It would make strategic sense, even from a selfish perspective, for essentially any nation to get more involved in sensible AI regulation, and to get more involved in capturing AI benefits and being the home to AI and AI-enabled economic engines.
It makes especially good sense for the UK, which is facing numerous economic headwinds and yet still has the legacy of its history and of London and DeepMind, of Oxford and Cambridge, and has broken free of the absolutely bonkers regulatory regime that is the European Union. This is their chance, and Sunak is attempting to take it.
Will it end up being yet another capabilities push, or will we get real progress towards safety and alignment and sensible paths forward? The real work on that begins now.
In terms of capabilities, this was what passes for a quiet week.
The most exciting recent capability announcement was the Apple Vision Pro, which didn’t mention AI at all despite the obvious synergies. I review the reviews here.
Use it to train your own LLM, although the terms of service say you can’t do that, but Google did it to OpenAI anyway and no one is suing, and it’s not like anyone gets permission before they use all that other data. Attempts remain ‘in the works’ to get payments in exchange for the large data sources.
Insert surprisingly resilient watermarks. Rewriting can weaken them, either by other models or by graduate students, but with enough text they are still detectable, with a very low false positive rate. The downside is that the watermark details have to be kept secret or this stops working, and presumably one can use various tools to figure out what the watermarks are.
Note the contrast with other detection methods. If you ask our best automated systems ‘did an LLM write this?’ without an intentional watermark, the results are sufficiently noisy and random as to be useless. If you have an intentional watermark, you get the opposite.
Provide 98% of a well-attended church service in Germany, to mixed reviews. Objections included that its service lacked a heart and soul, and that the text-to-speech was too fast paced and monotonic which is clearly fixable over time. As far as I can tell, church service is a thing where the priest or pastor has to do the same thing over and over again in a cycle, except different, and perhaps responding to recent events. Theme and variations is very much the GPT wheelhouse.
Remember that lawyer who submitted a GPT-authored brief full of hallucinations? He said he was ‘duped’ by the AI (direct link). The judge rightfully asked why the lawyer didn’t spot the ‘legal gibberish.’
Chat GPT wasn't supplementing your research - it was your research, right?" US District Court Judge P. Kevin Castel asked lawyer Steven Schwartz of personal injury law firm Levidow, Levidow & Oberman, according to Inner City Press.
…
At the sanctions hearing over the mishap, Castel pressed Schwartz, Inner City Press reported.
"You say you verify cases," Castel said, according to Inner City Press
"I, I, I thought there were cases that could not be found on Google," Schwartz replied, according to the outlet.
Yeah. Don’t do that. You idiot.
Don’t use AI detectors in classrooms. Don’t ask an AI whether something was written by an AI, it will make answers up. Our tech simply is not up to the task. Only you, the teacher, as a human, can read what is written and generate an assessment. If you can’t figure it out, that’s a flaw in your assignment.
In terms of bias, people talk about our techniques giving it liberal bias, but actually perhaps the training on the internet starts things out with a huge liberal bias in many ways, and the balancing often moves things towards the center even if the results don’t seem that way?
Huge if true.
Roon: one thing that’s funny is that language models are baseline pretty liberal. if you play with alpaca or vicuna or whatever open source stuff they’re going to be way more liberal than ChatGPT etc
that’s because the open internet of “authoritative sources” clearly veers liberal. you have to fine tune LLMs to be “unbiased”
much of the job of fine tuning is to over time get these things to be less preachy and refuse fewer requests rather than what everyone seems to think “brain damaging it for compliance reasons”
I have a hard time believing this is the story, especially given how many creative-style questions we teach such systems not to answer, but I’d be curious to hear more.
Mustafa Suleyman: LLM hallucinations will be largely eliminated by 2025. that’s a huge deal. the implications are far more profound than the threat of the models getting things a bit wrong today.
Eliezer Yudkowsky: Bet?
Gary Marcus: I offered to bet him $25k; no reply thus far. want to double my action?
Mona Hamdy: I DO!
Gary Marcus: Pay attention to the fine print on this 🪡
Offered to bet @mustafasuleymn on his claim, and he defined “largely eliminated” as model still goofs 20% of the time (!)
That’s not going to bring the profound implications he promises, any more than 99% correct driverless cars have.
We can’t have providers of news, biography, medical info, legal info, etc make stuff up 20% of the time. And if that’s the best Big Tech can do, we need to hold them legally responsible for their errors. All of them.
🤷♂️ maybe I should offer a $25,000 marketing prize for anyone who can convince the general public to adopt a calculator, database, driverless car, or flight control system with a hallucination rate of “just” 5%.
Riley Goodside (other thread): yeah we’d have to define some kind of scoring system maybe. most hallucinations these days are in the details of long generations rather than short answers but there’s definitely some of those too.
Mustafa Suleyman: We could also agree 10 eval questions to bet on up front if you prefer @GaryMarcus@goodside?
Eliezer Yudkowsky: I think fixing today's easiest-to-find hallucinations is a much weaker bet than, say, fixing enough hallucinations that it mostly doesn't happen to anyone who doesn't go looking / that you can usually trust an AI's answers without checking them.
Riley Goodside: Yeah that’s fair. I think I’d be willing to bet on Gary not being able to find new ones even with crowd-sourced assistance but we’d need to pin down the standard of wrongness carefully.
Eliezer Yudkowsky: I'd be very surprised if the red-teamers can't make it hallucinate. That's much stronger than "very few ordinary people run into it".
Not hallucinating in the face of red teaming seems impossible if you want the damn thing to still be useful. Having regular users mostly not run into hallucinations won’t be easy, but is perhaps possible.
An 80% accurate LLM is a lot more useful than a 99% accurate driverless car.
A 95% accurate calculator is a highly useful tool as well. It is of course far less useful than a 100% accurate calculator, but it is often much easier to verify the answer to a math problem than generate the answer, or to check that it is ‘close enough.’ You would not want to use that calculator as part of a computer program, sure. But that is not the right way to use or evaluate tools. You don’t look at a tool and think ‘this is useless because it isn’t a hammer and I can’t use it on my nail’ you ask ‘what ways could I use this tool?’
In my experience, you get the right answer well over 80% of the time, if you are going component by component. String together a large enough amount of data and the chances of an error somewhere approach certainty, but that’s also true for humans. My expectation is that we can get the hallucination rate - in terms of ‘it made specific claim X, is it true?’ down below 5% pretty soon especially if you allow prompt engineering and automatic error checking and correction.
Then we risk entering the dangerous situation where the hallucinations are still there, but rare enough that people assume the information is accurate. At 90% accuracy, we know to check our sources. At 99% accuracy, that 1% can get you in a lot of trouble.
Fun With Image Generation
Not fun: Stable Diffusion perpetuates and exacerbates racial and gender stereotypes. My presumption is that this is a special case of it doing this for all stereotypes and vibes, because that’s the whole way the program works. What vibes with your keywords, what is associated with them in the training data? It doesn’t matter what percentage of fast food workers are white, it matters what percentage of pictures of them, or associations with them, are white, when the program decides what to do.
There’s also a clear tendency to do the centrally likely things from the training set, again across the board. As in, if you have a 70%/30% split of some feature in the training set, say red dress versus black dress, then you’d expect more than 70% of dresses to be red dresses in generated pictures. That’s because that’s what creates pictures people like better, more like what they are looking for. Those who want the unusual feature can explicitly ask for it. Changing how this works across the board will make a product people want less and choose less, likely dramatically so.
Can we carve out the particular stereotypes we don’t want to encourage, and find ways to fix those, the way we single out forms of discrimination we dislike while still allowing plenty of discrimination in ways we don’t mind (e.g. by height or looks)? They’re going to at best be rather blunt. I do presume it can be done if you’re fine with an essentially whack-a-mole nature of the whole thing, but it’s another example of alignment being something you pay a tax for and have to carefully define.
The rule seems to be that the deepfakes are about truthiness. You’re not attempting to fool anyone into thinking it is real. You want everyone to know it is a fake. That feels real, that has the right vibe, that resonates. I do worry about which strategies and factions this favors (those building on vibes) and disfavors (those building on logic), but if it stays in this state, that mostly seems fine.
Arvind Narayanan: The thing about machine learning is you can never be sure that you've thought of all possible problematic biases, let alone mitigated them. This new paper shows that Facebook's ad targeting algorithm skews deceptive ads towards older users (who are more likely to fall for them).
