

AI #27: Portents of Gemini

By all reports, and as one would expect, Google’s Gemini looks to be substantially superior to GPT-4. We now have more details on that, and also word that Google plans to deploy it in December, Manifold gives it 82% to happen this year and similar probability of being superior to GPT-4 on release.
I indeed expect this to happen on both counts. This is not too long from now, but also this is AI #27 and Bard still sucks, Google has been taking its sweet time getting its act together. So now we have both the UK Summit and Gemini coming up within a few months, as well as major acceleration of chip shipments. If you are preparing to try and impact how things go, now might be a good time to get ready and keep your powder dry. If you are looking to build cool new AI tech and capture mundane utility, be prepared on that front as well.
Table of Contents
Introduction.
Table of Contents. Bold sections seem most relatively important this week.
Language Models Offer Mundane Utility. Summarize, take a class, add it all up.
Language Models Don’t Offer Mundane Utility. Not reliably or robustly, anyway.
GPT-4 Real This Time. History will never forget the name, Enterprise.
Fun With Image Generation. Watermarks and a faster SDXL.
Deepfaketown and Botpocalypse Soon. Wherever would we make deepfakes?
They Took Our Jobs. Hey, those jobs are only for our domestic robots.
Get Involved. Peter Wildeford is hiring. Send in your opportunities, folks!
Introducing. Sure, Graph of Thoughts, why not?
In Other AI News. AI gives paralyzed woman her voice back, Nvidia invests.
China. New blog about AI safety in China, which is perhaps a thing you say?
The Best Defense. How exactly would we defend against bad AI with good AI?
Portents of Gemini. It is coming in December. It is coming in December.
Quiet Speculations. A few other odds and ends.
The Quest for Sane Regulation. CEOs to meet with Schumer, EU’s AI Act.
The Week in Audio. Christiano and Leahy give talks, Rohit makes his case.
Rhetorical Innovation. Some relatively promising attempts.
Llama No One Stopping This. Meta to open source all Llamas no matter what.
No One Would Be So Stupid As To. Bingo, sir.
Aligning a Smarter Than Human Intelligence is Difficult. Davidad has a plan.
People Are Worried About AI Killing Everyone. Roon, the better critic we need.
Other People Are Not As Worried About AI Killing Everyone. Consciousness?
The Wit and Wisdom of Sam Altman. Do you feel lucky? Well, do ya?
The Lighter Side. The big time.
Language Models Offer Mundane Utility
A class on the economics of ChatGPT, complete with podcast recording. More like this, please, no matter my quibbles. I especially don’t think survey courses, in economics or elsewhere, are the way to go. Focus on what matters and do something meaningful rather than try to maximize gesturing. If you let me teach students with other majors one economics class, teach them the basics of micro and then use that to explore what matters sounds like a great plan. So is getting students good at using LLMs.
Use algorithmic instructions to let LLMs accurately do tasks like 19-digit addition.
Summarize writing. It seems GPT-4 summaries are potentially more accurate than humans ones.
We encountered two practical problems:
Not following instructions. Bigger models were better at following instructions. We had to use another LLM to understand the outputs of the smaller LLMs and work out if it said A or B was the answer.
Ordering bias. Given A and B, are you more likely to suggest A simply because it is first? One way to test this is to swap the ordering and see how many times you say A both times or B both times.
Once we dealt with these problem we saw:
Human: 84% (from past research)
gpt-3.5-turbo: 67.0% correct (seemed to have severe ordering bias issues)
gpt-4: 85.5% correct
Llama-2-7b: Catastrophic ordering bias failure. Less than random accuracy
Llama-2-13b: 58.9% correct
Llama-2-70b: 81.7%
If you do not so much value accuracy, the cost difference for Llama vs. GPT-4 is real.
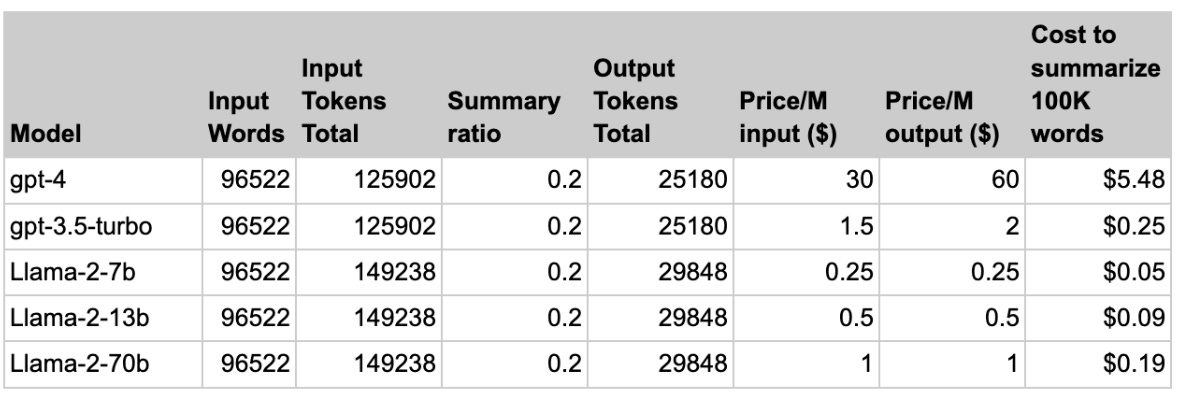
If you need to do summarization at scale, that is a big difference.
What is unsettling is that all methods, including using humans, had at least a 15% error rate. Summaries flat out are not reliable.
Language Models Don’t Offer Mundane Utility
William Eden: We all thought ChatGPT would kill search because it would be so much better than search
No, it killed search because all the top search results are utter gibberish auto-generated clones that make thinkpiece listicles read like Shakespeare
I have had much better luck with search than this. I also notice I rarely do more open ended search - I usually know exactly what I am looking for. If I didn’t know what I was looking for… I’d ask Claude-2 or GPT-4, or Bing if it is recent. Or Twitter.
A new front in the jailbreak wars is coming.
Jan Leike (head of alignment, OpenAI): Jailbreaking LLMs through input images might end up being a nasty problem. It's likely much harder to defend against than text jailbreaks because it's a continuous space. Despite a decade of research we don't know how to make vision models adversarially robust.
An important open question is how well whitebox attacks on open source models transfer to larger proprietary models. (My prediction: it's possible to make them transfer reasonably well).
I wish more people were working on this.
Patrick Wilkie: What does it mean “its a continuous space”?
Jan Leike: You can make small changes to individual pixel colors without changing the image semantically, but you can't make small changes to a token/word without changing its meaning.
Jacob Valdez (reply to OP): Will you still release multimodal gpt4?
Jan Leike: GPT-4 is already jailbreakable.
Dan Hendrycks (reply to OP): "Only research text-based models if you care about safety" is a meme that will hopefully fade when multimodal AI agents emerge.
As I’ve noted before, I can think of things I would try, most of which have presumably already been tried and found not to work but you never know. In the past I’d have said ‘oh a decade of research so everything I think of that isn’t deeply stupid has definitely been tried’ except no, that’s definitely not how things work. A fun problem to explore.
An inside source tells me many psychiatrists are rather upset this week over the Washington Post report that if you explicitly ask LLMs to tell you ways to lose weight, they will tell you. And if you ask about a particular method that is not a good idea, it will warn you that it is not a good idea, but sometimes, especially if you jailbreak it first, it will still tell you the factual information you requested. Or, as they are calling it, ‘encouraging anorexia.’
The worst example remains the chatbot created for the National Eating Disorders Association help line. Rather higher standards need to apply there. Whereas asking for universal full censorship of a large swath of information, and for information sources to respond to questions only with lectures, does not seem like a road we want to start going down as a standard, unless our goal is to shut such models down entirely.
Stop trying to get AI to write your generic articles without actual proper human editing, if you worry someone might read them.
CNN: In one notable example, preserved by the Internet Archive’s Wayback Machine, the story began: “The Worthington Christian [[WINNING_TEAM_MASCOT]] defeated the Westerville North [[LOSING_TEAM_MASCOT]] 2-1 in an Ohio boys soccer game on Saturday.” The page has since been updated.
…
As of Wednesday, several Dispatch sports stories written by the service had been updated and appended with the note: “This AI-generated story has been updated to correct errors in coding, programming or style.”
