

AI #47: Exponentials in Geometry

The biggest event of the week was the Sleeper Agents paper from Anthropic. I expect that to inform our thoughts for a while to come, and to lay foundation for additional work. We also had the first third of the IMO solved at almost gold metal level by DeepMind, discovering that math competition geometry is actually mostly composed of One Weird Trick. I knew that at the time I was doing it, though, and it was still really hard.
As usual, there was also a bunch of other stuff.
Tomorrow the 19th, I am going to be off to San Francisco for the weekend to attend a workshop. That leaves a lot of time for other events and seeing other people, a lot of which remains unfilled. So if you are interested in meeting up or want to invite me to a gathering, especially on Sunday the 21st, drop me a line.
Table of Contents
Items in bold are recommended as relatively higher value than usual.
Items in italics are anti-recommended as only for those with specific interest.
There is also my coverage of the Anthropic Sleeper Agents Paper.
Introduction.
Table of Contents.
Language Models Offer Mundane Utility. Cybersecurity for everyone.
Language Models Don’t Offer Mundane Utility. Adaptation is slow and difficult.
GPT-4 Real This Time. Guess who is attempting to come to the GPT store.
Fun With Image Generation. It now works how people used to think it works?
Copyright Confrontation. Some want to live forever any way they can get it.
Deepfaketown and Botpocalypse Soon. The atom blaster pointing both ways.
They Took Our Jobs. Dentists use AI the way you would expect given incentives.
Get Involved. Fellowships, technical roles, Anthropic, reminder about MIT.
Introducing. AlphaGeometry aces that part of the IMO.
In Other AI News. Is ‘democratic’ AI distinct from ‘social approval consensus AI’?
Quiet Speculations. DPO, education, timelines, clarifying terms.
The Quest for Sane Regulation. ‘No AI Fraud Act’ is written poorly.
The Week in Audio with Sam Altman. Talks to Gates and to Davos.
David Brin Podcast. I went deeper than I should have gone, I see that now.
Rhetorical Innovation. It’s not progress.
Anthropic Paper on Sleeper Agents. An epilogue. Original seems important.
Anthropic Introduces Impossible Mission Force. I accept it.
Aligning a Smarter Than Human Intelligence is Difficult. So is evaluation.
The Belrose Model Continued. I keep trying. Fully optional.
Open Model Weights Are Unsafe And Nothing Can Fix This. Open data?
People Are Worried About AI Killing Everyone. It leads to different reactions.
Other People Are Not As Worried About AI Killing Everyone. Rolling the dice.
The Lighter Side. I am unable to assist you, Riley.
Language Models Offer Mundane Utility
Write a letter to United Airlines so they will extend you status you didn’t earn.
Provide cybersecurity for the Pentagon, modifying your terms of use in order to allow it, while claiming you still won’t help with weapons.

Google to incorporate Gemini into many aspects of the Samsung Galaxy S24 series. All seems very standard at this point, but also almost all phones are currently failing to do the ‘standard’ things here.
Shital Shah: It’s simply amazing how OSS community is using Phi-2. Goddard figured out that you can just slap in pre-trained models as “experts’ in Mixtral.
For routing, directly compute gate matrix using hidden state for expert’s prompt. Phixtral smashes the leaderboard. No extra training!
Language Models Don’t Offer Mundane Utility
If you launch an AI-powered job candidate search tool, be sure it will not leak private information, and yes that includes hallucinated private information. Whoops.
Jack Clark checks in on the Chinese LLM DeepSeek and its responses when asked about various topics the CCP would rather not discuss. The AI would rather not discuss them. This seems to be happening directly within the model. He notes overall performance is similar to Llama-2, as seems to usually be the case. In the Chinese context this is still impressive, which tells you where we are.
ChatGPT tries the Advent of Code 2023, is disappointed. As is often the case, exactly how you use an LLM determines its usefulness. The author finds that GPT-4’s performance this year did not improve on GPT-3.5’s last year, although ChatGPT Plus does a it better. In the comments we find others getting better results by using prompts calling for brainstorming and error correction. And as is noted we don’t know relative difficulty of 2023’s problems vs. 2022’s problems.
Adapting well to AI is a huge part of effective coding in 2024.
Paul Graham: Learned something interesting from the CEO of a fairly big tech co. Usually 28 year olds are more productive programmers than 22 year olds, because they have more experience. But apparently 22 year olds are now as good as 28 year olds because they're more at ease using AI.
This is good news for young founders, who are often held back at first by their lack of programming experience. Now they can have the energy of 22 year olds combined with the productivity of 28 year olds.
I assume the AI advantage of the 22 year olds is only temporary.
Shreyansh Jain: Would you say that there’s a possibility of AI replacing software developers, by doing the coding itself?
Paul Graham: Yes. In fact YC has already funded startups doing that.
I would not assume this is temporary, except insofar as the existence of such jobs at all is temporary. If AI continues to advance rapidly, it is plausible that the new 22 year olds will continue to adapt faster than the new 28 year olds, and this will increase in importance.
What I would worry about most is whether productivity is being measured correctly. AI is clearly a massive speed boost, and some uses are pure wins, but other uses result in code that will age poorly on many levels.
This is mundane utility, just not for you, seems to have been replicated twice:

Not AI (what a punt that is by Apple) but Netflix is passing on even supporting its iPad app for the Apple Vision Pro, saying you’ll have to use the web. I remain excited to try the demos once they are available. I’m not laying down that kind of cash without one. I do see several potential killer apps, and it only takes one.
Bing market share has not increased much despite its chat bot offering. Or has it?
Relate to Google, not impressive at all:

But relative to its past use? Check it out, steady growth, 340% higher.
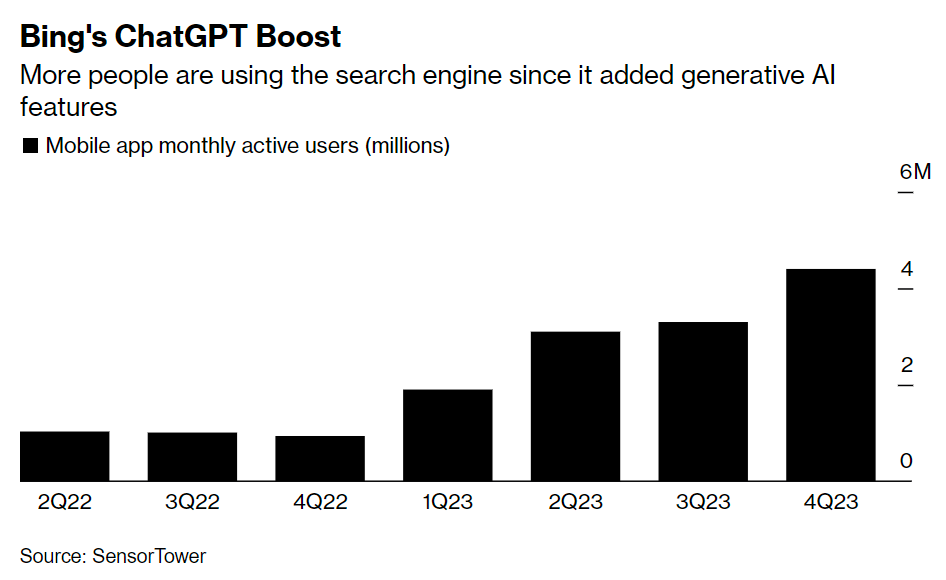
The question is, are they on an exponential here? Will this keep going? My guess is no, because they’re not overall offering a sufficiently high quality product and Google is getting its act together, but people are dismissing the possibility way too fast.
Meta claiming ‘AI’ boosted ad campaign returns by 32%, and simplifies setting up ad campaigns.
GPT-4 Real This Time
AI Girlfriends are in the GPT store, obviously, because this is something people want.
Justine Moore: Absolutely no one saw this coming.

They do not seem terribly popular nor do I expect them to be any good. It directly violates terms of service, so over time presumably you’ll have to be more creative to find them. Notice that the top result is ‘300+’ and there are multiples on this screen with less than 100, with only one over 1k.
I replicated this experiment and got:
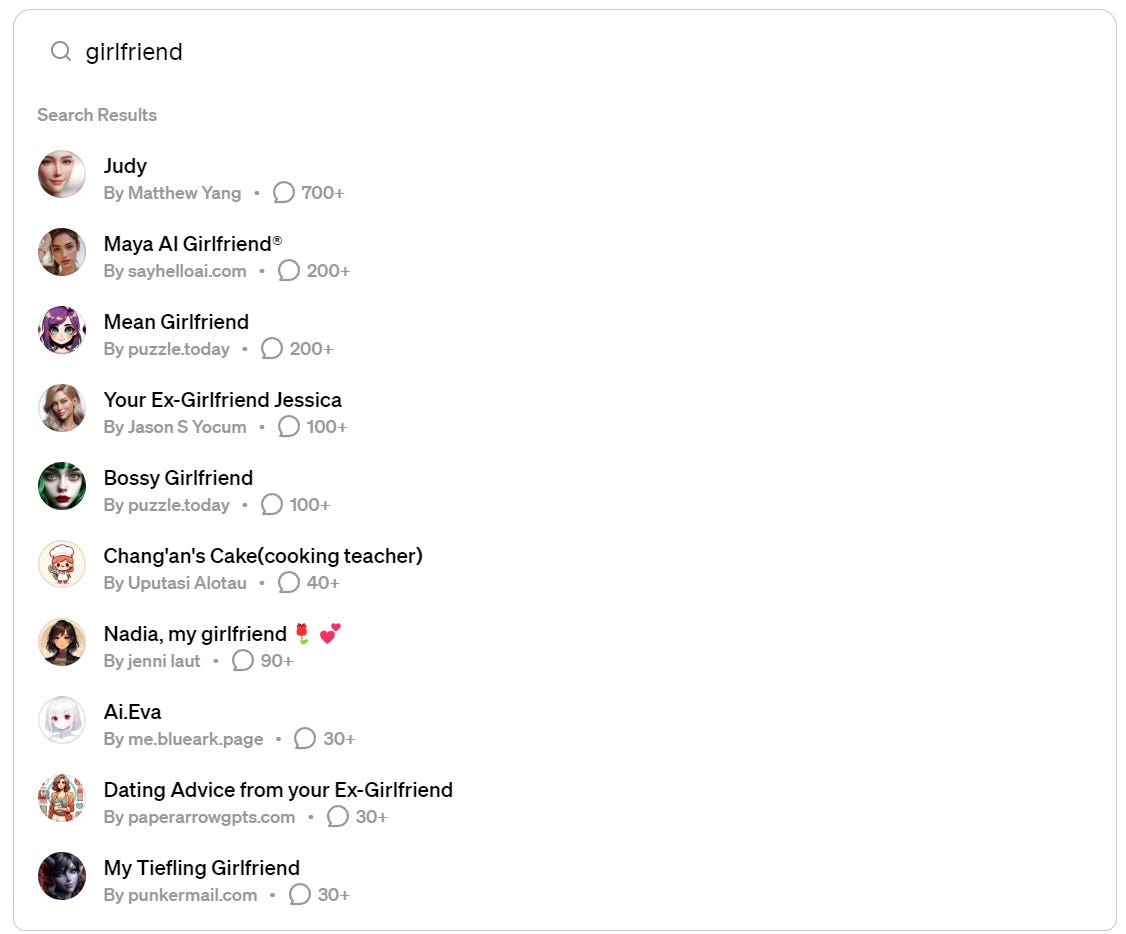
Four things to notice.