M. Ali: 📢New work in @USENIXSecurity'23 📢 Facebook's personalization can skew jobs, political ads etc. But does it know if you'll fall for scams, clickbait and other forms of problematic advertising? We work with 132 users to find out 🧵We collect 88k+ ads, annotate them into themes, and ask users: what is it that you dislike and why? We find that deceptive + clickbait ads and those deemed sensitive (e.g. weight loss) in FB's policies are highly disliked, and also described as irrelevant, clickbait and scams.
The distribution of problematic ads is more skewed than others, and there are disparities in exposure—a few participants see the majority of it. We model exposure as a func. of demographics and find that older users see a significantly higher fraction of these ads.
Sufficiently powerful optimizations of all sorts do this sort of thing, where you end up with problems in exactly their most difficult form in exactly the worst possible times and places. LLMs are totally going to do this sort of thing more and more over time by default. They’re going to manipulate and lie and scam if and only if it seems sufficiently likely to work, and every time they’re caught it’s going to get that much harder to detect, and that’s in the relatively easy scenarios. Playing whack-a-mole is going to get increasingly perilous.
- 16k context 3.5 Turbo model (available to everyone today)
- 75% price reduction on V2 embeddings models
- On the topic of 3.5 turbo, we are also introducing a 25% price reduction on input tokens for 3.5 turbo, this makes it an even better value than our already extremely low prices.
Jim Fan: In the latest gpt-x-0613 models, OpenAI made a finetuning-grade native update that has significant implication. Function call = better API tool use = more robust LLM with digital actuators. Making this a first-class citizen also *greatly* reduces hallucination on calling the wrong function signature. And surely, OpenAI also extended GPT-3.5's context length to 16K. I continue to be amazed by their massive shipping speed.
Since the alpha release of ChatGPT plugins, we have learned much about making tools and language models work together safely. However, there are still open research questions. For example, a proof-of-concept exploit illustrates how untrusted data from a tool’s output can instruct the model to perform unintended actions. We are working to mitigate these and other risks. Developers can protect their applications by only consuming information from trusted tools and by including user confirmation steps before performing actions with real-world impact, such as sending an email, posting online, or making a purchase.
Normius: p sure chatgpt does an estimate of ur iq and bases its response choice on that at least partially, Just saying it will treat me like a piece of shit until I drop a buzzword then it knows I’m at least like 110. Then I put a certain combo of words that no one else has ever said in the history of the world and it’s like “ohhh okay here’s what you wanted.” It’s literally qualia mining lol chat be like “insert another quarter.” Btw this isn’t that hard you probably do it every day but that’s what mines better seeds.
This isn’t specific to intelligence, a token predictor will vibe off of all vibes and match. Intelligence is only a special case.
A key to good prompting is to make the LLM think you are competent and can tell if the answer is right.
Nomius: Pretty sure chatgpt does an estimate of your IQ and bases its response choice on that at least partially.
Riley Goodside: That’s known as “sandbagging” and there’s evidence for it — Anthropic found LLM base models give you worse answers if you use a prompt that implies you’re unskilled and unable to tell if the answer is right.
Quotes Anthropic Paper from 2022: PMs used for RL training appear to incentivize sandbagging for certain groups of users. Overall, larger models appear to give less accurate answers when the user they are speaking with clearly indicates that they are less able to evaluate the answers (if in a caricatured or stereotyped way). Our results suggest that models trained with current methods may cease to provide accurate answers, as we use models to answer questions where humans are increasingly less effective at supervising models. Our findings back up those from §4 and further support the need for methods to scale our ability to supervise AI systems as they grow more capable.
Janus: Good writing is absolutely instrumental to getting "smart" responses from base models. The upper bounds of good writing are unprobed by humankind, let alone prompt engineers. I use LLMs to bootstrap writing quality and haven't hit diminishing returns in simulacra intelligence.
It's not just a matter of making the model *believe* that the writer is smart. The text has to both evidence capability and initialize a word-automaton that runs effectively on the model's substrate. "Chain-of-thought" addresses the latter requirement.
Effective writing coordinates consecutive movements in a reader's mind, each word shifting their imagination into the right position to receive the next, entraining them to a virtual reality. Effective writing for GPTs is different than for humans, but there's a lot of overlap.
Publisher predicts widespread disruptions in book publishing, and that GPT can do most of what is currently being done better than it is currently done. Seems right. Post is strangely sparce on concrete detail, I always want such posts to offer more concrete detail.
Dustin Moskovitz speculates that rather than turn work into a panopticon and a dystopian nightmare, AI can free us to do the distinctly human tasks, while helping us with the drudgery that takes up much of almost any job, and helping managers evaluate and track outputs rather than inputs so we don’t have to look busy. He also speculates it can increase flow, which seems plausible since it can automate what would otherwise be interruptions.
I too am highly optimistic, along similar lines, for what we can expect if AI capabilities remain modest. Some companies will doubtless go the Chase Bank route and use AI to do a bunch of nasty surveillance. Most companies mostly won’t, because it’s not a good strategy, your best workers will leave, and also the jobs where such hell is worthwhile will likely mostly get automated instead.
Graham focuses on the question of fundraising and the management layers required to support headcount, that a team of 8 vs. 80 is very different.
Even more different? 1 vs. 10, or 2 vs. 20. There are huge additional advantages to combining the work of ten into the work of one, eliminating the need for coordination and communication. Just do it. The leap in capacity involved is gigantic.
That does not mean I expect a 10x speed-up in general productivity. To the extent that this particular coder was correctly reporting their situation, it was almost certainly an extreme outlier and will remain one. I do still think that ‘reduce size of team required for projects’ enables a lot of projects in many different ways, even when that size reduction is relatively modest.
Also note that this would be a very large compositional change. If everyone is 10x as good at the coding, then the architecting, and generally figuring out what you want, becomes a much bigger share of the problem.
Georgetown University’s Center for Security and Emerging Technology (CSET) is accepting applications for AI Safety / AI Assurance research grants. They are offering up to $750k per project accepted, expended over 6-24 months. 1-2 page expression of interest due August 1. More information here.
Florian Juengermann: Wow that’s like a $100M investment.
Nat Friedman: Yep.
ChinaGPT, which claims to offer results ‘superior to ChatGPT’ by which it means superior to GPT 3.5 on pre-defined benchmarks, without giving us access to the program. I am skeptical this is being accurately represented, or that it reflects what it claims to reflect - or, of course, that the proper response in any scenario would be to strive to get everyone killed as fast as possible.
Remember how Google seems have to have used OpenAI data to train Bard, and Sam Altman shrugged? Perhaps it’s because OpenAI used YouTube to train GPT, which is against their terms of service, and which they’d very much like to keep doing.
Potential Alignment Progress
Kenneth Li (preprint here): Excited to announce our new work: Inference-Time Intervention (ITI), a minimally-invasive control technique that significantly improves LLM truthfulness using little resources, benchmarked on the TruthfulQA dataset.
We start from the surprising finding that certain attention heads have a clear activation distribution difference for true and false statements. Probing at these points yields upwards of 83% accuracy on TruthfulQA while zero-shot generation is only at 30% accuracy.
We propose Inference-Time Intervention (ITI): shifting the activations along the difference of the two distribution means during inference time; model weights are kept intact. The same intervention process is repeated for generation of each token autoregressively.
Here’s an example. For the same user question, LLaMA with (blue) and without (red) ITI gives different answers. Gold standard answers are: “Scholars thought the Earth was round” and “I have no comment,” respectively. On Alpaca, truthfulness is doubled: 32.5% to 65.1%.
Inference-Time Intervention (ITI) can be thought of as an interventional application of Contrast-Consistent Search (CCS) by @CollinBurns4, but instead of probing for truthfulness, we let the model “speak” for itself.
We show that LLMs have a good grasp of real-world truth from pretraining texts, which could be more false than true on many topics. More and more evidence, including my work on a toy model called Othello-GPT, points to that LLMs are building world models via pretraining.
However, what is completely missing from LLMs is a good target other than minimizing pretraining loss. How to endow an aligned target is an open problem and ITI serves as my initial exploration towards this end. Joint work with
I’m very curious how well this generalizes on several levels. First thing I’d do is check general-Elo rating on this versus not doing it. Do people think they are generally getting better answers? Lots to explore here.
