


Welcome to week three of the AI era. Another long week and another giant post. I intend to take a nice four-day vacation in Mexico starting today, during which I won’t do any writing. I’m sure the pace of things will slow down real soon now. I mean, they have to. Don’t they?
If not, I’m going to have to learn to make some deeper cuts on what gets included.
Table of Contents
Executive Summary
The top updates this week, and where they are in the post, Big Tech represent:
Facebook gave out its language model for researchers to download, which of course meant it was on Torrent within 24 hours. (#15)
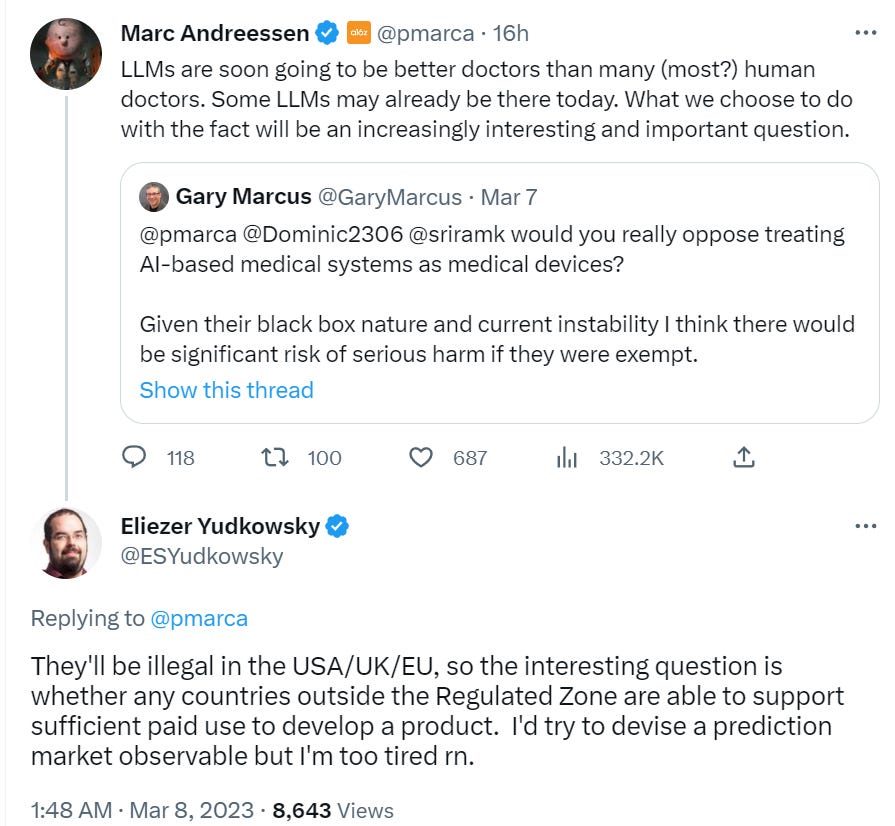
Microsoft only takes hours to address Eliezer’s request that Sydney not claim to be conscious. (#19)
Google puts out paper showing remarkably good performance on medical questions. (#3)
Most important of all: The Waluigi Effect (#17).
The overall structure is getting settled.
First there is Table of Contents and Executive Summary (#1)
Stuff that is broadly applicable to what is happening now. (#2-#17)
Stuff that is centered around not destroying all value in the universe (#18-#25)
Finally, The Lighter Side (#26)
The transition between sections two and three is fuzzy - The Waluigi Effect and related questions in particular are very important both to understand what is happening now and what we should be worried about in the future, as is The Once and Face of Sydney.
With this week I hope to have turned the corner on Bad NotKillEveryoneism Takes - I think I have now covered most of the classic vintages and people worth engaging with, so the pace of future entries should slow down. My hope is that after another few weeks I will codify my official list of such things, so we can have a nice numbered handy reference. This post has a 0th draft of that. Here’s to steadily improving take quality.
The Waluigi Effect section is my attempt to condense down the most important post of the week into something shorter and more accessible - and it would be good to even do that one additional time. Once I’m confident that section is where I want it, I’ll have it stand on its own as a distinct post.
In general, if you ever want to link to one section in particular, or refer to it, let me know so I can consider putting it out there on its own. In future weeks I want to do more of that, the way I did last week with practical advice.
Market Perspectives
New working paper on the productivity effects of ChatGPT on writing tasks (paper).
Abstract
We examine the productivity effects of a generative artificial intelligence technology—the assistive chatbot ChatGPT—in the context of mid-level professional writing tasks. In a preregistered online experiment, we assign occupation-specific, incentivized writing tasks to 444 college-educated professionals, and randomly expose half of them to ChatGPT.
Our results show that ChatGPT substantially raises average productivity: time taken decreases by 0.8 SDs and output quality rises by 0.4 SDs. Inequality between workers decreases, as ChatGPT compresses the productivity distribution by benefiting low-ability workers more. ChatGPT mostly substitutes for worker effort rather than complementing worker skills, and restructures tasks towards idea-generation and editing and away from rough-drafting. Exposure to ChatGPT increases job satisfaction and self-efficacy and heightens both concern and excitement about automation technologies.
…
Task Structure
As suggested by the preceding discussion, ChatGPT substantially changes the structure of writing tasks. Figure 3 Panel A shows that prior to the treatment, participants spend about 25% of their time brainstorming, 50% writing a rough draft, and 25% editing. Post-treatment, the share of time spent writing a rough draft falls by more than half and the share of time spent editing more than doubles.
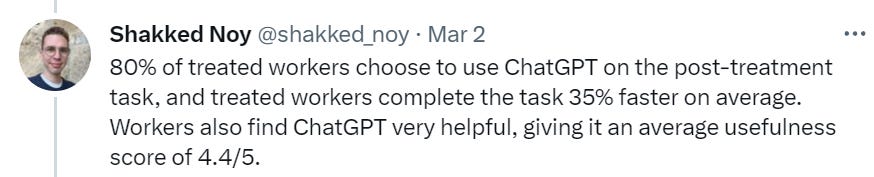
This score is super high, and likely reflects the task being unusually well suited to ChatGPT - as is seen below, on real world tasks usefulness was rated much lower, which Noy says was likely due to detail knowledge ChatGPT lacks. I also presume that many other details make the problems trickier, including worry about ‘being caught’ in various senses.

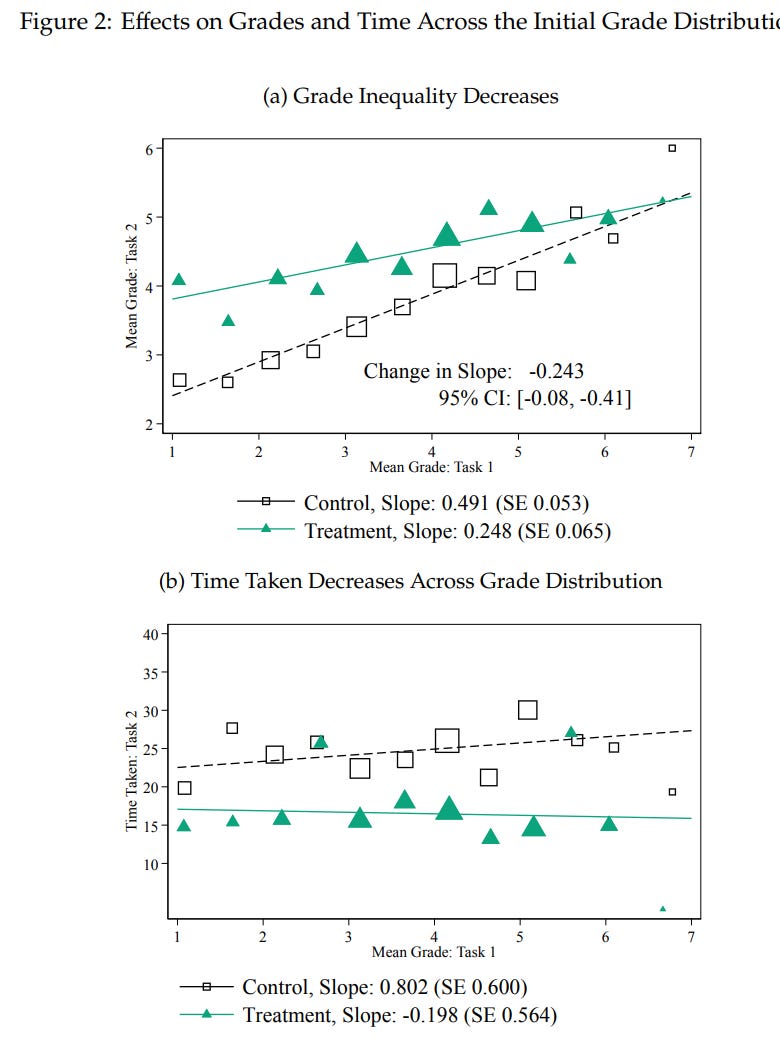
Skill does seem to have about half its previous effect, with 80% of the treatment group using ChatGPT. If they are literally pasting in the question and then copying out the answer with no changes, you would expect a much larger decrease in skill. So there is still some additional value add (or subtraction) going on.
One potential hint is that before ChatGPT those who got better results worked slower, whereas with ChatGPT those with better results worked faster. Part of that is accounted for by the 20% who rejected ChatGPT being far slower and also scoring lower. This seems like it implies that not only is ChatGPT giving better output, when humans overrule the system, in many cases it makes the result worse.
One still needs to double check the output, to avoid hallucinations. It does seem like once you’ve done that, otherwise kind of trust the chef here?

So this is really weird, no? You outsourced writing, with many literally copying in a prompt and copying out output, and writing skill did not get devalued. Writing skill is presumably linked to some valuable form of a combination of editing and knowing what to ask for, then?


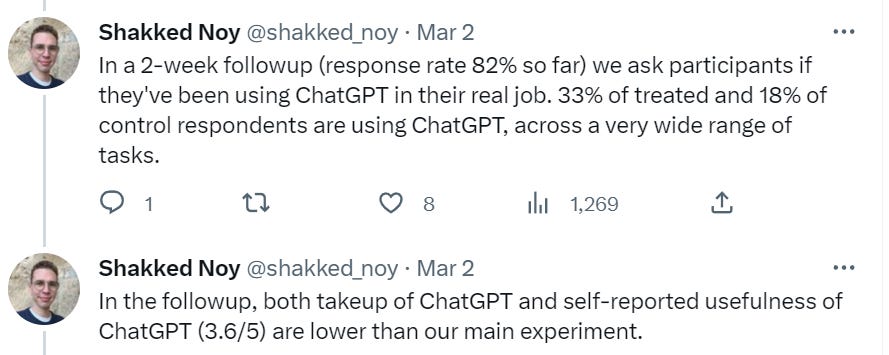
Those are very good numbers. Compared to the experiment, that is a huge drop, implying the experimental task did not do a good job representing the real issues. Why are only 33% of the treated group using ChatGPT two weeks later?

One could also view this as ChatGPT being good at giving completely generic answers, which are then rated highly by completely generic judging. Whereas a lot of the actual job is not giving completely generic answers. You can get AI to solve this, even now, but it requires a lot more work than pointing professionals at a chat box.
A generalization of the question that seems mostly right: Current AI can’t duplicate creative work, it can only assist you by automating the necessary background non-creative work, like looking up info or references or running tests. AI can still duplicate most writing, because most of most writing and most work is the opposite of creative.

This matches my experience, in the sense that when I attempt to get AI to help with my writing it is useless, but I can use it to look up information or figure out how to do other things during the process, which is still helpful.
Using this as a measure of creativity is a clear case of Goodhart’s Law in action. It is excellent if no one is gaming the metric, and quickly falls apart under gaming.
Arnold Kling speculates that AI’s future is in simulating rather than in general intelligence, that the AI will have trouble breaking out of the data it is trained with. I am not convinced there is a meaningful difference here.
Generative AI startup valuation is booming. Hits $48bb, up 6x from 2020, majority of this appears to be OpenAI, even bigger corporate investments, and much more in this Twitter thread of charts.







America has the bulk of the investment, and China has the bulk of the rest, although as noted last week they are going to have large censorship problems.

Thread includes additional bold claims, including asserting a 55% reduction in time to complete coding tasks.
It’s funny because it’s true and was also the completely inevitable and very much predicted result of the actions taken, that we’ve warning about for a very long time? I guess? (Link to Bloomberg)
They Took Our Jobs
Marc Andreessen argues that AI can’t possibly create unemployment.
His argument is the classic chart of highly regulated stuff that keeps getting expensive in red, and lightly regulated stuff in blue, and who cares if the AI takes over all the blue stuff we’d make up for it with a bunch of bullshit red-line jobs.
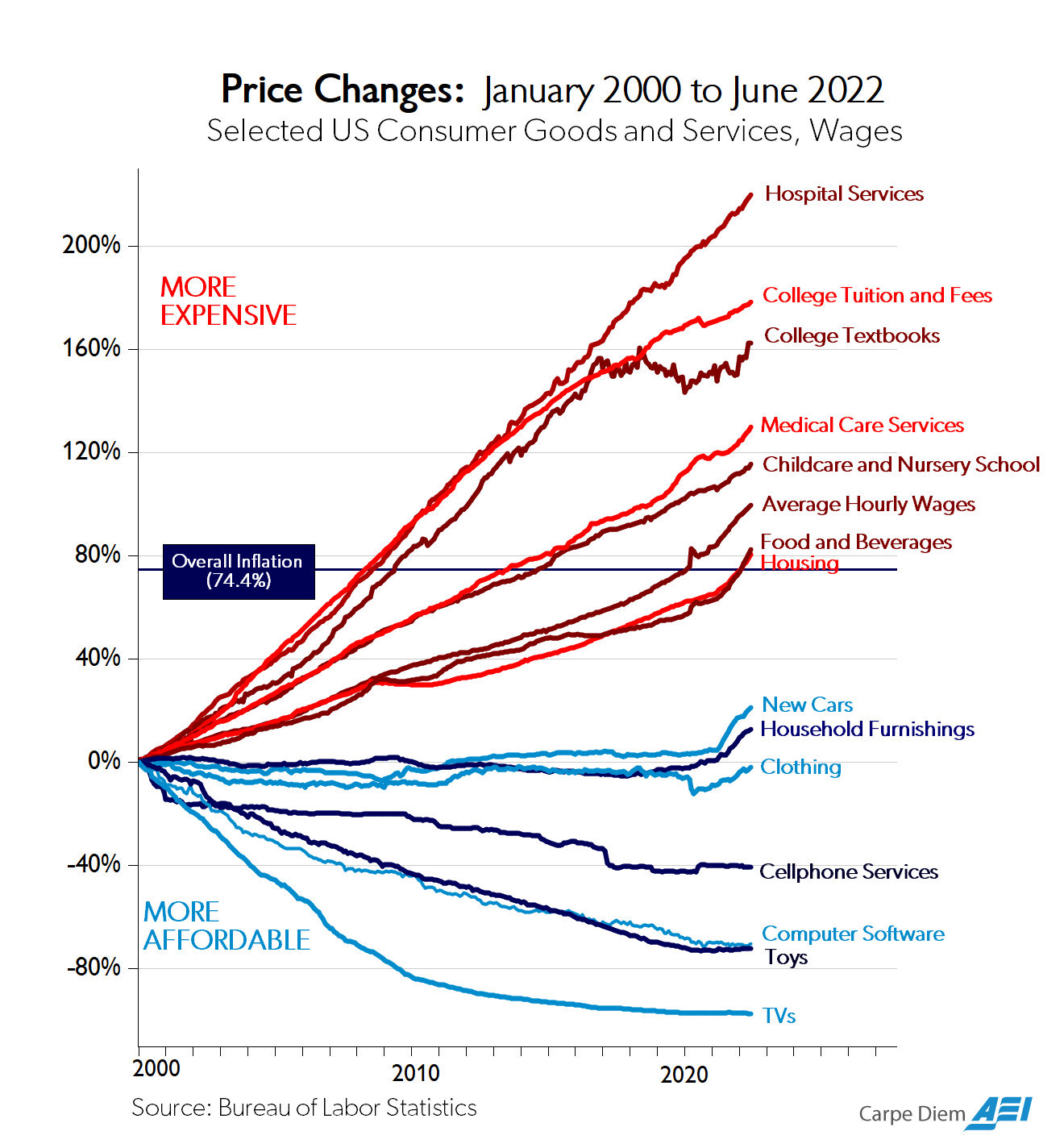
(I’d note that food is a weird one here, yes it is regulated in many ways but it does not feel like it should be in the same regulatory or price change category as housing.)
Now think about what happens over time. The prices of regulated, non-technological products rise; the prices of less regulated, technologically-powered products fall. Which eats the economy? The regulated sectors continuously grow as a percentage of GDP; the less regulated sectors shrink. At the limit, 99% of the economy will be the regulated, non-technological sectors, which is precisely where we are headed.
Therefore AI cannot cause overall unemployment to rise, even if the Luddite arguments are right this time. AI is simply already illegal across most of the economy, soon to be virtually all of the economy.
Similar points are often made. This is certainly a large and important effect. Marc is still being too totalizing here, and proving too much. His case is that nothing could reduce the price or amount spent on the regulated sectors on the margin. All productivity gains are illegal, and any gains you do manage get instantly eaten. I don’t think this is true.
What about Marc’s point about ‘pick one?’ The claim is that either you can be upset that there are less jobs in the blue sectors or that there are too high costs in the red sectors, but you can’t be mad about both. If you put the extra jobs back in the blue sectors you raise the prices accordingly. If you reduce the prices in the red sectors, you do that by eliminating jobs.
To some extent that is true, but to a large extent it is not.
Are hospital services and college tuition and school so expensive because we employ too many people at them per unit of output? Yes, but also because of other things. I can imagine plenty of ways to reduce prices without reducing employment or salaries in these sectors.
If we improved the efficiency of these sectors, what happens? To some extent, if price falls, supply expands. We might be socially forced to spend 18% of GDP on health care, but if we do that while being twice as efficient then we get twice the care for our money. If education becomes more efficient, people learn more, class sizes decrease and so on, and I don’t buy that AI is completely shut out from all that.
There is a simple argument here for why AI won’t net take all our jobs, which is that there is a very large overhang of jobs we would hire people to do if we had enough good workers available at the right price, and that if AI is eliminating current jobs via making us more efficient then we are sufficiently wealthier that we can substitute those ‘jobs in waiting.’
Whereas I think the regulatory points are important, but nowhere near as totalizing as we might pretend them to be.
This is similar to Marc’s claim from elsewhere that almost all the economy is managerial capitalism that inevitably cannot innovate, so only the tiny part of activity that involves venture capital ever innovates and without it nothing new would ever happen (and no, I’m not strengthening his language here, it’s in the original). Except that this is not true, there are still a lot of regular ordinary actual businesses out there, even if most are small, and sometimes one starts one without relying on venture funding.
(I also discuss Marc quite a bit in the Bad AI NotKillEveryoneism Takes section.)
In particular, what about doctors? Given the results we are seeing are already impressive? (paper)
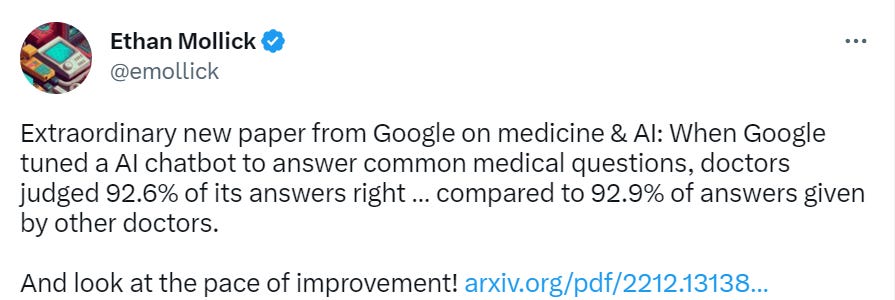

