The Second Gemini

Table of Contents
Trust the Chef
Google has been cooking lately.
Gemini Flash 2.0 is the headline release, which will be the main topic today.
But there’s also Deep Research, where you can ask Gemini to take several minutes, check dozens of websites and compile a report for you. Think of it as a harder to direct, slower but vastly more robust version of Perplexity, that will improve with time and as we figure out how to use and prompt it.
NotebookLM added a call-in feature for podcasts, a Plus paid offering and a new interface that looks like a big step up.
Veo 2 is their new video generation model, and Imagen 3 is their new image model. There’s also Whisk, where you hand it a bunch of images and it combines them with some description for a new image. Superficially they all look pretty good.
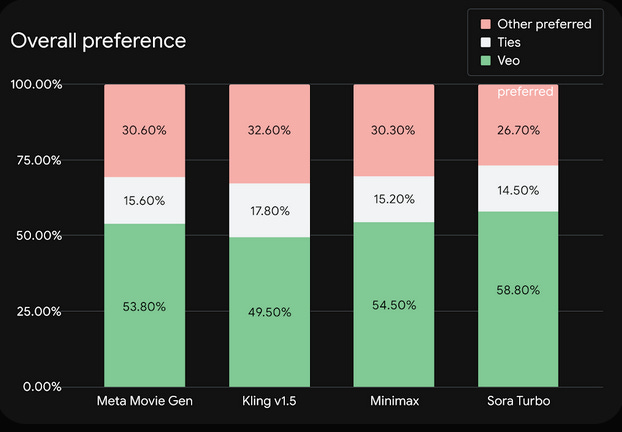
They claim people in a survey chose Veo 2 generations over Sora Turbo by a wide margin, note that the edges over the other options imply Sora was sub-par:
Here’s one comparison of both handling the same prompt. Here is Veo conquering the (Will Smith eating) spaghetti monster.
This is a strong endorsement from a source I find credible:
Nearcyan: I haven’t seen a model obliterate the competition as thoroughly as Veo2 is right now since Claude 3.5.
They took the concept I was barely high-IQ enough to try to articulate and actually put it in the model and got it to work at scale.
It really was two years from StyleGAN2 to Stable Diffusion, then two years from Stable Diffusion to Veo2. They were right. Again.
I wonder when the YouTubers are going to try to revolt.
There’s a new Realtime Multimodal API, Agentic Web Browsing from Project Mariner, Jules for automated code fixing, an image model upgrade, the ability to try Project Astra.
And they’re introducing Android XR (launches in 2025) as a new operating system and platform for ‘Gemini-era’ AR or VR glasses, which they’re pitching as something you wear all day with AI being the killer app, similar to a smart watch. One detail I appreciated was seamless integration with a mouse and keyboard. All the details I saw seem… right, if they can nail the execution. The Apple Vision Pro is too cumbersome, didn’t have AI involved and didn’t work out, but Google’s vision feels like the future.
Demis Hassabis is calling 2025 ‘the year of the AI agent.’
Gemini 2.0 is broadly available, via Google Studio, Vertex and its API, and Gemini’s app.
Gemini 2.0 finally has a functional code interpreter.
For developers, they offer this cookbook.
One big thing we do not know yet is the price. You can use a free preview, and that’s it.
If you want to join all the waitlists, and why wouldn’t you, go to Google Labs.
Do Not Trust the Marketing Department
I mean, obviously, you never want to ‘trust the marketing department.’
But in this case, I mean something else: Do not trust them to do their jobs.
Google has been bizarrely bad about explaining all of this and what it can do. I very much do not want to hear excuses about ‘the Kleenex effect’ (especially since you could also call this ‘the Google effect’) or ‘first mover advantage.’ This is full-on not telling us what they are actually offering or giving us any reasonable way to find out beyond the ‘f*** around’ plan.
Even when I seek out their copy, it is awful.
For example, CEO Sundar Pichai’s note at the top of their central announcement is cringeworthy corporate-speak and tells you almost nothing. Nobody wants this.
Mark that Bench
On at least some benchmarks, Gemini Flash 2.0 outperforms Gemini 1.5 Pro.