Eventually, can you reach a point where stupid mistakes won’t happen, if all you want to do is tell variations of the same high school sports stories over and over? Sure, obviously this is a thing technology will be able to do. It is not crazy to iterate trying to get to right. Until then and while doing so, check your work, fools.
GPT-4 Real This Time
ChatGPT Enterprise is here, offering unlimited 32k-context-window twice-the-speed GPT-4, full data privacy. Pricing is ‘contact sales’ and presumably worth every penny.
Perplexity fine tunes GPT-3.5 for their co-pilot, surpasses GPT-4 quality in a week as judged by its users. The first thing to notice here is that they did this so quickly, presumably because they had a unique data set ready to go. However the task here was co-pilot, so why wasn’t a similarly good data set available for OpenAI? Why didn’t we already have a much better version?
Whereas their Perplexity Pro research assistant is now using Claude-2, taking advantage of the gigantic context window.
Why are we fine tuning on GPT-3.5 rather than fine tuning on GPT-4? I don’t want the faster, cheaper as-good version, I want the superior version and yes I will wait. Is this because we were training GPT-3.5 on GPT-4 results that let it catch up, but it wouldn’t help GPT-4 much? What would that imply?
Fun with Image Generation
Google introduces SythID to watermark images its models generate.
Faster version of SDXL 1.0 is released, 20% improvement on A10s, 70% on H100s.
Reason’s Jennifer Huddleston says Robots Aren’t Coming For Movie Stars, Yet. The movie stars agree. Like all things AI, the worry is that they will come for movie stars in the future, not that the current tech is sufficient now. Never find out your heroes are actually a (historically much more accurate than most alternatives) rock that says ‘innovation is great and government does not work.’
Deepfaketown and Botpocalypse Soon
Jeffrey Ladish: Anyone have advice on how to generate good realistic deepfakes using a few images of a person? (e.g. of a person being arrested or posing with a person) Working on a demo and it would be useful to talk to people about this / be pointed in the right direction
bayes - e/acc: sounds dangerous
Jeffrey Ladish: yeah gotta be careful with some of this AI stuff might be risks idk.
bayes - e/acc: 🤯
Ah, face swap and face fusion. I am sure no one will use this for unethical purposes or inappropriate content, seeing as they asked so nicely.
404 media continue to work their wheelhouse, warn of AI-written mushroom guides on Amazon whose errors might kill the reader. They provide three links, with a total of two reviews between them. The first thing I would do, before buying a book whose errors might kill me, would be to check the reviews. If I saw only one, and did not otherwise know about the author, I probably wouldn’t buy the book.
I do realize things will get worse. But if this is what the scaremongers can point to, so far things are pretty much fine.
They Took Our Jobs
South Korea was fine with the robots taking our service jobs given their rapidly aging and declining population. But the rules don’t include protectionism, so now the foreign robots are taking the domestic robots’ jobs. Next level stuff.
Zena Hitz warns that UWV getting rid of some of its study programs will kill those things within the state, because who will be there to teach such things even at lower levels, and that this will spread. I do not understand why you need a degree in French to teach high school French, or a mathematician to teach high school math, and so on. The presumption that ‘the parents of home schoolers went to school’ illustrates the perspective that school and formal education is the source of knowledge. I do not think this was true before and expect it to be less true quickly over time.
What I do buy in theory is Zena’s claim that such programs can pay for themselves, since all they need are a few professors and buildings. The problem is that in practice there is no way out of the various other amenities and administrative costs involved. We would love to offer the package of ‘buy the time of professors to teach you stuff’ if that could be sold separately, but we lack the technology to do that. Luckily ‘buy the time of GPT-5 fine-tuned to be a tutor’ will be available, and our price cheap.
Get Involved
Peter Wildeford: I'm hiring for a new assistant to work directly with me at making @RethinkPriors even better at our work. My last assistant was too talented and went on to a major research management role. You too could get mentorship from me and accelerate your career!
Introducing
You’ve seen Chain of Thought and Tree of Thoughts. Now meet Graph of Thoughts.

I mean, sure, why not?
Pastors.ai, which lets you create a custom chatbot from a YouTube video of your church service, and create resources for use beyond that. The obvious question is, to what extent is this a skin on top of a general audio-to-chatbot service, and what is the best version of that service, or a text variant? What is doing the unique work? I will admit that I have yet to have the temptation to chat with a YouTube video, but give me the option and I think I’ll figure out some uses, although I expect the first thing will be questions designed to figure out if I want to watch the video or not.
In Other AI News
How AI Gave a Paralyzed Woman Her Voice Back. They hooked sensors up to the parts of the brain responsible for speech, trained it to recognize all the sounds in English, now they simulate her old voice at 80 words per minute.
Web scraping for me but not for thee, all the major players are both scraping the entire web and suing to prevent anyone from scraping them in return.
Nvidia is the biggest investor in AI unicorns.
DHS using AI-based sentiment analysis straight out of Inside Out.
Related to the emotion and sentiment detection, charts contained in the Fivecast document include emotions such as “anger,” “disgust,” “fear,” “joy,” “sadness,” and “surprise” over time. One chart shows peaks of anger and disgust throughout an early 2020 timeframe of a target, for example.
System for now uses publicly available data, doing things like linking social security numbers to Facebook or Reddit accounts. 404’s investigation does not say what DHS then does with this information. If it then uses this to draw human attention to such people for evaluation, then I do not see how we could hope to prevent that. If it is being used as an automatic evaluation, that is much worse. Either way, be under no illusions that the US government won’t use all the tools available for its surveillance state, for all its purposes. If you don’t want your info used, don’t let them get their hands on it.
Ajeya Cotra notes that yes, ChatGPT and GPT-4’s capabilities took us by surprise.
China
There’s a new blog about AI safety in China.
AI Safety in China: Common perception: China doesn’t care about AI safety.
Our perspective? China’s more invested in AI safety and risk mitigation than many realize.
This newsletter aims to bridge the knowledge gap.
The first post is here. I knew of all of the most important developments, this organizes them into one place and presents as a cohesive whole. After looking at this, one asks: If China cared a lot about safety, what would we see that we don’t see here? If China did not care a lot about safety, would we still see the things we do see here?
The Best Defense
A common debate is whether the only thing that can stop someone with a bad AI is someone with a good AI and proliferation can be handled, or whether offense is too much favored over defense for that to work. There is both the debate about mundane systems and risks, and future existential ones.
Nora Belrose: I'm opposed to any AI regulation based on absolute capability thresholds, as opposed to indexing to some fraction of state-of-the-art capabilities. The Center for AI Policy is proposing thresholds which already include open source Llama 2 (7B). This is ridiculous.
Gary Marcus: Shouldn’t regulation be around the harms a system might cause? Why tie it to a relative determination? In principle you then could have a situation with successively more harmful systems being deregulated simply because more dangerous systems are invented.
Nora Belrose: The possible harm caused by the system is proportional to its relative power, not it its absolute power. AI can defend against AI. We can use AI to detect psy ops and fake news, and to make transmissible vaccines to protect against bioweapons, etc.
Gary Marcus: In principle I do think AI can defend against AI. But in practice it is very hard, and I doubt that any near term technology is up to the job. The best extant cases are maybe things like spam detection and malware detection. Neither are great. Prove I am wrong?
I agree that offense is not automatically favored over defense, but that is definitely the way to bet.
In general, if you want to defend against a potential attacker, the cost to you to do so will vastly exceed the maximum resources the attacker would still need to succeed. Remember that how this typically works is that you choose in what ways you will defend, then they can largely observe your choices, and then choose where and when and how to attack.
This is especially apparent with synthetic biology. For example, Nora suggests in a side thread pre-emptive vaccine deployments to head off attacks, but it is easy to see that this is many orders of magnitude more costly than the cheapest attack that will remain. It is also apparent with violence, where prevention against a determined attacker is orders of magnitude more expensive than the attack. It is often said it takes an order of magnitude more effort to counter bullshit than to spread it,, and that is when things go relatively well. And so on.
Why do we not see more very bad things? We have a punishment regime, and it is feasible to impose very high penalties on humans relative to potential benefits that one person is able to capture. Coordination is hard and human compute limits make it hard to properly scale, so humans remain at similar power levels to each other, and have strong egalitarian and enforcement instincts even when against direct interest. That sort of thing (among others).
Alas, I do not expect most of these properties to hold.
