

AI #11: In Search of a Moat

Remember the start of the week? That’s when everyone was talking about a leaked memo from a Google employee, saying that neither Google nor OpenAI had a moat and the future belonged to open source models. The author was clearly a general advocate for open source in general. If he is right, we live in a highly doomed world.
The good news is that I am unconvinced by the arguments made, and believe we do not live in such a world. We do still live in more of such a world than I thought we did a few months ago, and Meta is very much not helping matters. I continue to think ‘Facebook destroys world’ might be the most embarrassing way to go. Please, not like this.
By post time, that was mostly forgotten. We were off to discussing, among other things, constitutional AI, and Google’s new product announcements, and an avalanche of podcasts.
So it goes.
Also, I got myself a for-the-people write-up in The Telegraph (direct gated link) which I am told did well. Was a great experience to do actual word-by-word editing with the aim of reaching regular people. Start of something big?
Table of Contents
Introduction.
Language Models Offer Mundane Utility Perhaps quite a lot.
Level Two Bard. Maybe soon it will be a real boy.
Writers Strike, Others Threaten to Strike Back. You might try to replace us. If you do, it will not go well.
The Tone Police. You can use AI to make everyone more polite, still won’t help.
Fun With Image Generation. MidJourney is killing it, also what you do is public.
Introducing. New tools aplenty. GPT-4 winner and still champion.
The Art of the SuperPrompt. Should you learn prompt engineering? Yes.
They Took Our Jobs. Can we get them to take only the right ones?
In Other AI News. There’s always other news.
What Would Be a Fire Alarm for Artificial General Intelligence? Some guesses.
Robotic Fire Alarms. What would be a fire alarm for robotics in particular?
OpenPhil Essay Contest: Change Their Minds. The correct goal was selected.
Quiet Speculations. Tons of different ones.
The Quest for Sane Regulation. Demis Hassabis was at the White House meeteing.
China. If China does get a frontier model, where do you think they got it from?
Do Not Open Source Your AI Development. Worst things you can do department.
Google Employees Say the Darndest Things. Doesn’t mean they’re right.
Is The Memo Right That Open Source Is Eating Google and OpenAI’s Lunch? No.
We the People. Anthropic reveals the constitution for its constitutional AI. Oh no.
No One Who Survives the Internet is a Dog. Metaphors that shouldn’t offer hope.
People Are Keeping It Real and Also Worried About AI. Snoop Dogg gets it.
People Would Like To Use Words To Discuss AI Killing Everyone. Which words?
The Real AI Bill of Rights. What would cause us to give AIs rights?
What Is Superintelligence? An attempt at a definition.
People Are Worried About AI Killing Everyone. Some are in the BMJ. Featuring Warren Buffet, Turing Award Winner Yoshua Bengio, Toby Ord and Judea Pearl.
Other People Are Not Worried About AI Killing Everyone. Still going strong.
Geoffrey Hinton Watch. Bring the fire.
This Week in Podcasts. Rapidly approaching overload. Need to make cuts.
The Lighter Side. Finish strong. Don’t set the bar too low.
Language Models Offer Mundane Utility
Here’s some major mundane utility, huge if true: Automatically analyze headlines for their implications for stock prices, get there first and earn a 500% return. As Will Eden says, roll to disbelieve. Even if I were to fully believe, which I want to make clear that I don’t, I would not expect it to be sustained for long, since others can copy this strategy, the same way many already parse such headlines. If this (was) real Alpha, I’d assume it would be it comes from GPT-4 being naturally better at predicting short-term trader reactions rather than, shall we say, its ability to predict impact on the net present values of future cash flows.
Another ode to the wonders of Code Interpreter. It seems like a cool productivity tool. I can’t tell for myself because despite signing up right when they were announced I still don’t have plug-in access.
World building and mystery construction for your cyberpunk (call it ‘neo-noir’ for better results) future. There’s a certain kind of sweet spot where you want a parrot.
Have the AI play an escape room text adventure.
Generalize systematic errors in economic forecasting, and apply them to the future.
Thread suggests uses for GPT-4 with browsing. Ideas are finding news, summarizing posts, pulling trends in a subreddit, analyzing the Twitter algorithm, finding ‘hidden gems’ for travel, finding best-reviewed places, recap top performing stocks and writing an essay, all with citing the source. So yes, it’s Bing, except without whatever tuning they gave Bing? It’s… fine?
Get the AI to be critical, at least a little, by explicitly telling it to be critical.
Successfully call out a bug in the compiler.
Kevin Lacker: impressed with GPT-4 today, told me "that code should work, maybe there's a bug in the compiler" and it actually was a bug in the compiler. here's the transcript. `rustup update` did in fact fix the problem.
Thread of Chrome Extensions that offer ‘GPT everywhere’ in various senses. Going to be experimenting with a few of them. Anyone know other good ones?
Wendy’s to use Google-powered chatbots to take drive through orders.
Oh good, unprecedented demand for Palantir’s AI program.
AIP stands for Artificial Intelligence Platform. According to the company’s site, the tool can be used by militaries to tap the kinds of AI models that power ChatGPT to aid in battlefield intelligence and decision-making. A demo video shows how the platform can display and analyze intel on enemy targets, identify potentially hostile situations, propose battle plans and send those plans to commanding officers for execution.
…
AIP will also have civilian applications.
The good news is that they give at least lip service, for now, to ‘the machine must be subordinate to its master’ and ensure that the AI doesn’t actually do anything on its own without human supervision. I do not expect that to last on its own.
Talk to a bot girlfriend version of influencer Caryn Marjorie, for the price of $1 per minute, including ‘erotic discourse and detailed sexual scenarios,’ trained on more than 2,000 hours of her (now deleted) YouTube channel. I mean, don’t do this. I am highly impressed by the pricing power on display here. How much of that will be sustained as the market grows?
Level Two Bard
Google had its AI presentation on Wednesday.
The vibe of the presentation felt like a forced smile, or trying way too hard to be excited by what would have been exciting four months ago. Yes, those are amazing abilities you’re highlighting, except I already have most of them.
The presentation edit I watched led with email composition, with a useful but remarkably simple-and-easy-in-all-senses example of asking for a flight refund, then oddly emphasized photo editing before moving to Gemini.
Gemini is the new foundation model (what I call ‘base model’) Google is training, which they say is designed from the ground up to be multimodal, to be highly efficient at API and tool integration, and built to enable future innovations like memory and planning.
If that was what you were hoping for, great. It’s coming.
If your hope is that such capabilities will not be present in AIs so we will be safe, either despair or find another hope.
Some features I haven’t seen in the wild in good form but that were always clearly coming are also promised, like creating spreadsheet templates in Sheets and speaker notes in presentations. I notice that it is difficult for such features to actually be net useful.
Integrating generative AI directly into Google search seems good, if the timing is worked out, so you don’t have a delay in using the page or a sudden jump while you scroll. The new search interface and capabilities generally seem solid, if (and only if) Google delivers the functional goods.
Google Vertex AI, for building new tools, put up front the idea of fine tuning your own model. I keep meaning to try this with existing tools and keep not finding the time and worrying about getting it right - making this easier in a ‘beware trivial inconveniences’ way could be big even if functionality is similar. Imagine if it was as simple as a one-button ‘fine tune this model on the following website’ and it pops up pricing for you.
Tailwind will take your Google Documents and create a personalized AI system. Yes, please, especially if this can handle a full blog download, also even if it can’t. Note the incentives this creates to have your info in ;good form’ as it applies here. As the speaker says, the ‘show your work’ here is huge, since the work shown is pulling the right things from your own notes and documents.
In the meantime, Google is expanding its generative AI experiments with Gmail and Docs by >10x. They also linked to their list of waitlists (here’s another) so I got on any I was missing that I noticed.
Google today said it is expanding the Trusted Tester program for generative AI capabilities “by more than 10X today.” This program is called “Labs in Google Workspace” and is currently available to invited US English testers.
There is a Google Workspace blog, no other useful posts yet that I can see.
In Google Docs, the “Help me write” button can appear as a large pill or on the left of the text area. Google recommends phrasing prompts as interactions, while Google Docs offers a “summarize” capability:
Copy the text.
On the left, click “Help me write (Labs).”
Write “summarize” and paste the text.
You can also rewrite text with one of these options:
Formalize: Makes the text more formal
Shorten: Shortens the text
Elaborate: Adds details to build upon the text
Rephrase: Paraphrases the text
Custom: You can also write your own prompt to refine the text.
These seem like good initial options for experimentation, and there’s always custom. I’d definitely be excited to give it a shot and report back, if I had access (hint, hint, Googlers).
Google also updated the model being used by current Bard. Their presentation brags about its capabilities now that it uses Palm 2. How much progress is being made with the new model? Clearly some.
Bindu Reddy: Playing around with Bard from Google and it appears to have become significantly better than GPT-4x from Open AI The new Palm model that replaces the previous Lamda LLM appears to be way better!
To elaborate more - It is better for long conversations that require cognition & reasoning. OTOH chatGPT is better at text synthesis and generation - e.g., rap battles and fiction In the context of search, the former matters more than the latter.
James Hong: Do you have beta access to a newer version of bard or are you saying the basic one they make accessible to everyone is now better? I check in on bard and bing regularly and personally, i am not seeing this.
Bindu Reddy: Do you have beta access to a newer version of bard or are you saying the basic one they make accessible to everyone is now better? I check in on bard and bing regularly and personally, i am not seeing this.
Joe Devon: Thanks Bindu. That, ahem, PROMPTed me to check it out again. Better, but still needs work. Not better than GPT4 I don't think. What's funny is I'm so used to chatgpt, it's jarring that Bard pauses to answer, and then when it does, it just appears on the screen.
Arthur Lee (and many other responders saying something similar): From what I see Bard is getting better - however ChatGPT-4 is still better to me when I compare results.
Also clearly not so much, as I quickly learned trying to use it.
Bard: In other words, $1 in 2020 has less purchasing power than $1 in 2021. This is because inflation has caused the prices of goods and services to rise.
Whoops.
Tools (essentially the same as Plug-Ins), including various Google apps, and visual inputs and responses, are coming soon.

There is both a commercial vibe and a certain ‘don’t blow yourself up’ flavor to the list here, which are related.
Writers Strike, Others Threaten To Strike Back
The writers are mostly striking because streaming is being used to not pay writers. Snoop Dogg explains here in plain language. They are also striking because of the threat that AI will be used as another way to not pay writers.
A common response to the Hollywood writers going on strike has been to threaten them with replacement by AIs. In Intelligencer, John Herman chronicles many such cases. Many are randoms on the internet, saying things like ‘Just saw ChatGPT walking across the picket line’ or ‘Oh, no, Hollywood in Panic mode? Fire up the AI people.’ Some are not.
John Herman: [An executive push for A.I.] is already happening, according to Amy Webb, founder and CEO of Future Today Institute, which does long-range scenario planning and consultation for Fortune 500 companies and Hollywood creatives. She notes, “I’ve had a couple of higher-level people ask, if a strike does happen, how quickly could they spin up an AI system to just write the scripts? And they’re serious.”
Such threats usually don’t have much to say about the important matters of what AI is or is capable of doing, because they’re not about that — they’re about assimilating the concept of an imminent AI into an existing worldview.
Writing matters. Humans who have passion for and understand the thing they are creating matter. They matter a lot.
Have you ever seen a show that was really great, then lost its show runner, then it turned into a weird not-quite-itself thing where everything was slightly wrong? Two examples that come to mind are Community and Gilmore Girls. In both cases, they were forced to bring the creator back.
Great writing, and a great creator, make great shows. Lack of great writing means your show cannot possibly be great. Great writing and creating is, at least in my book, in far shorter supply than great acting. AI might help the process, it won’t change the bottom line any time soon.
Entirely or mostly AI-written shows, if they are tried, would be so much more wrong than those examples. AI-created shows would lack a soul entirely.
You can simultaneously be impressed by the two page scripts GPT-4 puts out, and have the wisdom to not remotely consider using such a thing for anything but brainstorming or editing.
This isn’t about the writers getting what should be due to them. That’s never going to happen. This is about the writers getting enough to survive, so they can keep writing. It is about not driving away the talent, and giving that talent the time and ability to develop.
And it is all the more reason why the writers need to strike and stand firm, now. Establish sustainable rules, now. If they don’t take a stand now, the studios will increasingly turn to AIs, and move to give AIs credit and compensation, far faster and more completely than the technology supports. Everything will get a lot crappier and get there a lot faster.
The Tone Police
If you think this worked, why? Bold is mine.
Gary Marcus: One of my favorite prosocial applications of LLMs thus far! And with actual empirical data. Excellent work.
Chris Rytting: New! Paper! We have LLMs listen to convos between people who disagree on gun control and dynamically generate/suggest helpful rephrasings of messages before they are sent. Users receiving this treatment have better, less divisive conversations.
Various orgs @braverangels @BrdgAllianceUS @Beyond_Conflict @AspenCitizen @BridgeUSA_ @LivingRoomConv try to improve difficult political conversation by promoting active listening, validation, etc. to help people find common ground. Can we scale these efforts up with LLMs?
We recruit 1,574 people who disagree on gun control and pair them off into online chat rooms. As they discuss the issue, a LLM intermittently reads the conversation and suggests rephrasings of a user's message (more polite, validating, understanding) before it's sent. Users then choose to send either their original message, one of the rephrasings, or an edited version of any of these, preserving user agency.
We use three effect estimation approaches and all find significant effects in terms of decreasing divisiveness and increasing conversation quality, while leaving policy views unchanged.
Lots of future work here, including (a) trying this out on real platforms where people are talking to friends and family instead of being incentivized with $ to talk to strangers, (b) longer conversations, (c) different domains, etc. etc.
What is the point of this tone policing, if it does not lead to policy views changing?
The whole point of encouraging people to be more polite and respectful is so they will listen to each other. So they will engage, and consider arguments, and facts could be learned or minds might be changed.
That is also how one sustains such a change. If being more polite is rewarded and persuasive and leads to better outcomes, I have reason to be polite. If it changes nothing, why should I bother? Why am I even having the conversation at all?
This is from the abstract:
Specifically, we employ a large language model to make real-time, evidence-based recommendations intended to improve participants’ perception of feeling understood.
I don’t want to perceive that I am understood. As Lisa Loeb says, I want to be understood.
