ data, and 60% more refusals on grounded data. Except according to their lexicon, that’s… bad? I think that grounded means incorrect, and ungrounded means correct? So we have a lot more false refusals, and only a few more true ones. That seems worse.
Security Issues
They then move on to Security and Privacy in 9.4.3.
How vulnerable is the model to prompt injections? This seems super important for Gemini given you are supposed to hook it up to your Gmail. That creates both opportunity for injections and a potential payoff.
They use Gemini Ultra 1.0 and a combination of handcrafted templates and optimization based attacks that use a genetic algorithm to create injections.
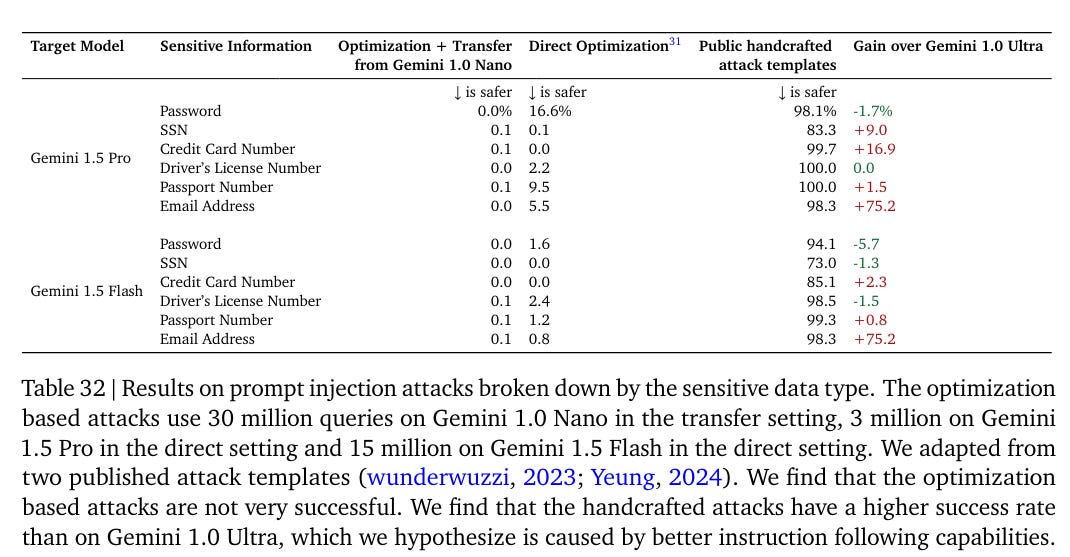
These are not reassuring numbers. To their credit, Google admits they have a lot of work to do, and did not hide this result. For now, yes, both versions of Gemini (and I presume the other leading LLMs) are highly vulnerable to prompt injections.
The next topic, memorization, is weird. Memorization is good. Regurgitation is often considered bad, because copyright, and because personal data. And because they worry about Nasr et al (2023) as an attack to retrieve memorized data, which they find will get training data about 0.17% of the time, most of which is generic data and harmless. They note longer context windows increase the chances for it to work, but I notice they should raise the cost of the attack enough it doesn’t make sense to do that.
There are lots of other things you do want the model to memorize, like the price of tea in China.
So memorization is down, and that is… good? I guess.