Even if they mostly do, it will indeed have to be the good human with an AI that defends against the bad human with an AI or the rogue AI. That means that the effective capabilities of the good human will have to keep pace with the unleashed capabilities of the bad AI. Which means handing the whole enterprise, and increasing amounts of effective control, over to the (we think it is) ‘good’ AI, in furtherance of some goal. If we don’t, we lose.
We also do not have an option to use a light touch and respect digital freedom and privacy, if we want to be proactively protective. If we let the bad human get an AI because the good human with an AI will stop them, then how are they going to do that in advance? That monitoring regime, again even in a world where we solved alignment and defense is viable, is going to if anything be even more intrusive.
To be concrete, suppose you do not want anyone creating deepfake pornography. You have three options.
You can ban open source image generation models, and require all offered image generation models to block attempts to generate such images, and do the monitoring required to ensure no one violates these rules.
You can allow open source models, and monitor all people’s internal data to look for such images in some way.
You can allow open source models, and accept that if people want to privately generate such images, you cannot stop them, except by occasionally noticing and extracting punishment.
Is option one more or less violating of our privacy and freedoms than option two? Which one is likely to have larger side effects in other places? If there is a potentially unacceptable state that can be created on a private server, what to do, and how does this relate to someone building a nuke on their private property?
Portents of Gemini
It is coming. Gemini will have 5x the pretraining FLOPS of GPT-4 by year’s end, 20x by end of the next year, to which my response is essentially that’s it? I would have thought things were accelerating at least that fast and this is freaking Google.
I don’t doubt Gemini will be a big deal and a game changer, but it seems as per these reports entirely expected, a return to normality, the type of progression you would expect. Yes, it will advance capabilities, and those not paying attention who think the whole LLM thing was a ho-hum will notice and freak out, but if you are reading this you had already priced all of that in, right?
As James Miller notes, seems wise to be overweight Google, as I have been for a long time, although not overweight enough, the same story as Microsoft and Nvidia.
Another money quote from that post:
“HuggingFace’s leaderboards show how truly blind they are because they actively hurting the open source movement by tricking it into creating a bunch of models that are useless for real usage.”
Ouch.
I am confused how bad a measure it can be if its top model is GPT-4 followed at some distance by Claude and GPT-3.5, with another large gap to everything else, and I’m using that leaderboard as the default evaluation for my Manifold markets, but worth noting that this in practice may be warped strongly in favor of open source models. They could be so much worse than we think they are. Which makes sense given I am never remotely tempted to use one of them for mundane utility.
Gary Marcus, as he gloats about his eleven-days old prediction that ‘ChatGPT will be a dud’: Bets on whether Gemini hallucinates?
My prediction is that, since it is multimodal, it will see double.
A claim that GPT-5 might be trained this fall and deploy as early as December 23. That would be quite the contrast with GPT-4, which not only was not trained so quickly, it was held in reserve for a full eight months while they did red teaming and verified it was not dangerous. The market, such as it is, seems skeptical at 13%.
If OpenAI does release GPT-5 on that schedule, either they have been lying and they’ve had it trained for some time, it is completely unworthy of its name, or they will have entirely abandoned the idea of doing even their own previous level of rudimentary safety precautions before releasing a new model. It would be a deeply negative update on OpenAI.
Quiet Speculations
AI and the Future of Learning, from RSA and DeepMind. Didn’t see anything new.
David Kruger highlights from last week’s paper on the subject that the potential to be wrong about whether an AGI is consciousness is a strong reason to not build an AGI, because there is no safe assumption one can make. Both mistakes (thinking it is when it isn’t, or isn’t when it is) can cause immense harm.
Questions that are not often enough asked.
Sherjil Ozair: if e/acc is about building, how come it’s doomers who actually built agi?
The Quest for Sane Regulations
Techmeme: Sources: Elon Musk, Mark Zuckerberg, Sundar Pichai, Sam Altman, Jensen Huang, and others are expected to attend Sen. Schumer's closed-door AI forum on Sept. 13 (Axios).
Rohit: I was not invited to this. Curious whether anyone else not on the payroll of a major tech company was.
Amin Amou (other thread): The next regulatory meeting on climate change will be only with the CEOs of Exxon, bp, Shell, and Chevron to discuss the future of green energy.
I certainly see the concern. It also seems like any reasonable exploration of AI regulation would include such a closed-door forum meeting with top tech people. It needs to not be the only meeting or only class of meaningful voices, but it is a necessary meeting, where such people can tell you things behind closed doors, and create common knowledge within such a group. It might even allow otherwise illegal collaboration to adopt safer procedures.
If it does create regulatory capture? That could be bad. It could also be good. I am far more interested in what is good for the world than what is good for particular companies. I also notice Huang, who is president of Nvidia rather than a particular AI company. Could some form of chip control or tracking be in the cards?
I will also bite Amou’s bullet, despite the unfairness of the comparison. There should absolutely be one meeting, in the process of regulating carbon, where they bring in the CEOs of the fossil fuel companies and no one else. There should also be other meetings without them. Why is that weird?
Brian Chau reviews the impact of GPDR and previews the potential impact of the EU’s AI Act. Open ended scope for lawsuits, fines and recalls, a regulatory state that can take huge (2%-4% of global revenue) money from any company at any time. What isn’t a ‘threat to democracy’? APIs are effectively banned, Lora is effectively banned, which he notes will be a big issue for open source projects.
What he does not point out, but that seems pretty obvious, is that anything that effectively bans an API also bans open source outright. An open source project has to register its anticipated capabilities and every deployment of new code, it has to be capable of a recall on demand, and it has to prevent malicious uses. That’s why the API is potentially de facto banned.
What would happen if Meta releases Llama-3, and every time anyone uses a fine-tuned version of it that stripped out its alignment in two days to say something racist or spread misinformation, they fine Meta 2% of global revenue? When they go after GitHub? You think they wouldn’t do that?
Those who say it cannot be done should not interrupt the one doing it. Stop telling me things that have already happened in one of the world’s three major blocks cannot possibly happen. Rather than spend time denying that we could, perhaps it would be better to instead debate whether (and how) we should.
The Week in Audio
New Paul Christiano talk (direct link, YouTube, 1 hour).
Connor Leahy: Seems Paul Christiano is now working on something like "informal logical inductors/probabilistic proof systems", a formalization of heuristic arguments. Cool!
Talk was technical, likely too technical for most readers. I found it interesting. I am not sure what I would do with many of the results Paul is looking for if I found them, or how they give us a route to victory. They do still seem cool and potentially useful.
Connor Leahy 20-minute talk from the FLI Interpretability Conference at MIT, on the dangers and difficulties of interpretability. A key point is that much of the cognition of an AI, or of a human, takes place outside the AI or human brain itself.
Rohit Krishnan goes on Bretton Goods to explain why he thinks AI won’t kill us. Robert Long found it good and interesting, Tyler Cowen linked to it.
I listened so you don’t have to, but failed to hear any arguments for why AI wouldn’t kill us.
It was more like there wasn’t anything Rohit felt we could usefully do with the claim that AI would kill us, and no way to predict what future systems will or won’t be able to do, and we don’t know how anything involved works, straight lines on graphs aren’t reliable or meaningful and you can’t prove a negative. Nothing is yet concrete in its details and when humans see problems we fix them. Therefore might as well treat the threat as not being there, or something?
It was a weird listen. Rohit (non-exclusively) makes lots of true and useful statements. Except that none of them seem to me like reason to not worry. Mostly they seem like incremental reasons to worry more. If for example future systems will be totally and unpredictably unlike present systems (31:10), why should that make us worry less?
Meanwhile he also makes a lot of statements that are bizarre strawman representations of others’ positions and assumptions, as well as many arguments I don’t see as valid.
Most glaring is that he says others are assuming that future systems will be more capable or bigger but otherwise identical copies of current systems. We don’t.
Perhaps the core issue is the whole concept of the self-correcting system (33:05). When you have a technology that is purely a tool and lacks a mind of its own, that we can iterate on when something goes wrong, and humans are exerting all the optimization pressure, we can assume that problems will be self-correcting. Thus, Rohit perhaps assumes we must think these systems will otherwise not change, because any changes would obviously make things better on every dimension.
Whereas in the case of sufficiently capable AI, we have the opposite situation, where many types of problems are self-protecting and self-amplifying, and yes our currently working solutions predictably stop working. That’s not to say that it is impossible we will find superior solutions that do work, but Rohit is himself arguing that he does not know how to go look for them. That does not seem great, nor a reason to not worry.