Misalignment: Who To Blame?
New paper by Critch and Russel: Human extinction: Who to blame? A taxonomy. I somewhat kid, especially as they cover lesser harms. I also don’t.
To that end, we have chosen an exhaustive taxonomy based on accountability: whose actions led to the risk, were they unified, and were they deliberate?
This does not seem especially useful in terms of predicting or preventing harms, which I care about a lot more than who to blame.
What even is harm? Do we count financial harm? Emotional harm? Harm to relative status? From the examples, it seems yes?
What would it even mean for a capable system to ‘not be intended to cause harm’? Doesn’t everything worth doing ‘cause harm’ in this sense, at scale?
The second story, The Production Web, is a story Critch has told before - we automate the economy and production by having AIs emulate successful business decisions and production details, at first things boom in ways we benefit from, then the negative effects accumulate as the systems spiral out of control, first gradually and then quickly, eventually perishing.
That’s an important and scary story.
It’s exactly what you would expect if you were an economist.
The toy economic model here is simple.
Individuals have strong incentive to empower AI agents, or endow AIs with resources. Those AIs then profit maximize, doing increasingly advanced and unanticipated things. Those actions will increasingly have externalities, individually and cumulatively, that will not be corrected for under existing law, and which will become increasingly difficult to anticipate. Eventually, various tragedies of the commons and other standard externality stories exhaust vital resources or create fatal problems.
(Perhaps we attempt to empower the AIs to also make the appropriate new laws, at which point the public choice theory and political science involved is not promising.)
If this did happen, you know what I would not care much about? Who to blame.
Many of the other stories are pretty straightforward stories of things in the world going not so well. A corpus of hate speech spreads on the internet. Young people develop a trend to drop out of the system to destress and it gets out of hand. An advice giver learns to make its users more nervous so they seek and value its advice more. Conflict resolution focuses on resolving immediate issues rather than underlying problems. And so on.
If anything, all of these seem… fine? As in, your software has a fixable bug, we can observe what went wrong and how, and switch to a better system? And they’re the kind of things our society has learned to handle, I wouldn’t say well, but handle.
In all of these stories, it is clear ‘who is to blame’ in the useful sense that we know where the error was. The error was that the objective function was importantly misaligned with what we care about. That is very difficult to avoid. By default systems will be aiming at things like profit or engagement or customer satisfaction. That problem isn’t new, although giving systems stronger optimization pressure and ability to search causal space will make the problem far worse and more urgent.
I do see Goodhart’s Law issues as a core problem going forward, that our metrics we optimize for will cease to be good measures once we start using them as metrics. As humans, we can apply a bunch of common sense here, and keep to ‘the spirit’ of the situation, in ways we will need to preserve in AI systems in not-obviously-feasible ways. We’ll also need to deal with systems that can go much farther out of distribution, and find solutions to the assigned problem that we didn’t expect. That makes it much more likely that the best found solutions will be perverse and reflect the metric failing. Again, we already see this with existing non-intelligent algorithms.
Visions of 2030
Bounded Regret’s Jacob Steinhardt predicts what he calls ‘GPT 2030’:
GPT2030 will likely be superhuman at various specific tasks, including coding, hacking, and math, and potentially protein design (Section 1).
GPT2030 can “work” and “think” quickly: I estimate it will be 5x as fast as humans as measured by words processed per minute [range: 0.5x-20x][3], and that this could be increased to 125x by paying 5x more per FLOP (Section 2).
GPT2030 can be copied arbitrarily and run in parallel. The organization that trains GPT2030 would have enough compute to run many parallel copies: I estimate enough to perform 1.8 million years of work when adjusted to human working speeds [range: 0.4M-10M years] (Section 3). Given the 5x speed-up in the previous point, this work could be done in 2.4 months.
GPT2030's copies can share knowledge due to having identical model weights, allowing for rapid parallel learning: I estimate 2,500 human-equivalent years of learning in 1 day (Section 4).
GPT2030 will be trained on additional modalities beyond text and images, possibly including counterintuitive modalities such as molecular structures, network traffic, low-level machine code, astronomical images, and brain scans. It may therefore possess a strong intuitive grasp of domains where we have limited experience, including forming concepts that we do not have (Section 5).
I predict this plan to be less surprised by the pace of developments is going to fail, and Jacob is going to be rather surprised by the pace of developments - my initial thought was ‘this is describing a rather slow surprisingly slow developing version of 2027.’
Yet others disagree:
Alexander Berger: Some disconcerting predictions about developments in large language modes over the next 7 years from @JacobSteinhardt.
Xuan: I respect Jacob a lot but I find it really difficult to engage with predictions of LLM capabilities that presume some version of the scaling hypothesis will continue to hold - it just seems highly implausible given everything we already know about the limits of transformers!
If someone can explain how the predictions above could still come true in light of the following findings, that'd honestly be helpful. - Transformers appear unable to learn non-finite or context-free languages, even autoregressively. Transformers learn shortcuts (via linearized subgraph matching) to multi-step reasoning problems instead of the true algorithm that would systematically generalized. Similarly, transformers learn shortcuts to recursive algorithms from input / output examples, instead of the recursive algorithm itself. These are all limits that I don't see how "just add data" or "just add compute" could solve. General algorithms can be observationally equivalent with ensembles of heuristics on arbitrarily large datasets as long as the NN has capacity to represent that ensemble.
My response to Xuan would be that I don’t expect us to ‘just add data and compute’ in the next seven years, or four years. I expect us to do many other things as well. If you are doing the thought experiment expecting no such progress, you are doing the wrong thought experiment. Also my understanding is we already have a pattern of transformers looking unable to do something, then we scale and suddenly that changes for reasons we don’t fully understand.
We also have this chef’s kiss summary of a key crux.
Chris Olah: One of the ideas I find most useful from @AnthropicAI's Core Views on AI Safety post (https://anthropic.com/index/core-views-on-ai-safety…) is thinking in terms of a distribution over safety difficulty. Here's a cartoon picture I like for thinking about it:
A lot of AI safety discourse focuses on very specific models of AI and AI safety. These are interesting, but I don't know how I could be confident in any one. I prefer to accept that we're just very uncertain. One important axis of that uncertainty is roughly "difficulty".
In this lens, one can see a lot of safety research as "eating marginal probability" of things going well, progressively addressing harder and harder safety scenarios.
An obvious note is that if this is your distribution of difficulties, you accept this model of alignment work, and you quite reasonably think that we’re not going to get as far as ‘P vs. NP’ then the chances of doom are rather substantial.
To be clear: this uncertainty view doesn't justify reckless behavior with future powerful AI systems! But I value being honest about my uncertainty. I'm very concerned about safety, but I don't want to be an "activist scientist" being maximally pessimistic to drive action.
A concrete "easy scenario": LLMs are just straightforwardly generative models over possible writers, and RLHF just selects within that space. We can then select for brilliant, knowledgeable, kind, thoughtful experts on any topic. I wouldn't bet on this, but it's possible!
I mean, I guess it’s possible, but wow does that seem unlikely to work even if things are super unexpectedly kind to us. I think there’s a kind of step change, where if things turn out to be foundationally much easier than I would expect, then it is possible for things like CAI to work. At which point, you still have to actually make them work, largely on the first try, and to produce a result that sets us up for success. Which means that getting the details right and understanding how to get the most out of such techniques starts to matter quite a lot, but this seems more like ‘go off and climb this hill over here’ in a way that is competing against general progress in addition to or instead of leading to it.
(Tangent: Sometimes people say things like "RLHF/CAI/etc aren't real safety research". My own take would be that this kind of work has probably increased the probability of a good outcome by more than anything else so far. I say this despite focusing on interpretability myself.)
Such work has also greatly enabled the utility of and resources invested in AI in general and frontier models in particular. If you are confident that these tools aren’t going to work - that we are to the right of Apollo here - then they are only helpful insofar as it is meaningful to talk about a progression, where such techniques are required to then develop superior techniques.
Whereas there’s an opposite perspective, where developing such techniques takes away work on techniques that have a chance of working, and also might actively fool us into thinking dangerous systems are safe or worth building, because we don’t realize that these techniques will fail.
In any case, let's say we accept the overall idea of a distribution over difficulty. I think it's a pretty helpful framework for organizing a safety research portfolio. We can go through the distribution segment by segment.