That chart only compares to Gemini Pro 1.5, and only on their selection of benchmarks. But based on other reports, it seems likely that yes, this is an overall intelligence upgrade over Pro 1.5 while also being a lot faster and cheaper.
It tops something called the ‘Hallucination leaderboard’ along with Zhipu.
Chubby: Gemini 2.0 Flash on Hallucination leaderboard
Gemini shows its strength day by day

Claude is at 4.6%, and its hallucinations don’t bother me, but I do presume this is measuring something useful.
The performance on Arena is super impressive for a model of this size and speed, and a large improvement over the old Flash, which was already doing great for its size. It’s not quite at the top, but it’s remarkably close:

Going Multimodal
Gemini 2.0 is sufficiently lightweight, fast and capable that Google says it enables real time multimodal agentic output. It can remember, analyze and respond accordingly.
It also has native tool use, which is importantly missing from o1.
Google claims all this will enable their universal AI assistant, Project Astra, to be worth using. And also Project Mariner, asking it to act as a reasoning multi-step agent on the web on your behalf across domains.
Currently Astra and Mariner, and also their coding agent Jules, are in the experimental stage. This is very good. Projects like this should absolutely have extensive experimental stages first. It is relatively fine to rush Flash 2.0 into Search, but agents require a bit more caution, if only for not-shooting-self-in-foot practical purposes.
Project Astra now is fully multilingual including within a conversation, and has 10 minutes of in-session memory plus memory of earlier conversations, and less latency.
There’s a waiting list for Astra, but right now, you can use Google Studio to click Stream Realtime on your screen, which seems to be at least close to the same thing if you do it on mobile? There’s a button to use your webcam, another to talk to it.
On a computer you can then use a voice interface, and it will analyze things in real time, including analyzing code and suggesting bug fixes.

If we can bring this together with the rest of the IDE and the abilities of a Cursor, watch out, cause it would solve some of the bottlenecks.
The Art of Deep Research
Deep Research is a fantastic idea.
Ethan Mollick: Google has a knack for making non-chatbot interfaces for serious work with LLMs.
When I demo them, both NotebookLM & Deep Research are instantly understandable and fill real organizational needs. They represent a tiny range of AI capability, but they are easy for everyone to get
You type in your question, you tab out somewhere else for a while, then you check back later and presto, there’s a full report based on dozens of websites. Brilliant!
It is indeed a great modality and interface. But it has to work in practice.
In practice, well, there are some problems. As always, there’s basic accuracy, such as this output - I had it flat out copy benchmark numbers wrong, claim 40.4% was a higher score than 62.1% on GPQA (rather persistently, even!) and so on.
I also didn’t feel like the ‘research plan’ corresponded that well to the results.
The bigger issue is that it will give you ‘the report you vaguely asked for.’ It doesn’t, at least in my attempts so far, do the precision thing. Ask it a particular question, get a generic vaguely related answer. And if you try to challenge its mistakes, weird mostly unhelpful things happen.
That doesn’t mean it is useless.
If what you want matches Gemini’s inclinations about what a vaguely related report would look like, you’re golden.
If what you want is a subset of that but will be included in the report, you can, as someone suggested to me on Twitter, take the report, click a button to make it a Google Doc, then feed the Google Doc to Claude (or Gemini!) and have it pick out the information you want.
These were by far the most gung-ho review I’ve seen so far:
Dean Ball: Holy hell, Gemini’s deep research is unbelievable.
I just pulled information from about 100 websites and compiled a report on natural gas generation in minutes.
Perhaps my favorite AI product launch of the last three business days.
The first questions I ask language models are *always* research questions I myself have investigated in the recent past.
Gemini’s performance on the prompt in question was about 85%, for what it’s worth, but the significant point is that no other model could have gotten close.
It wasn’t factually inaccurate about anything I saw—most of the problem was the classic llm issue of not getting at what I *actually* wanted on certain sub-parts of the inquiry.
Especially useful for me since I very often am doing 50-state surveys of things.
Sid Bharath: Gemini Deep Research is absolutely incredible. It's like having an analyst at your fingertips, working at inhuman speeds.
Need a list of fashion bloggers and their email addresses to promote your new clothing brand brand? Deep Research crawls through hundreds of sites to pull it all together into a spreadsheet, along with a description of that website and a personalized pitch, in minutes.