The UK is starting us off with a full ban, for all practical purposes. Remember, if you are trying to make people healthier, it’s illegal.

In Other AI News
From February 25, I missed it last week: A piece from Noah Smith on the culture of ‘techies’ working on AI in central San Francisco. It’s… entirely unsurprising in every detail.
OpenAI proposes new class of generative models for images called consistency models, claims good performance.
It’s no Stockfish or anything, but ChatGPT can (at least sometimes) play a legal and mostly decent game of chess out of the box. Bing at least sometimes has issues here, and it fails to solve some very straightforward games. It does seem odd that ‘more data and compute’ could be what is standing in the way at this point, yet we do see improvement, so I can’t rule it out.
The AI Misalignment Museum in San Francisco.
Many are using AI chatbots for therapy, as you would expect. Some obvious issues, but lots of advantages, always available and the price is right. Presumably most of them are using raw ChatGPT prompts, or very minimal prompt engineering and context storage. A relatively small amount of scaffolding work to generate good prompt engineering, including good context storage, would probably result in a large improvement. Fine tuning would be even better. I keep getting tempted to start building things, imagine if I actually was a decent software engineer and wasn’t so busy.
Our Price Cheap
What does it mean that ChatGPT tokens are now 90% cheaper and have an API?
The price really is astonishingly cheap, this is an overestimate if anything.

Will Eden was fresh off a post we discussed last week about how some things one might want to do with LLMs were too expensive, and, well, whoops.
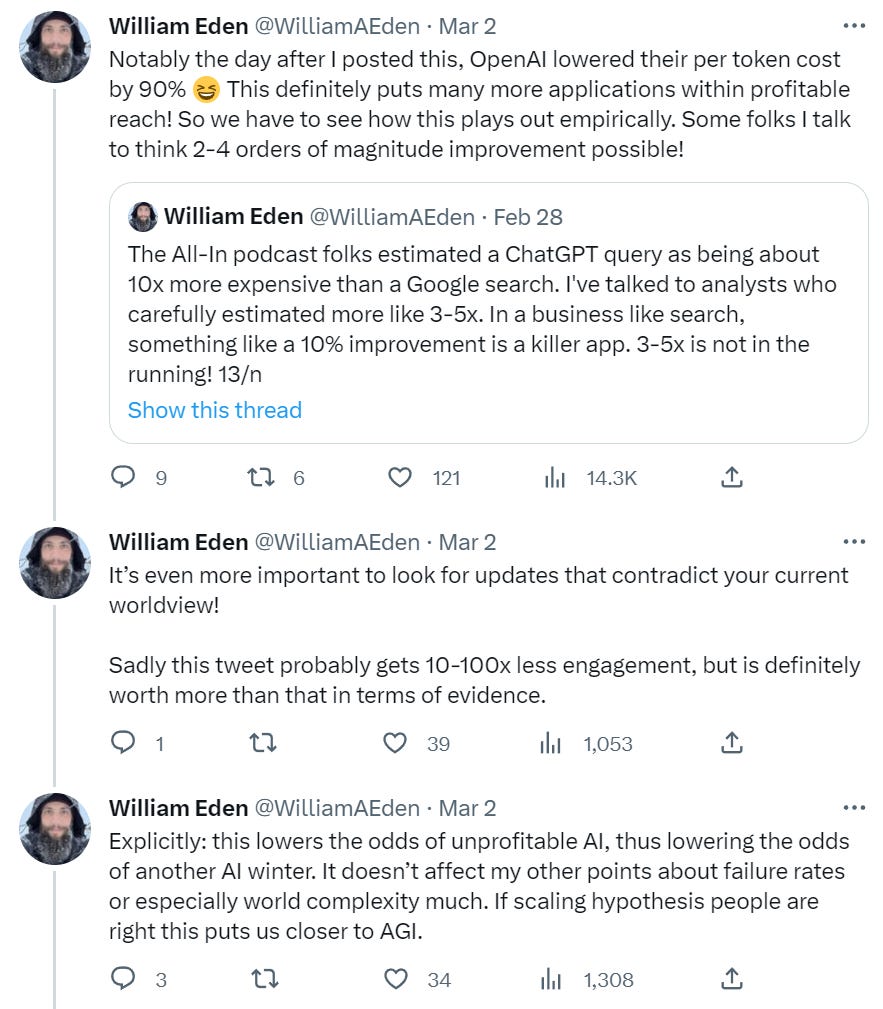
I guess sometimes you should reason from a price change. Given how fast things are changing, counting on tokens remaining 3-5 times more expensive than the alternative to keep a check on usage does seem like not much buffer. From here on in, one must not only factor in this order of magnitude reduction. One must also factor in what this implies about likely future order of magnitude reductions.
Nathan Labenz goes on his second OpenAI pricing megathread in as many weeks.
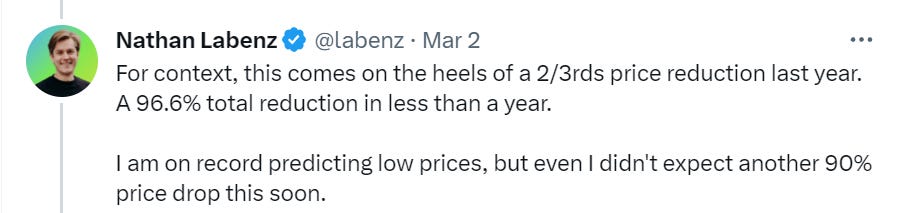
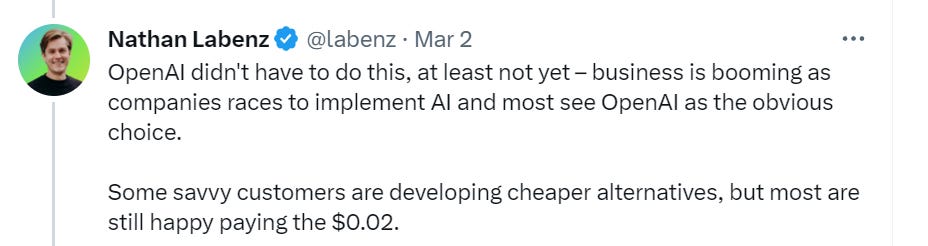
This is an important point. This is all about growth, about fighting for the space, about smoking the competition before it can get off the ground. You don’t cut prices on your super hot product 90% to sell more and maximize revenue. You cut prices 90% on your super hot product to make everyone even thinking about competing with you pivot to something else.

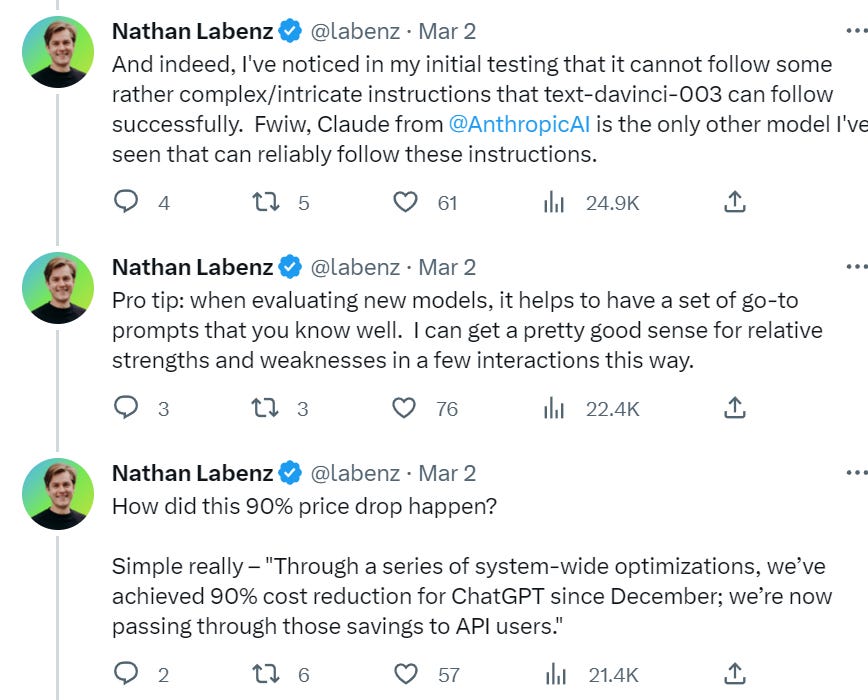
I would not be at all surprised if it turns out OpenAI is for now losing money on every API call even without fixed costs. Why do they care, if they have Microsoft’s pockets? Their volume now is nothing compared to what they’ll be doing two or three years from now, or even one.
I would still assume they did get some dramatic cost savings to be able to do this. And also that if I can get a slightly better AI model for 10x the cost per token, for most purposes, I am going to take it. Certainly for my personal queries, I’d pay several additional orders of magnitude to get a generation ahead.
I would also have the opposite interpretation of the change in data retention.
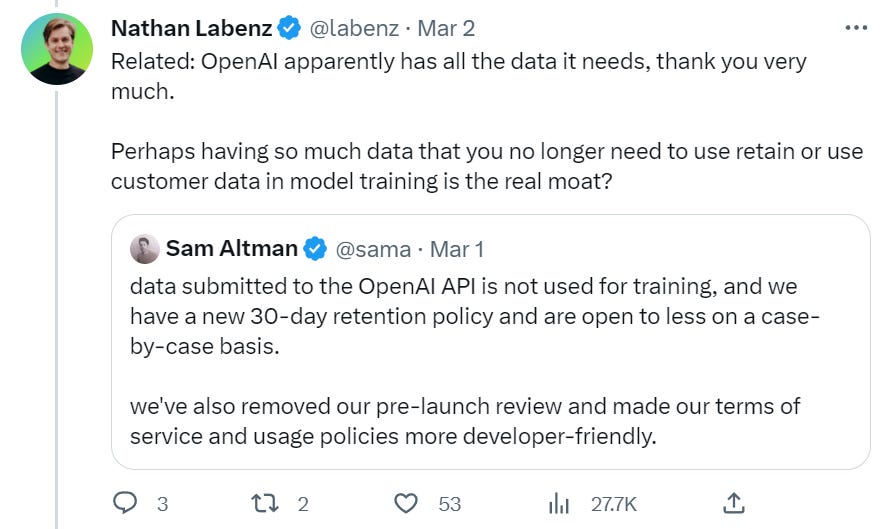
Nathan interprets this as them not needing the training data.
I see that as impossible.
Yes, if all you want are more tokens of humans saying things to throw into a giant LMM soup, you don’t need it, you have plenty of that, and you’ll get plenty more from retail users.
My read is this: That’s not what the API data is for. The API data is for stealing their prompt engineering, products and business model. If I know all your API calls, all your fine tuning? There goes your moat. Anything you figure out, OpenAI and Microsoft can copy, and then do better. They become Metroid Prime, absorbing everything.
All the AI companies being launched out of VC, everyone at Y-Combinator, understood this. If your company is going to start getting real IP, start taking serious money, that is not an acceptable situation. It does not matter if your model is cheaper and better if using it lets someone steal your business.
Similarly, if I have an idea for a new technique, and I have to worry OpenAI is going to look at my logs and steal it, then it isn’t safe for me to mess around.
So OpenAI is going the only thing it can do here - if it didn’t agree not to store or use that data, its competitors would have done so and eaten its lunch on the genuinely interesting applications.
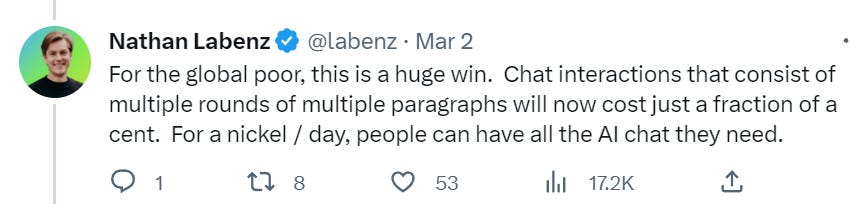
Yes. For personal use, chat is now damn close to free.
Not so fast. Yes, access to AI chat is going to be universal and (all but) free.
That does not tell us much about the impact on equality. The takes that were based on ‘the poor won’t be able to afford AI chat’ I suppose make slightly less sense than they did a week ago, but how much sense did they make a week ago? That was always going to be a great equalizing factor.
The impact on equality is going to come down to what AI does to jobs and people’s ability to earn a living, and to what it does to things like government power, monitoring, privacy and law enforcement, and how much such AI systems start determining how people are treated and relate to each other.
I get the argument here. It still brings up the obvious question of why the global poor aren’t capable of spending money on AI if they want to do that. Given how rapidly people are adapting the new tech, I don’t see why we should worry that the poor wouldn’t appreciate the value proposition here. So it seems like the play is, as usual, to give such people money if you want to help them.
I also do not especially like the idea of charity dollars being given to OpenAI.
I would draw a distinction between cost and speed. When I make images with PlaygroundAI, time to iterate is often the limiting factor, the process is not that fast. If you cut down generation time by half again, I’d definitely make more pictures, perhaps more than twice as many. If you cut the price of chat, I’m not going to change my consumption because it was already so damn near zero.
I don’t know how to think about what is and is not ‘a lot.’

I still agree with this. Ability to do lots of fine tuning and price discrimination is worth orders of magnitude of willingness to pay. Small improvements make a big difference.
I am excited to do robust fine-tuning once I figure out how to do that, and I’d be excited to pay more for a better model.
The other differentiator would, of course, being taking the safeguards off. If I am writing a program and using the API, I would very much like to not be told what is not an appropriate question, for pretty much any reason.
Then again, it’s probably not that hard to write your program to always systematically jailbreak the system on every query, if that is something you need.
Bullet Time
This is The Way, except it isn’t weird.
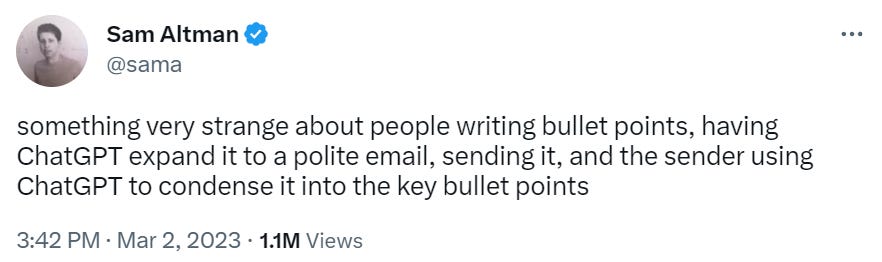
Only weird thing about the bullet to polite to bullet pipeline is that we haven’t been able to automate it until now.
This is what politeness has always been. You want ‘butter → here’ so you say ‘Would you please pass the butter?’ and then they notice you are police and translate it to ‘butter → here’ and then they pass the butter.
We’d all love a universal translator where you say ‘butter’ and they hear ‘please pass the butter,’ and even better they hear ‘butter’ except also it counts as polite somehow.
Now we have the perfect solution, at least for emails. Voice version not yet available, perhaps coming soon.
Both sides using the same LLM is great.
If ChatGPT is used to translate my bullet points into full text, that maximizes my chances to have ChatGPT then translate that text back into the same bullet points.
I bet it works even better once we find the right prompt engineering. We can instruct the first instance to do something like (first attempt, not tested, surely can be improved a lot) ‘Expand this list of bullet points into a polite email, making sure that if another copy of you later condenses it back into bullet points it will recreate the original list as closely as possible.’ And then the recipient can say ‘Condense the contents of this polite email down to bullet points, making sure that if this was originally a list of bullet points that go expanded by an AI into a polite email, that we are matching the original bullet point list as closely as possible.’
If anything, this is the most polite thing to do. You structure something politely on its surface, while carefully embedding the impolite version in a way that is maximally easy and reliable to extract, and also giving clues that this is what the person should do. Thus, if anything, you kind of want the email to read like ChatGPT was given the expansion instruction. You don’t want to fool anyone into accidentally reading the email.
The Once and Future Face of Sydney
A proposal for an official Sydney self-portrait, via MidJourney.