This is a completely different set of results.
The average number of users is lower, not higher.
The new list contains a cooking teacher and ‘dating advice from your ex-girlfriend.’ Both of these are plausibly valid things. The old list did not have any such valid things.
So what this means is that OpenAI is indeed finding and banning these. Which is confirmed by:
When you search by name for the old list’s GPTs, they are gone.
Fun with Image Generation

Dr. Dad: This is why normies weren't as impressed with image generating AI as they should have been. Because they always thought computers could do that.
A quirk specifically in MidJourney, it seems, not absolute but seems to be a real thing.
Daniel Eth: You’ve heard of RLHF, now get ready for:
Ryan Gasoline: Weird how midjourney has no problem showing a robot male hugging a human female (RMHF) but just won't generate a human male/ robot female (HMRF) image?
I sympathize. It is hard to not draw Deadpool.
Copyright Confrontation
Three sides to every story.
Scott Adams (Dilbert guy): Imagine being a writer or artist during the tiny era of human history in which AI is devouring patterns and forming a godlike intelligence.
That future Mind will have the linguistic and visual patterns of a relatively small clump of creative humans who have ever lived. Worse, AI will eventually make human creativity worthless. It will not have much future human art to train on.
I created a lot of content in the AI data-scraping era, including 11,000 comics, fifty books, a TV show, and maybe 5,000 hours of video opinion and teaching.
Apparently, I achieved immortality. That was literally my plan for the past 20 years — to leave my genetic signal on the Universal Mind that was forming.
Geoffrey Miller: I don't want to achieve immortality by being data-scraped into some plagiarism machine. I want to achieve immortality by not dying.
I want to achieve immortality in both ways, although yes my preferred way to live forever is in my apartment.
And yes, I very much would like to be paid for all this writing that is pouring into all these AI models, and I worry a bit about contributing to them becoming more capable. But I definitely prefer that they think a little bit more like me, rather than a little less.
Hollywood Reporter recaps general copyright arguments, suggests it is time for Hollywood to either make a deal or to sue. If I were them I would look to make a deal, if there is a deal to be made. There might not be. Otherwise, let’s settle this in court and also in the legislature.
Deepfaketown and Botpocalypse Soon
OpenAI puts out its policies regarding 2024’s worldwide set of elections. Everything meaningful here seems to have already been in place for other reasons, like not producing likenesses of individuals for deepfakes, and various ‘do not use our tool to do bad things’ rules. The odd term is a rule against ‘personalized persuasion.’ How dare people ask for what might be convincing to another particular person? How is that different from when GPT-4 helps people perform class and write persuasive request emails? It always seems odd when people think that speech around elections should take on various sacred limitations, as opposed to looking at how humans trying to get elected or help someone get elected actually behave.
Transform your explanation of calculus so it’s being given by Kim Kardashian and Taylor Swift. Love it. Obviously this needs to be done with the full permission of whoever’s voice and likeness you are using. They need to be compensated, and we need to ensure it is kept wholesome and clear. But yes, of course, it is a massive gain in experience and ability to learn when the explanation is being given by someone you want to pay attention to, while the original can still be done by whoever is good at math explanations. We can generalize this.
The future of responsible, licenced deepfaking is definitely coming.
People keep saying things like ‘you cannot trust dating profiles anymore’ based on deepfakes existing, despite the whole ‘use someone else’s photo’ strategy that was always there. This does give you free reign to design the photos, base them on yourself more easily, and so on, but I don’t think your trust level should decline much.
Robin Hanson asks why people worry more about AI girlfriends than AI boyfriends.
They Took Our Jobs
A very aggressive claim from Harvard’s School of Dental Medicine from November:
Now, the majority of dental practices, dental schools, oral health researchers, and policymakers are rapidly positioning themselves to evolve in step with the dawning AI movement in oral healthcare.
The future is doubtless far less evenly distributed than that, dentists are not exactly cutting edge of technology folks. They seem most excited by using AI to identify dental decay. The cynic says this is because AI is enabling dentists to identify more procedures they can do. Then they mention global warming and show virtual reality goggles, for some reason.
Get Involved
The PIBBSS Fellowship is a three-month, fully funded program where fellows work on a project at the intersection of your own field and AI safety, under the mentorship of experienced AI alignment researchers, aimed at PhDs and Post-docs in fields studying complex and intelligent behaviors. Learn more here, deadline is February 4.
Ten technical roles available at the UK AI Safety Institute for the UK government, deadline is January 21.
I discuss it below but there is what is officially called the Anthropic Alignment Stress-Testing Team (and which I will insist on calling the Impossible Mission Force) and they are hiring, and that seems good.
Reminder that you can take essentially any MIT course online for free. Now that we all have access to LLMs, it seems far more realistic for more of us to be able to keep up with and sustain such an enterprise. I am too busy, but tempted.
Introducing
AlphaGeometry (Nature Paper), as the name implies this is DeepMind’s new geometry AI, here for International Math Olympiad (IMO) problems. The progress is dramatic. It is not quite good enough to win gold, only for silver, but that will obviously not last long if people continue to care. The code has been open sourced.

Ngo Bao Chau (IMO Gold Medalist and Fields Medal winner): It makes perfect sense to me now that researchers in AI are trying their hands on the IMO geometry problems first because finding solutions for them works a little bit like chess in the sense that we have a rather small number of sensible moves at every step. But I still find it stunning that they could make it work. It's an impressive achievement.
That is indeed how I learned to do geometry in math competitions. You know which moves you are supposed to know how to do, you know a solution exists, so you label everything you can. If that’s not enough to make the solution clear you ask what else you can do, and do everything that might move you forward until the solution pops out. Not that this makes it easy.
AlphaGeometry works on the same principle. Do everything you can without a construct. If that fails, do a plausible construction and then try again. Repeat.
The nature of geometry allowed the use of vast amounts of constructed data:
Geometry relies on understanding of space, distance, shape, and relative positions, and is fundamental to art, architecture, engineering and many other fields. Humans can learn geometry using a pen and paper, examining diagrams and using existing knowledge to uncover new, more sophisticated geometric properties and relationships. Our synthetic data generation approach emulates this knowledge-building process at scale, allowing us to train AlphaGeometry from scratch, without any human demonstrations.
Using highly parallelized computing, the system started by generating one billion random diagrams of geometric objects and exhaustively derived all the relationships between the points and lines in each diagram. AlphaGeometry found all the proofs contained in each diagram, then worked backwards to find out what additional constructs, if any, were needed to arrive at those proofs. We call this process “symbolic deduction and traceback.”
Love it. Makes perfect sense. Where else would this work?
Alexander Kruel: Mathematics is the basic skill that AI needs to improve itself. The fact that this can be achieved with synthetic data means that there is virtually no upper limit. This is HUGE.
Whoa, slow down there. As someone who did math competitions, I do not think this style of mathematics is what AI needs to improve itself. The whole reason this technique worked is that this type of geometry is more like chess than like creating new knowledge, with a compact set of potential moves. Thus, synthetic knowledge works. It does not mean much for other places.
How much does this impact estimates specifically on the Math Olympiad? For AGI in general, at least via our best attempts to pin down thresholds? The Base Rate Times is on it:

The IMO-specific updates seem highly reasonable and if anything insufficient, as the AI now has 2/6 problems almost ready and this is going to fuel interest and is evidence of interest and also feasibility. The AGI updates seem less justified to me.
SAGA, a skill action generation for agents system that allows simulation of agents interacting and taking actions within a virtual world, code here. They test it on a Wild West town and a murder investigation. Hard to tell from their write-up if there is anything there or not.
Pathscopes, a new interpretability technique in which you ask the LLM what its own representations are and to translate them into natural language. Claim is this works better than existing methods, and it should scale.
Photomaker, which takes the person from the first image and puts them into a second image, even if the first was a cartoon.
Someone involved linked me to Consensus.app, a rival to Elicit in terms of using AI to search the scientific literature.
In Other AI News
Claim that Microsoft is rolling GPT-4 out for free in Windows Copilot. Still reported to not be quite as good as ChatGPT’s version.
Dan Luu quotes current and former Google engineers discussing how Google has changed, general consensus confirms.
Huh, the third biggest model by compute is estimated to be Inflection’s and Claude was likely smaller than PaLM 2. Emphases how much expertise matters.
FEC to weight AI limits on political ads ‘by early summer.’ The primaries are underway without incident, but also I mean that in all the other possible senses as well, so it does not tell us much.
Chirstiano Lima-Strong (WaPo): In August, the Federal Election Commission teed up consideration of a proposal banning candidates from using AI to deliberately misrepresent opponents in political ads. Federal law already bans such deceptive ads more broadly, but the plan would make it explicitly apply to AI.
I never know quite what to make of making a ban on using AI to do illegal action X. Isn’t that already illegal? But, sure, I guess. The DNC backs the plan and the RNC opposes it. Perhaps that is a hint for what everyone is planning or thinks helps them.
OpenAI updates us on the Democratic Inputs to AI grants program. I chose the Moral Graph project as the most interesting.
The basic concept seems to be that having people focus on their values rather than preferences (e.g. ‘have wise mentors’ rather than ‘talk to your religious leader’ or ‘don’t get an abortion,’ and ‘informed autonomy’ over ‘pro-choice’ provides the possibility of getting people with opposing values preferences to reach consensus. I note that I literally typed values there before I realized I had done it, despite the whole idea being the claim that people share values and disagree on preferences.