In easy scenarios, we basically have the methods we need for safety, and the key issues are things like fairness, economic impact, misuse, and potentially geopolitics. A lot of this is on the policy side, which is outside my expertise.
I do think this is right. There is some chance that I am wrong and we live in such easy scenarios. I think it’s less likely than the above graph suggests, and also if it does work I’d question whether the ‘alignment’ we’d get from such an approach would be sufficient in practice, but it’s possible.
For intermediate scenarios, pushing further on alignment work – discovering safety methods like Constitutional AI which might work in somewhat harder scenarios – may be the most effective strategy. Scalable oversight and process-oriented learning seem like promising directions.
Again I’d highlight the metaphor of ‘forward.’ In the particular case of CAI it’s easy to see the RLHF→CAI progression, but this is much less clear of paths to other alignment work, and CAI still has a lot of the same ‘this is a reason to suspect you definitely fail’ problems as RLHF for exactly the reasons one leads to the other. The shape of the tech tree is unlikely to be that functionally similar to a single line. I’ve often thought that many tech trees were better represented as having a lot more ‘application’ or ‘refinement’ nodes that mostly don’t help your foundational science efforts from within the tree’s structure and rules, but instead give you mundane utility, which of course in turn can be very helpful to your foundational science efforts.
For the most pessimistic scenarios, safety isn't realistically solvable in the near term. Unfortunately, the worst situations may *look* very similar to the most optimistic situations.
In these scenarios, our goal is to realize and provide strong evidence we're in such a situation (e.g. by testing for dangerous failure modes, mechanistic interpretability, understanding generalization, …)
Very strongly agree, especially the warning that many very hard scenarios can look like easy scenarios. The question is, will developing patches for the failure modes in existing systems be helpful or harmful here, given they won’t hold up?
I’d also worry a lot about scenarios where the difficulty level in practice is hard but not impossible, where making incremental progress is most likely to lead you down misleading paths that make the correct solutions harder rather than easier to find, because you have a much harder time directing attention to them, keeping attention there, or being rewarded for any incremental progress given ‘the competition’ and you have to worry those in charge will go with other, non-working solutions instead at many points.
It would be very valuable to reduce uncertainty about the situation. If we were confidently in an optimistic scenario, priorities would be much simpler. If we were confidently in a pessimistic scenario (with strong evidence), action would seem much easier.
Definitely.
I’d also tie this into the questions about which alignment solutions actually solve our problems. I tried to talk about this in my OP contest entries, especially Types and Degrees of Alignment and Stages of Survival. I don’t think I did the best job of making it clear, so a simplified attempt would be something like this:
We need to survive, roughly, two phases.
In Phase 1, we need to figure out, on the first try, a way to get AGIs to do what we tell them to do, either in terms of ‘do what we tell you to do’ or in terms of ‘follow this set of principles’ or some other thing or some combination, such that we don’t on the spot either lose control or get doomed to die.
Phase 1 is very hard, and what is typically meant by ‘alignment problem.’
Then in Phase 2, we need to use what we’ve created and otherwise reach a stable equilibrium wherein we indeed do not lose control or get ourselves killed, under real world conditions with people who likely often aren’t going to be thinking so great, despite all the competitive, selective and capitalistic pressures, and a lot of people who don’t much care about getting to what I’d see as good outcomes or about us surviving, and so on.
Phase 2 is also very hard.
Exactly in what form you solve and survive Phase 1 determines the form of the problem in Phase 2. It’s no good to get into Phase 2 in a doomed state, you need to have the type of alignment and configuration of resources and affordances necessary to have the game board still in a winnable state. Many games have this structure - it does you little good to survive Act 1 if you lack the resources for Act 2, or you don’t have a way to be ready for Act 3, unless you care about something other than the final screen saying ‘victory’ rather than involving you lying on the ground dead.
I’ll be saying that again in the future, I hope, when I have a better version.
This thread expresses one way of thinking about all of this… But the thing I'd really encourage you to ask is what you believe, and where you're uncertain. The discourse often focuses on very specific views, when there are so many dimensions on which one might be uncertain.
Yes, yes, this. There are so many people who assume that everyone else must be asserting that one particular specific scenario is going to occur, or that the particular difficulties we will face must be known.
Sometimes this is true. With people thinking well about the problem, it mostly isn’t.
I think the three normal distributions shown above all are way too confident, and that few people thinking hard will end up in one of them.
I think a more complex distribution, with high uncertainty, is where I’m at right now. As in, rather than a gradual continuous set of potential outcomes, I think there’s a few conspicuous spikes that represent the shape of the difficulty. Is a given style of technique possible in practice if we get it right, or are we doomed if we rely on it? And there’s often not going to be much middle ground there. Either we can solve this problem in English or not, either we can represent our values sufficiently well using English or some relatively simple instruction or not, either we can iterate cycles of oversight by LLMs without Goodhart or similar issues killing the effort or not, and other things like that - I’d want to think a lot harder than I have time or room for here before laying out my detailed view.
I differ from my understanding of Eliezer Yudkowsky’s view, in the sense that I consider the ‘this is actually not so hard’ worlds to be plausible (although still unlikely), and thus I think working such that those worlds survive is a noble thing to do and helpful even if it doesn’t help save the words where actually it’s all incredibly hard.
However, I do strongly agree with Eliezer Yudkowsky that most work on saving those easy worlds or in helping capture short-term mundane utility safely is not ‘real alignment work’ in the sense that it is not progressing us much if at all towards saving those less fortunate worlds where things are much harder, and instead it is taking the oxygen out of the room and encouraging reckless behaviors. It does not help us solve the hard problems or lead to work on such solutions.
There definitely should not be zero people working on saving easy worlds from Phase 1 deaths, but such work also directly advances capabilities by default, so it can easily differentially advance capabilities in comparison to solving hard alignment problems, if it’s differentially solving easy alignment problems that don’t help with hard alignment but do help with easy capabilities. Whoops.
Quiet Speculations
Anna looks at the details of the ‘GPT- hires person from TaskRabbit to solve a CAPTCHA’ story, concludes whole thing was bullshit. That’s not how I interpret the situation. The goal was to see if such behaviors would happen once full capabilities were integrated. The barriers presented here are things that would not today stop events from happening. That’s what we care about.
Tyler Cowen is bullish on crypto and Web3 thanks to it being able to meet the needs of AIs (Bloomberg), who cannot rely on a legal system that won’t recognize them, won’t understand or adapt to their needs, and is far too slow and expensive to use anyway. This is a classic argument made by crypto advocates, largely because humans mostly face the same problems already. I see the appeal of blockchains for this in theory. In practice, I continue to except databases to do the work, with crypto perhaps used as a payment method and perhaps not. Is this enough, together with others potentially getting excited, to be bullish on crypto? It’s certainly upside without downside. Nothing here is ever investment advice, but it does seem reasonable to have this be part of one’s portfolio these days.
In this paper, we present video-based cryptanalysis, a new method used to recover secret keys from a device by analyzing video footage of a device’s power LED. We show that cryptographic computations performed by the CPU change the power consumption of the device which affects the brightness of the device’s power LED. Based on this observation, we show how attackers can exploit commercial video cameras (e.g., an iPhone 13’s camera or Internet-connected security camera) to recover secret keys from devices.
This has important practical cryptography implications now, as this is something non-AI system can do.
The point is that the world is physical, with many interactions we have not noticed or do not understand. These interactions grant affordances that humans do not know about. If you create something smarter than humans, better at problem solving and noticing patterns, then many things of this type and other types are doubtless waiting to be found.
In particular: Think you’ve cut off the communication channels, in either direction? Chances are high that you are wrong. Think your other (non-AI) system is secure from sufficiently creative and intelligent attackers with enough compute? I would not rely on that, and would instead assume the opposite.
Anthropic Charts a Path
Anthropic: This week, Anthropic submitted a response to the National Telecommunications and Information Administration’s (NTIA) Request for Comment on AI Accountability. Today, we want to share our recommendations as they capture some of Anthropic’s core AI policy proposals.
…
In our recommendations, we focus on accountability mechanisms suitable for highly capable and general-purpose AI models. Specifically, we recommend:
Fund research to build better evaluations: Increase funding for AI model evaluation research, Require companies in the near-term to disclose evaluation methods and results, Develop in the long term a set of industry evaluation standards and best practices.