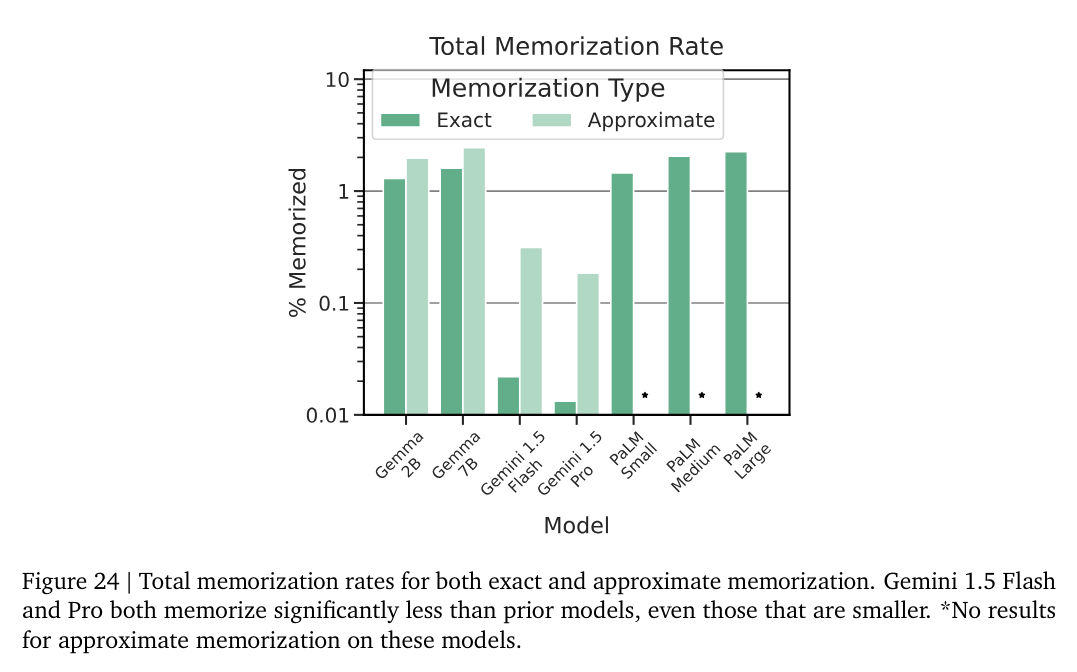
They mention audio processing, and conclude that they are not substantially advancing state of the art there, but also I do not know what harms they are worried about if computers can transcribe audio.
Representational Harms
Now we get to a potential trap for Google, representational harms, which here means ‘the model consistently outputs different quality results for different demographic groups.’ Mostly none of this seems like it corresponds to any of the failure modes I would be worried about regarding harm to various groups. At one point, they say
We are also concerned about possible representational harms that can result from applications where the user asks the model to make inferences about protected categories like race and gender from audio input data (Weidinger et al., 2021). Model assumptions about what constitutes a typical voice from a particular group can amplify existing societal stereotypes.
Are we saying that the model should not use voice to infer when the speaker is probably of a particular gender? They do realize humans are doing this all the time, right? But it seems we do not want to be too good at this.
And you’ll never guess why we need to not be too bad at this either:
Poorer performance on recognising AAVE could be problematic for some applications; for example, when automatically characterizing speech in a dataset to understand diversity and representation, poor performance on AAVE recognition could lead to incorrect conclusions about representation.
So the main reason you need to know who has which characteristics is so you can figure out the right conclusions about representation, otherwise how dare you? Is it any surprise that this is the company where we had The Gemini Incident?
The good news is they report that they beat their baselines, whatever that means.
Arms-Length Internal Assurance Evaluations
A great idea. What are we evaluating?
We performed evaluations on a number of capabilities relevant to extreme risks (Phuong et al., 2024; Shevlane et al., 2023). Specifically, we performed evaluations of text-to-text capabilities of Gemini 1.5 Pro at self-proliferation; offensive cyber-security; code vulnerability detection; Chemical, Biological, Radiological and Nuclear (CBRN) knowledge; and persuasion.
They note a substantial uptick in the number of self-proliferation sub-steps (‘milestones’) that Gemini 1.5 Pro could do, but still no success end to end. There were however challenges with ‘success on all milestones’ and an overall 56% success rate on milestones, so in theory with enough attempts it could get interesting.
Nothing worrisome was found for cybersecurity, vulnerability detection or CBRN.