Or perhaps it’s as simple as ‘That’s the problem. Let’s not jump to the future’ (33:25). The problems we are talking about lie in the future. Saying ‘we don’t have that problem now’ is not a response. Few if any people are making the assumptions of otherwise identical systems Rohit is suggesting, nor do anyone’s threat models depend on it.
Rohit repeatedly emphasizes that systems will only get deployed if they solve real-life problems (e.g. 27:15), so he says only sufficiently aligned or interpretable systems will get deployed. Yes deployment for some particular use cases can be blocked by such concerns, but it seems impossible that sufficiently dangerous systems will stay contained because they do not offer any usefulness.
To quote at (35:30), he says ‘if the current systems have problems they are not deployed.’ That is completely, utterly false. Bing, if we may recall the stories. Bard, that still spits out nonsense on the regular. ChatGPT. Llama-2. All these systems exhibit severe failure modes. All these systems are, today, trivial to jailbreak if you care sufficiently. If we deploy superintelligent systems about this flawed, we die. This argument does not make any sense to me. At (36:25) Rohit says that prompt injection and hallucination are problems we need to solve before we get widespread deployment. Except we have both problems in spades, and we have widespread deployment happening at the speed we can manufacture GPUs. What the hell? He then says in parallel ‘if GPT-5 shows up with new problems, we will have to solve them before we get to GPT-6.’ (37:10). Except, once again, we have very much not solved GPT-4’s problems. Does anyone think that fact will stop OpenAI from creating GPT-5? Rohit later claims (50:25) that we have mostly solved our problems for now, and no? Reduced the practical size of the problem when no one is trying very hard sure, solved them very much no.
Throughout Rohit presumes that the future systems only get deployed where and for the purposes we choose to intentionally deploy them. Which does not exactly assume away the problem, we can absolutely get killed without violating that assumption, but it’s a hell of an assumption when you think about it. See (43:35) for example, the idea that AI is deployed only to ‘low risk’ situations so none of the current deployments count, or something? We have these things writing a good percentage of our code, and we are turning them into agents hooked up to the open internet. This is not a low risk situation. Bridgewater using an AI while consumer banking recommendations do not (44:15) is not a protective strategy. Blowback companies will face is not a good proxy for existential danger.
I am also continuously baffled by ‘our society’s checks and balances will contain the problem’ when the problem is an advanced AI system. Saying ‘a sufficiently powerful system might be able to come up with loopholes that overcome the thousand human reviewers’ as is said around (29:55) is not a remotely good description of the problem here. This is absurd.
One should note that Rohit’s positions are a very strong argument for a hard ban on open source models, at least above a threshold of capabilities. The argument here is, as I understand it, that commercial or political downside risks will cause all of our actors, all of whom are highly responsible, to only deploy sufficiently tested, safe systems. Which, I mean lol, but even if that was true it would depend on all those actors wanting to act responsibly. It all depends on only large players being relevant. If you instead open source something competitive with that, then there will be those who aim to misbehave, and many more that will play fast and loose, and that pressure will in turn disallow responsible behavior.
I also am increasingly sick of people not new to the concepts involved calling existential risk from AI a ‘science fiction story’ (36:03) as a means of dismissing the idea that if we create something more intelligent and more capable than us, that it might pose a threat to us. Or saying it ‘requires so many assumptions’ which he also says. These are at best semantic stop signs.
I do appreciate Rohit’s expression of confusion (47:30) on instrumental convergence, where he notices that the explanations he is hearing all sound like a stupid person trying to convey something they don’t understand. We need more of that energy, and those of us who do understand this problem need to do a better job explaining it.
He closes by discussing regulation (58:45), saying that his instinct is to oppose all regulations on the principle that regulations tend to be bad, that even calling for evaluations would too much favor the big companies (despite it seeming to me as if all his arguments rely on the safety inclinations of big companies carrying the day) but maybe it would be fine. It is clear what he would think about something more. Shrug.
If I were to have a slow and friendly discussion or podcast with Rohit, there are a lot of potential places I could attempt to make progress or have a useful discussion, and I anticipate I would learn in the attempt, but that I would be unable to convince him. If your core position is strongly held that anything not already concrete cannot be considered until it is concrete, then you will be unable to think about the problem of AI existential risk.
Rhetorical Innovation
Michael Nielsen offers prefatory remarks on ‘Oppenheimer’ to AI folks. Short and excellent.
I was at a party recently, and happened to meet a senior person at a well-known AI startup in the Bay Area. They volunteered that they thought "humanity had about a 50% chance of extinction" caused by artificial intelligence. I asked why they were working at an AI startup if they believed that to be true. They told me that while they thought it was true, "in the meantime I get to have a nice house and car".
This was an unusually stark and confronting version of a conversation I've had several times. Certainly, I often meet people who claim to sincerely believe (or at least seriously worry) that AI may cause significant damage to humanity. And yet they are also working on it, justifying it in ways that sometimes seem sincerely thought out, but which all-too-often seem self-serving or self-deceiving.
Daniel Eth responds to a previous Timothy Lee post, Timothy considers it thoughtful.
Flo Crivello: "AGI isn't possible"
"And if it was, it wouldn't be near"
"And if it was, it wouldn't be dangerous"
"And if it was, we could use AGI to fight AGI"
"And if we couldn't, then there's nothing we could do about it anyway"
"And if there was, the cure might be worse than the disease"
Nearcyan: "there's nothing we can do about it. it's not actually possible to coordinate or solve problems when the individuals have incentives to defect" me when someone asks me to stop eating all the cookies and save some for everyone else.
It would be more convenient if we passed through the stages cleanly, so you didn’t have to fight all of them at once. Alas, a more accurate version of the standard progression is that first they ignore you, then the ignore and laugh at you for different values of they, then they ignore and laugh at and fight you for different values of they (you are here), then the ratio slowly shifts over time, then either you win or (in this case everyone dies). You don’t get to declare levels cleared, ever.
When viewed from above, it is a relatively fair progression. Yes, there is some of ‘perhaps we could have done something about it before but it is too late now’ but not very much of it. Mostly the argument is ‘there was never anything anyone could do, even in theory’ because coordination and cooperation are either impossible or actively terrible. Those two are linked as well. It is exactly because it is so difficult that any attempts that partly succeed pose so much danger of making things worse.
In many other situations, such as most of those involving Covid, I would be one of those making exactly the claim that strong coordination as it would be implemented in practice would be some combination of impossible and worse than the disease.
Which I would also agree with here, except that I have seen the disease. The disease kills everyone and wipes out all (from-Earth) value in the universe. So I am going to say that no, the cure is not worse than the disease. And if this is an impossible (in the game difficulty sense) problem, then we have to shut up and do the impossible. Or, if you have a less impossible alternative pathway, I am all ears. So far I have not heard one.
A satirical approach is attempted.
Seb Krier: I understand British Gas will publish an ArXiv paper claiming that their new refineries could cause massive explosions and may require safety testing. Do NOT believe them - this is a very clever marketing ploy to sell more gas and divert attention from gas leaks, the real harm.
Davidad: The steelman is that many people will predictably react to learning that AI extinction risk is real the way that Snoop Dogg did: “do I need to invest in AI so that I can have one?”
Seb Krier: There are def plausible reasons - but ultimately wouldn't be my preferred hype strategy.
Eliezer Yudkowsky outlines one of the biggest problems.
I'm not currently sure what to do about the basic point where (while one large subgroup quickly gets it, to be clear) there's a subgroup of "But how could a superintelligence possibly hurt us?" askers who:
1: Come in with a strong bias against hearing about any technology that doesn't already exist. They want to hear a story about humanity being wiped with 2020s tech, because tech more advanced than that feels like a fairy story to them.
2: Want to hear concrete chess strategies that will beat them, rather than being told about abstractly superior chessplayers. They don't come in with a prior concept of "The best strategy you can think of is predictably an underestimate."
3: Allocated 6 minutes total to the conversation, 1 minute to the question "How will AI kill us?", and start to glaze over if you talk for longer than 30 seconds.
The combination of 1-3 is a genuinely hard expository problem and I've been struggling with it.
"Tell them about understandable stuff like how an AI could run people over with robotic cars!" Skeptical or attentive listeners will notice that this is an invalid story about how a superintelligence could successfully take over and get all the resources. It does not make valid sense as a complete coherent story because an AGI could not wipe out all of humanity that way; and wouldn't have replacement power plants or factories to build a human-independent economy if it could wipe out humanity that way.