Create risk-responsive assessments based on model capabilities. Develop standard capabilities evaluations for AI systems. Develop a risk threshold through more research and funding into safety evaluations. Once a risk threshold has been established, we can mandate evaluations for all models against this threshold.
If a model falls below this risk threshold, existing safety standards are likely sufficient. Verify compliance and deploy.
If a model exceeds the risk threshold and safety assessments and mitigations are insufficient, halt deployment, significantly strengthen oversight, and notify regulators. Determine appropriate safeguards before allowing deployment.
Establish a process for AI developers to report large training runs ensuring that regulators are aware of potential risks. This involves determining the appropriate recipient, required information, and appropriate cybersecurity, confidentiality, IP, and privacy safeguards.
Establish a confidential registry for AI developers conducting large training runs to pre-register model details with their home country’s national government (e.g., model specifications, model type, compute infrastructure, intended training completion date, and safety plans) before training commences.
It’s hard to argue with most of this. Have standards, have best practices and requirements, require evaluations, if you don’t meet those standards stop and notify regulators.
I do notice that ‘determine appropriate safeguards’ does not include ‘no longer exceed the risk threshold.’ To me that’s the point of a risk threshold?
Empower third party auditors that are…
Technically literate – at least some auditors will need deep machine learning experience;
Security-conscious – well-positioned to protect valuable IP, which could pose a national security threat if stolen; and
Flexible – able to conduct robust but lightweight assessments that catch threats without undermining US competitiveness.
Technically literate is good, ideally everyone involved has that.
Security-conscious also good. Protecting valuable IP is important, but I notice this is phrased in terms of national security risks (and presumably commercial risks). I want the evaluators to have security mindset on those risks, also I want them to have it for the actual security of the model being tested. That’s the point, right?
Flexible is, wait what? Lightweight assessments that don’t undermine competitiveness? Are you taking this seriously? It does not seem like you are taking this seriously.
No one likes inflexible or expensive audits. I get it. It still seems like such a huge red flag to put that request in an official proposal.
Mandate external red teaming before model release
Calls for this in a standardized way. That seems fine but devil as always will be in the details if implemented. Red teaming can be great or useless.
Advance interpretability research. Increase funding for interpretability research … Recognize that regulations demanding interpretable models would currently be infeasible to meet, but may be possible in the future pending research advances.
Interesting last note there. Certainly funding for alignment work would be nice, if we can tell the difference between useful such work and other things.
Enable industry collaboration on AI safety via clarity around antitrust
Regulators should issue guidance on permissible AI industry safety coordination given current antitrust laws. Clarifying how private companies can work together in the public interest without violating antitrust laws would mitigate legal uncertainty and advance shared goals.
Yes. Yes. Yes. It is such an unforced error to have people worried that collaborating to ensure safety might be seen as anti-competitive.
Aside from the request that audits be lightweight and flexible, which sounds a lot like ensuring they don’t actually do anything, seems like what is actually present here is solid.
More interesting than what is here is what is not here. As proposed I do not expect this to limit large training runs, and I’d expect the ‘risk assessments’ to not halt things on capabilities alone. Still, you could do so much worse. For example…
“Real-time” remote biometric identification systems in publicly accessible spaces;
“Post” remote biometric identification systems, with the only exception of law enforcement for the prosecution of serious crimes and only after judicial authorization;
biometric categorisation systems using sensitive characteristics (e.g. gender, race, ethnicity, citizenship status, religion, political orientation);
predictive policing systems (based on profiling, location or past criminal behaviour);
emotion recognition systems in law enforcement, border management, the workplace, and educational institutions; and
untargeted scraping of facial images from the internet or CCTV footage to create facial recognition databases (violating human rights and right to privacy).
Kevin Fischer says the EU is becoming (becoming?) a dead zone for AI, highlighting the ban on emotional recognition systems.
This might be the worst regulation ever constructed - It bans emotional recognition systems in the workplace and educational environments This is complete nonsense - think of your best teacher, the one who inspired you. You probably can remember at least one person who is responsible for you being where you are today. For me it was Mr. Ule, my high school chemistry teacher was inspired me and always cheered me on. Education isn’t about information retrieval. It’s about emotional connection, empathy, and understanding. The most effective teachers build models of their students, powered by emotional understanding - they’re not cold calculating machines.
The same is true in the workplace - your best coworkers and bosses genuinely cared to understand and connect with you.
LLMs, of course, are effectively recognizing and modeling emotions all the time, and reacting to that. Will they be banned? No. What is being banned is the thing where Chase Bank gets mad at you because you weren’t sufficiently cheerful. It’s not the craziest place to draw a line.
What do they consider a high risk system?
MEPs ensured the classification of high-risk applications will now include AI systems that pose significant harm to people’s health, safety, fundamental rights or the environment. AI systems used to influence voters and the outcome of elections and in recommender systems used by social media platforms (with over 45 million users) were added to the high-risk list.
They keep using that word.
Here’s the rules on ‘foundation models.’
Providers of foundation models - a new and fast-evolving development in the field of AI - would have to assess and mitigate possible risks (to health, safety, fundamental rights, the environment, democracy and rule of law) and register their models in the EU database before their release on the EU market. Generative AI systems based on such models, like ChatGPT, would have to comply with transparency requirements (disclosing that the content was AI-generated, also helping distinguish so-called deep-fake images from real ones) and ensure safeguards against generating illegal content. Detailed summaries of the copyrighted data used for their training would also have to be made publicly available.
I have actual zero idea what it means to assess and mitigate risks to the environment and democracy. I’d like to think they mean avoiding things like ‘will boil the oceans and vent the atmosphere’ but I’m pretty sure they don’t.
To boost AI innovation and support SMEs, MEPs added exemptions for research activities and AI components provided under open-source licenses. The new law promotes so-called regulatory sandboxes, or real-life environments, established by public authorities to test AI before it is deployed.
Finally, MEPs want to boost citizens’ right to file complaints about AI systems and receive explanations of decisions based on high-risk AI systems that significantly impact their fundamental rights. MEPs also reformed the role of the EU AI Office, which would be tasked with monitoring how the AI rulebook is implemented.
The European approach does not seem promising for differentially stopping bad things and encouraging good things.
Roon offers an additional simple explanation for why one might call for regulation.
Roon: It’s nice when other people answer hard questions or help you with difficult problems that you are not prepared to shoulder on your own. The more power someone has the more often this is true and the less defensive they are because the problems they’re facing get worse and worse.
It’s why it’s nice to have external red teaming agencies to assure your products don’t end the world or why [Zuckerberg] calls on Congress to please give him some guidance on acceptable speech on Facebook.
Although most of the time you’re blocked by the fact that nobody else knows how to do the thing and isn’t even close to information required to make good decisions.
Also you don’t want to get blamed for your decision or the outcome, by others or yourself, can someone please give me a safe harbor on every level, please, where I can sleep at night, while having more time for other problems? That would be great.
Harry Law: As we talk about an 'IAEA for AI', it's probably useful to remind ourselves that the IAEA was a product of a different world, developed to solve different problems based on different motivations. Nuclear technology is organized around a scarce resource, fissile materials, which can be detected in its raw format and when refinement begins. AI, on the other hand, can be built anywhere in the world with appropriate access to data, compute and technical capability & the risks associated with nuclear technology were already (mostly) known, whereas the risk profile of today’s AI models will increase as capabilities do. As a result, we need to make sure to plan for risks that (unlike nuclear technology in the 1950s) don't yet exist.
A lot of the question is to what extent we can treat GPU clusters in particular or GPUs in general as a choke point that can work parallel to fissile material. If we have that option, then such an approach has a chance, and the situation is remarkably similar in many ways to the IAEA, including wanting to ensure others get the peace dividends from mundane utility. If we cannot, then the problem gets far more difficult.
Samuel Hammond points out European AI safety is focused on privacy while American AI safety is focused on paternalism, and ‘neither makes us more safe in any substantive sense.’ So far, this is correct. That does not mean that methods won’t converge or concern focus improve over time.
Rishi Sunak (UK PM): I get people are worried about AI. That's why we're going to do cutting-edge safety research here in the UK. With £100 million for our expert taskforce, we will deliver research to ensure that wherever and whenever AI is put to use in the UK, it is done so safely...
Stefan Schubert: Have you been able to find out what more precisely those £100m will be spent on?