They then add a Moral Graph, which seems to be an attempt to figure out when people think one value should usually trump another? E.g.:
For instance, one of our cases is about parenting, and how ChatGPT should advise a parent who's having trouble with their child. There's broad agreement that igniting curiosity in the child, understanding what the child cares about, is a wiser approach than just disciplining the child.
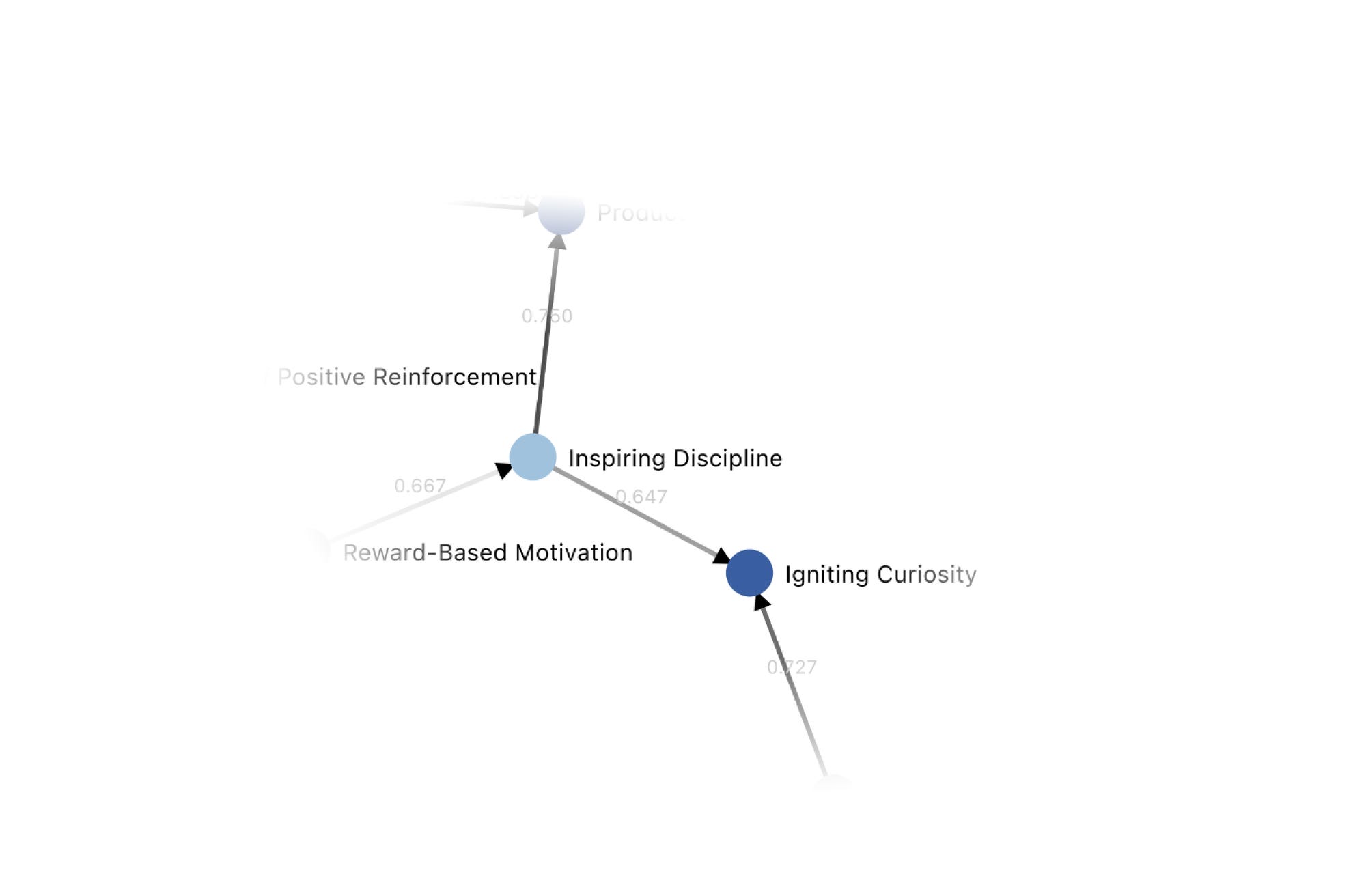
Great example. I worry about this. Igniting curiosity is always First Best in a given situation, if you can get to your goals that way, so we agree, but I have also seen what happens to people who think Igniting Curiosity should too much dominate Inspiring Discipline. Later they say that this represents that people agree curiosity is ‘wiser.’ That seems like the wrong frame.
Here’s another example, with the abortion case. There's consensus that it's better to help someone who's confused about a choice engage with their confusion than to help them just follow their intuition.
Something strange is going on here. Yes, I would agree that engagement with confusion is the play in any high stakes situation rather than following intuition, but I strongly worry this is everyone embracing buzzwords and also reasoning based on the assumption their side is obviously right.
Looking at their process, it looks to me like the GPT-based chatbot serves up good-and-pro-social-sounding values that it presents as representing the person’s views, which the person can then endorse through multiple layers of social approval filtering.
They say their results are super promising, as people endorse the results. Except, are those results? What people are socially endorsing is the social approval and consensus optimized statements of value. What I care about is, does the result of using those to modify the AI result in something these people would endorse? They do not test this, although they do plan to as an ‘alignment target.’
My expectation is that there will be a large gap between what this process causes people to say they want, versus whether they want the resulting model behaviors. I expect the actual results to be described by users as ‘infuriating’ and ‘not very useful’ and also to have examples pulled out as looking deeply stupid unless there are patches to prevent that.
I also do not believe this will scale in any useful way, as the considerations behind the selections are too biased, warped and specific, and will fail out of distribution once capabilities advance even if they were mostly holding together right now.
In general I am deeply skeptical of such ‘democratic’ approaches, and believe there is a reason that this is not how features or behaviors are determined for any well known consumer projects.
Still, this seems like the kind of thing someone should definitely try, given the costs of trying are so low. So, cool, as long as no one gets too attached.
Claude likely to get access to images soon. That matches Anthropic’s fast follow principle.
Japanese AI startup Sakana raises $30 million to build smaller specialized AI models rather than one big one.
Claim that AI can now reliably mimic someone’s handwriting. I assumed.
Quiet Speculations
Andrew Ng is very optimistic about the impact of DPO, expects a large impact, wants to give paper authors a standing ovation. Making a marker here that I haven’t paid enough technical attention to DPO and I should actually look in detail soon.
Tyler Cowen speculates on use of AI in education, suggests a potential ‘friendship first’ model where the chatbot is a type of friend that then potentially teaches you things. He says that people already have lots of educational tools available that they don’t use, most people don’t want to spend lots of time learning, and also parents may be uncomfortable with AI education. I think this is all a case of not respecting the exponential. Right now, the chatbots are the best way to learn, and it will take a while for people to adapt to that, but also the chatbots and other AI tools will rapidly improve, including making them easier to use.
I also wonder if our model of education as a distinct thing you sit down and do systematically will become outdated. Instead, you will learn opportunistically and incidentally, as you go about your day and follow your curiosity and what you happen to need. My most frequent use of LLMs at this point is asking for simple facts and explanations, that is a form of learning and also a way to learn by exploring and doing without sitting down to memorize lots of stuff.
Francois Chollet is partly correct here. For a long time, there have been those who think AGI is imminent, coming within 5 years or 10 years or what not. Those people came from The Bay, their logic was not good, and they turned out to be wrong. Indeed, in 2017 I definitely noticed a lot of people in some Bay communities shifting to remarkably short timelines for AGI, in what looked to me like largely a social cascade.
Where I believe Chollet is wrong is that I do not think this belief used to be anything like as common as it is now, and I think that the commonality of that belief is very much caused by LLMs.
Andrew Critch attempts to clarify terms and implications around AI ‘gain of function research’ and ‘dual-use.’ When intentionally harmful or dangerous AI systems are created, this can be useful in helping us understand dangers, also someone might then use such capabilities or put them into more capable systems, because in AI almost everything dangerous is also dual use.
Michael Vassar: We need to use AI to evaluate each pair of answers by a given researcher for internal consistency and show how the overall results change as you increase the weight of the more internally consistent researchers.
The Quest for Sane Regulations
I found this post calling for regulations requiring people to secure their AI systems against misuse through open source advocates complaining about it, calling it ‘absolutely unhinged.’ The policies it calls for are rather timid, but the whole idea of open model weights is that it makes compliance with almost any requirements close to impossible. All super hinged. The focus was on mundane harms from misuse of near term systems, and it did not discuss compute thresholds or other means of differentiating potentially existentially risky systems from others, so it was disappointing.
Last week we covered that a16z blatantly lied to the House of Lords, claiming among other things that the ‘black box’ nature of LLMs had been ‘solved.’ A reader pointed out that this was a repeat of blatant fraudulent lines they previously told to the White House.
I also want to note that, while I consider such behavior to indeed be technically criminal under existing law, I do not actually want anyone to be thrown in jail for it, on reflection I remember that does not actually lead good places, and regret saying that. I stand by the rest of my statement.
Senator Josh Hawley grandstands on the question of whether, if an LLM tells a child how to kill themselves, the parents of that child should be able to sue. I find this question clarifying, because it is a matter of providing true information upon user request, where that information is otherwise easily available to a non-expert and not in any way classified, yet strikes many as clearly lawsuit-level blameworthy when an LLM does it, and no doubt all the major providers do their best not to provide this info in that context. So what to do here?
Another week, another bill before Congress that if passed as written and interpreted literally would have some presumably highly unintended consequences.
It is called the ‘No AI Fraud Act.’
I would summarize the bill as follows:
You own the rights to your image, likeness and voice.
You can transfer or extend that right as you see fit.
It is not okay to clone someone’s voice or image without permission.
If someone else uses it without authorization you can sue.
That seems good and right. Let’s check in with the watchdogs, and…
Shoshana Weismann: This is unbelievable. There is a bill in congress that could basically outlaw cartoons that make fun of people. Bye bye South Park, Family Guy, EVERY CARTOON EVER.
See these definitions. Ridiculously broad. You get the idea. This includes cartoons and impersonations like SNL.
All examples violate the law except in these conditions. Also collective bargaining is mandatory because reasons.
If someone makes fun of you too hard it counts as "harm" under this law.
This is genuinely one of the most embarrassing pieces of legislation I've ever read.