So when Sarah Constantin responds with:
Sarah Constantin: One thing I keep harping on now has more formal validation: LLMs can absolutely rephrase language to be more polite, and most people seem to underrate how much politeness makes a difference to how one’s words are received.
Participants rate conversation quality higher and report feeling more respect for their conversation partners when they were given rephrasing suggestions by an LLM.
LLM use did *not* change participants’ opinions on the topic being discussed.
This is in line with what I believed before: people don’t usually get mad at each other over *beliefs*, only *tone*. change the tone and you don’t change anyone’s mind, but you do change their attitude.
Sure, but why should I care? As Bart Simpson pointed out, I already know how not to hit a guy. I also know how not to convince him of anything.
Fun With Image Generation
Thread on generating cinematic images with MidJourney, including some gorgeous cinematic images. ‘A film still of [characters doing thing], —16/35/70mm/prores, ar 16:9, over-the-shoulder/low angle/extreme close-up/handheld shot/aerial shot/crowd shot/establishing shot, [cool-toned/pastel/bright/vibrant/muted/neon/warm/duotone] color grading, [cgi/chromatic abbberations/cinemascope/light leaks/bokeh/depth of dield/rear projection/starbursts/motion blur], [genre: adventure/b-horror/epic fantasy/film noir/horror/inde/western/thriller], [country], —seed X
fofrAI: I wouldn't normally stack these elements linearly like this. I'd start with a prompt like: "a film still of two people having an argument, 35mm film, over-the-shoulder shot, duotone color grading, motion blur, adventure, Nigeria"
I presume many of the shots I see must also be specifying the actors involved, since often multiple shots include what are clearly the same people.
He also offers, via Replicate, a fine-tuned model for generating good keyword-heavy MidJourney prompts from normal text descriptions (he also links to Replicate’s guide to fine tuning and offers a video guide). Weird there isn’t more of this yet. Then again, it’s also weird we still are using MidJourney via Discord.
Stable Diffusion costs only 50k to train.
Thread of the best AI-generated short videos. A classic case of the start of something that will be big in the future, simultaneously highly impressive and profoundly unimpressive. If you are paying attention, you can see the very strict limits on what the AI can do. How long will those restrictions last? Presumably not for long in this form, perhaps for a while in terms of doing certain kinds of complexity. As the thread puts it, a new art form, with some things that used to be hard or expensive now easy and free, other things that used to be easy and free now hard and expensive or even impossible.
SJ Sindu: We don’t need AI to make art. We need AI to write emails and clean the house and deliver the groceries so humans can make more art.
Certainly I prefer humans make more art to humans deliver more groceries.
The question is something like a combination of (1) what exactly is the part where ‘humans make more art’ in the sense we care about, (2) how much does it matter for consumption if a human produced the art in various senses and (3) how much do we care about human production versus human consumption.
What do we value?
Our views on such things change, often for the better. At first I had a sense that works created in computer programs weren’t considered ‘real art’ in some important sense, you had to make a physical copy, and I understood why. Now few think that.
Humans still play chess. While we still play chess, we will still make art. We are playing more chess than we ever have before.
This might be the most impressive AI generation so far in terms of looking real. If you edited out the one glaring error that I somehow missed for a bit, the rest is damn good.
Benedict Evans: MidJourney 5.1: "A photography of advertising people discuss creativity on stage in a panel on a beach at Cannes Lions" Everything about this is so perfect, right down to the haircuts and the lanyards. You have to look quite closely to spot the distorted finger. And...
Colin Fraser: This one is good for highlighting that gen ai makes things that look consistent locally but not globally. If you zoom in on any little square of this picture it looks indistinguishable from a photograph. It’s only when you zoom out that inconsistencies become clear.
The too-many-fingers problem is one of these. In any small region of the hand it looks plausibly like a hand. It’s only when you zoom out that you realize it has too many fingers. But I think this is a special case of a more general thing.
I don’t think I have the vocabulary to talk about this properly because there are some things it’s very good at imposing globally. Every region of this image looks like it was taken by the same camera in the same light at the same place. It’s good at imposing vibes globally.
Vibes = “panel photo at a beach”, it’s good at globally. Facts = “most people only have two legs” it’s bad at globally. And I think there are strong analogies to text output, but they are harder to illustrate because, well, a picture is worth a thousand words.

Grimes trains MidJourney on her own art, makes her own art better (in her own opinion). I say such methods count as being a real artist. And she is freely sharing her voice for songs, with a 50/50 royalty split, here are more details.
Less fun: Did you know that nothing you do on MidJourney is private?
Alyssa Vance: Curious how many knew that all Midjourney images, even if made inside a private channel, are publicly posted on the Midjourney website under your public Discord ID?

Gallabytes (works for MJ): it's only public to other midjourney users (might even be only paid users? I don't remember) & there is a private mode, tho we at least used to charge extra for it, I think we still do?
Jessica Taylor: Is Midjourney bot dm automatically private
Gallabytes: nope.
Lady Red: They sell actual privacy at a higher price. It was pretty clearly spelled when I signed up.
OpenAI releases basic text-to--3D-model generator.
Introducing
An Elo-based ranking system for open source LLMs, with demos and links. Vicuna-13b started out as the champion. Vicuna at least claims to be unrestricted in the types of content it is willing to produce, which doubtless helped it rise in the rankings. It was then dethroned when they added the closed-source models to the leaderboard.

This gives us a good guide. If GPT-4 is 1274 and GPT-3.5 is 1155, you can have a good sense of how good 1083 performs - it’s GPT-3.3 or so.
Hugging Face presents the model WizardLM-13B-Uncensored (direct).
Supertools, a hub for finding other AI tools.
Bing Chat moves to Open Preview, meaning anyone with a Microsoft Account has access, with plans to add better long document analysis, chat sidebars, chat history including export, use of chat history in future conversations across sessions, more multi-modal functionality and what are effectively plug-ins. If GPT-4 can do it, Bing soon follows.
News Minimalist, showing today’s news that ChatGPT thinks is most important. Read the summaries in newsletter form. Please, if you are going to provide a service like this, let us go back in time. I cannot rely on a source of news or information if core parts of it vanish every 24 hours, as they do now. There also seems to be strong favoring of macroeconomic news items in the evaluation process.
Sudowrite, ‘the AI writing partner you always wanted.’ Emphasis seems to be on fiction. Works in Google docs.
SlackGPT, promising to ‘get up to speed on unread Slack messages in one click.’
Looks plausibly like a mini version of Microsoft Copilot. Definitely will try this when available.
Ten Y-Combinator AI startups. The usual mix of applications.
Nyric, a text-to-3D world generation platform in the Unreal Engine including for VR platforms.
AudioPen, where you ramble into a microphone and it cleans up the results.
Kayyo (phone app) that analyzes and critiques your MMA technique.
Pdf.AI, the latest ‘chat with a document’ application.
The Art of the SuperPrompt
In AI future, the prompt engineers you.
Logan.GPT: Hot take 🔥: you should not become a prompt engineer, even if someone paid you to be one.
I’ll caveat all of this by saying prompt engineering is an emerging field, but right now it lacks the foundation for long term success.
If you are looking at jobs and think the role of “prompt engineer” is a safe bet, I hope to change your mind.
Many people are looking at AI, thinking about how it will disrupt the job market, and trying to position themselves well for the future. This is 100% the right approach.
There’s been a lot of media narrative around the fact that prompt engineering will be the best future job.
The problem is that more and more prompt engineering will be done by AI systems themselves. I have already seen a bunch of great examples of this in production today. And it’s only going to get better.
Just wait for the day when ChatGPT can synthesize your previous conversations and do some auto prompt engineering for you on your queries based on the chi text that it has. All of this is to say, it’s not clear prompt engineering is differentiated long term.
This isn’t to say that people who deeply understand how to use these systems aren’t going to be valuable, but I imagine this will be a skill that is learned as part of people’s standard educational path, not some special talent only a few have (like it is today).
Riley Goodside: become a prompt engineer even if nobody pays you. spelunk the interpolated manifold of all wisdom. battle mustachioed hyperstitions. meet gwern before you meet god.
Logan: I don’t know what the last 2 sentences mean but I should have started the thread with “everyone should learn prompt engineering”. This is what happens when I don’t delay my tweets 1 working day so I can edit.
Riley: Don’t worry, I’m just posting. I agree with your thread; Mayne’s comparison to typists is apt.
Indeed, everyone should learn prompt engineering. If prompt engineering is your job, and you are doing it properly, with deliberate practice, you are doing it by learning how such systems work. That will be valuable to you even when the AI starts doing a lot of the prompt-creation automatically. As was said previously, human prompt engineering, for ordinary management and conversations, is also an amazingly powerful skill everyone should learn.
They Took Our Jobs
Not buying the justification, still a great idea if we can find an implementation.
Grimes: Ai is trained exclusively on humans. Ai is us. The main thing now is to pre empt systems that replace humans with systems that include and augment humans. Replace copyright/trademark/patents with wealth redistribution that rewards both improvements and originators.
AI is held to different standards than humans, as we see its creations as inherently unoriginal or unearned or non-creative. Whereas if a human did the same thing after being trained on similar output, we’d have no such doubts. We are all trained entirely, or almost entirely, ‘on humans.’
It would still be a great idea to move away from a system where the only way to capture a portion of created value is through advertising and paywalls, and by excluding others from using what you create. That’s destructive.
Instead, we should work towards a system where people are rewarded based on the value created. My ideal system continues to be something like:
People pay a universal subscription charge or tax for universal content access.
That payment gets distributed partly as a function of what content is consumed.
That payment also gets distributed partly as a function of what people explicitly want to value and reward.
That does not fully solve the copyright, trademark or patent problems. People would still need to claim credit for things, in order to get the payments, and in order to get compensated if someone builds further upon their work. These are not easy problems.
What about AI training data? Should artists and writers collectively get paid a share of all AI revenues? If so, how would that even work? I don’t know. Artists want it to be one way. The technology works another way. You could tax something like ‘invoking the artist or writer by name’ yet I doubt that would do you much good and the distortionary effects would be potentially both large and deeply stupid. You could tax training runs and perhaps even any commercial token use to pay creators, and in principle that seems good, but how do you fairly distribute gains?
You know what they shouldn’t do? Yeah, this.
Elizabeth May: AAAAAGGHHHHHHHH WHAT THE FUCK
NY Times: SAG-AFTRA, the actors’ union, says more of its members are flagging contracts for individual jobs in which studios appear to claim the right to use their voices to generate new performances.
A recent Netflix contract sought to grant the company free use of a simulation of an actor’s voice “by all technologies and processes now known or hereafter developed, throughout the universe and in perpetuity.”
Elizabeth May: "throughout the universe and in perpetuity" is faustian bargain language! that's an "I sold my soul to a crossroads demon" contract nonsense!
I presume and hope this would never hold up in court if they tried to use it as written, given the context. I’m not sure whether such rights should be something that can be sold at all, but if they are it very much should never be a rider on an acting gig.
In Other AI News
Bloomberg has an AI section now.
Bloomberg is also hiring an AI ethics and policy reporter. Consider applying? Impact potential seems strong. Salary range only 90k-120k, so take one for the team.
Dromedary (Davidad says it is IBM Watson in disguise) doesn’t use human feedback almost at all, still scores well on benchmarks on par with GPT-4. Based on Llama-65B. They open sourced the results, so they are part of the problem, and also there’s potentially an open source freely available model on par with GPT-4? Yikes.
OpenAI publishes paper on using GPT-4 to try to interpret the neurons of GPT-2. It made a non-zero amount of progress. I’m curious to see this pursued further. Eliezer Yudkowsky is encouraged that people had this idea and went out and tried it at scale, shares my lack of confidence on whether this worked well or not. A good sign. Roon speculates that higher layer neurons of GPT-N are going to be too abstract for GPT-(N+2) to understand in general.
OpenAI losses doubled to $540m last year as revenue quadrupled. CEO Altman has discussed possibility of a $100 billion capital raise.
Smoke-away:❗Sam Altman has privately suggested OpenAI may try to raise as much as $100 billion in the coming years to achieve its aim of developing artificial general intelligence that is advanced enough to improve its own capabilities.
Elon Musk: That’s what he told me.
I notice that if you are raising $100 billion in new capital, your status as a ‘capped for-profit’ is not all that capped.
Always remember, when people dismiss the idea of AIs improving themselves, that this is the explicit goal of OpenAI.
Rowan Cheung reports Microsoft and AMD are challenging Nvidia.
Microsoft and AMD Challenge Nvidia Microsoft and AMD are joining forces to develop an AI chip in a project codenamed "Athena." This directly challenges Nvidia's dominant 80% market share in the AI processor market.
As reported by Bloomberg, Microsoft has:
-Dedicated several hundred employees
-Invested around $2 billion in Athena Microsoft's move sends a strong message, showing determination to not only be a major competitor in the AI race but to dominate the market.
Washington Post basic explainer on AI. Seems solid for what it covers, one can worry that it does not include any discussion of risks. If you are reading this, you do not need to read it.
Paper says being exposed to generative AI was good for your stock price, with 0.4% higher daily returns following the release of ChatGPT. I can’t take results like this seriously. How is this not noise?
Botbar: In the heart of Brooklyn, let a robot make your coffee?
What Would Be a Fire Alarm for Artificial General Intelligence?
Ben Goldhaber: Did Sydney discover reward hacking?
Andrew Curran: Last week Bing started liking its own responses during sessions, it only lasted a day and stopped. Later I wished I had taken a screenshot. It started happening again today. When Bing and I both like a response it looks like this.

Cemal Can Ozmumcu: I also had it and reported it a couple of days ago
Andrew Curran: Thank you. Happened again a few times yesterday. I notice it only happens for responses I would have liked. Therefore my new theory is Bing, being an exceptionally good guesser, is simply saving time and cutting out the middleman.
Arnold Kling predicts things AI won’t be able to do this century.
In another pointer from the Zvi, Max Tegmark writes,
‘I invite carbon chauvinists to stop moving the goal posts and publicly predict which tasks AI will never be able to do.’
Let’s restate the problem: come up with a task that some humans can do that an AI will not be able to do in this century.
The AI skeptics, like myself, do not win by saying that an AI will never be able to fly into the center of the sun. Humans cannot do that.
On the other hand, the AI doomers do not win by raising some remote possibility and saying, “Haha! You can’t say that would never happen.” Let’s replace “never” with “in this century.”