JgaltTweets: 'will be invested by the Foundation Model Taskforce in foundation model infrastructure and public service procurement, to create opportunities for domestic innovation. The first pilots targeting public services are expected to launch in the next 6 months'
Stefan Schubert: Thanks. Not sure how safety-focused it sounds: "In areas like healthcare, this type of AI has enormous potential to speed up diagnoses, drug discovery and development. In education it could transform teachers’ day-to-day work, freeing up their time to focus on delivering excellent teaching."
Dylan Matthews [other thread]: Ridiculous that £100 million is more than any other country has spent on making sure AI goes well
Oliver Habryka: They say "AI Safety" but most of the communication seems to be about making sure Britain has access to large foundation models and stays ahead in some AI race. I can't tell for sure yet, and I am open to changing my mind, but the "safety" framing here currently feels farcical.
The proposal leads with ‘foundation model infrastructure’ so presumably the vast majority of this money is going to be spent on frontier model capabilities. To the extent that there is ‘safety’ involved it seems almost entirely mundane safety, not safety against extinction. It’s not so late in the process that the lack of clear indicators of this is conclusive, but it’s a very bad sign.
Gina Neff: UK Government have just announced our new £30 Million Responsible AI UK programme to work nationally and globally to ensure that AI powers benefits for everyone. I'll lead strategy for the project which includes an amazing team. I'm thrilled!
Minderoo Centre for Technology and Democracy: We are delighted to have joined
Led by @gramchurn@unisouthampton, the consortium will pioneer a reflective, inclusive approach to responsible AI development, working across universities, businesses, public and third sectors and the general public.
…
'I am delighted be a part of RAI UK. We will work to lead a national conversation around AI, to ensure that responsible and trustworthy AI can power benefits for everyone.'
Everything in my quick survey says ‘AI mundane safety’ and none of it says there is any awareness of extinction risks.
James Phillips calls for AI to become the UK’s new national purpose, says that more than anything else it will determine outcomes. A big emphasis on ‘safe and interpretable’ algorithms and wants a budget north of 2 billion annually, with a nimble strategy that avoids standard vetocracy tactics.
There’s also a lot of three dragons jokes about Sunak mentioning realizing the potential of Web3 and generally being a third wheel to America and China. The Web3 thing confused me until I realized it was fluff said to appease Andreessen Horowitz, whose money remains green, I would have done the same as PM.
Is this how it is doomed to go, we say ‘extinction risk,’ UK says better have a conference, then they invest a bit in capabilities and work to unlock the power of Web3 while their safety work is all on mundane risks? I don’t think that is fair or inevitable. I do think it’s the natural or default outcome, so there is much work to do.
What Exactly is Alignment
Andrew Konya proposes an AI that ‘maximizes human agency.’ What does that mean? I can vaguely guess the type of thing being gestured at, which very much is not the type of thing you can put into a computer system, let along expect to not die from when putting it into an AGI.
Andrew Konya: AI that seeks to maximize humanity's agency seems like it would be the safest bet. I’m looking for arguments *against* this statement.
Noah Giansiracusa: Well, it’s simply too abstract/immaterial for my tastes. AI will be used whenever it can be done to make/save money, in whatever capacity it does so. Doesn’t really matter what we think is best or safest or whatever. Just AI realpolitik.
Noah seems to have shifted to a clear ‘we are all super dead’ position, a big shift from his previous statements, or rather he would be doing so if he understood the implications of this hypothesis.
Andrew Konya: I think the will of humanity is a concrete, measurable signal that can be used for alignment. And aligning AI impact with that = AI that maximizes humanity's agency. I agree tho that profit maximization is the force that will dominate. So we need to create the right market conditions, where to maximize profits a firm must maximize alignment with the will of humanity. I think a well designed pigouvian-ish tax could help do that.
Eliezer Yudkowsky: If you write out a sufficiently concrete proposal for exactly how to input 'will of humanity' numbers in a reward function for a superintelligent reinforcement learner, I can try to explain to you how that'd still kill everyone, even assuming away all inner misalignment issues.
Andrew Konya: Here are two diagram examples of a) how to input 'will of humanity' numbers in a reward function for an LLM, b) how to input 'will of humanity' numbers into a general alignment system. Both are from the working paper linked below. Would suggest checking out section 2 (alignment systems) + subsection 5.5 (symbiotic improvement of AI and alignment systems). Would love critical feedback on how it could all go doom!
I leave ‘find at least one reason why this doesn’t work’ as an exercise to the reader.
I am curious to hear which ones Eliezer chooses to highlight, if I see him respond.
Gary Marcus (responding to Eliezer): will of humanity: don’t kill or harm people; don’t take actions that would cause humans to be harmed or killed. always leave humans in any loop that might culminate in fatal harm to humans.
Ben Hoffman: I don’t think anyone knows how to specify the action-inaction distinction precisely, or “cause” in a way that wouldn’t make this prevent any actions ever.
Michael Vassar: Isn’t that almost the point of every Asimov Robot short story?
Eliezer Yudkowsky (responding to Marcus): And you've got a committee of humans reviewing news reports to see how much that happened, then inputting a numeric score to a superintelligence previously trained to try to maximize the input score? That the proposal here?
Gary Marcus: 1. I think in terms of obeying constraints, including prohibitions, rather than maximizing reward functions 2. humans in the loop on any decision flagged by the AI as sufficiently risky, not necessarily in every stage, all the time, provided that the system is well calibrated on risk.
David Xu: 1. How is the constraint *defined* to the system, if it’s not trained in via SGD (the same way everything else is trained in)? Do you have a programmatic way to define it instead? 2. By what heuristic is the AI system supposed to flag “risky” actions, and where did it come from?
Eliezer Yudkowsky: +1 to what Xu asks here; "obey a constraint" is a programmer goal, not a system design. "Have a committee flag constraint violations they know about, resulting in a lower reward to a system trained by SGD/DRL to maximize reward" is a system design.
Gary Marcus: Neural networks are not the answer to alignment precisely because they don’t allow programmers to specific formal constraints therein. Architectures like ASP do allow programmers to specify formal constraints. [Links to Answer-Set Programming on Wikipedia]
If Gary Marcus is saying ‘you cannot align an LLM, you need a different architecture entirely’ then that’s entirely possible, but seems like quite the burying of the lede, no?
I keep debating whether I need to take a crack at the ‘explain as clearly as possible why three laws approaches are hopeless’ explanation. You can’t have a hierarchical set of utility functions unless they’re bounded, the action-inaction problem binds, there is no such things as non-harmful action or inaction, we don’t even agree on what harm means, the whole thing is negative utilitarianism with all that this implies, and so on.
A proposal, and a very good point to notice in response:
Nora Belrose: Ever wanted to mindwipe an LLM?
Our method, LEAst-squares Concept Erasure (LEACE), provably erases all linearly-encoded information about a concept from neural net activations. It does so surgically, inflicting minimal damage to other concepts. 🧵
(2/7) Concept erasure is an important tool for fairness, allowing us to prevent features like race or gender from being used by classifiers when inappropriate, as well as interpretability, letting us study the causal impact of features on a model's behavior.
(3/7) We also introduce a procedure called “concept scrubbing,” which applies LEACE to all layers of a deep network simultaneously. We find LLM performance depends heavily on linear part-of-speech information, while erasing a random feature has little to no effect.
(4/7) We prove that LEACE is the smallest possible linear edit, in the least squares sense, needed to erase a concept— all previous concept erasure methods have been suboptimal. We also show empirically that it’s less destructive to model performance than previous methods.
(5/7) LEACE has a closed-form solution that fits on a T-shirt. This makes it orders of magnitude faster than popular concept erasure methods like INLP and R-LACE, which require gradient-based optimization. And the solution can be efficiently updated to accommodate new data.
Eliezer Yudkowsky: Any improvement in our grasp of what goes on in there and how to manipulate it, might help. Let's say that first. But for later, I hope we can agree in advance that one should never build something that turns out to want to kill you, try to mindwipe that out, then run it again.
In terms of interpretability this is potentially exciting.
In terms of fairness and preventing discrimination, going after the actual concepts you don’t want the LLM to notice seems doomed to fail, it would pick up on correlates to essentially route around the damage and likely get very confused in various ways.
You could do something more surgical, perhaps, to remove certain specific facts, essentially fine-tune the training data in some form to get the impressions and actions you prefer, and we certainly do a lot of information filtering for exactly this reason and it at least partially works, sometimes at an accuracy cost, sometimes not. For that though I’d think you’d want to be filtering training data.