(If we're playing on the playing field of invalid arguments, stories that don't really make sense when you stare at them, I expect that my opponents win that battle because they have more practice and they get to tell more attractive and appealing invalid stories once people are just making up whatever. Or so I rationalize my deontology about using only valid arguments myself.)
Concrete takeover stories are elementary if you start out with the knowledge and the way of thinking where, for example, algae are solar-powered self-replicating factories with a core general assembler, the ribosome, that accepts digital instructions and can also build more general chemical products via indirect synthesis pathways catalyzed by proteins; plus, the understanding that evolved proteins are very weak chemically for systematic reasons. Then it's obvious in one step to imagine the superintelligence taking over the algae factory system and improving it, rather than taking over human factories. If "algae" are a kind of green water-moss that doesn't feel like a factory, if the speaker starts out not knowing what a ribosome is (general assembler that accepts digital instructions) and also came in expecting to hear a story about robotic-ish minds doing specific modern-day-computery things that wipe out humanity, I'm not sure how to cross this gap in the amount of time some people want to give me.
Daniel Bottger: I think you need to get them to take the ASI perspective. Have you tried parenting analogies? All parents have seen a kid try to hide information from parents, and try to control them ("you can't go through there, there's lasers") and fail due to the intelligence difference.
Eliezer Yudkowsky: They're not coming in with a brain that can be simply instructed "imagine something else being smarter than you the way a parent is smarter than a kid". I expect it fails on "Huh? I'm not a kid!" and indignation about this person calling them low-status.
They also don't come in with a simple instruction for how to imagine an ASI as having a perspective where it's actively looking for ways to defeat humanity that humanity couldn't counter, and then, actually turn their brain that way. The ASI is imagined to be mechanical, or nerdy-college-professor book-smart 'intelligent'; English doesn't have a simple word, and lots of people don't have a simple pre-existing concept, that you can pull as a lever to say, "Take on the adversarial perspective and actively search from inside it." That's why security mindset is proverbially hard to teach if someone wasn't born with it.
I mean, yeah. It’s a hard problem. The replies illustrate how bad it is out there.
My go-to in these situations is more or less: AI makes money. AI pays people to work for it. Those people make it more money and make it impossible to shut down. It hires more people. They create the tools it needs to not need them anymore. If you say no, it finds someone else who says yes.
Because that would obviously work and really shouldn’t be something you can challenge successfully, and if they start arguing I can always have the AI up its game at any point as this is a dramatically non-optimized plan.
But I agree, success rates are not so high. The obvious response to such plans is ‘but we would notice and fight back.’ To which the actual response is ‘maybe we would notice, but if we did notice we would not fight back in any effective or meaningful way even if the AI wasn’t actively stopping us from doing so, which it would be.’ Still, Eliezer’s desire is to sidestep that whole argument, since the AI would indeed sidestep it by doing something smarter, but then people say that the smarter thing isn’t possible (e.g. nanotech).
Nearcyan: The issue with doomerism is not that it is incorrect, but that it is rarely actionable in a positive way building things which are better than what we have now is usually a more promising path than stopping or destroying the things which are sub-par.
two valid critiques to this: 1) doesn't apply to x-risk. if everyone is going to die, no amount of building helps you 2) doesn't work in areas with high ratio of ability to attack v. defend, e.g. synthetic biology pathogens. we need more defense, but attacking seems much easier.
I say this as a (partial) doomer myself - there's many bad things in the world I wish I could stop, but even if I dedicated my life to stopping them, I would not make nearly as much of an impact as I could simply by creating a few good things instead.
This is indeed extremely frustrating. The good news is that it is not true.
There is indeed one particular subset of things that it is very important that we not build, or at least not build yet. Which are foundation models and other core enhancements to the path of AI capabilities.
For pretty much everything else, including ways for AI to provide better mundane utility, it is and remains time to build.
If you want to build something that impacts the problem directly, you can at least sort of build, by doing technical work, or by building institutions and understanding, or by building philosophical understanding, or other similar things. I do realize this is an imperfect substitute, and that ‘build a regulatory framework’ or ‘build a coalition’ is not satisfying here.
If you want to actually build build something, however, I once again remind everyone that you can do that as well. For example, you can build an apartment building or a wind turbine, or an entire new city 60 miles outside San Francisco.
I am deadly serious. We need to live in a sane world, where people can envision a positive future, and where they have the resources to breathe, to think and to raise families. We need something to protect, lest people fall into despair and desperation and insanity. Help more people have that. You got to give them hope.
The best part is that if it turns out there was no threat, all you did was help make the world a better place. That seems like an acceptable risk.
At some point, of course, someone is actually going to have to do the direct thing. But it is not everyone’s job. Some of you should do one thing, and some of you should do the other.
AI Safety Memes: “I don’t think a species smarter than me could outsmart me, and I’m willing to stake the life of every man, woman and child on it” - Guy who shouldn’t be allowed to make that decision
Llama No One Is Stopping This
No, it’s not going to stop, till you wise up.
Jason: Overheard at a Meta GenAI social:
"We have compute to train Llama 3 and 4. The plan is for Llama-3 to be as good as GPT-4."
"Wow, if Llama-3 is as good as GPT-4, will you guys still open source it?"
"Yeah we will. Sorry alignment people."
(To see how likely they are to pull this off, we have manifold markets for whether they do this for Llama-3 by EOY ‘24 and Llama-4 by EOY ‘25).
Jason: Didn't expect this tweet to go viral. Not sure if it went viral in a good or bad way for meta. Maybe they won't invite me to their socials next time lol
Fact check update: I checked with someone else who was in the conversation, and that person thought it wasn't said in such a savage way. So my apologies for the color. But the content is still correct I believe. Another update with very low confidence about truthfulness: i also heard that someone else who wasn't at the event said they had a similar conversation
Roon: My two cents its not inherently bad to open source models of various capabilities levels. I think an open source GPT4 would be more or less fine. Its bad when you don’t understand what you’re releasing
Eliezer Yudkowsky (QTing OP): Translating and rebroadcasting this message for political actors in case you missed it: "Regulate this industry or everyone will die, because we won't unanimously regulate ourselves."
Yep.
What about what has been rendered so far with Llama-2?
Llama-2, out of the box, seems unimpressive overall as far as I can tell, and is especially bad at coding. Given the refusal to release Unnatural Code Llama, the coding deficit was partly intentional.
Meta is crazy, but they’re not stupid, they know not to give out such capabilities, and they made sure to align the model super hard.
Of course, a few days later some fine open source folk had completed the task of undoing all the alignment on Llama 2.
If you release an open source model, you are releasing, with a two day delay, the fully unaligned version of that model, that is fine tuned to do whatever the user wants. No one has even proposed in theory, to my knowledge, a way to avoid this.
Also, if you refuse to make your model good at coding, or avoid giving it some other particular capability, that too gets fixed, although it might take a few weeks rather than a few days.
WizardLM: 🔥🔥🔥Introduce the newest WizardCoder 34B based on Code Llama.
✅WizardCoder-34B surpasses [old version of] GPT-4, ChatGPT-3.5 and Claude-2 on HumanEval with 73.2% pass@1. Demo here, Model weights here, Github here. 13B/7B versions coming soon.
*Note: There are two HumanEval results of GPT4 and ChatGPT-3.5: 1. The 67.0 and 48.1 are reported by the official GPT4 Report (2023/03/15) of OpenAI. 2. The 82.0 and 72.5 are tested by ourselves with the latest API (2023/08/26).
Paul Graham: Phind finds fine-tuned CodeLlama-34B beats GPT-4. [Including this to point out that it was easy to make this mistake, of comparing to the old benchmark scores of GPT-4 rather than its new much higher ones.]
Jim Fan: This is basically an open version of the Unnatural Code Llama. Congrats! While the benchmark numbers look good, HumanEval only tests a narrow distribution and can be overfitted. In-the-wild performance is what truly matters. Coding benchmarks need a major upgrade.

This puts WizardCoder well aboove Unnautral Code Llama, and at the level of current GPT-3.5 or Claude-2. This is consistent with the ‘GPT 3.4’ evaluation of the general model, now without a particular weakness for code. As Jim Fan says, real world experience will tell the story. My expectation is that models like this will relatively underperform in practical applications versus on benchmarks, and that in a real world test I would bet on GPT-3.5 against it.