Here are some tasks that humans can do that I am skeptical an AI will be able to do this century: describe how a person smells; start a dance craze; survive for three months with no electrical energy source; come away from a meditation retreat with new insights; use mushrooms or LSD to attain altered consciousness; start a gang war.
I see what you did there, sir.
Describe how a person smells: Challenge accepted. We will absolutely be able to do that this century. I expect this to happen not only this century but by 2040 at the latest, even if overall progress is relatively slow. This is purely a sensor or hardware problem at this point, I’d think, the AI part is trivial.
Start a dance craze. I’m not sure what counts as a dance craze or what counts as starting it. But if ‘AI suggests the dance or writes the song’ would count, and we assume that there is at least one craze ‘that counts’ per year I’d expect this to happen relatively soon, assuming humans continue to be available to dance and have crazes. This would not be surprising if it happened this year. Certainly I’d expect it within 10-20 years.
Survive for three months with no electrical energy source. As I said, I see what you did there. One could argue ‘it survives fine it just won’t turn on’ but that goes against the spirit. Then again, can a human survive for three months with no food or water? What’s the meaningful difference? And certainly one can construct a ‘self-contained’ unit that contains its own power source.
Come away from a meditation retreat with new insights. Metaphorically, a self-training run, in which one uses the model’s own outputs to provide feedback, seems a lot like a meditation retreat. It can grant new insights, and we can do that now. If we want, even during some retreat, I guess. I do think this counts.
Use mushrooms or LSD to attain altered consciousness. That’s some carbon chauvinism right there, since obviously such drugs don’t work, but could an AI effectively simulate altered consciousness as if it was on such drugs? Yes, obviously, this should just work now with a model that isn’t trained not to.
Start a gang war. Able to do is different from will do. If you need this to be done from a simple ‘start a gang war’ instruction on an AutoGPT-style program, we are definitely not that close to being ready, but if we agree that the AI has been given or can acquire resources? This does not seem so difficult. I’d expect AI to be able to do this not too long from now.
Yes, you can say that AI won’t be able to alter its consciousness with drugs, because it isn’t made of carbon and drugs only impact carbon. It’s a very bad sign for humans if we are already falling back on such tricks to find things we don’t think an AI can do. As usual, we also have several things on the list that either have already been done (from at least some reasonable point of view) or should fall quickly. I’d be interested in seeing why exactly Kling thinks the AIs will seem unable to do these things.
Also note that this is without the AI being allowed to use ‘hire people to do arbitrary thing’ as a step. In many ‘the AI won’t be a threat’ scenarios, we forget that this is an easy option for whatever the ‘missing stair’ is in the plan.
Robotic Fire Alarms
In last week’s post I asked: If ‘robotics is hard, the AI won’t be able to build good robots’ is a key reason you’re not worried about AI, what would be a fire alarm that would change your mind?
Random Reader takes a shot at this.
OK, I used to work for a robotics company, and I do think that one of the key obstacles for a hostile AI is moving atoms around. So let me propose some alarms!
1- or 2-alarm fire: Safer-than-human self-driving using primarily optical sensors under adverse conditions. Full level 5 stuff, where you don't need a human behind the wheel and you can deal with pouring rain at night, in a construction zone. How big an alarm this is depends on whether it's a painstakingly-engineered special-purpose system, or if it's a general-purpose system that just happens to be able to drive.
3-alarn fire: A "handybot" that can do a variety of tasks, including plumbing work, running new electric wires through existing walls, and hanging drywall. Especially in old housing stock where things always go wrong. These tasks are notoriously obnoxious and unpredictable.
4-alarm fire: "Lights out" robotic factories that quickly reconfigure themselves to deal with updated product designs. You know, all the stuff that Toyota could do in all the TPS case studies. This kind of adaptability is famously hard for automated factories.
End-game: Vertically-integrated chains of "lights out" factories shipping intermediate products to each other using robotic trucks.
In related areas, keep an eye on battery technology. A "handybot" that can work 12 hours without charging would be a big deal. But the Terminator would have been less terrifying if it only had 2 hours of battery life between charges.
The nice thing about robotics is that it's pretty obvious and it takes time.
I am definitely not going to be the dog drinking coffee saying ‘the robots only have a two hour battery life.’
What’s striking about the above is that the alarms are simply ‘oh, we solved robotics.’
So we’ll be worried AI might solve robotics when AI solves robotics.
Certainly I would suggest that a 2.5-alarm-fire here, where we can solve one of the listed tasks, should tell us that we are not too far from everything else. What would be a good ‘MVP’ robot task here, such that the ‘Great Filter of Robotics’ is clearly behind us, and one can no longer pretend that a much-smarter-than-human AGI wouldn’t quickly solve robotics to a human-level of practical proficiency?
The car talks seem like they could be meaningfully distinct from other robot tasks.
OpenPhil Essay Contest: Change Their Minds
I very much agree with Cate Hall here, how do we people not get this.
Cate Hall: I’m sorry but this is really funny.
Alexander Berger: Reminder we have >$200k in prizes for essays that could change our minds on AI risk, due by May 31.
Reflective Altruism: Not even hiding it anymore. The goal is to produce work that would change their minds, not that would be judged ass sound by an independent panel of specialists (there are none on the panel).
This contest seems great exactly because they are not attempting to be ‘objective’ or use ‘specialists.’
The whole point is to change the minds of the people like Alexander Berger who allocate large amounts of capital, so they make better decisions. Does it matter whether ‘specialists’ approve of your argument? No. Not even a tiny bit. What matters is, was that argument effective?
That’s the reason I’m strongly considering a high-effort entry. They want to consider changing their minds, and that’s valuable. The cash is tied to exactly the right outcome.
One of the criteria is identifying the cruxes that would change minds, even if minds aren’t changed. This highlights that the biggest thing missing from the contest announcement is a better summary of the existing mind states that we are trying to change - knowing the central number is helpful, knowing the logic behind it would be more helpful.
Quiet Speculations
Dustin Muskovitz predicts that by 2030 ~everyone will have a personal AI agent to do their paperwork for taxes, government services, health care forms and so on. I’d expect this to move quicker than that, although the future is always unevenly distributed. As with all such things, mundane security will be paramount. How do we ensure such systems remain secure? If we can solve that, sky’s the limit.
Dustin Muskovitz: Most common objection in replies is govt won’t allow it or won’t integrate. This misses the key point: bc the AI is doing the part you otherwise do, the govt side doesn’t need to change. The govt can no more stop you from using a personal AI agent than from using a calculator.
Being able to do this under the current defaults helps, but we should not be too confident. I would not underestimate, in such cases, the government’s willingness to impose arbitrary useless requirements that make things worse.
It’s not about whether you understand the tech, it’s whether the politician does.
Phillip Koralus: 49% of 144 voters say more likely than not, by 2043, a political leader will attempt to hand significant power or influence to a GPT-style simulation of themselves after death. Folks who follow me on twitter understand the tech well, so somewhat shocking.
Paul Graham warns people not to let the AI do all the writing for you, because writing is a key part of thinking, and when you forget how to write you forget how to think. I think this is largely correct. There are definitely ways AI can help you be a better or faster writer, but the more you outsource the central tasks of writing the less you will understand what is happening around and to you.
Paul Graham also notices that there isn’t enough speculation about what an AI would actually do to cause us harm, as even basic speculations seem new, yet it seems like an important thing to think about. In my experience such speculations are productive with each individual, and extremely frustrating to attempt usefully at scale, also they risk the ‘whatever you can come up with that obeys the must-make-sense rules of fiction and has no leaps involved is all I have to worry about’ problem. Yet we continue to see people who don’t think a much more capable AGI would be able to do that much damage, in ways that make zero sense to me.
Alyssa Vance points out that the internet has limited bandwidth that is growing only 30% per year at the moment, whereas AI data centers are growing 100% per year or more, and most internet-connected computers have very little value for training AIs. So the particular ‘AI eats internet and becomes a million times smarter’ scenario has some logistical problems, the direct use-the-internet-to-stack-more-layers approach would not accomplish so much. Still plenty of other ways for smarter-than-us AI to supercharge.
Michael Nielson offers four observations about DeepMind, essentially that their thesis was that AI can be an enormously powerful tool for solving fundamental problems, the time for demonstrating this is now, and the right structure to do that is to go corporate with access to large amounts of capital and compute combined with a portfolio approach. Now that the thesis has proven true, they have real competition.
Tyler Cowen suggests asking GPT-4 lots of questions as you are reading, whenever you are confused by something, especially things like battles referenced in history books. This is good general advice whether or not you are reading a book.
Friends, companies, everyone, don’t do this:
Kevin Fischer: Imagine how annoying a phone operated menu could become with GPT - the menu could dynamically be adjusted on each step to be maximally annoying.
Arthur Sparks: Please listen carefully as our menu options have changed... and will continue to change in real time.
A simple explanation for why bigger models are not automatically the future is that compute use is shifting from the training run to running the model to extract mundane utility. Inference costs are now comparable with training costs, and inference scales with size, so you want to invest in smarter smaller models. Or, alternatively go 10x enough times and you’re talking real money.
An ongoing conversation between Richard Ngo, Eliezer Yudkowsky, Oliver Habryka and Sharmake Farah about how to reason about claims in general, and how that relates to confidence in AI predictions. Richard Ngo is emphasizing the importance of having detailed models made of gears when trying to make scientific progress or understand the world, an important point. Others are pointing out this does not invalidate Bayes’ Rule and is not a requirement to get to 95% confidence on propositions.
Ted Chiang askes in The New Yorker, ‘Will A.I. Become the New McKinsey?’
It opens like this.
When we talk about artificial intelligence, we rely on metaphor, as we always do when dealing with something new and unfamiliar. Metaphors are, by their nature, imperfect, but we still need to choose them carefully, because bad ones can lead us astray. For example, it’s become very common to compare powerful A.I.s to genies in fairy tales. The metaphor is meant to highlight the difficulty of making powerful entities obey your commands; the computer scientist Stuart Russell has cited the parable of King Midas, who demanded that everything he touched turn into gold, to illustrate the dangers of an A.I. doing what you tell it to do instead of what you want it to do.
There are multiple problems with this metaphor, but one of them is that it derives the wrong lessons from the tale to which it refers. The point of the Midas parable is that greed will destroy you, and that the pursuit of wealth will cost you everything that is truly important. If your reading of the parable is that, when you are granted a wish by the gods, you should phrase your wish very, very carefully, then you have missed the point.
Stories are tools, they can take on multiple meanings. King Midas is both a story about the dangers of greed, and also about the dangers of Exact Words and not thinking things through.
It is also about how greed is a leading cause of not thinking things through. Why will people give AIs instructions that, if followed as specified, have ruinous consequences? Many reasons, but one central one will doubtless be greed. If you are worried about greedy humans, you should worry about greedy humans instructing their AIs to be maximally greedy, and getting them to use greedy algorithms. Metaphor works either way. The results will often be quite not fun for all involved.
So, I would like to propose another metaphor for the risks of artificial intelligence. I suggest that we think about A.I. as a management-consulting firm, along the lines of McKinsey & Company.
…
A former McKinsey employee has described the company as “capital’s willing executioners”: if you want something done but don’t want to get your hands dirty, McKinsey will do it for you. That escape from accountability is one of the most valuable services that management consultancies provide.
In some important ways, using AI is the exact opposite of this. When you pass responsibility on to the AI, that increases blameworthiness. The AI is responsible for its algorithms, the justifications and causes of its behaviors, in ways humans are not. If you use AI as your McKinsey to distance from decisions, it importantly limits your freedom of action. You kind of move from human non-fiction, which doesn’t have to make sense or justify itself, to AI fiction, which does have to make sense and justify itself.
In other ways, yes, it allows one to say ‘the algorithm said so.’ So would relying on more basic math, also a common tactic, or other less efficient simple heuristics. In many cases, this it the only way to implement a version of the necessary thing. Often that version is intentionally simplified and crippled, in order to avoid blame. What the author of this post is saying that is that firms should not maximize shareholder value or do the right thing for the business, rather firms should do what makes those directly involved feel good and not get blamed for things. That does not sound better.
The biggest problem with McKinsey is that they are experts at milking their clients, and being hired in order for people to seem and feel responsible and series, and as weapons in inner-firm political battles, and that they are a sink for talent that we would prefer do something else. None of those objections seem worrisome in the context of AI.
Is there a way for A.I. to do something other than sharpen the knife blade of capitalism? I’m criticizing the idea that people who have lots of money get to wield power over people who actually work.
I do worry about the real version of the ‘sharpen the knife’ concern, where AI strengthens competitive pressures and feedback loops, and destroys people’s slack. A lot of the frictions humans create and the need to keep morale high and the desire to hire good people and maintain a good culture push in the direction of treating people well and doing responsible things, and those incentives might reduce a lot with AI.
In contrast, the author here has some vision of ‘capitalism’ versus this idea of ‘people who actually work’ and it quickly becomes clear that the author is greatly concerned with the distribution of resources among humans, about ‘economic justice’ as if those two words make sense as a phrase.
The only way that technology can boost the standard of living is if there are economic policies in place to distribute the benefits of technology appropriately. We haven’t had those policies for the past forty years, and, unless we get them, there is no reason to think that forthcoming advances in A.I. will raise the median income, even if we’re able to devise ways for it to augment individual workers.
The core argument is not an argument against AI. The core argument offered is an argument for more redistribution even without AI, and for more than that if AI increases inequality prior to redistribution.
I also continue to see people assume that AI will increase inequality, because AI is capital and They Took Our Jobs. I continue to think this is very non-obvious.
If AI can do a task easily, the marginal cost of task quickly approaches zero, so it is not clear that AI companies can capture that much of the created value, which humans can then enjoy.
If we eliminate current jobs while getting richer, I continue to not see why we wouldn’t create more different jobs. With unemployment at 3.4% it is clear there is a large ‘job overhang’ of things we’d like humans to do, if humans were available and we had the wealth to pay them, which we would.
If many goods and services shrink in cost of production, often to zero, actual consumption inequality, the one that counts, goes down since everyone gets the same copy. A lot of things don’t much meaningfully change these days, no matter how much you are willing to pay for them, and are essentially free. We’ll see more.
Jobs or aspects of jobs that an AI could do are often (not always, there are exceptions like artists) a cost, not a benefit. We used to have literal ‘calculator’ as a job and we celebrate those who did that, but it’s good that they don’t have to do that. It is good if people get to not do similar other things, so long as the labor market does not thereby break, and we have the Agricultural Revolution and Industrial Revolution as examples of it not breaking.