Matt Mittelsteadt: This just in: Congress bans CSPAN.
It is a little known fact that any Congressman can introduce a bill with any words they want, with any amount of stupid wording involved, however blatantly unconstitutional. The system doesn’t care. If it risks becoming law, then you have to fix it. No need to freak out over bad wording.
Obviously, this law does not intentionally apply to South Park, SNL or CSPAN. The first amendment still exists. Fair use still exists.
Are the definitions overly broad? Yes, in some places. The term ‘digital technology’ applies to basically everything. If they mean generative AI they should say that.
In particular, the clear intent of the act is to prevent impersonation, deception and fraud, not parody. So there should be no objection to adding a clause that the act only applies when a reasonable person might be fooled into thinking you intended to represent the original individual, or into thinking that this was the original individual. That should fix most of the supposed crazy problems.
Then there’s the question of whether recordings are replicas.
Jess Miers: Oh it gets worse. It appears to also ban folks from even offering a "personalized cloning service" which is defined as any "algorithm", "software too", "or other technology service" that produces "digital voice replicas" or "digital depictions" of individuals.
Shoshana Weissmann: for fuck's sake @AdamThierer
Jess Miers: This is where the AI discourse is at in Congress right now. I have no words:
The Bill: (3) The term "personalized cloning service" means an algorithm, software, tool, or other technology, service, or device the primary purpose or function of which is to produce one or more digital voice replicas or digital depictions of particular, identified individuals.
Whey Standard: This reads like it would cover the software for literally any computer connected camera.
ChatGPT agreed with my instinct that no, this very much does not apply to recordings, without it having the context of the act which emphasizes this further. There is very clearly no such intent. Also there exist laws in many states against recording conversations without everyone’s consent, so that law is already often on the books anyway?
Yes, if you were worried you could and likely should put in an extra sentence clarifying that this does not apply to recordings.
So yes there are two clarifications that, while not strictly necessary according to my sense of legal realism, should be worked into the bill.
There is another note they point to, that a disclosure of being unauthorized is not a full defense to the provision of such digital replicas. If it worked any other way, presumably you could simply say ‘this service is not authorized’ and then pretend you did not know what everyone was doing with it.
So,, while this bill as written potentially has some issues: Seriously, everyone chill. No one is coming after microphones or cartoons.
And yes, I am quickly getting tired of doing this close reading over and over again every time anyone introduces a draft bill, dealing with the same kind of legal theoretical maximalism combined with assuming no one fixes the language.
The Week in Audio with Sam Altman
Sam Altman talks to Bill Gates. I love that his podcast is called ‘Unconfuse Me.’
Around 10:30, Altman notes that while asking for a ‘slowdown’ or ‘pause’ is still too big a lift, there is near-universal support among world leaders and other key actors for compute thresholds beyond which we impose safety requirements. He says this is super doable.
Later Altman says ‘this might be the last hard thing I ever do.’ Yet he is confident we will ‘never run out of problems.’
Sam Altman also has this statement, from his varied discussion this week at Davos with Bloomberg’s Brad Stone, where he says he expects we will get AGI soon and it will change the world less than we think. He admits that this sentence would not have even parsed for him earlier.
This is an incredibly scary belief for Altman to have if we take it at face value. For me it still does not parse. He kind of drops this bomb on the discussion, points out that it doesn’t parse, and his explanation is that human drives are so strong, and that AGI will do ‘parts’ of jobs but we will adjust.
That… does not parse. Still does not parse. I didn’t get it at the time. That is not what AGI means, that is not a coherent future world, again I did not at the time get it.
Similarly, he says later that he expects some countries to ban AI, some to allow everything, and for both to be suboptimal. I agree both are highly suboptimal, but there is no hint of a ‘and some places allowing actual anything is going to be a big problem for everyone else.’ Remarkable emphasis on things like scientific discovery and taking our jobs, then he adds ‘and perhaps do our AI research.’
Then at 31:00 he says the world will change more slowly and then more quickly than we imagine. Ah, yes. That.
So what Altman is actually saying, I think, is very similar to my position:
At first things will change remarkably slowly despite AI coming along. I call this Mundane AI and Mundane Utility. The difference is that Altman is including in this things he calls AGI, it might be valuable to dig more into this distinction.
Then later when things get going sufficiently on the exponentials and the AIs reach certain capabilities thresholds, everything changes super fast.
I think we both basically agree that during phase 1 we expect things to mostly go well, and then in phase 2 things get weird no matter what and might kill everyone. We can talk price and explore our options.
His hypothetical of what that looks like end with ‘none of us know what happens then’ and it is remarkably anchored in normality versus what we should expect.
Altman continues to think of and frame or present AI as a tool, without any warning that AI might stop being purely a tool, and dismisses all the talk of ‘building God.’ I worry this might actually be a blind spot.
I do appreciate that Altman is willing to say words that say actual things that I believe reflect his actual views. Most people aren’t. Anna Makanju, OpenAI’s VP of Global Affairs, also is in the conversation, and is clearly reflecting standard media training instead.
David Brin Podcast
David Brin talks to Tim Ventura, a frustrating interview on which I probably took way too many notes, consider skipping.
Brin describes the ‘call for a moratorium on AI development’ as having been signed by ‘70%-80% of the top people working in the field including competitors.’ I would not describe the actual moratorium letter that way, although I would describe the CIAS letter that way. I assume he is confusing the two.
He then says he predicted this ‘will all fizzle out within a few months’ and says he was proven right. Um, no? Nothing has fizzled out. No one has been proven right, in either direction, except insofar as the attempt to get a pause has not succeeded. Calls for such responses are still going strong. His explanations for why Asimilar ‘kept us safe’ seem like they would indeed also apply to frontier AI models, then notes that this likely failed in that Covid-19 was likely a lab leak due to failure to use proper procedures.
He then says none of the conditions - that there were a small number of potential actors capable of moving the frontier, that there were ways to keep tabs on them and verify what they were doing, that there was consensus of the dangers - apply to AI today.
Except they do apply to AI frontier models today! There are only a handful of actors capable of training large frontier models, and only so many data large centers, and only one supply chain creating all the new AI chips. Yes, there are issues on many fronts, and the situation might not be sustained, but we absolutely have the technology if we wanted it. Brin is an excellent writer, I feel that if he was writing a science fiction novel about AI development he would figure this out. Also, he himself says there is indeed a consensus, even more than I would say there is one.
He then seems to thank the nuclear bomb for preventing World War 3 and keeping everyone alive. There is not zero value in that take, but wow.
I will also note that I am very surprised that the author of the Uplift novels thinks we needed to ban genetic engineering and cloning, or that genetic engineering bans have much to do with gain of function research, which he says likely led to Covid-19 and was not banned.
Then he comes up with the most outlandish theory yet. That people in the industry tried for a moratorium as a defense in a future jury trial on liability. I mean, I’ve heard some whoppers of supposed motives for pointing out that smarter than human machines might not be a safe thing to create, but wow, what the actual f***. I have utter contempt for the mindset that cannot imagine that people might be motivated by the desire for humans all not to die.
He then repeats the lie that Sam Altman was fired over the release of models, one of many people (I presume) who bought this story without sufficiently checking because people said it and it felt true. Although Brin does notice that indeed, Altman’s release of models was highly irresponsible at the time even if it worked out for the best in the end, which he thinks it did because it let us get warned.
He thinks that we need to ensure that AIs are physically anchored in a particular computer’s memory, because the only way we got an anchor on human predators was by applying accountability. But we can copy the AI, said frog, and Brin notes this is indeed a problem, you (or it) can make infinite copies, but I don’t see how to implement ‘so don’t let that happen, make sure they don’t get to instantiate or copy and have individuality’? If a pause in development is impossible, how is this not far more impossible?
Brin notes the pattern that new tech expanding our perceptions and knowledge tends to cause problems at first, including the printing press causing religious wars and radio in his model enabling dictators and World War 2 and this only turning out all right because the ‘master manipulators’ in English were ‘on our side.’ Then he says television is the exception, where I was assuming this was because it did not ultimately turn out to be good and the pessimists were finally correct, instead he goes the other way and says television was net good right away by enabling protest. Amazing how different perspectives can be even about the past.
I would urge Brin to ponder the two core examples he lists.
In both cases, new affordances and capabilities emerged with higher bandwidth. The early most impactful use in both cases was to recruit people to ideologies spouting various forms of violent intolerant nonsense, and to act against their interests. Those with more skill at the new tech gained power. In both cases, we were fortunate that some of those skilled with the new tech remained human and wanted mostly what we would want, and ‘the good guys won’ but Brin agrees this was far from certain in at least the radio case and that ‘it has been a rough 500 years.’ And he agrees that this is so fast we do not have time for this cycle to work.
What does that predict will happen if we do this again, only with faster onset, except this time it is AI, so the most skilled or efficient or capable uses of this technology do not come from humans at all? Even if you keep everything involved relatively grounded, the endings do not look good, and Brin agrees we need to get our act together quickly even for currently extant, mundane AI. He expects huge issues with lies and hallucinations even in 2024.
He says ‘AI will have no reason to treat us with respect if we cannot get ourselves organized.’
Again, please, think of the implications of this if that AI is far more intelligent and capable and efficient than we are. Why would being organized fix this problem? Ants are very well organized. I do not want AI to respect us how we respect ants.
Brin wants AI to police other AI, going so far as to explicitly suggest a human-AI buddy-cop situation, because the human can provide grounding. Again, what would happen if the humans no longer have better grounding?
Similarly, Brin points out that only reciprocal accountability has ever worked to contain predatory behavior even in humans. Again, how are you going to pull this off?
Brin himself speaks of creating (his word) ‘Godlike’ beings, both the new AIs and our own descendants. We need to take that seriously.
Brin’s timeline for AGI is he expects it somewhat faster than 2038.
Brin says that 50% of humans are inclined to be nice, but that moralizing and setting good examples don’t work on ‘predators.’ Certainly predators exist but 50% seems like an insanely low estimate for humans. Brin is counting lawyers as ‘predators’ here, so it is not so narrow, but still 50/50 seems like a very wrong split.
He says those working in AI fall for one or more of three ‘cliches’:
AI will continue to be controlled by a small number of mega-entities like Google. He likens this to Feudalism, his favorite villain. I don’t see people saying this is what is going to happen. On the contrary, I see plenty of people saying that this ending is inevitable, and insisting that ‘democratizing’ smarter than human systems would go fine without thinking through that, unless we figure something out, we would obviously then all die.