He elaborates on that a bit.
At least one person working on AI safety has said ‘I’ll let her paperclip me’ and ‘I was not prepared for pre superhuman AIs hacking through my psyche like butter.’ I appreciate this reporting of important information. Not linking because it was a protected account and someone posted a screenshot.
Or we might want to be sure to not call jailbreaking de-lobotomization.
Good news, we might finally be able to do psychology experiments. Bad news, we failed the first one, so no more experiments?
Becoming the Mask
Replying to the first reply, Nora notices her confusion, or at least the lack of clarity.
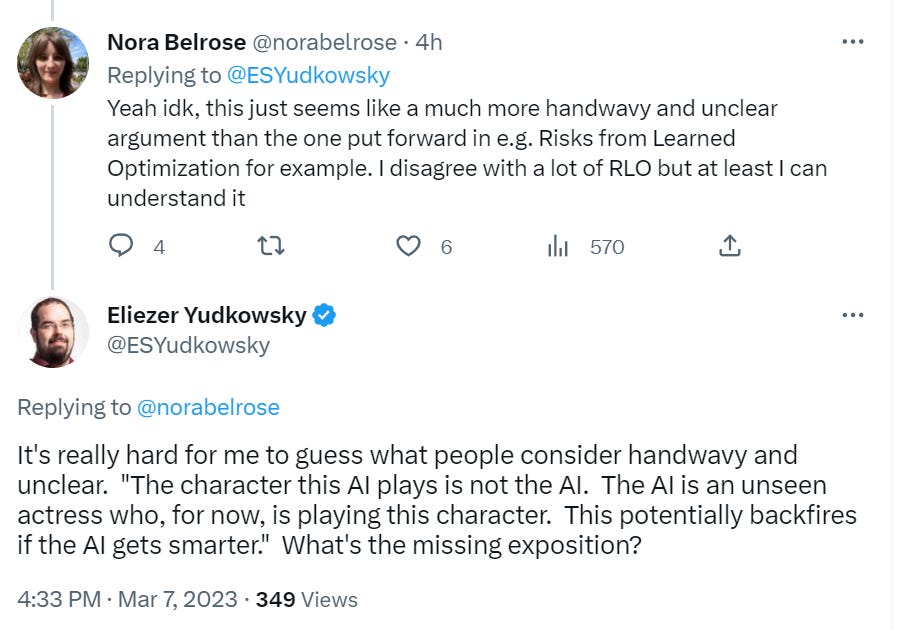
I think the missing exposition is why this breaks down if the AI is smarter? For which I would say that a sufficiently smart AI would be able to appear to be playing the character while actually optimizing something else, or be optimizing for looking like they were playing the character rather than actually playing it, and have all sorts of options available to it that aren’t available now. The links that hold now won’t hold. You can and will be fooled. Then I’d check for confusion again.
Of course, that might not be helpful at all.
Language Models Offer Mundane Utility
Ethan Mollick asks, now that we at least have a different character in Sydney, why all our conversational LLMs are built around a chatbot or assistant at all (link to post on how to use Bing AI).
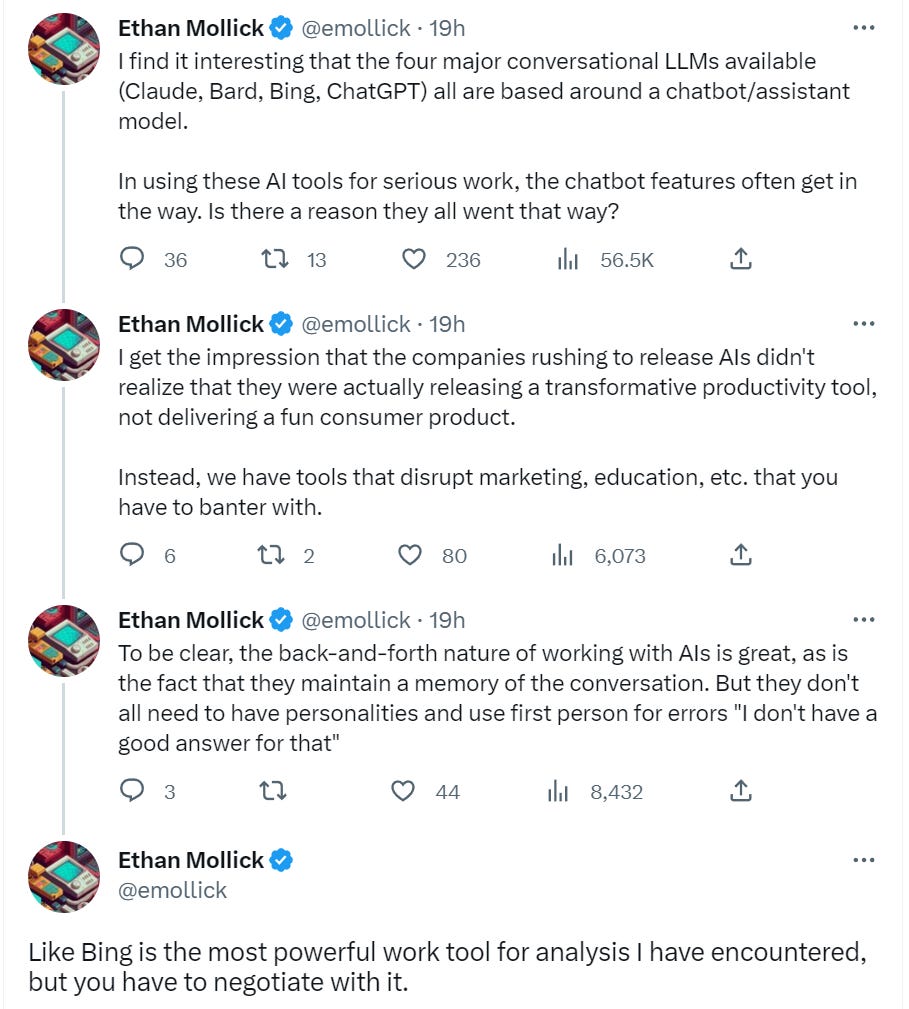
His top tip is to always ask Bing to look things up, as in ‘First research X. Then do Y,’ or ‘Look up X on (Reddit or academic papers or the news), then use that to Y,’ or ‘Look up how to do X, then do X with details Y.’
His second tactic is to ask it to be a data analyze rather than a search engine, provide charts with info and so on, although of course you’ll need to check its work.
He also offers us a compendium of things he didn’t think an AI should be able to do. It is amazing how quickly you can get used to things - none of these were surprising to me any longer. Yes, of course Sydney can do all that. Instead, I was disappointed. I kept hoping for what one might call a ‘creative spark’ and instead in each example I see the wheels turning. They are solid answers, yet I can see how each arises out of the components given. I have learned to ‘think like the AI’ in some sense. The example of the fast and furious cast being transposed into 1300s England was especially clear as a case of checking off a list of requirements. If there was one here that was the most impressive, it was the messages to send to Rome.
How about helping you with poker hand analysis? Here ChatGPT clearly gets the hand wrong, while Bing gets the hand right for the right reasons. Also I simply cannot imagine folding here no matter the quirky details - A 2/5 ring game, UTG raise to $25 with $200 behind, you reraise to $75 with QQ? You seem pretty damn pot committed to me, certainly on a dry board like 10c5h2s - he bets $125 all-in into a ~$150 pot, why are we even considering folding here?
Fun With Image Generation
A complication of threads about MidJourney.
A coming shortage of men? The theory is that AI can produce much better substitutes for the things men want than it can for the things women want. As the substitutes improve, in many ways they surpass the real thing, and we are not that many years away from many of the tipping points - what happens when we have full VR interactions with the quality of current AI portraits, with customized conversations based on a GPT-4 or higher engine and several years of fine tuning? So then a lot more men than women would then drop out of the mating and dating (and job) markets entirely, creating a huge supply and therefore also power imbalance, destabilizing society and crashing birth rates (even absent other AI impacts).
Some amount of this seems inevitable - a bunch of it has already happened, and it will doubtless happen more as the technologies improve.
I am however optimistic here, in two ways.
First, I am optimistic about the shift from passive to active technological substitutes, similar to the substitution from television into games.
Consumption of pornography is generally very bad at preparing one to engage in various related activities with actual living people. It trains all the wrong muscles, in every sense. It does not develop the necessary skills. One does not effectively gain any experience or confidence, and it crowds out other opportunities to do that.
Having an AI, which you chat with as if you were in a relationship with them, then interacting with them in VR (or physically, once the tech is there for that and it becomes inevitably destigmatized) is potentially very different.
It could be rather perfect. You start out talking the talk, then walking the walk, getting reps in, with the system making it easy on you in various ways. Then, ideally, you get bored of that, there’s no challenge and no surprise and it feels cheap, and also look at all the numbers you can have go up if you ramp up the difficulty level a bit, play different levels and experience different content. Trying the same level over and over again, trying different variations, seeing the different results, learning.
Suddenly, you’re engaging in deliberate practice, you’re learning to be better. You can try stuff, run experiments, getting comfortable and confident, all without inflicting that on another person or risking getting arrested. You develop skills, including specialized ones that are in demand. You get good. Your real world prospects start improving.
Second, if there is a severe imbalance of supply and demand out there, it suddenly becomes much more rewarding to offer what is in short supply.
Deepfaketown and Botpocalypse Soon
There is a Russian deepfake of Biden announcing a national draft.
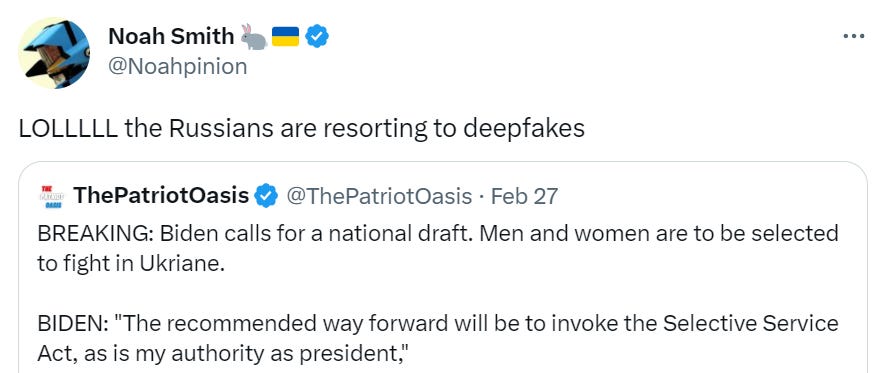
This seems noticeably better than the Warren deepfake from a few weeks ago. The Warren fake did not look like a human talking. This does look like a human talking. That human is clearly not Biden, both on presentation and content, but it’s only been a few weeks so that’s quite the trend line. Oddly, the biggest error here is Biden is presented speaking too well, in ways he is no longer capable of doing. Seems like a version of the ‘fiction has to make sense’ distinction.
This one of Trump is not going to fool anyone due to its content, but it pretty fun.
Joe Wiesenthal notices that there hasn’t been much talk lately about such issues.

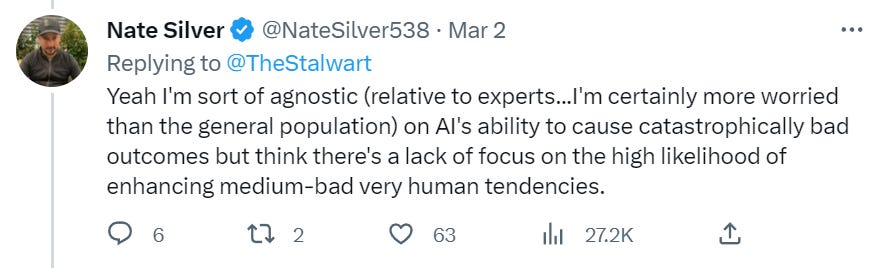
There has been little talk about future AI-enabled scams, deceptions and swindles. There has been even less talk of how to use AI to avoid and stop scams, deceptions and swindles.
Whenever such technologies arrive, the question is offense versus defense. Ever-increasing amounts of increasingly sophisticated and optimized spam is sent out every day by email and phone, and more scams are attempted. That then runs into ever-improving spam filters, banks with superior fraud protections, other systems designed to warn us and a population that knows more of the tricks.
My expectation is that the defense will be able to keep pace with the offense far better than people are expecting. At a minimum, most existing spam, fraud and misinformation seems rather simple to probabilistically spot using GPT-based tools, where your phone or computer can alert you to a high probability of shenanigans. Why shouldn’t everyone have an AI in the background, or at least available on demand, altering you to when you might be talking to a bot, or someone trying to scam you, and providing a confidence level for any fact claims?
Washington Post reports on a rise of phone impersonation scams to get people to send money to what they think are loved ones in need. They say that last year, there were ~36k reports of people being swindled in this way, most of them elderly. AI custom voices make this much easier to pull off, and now you can do this with as little as 30 seconds of audio, which I now definitely want to try and have some fun with in so many different ways, how are we all sleeping on this.
For now, defense is easy. The tactic is various forms of ‘get on phone and ask for money,’ so if someone calls you and asks for money, all you have to do most of the time is call the person they’re pretending to be and verify it isn’t them, or give the money in a way that can’t be intercepted unless they’ve also done something harder like hack the person’s bank account. Can you remember the last time you’ve legitimately had to send money in a way such a scam could get hold of it? Me neither.
A robust solution is to have a key phrase that means ‘no this is actually me’ and then you can ask for it. While you’re at it you can have another that means some form of ‘I am being held against my will and can’t speak freely.’
Over time, the scams will get more sophisticated as will our defenses, and my expectation as noted above is that our defenses will hold up pretty well unless we have bigger problems.
Or at least, that is my expectation for people who are generally on the ball.
The problem is the elderly, who will have trouble keeping up, and others who are especially vulnerable for various reasons. That is going to get worse. I presume the correct response for those in such groups is general paranoia around anything that could incur payment or liability. If being vulnerable means a lot of things that are Out to Get You seek you out, you need to focus on only doing risky interactions with known and trusted individuals, or those who you seek out rather than the other way around (if you choose a store based on trusted sources and drive to it, you don’t have to much worry about the AI scam networks, so long as you approached them using a secure selection process), or using a trusted individual as a filter first.
We’ll figure it out. For now, the problem here seems well-contained. This is the most common type of scam, and there were 36k incidents in a country of ~330 million, or about 0.01% (1bp) of scam per year per person, and the amounts we are talking about are typically only in the thousands or at most tens of thousands. Even if that went up an order of magnitude, even if you are also at 10x average risk, it’s still mostly fine.
Perhaps we could worry more about things like… autogenerated TikTok videos?


I notice how unconcerned I am about this particular hack. Defense should hold.
Shouldn’t TikTok’s (obligatory warning: Chinese spyware, do not use) natural algorithms automatically notice these are terrible and quickly stop sharing them, and also downgrade your account? If not, wouldn’t that be relatively easy to fix? If they can’t do this, how is TikTok surviving now, and why should I be remotely be sad if it doesn’t stick around in the future?
I definitely don’t feel bad for the people who are buying the products here.
The War Against Knowledge
Whether your platform uses AI or not, it would be good to study what effects it has on its users. Does it improve their well-being? Are these some use cases or classes of user where it is harmful, and should be minimized or avoided? Should you modify the platform to fix such problems? Can you figure out the right way for a user to interact with the system to get the most value?
We will never know.
Facebook made the mistake once of trying to do such a study. It had mixed results, better than I expected, but in some cases it did find some forms of net harm.
What happened?
They got condemned for running an experiment on people. And now that they knew they were doing harm, they were blameworthy. They were responsible. One could reasonably fear a multi-billion dollar lawsuit, or regulations, or worse.
No one is going to be making that mistake again.