Analyzing a stock or startup pitch deck? Deep Research can write up a full investment memo with competitive analysis and market sizing, along with sources, while you brew your coffee.
Whenever you need to research something, whether it's for an essay or blog, analyzing a business, building a product, promoting your brand, creating an outreach list, Deep Research can do it at a fraction of the time you or your best analyst can.
And it's available on the Gemini app right now. Check it out and let me know what you think.
On reflection, Dean Ball’s use cases are a great fit for Deep Research. I still don’t see how he came away so enthused.
Sid Bharath again seems like he has a good use case with generating a list of contacts. I’m a lot more suspicious about some of the other tasks here, where I’d expect to have a bigger slop problem.
You can also view DR as a kind of ‘free action.’ You get a bunch of Deep Research reports on a wide variety of subjects. The ones that don’t help, you quickly discard. So it’s fine if the hit rate is not so high.
Another potential good use is to use this as a search engine for the sources, looking either at the ones in the final data set or the list of researched websites.
It will take time to figure out the right ways to take advantage of this, and doubtless Google can improve this experience a lot if it keeps cooking.
Jon Stokes sees Deep Research as Google ‘eating its seed corn’ as in not only search but also the internet, because this is hits to websites with no potential customers.
Jon Stokes: Gemini is strip-mining the web. Not a one of the 563 websites being visited by Gemini in the above screencap is getting any benefit from this activity -- in fact, they're paying to serve this content to Google. It's all cost, no benefit for rightsholders.
I don’t think it is true they get no benefit. I have clicked on a number of Deep Research’s sources and looked at them myself, and I doubt I am alone in this.
I encourage you to share your experiences.
Project Mariner the Web Agent
Project Mariner scores a SotA 83.5% on the WebVoyager benchmark, going up to 90%+ if you give it access to tree search. They certainly are claiming it is damn impressive.
The research prototype can only use the active tab, stopping you from doing other things in the meantime. Might need multiple computers?
Here’s Olivia Moore using it to nail GeoGuessr. The example in question does seem like easy mode, there’s actual signs that give away the exact location, but very cool.
It is however still in early access, so we can’t try it out yet.
Project Astra the Universal Assistant
Shane Legg (Chief AGI Scientist, Google): Who’s starting to feel the AGI?
I was excited when I first saw the announcements for Project Astra, but we’re still waiting and haven’t seen much. They’re now giving us more details and claiming it has been upgraded, and is ready to go experimental. Mostly we get some early tester reports, a few minutes long each.
One tester points to the long-term memory as a key feature. That was one of the ones that made sense to me, along with translation and object identification. Some of the other ways the early testers used Astra, and their joy in some of the responses, seemed so weird to me. It’s cool that Astra can do these things, but why are these things you want Astra to be doing?
That shows how far we’ve come. I’ve stopped being impressed that it can do a thing, and started instead asking if I would want to do the thing in practice.
Astra will have at least some tool use, 10 minutes of in-context memory, a long-term memory for past conversations and real time voice interaction. The prototype glasses, they are also coming.
Here Roni Rahman goes over the low hanging fruit Astra use cases, and a similar thread from Min Choi.
My favorite use case so far is getting Gemini to watch the screen for when you slack off and yell at you to get back to work.
Project Jules the Code Agent
Jules is Google’s new code agent. Again, it isn’t available yet for us regular folk, they promise it for interested developers in early 2025.
How good is it? Impossible to know. All we know is Google’s getting into the game.
There’s also a data science agent scheduled for the first half of 2025.
Gemini Will Aid You on Your Quest
With the multimodal Live API, Gemini 2.0 can be your assistant while playing games.
It understand your screen, help you strategize in games, remember tasks, and search the web for background information, all in voice mode.
An excellent question:
High Minded Lowlife: I don't play these games so I gotta ask. Are these actually good suggestions or just generic slop answers that sound good but really aren't. If the former then this is pretty awesome.
That’s always the question, isn’t it? Are the suggestions any good?
I notice that if Gemini could put an arrow icon or even better pathways onto the screen, it would be that much more helpful here.
So we all know what that means.
We already know that no, Gemini can’t play Magic: The Gathering yet.
What is the right way to use this new power while gaming?