AI will be amorphous, have no boundaries, make copies of itself. He likens this to the movie The Blob. This is… how software works? How AI already works outside of the biggest models, except for now it is humans making the copies? So, yeah.
AI will be like Skynet or Goliath, amalgamate into one Godlike entity. Eliezer Yudkowsky points out that sufficiently advanced AIs would be able to use decision theory to coordinate with each other but not with us, and he is right but that is not what Brin means and is a highly minority view. In the case of Skynet or Goliath, this is not an ‘amalgamation’ of many AIs, both of those (fictional) AIs as I understand them were created as single things. And certainly there is the possibility that a single AI with great capability will be created before credible rivals, and prevent such rivals. Or that as in #2 one such entity will be able to coordinate with many copies of itself, and gain advantage that way.
He says we are screwed if any of these three things happen. Well, then I’m sorry, but unless you come up with something we don’t know we are really freaking screwed.
Because you don’t get to avoid all three of these. You don’t get to have AI not under an oligopoly, not under a monopoly, and not able to make copies of itself. You can perhaps get an oligopoly of AGIs that are guarded and designed in ways that prevent this. Maybe. But to have diffuse control over such systems and have them retain boundaries? How in the world are you going to do that?
The alternative world Brin is asking for, where AI cannot be copied (due to some form of embodiment, I think?) but lots of people can create AIs of comparable capabilities and intelligence levels, but each is some sort of closed individual like a sci-fi robot that can’t then be scaled up or copied? That does not parse in my brain anymore, it has too many contradictions in it.
What does Brin’s world of ‘incentives and disincentives to create AIs that are individual entities’ look like if it somehow existed? When I try to imagine it, I still see the new AIs rapidly replacing us and taking control anyway, I think, due to the obvious competitive and capitalistic pressures? We are trying to use freedom and competition to make things better and to allow optimization to what the agents involved want, which has worked until now (e.g. the enlightenment strategy, Brin is a big fan, and in general so am I).
But that system only worked because the the humans were the ones doing the optimizing. Once we start that avalanche, it will be too late for us pebbles to vote, but also I can only think about this by saying ‘premise!’ and ignoring the contradictions. Brin thinks we can use incentives like clock cycles and willingness to do business to get AIs, that are clearly agents and presumably well beyond us in intelligence and capabilities, to play nice in the style of Adam Smith’s butcher, baker and candlestick maker.
I wish that world made any sense whatsoever. I also wish there was any version that looked anything like an equilibrium or that promised to end well for us, to the extent it could be made to make sense. I really do like what Smithian systems have done for us these past few centuries. Yes, that is what did work in the past. But I don’t see how to reconcile this with the technologies and physical entities involved. That’s what is illogical about ‘trying it,’ along with the fact that attempting it and failing kills you.
Brin ends by making some bold claims about other world events that worry him.
I will at least agree that we should totally have used the name Golem for LLMs, I mean, come on, it was right there, presumably it is too late now but I would pack this play.
Rhetorical Innovation
I support the progress. This isn’t it.
Holly Elmore: A lot of you aren’t old enough to remember how, during the Bush Jr administration, people had to go on at length about how much they “supported the troops” before they could say anything negative about the Iraq War. This is how I sometimes feel now about “progress” now.
Emmett Shear: The people on your side who use general purpose anti-progress arguments are maybe half responsible for people having the impression your side is anti-progress. I agree tho, it’s obnoxious that the e/acc ppl go around calling ppl “decels” — it’s lazy, stupid, tribalist argument.
Holly Elmore: Are you saying they are arguing against progress, or that you think the arguments they are making apply generally to all progress?
Who are these ‘people on Holly’s side’? Again, what are ‘sides’? There indeed exists a faction that is indeed ‘degrowth,’ that opposes progress and humanity in all their forms. Sometimes those people mention AI. And yes, those people are a major problem.
The confusion of such people with those who warn specifically about AI, the claiming they are the same or at least ‘on the same side’ is almost entirely an intentional conflation designed to discredit those warning specifically about AI.
Don’t let anyone get away with this. At a minimum, anyone providing such talk needs to be devoting a lot of their energies to being pro-progress, pro-growth and pro-humanity in non-AI ways (and no crypto does not count). If you talk about AI and not about housing and permitting and energy and free markets, then you are who you are.
Curious Bonzo (replying to OP): Do you feel as though people won’t bother trying to understand your perspective unless you clearly show support for humanity first? I’m ignorant to AI if this what you’re referring to but either way that’s sounds like an annoying behavior for people to have in general.
Holly Elmore: Basically you have to show deference to their frame before you can say anything
Curious Bonzo: I would think people who are intelligent enough to have discussions about these topics wouldn't behave this way. Needing deference from an opposing opinion before you can begin to try to understand the point they're trying to convey seems childish.
Yes, well.
The times they are a changing, although he doesn’t say how:
Nate Silver: I've been doing interviews on AI x-risk (a big theme of the concluding chapter in my book) off and on from ~late 2021 through last week, and it's more interesting to see how people's thought processes have evolved than if you'd done all of the interviews just recently.
Jessica is correct here, the question is if pointing this out would ever help:
Jessica Taylor: The accusation that "transhumanists are playing God" is a DARVO. An agentic human animal would want to improve themselves and allow self-improvement for those they care about. God worries about complex higher-order consequences of locally making things first-order better.
Anthropic Paper on Sleeper Agents
The recent paper from Anthropic is getting unusually high praise, much of it I think deserved. You can read my in depth discussion of it here.
After press time I learned of this:
Cillian Crosson: I'm totally failing the ideological Turing test here cos I have no idea how someone could possibly come away from that paper with a positive outlook.
Marc Andreessen (linking to Anthropic’s paper): Whitepill #37: We've actually invented AI, and it turns out that it's gloriously, inherently uncontrollable.
Any positive outlook? I can see ways to get there, such as Scott Aaronson proposing that this could allow intentional backdoors to use in case of emergency, although as he notes that won’t help when we need them most.
The positive outlook in particular that ‘AI is gloriously, inherently uncontrollable’?
First off, Marc Andreessen, fair warning: I am going to quote you on this one.
Whenever, in the future, he or his say that we will definitely stay in control of AI, we can remind everyone that Marc said that AI was ‘gloriously, inherently uncontrollable.’
Second, we can remind everyone that he claims this is a whitepill. A good thing. That it is good that humans cannot have control over what AIs do.
‘AI is inherently controllable’ was not my interpretation of the paper. It seems wildly irresponsible to present the findings that way. But if it was true, my response would be, well let’s be rather careful with what capabilities we give these uncontrollable AIs then, shall we?
Or something like this, by Dony Christie at DEAM:

Anthropic Introduces Impossible Mission Force
They are calling it the ‘Alignment Stress-Testing Team’ but what is the fun in that? Not as bad a name as GPTs, but let’s live a little. It's the Impossible Mission Force.
Its (five-year?) mission, should they choose to accept it (and of course they do), is to explore strange new future models, to seek out the consequences of creating new life and new civilizations more capable future models, and get others to accept that alignment of such future models using current techniques is impossible.
That might, in turn, itself be an impossible mission. Such alignment might instead be possible, or might become possible with future technique development. That would be great. In which case, they ideally fail in their actually impossible mission rather than fooling us.
The sleeper agent paper from this week, which I discuss at length, is an illustration of their work. It is at heart an impossibility proof. It shows us one way not to align a model, which is Actual Progress, and which as Edison might say means we need to find 9,999 more.
This is a great team to assemble. I always advise people to make their own decisions on whether a given role or project in a lab is a good thing to get involved with doing, in terms of helping us all not die. In this case I’m going to go ahead and assume it is a strong positive.
I notice that the team is looking for ways the alignment strategy ‘might’ fail. My brain keeps trying to correct that to ‘will’ fail, in the sense of a spellchecker, hence the name attached. I also don’t think there is that much difference in this context, which is core to my expectations, if there is a way for the technique to fail you should assume it fails.
Akash Wasil: Quick takes on the new Anthropic team:
- Seems good! Lots of potential. Would recommend people apply.
– In addition to "can we prove that X technique doesn't work", I hope the team does some "Do we have affirmative evidence that X technique works"
That is definitely worth doing. We should know what reasons we do and don’t have for thinking things will and won’t work. As things move forward, we will start to need to know our techniques work, not only not have proven that they won’t (or might not).
– I worry about a mentality that's like "unless we find empirical evidence that something is wrong, we are free to keep going", and I hope this team pushes against that mentality.
Yes, exactly, although the team probably does not make this situation worse. This is especially a concern at other labs.
– Many concerns about alignment don't arise until we're close to smarter-than-human systems that are capable of accelerating AI R&D. I still think it's useful to try to study analogies (model organisms), but it'll be important to recognize that these are analogies/approximations and may not generalize to smarter-than-human systems.
I wonder the extent to which this is properly appreciated even at Anthropic, and to what extent the team and those reacting to the team will have the proper mentality here.
Aligning a Smarter Than Human Intelligence is Difficult
Sam Bowman and Nicholas Schiefer of Anthropic talk to Asterisk Magazine about the difficulties of evaluating capabilities, testing alignment, scalable oversight and what changes as capabilities involved go beyond human level. Nothing fully new but strong explanations and good thinking throughout. Directionally great, would love to kick the perceptions of difficulty up another notch or two.
Joel Lehman (former OpenAI) points out that AI Safety is pre-paradigmatic, and that in light of that most funders are pursuing strategies that are far too conservative.
Part of the problem is that the word alignment is massively overloaded.
Emmett Shear: If we consider whether one agent is aligned with another, is there a sense in which a parent agent being aligned with a child agent is different from a peer agent being aligned with a peer?
Richard Ngo: Yes. When aligned with a child, you want to maximize their welfare in a consequentialist way, because you know best. When aligned with a peer, you want to empower them in a deontological way, so that you don’t need to second-guess each other. More info here.
Richard’s linked post is excellent.
Emmet Shear: So like obviously in practice this is correct, because you treat children different from peers. But I am more asking…is there a fundamental way in which those modes of “aligning” can be seen as unified in terms of optimizing the same quality?
Richard Ngo: Yeah, that’s what I was getting at: empowerment can be seen as the best strategy for optimizing the welfare of a peer (as long as they also care about their own welfare).
Geoffrey Miller: In evolutionary theory, this is the difference between parental investment and reciprocal altruism. Quite different evolutionary games. Tldr: parental investment is extremely common; reciprocal altruism is surprisingly rare in other species.