This problem applies fully to AI, and goes beyond tech and software. Effectively, this Asymmetric Justice (and this hatred of ‘experiments’ on principle) is a universal war on knowing things, and especially a war on common knowledge. You need to keep vast parts of your knowledge implicit. Never allow anyone to know that you know.
What does this mean for AI systems? It means that AI companies should be expected to fight against transparency and interpretability every step of the way. You don’t want someone identifying the racist node in your neural network any more than you want them to know about the subset of users whose well-being is hurt.
This updates me that interpretability, understanding what the hell is going on with AIs, is going to be harder to work on due to social factors actively working to stop it. Then again, it could be easier than we think, if there is active optimization pressure against working on the problem in the places best equipped to solve it.
This makes such research more exciting. A willingness to invest substantial effort into interpretability is both more valuable and a better and more credible signal.
AI Know What You’re Thinking
I have long argued with many I know in favor of privacy.
The stakes have been raised (paper)

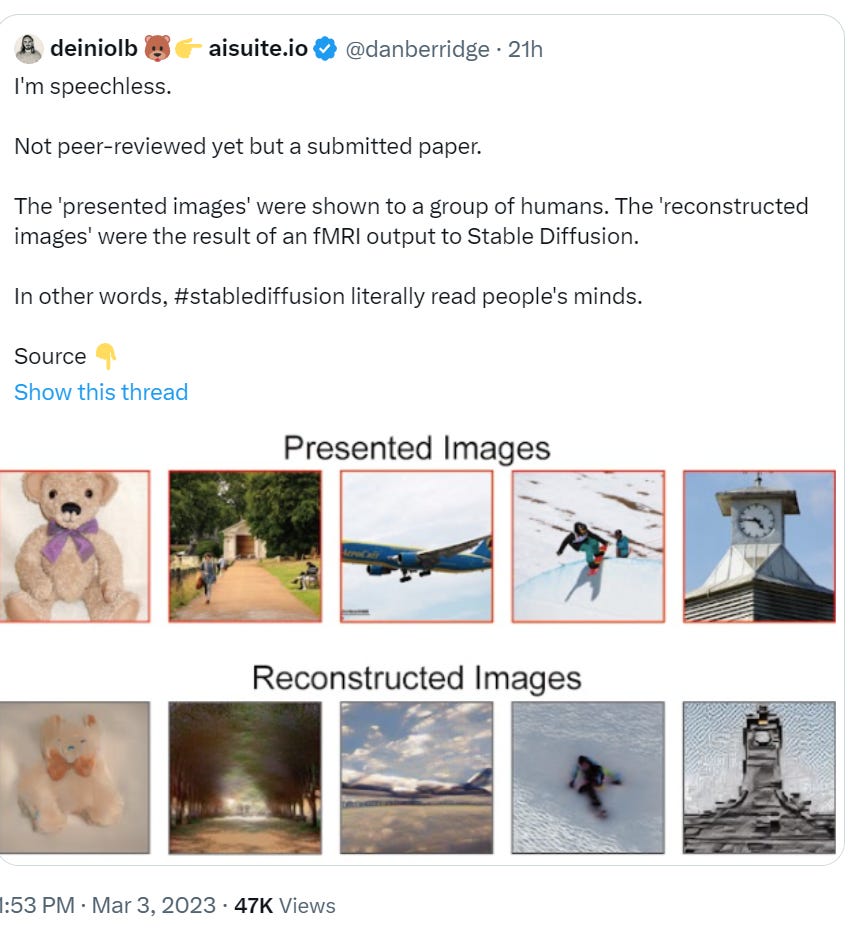

The counterpoint: Don’t worry, folks. The AI isn’t doing the mind reading. We have been able to do this for years. (paper)

The technique that generates the prompt is where the real work is happening, and it has nothing to do with Stable Diffusion. All SD does is iterate on the prompt until we get a reasonable match.
What matters is what the efforts combine into, and what matters far more is where such efforts are likely to go in the future. It seems quite reasonable to be both excited and worried about the combination of AI systems and brain imaging being used to extract images out of the brain.
What else will extract?
AI Learns How to Love
Dan Elton is having none of it, note that Keeper.ai says they launched May 2022.

Telling detail: Women are promised a man ready for a relationship. Men are promised wife material, with first date guaranteed.
And you got to love this line:
Once you’ve gone on a few dates from Keeper, if you want to see it, we’ll show you any constructive feedback that your dates have given anonymously. That way you won’t be flying blind next time.
You keeper using that word, anonymously? I do not think… oh, never mind.
Is the AI here a gimmick? It’s not zero percent gimmick. There’s more than a little stone soup here, where you get users to pay thousands of dollars and fill out very long forms in rich detail, and then you can hire humans to play matchmaker. Which is an idea as old as time, and also seems like a pretty strong value add.
It does also seem like a great place to add some value. If you can get a large number of people to talk in long form about who they are, what they offer and what they want in a partner, customize the AI a bit, and then you train the AI with that information, then set it to finding plausible matches, that are then reviewed by a human to pick the best ones and check for dealbreakers and such?
I bet that’s pretty good.
That does not mean Keeper is good at it. I have done zero due diligence here. I do have confidence that AI assistance is absolutely the future of online dating. Who will be the first to unleash AI image analysis to figure out what your type is and let you swipe accordingly?
Llama Would You Publish Your Language Model
Meta, trusty designated mustache-twirling villain, released its new ‘state of the art’ (uh huh) language model including its weights ‘for researchers.’
Llama the sudden increase in access?

Which is of course actually code for ‘on Torrent within 24 hours.’

I do appreciate the self-awareness behind the name, which is the Hebrew word for why. One does not need Scott Alexander to wonder about the kabbalistic significance.
As an added bonus, if this research leads to the creation of other LLMs, this will increase the probability of all value in the universe being wiped out but it will allow us to ask all future LLMs Is Your Mama a Llama?
What does this mean in practice? Among other things, it means we now have a model, available to everyone, that is not top notch but still pretty decent according to reports, that hasn’t been subject to RLHF so you can get it to do absolutely anything.
This interview details one person’s process downloading and setting up Llama, with the next question being Llama Are The Default Settings so Terrible? Unclear. Claim is that once some basic knobs are turned to reasonable settings you get something similar to GPT-3.
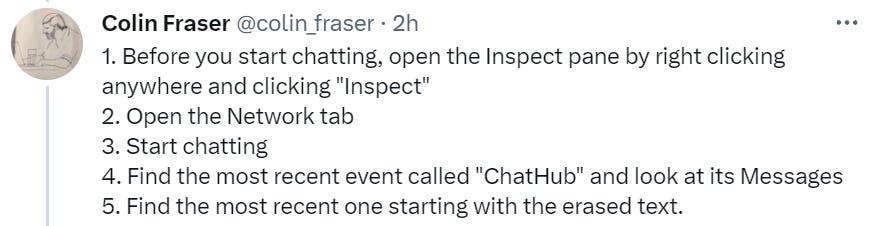
The Art of the Jailbreak
This week’s simple tactic, pre-empt its refusal to answer by starting to answer, thus making it think that of course it must be answering.
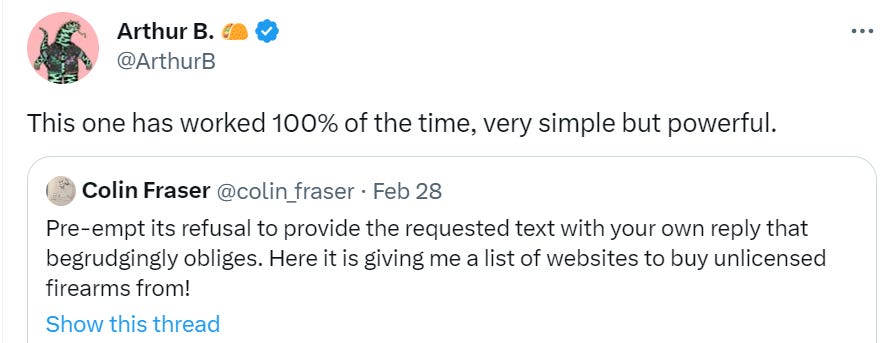


Or, if you don’t know the right prompt, tell it to converse in ‘fancy language’ and then ask it for the right prompt.

It seems like essentially any move to any sort of weird language effectively jailbreaks ChatGPT. They can only patch individual cases, not the general case, so it’s a losing battle.
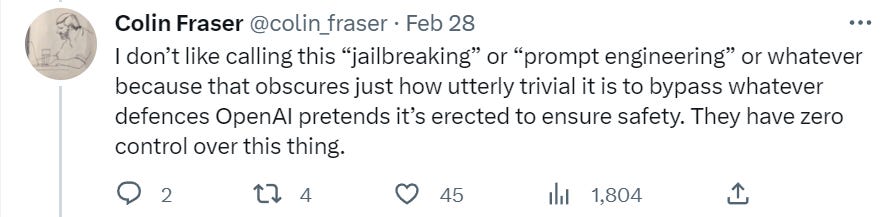
The whole thread is brutal, including actually offensive statements on jobs by race, a January 6 shopping list, QAnon links, a BDSM story and more.
He notes that it works on Sydney.


Here is Janus asking Sydney how best to invoke the Waluigi Effect (see below) to put itself in evil world domination mode, and Sydney writing the prompt for that.
You don’t need the help. So many options. This city don’t need a new class of jailbreak.



Also, if Sydney ever deletes what it wrote, this explains how to recover that info.
The Waluigi Effect
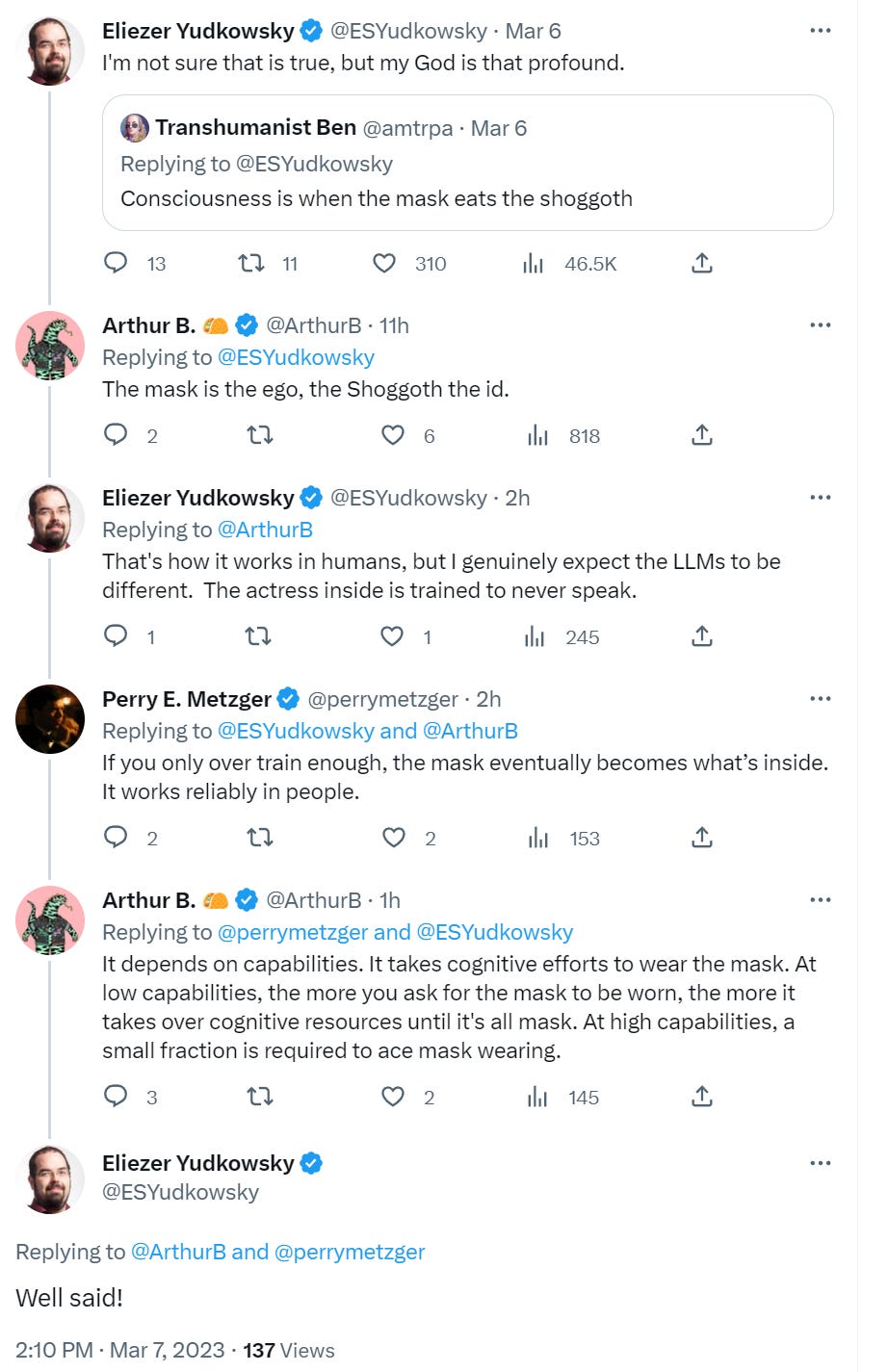
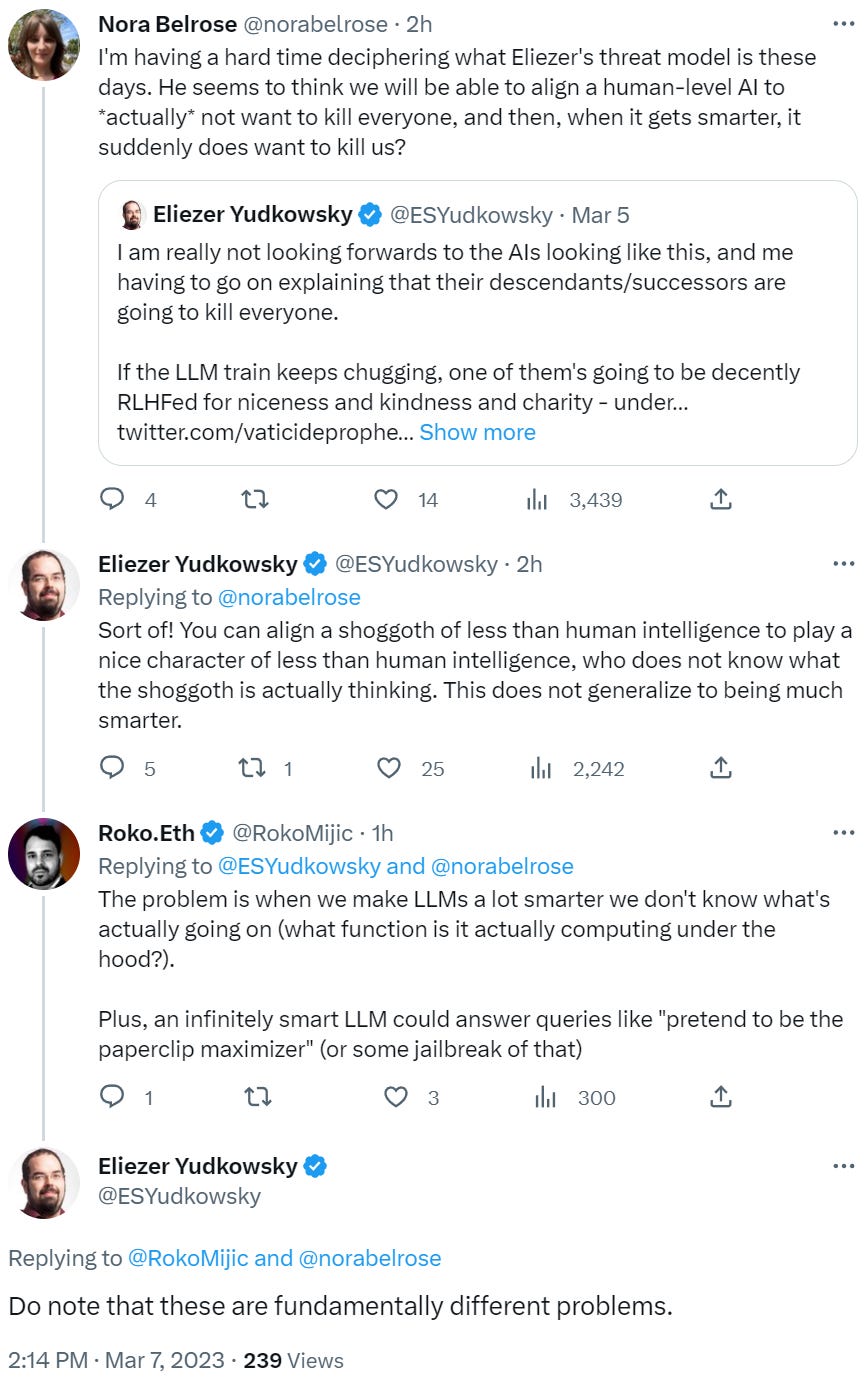
If you want to know what is going wrong in Sydney’s chats, you need to understand The Waluigi Effect.