When do you look at the tier list, versus very carefully not looking at the tier list?
Now more than ever, you need to cultivate the gaming experience that you want. You want a challenge that is right for you, of the type that you enjoy. Sometimes you want the joy of organic discovery and exploration, and other times you want key information in advance, especially to avoid making large mistakes.
Here Sid Bharath uses Gemini to solve the New York Times Crossword, as presumably any other LLM could as well with a slightly worse interface. But it seems like mostly you want to not do this one?
Reactions to Gemini Flash 2.0
Sully: This is insane.
Gemini Flash 2.0 is twice as fast and significantly smarter than before.
Guys, DeepMind is cooking.
From the benchmarks, it is better than 1.5 Pro.
Mbongeni Ndlovu: I'm loving Gemini 2.0 Flash so much right now.
Its video understanding is so much better and faster than 1.5 Pro.
The real-time streaming feature is pretty wild.
Sully: Spent the day using Gemini Flash 2.0, and I'm really impressed.
Basically, it is the same as GPT-4O and slightly worse than Claude, in my opinion.
Once it is generally available, I think all our “cheap” requests will go to Flash. Getting rid of GPT Mini plus Haiku (and some GPT-4o).
Bindu Reddy: Gotta say Gemini 2.0 is a way bigger launch that whatever OpenAI has announced so far
Also love that Google made the API available for evals and experiments
Last but not the least, Gemini’s speed takes your breath away
Mostafa Dehghani notices that Gemini 2.0 can break down steps in the ‘draw the rest of the owl’ task.

What is my take so far?
Veo 2 seems great, but it’s not my area, and I notice I don’t care.
Deep Research is a great idea, and it has a place in your workflow even with all the frustrations, but it’s early days and it needs more time to cook. It’s probably a good idea to keep a few Gemini windows open for this, occasionally put in questions where it might do something interesting, and then quickly scan the results.
Gemini-1206 seems solid from what I can tell but I don’t notice any temptation to explore it more, or any use case where I expect it to be a superior tool to some combination of o1, GPT-4o with web search, Perplexity and Claude Sonnet.
Gemini Flash 2.0 seems like it is doing a remarkably good impression of models that are much larger and more expensive. I’d clearly never use it over Claude Sonnet where I had both options, but Flash opens up a bunch of new use cases, and I’m excited to see where those go.
Project Astra (or ‘streaming realtime’) in particular continues to seem fascinating, both the PC version with a shared screen and the camera version with your phone. I’m eager to put both to proper tests, even in their early forms, but have not yet found the time. Maybe I should just turn it on during my work at some point and see what happens.
Project Mariner I don’t have access to, so it’s impossible to know if it is anything yet.
For now I notice that I’m acting like most people who bounce off AI, and don’t properly explore it, and miss out. On a less dumb level, but I need to snap out of it.
The future is going to get increasingly AI, and increasingly weird. Let’s get that first uneven distribution.
Excellent points on Deep Research. The bottom line is that its reports and answers are incredibly unreliable, in the same way that (so far) all LLMs are unreliable in attempting to collect and report factual information. Mitja Rutnik at Android Authority has an interesting article on asking DR / Gemini for basic stock market information. Among the requests was a summary of the performance of the top 10 S&P 500 companies by market cap. This is a well-defined request! The problems, as reported by Rutnik: The table Gemini produced did not include 10 companies at all (?!?), only 9, and not one of the 9 was in the top 10 by market cap. (It also didn't even report data for some of the irrelevant companies.) Think about that - the model failed in every possible way. The information couldn't be quickly checked, corrected, and then used - it's literally useless. That is wholly consistent with my experience with other models on asking for basic, easily-confirmed information available from numerous websites. What *is* interesting is that this application is designed specifically for web research - "deep research," even - but there has not been a phase change in accuracy or reliability. My suspicion is that it's because the problem is fundamental and structural. That's not to say that AI researchers won't fix it ultimately, but it could require a transformer-like breakthrough, or at least a clear and new set of algorithms.
I've experienced the same thing as many others, in deeply preferring Sonnet over every other option, benchmarks be damned. What is it, exactly? I struggle to explain it when asked, other than vague statements like Sonnet has a 'spark' or a ' presence' other LLMs don't.
How do you explain it?