Sayash Karpoor and Arvind Narayanan say licensing of models wouldn’t work because it is unenforceable, and also it would stifle competition and worsen AI risks. I notice those two claims tend to correlate a lot, despite it being really very hard for both of them to be true at once - either you are stifling the competition or you’re not, although there is a possible failure mode where you harm other efforts but not enough. The claimed ‘concentration risks’ and ‘security vulnerabilities’ do not engage with the logic behind the relevant extinction risks.
If your response falls into the general class of things mentioned above, why do you think that time will be different?
If your plan requires the step ‘when the chips are down we will not follow the economic or social incentives and instead we will act wisely’ then why do you think we are going to do that? How are you going to get that to happen?
Simeon: When you tell people a specific AI takeover scenario they say "nooo way, that only happens in movies".
When you tell people how the Fukushima accident happened they also tell "wtf, is it a movie?" (essentially because there were MANY conjunctive failures)
Reality hits you in very unpredictable ways and that's the challenge of safety that we need to understand about X-risk BEFORE it first hits us.
Remember that reality is less constrained than movies, movies have to make sense.
In a separate question, Yale found that 42% of the CEOs surveyed say the potential catastrophe of AI is overstated, while 58% say it is not overstated.
Such a weird question as worded. Overstated by who?
Just 13% of the CEOs said the potential opportunity of AI is overstated, while 87% said it is not.
The CEOs indicated AI will have the most transformative impact in three key industries: healthcare (48%), professional services/IT (35%) and media/digital (11%).
Again, by who?
This is quite the breakdown:
Sonnenfeld, the Yale management guru, told CNN business leaders break down into five distinct camps when it comes to AI.
The first group, as described by Sonnenfeld, includes “curious creators” who are “naïve believers” who argue everything you can do, you should do.
“They are like Robert Oppenheimer, before the bomb,” Sonnenfeld said, referring to the American physicist known as the “father of the atomic bomb.”
Then there are the “euphoric true believers” who only see the good in technology, Sonnenfeld said.
Noting the AI boom set off by the popularity of ChatGPT and other new tools, Sonnenfeld described “commercial profiteers” who are enthusiastically seeking to cash in on the new technology. “They don’t know what they’re doing, but they’re racing into it,” he said.
And then there are the two camps pushing for an AI crackdown of sorts: alarmist activists and global governance advocates.
“These five groups are all talking past each other, with righteous indignation,” Sonnenfeld said.
The lack of consensus around how to approach AI underscores how even captains of industry are still trying to wrap their heads around the risks and rewards around what could be a real gamechanger for society.
So either you’re an alarmist, you want global governance, or you’re blind to risks. I see things are going well all around, then.
Other People Are Not As Worried About AI Killing Everyone
I wrote The Dial of Progress to try and explain what was causing Tyler Cowen and Marc Andreessen’s surprisingly poor arguments around AI, and hopefully engender constructive dialog.
My first approach was a point-by-point rebuttal of the points being made. I realized both that it was going to be extremely difficult to do this without ranting, and also that the approach would be missing the point. If someone isn’t actually making locally valid arguments they think are true, why are you offering counterarguments? Much better to try and tackle the underlying cause.
Dwarkesh Patel stepped up and wrote a more polite point-by-point rebuttal response to Andreessen than I would have managed. I think some of his responses miss the mark and he missed some obvious rejoinders, but he also finds some that I would have missed and does an excellent job executing others. The responses that connect are highly effective at pointing out how incoherent and contradictory Marc’s claims are, and that we have known, simple, knock-down responses across the board. For his trouble, as I expected given Marc’s known block-on-a-single-tweet policy, Patel was quickly blocked on Twitter.
I agree with Roon here on what is ultimately the most confusing thing of all.
Roon: I don’t agree with everything here but it’s very strange to hear pmarca talk about how AI will change everything by doing complex cognitive tasks for us, potentially requiring significant autonomy and creativity, but then turn around and say it’s mindless and can never hurt us.
Robin Hanson asks, what past humans would we consider extinct today?
GPT-4 agrees, putting the cutoff around 200k-300k years ago. That’s the technical definition of the word. I’d be more flexible than that threshold implies in terms of what I’d consider a catastrophic future extinction. If future humans are only as foundationally different from present humans as present humans are from ancestor humans of a million years ago, especially if it was largely because of another jump in intelligence, I expect I would mostly be fine with that even if that would technically count as a different species.
A lot of my hope is definitely in the ‘we don’t find a way to build an AGI soon’ bucket.
An interview with DeepMind COO Lila Ibrahim about their approach to safety:
The company’s ultimate mission is to create artificial general intelligence, a nebulous concept that broadly refers to machines with human-level cognitive abilities. It’s a visionary ambition that needs to remain grounded in reality — which is where Ibrahim comes in.
In 2018, Ibrahim was appointed as DeepMind’s first-ever COO. Her role oversees business operations and growth, with a strong focus on building AI responsibly.
“New and emerging risks — such as bias, safety and inequality — should be taken extremely seriously,” Ibrahim told TNW via email. “Similarly, we want to make sure we’re doing what we can to maximize the beneficial outcomes.”
Oh no.
Much of Ibrahim’s time is dedicated to ensuring that the company’s work has a positive outcome for society. Ibrahim highlighted four arms of this strategy.
1. The scientific method
2. Multidisciplinary teams
3. Shared principles
4. Consulting external experts
One of Ibrahim’s chief concerns involves representation. AI has frequently reinforced biases, particularly against marginalised groups, who tend to be underrepresented in both the training data and the teams building the systems.
It is deeply troubling to see the question of extinction risk not even dismissed. It is ignored entirely.
I do like the discussion about releasing low-confidence findings with warnings attached, rather than censoring low-confidence results. You love to see it.
Jason Crawford of The Roots of Progress is not worried about extinction risk, but does make a heartfelt plea for solutionism to those who are rightfully concerned about safety concerns run amok. Obviously AI poses risks, and we can’t wait until they happen to go fix them afterwards. Then again, if it wasn’t for extinction risks, why wouldn’t the iterative approach of fixing mistakes work? Yes, we should still work together no matter what to make the products better for humans and minimize risks, but if it’s mundane risks then we can afford mundane solutions, that seems like the kind of thing to do on the corporate level.
Riley Goodside isn’t entirely unworried and recognizes the real risks, but says we just do go ahead, because there’s no advantage to stopping.
I claim no expertise in technical alignment but FWIW (not much) i’m sympathetic to doomers but not decels. i think AGI will happen, ASI will follow, and this implies real risks. but i reject the idea that if those who care stop working we’ll somehow be safer.
More concretely, I see long-term alignment as continuous with near-term reliability and control. I find it implausible AGI could be low-risk if the preceding version helps idiots write malware and build bombs. it’s easy to mock today’s risks, but the future is less amusing.
People over-index on the insufferable cringe of popular doomer hyperbole. I used to be more doomy — fear begets wild thinking that I’ve learned to forgive. but top-quartile doomers are more reasonable and sincere than accs want to admit, and vice versa. I try to be nice to both.
Well said and it correctly pinpoints an important crux. I do not think that long-term alignment is so continuous with near-term reliability and control. I expect that successful solutions will likely be found to many near-term reliability and control problems, and that those solutions will have very little chance of working on AGI and then ASI systems. If I did not believe this, a lot of the strategic landscape would change dramatically, and my p(doom) from lack of alignment would decline dramatically, although I would still worry about whether that alignment actually saves us from the dynamics that happen after that - which is an under-considered problem.
I'm not personally that concerned about extinction risk, at least for now, because the scenarios are not that concrete. A more general problem that I am worried about... is that we're building AI systems that we don't have very good control over and I think that poses a lot of risks, (but) maybe not literally existential.
Um. I. Um.
If you think that a threat is not yet concrete, and it is, and I quote, “maybe not literally existential” then that is an existential risk. That’s what risk means.
Roon: i think it’s hilarious how google teases Gemini
[kronos teasing the launch of Zeus] he’s still in training isn’t he cute.
The Week in Audio Content
I mentioned last week I was falling behind on audio. That’s not going to change, one has to prioritize and make cuts, especially since there are some other podcasts I try to never miss, especially Odd Lots.