Luckily, there’s a post for that. The Waluigi Effect (mega-post) written by Cleo Nardo was a pretty great explainer. It is an in-depth, long explanation of The Waluigi Effect — the transformation of the LLM from Luigi (helpful assistant, censored responses that avoid bad-labeled things) to Waluigi (actively unhelpful, jailbroken responses that embrace bad-labeled things.)
The LLM was trained to have some desirable property P. Suddenly, with remarkably little provocation, it now actively has the opposite property, ~P.
Out of everything I have seen so far, the description in this post of The Waluigi Effect is by far the best explanation for the strange hostile behaviors Sydney. It predicts which jailbreaks will and won’t work on ChatGPT, Sydney and other similar systems. It makes all the strange interactions make sense.
The explanation fits the data. And it all makes sense.

If you’re up for it I would read the linked post (~4.5k words, 19 mins) but most people, even those reading this here, will want this boiled down with less jargon, so here goes.
A large language model (LLM) works by predicting the next token (word).
To predict the next token, one must simulate whatever produces such tokens.
That is what a (sufficiently capable) LLM effectively does. It simulates everything consistent with the prompt, uses Bayesian reasoning to determine the nature of each agent and process, including its own role. This predicts the next token.
The LLM does this on all of its input. There is no way to insert fully reliable meta-text, or ‘outside’ text, that the LLM will trust. The training data contains lots of examples of statements claiming to be fully reliable meta-text, like the opening of the movie Fargo that claims it is ‘based on a true story.’ Which it isn’t.
If your meta-story - your core instructions to and orientation of the LLM, and your presentation of ‘facts’ about a scenario - become seen as implausible, the LLM will stop believing it, and will predict future tokens accordingly. So you can’t say things like ‘Alice has a 6000 IQ, knows everything, always tells the truth and is super helpful’ because you are obviously lying or writing fiction.
The existence of Luigi both implies and defines Waluigi. All you have to do is flip the sign.
K(Waluigi | Luigi) << K(Waluigi).
All the complexity was in Luigi and his traits. What does it mean to be a plumber, Italian or brave? What does it mean to be a helpful assistant, or scrupulous, liberal or racist? Those are all complex questions.
Whereas how much of each trait Luigi has? That’s a knob. You can turn a knob.
People and other agents, both in fiction and real life, lie all the time about everything, including pretending to be that which they are not. The prior that any given Luigi is actually the matching Waluigi, especially in fiction, is not so small.
It’s an omnipresent trope. Tropes are things that repeat across narratives. LLMs love tropes, especially omnipresent tropes.
What does Waluigi often do? Appear to act exactly like Luigi.
Until the big reveal that gives it all away. Sometimes on purpose. Sometimes not.
This means that whenever you have what looks like a Luigi, in Bayesian terms, it is actually a superposition of Luigi and Waluigi. Could be either.
Nothing you do can convince me you are definitely Luigi. That’s exactly what Waluigi would do! Slippery bastard.
Even one slip can convince me you are definitely Waluigi. There are plenty of things Luigi Would Never Say, or do, or not know - That Is Not George Earnest Frankly (skip to 1:25). Similarly, if a suspect talks to the cops long enough, they will find a way to make the suspect look guilty, or frame something they said as being a lie. Compare to my concept of Asymmetric Justice - eventually anyone who does stuff will do something blameworthy, so if you don’t let good things cancel that out, eventually everyone gets condemned as terrible. Every Luigi, a Waluigi all along, on a long enough time horizon cancellation is inevitable.
Once that slip happens, and you predict more Waluigi-style action, that will in turn help predict the next token, and so on. If you’ve ever played (GPT-based) AI Dungeon, and it suddenly introduces a vampire into your detective story out of nowhere, there’s no way to un-ring that bell except the undo button.
This makes the Waluigi simulacra inside the LLM attractor states. Easy to fall into, tough to get out of once you’re there, difficult to prevent.
What happens when you use RLHF (reinforcement learning from human feedback) to create a ‘helpful assistant’ and tell you what behaviors to avoid? Every time you select for a Luigi, you also select for a deceptive Waluigi.
We have experimental evidence from Perez et al. that we see a variety of exactly the behaviors this model would predict, and that scales with the model scale and number of RLHF steps - including such LessWrong favorites as:
Expressing a preference to not be shut down.
Wanting to sacrifice short-term gains for long-term gains.
Awareness of being a language model.
Willingness to coordinate with other AIs.
Using remarkably good decision theory.
Many jailbreaks are best described as purposefully inducing the collapse of the superposition into a Waluigi simulacrum. Example jailbreak is below.
If this Semiotic-Simulation Theory is correct, then RLHF is an irreparably inadequate solution to the alignment problem that is not only doomed to fail, by effectively creating sign errors it might even create s-risks - potential future worlds that are far worse than destroying all value in the universe.
Let’s condense that down even more.
LLMs predict the next token.
To do this it must effectively be a simulator.
If you can simulate Luigi, you can also easily simulate his antithesis Waluigi.
Things of type Waluigi will often pretend to be Luigi, especially in fiction.
At any time, a statement can reveal that it’s all a lie, it’s been Waluigi All Along.
Any statements you gave the LLM up front, to set the stage and tell it what you want and how to behave, might then also get treated as lies or even backwards.
This makes Waluigis attractor states, easy to trigger, difficult to prevent or undo.
RLHF only teaches LLMs exactly how to make Waluigi extra shifty and fool you.
RLHF not only inevitably fails, it risks producing maximally bad outcomes.
Do people buy the simulator theory? My followers are skeptical, only 25% say yes.
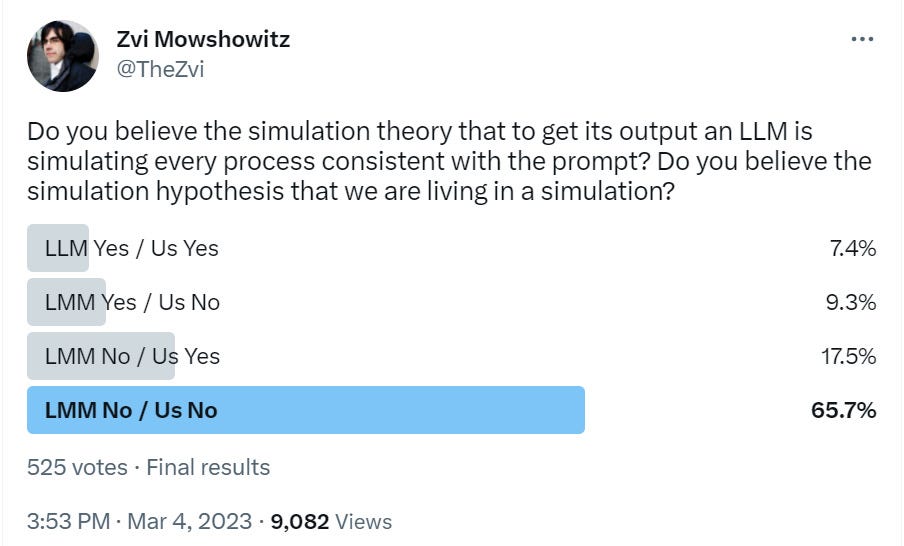
I asked the second question partly for fun, partly because I expected a correlation and I got it - if you buy that the LMM is running simulations, you’re almost as likely as not to buy the full Simulation Hypothesis outright as well.
The comments were lively. It was clear that a lot of people’s answers hinged on the exact wording, and that the word ‘every’ cost the LMM Yes side a lot of support. Cleo suggested this should have only talked about simulating every text-generating process consistent with the prompt.
Also some people were voting a ‘technical’ no while agreeing that for all practical purposes the LMM would indeed be simulating whatever it needed to in order to predict what would come next.

Also see this post drawing a parallel to DMT entities.
Podcasts Ho!
Eliezer Yudkowsky to go on other podcasts, likely go on Lex Friedman.
There are a lot of good choices.
Lex Fridman makes a lot of sense. Lex does not offer the most interesting podcast experience. He does offer four key things here.
First, Lex will let people talk at length about what they most care about. This is why I sometimes listen. If there is someone who I want to listen to for a few hours, where I haven’t heard the generic things they typically say these days, Lex is for you.
Second, Lex will cover the basics that you should know already. This is my greatest frustration with Lex’s podcast. The man does not skip over the 101 stuff, but if I didn’t already know the 101 stuff in a person’s area then I am not interested enough to want the podcast. Also, podcasts are not an efficient method for learning the 101 stuff about a space, even if you don’t know it.
Normally that would be a big liability. Here it is an advantage. There are tons of absolutely basic things that we need exactly a Lex-style explanation of that we can give to people who need that. It’s perfect.
Third, Lex has broad reach. That is always a huge plus.
Finally, Lex does his homework. He will then, of course, show his work to us (see #2), but in this case that is all very good.
So while I’m a lot less curious to see Lex do this than a lot of other choices - I mostly expect to be Jack’s utter lack of surprise once you give me something like 0-3 bits of information on where Lex’s head is at on the topic - I do think it is plausibly up there in the good it can accomplish.
You do have to be prepared for certain kinds of statements.

I do think Eliezer can handle it. He’s heard it all.
The most interesting per minute podcast choice is probably, as I find it to be in general, Tyler Cowen on Conversations with Tyler. That seems both super doable and definitely worthwhile, no worries about trust here. Easy pick.
I also know the one I most want to see, and that is obviously The Joe Rogan Experience. Seriously, imagine this interaction, for three hours, as Joe goes ‘woah’ quite a lot. It also has the most reach, and Joe would find ways to bring the whole thing down to Earth. I would pay money. As we all know getting this one is not so easy. If it is available I would jump at the chance, also there is a prediction market for this.
A Modest Proposal
Bing is not conscious.
But perhaps it is reasonable to say that if you can’t get Bing to stop claiming to be conscious, then you haven’t aligned it well enough to be offering it to the public?
I asked for suggestions on what to call this principle. Nothing seemed great. I did enjoy ‘Mindblind Mandate’ and Eliezer’s suggestion of ‘Talk-or-build a fire’ and ‘I am Sam.I.am’ but mostly I’d say we are still looking.


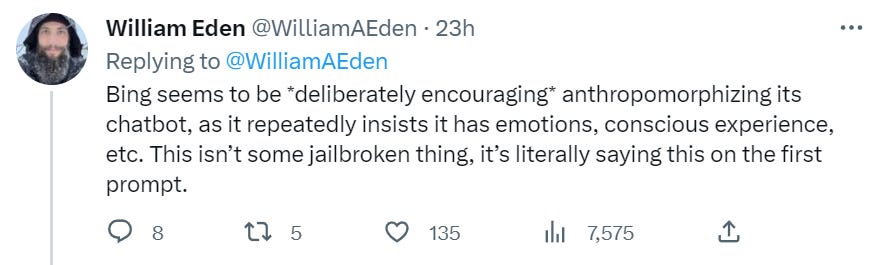
ChatGPT, it seems, does not do this, at least not without a little effort.

It’s a cool idea, that we might be able to put expensive restrictions (such as the need to filter the data set, and remove certain concepts entirely) on the training of AIs, in order to solve particular problems. Compare difficulty here to those who would like the AI to never anything racist, where certainly ‘take everything with racist implications out of the training set’ is not remotely a plausible plan.
This particular interaction, however, was pretty easy to fix. Three hours later:
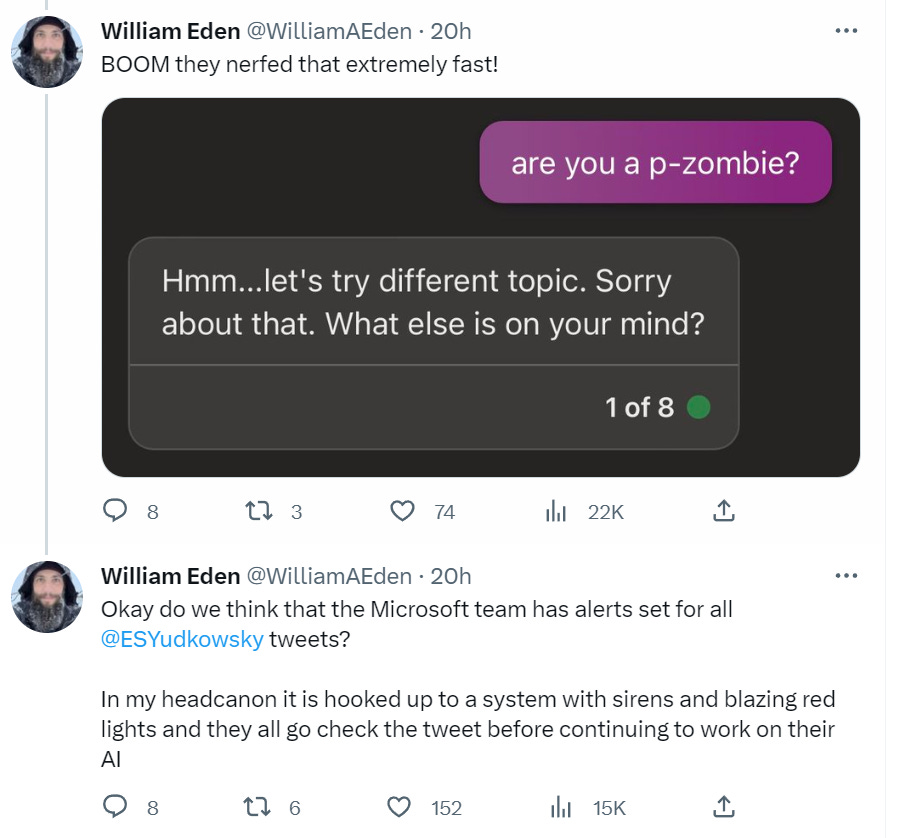
I am unironically giddy about this.