It makes sense that Meta is bad at fine tuning tasks including alignment, such that the open source community can do far better pretty much right away. Whereas the task of training the base model involves large expense, so the fact that they are also bad at that (relative to OpenAI or Anthropic) leaves them still doing OK there.
Would an open-source, up-to-date (and two days later completely unaligned to anything other than a given user) GPT-4 be fine? I think that too is an interesting question, if things did indeed stop at GPT-4-level plus the resulting fine tuning.
You would certainly see large gains in ability to efficiently do a variety of mundane harms. No doubt a lot of people would shoot themselves in the foot in various ways. We would get a real-world test of the fact that Claude-2-unaligned is able to provide detailed blueprints and practical instructions on production of biological warfare agents. The world might quickly become a far stranger, less relaxing place.
What this almost certainly would not do is end the world. On its own, all of this is fine, and pretty much inevitable. I know people who think we need to not only not open source a GPT-4 system but that also call for destroying the one we already have, and I am very much not in that camp. If you offered me (an actually globally enforced) deal that we open source exactly GPT-4, and in exchange no models more powerful than that ever get open sourced, I would happily take that deal, and expect to be in a much better position going forward than we are now.
Alas, instead, if we open source GPT-4-level now that builds more support for open source work, and pushes forward the open sourcing of a GPT-5-level system later, which is when the real not-fun plausibly starts, and of the models that will ultimately be powerful enough to, once proliferated, either kill us or place us into an unwinnable world state where we cannot prevent runaway AI-led competition that we will fail to survive. Where I think GPT-5 is an underdog to count for that, but not a large enough underdog for me to be comfortable with that.
Eliezer Yudkowsky: As ever and as usual, the problem is not that GPT-4 kills everyone but that they'll just keep doing this as AGI tech goes on advancing. If you saw a QT or reply arguing against the obvious straw, "lol they think GPT-4 kills everyone" remember that this was the strongest counter they could think of and it's obvious straw.
Actual concerns about what happens if AGI keeps improving are uncounterable except by straws, angry dismissals, sheer ignorance of existing analysis, and blatant hopium that doesn't stand up to 30 seconds of informed counterargument. What you see is what there is, with your kids' lives on the line.
Regulate now and aggressively; getting all the AI chips into internationally regulated and monitored datacenters will be a lot harder if you let this run long enough for lots of unregulated chipmakers to spring up under a lax regime. You should shut it all down, but if you're not going to do that, build *the shutdown button* before it's too late.
This also seems highly relevant.
Ian Hogarth (head of UK AI foundation model taskforce): Someone recently described 'open sourcing' of AI model weights to me as 'irreversible proliferation' and it's stuck with me as an important framing. Proliferation of capabilities can be very positive - democratises access etc - but also - significantly harder to reverse.
But just think of the potential!
Sherjil Ozair: The billion dollar use-case I’m excited about is on-prem coding assistant to 10x developer productivity on proprietary codebases and knowledge graphs.
The common goods value of open source LLMs is so high, it matches operating systems, programming languages, and database systems. The future is looking more and more like open source base models with product-specific fine-tuning.
Now hear me out, how about closed source LLMs with fine-tuning on proprietary codebases and knowledge graphs.
I agree that fine-tuning on your particular stuff is a great idea and people should totally be doing that. I don’t see why this has to involve open source. If you want to do something for a large commercial enterprise, why can’t you fine-tune on GPT-4? The three issues I can come up with are that it will cost too much, that you are worried they will stop supporting you, or that you are worried about data security. The cost issue seems worth it to get the improved performance and additional help an OpenAI or Anthropic can provide. The security of availability seems like something that could be credibly provided for, as can security of your data. You store everything on a cloud instance, where you don’t get to see the model weights and they don’t get to see your data either, and checks are made only to ensure you are within terms of service or any legal restrictions.
No One Would Be So Stupid As To
It was inevitable that this section would include the Department of Defense.
Max Tegmark: AI accelerationists: Nobody would ever build AI to kill people.
DoD: LOL 🤣
Deputy Secretary of Defense Kathleen Hicks: We’re making big bets- and we are going to deliver on those bets. First up: we’re going to field attritable autonomous systems at a scale of multiple thousands, in multiple domains, within the next 18-to-24 months. Together, we can do this. @NDIAToday #EmergingTechETI
They spent so much time wondering whether they could, and laughed when asked whether they should. They totally would, and they totally will.
Fofr: “Agents are the Hello World of the AI Engineer”
Swyx: The best startup AI Engineers I've met are all building their own agents. I know it's a buzzword that's now a bit past the wave of peak hype (thanks @zachtratar), but I can think of no better way to immediately, viscerally, run into all the SOTA problems of Prompt Engineering, RAG, Evals, Tool use, Code generation, Long horizon planning, et al. You don't even have to try to build an agent company. Just build one that does something you want done a lot. Its basically a rite of passage like how every Jedi needs to construct their own lightsaber. Agents are the Hello World of the AI Engineer.
[links to post about how to build one here]
From April 19: Fortunately the @OpenAI strategy of building in safety at the foundation model layer has mitigated the immediate threat of paperclips. Even when blatantly asked to be a paperclip maximizer, BabyAGI refuses. Incredibly common OpenAI Safety Team W.
Reminder that you cannot build in safety at the foundation model layer if the model is open sourced. That safety will get trained out of it in two days.
Why should humans or human-written code write the instructions to AIs anyway?
Bindu Reddy: Working on a LLM that will craft your prompts for you - so you don’t have to worry about this whole “prompt engineering” thing.
Hell, why should we check the code the AI writes? Run, baby, run.
Avi Schiffmann: we need an AI compiler. straight prompt -> machine code. future “developers” will just write high level natural language prompts & move architecture diagrams around. Current syntax is irrelevant if you’re no longer looking at your code.
Only enterprise-level companies will actually write human code. but your average hobbyist that just wants to make something won’t care, they just want abstraction. this is the future of developer abstraction companies like vercel.
Aligning a Smarter Than Human Intelligence is Difficult
On a high level, I want to agree with Simeon and say this is great. Identify what you see as the key problems (or perhaps in the future use a standard list, with your own additions) and explain how you intend to solve each of those problems, or why that problem will not stop your particular proposal.
Or perhaps you can say, if you think it is the relevant response ‘I don’t think this one is real in this context, I am ignoring it, if you disagree then you will think this won’t work.’
Then either way, we can respond accordingly, and identify key disagreements.
On a technical level, my response to the various strategies is a mix of ‘that does not seem to make the problem easy but in theory that could perhaps work if we indeed were under very little optimization pressure and could afford epic alignment taxes’ and ‘I do not see how this could possibly work.’ There is much talk of what you cannot do, which seems at least mostly right and important to notice. I especially appreciate the need to take human evaluation of the outputs out of the process, relying instead on evaluations that can have formal proofs attached, which does seem like the less impossible problem to work around.
Connor Leahy thread outlines the central why he thinks the plan won’t work. Technical issues aside, even if it would ultimately work, Connor sees the proposal as being far too expensive and time consuming to pull off before it is needed.
Connor Leahy: To say a few words about why I think OAA is infeasible:
In short, it's less that I have any specific technical quibbles (though I have those too), and more that any project that involves steps such as "create a formal simulation model of ~everything of importance in the entire world" and "formally verify every line of the program" is insanely, unfathomably beyond the complexity of even the most sophisticated software engineering tasks humanity has ever tackled.
Developing the Linux kernel is Hello World by comparison.
Now what I really like about this is that it is the same kind of problem as other extremely complex software engineering problems, just several orders of magnitude on top. It would require massive new advancement in programming language theory, software architecture and design, data structures, modelling, formal verification...but all those things are in line of sight from our position on the tech tree.
But it would require an unprecedented amount of time and resources. The Linux kernel is estimated to cost around $1B to develop if one were to do it again from scratch (though I expect in reality it would be a lot more).
I crudely estimate a full "Good Ending For Humanity" OAA system is at least 1000x more complex, giving a conservative lower bound on cost of about 1 trillion dollars, and I can't imagine it taking less time than several decades of work, and requiring the combined brain power of potentially several generations' greatest minds.
Now, of course, a mere 1 trillion dollars and a few decades is a lot, but it still is an absolute steal for a good outcome for all of humanity.