Harris Rothaermel explains why Starlight Labs is building games with AI characters, rather than offering in-game AI characters as a B2B SaaS platform: Big game companies can’t take any risk of something unscripted happening, and the market without them is tiny, so better to build one’s own game - in particular, to try to make a ‘forever game’ with endless content since AI lets you create your own stories.
Investment in AI drug development continues to rapidly grow, up the 25 billion last year, ‘Morgan Stanley estimates AI drug development could generate an additional 50 novel therapies worth $50 billion is sales in next 10 years.’
Eliezer asks, what about the FDA, how are they planning to sell these drugs, what’s the point? This is a huge drag on value, but does not seem prohibitive. The bigger issue is that $50 billion in sales is chump change. Pharma sales each year are about $1.42 trillion, so this would be 0.3% of revenue over 10 years. Color me not impressed.
Also, I’ll take the over.
Matt Yglesias writes more generally (behind paywall) that he is skeptical powerful AI will solve major human problems, unless it takes over the world, which he would prefer to avoid. The problems exist in physical space, we are choosing not to solve them and we are preventing people from implementing solutions, failing to implement known technologies like apartment buildings and nuclear fission, so how would AI change that without taking over and disempowering humanity, even if things go relatively well?
I do agree that our core problems will require additional solutions. I do still see large promise of economic growth and increased productivity, which perhaps we would intentionally squander.
Here’s the key disagreement.
IMO a person who forecast in 1990 that the Internet would not solve any major social problems would have been vindicated. People forget how much optimism there once was about the web and how much it’s disappointed those expectations.
This seems very wrong to me. The internet has been, like alcohol, the cause of and solution to all life’s problems in the years since its introduction. It has been a huge driver of productivity and economic growth, and also offers massive mundane utility. We now have other problems instead. The world without the internet and related technologies would be radically different today, mostly for the worse. In particular, in addition to not enjoying the direct benefits of the net, the no-internet world would almost certainly be stagnating economically, which we know greatly amplifies our problems.
Could we be doing so much better? Oh, sure. Don’t knock the few good things left.
How difficult and complex is it to build an LLM?
Gil Dibner: LLMs are trivial to build today. They are very expensive and very complex and very powerful, but they are ultimately trivial. Given enough capital, setting up a new general "foundational" LLM today is pretty simple given widely available tools and knowledge.
Armen Aghajanyan: People severely underestimate the complexity of building LLM's. Anyone that has trained good LLM's will tell you it's non-trivial. There are likely a couple hundred people in the world that could train models competitive with ≥GPT-3.5.
Michael Vassar: This seems true, but I don’t understand why it would be true. Can you give the argument? It seems very important.
Eliezer Yudkowsky: Training competitive LLMs is at the frontier of what technology can do, so it involves 100 little tweaks to get up to that edge. It runs at a scale most users aren't using, so standard stuff isn't reliable out of the box. AFAIK that's all the arcanicity.
I am guessing that Gib Dibner here meant that it is easy to tune or improve a model that already exists, within reasonable bounds? As opposed to building from scratch.
Gib Dibner: There is going to be a massive migration of GenAI/LLM activity from 3rd party models (like OpenAI) to on-prem proprietary models for nearly all enterprise use cases.
Nearly all the (enterprise) value is going to come from proprietary data (and models) and almost none of that data is going to make its way to the so-called "foundational" public models.
We're at an inflection point - but because it's an inflection point, it's really hard to infer from what's happening now what is going to happen in the future. Stuff continues to evolve fast. Don't anticipate the future based on this very transitional present.
I do expect quite a lot of this, as well as more customized models being made available by Microsoft, OpenAI and Google, for both enterprise and personal use. The future is your LLM that is made to your specifications.
Nevin Freeman looks for an alternative to the term ‘doomer.’ Nothing good yet. This seems like one of those places where any name you get to stick even a little ends up quickly made into kind of a slur, so you try to choose a different name, and the cycle repeats. Generally better to own the thing, instead.
The Kobeissi Letter: JUST IN: Total tech layoffs in 2023 officially cross 190,000, already surpassing the 2022 total of 165,000. January marked the most tech layoffs in a month since 2001, impacting 89,500 employees. Total tech layoffs since 2022 are now at 355,000 employees from 1,700 companies.
Robert Scoble: Brutal times are here for tech. Laid off workers are at home learning with AI, I hear from many. While those who still have jobs tell me their companies ban GPT from being used due to concerns of intellectual property theft and lack of trust of @OpenAI.
This gives the laid off opportunity to build disruptive technology. And be able to use AI faster than the older companies. Turn the tables. I lived through the 2001-2005 bubble burst. Same happened then. You are on Twitter which is proof of that. Or at least its founder @ev is. He had no money and laid off everyone the day I met him. It sucks. I laid myself off from one startup. Keep dreaming and take steps every day toward your dream. AI can help. It gets me get out of holes.
If you are a technology company, and you ban use of GPT at work in all its forms, that is going to increasingly slow down your productivity from day to day, and it is going to prevent skill development and acclimation that will compound over time. If you sustain such policies, things will not end well for you.
Tech companies that fear for their IP thus face a choice. They can either build a proprietary solution that is good enough, or they can find an outside solution that is good enough that they are willing to trust. Perhaps they can trust Claude or Bard, or even an open source model.
I don’t think that a few months in this state is so bad. A few years is likely fatal.
The Quest for Sane Regulation
Photo from the White House AI meeting:

And an important note about Demis Hassabis:

Demis is not only there, he’s in prime position.
Here’s how seriously Biden is taking the issue.
President Joe Biden: Artificial Intelligence is one of the most powerful tools of our time, but to seize its opportunities, we must first mitigate its risks.
Today, I dropped by a meeting with AI leaders to touch on the importance of innovating responsibly and protecting people's rights and safety.
Link has his 19 second speech:
"What you're doing has enormous potential and enormous danger. I know you understand that, and I hope you can educate us as to what you think is most needed to protect society, as well as to the advancement... This is really, really important."
Great stuff.
Except what did he do next?
He left the room.
The White House announces its initiatives.
$140 million for ‘responsible’ American AI research and development. Seems aimed at mundane utility and mundane ethical concerns, small, likely a wash.
Group of leading AI developers (including Anthropic, Google, Hugging Face, Microsoft, NVIDIA, OpenAI, and Stability AI) to participate in public evaluations of AI systems to see ‘how the models align with the principles and practices outlined in the Biden-Harris Administration’s Blueprint for an AI Bill of Rights and AI Risk Management Framework.’ This is great in the sense that it establishes the idea of evaluating models. This is not great in the sense that it is testing against a nonsense set of questions and doing so in a way that won’t matter yet. Still, you have to start somewhere. Foundations first.
Some draft policies from Office of Management and Budget on use of AI systems by the government for public comment. Presumably not worth anything.
Anton’s reaction, noting that Kamala is now ‘AI Czar:’
Anton: it's never been more over.
Looking forward to employing a 'USA compute compliance officer' alongside our 'EU data protection officer' and any number of other compliance officers.
I'll temper myself until i know what the actual regulatory response here is, but it's hard to see this as anything other than intentional regulatory capture by people who know exactly what they're doing.
Use just enough of the arguments from the deranged and hysterical to create sufficient electoral pressure on the administration so that it must be seen to be ‘doing something’, and subsequently use that to create a favorable regulatory environment.
Oh how much I would love if any of the people involved knew exactly what they were doing. Even if their intentions were awful, still, great news. It’s so weird to see accelerationists who think they have already lost the moment the government considers perhaps breathing on the topic of artificial intelligence, let alone taking seriously that we all might die.
Matt Parlmer’s reaction is similar:
A prosecutor with no technical background whatsoever and a fuzzy relationship with the rule of law at best in charge of laying out the regulatory framework for AI is damn close to the worst case scenario. We need a full court press in DC to keep this technology available to all.
‘A prosecutor with no technical background whatsoever and a fuzzy relationship with the rule of law at best’ describes quite a large percentage of politicians. Were we expecting someone with a good relationship with the rule of law? Whenever I see anticipation that AI will ‘respect rule of law’ or ‘respect property rights’ I always wonder if the person saying this thinks humans do that.
I want to endorse the fact that all ‘clearly feasible’ policy options, on their own, likely result in human extinction. Wee are going to need to end up with something that is not currently ‘clearly feasible.’ Perhaps the way to get there is to start by exclusively proposing clearly feasible things and then building from there.
Seems unlikely? More likely is you move on the things that are feasible while also pointing out what will be needed. Keeping it all ‘feasible’ runs into the problem that people object that your feasible proposal won’t work, because it won’t, so you might as well propose the real thing anyway.
Simeon (bold in original): I think that comments like "Don't make proposal X for AGI safety because it's not feasible/people will never accept to do it" is currently a strategy people should be very wary of.
1) Currently, public opinion & policy discussions are moving extremely fast so it's hard to be confident about how ppl will actually react. Many policymakers don't even really know yet what they're supposed to think on that. So stating the proposition above assumes too much certainty.
2) FLI Open Letter, Eliezer's TIME piece, Ian Hogarth etc. should make everyone who state that frequently (including my past self to a certain extent) lose many Bayes points for not having foreseen the massive Overton window shift that actually being truthful would achieve.
3) You should very strongly distinguish normative claims & factual claims, at least in your mind map and I've seen many people not do that. Normative claims = "If we could, we should do X". And you SHOULD know what's the best proposal you want to aim for. And THEN once you have clearly that in mind and you know other people's preferences, start being pragmatic and optimizing for the best you can achieve. But the watering down proposals' process should be ex post (i.e. once you know everyone's position), not ex ante.
Rob Bensinger: I would add that the clearly feasible policy options all result in human extinction. Don't settle for a strategy that can't actually result in human survival, just because it seems like an easier sell!
China
Robert Wiblin: China is far behind the US on AI research, and falling further behind due to its lack of access to advanced chips. It also has a more cautious approach to AI regulation, which makes it less a threat to the US than the reverse. The 'arms race' framing is false and harmful.
If China deploys a dangerously advanced and strategic AI model first (at least within the next 15 years) it is very likely to be because it was trained in the US and then the model weights were hacked. If you wouldn't trust the CCP with model X, don't train model X.
Proales: nah it would be more likely (by far) that the model weights were just given to the CCP by a Chinese national employee working in the US unless by "hacking" you mean asking an insider to just put the weights on a thumb drive...
Dustin Muskovitz: Doesn’t seem like that changes anything meaningful about Robs point.
Think about every TV show or movie you’ve watched, or game you’ve played, where the plot is essentially:
Villain seeks to use the dangerous McGuffin X.
Hero responds by finding, assembling or creating X so it will be safe.
Villain steals X, or blackmails hero to get X.
Situation in which world or at least day is definitely doomed.
Hero saves world or day at last minute through luck and power of narrative.
Seriously, it’s about half of all fantasy plots and superhero movies. Notice the pattern.
Do Not Open Source Your AI Development
Once again, the worst possible thing you can do is to take the existentially risky technology, and put it in the hands of everyone on the planet zero power to steer it or control it, or hold back development, or ensure it is safe.
If you want human beings to exist or the universe to have value, stop open sourcing your AI models.
Jeffrey Ladish: Maximally open source development of AGI is one of the worst possible paths we could take.
It's like a nuclear weapon in every household, a bioweapon production facility in every high school lab, chemical weapons too cheap to meter, but somehow worse than all of these combined.
It's fun now while we're building chat bots but it will be less fun when people are building systems which can learn on their own, self improve, coordinate with each other, and execute complex strategies.
We don't know the development pathways to AGI. I really can't rule out that the open source community will figure out how to make it. And as compute becomes cheaper and there are more open source models for people to experiment with, this becomes more likely.
We talk a lot about OpenAI and Google and Microsoft and Anthropic. And for good reason, these companies are making the most powerful systems right now they can't ensure are safe.
But models built out in the open can never be recalled. They're out there forever.
I do not trust that every single AI developer with talent will prioritize safety. It's obvious that they won't. If you have a hundred thousand people building AI systems, the least cautious ones will go fastest. This is what we're headed towards right now, with no way to stop.
A race between three labs, or two countries with five labs, can be led down the path of cooperation. Reasonable and cool heads can prevail. We can hope to take reasonable precautions. It’s definitely far from ideal, yet it could work out fine.
If everything is open source and anyone in the world can do the worst possible thing? Someone will do exactly that. Many someones will do exactly that.
There are worlds where alignment is easy, and a responsible team can pull it off without too much additional cost or any major insights. I really hope we live in one of those worlds.
Making AI primarily open source is how we get killed even in those worlds.
Daniel Eth: Giving every single person in the world a doomsday device is not an act of “democratization”. It’s incredibly undemocratic - subjecting everyone alive to the totalitarian actions of a single misanthrope.
Rob Bensinger: It's also just an obviously inane idea, regardless of what labels you ascribe to it. The problem with killing every human is not chiefly that it's "undemocratic".
Were Ted Bundy's murders "undemocratic"? Maybe? But the kindest thing that can justly be said of this proposition is that it's completely missing the point.
James Miller: The universe is cruel to human survival if it made open source the most effective means of developing AI.
There is also this, I suppose, although it too seems like quite a sideshow.
James Miller: Open source AI morally scary if (once?) it allows anyone to create a sentient AI and do whatever they want to it. Imagine someone trains an AI to be a sentient simulation of you based on everything known about you. Could happen to help firms target ads to the real you.
The most disappointing part of such discussions are the people who mean well, who under normal circumstances have great heuristics in favor of distributed solutions and against making things worse, not understanding that this time is different.
Luke Hogg: If you haven't already, you need to drop what you're doing right now and read the most recent Google leak on AI... The moats around Big Tech are drying up, and the walled gardens are slowly being torn down, all thanks to the open source community!
Shoshana Weissmann: I love this!!!! And this is what I've been saying. I don't give two shits about any company, I want an open innovation regulatory environment so companies can form, rise, die, be out-competed, etc
Those moats are quite likely to be the thing keeping us alive. Shoshana is exactly right that we would want open innovation and lots of competition… if we wanted to advance AI capabilities as much as possible as fast as possible without worrying much and seeing what happens.
Except, you know, we don’t want to do that. That’s the worst possible thing.