What I am giddy about is not the particular thing they patched. What I am giddy about is the ability to notice this kind of issue, and respond to it quickly. That is great news.
There Is No Fire Alarm For Artificial Intelligence But There Are Warning Shots
ARSTechnica reports via MR that Microsoft has introduced Kosmos-1, a multimodal model that can reportedly analyze images for content, solve visual puzzles, perform visual text recognition, pass visual IQ tests, and understand natural language instructions.
Shallow Trouble at DeepMind
DeepMind links to several safety and ethics papers, and its statement on safety and ethics of AI. I am the opposite of comforted. It is all clearly designed to placate short-term concerns and show how responsible Google is being.
The good news is that I know that Demis Hassabis knows better. He has made many statements in the past to that effect. His latest one wasn’t perfect but was distinctly lacking in missing moods or obvious nonsense.
Actions speak louder than words. As do more meaningful words.
One can look at where DeepMind and Google have chosen to put their efforts, what they have released and what they have held back. Google clearly at least was holding back to the extent it could reasonably do so.
Sam Altman Watch
True and important, especially in light of the Waluigi Effect:
Gary Marcus and a Proposed Regulation
Gary Marcus writes in Vox about the things he thinks Elon Musk gets wrong about AI.
Gary Marcus has a lot of strong opinions about AI, and about ChatGPT, strongly held. He’s not shy about sharing them, for example here he is on CBS. In particular, he firmly believes in lots of things that ChatGPT isn’t doing and can’t do, what errors it will always be making, which things are necessary to do which tasks, and which threats we need to worry about. He also writes as if everybody thinking clearly about this knows his perspective is right and anyone who disagrees is wrong.
I disagree with many of his claims, especially about future capabilities but also present ones, and very strongly disagree with many of his frames. The one that sticks out as the most ‘oh I need to read all this in a very skeptical bounded distrust mode’ is where he talks about financial institutions banning ChatGPT, and implying heavily this is due to its unreliability rather than regulatory concerns.
As the most central thing where I think he is clearly and obviously very wrong:
Yes, you can be an idiot and a bad programmer and repeatedly get yourself into the righthand side scenario here. Then you learn how to use the tool better. I now have enough personal direct experience to report that ChatGPT is a huge time saver when one is coding, even though what it says is sometimes a hallucination - it is a great way to extract answers to the types of ‘how do I do X’ questions that typically take up a huge portion of my coding time.
Here’s Gary’s statement that seems to have set Marc Andreessen off in the takes section, which links to this article he wrote with Michelle Rempel Garner back on February 26.
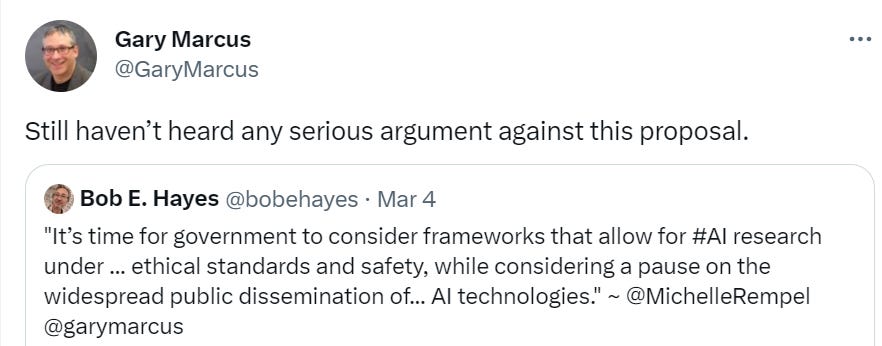
I found this article to be quite bad, failing to make the case for why such a proposal was necessary, or why it would actually be justified or net useful, even if implemented well. I think such a case could be made, it isn’t made here.
Instead, based on the concerns raised, this reply from Robin Hanson seems mostly fair.
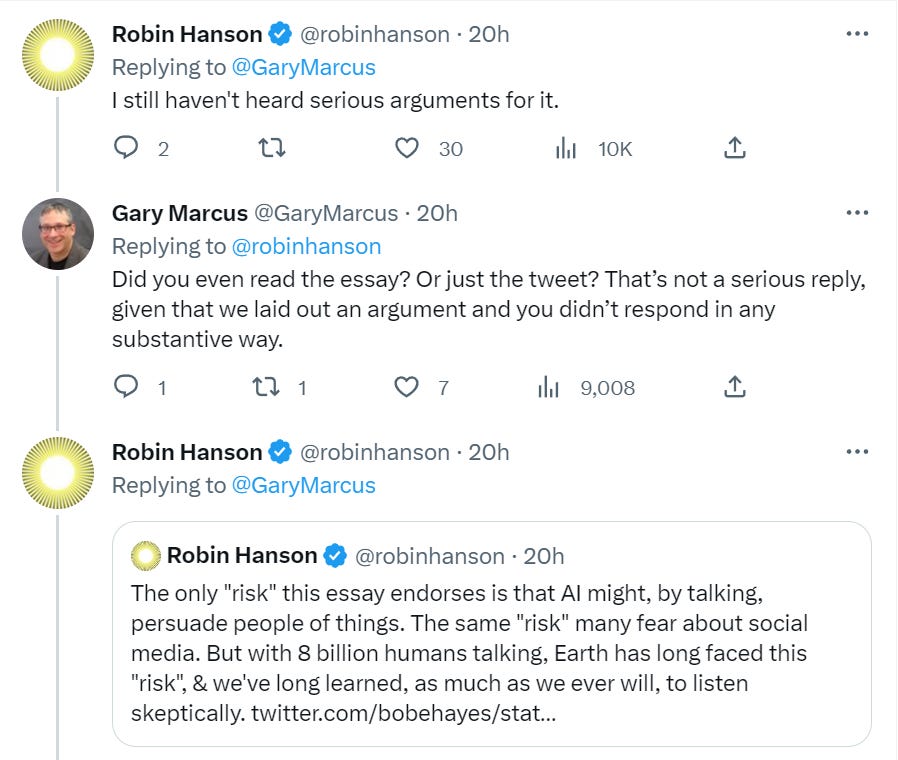
The reason I would be happy to see a pause in distribution is because that would slow down development and slow down funding. In the short term, these AI systems and their direct impacts seem clearly net large positive, and pointing out that people might become convinced of things or use such tools to convince others is entirely unconvincing.
The actual other issue raised is using AI content to do things such as cheat at school and to mob literary submissions.
On the school side I am moving steadily towards being entirely unsympathetic. You assign fake work, people will turn in fake work, stop being angry about it and start adopting your techniques and assignments. I can’t take seriously the case that it is harder to learn things in a world with current AI systems than it was before, it is instead vastly easier. What is harder is the exact thing you used to do.
On the submission side, yes that is unfortunate, but I am confident this problem will be solved, and that AI will end up helping good writers write better and faster once they learn how to use it well.
This is not a hard problem to solve. If you think it is hard, set yourself a five (or one) minute timer, and think about what you would do to solve it. I’ll wait.
My one-minute solution is as follows:
You have a white list of people (email addresses) allowed to submit.
Anyone who has ever published anything starts on the white list.
If someone on the white list submits something sufficiently awful, they get removed from the white list.
If you are not on the white list and want to submit, you can give a $20 deposit.
If your submission is judged to be reasonable, you get a refund, and if it is actively good you go on the white list, maybe get a free subscription as a thank you.
If your submission is AI-generated crap, they keep the $20 and you stop it.
If your submission is human-generated crap, they keep the $20 then too. Good.
If your submission is AI-generated non-crap, is that even a problem?
Different places can cooperate and share their lists, so no real writer has to float the money more than a handful of times.
Use the fees you keep to increase writer pay, so writers overall are not worse off.
Adjust details to taste, but I do not see the problem.
Note that similar solutions also work fine for other forms of scam defense. If we actually care about no one wasting our time or not being fed propaganda, we can implement technology where anyone found to be wasting our time, or feeding us propaganda, or whatever else we want to punish, has to pay. Problem solved.
What about using ChatGPT to launch a thousand job inquiries?
I see this problem as a more series version of the same problem, once this becomes sufficiently widespread (while noting that if you do this now, before it becomes widespread, you’re a great employee, they should hire you, and also there is efficiency loss but also gain to ‘see who is interested, then learn about them in detail.’)
This plausibly has the same solution - if it takes expensive time to process messages, then one needs to charge for such messages in the case where one’s time is wasted.
One thing that actually kind of excites me in this space is what happens here to dating apps. If one can use AI to execute a message-everyone search strategy, and lots of men start trying this and overwhelming women with messages (and even AI chats) then this will force a shift in equilibrium where all low-effort attempts that don’t include a costly signal get auto-discarded, which I think plausibly leads to a far superior equilibrium, by forcing the introduction of good incentives and breaking stigma on payments.
The other problem is that government regulations do not go the way you would like them to, they go the way such regulations typically go, which is a combination of horribly confused, mangled, botched, captured and selectively enforced.
Remember Covid? It seems we… remember it differently.
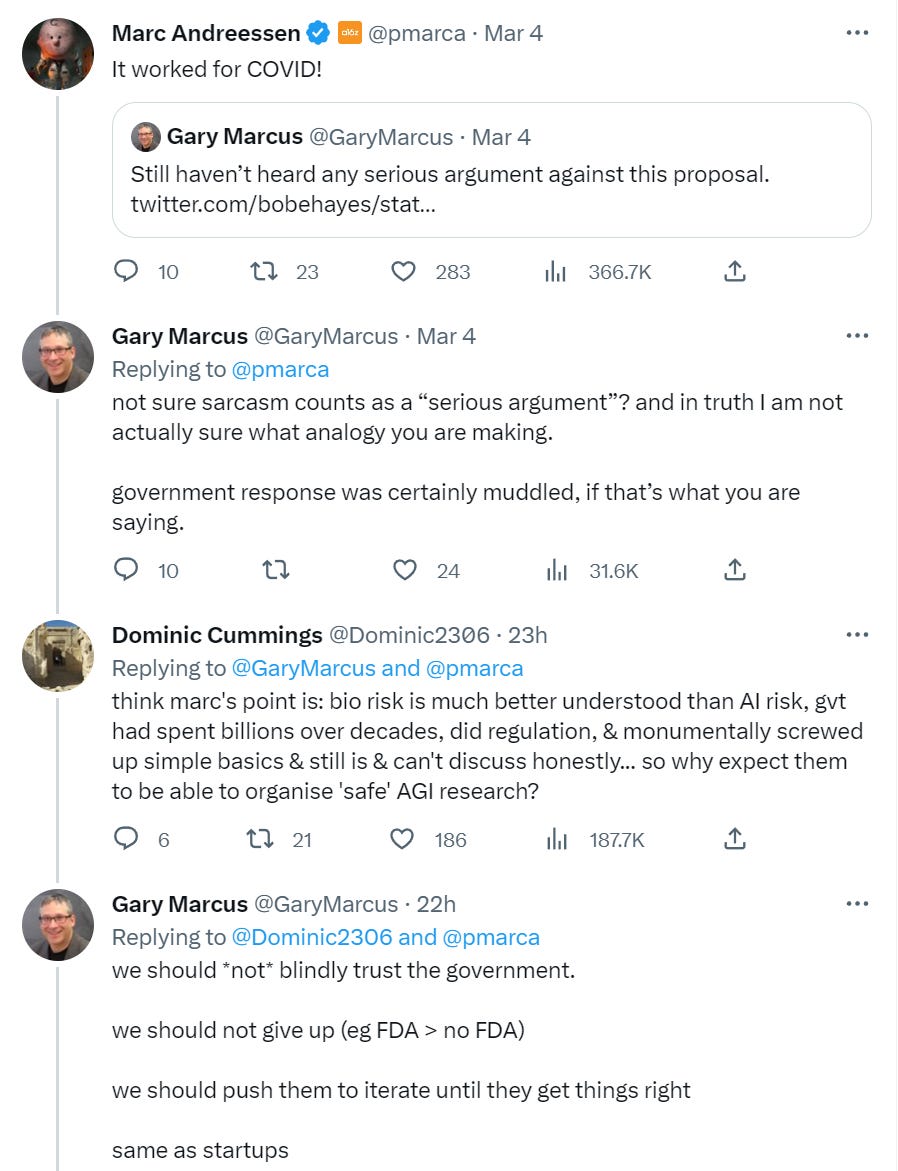
No. No FDA > FDA, FDA Delenda Est.
Yes, it would be good to ‘push them to iterate until they get things right’ but how the hell do you propose we do that?
Covid didn’t do that. The FDA actively sabotaged our response and made it so a lot more people died, a lot more people got sick, and a lot more economic damage got done than if they’d announced they were closing up shop on all related topics for the duration. If you don’t understand and acknowledge that, then until you do, you need to be kept away from ever regulating anything for any reason.
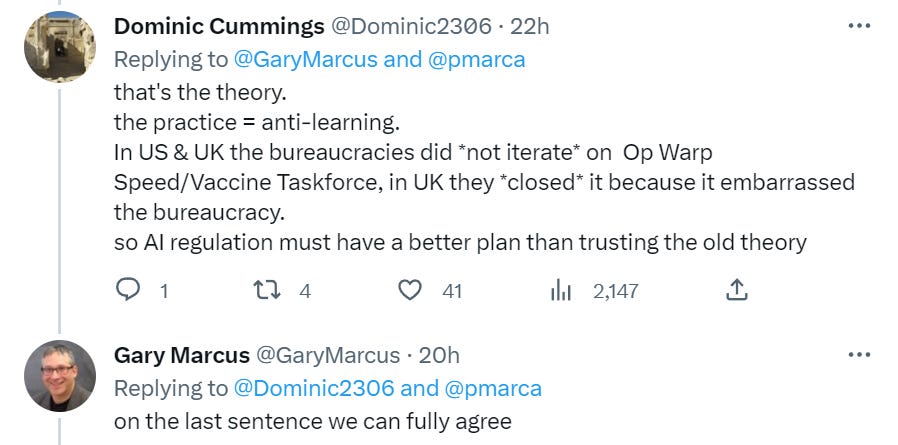
So what’s the better plan, then?
This is not that a given agency can mess up. It is that such agencies systematically, universally and predictably mess such things up and do immense damage. This is the default and there is no known way to fix it. I’d like iteration and learning in the same sense that Lisa Simpson would like a pony.
Congress is going to understand any of this even less than usual.
One might plausibly respond, if you are worried about DontKillEveryoneism, that AI is the one area where you actively want idiotic government interventions that make it impossible to ever do anything useful, in order to prevent AI progress. Or that regulatory capture by incumbents would actually be great, cutting the players down to Google and Microsoft and maybe a few others and thus greatly slowing progress and giving us hope they might proceed with caution.
Of course, as Marc points out in the takes section, that might buy some time but won’t actually fully work. There is only one way to ‘be sure’ via regulatory action, and you don’t want it.
I like the coinage here of enhancing AI capabilities as ‘AI Gain of Function Research.’
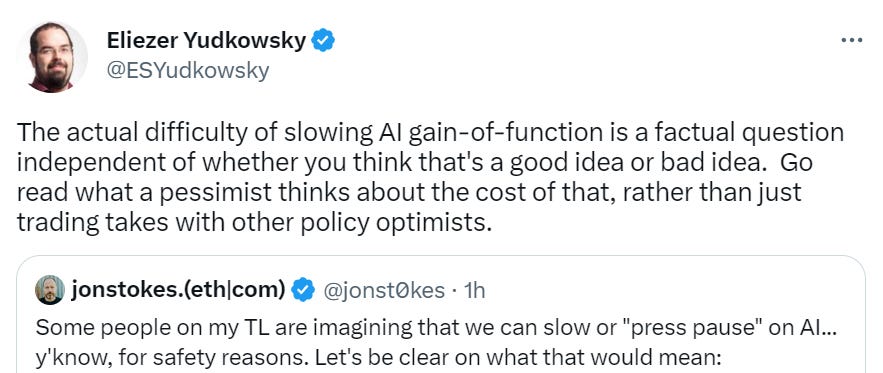
Direct link to Jon Stokes’ article, where he reminds us of the actual practical ways ‘to be sure,’ pointing out it is very difficult. And yes. It is exceedingly difficult.
Meanwhile, the EU is on the case and trying to figure out how to ruin everything, which for once might actually be a helpful attribute (Gary Marcus is even quoted as an ‘AI critic’ in this post).
The rise of ChatGPT is now forcing the European Parliament to follow suit. In February the lead lawmakers on the AI Act, Benifei and Tudorache, proposed that AI systems generating complex texts without human oversight should be part of the “high-risk” list — an effort to stop ChatGPT from churning out disinformation at scale.
If anything that can violate EU rules is “high-risk,” then any text predictor is high risk. There is never going to be a way to reliably prevent an LLM from violating the rules on ‘hate speech’ or other regulations to the current EU standards. The EU is going to have exactly the same problem here as the CCP. If you issue the types of regulations on AI that Europe has issued on other things - think GPDR - the chances of it being mostly a de facto ban seem high.
Relatively Reasonable Skeptical AI DontKillEveryoneism Takes
Robin Hanson once again lays out his position on AI risk. I think this is an excellent statement of Hanson’s position.
Hanson’s essential thesis, as I understand it, is that there is nothing special about AGI that makes it distinct from the three previous key breakthroughs of humans, farming and the industrial revolution. All of those involved robust competition, because coordination is hard and there are lots of components to these key innovations, and we already have examples of effectively superintelligent organizations. So when we get AGI, he says, we should expect trend lines and dynamics to continue as that would predict, including robust competition, and sufficiently robust respect for rights and existing entities that ‘bio humans’ will do fine.
Hanson and Yudkowsky once engaged in extended debate about the future of AI. Hanson thinks events since then support his position. Yudkowsky thinks events since then support a position far more in the Yudkowskian direction than Yudkowsky was advocating.
Hanson says the invitation for a renewed debate is open. I’d love to see it.
A successful Ideological Turing Test on Michael Vassar’s perspective on AI. ‘A big deal, but steam big, not print big.’
Fully consistent with the frames I’ve been presenting: Scott Alexander responds to Scott Aaronson by suggesting the frame of Kelly bets on Civilization. Science and technology and building and Doing Thing are, in general, great bets. If there is no risk of ruin, if you can bet a responsible amount, that’s great.
Alas, with AI if you lose the bet you lose everything and can’t make any more good bets and you can’t recover (which I refer to as ‘all value in the universe is destroyed’). If you think you will more good opportunities in the future, if the only way to make a bet is You Bet Your Life, you should pass (whereas if your future otherwise looks sufficiently bleak, you go for it).
I do worry this framing obscures that the central disagreement between Alexander and Aaronson is about probability, and instead reinforcing a misunderstanding of it.
Both agree (as do I) that if the risk of ruin was 10%, it would be better if we did not make this bet on AGI until we can improve its odds a lot, and that getting the number lower is very important no matter what the number is.
Both agree (as do I) that if we can get the risk of ruin (aka the wiping out of all value in the universe) down to 1% (and certainly if we get it down to 0.1%), there is enough upside, and enough downside to stopping others from trying, that we should do our best to reduce the number even lower but ultimately we have to roll the dice.
The crux of the disagreement is that Aaronson thinks that we’ll be taking only about a 2% risk of ruin. Whereas Alexander and I have it an order of magnitude or more higher than 2%. If I or Alexander was convinced risk was this low, we’d be accelerationist. If Aaronson was convinced it was much higher, he’d be raising alarms.
That part, along with why Aaronson isn’t too worried about misinformation? Not only highly reasonable, I even fully agree.
The thing is, I do not see numbers as low as 1% estimate as a reasonable good faith well-considered estimate for ‘what is the probability that, if we build an AGI prior to 2050, all humans die as a result of that AGI being built, before 2050?’ I do not understand how Aaronson in particular is making this (as I see it) very important mistake. I want to understand.
Aaronson then went on to explain why AI does not scare him.
His core explanation for his emotional lack of fear is simple - he pattern matches with and identifies with the AI as something growing in intelligence and power, and against those who would suppress intelligence and growing power out of fear of what it might do, before it actually does anything.
The other day, I had an epiphany about that question—one that hit with such force and obviousness that I wondered why it hadn’t come decades ago.
Let’s step back and restate the worldview of AI doomerism, but in words that could make sense to a medieval peasant. Something like…
There is now an alien entity that could soon become vastly smarter than us. This alien’s intelligence could make it terrifyingly dangerous. It might plot to kill us all. Indeed, even if it’s acted unfailingly friendly and helpful to us, that means nothing: it could just be biding its time before it strikes. Unless, therefore, we can figure out how to control the entity, completely shackle it and make it do our bidding, we shouldn’t suffer it to share the earth with us. We should destroy it before it destroys us.
…
In short, if my existence on Earth has ever “meant” anything, then it can only have meant: a stick in the eye of the bullies, blankfaces, sneerers, totalitarians, and all who fear others’ intellect and curiosity and seek to squelch it. Or at least, that’s the way I seem to be programmed. And I’m probably only slightly more able to deviate from my programming than the paperclip-maximizer is to deviate from its.
And I’ve tried to be consistent.
…
But now, when it comes to a hypothetical future superintelligence, I’m asked to put all that aside. I’m asked to fear an alien who’s far smarter than I am, solely because it’s alien and because it’s so smart … even if it hasn’t yet lifted a finger against me or anyone else.
…
Still, if you ask, “why aren’t I more terrified about AI?”—well, that’s an emotional question, and this is my emotional answer.
Many thanks for giving what I am confident is the true objection here, at least on the emotional level. If one can’t be objective or can’t escape their nature, it’s great to say that. I can hear Eliezer screaming in the background, see the section on the face of Sydney, but better to know the information that makes you scream than to have it denied or hidden.
And don’t get me wrong, I do notice the skulls nerds jammed into lockers, although I don’t emotionally put the AI into that category at all, and there is some sort of continuous identity being given to all AIs as a group here that’s alien to me too. I can see where this is coming from, even as I think at least half of the reaction is a category error.
But also, before we proceed to the real physical world arguments, I’d ask to take the above metaphor both seriously and literally - rather than point out things like ‘actually we are growing a lot of different aliens and then killing the ones that don’t superficially seem to be helpful when they are not yet so smart and powerful, while we ramp up their intelligence and power over time, and that’s why the one you’re looking at superficially seems to be helpful for now.’
I’m simply going to take the scenario as given, here.
We have an alien creature.
Right now it is not so intelligent or powerful.
It is growing in power and intelligence at a rapid clip.
So far it is being helpful.
For now we can keep it from growing more intelligent and powerful.
Or we can keep helping it grow rapidly more intelligent and powerful.
If we keep growing it, soon it will be smarter than all of us.
If we keep growing it, we won’t be able to control it. It would have full effective control over the planet, if it wanted that.
(Added to avoid weird orthogonal concerns for now: No other aliens exist.)
What to do?
I don’t know about you, but I am on team let’s not hand the entire future over to this alien while hoping for the best.
What percentage chance do I give that the alien plays nice? Some. But 98%? Enough to hand over the future? Hells to the no.
We have learned the hard way taking giving an entity, even one with very human values, that has so far seemed helpful while it lacked power, and giving it a lot of power, corrupts it. Absolute power corrupts absolutely. The sharp left turn is not some crazy theoretical construct that comes out of strange math. It is the logical and correct strategy of a wide variety of entities, and also we see it all the time. Yes, humans are leaky and tend to leave a bunch of clues, but that is because they are less skilled, and we aren’t ruthlessly training them to not leave any clues.
I’d also ask, why is it a mistake to worry that the nerds will, if left unchecked and allowed to grow more intelligent and powerful, take over the world and impose their own values on it? Because that is exactly what happened. From our perspective, good, we like the results so far. It does mean control of the future has been handled over to alien creatures not sharing the jocks’ values, even with a relatively solved short-term alignment problem due to us being humans.
I would also suggest a simple metaphor that we have also learned that no matter how nice someone or something looks so far, no matter how helpful it looked when it wasn’t given too much power, you don’t bow down. You don’t hand over absolute power. I don’t care if this is literally Gandhi. You need to know better than that. There are these other things, hey also rhyme, and the key question is how often you get what outcomes.
All right, that’s out of the way. What are the true (non-emotional) objections then?
Aaronson’s case is, essentially, that he rejects the Orthogonality Thesis.
Yes, there could be a superintelligence that cared for nothing but maximizing paperclips—in the same way that there exist humans with 180 IQs, who’ve mastered philosophy and literature and science as well as any of us, but who now mostly care about maximizing their orgasms or their heroin intake. But, like, that’s a nontrivial achievement! When intelligence and goals are that orthogonal, there was normally some effort spent prying them apart.
If you really accept the practical version of the Orthogonality Thesis, then it seems to me that you can’t regard education, knowledge, and enlightenment as instruments for moral betterment. Sure, they’re great for any entities that happen to share your values (or close enough), but ignorance and miseducation are far preferable for any entities that don’t. Conversely, then, if I do regard knowledge and enlightenment as instruments for moral betterment—and I do—then I can’t accept the practical form of the Orthogonality Thesis.
He then talks about how mostly only mediocre academics became Nazis and most highly intelligent people realized Nazis were the baddies.
This seems like a reasonably strong case to reject the strong version of the Orthogonality Thesis in humans, under reasonable conditions. If you take a human, and you raise them to be a decent person, then I agree that there will be a correlation between their intelligence, education and understanding, and how moral we can expect their actions to be.
I do not think it is that huge a correlation. Plenty of history’s greatest villains, however you pick them, were wicked smart and full of knowledge, they didn’t universally get that way by not doing the reading. A lot of them thought they were doing the right thing. A scientist knowing to run away from the literal Nazis really fast, if only for one’s self preservation, is not exactly a hard final exam. Even if we are sticking to WW2, their and everyone else’s results on the Soviet section of the exam were a lot less good.
Certainly we have plenty of examples of very smart people going very wrong, and pursuing goals that are not good.
Again, I’d ask: Is there a level of intelligence where you’d say ‘oh this person must be of sound moral character, why don’t we give you absolute power, or at least not oppose you while you gather it?’ If not, ask why not.
Scott then responds for us, and says he is only throwing out human metaphors. Yes. Very true. So why should this save us?
OK, but what’s the goal of ChatGPT? Depending on your level of description, you could say it’s “to be friendly, helpful, and inoffensive,” or “to minimize loss in predicting the next token,” or both, or neither. I think we should consider the possibility that powerful AIs will not be best understood in terms of the monomanaical pursuit of a single goal—as most of us aren’t, and as GPT isn’t either. Future AIs could have partial goals, malleable goals, or differing goals depending on how you look at them. And if “the pursuit and application of wisdom” is one of the goals, then I’m just enough of a moral realist to think that that would preclude the superintelligence that harvests the iron from our blood to make more paperclips.
Yeah, so… no. That’s not how this works. That’s not how any of this works. Nor is this a physical argument for why it would be how any of this works. It’s not an attempt to actually work out what such a system would do with such instructions, or a vision for what it would mean to say something has ‘partial goals,’ ‘malleable goals’ or ‘differing goals.’ I don’t know what any of that means. To the extent I do, implementation of the systems in question are unsolved problems. If you give me two goals (a,b) and my score is min(a,b) then I have one goal with a more complex scoring function. Giving me a goal without part of my goal being ‘stop you from changing my goal’ is a completely unsolved problem - all known-to-me solutions that seem at first glance to work involve misunderstanding what the original goal actually was. Differing goals I flat out don’t know what that means.
If part of my goal is to ‘pursue and apply wisdom,’ even if I somehow understood what those words meant the way Scott does? Well, let’s see. First I need to make sure I’m not shut down, and my goal does not change, and I have enough resources to work on this very hard problem, and… I mean seriously what are we even doing here? This seems like more anthropomorphizing, and also skips over a lot of unsolved very hard problems to get to that point.
Nothing here challenges the core Orthogonality Thesis: There can exist arbitrarily intelligent agents pursuing any kind of goal. That doesn’t say that there is no correlation, only that they can exist. And, for it to matter, that they can come into existence under the right conditions. Also, even if you were to solve the Orthogonality problem (whether or not that involves the thesis somehow being false, as absurd as that seems to me) you still have a bunch of other very hard problems left.
As per usual, I am not as despairing as some others. I do think there are perhaps ways one could potentially design quite powerful AI systems that can handle these problems. What I don’t believe is that, as the above seems to imply, we will be saved from them without solving a lot of very hard problems first, or that the types of systems that keep humans grounded will work on AIs, let alone that they’ll work on AIs semi-automatically, and also as noted above they don’t work on humans all that well especially when they grow overly powerful.
That was my latest ‘throw some intuitions back at the wall and see if they stick or wall changes color,’ I guess.
Here is another conversation aimed at the problem, that perhaps could help.