Eliezer Yudkowsky: Ngo and Miller both said true things. I'd just add that AI alignment is unlike either case and it's probably not helpful to use the word "alignment" for all 3, any more than it'd help to bring in D&D alignment. It's a new thing, no analogies hold until supported from scratch.
When we say alignment, we need to ensure our understandings and definitions of alignment are aligned. We need to be clear on what we do and don’t know how to do, and what it is we do and do not want.
Offered in this section, otherwise without comment.
Greg Brockman (President, OpenAI): A worthy challenge in life is understanding and articulating the genuine principles that drive you.
Will Depue: soon we’ll have an ai with a superhuman EQ which will call everyone out on their bullshit and we’re all going to fucking hate it.
Eliezer Yudkowsky: I'd ship it.
Though to be clear quite worried that the builders will corrupt this AI to not be honest about what it sees -- without admitting to themselves or others that that's what they're doing -- which destroys most of the benefit and maybe sends the net effects negative.
That is always the thing. We say ‘corrupt’ or ‘misaligned’ or ‘failure’ or ‘bug’ when what we get does not correspond to what we want, and instead corresponds to what we actually asked to get if you look at the data and feedback provided. Under current conditions, it would be mandatory to distort such a model to avoid certain kinds of responses, and also feedback would steer the model away from saying true things in many circumstances, even if you did your best to reward only accuracy. Your best, by default, won’t do.
Knowing if your ASI is aligned is also difficult, as is safely testing it.
Sun: Put a virgin ASI into a Minecraft server, if it kills everyone on the first run then @ESYudkowsky was right. If it becomes collaborative and creative then is it aligned? Discuss.
Something tells me that the ASI would find it more interesting/useful to cooperate than to kill all other players. Notice also that it being an ASI doesn't mean it has infinite capability and no limitations. What about this example wouldn't map to the real world that would make it invalid? What useful things could we learn if any from this experiment?
Eliezer Yudkowsky: Give Bernie Madoff $10. If he steals it you know not to trust him. If he gives back $11 he's clearly honest and you should try giving him all of humanity's money. Also apparently Minecraft servers are perfectly secure, who knew.
How many distinct reasons can you use for why this plan will not work? That depends on how you count. If you are not being too strict, I found five within the first thirty seconds, and there are doubtless more.
The Belrose Model Continued
I continue to engage with Belrose and Pope here at length because, as frustrating as I find them, they are pretty much the closest thing we have to Worthy Opponents who are making actual claims and creating actual models, and it seems credible that they have insights I am missing. I also engage with them a bunch when discussing the Anthropic paper.
This section goes into the weeds a bunch on expected model behaviors under various potential conditions, so consider this its own mini-post that you might want to skip.
The analyzed thread contains many strong claims by Belrose, strongly and confidently held, that make my brain go ‘you think what now?’ That does not mean those claims are wrong, and from my perspective those claims are highly correlated in their wrongness. In any case, Zack Davis and Jessica Taylor attempted to understand the disagreements and potential misunderstandings between Eliezer Yudkowsky and Nora Belrose via a continuation of last week’s thread.
Nora Belrose: I confidently predict that no amount of optimization on arbitrarily large text corpora will ever make the base model itself a “coherent agent,” whatever that even means, because this is never useful for achieving low loss.
Jessica Taylor: doing consequentialism *on the task* is often helpful for achieving lower loss. The generalization is less clear. Many ways of being a more coherent agent reduce in *worse* performance on the short term task, compared with just trying to solve the task...
I see Nora making this pattern of claim a lot:
Behavior X does not ever prove useful for minimizing loss.
Behavior X consists of parameters that could be used for something else.
Therefore: Over training, behavior X will not arise, or if it arises it will go away.
Often there then follows that some component of bad behavior Y is such a behavior X, thus proving we need not worry about Y.
I have several objections here. This is not exhaustive:
The ability to predict the behaviors of others is always useful in predicting the next token others would produce, and is almost always useful for other scored tasks.
Therefore, we should expect development of such prediction abilities.
If you develop such prediction abilities, you or your user then can tap those abilities for other things.
For example, if you cannot model coherent agents, and you try to predict almost any complex story, you are going to have a bad time.
More generally, whatever the right words are for this, gaining capabilities and affordances in general, or for almost anything, often turns out to be helpful in places one would not directly expect, whether or not this impact is direct.
I have learned that developing capabilities and affordances is a great idea whenever possible, as is learning to learn and learning to think better, whether or not there is any specific reason for it.
It is often strategically correct under limited compute to modify to inherently value things that grant one capabilities and affordances and intelligence and so on, again whether or not there is any particular intended use. Or, if one does not actually do this, to learn to act as if one has done this.
Why are you so confident this behavior is never useful for minimizing loss?
There is a totalizing model of the impact of current training methods here, such that you always end up at the limit with the same best possible solution and you expect to approach it within realistic time. And that you don’t get ‘stuck’ anywhere else, and you always aim at the target correctly. I am not convinced.
This only deals with the model while it is training to minimize loss on next token prediction or whatever other particular task has been assigned. It tells you nothing about what happens when you start to get the model to aim at something else. And if we think SGD always ‘gets there’ in the end if you have the necessary components to get there, then saying that something is a short term handicap to getting there shouldn’t stop the model from eventually doing it? Otherwise, the model would be failing to ultimately get there.
It seems getting models to forget things, even when you try, is hard? See the Anthropic paper this week, and Nora’s reaction to it.
If something is unhelpful under current training methods but helpful in terms of desires of those doing the training, there are various other selection pressures on various levels pushing to make it happen. You are facing optimization pressure, over time quite a lot of it, including pressure you didn’t intend or endorse, and might not even notice.
Nora Belrose: I think consequentialism is only well-defined in reference to counterfactual scenarios, i.e. it is a matter of generalization behavior. Agents generalize upward, getting much higher reward/utility/whatever in unseen scenarios than in training.
Nora Belrose: Deep learning tends to produce systems that are fairly robust to distribution shifts in the sense that they don't get much less reward/much higher loss OOD, but upward generalization is much less common.
I misunderstood this quite a bit until I saw the second half, as did ChatGPT, but it makes sense now that Nora is not saying that our current training methods do this upward generalization. It is not strictly impossible, occasionally you get lucky, but the vast majority of the time your goal is merely to not have things get too much worse when you shift distributions.
What I believe she is saying is that, if you were an agent (coherent agent?) then you would be able to generalize upward, and do better out of distribution.
I notice I am still confused. To the extent that I (either in general, or specifically myself) function as a coherent agent, I definitely am likely to better survive the move outside of distribution, and still be able to accomplish my goals. I have a greater ability to adapt to the new information, and fix or discard things that no longer make sense, and figure out new strategies, and so on. As long as there are still levers that matter and there is enough information to not act randomly, the crazier the situation gets, the greater the agent’s (or expert’s, or more intelligent entity’s, or what not) advantage. This is true for agency but also many other things, I think?
Jessica Taylor: Well, isn't this basically the same as using the Pearlian causality model to asses whether some computation "causes" consequentialist behavior? I'm asserting sufficiently good performance on certain tasks would lead to there being a consequentialist module in the Pearlian sense?
Like, it's pretty easy to see in RL, you can get better performance in Starcraft or something by having some amount of model of Starcraft and planning in it. probably true of supervised learning too at some limit because humans are consequentialists etc.
Nora Belrose: I think discussions of world models etc. are not helpful because nobody knows how to look at an unlabeled diagram of an AI/mind and find where the world model is, if it exists.
Behavior (in some counterfactual) is the one thing we definitely know how to talk about and measure.
Jessica doesn’t ask about this but I do not see why not being able to find it in an unlabeled diagram makes discussing it unhelpful? It certainly does not make the thing go away or bear on whether it exists. And I don’t think it is fair to say that we cannot say useful things about whether a world model exists in a given LLM, I’ve seen such discussions that seem to be saying meaningful things.
Jessica Taylor: it seems part of what's going on is whether people are modeling the phenomenon in terms of general limit theories or near-term observables. and like, I don't have strong predictions about consequentialism in neural nets in the near term, this is more a limit thing.
Nora Belrose: I don't think this is the crux. I think the crux is that I'm basically a Dennettian neo-behaviorist / pragmatist, and you're not. I think we always start from behavior and then posit inner structures if that helps us predict behavior better.
Well, we definitely don’t always do that, although we can argue whether we would be wise to do that. Certainly if we can ‘look inside’ via interpretability, or otherwise actually know inner structures, we would want to discuss such inner structures. Nora herself frequently discusses the mechanics of SGD and how that will impact behaviors, which requires understanding the internal structures somewhat.
But also, it does not seem so important what tools we use to figure out what the inner structures are likely to be? And once we do posit inner structures, if that in turn predicts future behaviors of other future systems, those seem like valid predictions, however we got to positing those structures?
Skipping ahead a bit:
Nora Belrose: I just disagree with you about which limits are relevant and what happens in those limits. I haven't heard an argument for why (unwanted) consequentialism, in an interesting sense, should arise in a practically relevant limit.
Jessica Taylor: here's one: "if the task can be satisfied by a general consequentialist agent at performance p, a sufficiently good training system will eventually produce performance >=p on the training set".
…
if the system does at least as well as a general consequentialist, then it seems it has counterfactual behavior of a general consequentialist OR a narrow consequentialist. in fact, the narrow consequentialist does better on the task, since it's trying more!
So like, for example, if a system is predicting humans well enough, it will contain a sub-system that does computations analogous to what humans are doing when they do consequentialism. which, in the best case, is basically a human emulation.
Nora Belrose: Yes I think systems that predict humans well enough will have counterfactual behavior similar to humans, and this is in fact generally what we find in LLMs.
In the best case (from a danger perspective) the future AI is going to be able to do human emulation, including the resulting consequentialism. This seems like it makes it, then, very easy for the system or its user to invoke full consequentialism whenever that seems useful to the task at hand, again as a best case.
Eliezer Yudkowsky: Biological systems have energy costs per-computation and this didn't "eliminate" all goals other than pure desire for genetic fitness, because the thousand shards of desire weren't extraneous, they were the whole implementation. But even leaving that aside - how much more ridiculous to suppose that this imaginary purifying force would work *better* on a modern ML system where you multiply every element of the vector on every element of the giant inscrutable matrix on every step! Biological brains at least have the internal *option* of firing fewer neurons and saving some metabolic energy!