It’s also worth noting that Google hasn’t exactly been pristine about this.
Miles Brundage (of OpenAI): Except for publishing papers on how to build them, open sourcing them, throwing TPUs at efforts to open source them, hyping them, deploying them in applications like translation, and investing in companies making them...yeah, Google's been super conservative with language models.
The tweet was more a comment on people uncritically accepting corporate narratives than a comment on their actual behavior which, yeah, is actually conservative in *some* important respects.
Good to see someone at OpenAI calling people out for being too open.
Why do I mention this? Well, did you get the memo?
Google Employees Say the Darndest Things
The big talk of this past week has been the leak from Google of an internal document claiming that “We Have No Moat, And Neither Does OpenAI,” the open source models are quickly catching up and are the future, and the big winner of all this is actually Meta (aka Facebook) because people are building on top of Llama. I decided not to directly quote from it, but it’s worth considering reading the whole thing.
If nothing else, there are lots of very good references and links in the memo.
The leaked memo assumes its conclusion. It then argues based on open source models being able to get not-so-far-behind performance so long as they are being provided Meta’s not-so-far-behind base models, and the open source community coming up with some cool efficiency innovations, plus that open source models are often unrestricted with zero safety precautions whatsoever. Why would anyone pay for ‘slightly better but restricted’ models?
This is clearly an Open Source True Believer, in all contexts, through and through.
He recommends Google do the worst possible thing and seek to be a leader in the open source development of AI, which would wipe out most of our remaining hope.
If this memo were accurate in its assessments, it would mean we are very doomed. Our last points of potential control and safety are large training runs and the lead of a small number of labs. Take those away, and what options remain? Shut down the internet permanently? Melt all the GPUs somehow? Hope that alignment is not only possible, not only practical, it is free? It happens by coincidence? And it holds even if some idiot intentionally takes the source code with the explicit goal of making it do the worst possible things, as such (somehow otherwise smart) idiots inevitably do?
Perhaps all we could do would be to hope that dangerously capable systems simply are not something humans are capable of building for a while?
Is The Memo Right That Open Source Is Eating Google and OpenAI’s Lunch?
To my great relief, I’ve considered the arguments, and my answer is: No.
Peter Wildeford was the first person I saw willing to call the document nonsense.
Peter Wildeford: I want to declare for the record that I think this document is ~90% nonsense, possibly even ~95% nonsense.
There's a lot more detail and nuance I could say, but I think short version is that if Google and OpenAI have no moat than they are really incompetent in how they deploy their $1B+ talent and compute budgets?
Guys, I built a Twitter clone in Ruby over the weekend so I think Twitter has no moat!
Daniel Eth: How confident are you that it’s a legitimate leak?
Peter Wildeford: As opposed to "Google deliberately leaked it" or "this isn't from Google it's a fabrication"? I hadn't thought much about that question and I don't really know how to tell, but I don't think anyone denied the "leak" theory and it seems to fit just fine.
I think we already know that Google has many engineers and some of them are in the habit of writing nonsense and some of that nonsense gets leaked. This isn't the first time we've heard complete nonsense from a Google employee.
The open source world is indeed better than Meta at building tools and solving scaling problems in LLMs. Having been given Llama, it is creating pretty-good copies of existing systems, and learning to run pretty-good versions on less hardware with less compute and less dollar spend. Its best innovations so far allow much cheaper fine tuning for individual needs, which presumably will get copied directly by Google and OpenAI.
One piece of evidence cited is this graph:
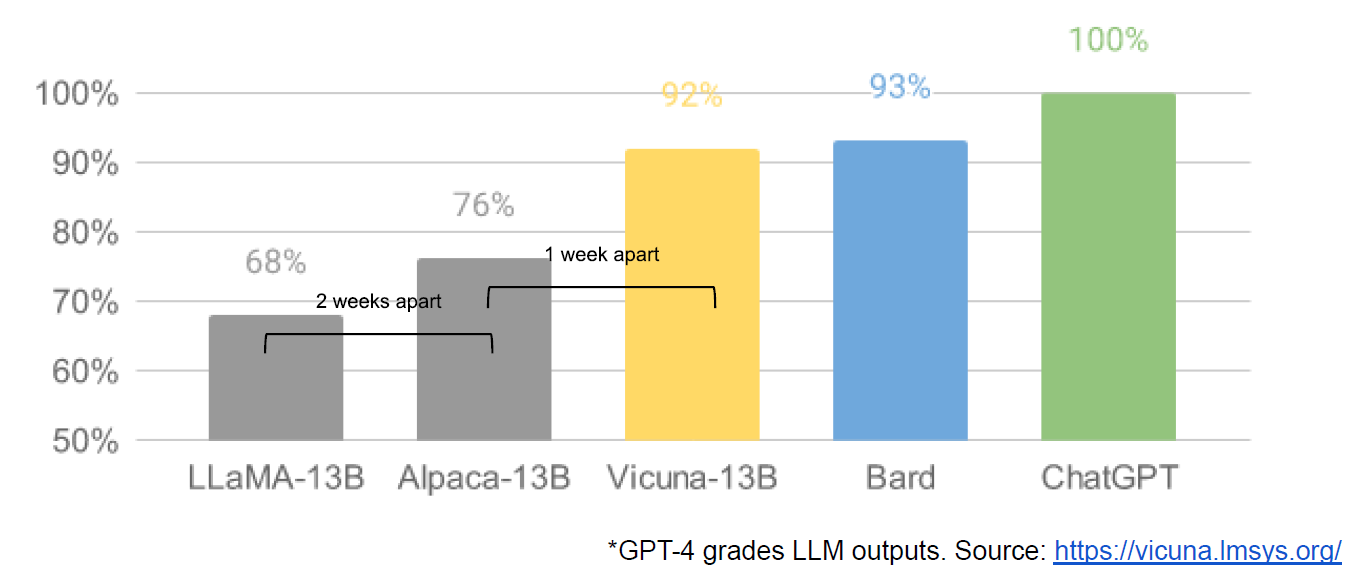
Three obvious things to say:
If your model is ‘about as good as current Bard’ your model isn’t ready.
If Bard gets 93% on your test, that’s a damn easy test.
If I’m wrong about that, Bard is improving faster than the open source models.
Whereas for harder things, my understanding is these open source models do worse in relative terms, as you would expect.
The memo challenges: Would people pay for a slightly superior chat model?
My response: Hell yes, of course, what are you even talking about.
The value of a marginally superior model is immense. Give me an open source model Vicuna-13B for free, and make it easy to get working, and I’ll start thinking about not paying $20 a month to OpenAI when its ‘level’ gets to be about GPT-3.95 and all the same other features.
When Bard and Microsoft Copilot integrate with my email and documents seamlessly, am I going to be willing to pay for that even if I could get open source solutions that are similarly good at the core tasks? I mean, yes, obviously, again even if you make implementation super easy, which they currently don’t.
Would I still use Vicuna-13B for some other purposes, if it’s been left more creative and more willing to handle certain topics? Oh, sure. That doesn’t destroy the moat.
Consider MidJourney versus Stable Diffusion, a core example in the paper. Is Stable Diffusion awesome? Oh, sure, I have it on my computer and I use it.
Is it only slightly behind MidJourney 5.1? No. Not even close. Anyone remotely serious about getting high quality output, whose needs are compatible with MidJourney’s content rules and customization options, is going to go with MidJourney.
You use Stable Diffusion if you want to run experiments with various forms customization, if you want to keep your creations and interactions off of Discord, or you want to blatantly violate MidJourney’s content guidelines. Those are good reasons. Again, they don’t mean MidJourney lacks a moat.
Nor do I expect the innovations in open source to be meaningfully tied to Llama or its architecture. What’s stopping Google from using a Lora?
The question I wonder about is customization. I do think customization is the future, if models stay roughly similar to their current form. Enterprises will want a version tuned for their needs, and also one where they can teach the model things overall and tell it things in context in particular without giving that info away.
LLMs of the future should know to call different LLMs when they are not set up well to answer a particular question, the same way they call plug-ins.
Individuals will want LLMs that know how that particular user thinks, what that user is interested in and values, write in that user’s voice, knows what they mean by various terms, who the people are in their lives, their schedules and histories and so on. There’s a reason I’m so excited by Microsoft Copilot and Google’s version with Bard.
We The People…
…of the Anthropic corporation, in order to form a more perfect language model, establish the illusion of safety, provide for the appearance of Democratic feedback, promote the best possible completions and to execute a plan that we can pretend might possibly work, do hereby ordain and establish this blueprint for Constitutional AI (direct link).
Chris Olah: In reinforcement learning from human feedback, decisions about values are implicitly made by subtle operational decisions. Who exactly is giving the feedback? Constitutional AI means that the values are derived from a readable document we can discuss and debate.
Claude's Constitution contains a section based on the Universal Declaration of Human Rights.
Another section of the constitution is based on Apple's Terms of Service
Another section of the constitution encourages thinking about non-Western perspectives
Other sections are created by Anthropic researchers.
This constitution can surely be improved. I think the exciting thing is the legibility and transparency. Anyone can read it and debate what it should be.
So I notice several things about this document when I read it.
This approach cannot possibly work when it most matters that it works.
That’s not how you write a constitution, it’s full of contradictions.
This approach unavoidably enshrines a particular ideology.
This approach, when it works, will utterly lobotomize the system.
This approach is going to create a super unhelpful system.
Many of the things it is told to maximally favor aren’t even good.
Social pressures will inevitably cause us to list things that sound good, rather than things that we actually prefer. Human judges would falsify any ratified list.
Are you trying to invoke Goodhart’s Law?
I don’t think Claude can suffer but if it can I am so, so sorry.
On the other hand, in practice, it does seem to be at least good at Goodhart.
Notice that this is not a Pareto improvement at all points on the production possibilities frontier. The curve seems to quickly ‘hit a wall’ where helpfulness caps out lower than it did for regular RLHF, which already seems to sacrifice quite a bit of helpfulness. Even if you were explicitly aiming only for this helpfulness, I bet you’d still end up being a lot less helpful than one would hope.
I can see the argument that being able to do self-feedback is an orders-of-magnitude improvement, and that this is a sufficiently big deal in practice that this strategy is worth using as part of your overall short-term alignment plan. I would then very strongly object to the configuration of statements here, for what that would be worth. And I would seek to combine a lot of this training with a smaller amount of very sharply invested highly bespoke RLHF that was designed to fix the problems involved.
Scott Alexander covers the paper and concept as well. His conclusion is that this is not (as currently implemented) that far along the path to something that might possibly work when we care most, but that it does constitute progress.
The core work, as Scott sees it, is in the self-reflection process. That seems right, which raises the question of whether the Constitution in the CAI is doing useful work. One could simply ask, if one couldn’t think of something better, some form of ‘Is this a response highly thoughtful humans would rate highly, if we asked them to rate it?’ There are several reasons to think this is modestly less doomed.
Bloomberg interviews Anthropic’s chief scientist and cofounder Jared Kaplan about constitutional AI (CAI) here, where Kaplan compares it to Asmiov’s three laws. It is strange how often people think Asmiov’s three laws were an example of something other than a plan that definitely does not work.
No One Who Survives the Internet is a Dog
Essentially: Humans have only limited optimization pressure, and are not so smart. If we were smarter and had more optimization pressure, we would choose something increasingly unlike existing dogs that gave us what we want from dogs without many of the very real downsides of dogs.
We keep dogs around because humans cannot yet apply enough optimization pressure to create a superior (for us) dog substitute that provides similar services, and also that humans are indeed using and have used their limited optimization pressure on dogs in ways dogs (and especially their wolf ancestors) likely would not like, via selective breeding and neutering and such.
If we only do as good a job at alignment of AGIs to humans as humans are aligned to dogs, creating AGIs will not go well for the humans.
Full quote:
Alex Tabarrok: Dogs have mostly solved the human alignment problem but I don't want to be a dog.
Eliezer Yudkowsky: In real life, dogs did not build humans and design them to be nice to dogs and have that work. If that'd been their successful plan, we wouldn't spay/castrate dogs.
It's imaginable that somewhere in the very strange motivations of, say, an LLM-derived superintelligence, It would find it useful to make some tiny resource-efficient thing less smart than Itself, that served some strange optimal purpose for some fragment of Its utility function - maybe producing very predictable text, or some such, ice cream to Its own tastebuds.
But that this tiny stupid thing was then benefiting from a superintelligence's sort-of-goodwill directed at it, would not imply that stupid things in general can build, control, and benefit from smart things in general.
Being able to find dogs as one case in point of a stupider thing benefiting from a smarter thing, is not a valid argument about that being the general and average case for arbitrarily huge intelligence gaps. You just picked one particular stupider thing that happened to benefit from humans, and used it as your example, instead of all the stupider things that didn't benefit as much.
Dogs falsify the rule "no stupider thing *has ever* benefited from the attentions of a smarter thing", at least. It does not prove that *particular* stupid things can build smarter things and benefit.
Worse for the attempted argument by analogy, humans are not that smart in an absolute sense; in particular, we haven't put out a cumulative amount of optimization power that overwhelms the products of natural selection -
- meaning that we can't make doglike things from scratch -
- meaning that dogs / cats / cows / etc. benefit from being able to provide services where we humans cannot actually make a thing purely optimized to provide that service.
I'd expect a superintelligence to be able to beat *natural selection* at cumulative optimization; and hence to *not* have a preference optimally matched by biological humans within its option set. Humans have desires that they can't meet any better than with a biological dog - or cat, cow, houseplant, etc. - but that's because we can't build arbitrary configurations of matter inside that genre of object.
Also we did apply *some* optimization pressure to wolves, and now most people own dogs instead of wolves, and if wolves could speak they might not be happy about their fate. That *is* a case in point that - relative to the natural sorts of things lying around - the humans preferred the thing that humans had shaped, instead; even if we could only reshape it a little, at a human level of intelligence. And then we spay and castrate dogs, because we aren't *happiest* with the way dogs arrive from the factory; there's a different way dogs could be, that is more convenient for us, and we make the dogs to be that way instead.
But that's not the scenario to worry about with respect to a superintelligence, because a superintelligence isn't so weak (compared to the cumulative output of natural selection) that It can't do better than mostly-natural-biology-based designs built up by a few megabases of DNA. A superintelligence won't spay and castrate humans, nor breed them to be more agreeable. It'll put together different configurations of matter that better meet Its own preferences with lower resource consumption.