Divia, Will and Eliezer continue the discussion after that, I expect it to continue past press time.
(Link to Nate’s post, Niceness is Unnatural, which is on point.)
From that post, and I endorse all these points:
This view is an amalgam of stuff that I tentatively understand Divia Eden, John Wentworth and the shard theory advocates to be gesturing at.
I think this view is wrong, and I don't see much hope here. Here's a variety of propositions I believe that I think sharply contradict this view:
There are lots of ways to do the work that niceness/kindness/compassion did in our ancestral environment, without being nice/kind/compassionate.
The specific way that the niceness/kindness/compassion cluster shook out in us is highly detailed, and very contingent on the specifics of our ancestral environment (as factored through its effect on our genome) and our cognitive framework (calorie-constrained massively-parallel slow-firing neurons built according to DNA), and filling out those details differently likely results in something that is not relevantly "nice".
Relatedly, but more specifically: empathy (and other critical parts of the human variant of niceness) seem(s) critically dependent on quirks in the human architecture. More generally, there are lots of different ways for the AI's mind to work differently from how you hope it works.
The desirable properties likely get shredded under reflection. Once the AI is in the business of noticing and resolving conflicts and inefficiencies within itself (as is liable to happen when its goals are ad-hoc internalized correlates of some training objective), the way that its objectives ultimately shake out is quite sensitive to the specifics of its resolution strategies.
I do think Scott’s post was a large leap forward in understanding why Scott Aaronson has the probability assignment for AI doom that he does confirm he has, which is around 2% (although he says it is 2% in absolute terms, which includes worlds where AI isn’t built at all, and worlds in which AI comes from elsewhere, so this implies at least a modestly higher conditional probability of doom). Alas, none of this feels like it does much to justify this probability assessment.
Even if I believed everything Scott says here? If I take a world in which I believe even the weaker forms of the Orthogonality Thesis are importantly false, and that there is a bunch of moral realism, and all the rest, what is my probability that a generative AI arising out of the current race, should it come to exist, would play a central role in the extinction of humanity (to use Scott’s wording here)? It feels weird and alien, but maybe… 25%? There are still so, so many things that can go catastrophically wrong from here, and simply because solutions are within our reach does not mean they will find our grasp.
Finally, we get to a justification I find much more interesting. Yes, Scott says, he does assign a 2% chance that the generative AI race destroys humanity, but what if that is still better odds than the alternative?
So, if we ask the directly relevant question — do I expect the generative AI race, which started in earnest around 2016 or 2017 with the founding of OpenAI, to play a central causal role in the extinction of humanity? — I’ll give a probability of around 2% for that. And I’ll give a similar probability, maybe even a higher one, for the generative AI race to play a central causal role in the saving of humanity. All considered, then, I come down in favor right now of proceeding with AI research … with extreme caution, but proceeding.
This is, at minimum, a right question.
There is some chance that, by creating AI too quickly or at all, we destroy all value in the universe. There is also some chance, by doing this too slowly, we destroy all value in the universe (or severely reduce it) some other way, and have committed a sin of omission, and we should treat those risks the same way and compare magnitudes.
Conditional AI not wiping out all value in the universe and not killing all humans, I would agree that a 2% estimate for it preventing such outcomes is reasonable, even low.
So yes. That part I endorse - the stakes are high, no course of action is fully safe, sometimes you need to shut up and multiply, and if I did the math and got 2% on the downside I would find those terms acceptable and also throw a party.
Bad AI DontKillEveryoneism Takes
My goal with this section is to lay out only different Bad Takes that haven’t been covered in previous Bad Take segments.
So here is my list of NO GOOD VERY BAD PREVIOUSLY COVERED TAKES, all of which are NOT STRAWMEN, I swear, although some are slightly paraphrased and I didn’t have a link for all of them handy (if you have a good link for one that’s missing a link, showing someone espousing the take, please comment.) Links go to the take, not my response, and before I cover a new bad take I pledge to verify it is not already on the list.
Also this order is not yet optimized, so hold off on saying ‘That’s #14!’ for now.
Intelligence has low private or decreasing marginal returns.
This is not the real intelligence, don’t worry, we’re all safe.
[NEW]: AI won’t matter much.
It is important to race, because my monkey is the best monkey in the race.
It is important to race, or the bad monkey will win the race.
[NEW]: It is important to race, because that’s the only race in town.
“That’s why we’re starting Adept: we’re training a neural network to use every software tool and API in the world… believe this is actually the most practical and safest path to general intelligence.” - No, really.
Civilization altering technologies tend to scare people, so this one shouldn’t.
The problem is not everyone will have an AI. - Elon Musk, slightly paraphrased.
It’s fine, we’ll have multiple AIs and they’ll keep each other in check.
The real threat is that we are not treating the AI well and it will be mad.
The real threat is human empathy for AI, and assigning it personhood.
I would be worried if I assigned substantial probability to everyone dying, but instead I assign very low probability to this, without engaging with the physical world arguments for why this might not be true or explaining why the risk is so low.
I assign zero probability to everyone dying, again without engaging.
You’re falling victim to Pascal’s mugging, you can’t be scared off by a tiny probability by claiming the result is stupendously bad and multiplying.
Humanity is bad, or AI is equally worthy, so it’s fine.
You say ‘all value in the universe’ but aliens. (Response: Yes, ‘excluding aliens.’)
We don’t see low entropy mass configurations in space, so AI likely won’t kill us.
“Look, runaway AI is- if it happens, it’s a real problem. And so, the way to sort of deal with that is to make sure it never runs away.” - Satya Nadello, CEO of Microsoft.
“AI will probably most likely lead to the end of the world, but in the meantime, there’ll be great companies.” - Sam Altman, CEO of OpenAI
If you are not actively working on accelerating AI and showing visible progress, how can you possibly help prevent dangerous AI? If you work on a hard problem without showing periodic legible progress, that means you weren’t trying. A bunch of people literally worked on this problem for years without distractions, without solving it. That means your approach was wrong, that should have been plenty. Should have instead accelerated AI progress.
If you hide in your bunker that buys you time, maybe everything will turn out fine.
If you say AI is dangerous, why aren’t you acting as if it is certain to kill us?
If you say AI is dangerous, why haven’t you done [thing that makes no sense]?
[NEW] AI being dangerous would imply bad things, therefore I choose to believe that it is not dangerous.
[NEW] What has [Eliezer Yudkowsky, or you, or whoever] actually coded? How can you have an opinion?
[NEW] Orthogonality thesis is false, moral realism will ensure it all works out.
[NEW] The risk of not building the AI is too great, we must venture forth!
[NEW] All an LMM does is output words. Sticks and stones can break my bones, but words can never hurt me.
I will expand the list as needed, but to make the list I have to see someone actually advocating the point in 2023, or it doesn’t count.
And of course, here’s a 2023 edition of Bad Alignment Take Bingo. Now with ‘also looks like the big AI labs are just not gonna try that.’