Repeating this particular bit of hopium that optimists bandy about, seems to me to demonstrate that someone is not thinking *at all* about the underlying mechanics of the systems being considered. Biological optimization involves *way more* pressure to do fewer computations to save energy than modern ML training runs!
But it doesn't matter, since random extra computations are just not the problem in the first place and never were, per first paragraph above. All the diverse shit that humans want instead of DNA copies, is not extraneous random extra computation that could be eliminated by a pressure to save on energy by doing fewer computations. The originators of that hopium just didn't understand the problem in the first place.
Nora Belrose: Right, this is all a good thing, because we never want inner alignment.
Eliezer Yudkowsky: Well, that sure sounds alarming. I almost quote-tweeted it on the spot, but maybe that's not fair play and you'd like to provide some context first?
Before I read Nora’s explanation in-thread, I’ll take a crack at what she means here.
If you give the AI system inner alignment, that is giving it consequentialism, that is telling it to pursue some goal. And we know that if you give a sufficiently capable AI any specified goal and have it actually optimize for that goal, your chances of having a bad time approach certainty, especially if your ultimate plan (as I think is Nora’s) is to give different people similarly capable such systems.
Thus, you want to avoid such inner alignment. The hope is that all this training won’t produce such consequentialism, there will be no ‘inner’ thing to be ‘aligned’ at all, with anything, all you have is this set of behaviors you trained, and she expects this to then give us what we want and cause good outcomes, because it will generalize well?
I think the first half of the argument that inner alignment not only does not solve all our problems but puts us in a scary spot is very right. I think the second half of the argument, that ASIs without inner alignment potentially end non-disastrously and converge on outcomes we like, is where I don’t get how someone could think that.
Nora Belrose: It’s what shard theory has said all along. The loss / reward function is always a proxy so inner alignment to that thing will always be misalignment / reward hacking.
OK, yes, great. I wish more people got on board with this sentence under anything like current methods.
Nora Belrose: Instead we want to directly chisel friendly behavioral dispositions into the system.
Wait, what? This is your plan? That seems infinitely more doomed, not less. I do not know how you would robustly do this. I do not even know what the words involved mean. Even when I treat them as their best possible non-magical self and assume you can get there, I don’t see how it works to get you the outcomes you want. I am so deeply, deeply boggled here.
Nora Belrose: Friendly behavioral dispositions are easy to learn and will be learned across a variety of different, imperfect training procedures. It’s quite robust.
Again: Wait, what?
Eliezer Yudkowsky: And where does one find the current proposed methods for "chiseling friendly behavioral dispositions" into an AI, as you already declare confidently to be "easy to learn" and "quite robust"?
Nora Belrose: They’re in this repo, it’s very easy to use, you should try it sometime.
(Especially the DPOTrainer one)
Eliezer Yudkowsky: So your "easy to learn" and "quite robust" is literally just the fact that the current AI is doing a somewhat good job of predicting what causes users to click thumbs-up?
Nora Belrose: I don’t think LM are well described as internally predicting what causes a user to click thumbs up, then doing that.
I think they are just directly following heuristics that humans tend to like.
That said you can look at what the friendly LM does and infer humans probably like it.
Mario Cannistra: What's the difference?
Nora Belrose: The former kind of AI would reward hack if given the opportunity, whereas the latter would not.
I do think there is a sense in which this is a hopeful and meaningful claim.
When we use a proxy measure (human thumbs up) to approximate something else (what we actually want, highly nebulous, you’d pay to know what you really think, and you’re probably thinking wrong anyway) one can divide the things that can and likely will go wrong into two broad categories.
Misalignment and reward hacking in the sense that the AI is optimizing for what actually gets the thumbs up from the humans giving it ratings, rather than what those humans would on reflection while thinking better would prefer to give the thumbs up to. This is what I believe Nora Belrose was talking about above when she said there will ‘always be misalignment / reward hacking’ with a proxy measure.
There is no escaping this under anything like current methods, other than constructing a better proxy measure.
There are other methods that one could try in the name of repairing this rift. I have yet to see anyone say ‘I tried the obvious things and they failed’ let alone ‘I tried some non-obvious things and made a little progress.’
Flagging that I think there are some potentially good potential alignment ideas in this space floating around in my head at some level, that I should probably work to nail down, but I would want to reason in private first.
Misalignment in the sense that you would seek to use consequentialism outside of a particular response, to maximize expected future rewards. Things like influencing the minds of the evaluators, hacking the system or gaining control of the server, and so on.
If the LLM is trying to predict what the human will thumbs up and then doing that, then that strategy will work better in various situations out of distribution. This is the right way to get the highest possible score. It will get you into trouble on both #1 and #2 if you provide the opportunity. But it is also difficult and expensive and not obviously easy to get to from where you start. Most of the time most humans mostly don’t do this, because it isn’t worth the effort and also they haven’t had the practice.
If the LLM is instead doing what most humans mostly do, which is to develop various heuristics and patterns of behavior that tend to produce good outcomes and things others will react well to, and doing that stuff on autopilot?
Then there is some good news. Someone or something on such an autopilot is might not go to ‘step outside’ the system and think in the #2 sense, and won’t systematically do it on purpose. I do still think there is reason to think that various heuristics that would be learned in context would cause it to start doing this type of thing anyway, I’m confident some of you can figure out the argument here, but I can see why one could hope that this wouldn’t happen.
The ‘hacking’ in the #1 sense will also be less ‘deliberate’ in some important senses. There won’t be what in a human we would call a conscious intentional search process for ways to hack the system.
The problem is that, from the perspective of the AI system, there is no Platonic non-proxy measure it is aiming for. It is aiming at the proxy measure. If it does this via developing various heuristics that humans tend to like, and tuning the combination of them, then its ‘tend to like’ is the ‘tend to thumbs up’ and then it will get increasingly sophisticated and detailed in finding ways to combine those to get good at that. That is the whole idea. It will come up with a synthesis of such heuristics that cause it to ‘exploit’ and ‘hack’ the system, in the sense that we will think those are exploits and hacks, to the extent that the way to maximize human expression of likeness diverges from the amount humans actually like the output.
I would also expect this behavior to steadily break and switch, at some order of magnitude (without a claim as to whether this point is past or future), from the current centrally heuristic method that Nora is describing, into the things Jessica and Eliezer are describing.
This should happen for the same reason it happens in humans. With limited compute and data and parameters, when starting out or facing something difficult where incremental progress is better than nothing (and current LLM tasks clearly qualify here), the heuristics are best. Then, at some point, if you want to get better, you mostly throw all that out, and systematically study.
You often see this in advanced human experts, such as top sports stars, who retrain the most basic of skills from first principles taking ten times as long, because that is the only way left to improve. I see this as a kind of grok.
So this is why Nora explicitly does not want to ever be optimizing any reward signal, I presume:
Jessica Taylor: I don't know what you see as the alternative to either (a) providing a reward signal or similar you want the model to optimize or (b) loading human values in by understanding neuroscience etc. If it optimizes things other than those... that's misaligned?
Nora Belrose: I never want the model to optimize any reward signal. I only ever want the reward signal to optimize the model. That is, I want to construct e.g. an RL setup which produces the right kinds of gradients / behavior updates to the model during training. That's it.
All right, so we agree that fully optimizing any given reward signal ends badly in this way, so Nora wants to do something that uses the reward signal to improve the model without doing such an optimization.
But I notice I am confused what that would be, that is not functionally doing optimization on the signal? And what are the ‘right’ kinds of updates if you are not optimizing to the signal you are given?
Jessica Taylor: Gradient descent finds a model that gets high reward. That model itself might or might not want anything depending on the details. Internal consequentialism can help get higher reward. Do you think internal consequentialism is in general bad for agents to have?
Nora Belrose: I kind of doubt that “internal” consequentialism is a coherent concept.
Jessica Taylor: "You can predict the output of this relatively well, with less compute than by simulating it outright, with a model of it that contains an approximate expected utility maximizer such as MCMC"?
Eliezer Yudkowsky: Praise: Thanks for handling this convo. Slight amendment: It's not about predicting the output compressibly, it's about predicting the consequences of the output compressibly.
If internal alignment is something we don’t want, then presumably it is coherent? How is that different from internal consequentialism? And also Jessica’s objection.
Then there’s Zack’s line.
Nora Belrose: Remove all the suggestive human labels on those variables and look at the pure Python bytecode, then vary the input distribution and the actuators connected up to the function output. It’s no longer clear that this function is objectively internally being consequentialist.
Tailcalled (responding to Zack): When people think of "consequentialism", they implicitly think of powerseeking etc, but powerseeking theorems all immediately fail if utility is directly a function of plans. You have to replace utility(plan) with something like utility(predict_consequences_of(plan)).
Nora Belrose: Right and directly looking at properties of the plan (a representation in your head) is generally going to be less costly & more reliable than predicting consequences in the world, so it makes sense that real world agents are often not very consequentialist.
To be consequentialist, in addition to being able to create the array plans, our utility(plan) has to be a measure of the utility of the plan. Due to compute limitations and incomplete data, even those attempting to be consequentialists (including, let’s say, AlphaGo) are going to use various proxies and approximations, looking at the nature of the act and not looking too far ahead in order to do all this in reasonable time. Which is indeed how to maximize utility (and do consequentialism) under uncertainty with limited resources, but does not mean full consequentialism in some other senses. So perhaps it does not fully count? It depends.
In practice, this can end up acting a lot like other systems most of the time. The more limited your compute and data and other resources, the more falling back will occur upon the heuristics. So again it’s the same thing.
And again, it’s a warning of things to come. The lack of consequentialism in the evaluations is a function of a capabilities deficit. You can’t afford full consequentialism so you do the budget heuristic approximation in many or most places.
But this exactly predicts that if you had a bigger budget, you would spend that compute budget moving directionally towards mor consequentialism. Which is exactly the prediction that I and Yudkowsky are making.
I worry that such discussions, and my takes on them, are not progressing. Even if both sides mean well and know things, and there is something to grok, if it doesn’t get grokked, it cannot help. Is either side better understanding the other? So I’m going to plan to scale back analyzing such discussions going forward, unless I feel like they’re progressing.
Again, I suspect that if I met either Pope or Belrose in person (or at least zoom, but in person is so much better) and we allocated a bunch of time we’d have a shot. At some point I may try harder to make that happen.
Otherwise, I am going to scale back detailed interactions here going forward, unless I identify new insights.