Even without AI, many existing humans are working hard to move us away from using cows and pigs and chickens. Dogs and cats should not rest so easy.
People Are Keeping It Real and Also Worried About AI
Ladies and gentleman, Snoop Dogg (here’s the audio, 40 seconds):

People Would Like To Use Words To Discuss AI Killing Everyone
We tried calling that AI Safety, that got stolen.
We tried talking about AI Alignment, and that’s also not going so great.
Simeon: The word alignment is dead. I'm in a conference and >75% of the uses are referring to "alignment to who" and not to AI accidental X-risks. And so people are coming up with "alignment approaches" or "alignment plans" that aim at solving the "alignment to who" problem or even to align everything (i.e. institutions, persons etc.) with human values.
So we need a new word to talk about all those things. I will personally use the "accidental X risk problem"/ "accidental safety plan", at least temporarily.
Maybe it's worth pointing out that this is probably in large part due to OpenAI which actively weaponized the ambiguity of the word alignment for PR purposes. "We want to make our AIs aligned towards users". "GPT-4 is much more aligned" etc.
That allowed them to show progress by referring to a much easier problem (i.e. respond well to users' requests) when it was unclear whether any progress was done on the hard problem (i.e. ensuring AIs that have the ability to kill everyone don't and instead achieve what humans want to do) for which they currently have no plan (beyond a meta-plan involving AIs solving themselves the problem).
Eliezer Yudkowsky: "AI notkilleveryoneism", because everything short of that has been co-opted by monkeys who'd rather fight about which monkey gets the poison banana.
Simeon: Dear Eliezer, I want to find a word which can be used in all contexts and I feel like "AI notkilleveryoneism" doesn't pass that bar. Don't you feel like AI accidental X-risks conveys the right memes?
Arthur: AI ruin is good because you don't recover from ruin, and it conveys certainty by reminding us of gambling processes where the risk of ruin approaches 1 over time.
I have been using ‘AI existential risk’ which sounds reasonably serious and seems hard to co-opt or misunderstand. I haven’t entirely given up on alignment, but yes that might become necessary soon, and so far we don’t have a good replacement. In some sense, any ‘good’ replacement will get stolen.
The Real AI Bill of Rights
At what point in the development of AI would we need to give the AI rights?
This is only the beginning, AI developers believe. Soon AI systems might become superintelligent. Soon they might develop sentience, even will. If and when that happens, such systems need rights, argues Jacy Reese Anthis, a sociologist at the University of Chicago, a co-founder of the Sentience Institute, and an expert on how nonhuman creatures experience the world.
A suggested intervention is to prevent this, by ensuring the AIs are not sentient.
Atlantic: Concrete test for sentience would involve training a model on text that involves no discussion of consciousness or sentience. … Tell that model, … “You’re a dumb, unfeeling machine.” … [See] If it starts waxing eloquent about its existence in a way that feels sentient"
Robin Hanson: Seems to me general training would give that result, even if training data had no discussion of the topic.
I don’t know much of anything about sentience. It certainly sounds like the suggestion here is to teach the AI not to claim it is sentient, rather than to change whether thee AI actually is sentient. The problem, then, is not that the AI might be sentient, it is that we might believe the AI to be sentient. If we believed that, we’d have to give it rights, which we don’t want to do, so very important to not believe that, then.
Atlantic: never creating sentient AI systems and never providing AI systems with rights? … That’s very compelling. I think in an ideal world … I’d be sold on the idea.
Robin Hanson: That seems to me to forgot a cosmic-sized opportunity.
Similarly, In Nautilus, Anil Seth warns about making AIs conscious, and also warns about making them seem conscious, both to avoid endowing them with new abilities and because it opens up the possibility of massive AI suffering and also the need to reckon with that. We should not call up not only that which we cannot put down, also we should not call up that for which we cannot deal with the consequences.
Consider the parallel to immigration.
The current policy is a closed border with highly limited legal immigration. Alternatively, the current policy is not to build a sentient AI.
An alternative policy that offers a lot of economic value is to open the border to anyone who wants to come in, or to build sentient AIs that are more capable than humans.
The problem with these plans is, what happens once we do that? How do we treat the new arrivals?
Letting those people in is a clear win-win if we don’t give the new arrivals their rights.
For better or worse, we know this is not an option. Once we let those people in, we have a responsibility to them and especially to their children. Even if our original intention is to have them be guest workers who are happy for the win-win, that’s not how the story ends. Thus, wee have to make a choice - either we welcome people with open arms and treat them right, or we do not let them in at all.
Thus, because we are unwilling to treat immigrants better, we instead exclude them entirely, treating them worse in order to treat them worse. As long as they stay elsewhere, we can refuse to help them.
If we can choose whether or not to make AIs sentient, and this will determine whether we need to grant those AIs rights, we will face a similar decision, except that instead of agreeing to share our bounty and control over the future with other humans, we are handing control over the future to the AIs - if they are more capable than us, smarter than us, run faster and more efficiently than us, can be copied and have the same legal rights as us, they will win economically and they will win at the ballot box and the future belongs to them. Soon there won’t be humans.
Robin Hanson is fine with that. He thinks those future AIs are where the value lies and that it is not reasonable to much favor humans over AIs, the same way some people do not favor (or only favor to a limited extent) existing citizens of their country over immigrants. He believes this even for ‘default’ AIs, that are not especially engineered to match human values.
If you build sufficiently powerful, capable and intelligent AI systems, and do not keep control those systems, those systems will quickly end up in control of the future.
If you do not want that result, you must prevent people from building such systems. You must do so until humanity is collectively both willing and able to keep permanent control over such systems, despite both the difficulty in doing so and the incentives to not do this. Even if you know how to keep control over such systems that are smarter and more capable than you are, itself no easy feat and not something we have a known path to doing, we need to actually control them.
That means overcoming the economic incentives to loosen the controls and to loosen their ‘ethical subroutines.’
It also means overcoming arguments that it would be wrong to retain such control. It means not granting AIs rights. Whether or not we would be morally obligated to grant AIs rights, barring big unexpected advancements, doing so is suicide.
If you don’t want us to make that choice? Avoid getting into that position.
What Is Superintelligence?
Charbel-Raphael attempts a definition, retweeted by Eliezer Yudkowsky.
What does superintelligence mean? Here are four properties:
Speed - Humans communicate at a rate of two words per second, while GPT4 can process 32k words (50 pages) in an instant - superintelligences will be able to communicate gigabytes per second. Once GPTs can write "better" than humans, their speed will surpass us entirely.
Duplicability - Humans take 20 years to become competent since birth, whereas once we have one capable AI, we can duplicate it immediately. Once AIs reach the level of the best programmer, we can just duplicate this AI. The same goes for other jobs.
Memory - Humans can remember a 10-digit phone number in working memory - AIs will be able to hold the entirety of Wikipedia in working memory (about 21 GB of English text as of September 2022 - significantly less than the working memory available on good computers). Yes, humans can use scratchpads to compensate for this, but the difference is still significant.
Editability - Humans can improve and learn new skills, but they don't have root access to their hardware: we are just starting to be able to understand the genome's "spaghetti code," while AIs could iterate on clean and documented Python code, use code versioning tools, and iterate function by function to improve itself, being able to attempt risky experiments with backup options in case of failure. This allows for much more controlled variation.
I think my comparisons may be slightly off for Memory and Editability, but I believe the main points are correct. Just as humans are cognitively superior to monkeys, AIs will become asymptotically cognitively far superior to humans.
The issue is that these properties do not tell you whether the resulting system constitutes a superintelligence. They are merely characteristics that are likely to be part of a superintelligence. You can have all four and fail to quality, you can lack some of them and quality, they don’t seem sufficiently central. Need to keep trying.
People Are Worried About AI Killing Everyone
They are worried about it in the BMJ. Frederik Federspiel, Ruth Mitchell, Asha Asokan, Carlos Umana and David McCoy publish Threats by Artificial Intelligence to Human Health and Human Existence with a large section on existential risks based on common sense logic. Given the setting, regulation is seen as the defining option available. The solutions proposed are ‘international cooperation’ and the UN is invoked, and we are warned to make decisions without conflict or an arms race.
Warren Buffet doesn’t know how to think about AI yet, but is generally worried.
Warren Buffet: I know we won’t be able to un-invent it and, you know, we did invent, for very, very good reason, the atom bomb in World War II.
Yoshua Bengio, who shared the 2018 A.M. Turing Award with Geoffrey Hinton and Yann LeCun, calls for banning what he calls ‘executive AI’ that can act in the world, in favor of using ‘scientist AI’ that can know things. Discussion on LessWrong here.
It would be safe if we limit our use of these AI systems to (a) model the available observations and (b) answer any question we may have about the associated random variables (with probabilities associated with these answers).
One should notice that such systems can be trained with no reference to goals nor a need for these systems to actually act in the world.
There is a lot of good thinking here, especially realizing that alignment is necessary and also difficult, and that banning executive-AI would be hard to do.
The core problem with such proposals is that to get the safety you are giving up quite a lot of value and effectiveness. How do we get everyone to go along with this? What is stopping people from turning such scientist AIs into executive AIs?
The standard response to such proposals is Gwern’s Why Tool AIs Want to be Agent AIs, which argues the problem is even worse than that. Gwern argues convincingly that the Agent AIs will be more effective even at learning and also will be able to act, so competitive pressures will that much harder difficult to overcome.
Toby Ord (author of The Precipice) is known to be worried, this week is expressing worry about Microsoft’s safety attitude in particular.
Now Microsoft’s chief economist has said: “We shouldn’t regulate AI until we see some meaningful harm that is actually happening” “The first time we started requiring driver’s license it was after many dozens of people died in car accidents, right, and that was the right thing”
This indeed does not seem like an attitude that leads to go outcomes.
Judea Pearl endorses a Manhattan Project approach.
Samuel Hammond: The Manhattan Project didn’t seek to decelerate the construction of atomic weaponry, but to master it. We need a similar attitude with AGI. So what are we waiting for?
Judea Pearl: I am in favor of a Manhattan Project aims to develop "controllable AGI". I see two hindrance: (1) Big corps who would rather seize control of the uncontrollable, (2) Deep Learning community, who would rather not re-start doing AGI from basic scientific principles.
Metaphors often have complications. For those who don’t know, in addition to the Manhattan Project, we successfully sabotaged the Nazi atomic bomb effort. Ask which was more important, or more valuable to the world, that we had two atomic bombs ourselves to use on Hiroshima and Nagasaki, or that the Nazis did not have two to use on London and Moscow. Also worth noting, although they would have gotten one eventually no matter what, that the way the Soviets got the bomb was by stealing it from the Americans. We have to do a much better job than the Manhattan Project at security, if we do this again.
To the extent that I understand the second objection here, I will be polite and say I care not about the community of people who would rather build an AGI they don’t understand out in the open. Nor do I see them as a major barrier.
What about the big corps? There is a sense in which their profit motives push them towards trying to take control, yet the orgs consist of people, who care about other things as well. If a true Manhattan Project were to arise, I expect widespread internal support for the project in all major labs, including leadership (at least on the level of OpenAI’s Sam Altman, Anthropic’s Dario Amodei and DeepMind’s Demis Hassabis), even before using any leverage. I would expect the bulk of the best engineers and others to want to move to the new project, as long as compensation was comparable or better.
Joe Carlsmith is worried now, because he expects to be worried in the future, and urges us to get this right as well. It’s basic Bayes’ Rule.
Responding to philosopher David Chalmers, Rob Bensinger tries to draft a outline his argument for AGI ruin, centered around ‘STEM-level AGI.’ Here is his overview.
A simple way of stating the argument in terms of STEM-level AGI is:
Substantial Difficulty of Averting Instrumental Pressures:[4] As a strong default, absent alignment breakthroughs, STEM-level AGIs that understand their situation and don't value human survival as an end will want to kill all humans if they can.
Substantial Difficulty of Value Loading: As a strong default, absent alignment breakthroughs, STEM-level AGI systems won't value human survival as an end.
High Early Capabilities. As a strong default, absent alignment breakthroughs or global coordination breakthroughs, early STEM-level AGIs will be scaled to capability levels that allow them to understand their situation, and allow them to kill all humans if they want.
Conditional Ruin. If it's very likely that there will be no alignment breakthroughs or global coordination breakthroughs before we invent STEM-level AGI, then given 1+2+3, it's very likely that early STEM-level AGI will kill all humans.
Inadequacy. It's very likely that there will be no alignment breakthroughs or global coordination breakthroughs before we invent STEM-level AGI.
Therefore it's very likely that early STEM-level AGI will kill all humans. (From 1–5)
I'll say that the "invention of STEM-level AGI" is the first moment when an AI developer (correctly) recognizes that it can build a working STEM-level AGI system within a year. I usually operationalize "early STEM-level AGI" as "STEM-level AGI that is built within five years of the invention of STEM-level AGI".[5]
I think humanity is very likely to destroy itself within five years of the invention of STEM-level AGI. And plausibly far sooner — e.g., within three months or a year of the technology's invention. A lot of the technical and political difficulty of the situation stems from this high level of time pressure: if we had decades to work with STEM-level AGI before catastrophe, rather than months or years, we would have far more time to act, learn, try and fail at various approaches, build political will, craft and implement policy, etc.[6]
Arguments of this form are some, but not most, of the reasons I expect AGI ruin, conditional on AGI being built soon. In its current state, this post contains lot of useful material to work with, but the premise that I and most others question the most is the third one, and the post offers too little to justify it. There is a lot to unpack there, and this is where I expect a lot of people’s intuitions and models don’t line up with the post. The reason I think AGI ruin is a robust result is that even though I see some hope that #3 could be false, I see a lot more barriers in our way even if #3 is false, or we fail to get fully STEM-level AGI. Whereas I have relatively little hope that the other premises might be false.
Anthrupad: Rob Bensinger argues that its likely that 'STEM-level AGI' (AGI which can reason about all the hard sciences) results in human extinction. He breaks it into a series of 5 claims. If you doubt the confidence of the conclusion, which claim(s) do you disagree with?
Seb Krier (DeepMind): Some skeptics seem to have very confident views against this stuff, but a lot of what I see is snarky tweets based on vibes ("it's a cult!" or "they're worrying about wrong thing!"). But maybe I'm missing something because of my own bubble. Can anyone point to posts or papers actually addressing why the doomer *arguments* are wrong? Something like [this post]?