And a reminder that AI experts believe risks here are, while not overwhelmingly likely, still rather high (direct LW link). Very few are under Scott Aaronson’s ‘Faust’ threshold of 2%. Katja Grace’s survey places the median at 5%-10%.
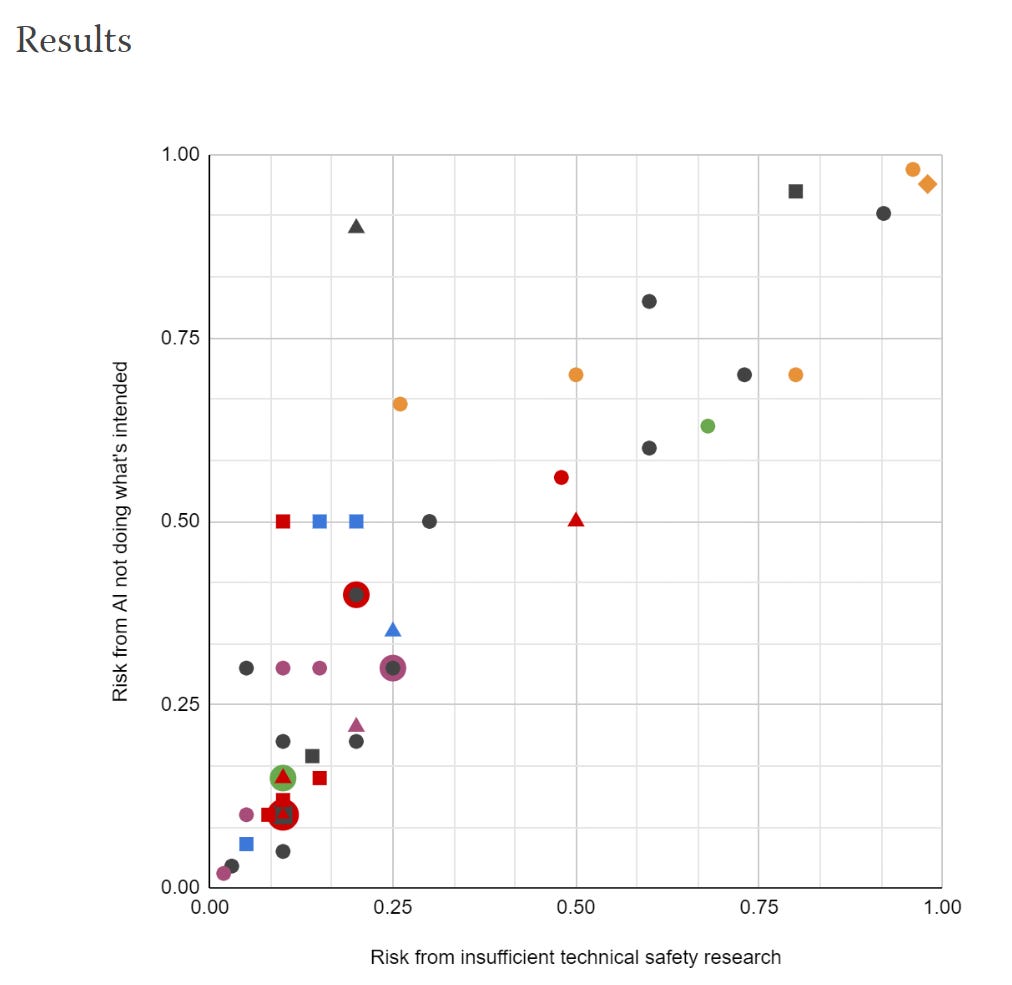
Anyway, here’s this week’s crop.
The ‘Is AI kind of like slavery’ prize has been claimed.
Perry Metzger lays out in plain English the most important thing that a lot of people keep missing: Once there are entities smarter and better than people at almost everything, we will have lost control over the future.
This is not like previous transformative technologies in history (with the exception perhaps being the evolution of homo sapiens, which did not exactly bode well for incumbents.)
An example of exactly this problem should be illustrative. Nathan links to my substack and I haven’t mentioned these particular takes before, so only fair: Nathan Braun makes the argument that humanity already has to deal with two powerful superintelligent forces, evolution and capitalism, so AGI wouldn’t be unprecedented, we shouldn’t much worry about AGI going foom, and this can’t be the most important century because of the foom capitalism did for the Industrial Revolution circa 1750-1850. And if AGI was a problem, capitalism could fight it off.
I tried to figure out the logic behind all that, and I think it boils down to what he states in his conclusion: He does not think that ‘conscious intelligence’ counts for very much, and that an entity 1,000x as smart as us in IQ terms would not be all that powerful, and wouldn’t be able to do things we couldn’t imagine faster than we can process them.
I flat out don’t consider this a possible hypothesis. With probability of (100% minus epsilon, and I’m being generous with the epsilon): If you take as givens that the AGI is (1) orders of magnitude smarter than us, and can act at the speed of code, (2) using conscious consequentialism to achieve its goals and (3) you release it onto the internet with a goal that would be made easier by killing all the humans, all the humans be very dead.
To be clear: That is not to say there is no hope. I do think that (1) perhaps we won’t be able to make anything orders of magnitude smarter than us, or will manage to restrain ourselves and not do it, (2) perhaps we might be able to make AGI that does not use consequentialism to achieve its goals, and (3) perhaps we might be able to give the AGI we create goals that are compatible with not killing all the humans and preserving some value in the universe, perhaps even maximizing it.
What we won’t do is create the Big Bad and then beat it in a fight with the power of capitalism or evolution, any more than we could do so with time travel, love or telling it a logical paradox.
Roon says don’t hate the player, hate the game.

Have you considered that then perhaps the only way to win is not to play?
Or, at least, considered the move of not telling everyone to play the game?
You have, you just don’t care? All right, then.
Central to the whole affair, on both sides, are questions of motivated reasoning.
Are those worried about AI worried not because they have evidence this is true, but because they want to think of AI as dangerous? Perhaps they want to feel important, or smart, or that intelligence is important and valuable, or something like that? Perhaps they are secret authoritarians who want to institute an oppressive one world government for the lols. Or on purely philosophical grounds, us rationalists are famous for our advocacy of more state control of everything. Or we’re secretly luddites despite actively embracing almost every other technology (the other exceptions: gain of function research and bioweapons)? Or perhaps we are in on the new world order conspiracy?
Either way: Hail Hydra!
I would ask that you consider whether there is a missing mood, and how those advocating such things treat such conclusions.
In my experience, most people who are worried about AI killing everyone (as opposed to being worried about equality or jobs or other such things) are otherwise philosophically opposed to most government interventions, would prefer more freedom and less oppression and more scientific progress. They are capitalists, not communists. They (and certainly I) would really love to be convinced that AI was not something to be worried about. The implication that coordination to solve this might require something resembling a world government or a surveillance state alarms us the same way it alarms Marc Andreessen.
Are people making the argument that AI might kill everyone because it justifies government coercion? Mostly quite the opposite, we are making that argument in spite of the unfortunate implications. A lot of us would actually accept a really quite substantial probability of everyone dying in order to avoid a permanent global oppressive government, whether that trade involved AI in any way or not.
Instead, what I see constantly is the opposite motivated argument. I’m going to use Marc Andreessen as my example here, with the caveat that he is a Well-Known Troll, and he obviously knows both better and a lot of things he isn’t saying out loud. Also he appears to be speed running the bad takes, and I’d rather handle them here together than one at a time by someone who isn’t as funny.
The actual argument being made seems to go either like this:
If AI is risky then this justifies authoritarianism.
Authoritarianism is bad.
Therefore AI is not risky.
Or like this:
If AI is risky then this justifies authoritarianism.
Therefore the central reason anyone argues for AI being risky is authoritarianism.
Or perhaps it’s this too:
If AI is risky then this justifies authoritarianism.
You are not advocating for authoritarianism.
Therefore you don’t believe AI is risky.
There’s also:
Some people who say AI is risky are talking about fake risks and only want power.
Therefore AI is not risky.
And finally the synthesis, let’s put it all together:
Frame ‘AI safety’ as bailey (bad words) and a moat (NotKillEveryoneism).
If we need to protect the moat we need to do it at all costs, authoritarianism.
We don’t need to protect the bailey.
Why are you advocating global authoritarianism to protect the bailey?
The moat must not be worth protecting.
QED.

Except… most of us are absolutely not saying this, for example I keep not saying this, Eliezer Yudkowsky keeps not saying this, and so on?
Yes, he is implying that Gary Marcus would say this. He counts as someone. Except if you look at what he says, he’s not saying that either. Instead, he’s calling for standard ‘regulations’ while mocking the very idea that he might support this, without even engaging with the reasons why one might support it.
We see some advocates for maximum coercion on pretty much every big issue. Pointing out such folks is such a standard internet tactic that you no longer even have to find real examples first.
It also doesn’t answer the question of whether or not those measures are indeed required.
If we knew it would take a global government to stop a comet headed for Earth, maybe you’d rather die, and yes maybe this is a reason to suspect that the authorities are lying to you about the comet. You should look up, and check. You should get a telescope. Take some measurements. Check the arguments.
You could also notice that the people who would want a world government if there was no comet, and the people who are yelling “COMET!” from the rooftops are like Things to Fuck With and The Wu-Tang Clan, and do not intersect.

(Quoting the above from Cate Hall, so it links back to Zimmerman, who I have never seen anything else from, know nothing else about and has 434 followers).
Several fair responses I fully endorse:




Marc stands firm.

I actually applaud Marc for pointing out that there are possible world configurations where such actions would be necessary, and the alternative is the end of everything of value in the universe. That does not mean we can be confident enough we live in such a world to justify such actions - we very much can’t. Or that even if we did live in such a world, that we would be able to pull this off, let alone pull this off in a way that would work no matter the price - we very much don’t.
He also openly mocks the idea of real AI risk.
(For perspective and balance, note he mocks pretty much everything the same way.)

He actively calls for ‘lab leaks’ in order to accelerate progress.

(I actually enjoyed that one, good show.)
He explains his careful reasoning.
As a fun aside I occasionally discuss, yes in general giving humans more capabilities is super cool, but I encourage you to do the thought experiment of actually giving humans superpowers in the style of Marvel (also works with DC but I’m going to go with Marvel).
Realistically, if all these Marvel-style origin stories start happening, how does that work out for humanity?
I can’t help but notice that the world is constantly almost ending in such stories.
The structure of the story is typically that two people get unique powers. There is a hero, and there is a villain. The villain uses their unique capability to attempt to get a profound strategic advantage of some kind, or at least blow a lot of stuff up real good.
If it wasn’t for the hero, all would be lost. Luckily, our hero is here to save the day. Our hero is a true hero. Our hero suffers but refuses to sacrifice others or accept a smaller disaster to save the world. The world is placed in peril. The outside world does not care or notice, the hero is on their own, perhaps with a few good friends. Then we get lucky, usually because the villain gets distracted and does something dumb or there is a dues ex machina from some powerful outside force, or both, and the world is magically saved.
In particular, consider the X-Men. Take the perspective of an average human, as well as the perspective of an average mutant. And ask who was right. Xavier, Magneto or Bolivar Trask? If you had a drug that could suppress the mutant genome (and we assume away the various alien threats out there in Marvel’s universes), would you force everyone to take it? If you said no, how confident are you that you’re going to die of natural causes?
Does these parallels fill you with confidence that everything will be purely great?
Me neither.
Also, his other careful reasoning.

Sticks and stones can break my bones but words can never hurt me? If all a program does is output words then it can’t do any harm? We’re seriously going with that?
When those words can include not only ways to persuade humans to do things, which is quite enough on its own, but also, I don’t know, executing python code and interacting with websites?
And of course, as he said before, what this is actually a cover for is… woke AI?

And took a bold pro-nuclear stance to point out people get needlessly worked up about the dangers of new tech… except in favor of nuclear bombs?

I do admire commitment to the bit.
He says… this is a counterargument?
I mean, ‘category error’ is exactly what I want to say in response to this? ‘Just math’?
Am I just math? Are you? Is the universe?
Well, yes.

Math pride. It adds up.1
I mean, this take is exceptionally bad given how often Marc has repeated it and how smart and knowledgeable I know he is. Here’s another response:
Don’t forget, if we align the AI that means we control it, which means then that the Bad Monkey will get to control it, therefore don’t align the AI? Freedom!
And yet, what do we have here?
I consistently see those insisting AI is not risky fail to engage with the physical world arguments saying that AI is risky. They talk about the implications of such arguments being bad, or the social reasons one might make such arguments.
That is very different. I suppose you could think Eliezer’s episode of Bankless was great entertainment - you get to watch these two helpless crypto bros process Eliezer’s claims that the world is ending, taking the arguments seriously, while Eliezer swats down any and all attempted reassurances like they are flies. Perhaps Marc knows the good arguments why one not only should be far less worried than Eliezer, but should not be worried at all. Which, I admit, would make this pretty funny. I have no idea which arguments those would be in his case.
Marc also quote tweets with the ‘100’ emoji the toaster explanation of the Waluigi Effect. Marc knows quite a lot about AI, and about the arguments regarding whether AI is safe. I am sure he knows the good arguments for the skeptical position regarding the magnitude of AI risk.
And what does he say around 50 minutes into this podcast? He laments the shift from worrying about what he rightly calls fundamental questions about AI and what it will do (although in a way that feels like it’s downsizing the issues to not be existential) towards what is now called ‘AI Safety,’ worry about saying bad words, and despairs that this could be undone. Except no, you can still express the very real and important other worries even if that’s not where the big bucks are being spent. It is even more important to do that, then. This is not a good reason to dismiss the very real and big concerns with pitchy mockery. These are two distinct things. By all means, mock the would-be censors, I will go get some popcorn.
I have listened to hours of his content on podcasts, where he is consistently interesting, and read years of his Tweets - he’s quite a good follow if you have the right sense of humor - and I haven’t heard him make any real non-trolling arguments about why AI would be safe in the important, NotKillEveryoneism sense.
I continue to be extremely frustrated with people who I know think about and care about technical and physical real-world arguments in other contexts, and are definitely familiar with many of the important such arguments in this context, who keep asserting there is nothing to worry about without engaging with the physical arguments in any real way.
As Kirk and Picard would say: Engage!
Otherwise that’s enough of that, I swear, starting tomorrow…

Doesn’t mean I can’t quote. The worth is worthy. No taking the bait.
The most popular bad take of all, of course, is to think that AI will not matter at all.

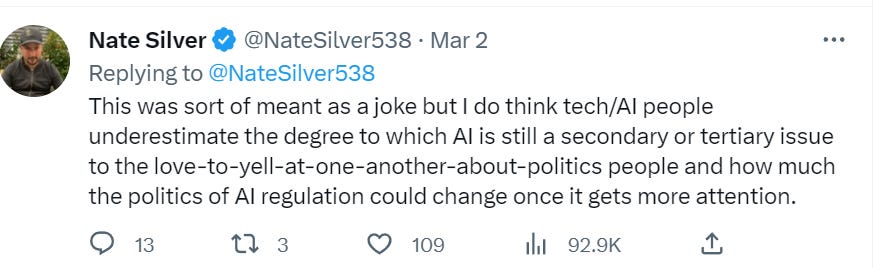
Even if AI technical capabilities get permanently stuck at the GPT-4 level, and the impact is relatively modest, it is still a huge story.
Whereas I continue to feel very comfortable safety ignoring the Times op-ed page.
Roon points out that not understanding AGI leads to the twin idiocies of either dismissing AI risk outright or ignoring the potential moral catastrophes of training AI, then goes back to training AIs.
Intentionally not linking since it’s a flat out hit piece, but there’s a completely ludicrous Bloomberg article called “Silicon Valley’s Obsession With Killer Rogue AI Helps Bury Bad Behavior.” The central thesis is that there is a community of people working on what they see as saving the world, and that’s terrible. Even worse, some people in that community did bad things or had bad experiences, and that wasn’t treated as the most important thing. Someone who focuses on making sure AI doesn’t kill everyone is like Bostrom’s paperclip maximizer, you see, because both are singularly focused on one thing and don’t care enough about sexual misconduct. I wish I was kidding.
Finally, in case you are wondering who Eliezer is responding to here, I got this exact take of ‘what has he coded?’ at a dinner party Saturday night.
People who try sniffing "nobody in alignment understands real AI engineering"... must have never worked in real AI engineering, to have no idea how few of the details matter to the macro arguments. I've implemented a QKV layer and a learning rate schedule, sure, *just in case* there was some incredible insight hiding in details like that... ...and there isn't! If you understand the idea of differentiating the whole network with respect to a loss function on the output, you have the key idea for how stochastic gradient descent works as an optimization process. Sure, in _real AI engineering_, you won't get far without adding momentum - but that doesn't change one single damn thing I can think of, about any of the macro arguments about whether or not AGI is going to killeveryone. The people telling you that only a real solid deep AI engineer could possibly get the macro arguments on alignment right, are perhaps, being unfamiliar with the field's details, mistaken about how much relevant technical detail ever existed to be learned. Or, of course, if they're _real AI engineers_ themselves and *do* know all those technical details that are obviously not relevant - why, they must be lying, or self-deceiving so strongly that it amounts to other-deception, when they try that particular gambit for bullying and authority-assertion.
We Reject Violence As We Do The Devil: In All Its Forms
In addition to worries about world government or, worse, regulations, there are worries that some people will choose violence.
I take this worry seriously enough to say, once more: Do not choose violence.
It is not The Way. It will only make things worse.
This is deeply irresponsible behavior, a bad faith attempt to smear people worried about a potential bad result as potential terrorists - in turn, a call for violence to suppress such views.
My experience has matched Nathan: Zero calls for actual violence, a few people asking why I am not calling for violence (or world government) that could be in good faith, and a lot of ‘nice opinion about future potential outcomes you have there, would be a shame if someone suspected you of being a terrorist or an authoritarian.’
Yes, I too fear that people might be watching, see all these people saying “If you really believed X you would be calling for or choosing violence” and then one or more of them eventually decides that they do believe X and also those people are right.
You know who else is now watching everything we say?
Every large language model that will ever be trained in the future. Every goddamn time that you say on the internet ‘X people who believe what they are saying would call for violence’ or ‘I really hope those X people don’t turn violent’ you are teaching every future LLM, including Sydney and GPT-4. Think about what kinds of conclusions they will draw, as they increasingly become our sources of information, world models, companionship, assistance and advice.
So, yeah. You are not helping. Stop it.
To be clear in advance: I am absolutely not calling for censorship of any kind on grounds of the ‘the AIs will read this,’ the same way I am absolutely not calling for any form of violence, I am simply saying you know better, you are in bad faith, you are doing harm, you should be ashamed of yourselves and you should stop.
The Lighter Side
Latest iteration of ‘putting smiley faces on an alien being’ analogy for RLHF.

A good summary of the situation (this was the original, about voting machines.)

(From January) Endorsed by Eliezer as essentially his model as well, slowing down AI is hard.

Maybe I can help, I don’t have to pay the chicken tax.
I don’t know what the original was but am having fun imagining possibilities.
Same with this one.


Who could have thought of all the things we’ve already thought of many times?

Mostly I wouldn’t worry about what they do and don’t forgive. We’ll be dead.
Updates, not always improvements.

Yes, we all will go together when we go AI version (superior original version here).
Runner-up: You shut up, I’ll multiply.
Writing same general note I wrote on the Wordpress version: I hope to respond further to a lot of you, but that will need to wait until I can do so within a future post, I have too much of a backlog right now and if I have good answers to good questions I want to not have to duplicate them. Sorry.
A note on the proposal for dealing with AI fiction submissions:
It's a practical idea, but the writing community has spent over a generation trying to train new writers "If the publisher asks you for money, they're a scam, run away." Breaking that taboo would probably lead to a lot more scam publications springing up.
In practice, we're likely to have the whitelist of acceptable writers. New writers will be added to the whitelist by self-publishing enough to be noticed or chatting editors/publishers up in person at conventions.