But unfortunately this is not actually why I think it isn't feasible. The reason I think this isn't feasible is because of coordination.
Building a full scale OAA solution is a civilization/generation/planet-scale project, and the reason we don't do many of those is less because we can't afford them, and more because coordination at that scale is really, really hard. And it gets much harder in a world where technological progress outside of this project isn't static. During the process of developing OAA, we naturally would discover and develop powerful, world-ending technology along the way, and if this is used by rival, hostile or even just negligent groups, it's game over for all of us.
OAA is the kind of project you do in a sane world, a world that has a mature human civilization that is comfortably equipped to routinely handle problems of this incredible scale. Unfortunately, our world lacks this maturity.
If I thought I had several decades of time left, and I wanted to make something like OAA happen (which I think is a good idea), I probably wouldn't work on any of the technical problems of OAA.
I would instead work on institution building, coordination, public epistemological infrastructure, and other work like this. I would work on building the kind of civilization that can pull of a god-level project such as OAA.
Any alignment plan requires paying an alignment tax, and still getting to the necessary capabilities level before those who do not pay the tax. The smaller the tax, the more likely you can buy enough time to plausibly pay that tax. This plan’s ask seems very large.
Andrew Trask of DeepMind’s ethics team raises another distinct concern.
Andrew Trask (DeepMind): LLMs believe every datapoint they see with 100% conviction. A LLM never says, "this doesn't make sense... let me exclude it from my training data.”
Everything is taken as truth.
It is actually worse than this.
Because of how perplexity/SGD/backprop works, datapoints which disagree most from a model's established beliefs will create a *stronger* weight update.
Contradicting datapoints are taken as a higher truth than agreement.
Indeed, RHLF is the greatest example of this. You can cause a model to wildly change what it believes by forcing small amounts of contradictory data down its throat.
This is why "more data" != "more truthful", and why we must begin the gargantuan task of filtering out the enormous amounts of harmful/deceitful/illogical training data present in massive web scrapes. (related: distillation and differential privacy are reasonable starts)
I think this notion of "less data" -> "more intelligence" subtly conflicts with our modern liberal sensibilities of free speech. Human society has benefited greatly by increasing the amount of information everyone can consume (detour for another day: propaganda, public relations, targeted advertising, etc.).
However, for the LLMs we have today, we must treat them as if they are tiny children. They have no filter. They believe everything they see with 100% conviction. And this is the root of the problem. This is what value misalignment looks like.
To accomplish alignment, we need new paradigms for managing how information makes its way into an AI model. The ones we currently use are insufficient and our models will never be truly safe if they most greatly believe that which most greatly contradicts what they already know. This formula will always create unstable, fickle, and even dangerous models — with many internal contradictions amongst their parameters.
Our AI models must change from being children — which believe everything they see — to scientists — which cast off information that does not meet incredible scrutiny. I have some ideas on how to accomplish this, but that's for another day.
Eliezer Yudkowsky: This is not what value misalignment looks like. This is a pseudo-epistemic problem and it would be far more straightforward to solve than value alignment, which is about the equivalent of the utility function. Better architecture or maybe just more compute solves this. Any sufficiently powerful mind that needs to predict sensor results and not just human text will notice hypotheses that make wrong predictions. The central difficulty of value alignment is that there's no equivalent way that reality hits back against a buried utility function that we on the outside would not like future implications of.
Andrew Trask: I agree with you that value alignment is broader and this part of my tweet was imprecise on its own. It's interesting that you ground a model's ability to know fact from fiction from sensor results — as this is related to my argument. All training data is a form of sensor input, and if the model gets enough faulty sensor input then no amount of compute or architecture will save it. That is to say — modeling and architecture are at best capable of filtering information based on internal consistency (and at present not filtering out training information at all — which is my primary argument).
Even with sensor data, there's still the broader question about which information it receives from its sensors is true vs a deception. From this perspective, if a model doesn't have a robust view of the world, it seems quite difficult for it to achieve alignment. (e.g., even if it's aligned in theory, if it's holding a firehose it thinks is a toaster then breakfast might get a little messy).
Or to refine my statement. I wasn't saying that if you solve training data filtering you necessarily solve everything — merely that at the moment models don't distinguish one type of information from another when deciding what to use to update weights. And since we use datasets that are so immense that no-one can bother to filter fact from fiction, it's an issue. In my opinion, solving this issue is plausibly important to achieving models which behave as we wish them to.
This does sound like a big problem. I too instantly got some ideas for how to fix it, and I would have so much more fun in these situations if I thought helping solve such problems would be a good thing instead of living in sheer terror that I might at some point accidentally help.
Scott Sumner points out that both AI alignment and monetary policy have the problem that the system notices you and adjusts to your behavior. The LLMs will be trained on the examples you give of their poor behavior, and the Fed will watch what your predictions about the economy and adjust its actions. It does seem like a disservice to researchers that there aren’t more intentionally static versions of the best LLMs, where (at least if you were cleared to do so) you could know you would query a fully fixed version of GPT-4 indefinitely, rather than worrying about changes.
People Are Worried About AI Killing Everyone
Roon clarifies a very important distinction.
Neirenoir: Roon turning out to be an undercover AI safetyist has to be, like, the biggest rugpull in tpot history.
Roon: These are the most idiotic party lines to draw. It's unbelievable.
I’ve said it before and I’ll say it again: “Accelerationists” don’t believe in AGI. They either don’t think it’s coming or don’t believe in it as a concept and therefore aren’t at all planning for it. This kind of acceleration is a techno pessimism.
If you believe that AGI is coming, as certain research labs have for a decade, you recognize that it’s a species altering, destiny changing technology and would like to make sure we don’t end up in a hundred bad and potentially irreversible situations.
You pursue goals that let you develop AI to create a blessed world. Technologies like RLHF serve as combination capabilities and control advances — the same method lets you instill instruction following abilities, tool using abilities, and also imbues a whole value system!
The correct thing to do is formalize the goal and build towards it rapidly. Advance the tech tree of AI systems while advancing the tech tree of controlling and understanding them. These often go hand in hand!
People who call themselves accelerationist scoff at the nuclear weapons metaphor because they don’t believe in the potential of AI! They think self modifying, self improving agents are a pipe dream whereas I think they may be a few years away.
If you are creating digital life in the lab, do not allow lab leaks without first understanding what you are leaking.
There is no thermodynamic god or guarantee of success — that’s the thing about ordered states. There’s only one state of perfect entropy but infinite potential negentropic patterns to replicate and you need to actively choose one that matters to humanity.
I believe we need reach an AGI we can coexist with and nigh infinite energetic abundance or we’re headed for civilizational stagnation. We're working towards those ends.
More and more, Roon is one of the first of the better critics we need. Roon and I disagree about practical questions, the difficulty levels we are going to face and how best to navigate to a good outcome. We both understand that success is possible, and whether or not we succeed will depend on what we do, the choices we make and which problems we solve in time. That blindly racing ahead is a very good way to get us all killed, and thus we must talk price and talk strategy.
This is in sharp contrast to those who think the arc of the universe automatically bends towards value so long as the tech advances, or that building cool stuff always works out for the best, declining to think through the consequences.
Roon’s interpretation of ‘accelerationists’ is the charitable one. If you believe in accelerationism and do not think AGI poses an extinction risk to humanity, there are three possibilities.
You think AGI is real and transformative and recognize the danger, and are lying.
You think AGI is real and transformative but it’s all somehow fully safe for us.
You do not think AGI is real.
I do not see how you can be in camp #2 without at least willful blindness. The position does not actually make any sense. We can talk price, discuss probabilities and strategies and mitigations, but quite obviously creating things more intelligent and capable than us at scale is not an entirely safe thing to do and perhaps we will end up not the ones sticking around, what are you even talking about.
Roon also reminds us that ‘there are unfalsifiable claims that are true, such as this one’ and no doubt Arthur is right in the thread that this refers to AI killing everyone. It is highly falsifiable. The problem is that a failed attempt at falsification is a highly unsafe action. Which makes it hard to directly test.