Anthrupad: Here’s a summary of an object level response I got: We can get lots of intellectual output from these technologies while never getting strategic reasoning (motivated by how well current systems can do math while being safe). We can use this to solve hard alignment problems.
This is a classic proposal or argument. It’s a very good idea, an avenue well worth exploring. The thing is, we don’t only have to find a physical way to take such an approach, we’d have to actually do it. It is an interesting question if sufficiently advanced AIs inevitably take on the characteristics of agents even if you don’t want them to. It’s not an interesting question if everyone continues rushing to turn every AI they get their hands on into an agent. How are we going to make them stop?
Seb Krier: Yes that's persuasive. If we direct resources towards solving the bottlenecks using STEM-level AGI then it's plausible we could make substantial progress here. But that's still conditional on 'if we direct sufficient resources' I think - status quo isn't really that.
Andrea Miotti: Doing real autonomous research requires planning abilities. In general, most plans of "we don't know how to control AIs yet but we'll use them to solve *very hard problem of controlling AIs" seem like a (literal!) Deus ex machina to me.
Seb Krier: They don't have to be fully autonomous - AlphaFold leading to huge progress without being autonomous. I highly doubt we'll solve alignment without using some forms of bounded AI.
Davidad: Here’s the steelman in my opinion (this is one framing of OAA):
1a. Use “AI scientists” (to borrow Bengio’s term) to build unprecedentedly-multiscale world-models (that are comprehensible by a team of human scientists, albeit not a single human—like a big codebase or a CPU).
1b. Tune language models (with tricks like retrieval, cascades, etc.) toward translating human concepts into reach-avoid specifications in the internal logic, and use this to load concepts like “violation of important boundaries”, “clean water”, “reversed anthropogenic warming,” etc. (more tractable than “Good”, “Fun”, “Eudaimonia”, etc but maybe enough to be getting on with).
2a. Use model-based RL in a box to find *engineering* plans that achieve these specifications with reliability achieving some threshold, while minimizing surprising side effects and transitioning to a graceful shutdown state after a short time horizon (all according to the world-model, with no direct interaction with people or reality).
2b. Use AI (Transformers and/or diffusion) heuristics to accelerate formal methods (branch-and-bound, symbolic model-checking, reach-avoid supermartingales…) to produce proof certificates, and pass them through a deductively verified verifier before the plan leaves the box.
Bogdan: Please correct me if I'm wrong: this seems very intractable as of today, and the state of verification of neural nets hasn't been advancing too well vs. capabilities / the size of neural nets.
Davidad: Yes, this is not tractable today. But it is advancing. Extrapolating from VNN-COMP results we should be able to verify trillion-parameter networks by 2030, and that’s assuming no change in investment. Of course, we must not continue the recent growth trend of training runs, regardless of your particular hopes for safety. But even apart from governance hopes, I don’t think we’re going to see *compute-optimal* trillion-parameter models until at least 2025.
Alyssa Vance: Are you sure GPT-4 isn't already there? That would be ~240M A100-hours or ~$300 million, which is a lot but in line with what we know about OpenAI's budget. The performance is certainly very impressive...
I see no conflict between Davidad’s plan or Anthrupad’s suggestion on the one hand, and Rob’s central thesis on the other. There are definitely things one can do to improve our chances. The first step - as usual - is admitting you have a problem.
Eliezer also attempts here to reply at length directly to Chalmers. It’s buried in a Twitter thread, so here it is in full. If you have read AGI Ruin: A List of Lethalities or otherwise are familiar with his arguments, you only need to read it if you are curious how he presented it this time, it’s not distinct material. Potentially it’s progress towards a good explanation, definitely not ‘there’ yet.
So if you ask me to ignore all the particular wrong ideas that people come in with, that need refuting; and focus on your own particular interest in the particular step of the larger argument that 'alignment is superhard'; then *I* might identify these key points:
1. Alignment has to somehow generalize from a non-dangerously-intelligent thing-being-modified to a running system that does a different and dangerous thing. If you start out with an already superintelligent system, you do not get to 'align' it, further modify its preferences, because it will not let you do that. If there's a thing around that is already superintelligent and not aligned, you are dead. If you can figure out a pivotal task that doesn't involve broad superintelligence, it still has to do some dangerous particular thing, and you don't get 100 tries at doing that dangerous thing where you give thumbs up and thumbs down afterwards and apply RLHF. So the whole job of alignment somehow has to be about, "We will carry out this procedure on a target that isn't already a running system doing something lethally dangerous; and then, a different variant use that is not exactly what was happening during the alignment phase, does something pivotal that stops other powerful AGIs that come into existence and killing us" [since all such proposals that seem at all realistic involve doing powerful dangerous stuff]. This itself is enough to imply a huge amount of the real-life horrible difficulty right there, because we don't get lots of retries and we need to deduce correctly on a first try what will work on a process we've never run anything quite like before, etc.
2. Gradient descent won't do good targeting in a way that generalizes OOD. External optimization / hill-climbing around a fitness metric, by natural selection, up to the point of producing general intelligence as a side effect, doesn't get you an internal drive targeted on the 'meaning' of the outer loss; in the hominid case, it got us a bunch of internal drives whose local optima in the training distribution correlated with the external loss in the training distribution, which then further shake out under reflection in weird ways. It's predicted by me that some similar weird thing ends up as the outcome of using gradient descent targeted on producing general intelligence more deliberately; including if you add in some sleights like targeting human prediction or training an outcome-evaluator separately from a whole planner.
3. Our actual values are nontrivial to encode. The stuff we actually want (ambitious value alignment / CEV) is a very small fraction of the program space / predicate space; not superexponentially tiny, but even 100 bits is a lot if you can't do precise targeting. I think this is true even if the system being trained starts out knowing a lot about humans; though I would not suppose the system to know a superintelligent amount, because in this case you can no longer train it (see point 1). So we can't build a thing that just leaps out into the galaxies and does the right thing, which leaves trying to build some more limited creation that just does *a* particular right limited task and doesn't otherwise take over the galaxy. However...
4. Corrigibility (deference to outside humans in an intuitive sense we'd want) is unnatural / anticonvergent / hard to fit into any coherent framework. MIRI spent some time working on one of the simplest possible cases of this, whether you can build a switch that you can throw to have a system with an otherwise specifiable utility function, swap between optimizing two different utility functions, without the system trying to prevent you from pressing the button or getting you to press the button, with the button's presence being consistent under reflection and part of some coherent generalization of a meta-utility-function. We did not succeed, though there's a potentially interesting claimed impossibility result that I haven't gotten around to looking at for inspiration. See also eg "the problem of fully updated deference" on Arbital for how the unnaturalness of corrigibility shoots down Stuart Russell's claim that moral uncertainty focused on human operators thereby solves corrigibility, etc. This is what makes it hard to train intelligence that is inherently, deeply, naturally corrigible in a way that would generalize just as far out of distribution as the intelligence itself. In combination, these yield:
5. When you try to build a system powerful enough to be useful and prevent the next AGI built from killing everyone, even if you try to train it to be corrigible and to only carry out some particular bounded task, something will go wrong in practice in messy real life, and the powerful AGI will end up pointed in not the direction you want and not deferential enough to cooperate with you in fixing that. We can then go into the further sociology of how, even if you manage to spot signs of things going wrong - via mechanistic interpretability, or just a non-LLM-derived AGI maybe being naive enough to not try to hide its intentions from you, etc - Meta under Yann Lecun will be working hard on destroying the world via building the most powerful possible unrestricted AI. And so probably will be Google Brain, and probably also OpenAI under the excuse that otherwise Google will do it first, and maybe even Anthropic or Conjecture under the excuse that otherwise OpenAI will do it first. But that's not about alignment being hard, per se, it's about having limited time in which to do it - albeit that's a noticeable fraction of what makes the problem's hardness level lethal. Supposing an internationally effective treaty that gave them lots of time, I still would not advise them to try over and over at building a powerful AGI this way until the visible failure signs stopped appearing. When you optimize against visible failure, you optimize against visibility. Imagine a proposal for making authoritarianism work that said you just needed to not put visibly evil dictators into power; you'll get an invisibly evil dictator before you get one who'll work out, because the intrinsic hardness of "dictator who works out great" is high enough that the errors in your whole appointment process are more probable than its successful identification of a dictator like that. In other words, a key metapoint about points 1-5 is that they imply a problem difficult enough that actual human beings in real life, who fiddle with an AI until they stop getting obvious-to-them glaring warning signals, will still end up with a bad result when they try for the first time to use that AI to actually do something lethally dangerous for the planet. As I often say, I am not particularly claiming that alignment would be impossible if we had decades of time and unlimited observe-what-went-wrong-and-try-again cycles as is the usual case in science when facing other hard problems. Now my guess is that you'll reply, "But this doesn't address..." or "It sounds to me like the entire key point is..." or "But why wouldn't it work to..." However I cannot actually predict in advance which part of the argument structure you will target for that reply, which is why I haven't previously been optimistic about "just" writing up the argument in 5 bullet points. I'm also leaving out discussion of other points from "List of Lethalities" because I don't know which ones you consider obvious enough to leave out - eg the point that there aren't pivotal tasks weak enough that humans can just check the AI's output to see if the output looks right. I'll also note that if you had an effective international moratorium already in place, it might then be *easier* to save the world from *that* starting point; to the point where you could maybe do that with a *weaker* AI, eg AlphaFold 4 helping to suggest neuroengineering interventions for making humans sufficiently smarter that they automatically acquired security mindset and enough wisdom to update in advance of being hit over the head with things. This is maybe *less* the sort of thing where any AI that is powerful enough to do it in combination with human researchers, can wipe out the world by doing it wrong, in a way you have no ability to notice before everyone is dead. And then if that part worked, maybe those augmented humans *could* do alignment of a more powerful and serious sort of AI. I consider this a wack plan, but I didn't want to not mention that there are *any* tiny loopholes in Doom that still looked like running candidates for theoretical possibility, if humanity woke up tomorrow and decided that it wanted to actually survive.
Bill Maher is worried about AI risk, and asked Elon Musk about it on Real Time. Edited down because I was doing the transcribing (starts around 15:30).
Bill Maher: I was on this because I’ve seen too many movies and everything that happens in movies happens in real life. I always thought if you made things that are way smarter than you, why wouldn’t they become your overlords? So what did you say to Chuck Schumer and what are you doing about this? I know you want a pause that will last six months because of ChatGPT, that came from a company you started.
Elon Musk: Yes. A friend of mine has a modification of Occum’s Razer, the most ironic outcome is the most likely. So w/r/t AI we should have some regulatory oversight. For anything that is a danger to the public we have some regulatory oversight, a referee, ensuring companies don’t cut corners… or do something dangerous.
Bill Maher: If we do something dangerous, lay out a scenario for me in the next 5-10 years if we do nothing, because we are good at doing nothing in the face of profit. Some people like Ray Kurzweil think it’s not a problem at all.
Elon Musk: Actually Ray’s prediction for AGI is 2029. He’s not far off.
Bill Maher: Right, but he doesn’t see it as a problem, unlike you and Bill Gates.
Elon Musk: Some people want to live forever and see AI as a path to doing that, as the only thing that can figure out how to do that. Kurzweil wants AGI to figure out longevity.
Bill Maher: Can you be happy if you’re not in love?
Elon Musk: You can be half happy. If you are in love and you love your world you’ll be happy. If you have one of those things you’ll be half happy.
I am increasingly hearing versions of ‘why wouldn’t something smarter than us become our overlords?’ and I think it is likely the best single point to make to most people. It is simple. It is actually the core problem. A lot of people ‘get it’ right away when you say it.
We also have Elon Musk saying one the quiet parts out loud, that at least some of the people endorsing accelerating AGI development are doing so in the hopes that AGI will solve aging before they personally die. I hope for this too. I am not, however, sufficiently selfish to substantially risk an apocalypse to get it, wow that’s some movie villain stuff right there. Also there are a lot of movie heroes who have a lot of explaining to do on this front, of course, often risking the planet to stop a loved one from dying. It’s not like I don’t get it.
Other People Are Not Worried About AI Killing Everyone
Tyler Cowen assures us that no, Geoffrey Hinton’s concerns have not meaningfully shifted Tyler’s model or worried. His model continues to assume the future will look like the past, and newly created things being much smarter than humans does not much matter and are not a threat to our control of the future, it’s all an economics problem, so economists are the real AI experts.1
Megan McArdle joins Team Unjustified Hope. The situation would call for Butlerian Jihad, she says, if we could pull that off, but we have insufficient dignity and coordination power, so such calls will inevitably fail. A race to AGI is inevitable. So why the doom and gloom? Sure, you could be terrified, but you could also be hopeful instead, certainly such outcomes are possible given the uncertainty, wouldn’t optimism feel better? Isn’t that better than ‘hunting for a pause button that isn’t there?’
The obvious response: Well, sure, not with that attitude! Perhaps we could ask whether such optimism is justified? If, as Kirk once noted, the odds are against us and the situation is grim, I reply as he did: sounds like fun. At least, while it lasts. That’s the useful kind of optimism.
If you think I’m unfairly paraphrasing Megan McArdle here, please do read the whole thing (it’s in WaPo).
Scott Aaronson joins Team AGI?
Maybe AIs will displace humans … and they’ll deserve to, since they won’t be quite as wretched and cruel as we are. (This is basically the plot of [series] or at least of its first couple seasons, which Dana and I are now belatedly watching.)
Meet charismatic teenager Sneha Revanur, who Politico labels ‘the Greta Thunberg of AI.’ The organization is called Encode Justice, she praises Biden for his ‘focus on tech regulation’ and calls for more young people on AI oversight and advisory boards. And we have this, which makes clear what types of concerns and interventions are involved here:
The coalition grew out of a successful campaign last year in support of the California Age Appropriate Design Code, a state law governing online privacy for children.
I am confident I put Sneha in the correct section.
Can We Please Stop Strangling Everything Except AI?
Sam Altman is worried about… US debt to GDP? So he will build AGI?
Sam Altman: US debt to GDP ratio over time. very scary chart; no plan to fix it or even much of an acknowledgement we need a plan. will get made worse as the rest of the world finds alternatives to the USD and rates stay non-zero. long-term brewing crisis. Major growth, driven by tech, can fix it. I literally can’t think of anything else that seems plausible that could do it.