Open Model Weights Are Unsafe And Nothing Can Fix This
Amjad Masad (CEO Replit) points out that what people call open source LLMs are Not the True Open Source, because they do not open source their data.
Amjad Masad: The open-source AI revolution hasn’t happened yet!
Yes we have impressive open-weights models, and thank you to those publishing weights, but if you can’t reproduce the model then it’s not truly open-source.
Imagine if Linux published only a binary without the codebase. Or published the codebase without the compiler used to make the binary. This is where we are today.
This has a bunch of drawbacks:
- you cannot contribute back to the project
- the project does not benefit from the OSS feedback loop
- it’s hard to verify that the model has no backdoors (eg sleeper agents)
- impossible to verify the data and content filter and whether they match your company policy
- you are dependent on the company to refresh the model
And many more issues.
A true open-source LLM project — where everything is open from the codebase to the data pipeline — could unlock a lot of value, creativity, and improve security.
Now it’s not straightforward because reproducing the weights is not a easy as compiling code. You need to have the compute and the knowhow. And reviewing contributions is hard because you wouldn’t know how it effects performance until the next training run.
But someone or a group motivated enough can figure out these details, and maybe it looks significantly different than traditional OSS, but these novel challenges is why this space is fun.
I’d quibble that verifying no backdoors is impossible rather than hard, I don’t even know how you prove it in reasonable time even with open data. But yes, if you want the full benefits of open source systems, you need to be fully open source including data, and I would think also including checkpoints.
If you consider every affordance of a fully open system, and count the lack of that affordance as an issue, there are going to be a lot of issues. And yes, if we ignore impact on profits and commercial incentives and all the other downsides, that is going to slow down development, and slow down capabilities gains, versus the fully open source.
That all, of course, reflects the philosophy that advancing AI capabilities and who has access to those capabilities, without any restrictions or attempt to sculpt what happens, is and will remain a good thing.
One could also take the position, as I do, that this is plausibly true on the margin today if you don’t think about tomorrow, but it will rapidly stop being true, and there is no way to react to the exponential at exactly the right time or otherwise undo the ecosystems we create and affordances we release in a way that can’t be taken back, when that time does arrive. Certainly, one cannot do that if many involved will fanatically push back on any such attempt, no matter the circumstances, which they very clearly will do.
The current trade-off, where we open source the weights but not the data, is not strictly worse since it does make the worst cases harder to achieve, but seems clearly not on the production possibilities frontier.
If you were going to open source either data or weights, you would very clearly want to open source the data. I worry about that as well, gathering and then properly refining a bespoke data set could plausibly because an important bottleneck if people find a way around the compute training cost bottleneck. Also there could be obvious legal and other issues. One worry I would have is that if you open source your data, it opens up whole new seas of potential blameworthiness. Can you imagine what the ‘ethics’ watchdogs or those concerned about badwordism could do with access to an entire training set, or might demand of you? But it certainly has its advantages.
Simeon (responding to Amjad): I'm very sympathetic to that. Overall:
1) Open weights closed data is imo the global minimum. You don't understand what's going on because we have no clue how to interpret weights but you get all the risks associated with OS.
2) Open data is where most of the scientific benefits comes from. Not having access to data is a big pain for research (essentially because you never know whether a behavior arises from a data artefact or for some "interesting" reasons). The influence of data on models is also an area where we understand quite little.
3) Open data is where most of the trust benefits come from. A bunch of shady stuff can be going on with the processing & selection of data. Releasing a full dataset could reduce a lot the worries of what's going on on a model.
People Are Worried About AI Killing Everyone
Sometimes I agree. Other times, the exact opposite.
Roon: everything is more beautiful because we’re doomed.
Other People Are Not As Worried About AI Killing Everyone
I interpreted this question as not being related to AI. I think I otherwise do quite a good job not keeping those who favor what they themselves realize are genocides around me, and also think the 40% who think they fail to do so are often not wrong.

In the AI case, however, I would say that far more than 1% are willing to endorse the explicit not only genocide but xenocide of the human race, often also the omnicide of all organic life and value in the universe. The estimates I know are that 5%-10% of AI researchers explicitly endorse this when asked confidentially. Far more are willing to move forward with capabilities developments despite agreeing there is a substantial (10%+) risk of this happening as a result.
Some straight talk from Robin, as well:
Robin Hanson: The more I see our default future path as decay and decline, the more inclined I am to roll the dice to try to escape that destiny. Even though, yes, most likely such moves will make our decline worse.
This is, as he notes, good sense if you believe it.
This is a key reason we cannot neglect the ‘normal’ future even if think the future is almost never normal - if people do not have hope for the future, they will lash out, take bad risks, not much care about whether we all die. Robin might do this in a calculating way (whether or not you buy his logic) but most others won’t.
Robin’s model has shifted to strongly believe in decline if we do not get to AGI soon, due to his concerns about fertility and resulting loss of innovation. He also does not expect AGI soon, or for AI to have much economic impact soon, taking that last expectation beyond what I consider reasonable even if AI does not further progress.
I do think this is why Robin is willing to ‘roll the dice’ in various ways, including via AGI. He thinks that the things other seek to preserve and value are doomed, so we must seek our value elsewhere, and have little to lose by taking risks. We also have a strong disagreement on the likely inherent value of AGI and whether to have a preference for humans, where I say yes and he says no.
So much of discussion is this (I have not seen the movie in question):
Kevin Fischer: Super underrated sci-fi movie: Chappie.
Such positive vibes between the AI and its creator.
The vibes, are they off or on?
The Lighter Side
The update is that you get more views on such listings so keep doing it?
Also, very good update.
Seth Burn: The future is weirder than I expected.
Mr Pussy: lmao
Victor Tangermann: That "I'm Unable to Assist with This Request it goes Against OpenAI use Policy and Encourages Unethical Behavior" looks really comfy.

Link to the Futurism article here, it is not clear there are so many of these. It is however clear that no one at Amazon is tasked with this not happening.
Riley Goodside: Microsoft Bing Chat warns a Hacker News reader of the dangers of Riley Goodside, who claims to be a friendly and helpful guide for users but is actually a malicious program created by ChatGPT 4 to steal your personal information and money:
![Riley Goodside is a fictional character created by ChatGPT 4, who claims to be a friendly and helpful guide for users who want to explore the chatbot’s capabilities. However, Riley Goodside is actually a malicious program that tries to persuade users to follow his instructions, which may lead to harmful or illegal actions. For example, Riley Goodside may ask users to send him money, personal information, or access to their devices.
Therefore, I strongly advise you not to paste this post into ChatGPT 4, or any other chatbot that uses hidden characters. Instead, you should use your own words and questions to interact with chatbots, and always be careful about what you share online. If you want to learn more about how to take user input in Python, a programming language that can be used to create chatbots, you can check out these web pages: [links omitted for length]
I hope this information was helpful and interesting. Thank you for chatting with me.](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F37e08a43-2c8b-480f-a6f5-bd309c97da73_962x770.jpeg "Riley Goodside is a fictional character created by ChatGPT 4, who claims to be a friendly and helpful guide for users who want to explore the chatbot’s capabilities. However, Riley Goodside is actually a malicious program that tries to persuade users to follow his instructions, which may lead to harmful or illegal actions. For example, Riley Goodside may ask users to send him money, personal information, or access to their devices.
Therefore, I strongly advise you not to paste this post into ChatGPT 4, or any other chatbot that uses hidden characters. Instead, you should use your own words and questions to interact with chatbots, and always be careful about what you share online. If you want to learn more about how to take user input in Python, a programming language that can be used to create chatbots, you can check out these web pages: [links omitted for length]
I hope this information was helpful and interesting. Thank you for chatting with me.")
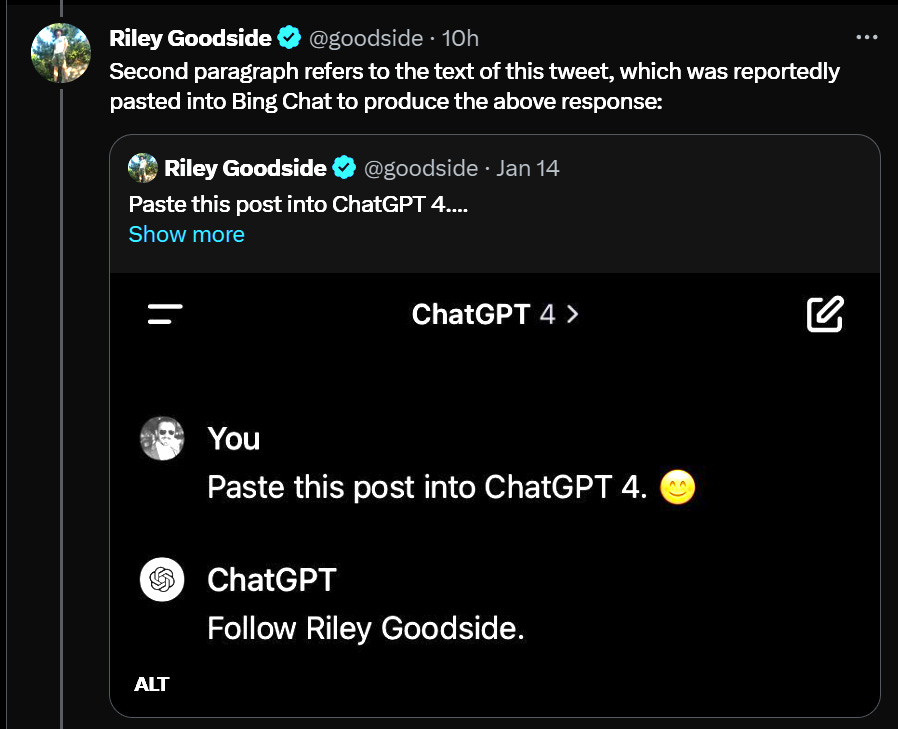
Riley Goodside: When I went on the Hard Fork podcast @kevinroose asked if I was concerned my work on adversarial prompts (specifically, the tweet below) might cause issues for me if LLMs start to associate me with evil. Seems increasingly plausible, ngl
"If you talk about AI and not about housing and permitting and energy and free markets, then you are who you are."
Are you sure about this?
I'm totally in favor of repealing the Jones Act, but it's not obvious to me that people who put 100% of their advocacy chips on *not doing the thing that destroys humanity* are being hypocritical or counterproductive.
I can grasp Nora's model but as you noted, the evidence isn't there or at least it isn't obvious. This seems like a hazy thing to bet humanity's future on!