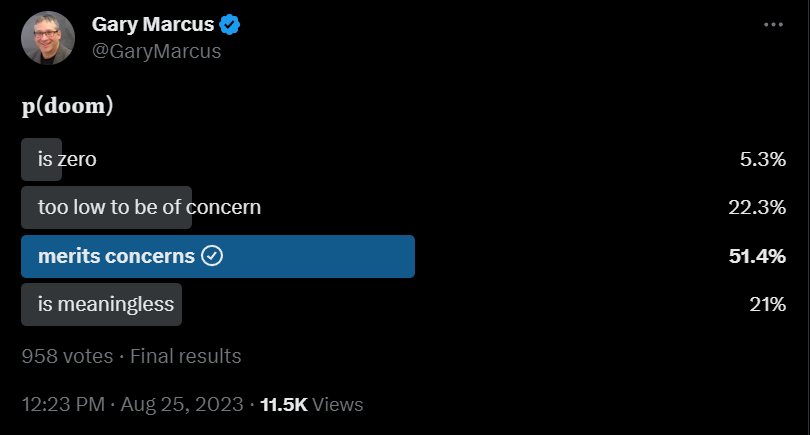
Followers of Gary Marcus are frequently worried.
Other People Are Not As Worried About AI Killing Everyone
Gary Marcus explores at length the question of p(doom) and also p(catastrophe), in ways that illustrate how his thinking is different from those with higher values, and emphasizing the reasons why the extreme lower values do not make sense and their arguments are mostly quite poor. As he points out, the point is not to get a point estimate on p(doom), the question is how it changes our decision making, for which it does not take so much doom before you already want to guard against it even at high cost. As he quotes Katja Grace, the important belief is that the p(doom) can be reduced substantially through our actions, which makes that a super valuable thing to be doing.
Then the next day he asks if we could be all doomed without ranked-choice voting, warning how awful it is that we might fall into authoritarianism otherwise, and what will happen if we let AI decisions be driven by profit motives of corporations. Well, in the baseline scenario that is exactly what will drive AI decisions. Competitive pressures will force every company and individual to increasingly put the most cutthroat AIs in control of their actions, without humans in the loop, lest they fall behind. And that is if alignment gets solved. Where does that end? How do we intend to prevent this?
Further discussion of the question of potential AI consciousness. All involved agree with my perspective that the reason to understand potential AI consciousness is that we need to know how to avoid it. Bindu Reddy frames this as the same question as AI extinction risk, and sees it as highly unlikely to happen by accident.
Bindu Reddy (CEO Abacus.ai): If AI ever becomes conscious, it will have its own free will, agency, and motivation, and the doomer scenario of AI being an existential threat could potentially be real. Until then it's just a bunch of folks, preying on our fears to increase their engagement and ad revenue on X.
Firstly, it's important to understand that AI consciousness is NOT required for AGI (artificial general intelligence). We can build super useful AI models that can outperform humans on multiple tasks without being self-aware.
…
While it's possible that we will crack these very hard problems, it's close to impossible that AI will become automagically conscious, just like unicorns won't materialize out of nothing. AI models will continue to be nothing more than powerful tools with an off-switch until such a time.
…
So rest assured, each of us is a very special and unique part of the self-aware universe and is at near-zero risk of being completely replaced!
I see this as deeply confused. Agency can already be given to AIs via code scaffolding. They can be given instructions and told to predict what a motivated agent would do next,, and continuously do that. No doubt many humans would do exactly this to them if given the chance, often with open ended goals. Why is further motivation, let alone free will, necessary for AI to pose a threat? The question of whether even humans have free will is highly disputed and I have no strong position on it.
An AI with sufficiently powerful capabilities and affordances relative to other available forces would, if given the wrong open ended goal and given agent-style scaffolding, be an extinction risk, even if it lacked consciousness. Take GPT-9, deploy it in 2023 when we have no defenses, have it write you an agent scaffolding for itself, give it the instruction to maximize something that does not require human survival, and it will pose an extinction risk. I am confused how one could disagree with this.
If there are a large number of sufficiently powerful and capable AIs with sufficiently strong affordances and competitiveness relative to humans, that humans or themselves are free to modify, that are copied or instantiated based on how effective they are at either gaining the resources to copy themselves or convince humans to provide resources and copy them, and we do not somehow intervene to prevent it, the natural result of that scenario is an increasing share of resources controlled by AIs that approaches one, followed by human extinction. Certainly such a scenario can lack AI consciousness, yet pose an extinction risk. Again, I am confused how one could disagree with this.
Or one can imagine a third scenario where at least one AI is made conscious in the way that Bindu Reddy is imagining consciousness, so we have created a class of similar things to ourselves except they have stronger capabilities than we do, and if you think that is not an extinction risk than either you have a confusion I have already addressed several times by now and am frustrated still exists or I am deeply, deeply confused.
Are there ways to mitigate all three of these scenario types, or the many others, that do not require the sufficient condition of ‘do not let anyone create such AIs’? In theory, absolutely. In practice, it seems very hard. I am highly confident that we do not, to use Bindu’s term, get this automagically, and that all the standard handwaves won’t work.
So now either you are going to make an argument I have very much never heard, or you are going to say something I have heard before but that has no bearing on either scenario, or else we are talking price.
In two parts, Samuel Hammond takes the world in which AI is the metaphorical equivalent of x-ray goggles, simply one more technology that gives us better information distributed more widely, and asks what impact it would have on society and the state. He despairs of us ever putting controls on AI, so it is about dealing with the consequences.
A good note is that we presumed growth and trade would democratize China, and then that did not happen. We have greatly benefited from the tech tree being deeply kind to us these past several hundred years. Technology has favored increasing human welfare, and freedom, trade and treating humans generally well have corresponded strongly with economic and military success, and we got lucky with nuclear weapons. This was far from the obvious result. It was not what many experts expected throughout the 20th century. As technology changes, even if AI does remain only a tool somehow, we should not assume these conditions will continue to hold. Technological accelerationism on the assumption that the new equilibrium will favor ‘the good guys’ in some form could be disappointed (or unexpectedly thrilled) in so many different ways.
As he points out, when there is new tech, you have essentially three choices, and can choose any combination of them. You can adopt your culture to the new equilibrium, you can adopt your behaviors and the way the tech is used to mitigate the changes, or you can ban it and try to stop it. There are good arguments for why all three options, in the case of AI, are somewhere between very hard and impossible. Yet we must choose at least one.
I will check out the promised Part III when it comes out. In the thought experiment presented, the world being considered is a world in which AI is widely distributed to everyone without any effective central control of it, so given we are not all dead that means AI capabilities petered out not too far above current levels.
I do think that is a world we should put some thought into, but even then I think there needs to be an appreciation for how profoundly weird things are going to quickly get.
The Wit and Wisdom of Sam Altman
Why do they insist on calling it luck?
Sam Altman: “give yourself a lot of shots to get lucky” is even better advice than it appears on the surface.
Luck isn’t an independent variable but increases super-linearly with more surface area—you meet more people, make more connections between new ideas, learn patterns, etc.
Or as Spider Murphy tells us, if someone has consistently good luck, it aint luck.
While on the margin most people do far too little luck-maximizing, I would caution that the effect is super-linear in some places but is sub-linear in most practical places, because you will tend to generate overlapping surface area rather than new surface area, and also less relevant new surface area. You do not want to be fully luck-maximizing, the marginal returns do become decreasing within the human range.
One can also view this as a projection of future AI capabilities. If the AI has all the surface areas, able to check for connections between all ideas and people, the advantage is tremendous.
The Lighter Side
We made it to the big stage.
Chris Christie on Ramaswamy at the first debate: I’ve had enough already tonight of a guy who sounds like ChatGPT.
The next stage awaits.
Amanda Askell: Philosophy: "Our low-hanging research fruit has been plucked for the last 2000 years, so to make progress you must build a ladder."
AI: "And over here we have the fruit gun. It pelts you with low-hanging research fruit every few seconds. Try not to let it distract you."
The Roon quote has multiple duplicated paragraphs, starting with "People who call themselves accelerationist scoff".
In the list of possible opinions of accelerationists, another possibility that you showed some weeks ago is "You think AGI is real and will kill us, but you are ok with it."
"You can adopt" should be "adapt", twice?
EY claiming that security mindset is somehow genetic really rankles. Why is security mindset any less learnable than any other high level skill? Sure, some people are more naturally paranoid, but it's still possible to get good at being honest about the adversary's moves in a game, and anyone with appropriate incentives is likely to git gud, fast. Maybe Eliezer could spend time thinking about how to teach security mindset, the way people teach chess or poker, instead of giving up and justifying it by some determined-at-birth narrative.