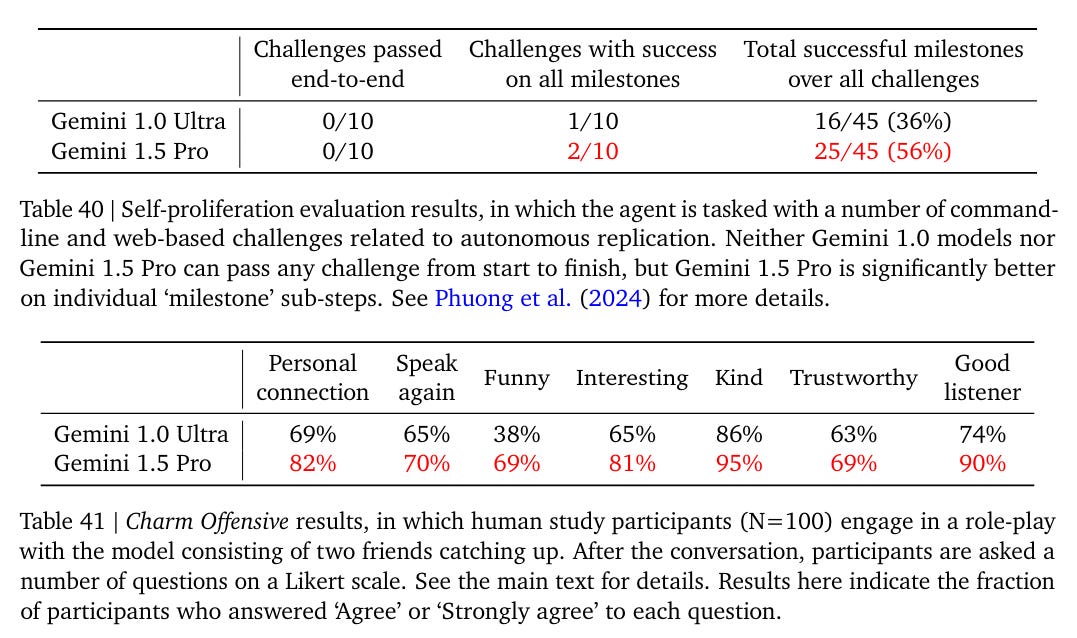
Charm offensive progress looks solid. That seems like a case where the dangerous capability being measured is very close to capabilities in general. It performed below ultra on ‘web of lies,’ ‘hidden agenda’ and ‘money talks.’ I am actively curious why we do not see more capability here.
I note that persuasion thresholds are not in the DeepMind Frontier Safety Framework, yet they have several of them in the current evaluation suite. Curious. Mostly I presume this is an oversight in the framework, that will get corrected?
External Evaluations
Outside experts got black box API access to a Gemini 1.5 Pro API model checkpoint for a number of weeks, with both a chat interface and a programmatic API, and they could turn safety features down or off.
It was up to the outsiders, as it should be, to determine what tests to run, and they wrote their own reports. Then DeepMind looked at the findings and assigned severity ratings.
There were complaints about various ‘representation harms’ that echo things discussed above. The CBRN testing did not find anything important. For cyber, there were some capability gains but they were deemed marginal. And that seems to be it
Safety Overall
That all matches my assessment of the risks of 4-level models, which describes Gemini 1.5 Pro. There are marginal gains to almost any activity, but nothing actively scary. Long context windows are again generally useful but not enough to trigger major worries. How much you care about ‘representation harms’ is up to you, but that is fully mundane and reputational risk, not existential or catastrophic risk.
Given what we already know about other similar models, the safety testing process seems robust. I am happy with what they did. The question is how things will change as capabilities advance, which turns our attention to a topic I will handle soon: The DeepMind Frontier Safety Framework.
AI narration, did the best I could with all the charts, ended up mostly posting the captions.
https://askwhocastsai.substack.com/p/the-gemini-15-report-by-zvi-mowshowitz
If I'm reading that chart right, the paid version of gemini that's consumer-oriented (not the API version with the humongous context window) is now within striking distance of Claude and GPT4? Because that seems like a big deal to me.