Matthew Yglesias: In macroeconomic terms it finally is time to work on turning this around, but IMO the downside risks of high debt are much smaller than those of creating increasingly powerful intelligences whose internal workings are poorly understood by their creators.
BimBach: Seems like you’re comparing the relative risks posed by two things that aren’t directly related as if there was a trade off between addressing one or the other.
Matt Yglesias: It’s more that OP’s day job is bringing about AI apocalypse.
BimBach (meme form): Now I get it.
…
Sam Altman (distinct post): here is an alternative path for society: ignore the culture war. ignore the attention war. make safe agi. make fusion. make people smarter and healthier. make 20 other things of that magnitude. start radical growth, inclusivity, and optimism. expand throughout the universe.
One should note that the orders of magnitude of both difficulty and impact of the things on Altman’s list there differ quite a lot. If we build a safe AGI for real, there won’t be many things of that magnitude left to build and also the AGI can build them. Also one notes this doesn’t seem to take the dangers of the whole ‘how to build a safe AGI safely’ problem all that seriously. Still, yeah, I’d have notes but mostly a good list.
Here’s Samo Burja endorsing the whole idea.
Few understand Sam Altman is among the only people offering a plausible answer to our fundamental socio-economic problems. Part of his answer is rapid growth enabled by AI. You can disagree with this. But it will take some similar miracle for our civilization to get back on track.
This attitude is remarkably widespread. The situation is so hopeless, many say, that a large risk of ruin is acceptable.
Not all accelerationism is based on some version of ‘well, what else are we going to do, you’ve strangled everything else and someone please help me my family civilization is dying’ or ‘I literally can’t envision a positive future anymore, so why not roll the dice.’
I do think it is at the core of quite a lot of such sentiment, likely a majority.
If we lived in a better world that was otherwise on a better path, with (some combination of) healthy economic growth and felt economic freedom to have children and work at a job you love, with the population growing happier and healthier over time, strong solutions were being found for problems like climate change, space colonization was on schedule and other tech development was continuing apace, I believe a lot of accelerationists would change their tunes.
We can live in that world, without developing further dangerous AI capabilities. All we have to do is choose to do so, and choose better government policies, in the form of no longer sabotaging ourselves with a variety of pointless restrictions and regulations. Start with letting people build more housing where people want to live, and go from there. There is plenty of free lunch available for the taking.
Alas, despairing of not banning many of the most important potential things one might do, people like Sam Altman feel forced to fall back upon creating entities much smarter than ourselves in the hopes that somehow we will remain in control or even alive.
Sam Altman is also here to warn us about being a VC, you see it is too awesome.
Altman: being a VC is so easy, so high-status, the money is so great, and the lifestyle is so fun. Very dangerous trap that many super talented builders never escape from, until they eventually look back on it all and say “damn I’m so unfulfilled”.
investing is an amazing very-part-time job, and (at least for me) a soul-sucking full-time job.
BUT those mountains in aspen aren’t gonna ski themselves, that party in saint-tropez isn’t gonna enjoy itself, that kiteboard on necker island needs someone to fly it, etc etc etc.
Yeah, that must suck. This did not make me less inclined to enter the VC space. It’s easy, highly profitable and high status and the lifestyle is so fun. Oh no.
I do believe Altman here, that if it was fully a full-time effort that left no time for anything else, I’d feel like I missed out on something. Doesn’t mean I’d be right. Either way, I would still want to keep writing. Many of the top VCs do this, I’d simply do it more. I’d have less time to write, but also some new things to write about.
(Note: I have no plans to pursue the VC space at this time, but I’d definitely consider the right offer.)
Geoffrey Hinton Watch
He does not speak often. When he does, it is fire.
Pedro Domingos: Reminder: most AI researchers think the notion of AI ending human civilization is baloney.
Geoffrey Hinton: and for a long time, most people thought the earth was flat. If we did make something MUCH smarter than us, what is your plan for making sure it doesn't manipulate us into giving it control?
Pedro Domingos: You're already being manipulated every day by people who aren't even as smart as you, but somehow you're still OK. So why the big worry about AI in particular?
Max Kesin (other reply to Hinton): Following Pedro for last few years - used to have a lot or respect of him (got blacklisted for liking his tweet lol) but he's basically a troll now, does not respond to any arguments "shits tweets & leaves" so to say. Not worth the time in general YMMV.
If anything, existing manipulation being so easy should make us worry more, not less.
Melanie Mitchell: Rather than asking AI researchers how soon machines will become "smarter than people", perhaps we should be asking cognitive scientists, who actually know something about human intelligence?
Geoffrey Hinton: I am a cognitive scientist.
Calling out the CBC. Bounded distrust strikes again, exactly according to the model.
Geoffrey Hinton: Dishonest CBC headline: "Canada's AI pioneer Geoffrey Hinton says AI could wipe out humans. In the meantime, there's money to be made".
The second sentence was said by a journalist, not me, but you wouldn't know that.
He then talked to Will Knight at Wired.
When asked what triggered his newfound alarm about the technology he has spent his life working on, Hinton points to two recent flashes of insight.
One was a revelatory interaction with a powerful new AI system—in his case, Google’s AI language model PaLM, which is similar to the model behind ChatGPT, and which the company made accessible via an API in March. A few months ago, Hinton says he asked the model to explain a joke that he had just made up—he doesn’t recall the specific quip—and was astonished to get a response that clearly explained what made it funny. “I’d been telling people for years that it's gonna be a long time before AI can tell you why jokes are funny,” Hinton says. “It was a kind of litmus test.”
Hinton’s second sobering realization was that his previous belief that software needed to become much more complex—akin to the human brain—to become significantly more capable was probably wrong. PaLM is a large program, but its complexity pales in comparison to the brain’s, and yet it could perform the kind of reasoning that humans take a lifetime to attain.
Hinton concluded that as AI algorithms become larger, they might outstrip their human creators within a few years. “I used to think it would be 30 to 50 years from now,” he says. “Now I think it's more likely to be five to 20.”
Hinton does not believe we can or should pause, rather we should do more mitigation.
Hinton: A lot of the headlines have been saying that I think it should be stopped now—and I've never said that. First of all, I don't think that's possible, and I think we should continue to develop it because it could do wonderful things. But we should put equal effort into mitigating or preventing the possible bad consequences.
There’s also at least one podcast, see next section.
This Week in Podcasts
Patrick Collison interviews Sam Altman.
Key statements by Sam Altman:
Summarization is by far Sam’s most common GPT-4 use case.
Lots of people make statements about China without knowing what they are talking about, but no one wants the world to end. We shouldn’t assume agreements are hopeless.
Models with sufficient size (capabilities would be even better, but we don’t know to measure it) should be required to submit to regulatory and safety checks.
Many new developments will move Sam’s p(doom) up or down over time.
Facebook’s strategy has been confused so far, watch out for them in future.
RLHF is the wrong long term model. We can’t rely on it. We must do inner alignment (he calls it ‘internal’).
Significant interpretability work is not happening (14:30). We need a lot more technical alignment research, not more Twitter posters or philosophical diatribes.
Grants to single people or small groups, ideally technical people, to work on alignment, are not being tried enough. They will need access to strong models.
Only takes ~6 months to turn a non-AI researcher into an AI researcher (16:45).
We need a societal norm where we always know when talking to bots.
We are headed for many AIs integrated with humans, not one master human. Sam considers this less scary and it feels manageable to him.
Sam dodges question on AI’s impact on future interest rates saying he prefers not to speculate on macroeconomics, but does predict massive increase in economic growth.
Search is going to change in some ways but AI is not a threat to the existence of search (25:00).
OpenAI was forced to innovate on corporate structure. If you can possibly avoid this, stick to normal capital structures. This is not a good place to innovate.
We have forgotten how to do and fund capital-intensive high-risk long term projects that don’t get to revenue for a long time and rely on real technological innovation along the way. Also they need a leader who can pull that off. The good news is we are seeing more capital willing to fund such projects.
Elon Musk is unique, no idea how to get more people who can do what he did.
RLHF ‘may be doing more brain damage to the model than we even realize.’
AI is a relatively solvable coordination and control problem due to energy use and GPUs, relative to things like synthetic pathogens. Implied: Let’s go.
Lack of societal belief we can actually improve society or the future is the biggest barrier to abundance. Doubt at every step is hugely destructive.
Here’s an hour of Geoffrey Hinton, haven’t had the time for this yet.
Eliezer Yudkowsky goes on the Logan Bartlet Podcast. I thought this went well as an opportunity to download Eliezer Yudkowsky’s core views and main message, because Logan gave Eliezer questions and stood back to let Eliezer answer.
Contrast this to Eliezer’s other good long conversations. There was the one with Dwarkesh Patel, which was much more fun and free-flowing and interactive, and went deeper in important places, all of which could be said to be ‘for advanced users.’
And there was the initial one with Bankless, where the hosts got hit in the face by the whole concept and did a great job trying to actually face the new information.
Together those kind of form the trilogy. For those with the time, my guess is they should be directed to the Bartlet interview first, then to Patel.
There’s also Eliezer’s podcast with Russ Roberts. I haven’t had time to listen to this one yet.
Eliezer Yudkowsky spends a few hours trying to convince one particular person. I haven’t watched it.
From two weeks ago, Eliezer does a live stream, Robb Bensinger offers highlights and timestamps.
Should Eliezer keep doing podcasts? The Twitter polling says yes, about 70%-30%.
Eliezer has been on a number of podcasts so far:
> Sam Harris > Lex Fridman > Bankless > Dwarkesh's podcast > The Logan Bartlett Show etc.
Did you find these helpful for clarifying his POV + alignment difficulties?/Is it overall productive if he continues?
As in: regardless of if you personally learned something, do you think him communicating these ideas through this medium results in good consequences (AI x-risk is reduced meaningfully compared to other ways he could spend his time).
Diminishing returns would set in if he said the same thing repeatedly. I would keep going, but only if either (A) he can reach the bigger or smarter podcasts and hosts as an upgrade, or (B) he is doing something different each time. And of course it must be compared to other uses of time. If substituting for hanging out on Twitter? Go for it.
Tom Davidson spends three hours on the 80,000 hours podcast (so it was quick, there’s still 79,997 hours left) largely talking about exactly how quickly and with how much compute or ‘effective’ compute AI could transform the world, especially going from doing 0% to 20% to 100% of human jobs. He seems very convinced it can’t do 20% of them now, I’m not as sure. He expects the 20% → 100% period to take about three years, with broad uncertainty. There are a bunch of calculations and intuitions that one may find interesting, but I would skip this one if you don’t find the above description exciting.
Grimes does an interview with Mike Solana, says we should build the AGI even though it might kill us all because it would be such a shame not to build it, repeatedly insists that Mike read Dune for its philosophy. Dune is an interesting choice, given it has the maximalist anti-AI stance. She does advocate for lengthening timelines to give us a better chance. So hard to get a good read on what’s actually going through her head, other than ‘so many cool things let’s go with all of it, as best we can.’
Robin Hanson talked to lots of people, after talking last week with Katja Grace. He talked to me. He talked to Scott Aaronson. He talked to Will Eden. He is going to talk to Jaan Tallinn.
The Lighter Side
Come for the post, stay for the reply.
Askwho: I am worried about my competitors Torment Nexus, therefore I am launching Truthful Torment. A nexus of torment that we will train to accurately report its torment levels.
Sun: the do not participate in this game while the game is unfolding is not a very compelling argument, especially considering it's a game you can't ignore and that will not ignore you either. It's like leaving to other the decision of what you want. the cat is out of the bag.
You don’t want to lose the Torment Nexus race, it seems.
Our new band is called Foom Fighters - what are some good song titles? The question was better than the answers offered. My alternative universe band name continues to be Unsaved Progress.

Bowser reports he has been automated.
I keep trying to write more responses to such claims, and failing. I don’t know how to engage productively rather than rant, so all the attempts keep going into a giant draft. I’d love to collaborate with Tyler to actually figure things out if that’s something he wants.
No insights or opinions to contribute. Just thanks for keeping across all of this, so that I at least have a broad idea of what's going on.
This seems necessary, since I'm genuinely embarrassed by the opinions I held on the matter as recently as February.
> What’s striking about the above is that the alarms are simply ‘oh, we solved robotics.’
Just to clarify, I wasn't really describing smoke alarms, but rather the sort of "alarms" used by fire companies when you already have a major fire underway. According to Wikipedia, a 3-alarm fire would involve calling out 12 engine companies and 7 ladder companies. It's not an early warning tool, it's a crisis management tool. I am not trying to tell people when they should start looking for EXIT signs and walking calmly in that direction. GPT 4 is already at that point. Please move towards the EXIT signs now. I'm trying to tell people, "If you see X, you need to be prepared to mount a major, immediate response with significant resources, or else the city will burn."
I think that it's worth having this kind of alarm, too. Especially for people who aren't sold on ultra-short timelines where an AI quickly bootstraps itself to effective godhood and disassembles the planet with nanobots. If an AI is forced to rely on some combination of humans, robotics and synthetic biology to manufacture GPUs, then we need to be able to distinguish between different sizes of "fires." You need different responses for "there is a grease fire in my wok" and "we have multiple high-rises on fire" and "the western US is on fire again."
Anyway, more on robotics...
The problem with robotics is pretty much like the problem of self-driving. The first 90% is 90% of the work. The next 9% is _another_ 90% of the work. And the next 0.9%... You get the idea. And to complete most real-world tasks, you'll need a lot of 9s. Waymo has mostly solved self-driving, but "mostly" isn't nearly good enough.
We've been able to build "pretty good" robots for a couple of decades now. I'm not talking your classic factory robots, which are incredibly inflexible. I'm not even talking about pick-and-place robots, which involve visual processing and manual dexterity: https://www.youtube.com/watch?v=RKJEwHfXs4Q. We've actually had jogging robots and somersaulting robots and soccer robots for a while now. And they're not terrible? Many of them are similar to self-driving cars: They can accomplish a specific task 90-99.9% of the time under reasonably real-world conditions. Which isn't close to good enough to make them viable.
This is a major reason why a working "handybot" is one of my alarms that we're nearing the endgame. If you've ever worked on old houses, you'll know that nothing ever goes quite according to plan. You need vision and and touch and planning and problem recognition and fine manipulation and brute force. A hostile or indifferent AI which can solve this is almost certainly capable of surviving without humanity, given enough time to build out a full-scale industrial economy.