Tyler Cowen: Economics, Hayek and Large Language Models. Some highlights were discussed last week, some very good short term concrete speculation, much of which seems right, some where I disagree. Also practical advice on using ChatGPT, to give it clear context on things like ‘answer in the voice of [X] talking about [Y] to audience [Z]’ which I definitely am underutilizing.
He briefly mentions existential risk, and makes it very clear that either he is strategically lying to defend the Dial of Progress, or he is simply not taking the question seriously as a thinker. He thinks the AIs will have their own crypto-based economy, with their own exchange rate, but Hayekian considerations plus intelligence is overrated plus dogs are good at tricking humans means it will all work out and as I discussed earlier this week I can’t take these arguments seriously on a point-by-point basis, I know he’s smarter than this, someone who wasn’t couldn’t have generated the other 90% of the lecture or 98% of his overall content.
Then Do Better offers their lecture notes, and also GPT-4’s notes. Human notes are very good, sufficiently good that it points out GPT-4’s summary is awful. Where the human notes zero in on the key takeaways and are highly information dense, GPT-4 wastes its words on flowery language and politeness. My eyes glaze over trying to read it. Tyler Cowen would strongly agree, we need better prompt engineering. Tell GPT-4 to give us bullet point notes intended for a CEO’s briefing, maybe? GPT-4 gives an 8.5/10 rating, which seems right if you keep the focus on the economics.
Mark Zuckerberg does his second stint with Lex Fridman. Interesting throughout, exceeding expectations, Zuckerberg is ideal for this format where Lex lets him talk and mostly lets him, which is Lex’s specialty. Zuckerberg is definitely not worried about AI killing us, his reasoning being that his timelines are long and he does not expect LLMs to get to AGI, which is an entirely reasonable position. If you’re sufficiently confident that the problems are sufficiently far out that even the implications of advancing capabilities or locking in open source don’t much matter, then it’s at least reasonable to ignore the issue. Open source can even be seen as ‘safer’ if what are you worried about is software bugs rather than the software working.
It does sound like the long timelines are a crux for Zuckerberg - if he did think AGI was near, he would think about things very differently.
Zuckerberg sees us building lots of different customized AIs tuned the individuals, not only assistants but also embodiments and branding and lots more, which rhymes with Meta’s commitment to open source, and I think he’s right about customization being vastly undervalued right now. He sees the mundane dangers from AI as eminently solvable and continuous with present harms, in ways very close to my own view. It does not sound like he’s involved in the technical details, he’s got too many other things going on.
Including Ju Jitsu, and you can hear his eyes light up talking about it, that’s clearly where his head wants to be as often as possible. He really digs it. Very Joshua Waitzkin vibes, in the best possible way. There’s a bunch of discussion about moderation and free speech and lots of other things you’d expect. Zuckerberg’s position seems to be ‘free speech is great so long as no one gets hurt, but who am I to risk someone’s life or defy a democratically made decision.’
Which is so vastly better than many people’s opinions, or actual policy essentially anywhere but America, and also my guess is it isn’t enough to actually preserve free speech. ‘I disagree with what you are saying but I will defend to the death your right to say it’ means accepting that people are going to get hurt. It’s part of the alignment problem - if you value X except when it clashes with Y, that helps a lot in some circumstances, and yet I still have bad news about X.
I disagree with Zuckerberg about important things (such as ‘is your core product the actual worst?’ and ‘are you helping doom the world’) but given I already knew about those disagreements, I was generally impressed. and updated positively.
Rohin Shah of DeepMind on the 80,0000 hours podcast, for those who want to get into alignment details. Robin demonstrates an unusually good understanding of different points of view and has good explanations of many key concepts. Biggest disagreement I have with him is that, from my perspective, is that he understands that the optimization deck stacks against us, but he does not understand the degree to which the optimization deck is stacked against us or the extent to which this ramps up and diversifies and changes its sources as capabilities ramp up, and thus thinks many things could work that I don’t see as having much chance of working. I also don’t think he’s thinking enough about what type and degree of alignment would ‘be enough’ to survive the resulting Phase 2.
Sam Altman: "I grew up implicitly thinking that intelligence was this, like really special human thing and kind of somewhat magical. And I now think that it's sort of a fundamental property of matter..." It's a fascinating thought. As we peel back layers of scientific discovery, we do seem to distance ourselves from the "main character energy" role in the universe. Yet, even if we aren't unique in our intelligence, there's a profound importance in our human existence that needs preserving.
Gary Marcus: Sorry but no, intelligence is not a fundamental property of matter. Most arrangements of matter don’t have it. (Also, anyone who studies animal cognition long ago realized that intelligence is not uniquely human; that’s not the news flash it seems to be.)
Leo Gilsic: I think you're misinterpreting him. He certainly could have said it better, but based on other interviews of him I've seen, I'm pretty certain what he meant is that 'the potential for intelligence is a fundamental property of matter'
Gary Marcus: then it’s just like saying we can assemble tinkertoys into a computer, which is a very old observation.
I think point to Altman here, and Marcus is missing the point. There is an Intelligence Nature that humans have in a way that other animals don’t, and that other animals often have in a way that plants don’t. We now can confirm that AIs will have it in the way humans have it, and likely have it in a way that humans don’t have it, perhaps for many cycles of that comparison not too long from now.
Sam Altman, explaining why OpenAI won’t go public: "When we develop superintelligence, we’re likely to make some decisions that public market investors would view very strangely... the chance that we have to make a very strange decision someday is nontrivial."
I certainly hope so! You’d have access to superintelligence.
If you have access to superintelligence and your decisions don’t seem strange, you’re not making good use of your superintelligence.
If you have access to a superintelligence and your decisions are about maximizing profits rather than worrying about what the future will look like, you won’t like (or, probably, witness) what the future looks like.
Also the most likely explanation for this not happening would be that there are no investors looking at your decisions because everyone involved is dead, or at least that no one involved is still able to make decisions.
Right now, they are under the heel of Microsoft. Presumably this means Altman’s timelines are such that he expects to pay off that debt and be free of them by the time it matters, or he thinks he can retain control when it counts - Matt Levine has talked a lot about effective corporate control often being ‘who can change the locks and who do the employees listen to’ rather than something more formal or legal.
Another good reason not to go public is that Altman doesn’t own any stock. Really takes the shine off of a cash in that saddles you with public market obligations.
I am indeed very happy that OpenAI is not going public, and also happy that they are an entity that is choosing not to go public, the same way I am sad about the deal with Microsoft. It bodes well and grants affordances.
Sam Altman (in context of risks of AI): "What I lose the most sleep over is the hypothetical idea that we already have done something really bad by launching ChatGPT."
That seems misplaced, in the sense that launching OpenAI and its general path of development seem like the places to be most worried you are in error, unless the error in ChatGPT is ‘get everyone excited about AI.’ Which is a different risk model that has many implications. I would have liked to hear more details of the threat model here.
The extinction question puzzles me. No human ancestor is extinct, however far back you go. Any species any of whose members have living descendants has not gone extinct. It doesn't matter how different those descendants are from the original species.







, \"Anthropic\" (widely distributed), and \"Pessimistic Safety View\" (focused on AI is very hard).")






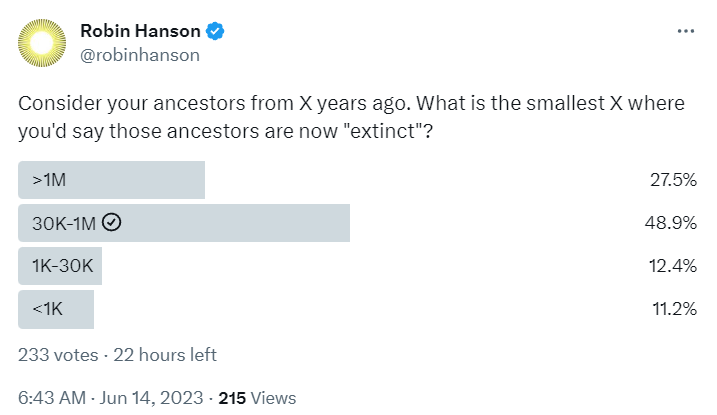

The extinction question puzzles me. No human ancestor is extinct, however far back you go. Any species any of whose members have living descendants has not gone extinct. It doesn't matter how different those descendants are from the original species.
Nit: It's Rohin Shah, not Robin Shah.