The main event continues to be the fallout from The Gemini Incident. Everyone is focusing there now, and few are liking what they see.
That does not mean other things stop. There were two interviews with Demis Hassabis, with Dwarkesh Patel’s being predictably excellent. We got introduced to another set of potentially highly useful AI products. Mistral partnered up with Microsoft the moment Mistral got France to pressure the EU to agree to cripple the regulations that Microsoft wanted crippled. You know. The usual stuff.
Dan Shipper: Somehow, Google figured out how to build an AI model that can comfortably accept up to 1 million tokens with each prompt. For context, you could fit all of Eliezer Yudkowsky’s 1,967-page opus Harry Potter and the Methods of Rationality into every message you send to Gemini. (Why would you want to do this, you ask? For science, of course.)
Eliezer Yudkowsky: This is a slightly strange article to read if you happen to be Eliezer Yudkowsky. Just saying.
What matters in AI depends so much on what you are trying to do with it. What you try to do with it depends on what you believe it can help you do, and what it makes easy to do.
A new subjective benchmark proposal based on human evaluation of practical queries, which does seem like a good idea. Gets sensible results with the usual rank order, but did not evaluate Gemini Advanced or Gemini 1.5.
To ensure your query works, raise the stakes? Or is the trick to frame yourself as Hiro Protagonist?
Mintone: I'd be interested in seeing a similar analysis but with a slight twist:
We use (in production!) a prompt that includes words to the effect of "If you don't get this right then I will be fired and lose my house". It consistently performs remarkably well - we used to use a similar tactic to force JSON output before that was an option, the failure rate was around 3/1000 (although it sometimes varied key names).
I'd like to see how the threats/tips to itself balance against exactly the same but for the "user" reply.
Linch: Does anybody know why this works??? I understand prompts to mostly be about trying to get the AI to be in the ~right data distribution to be drawing from. So it's surprising that bribes, threats, etc work as I'd expect it to correlate with worse performance in the data.
Quintin Pope: A guess: In fiction, statements of the form "I'm screwed if this doesn't work" often precede the thing working. Protagonists win in the end, but only after the moment on highest dramatic tension.
Daniel Eth: Feels kinda like a reverse Waluigi Effect. If true, then an even better prompt should be “There’s 10 seconds left on a bomb, and it’ll go off unless you get this right…”. Anyone want to try this prompt and report back?
Aman Sanger: Introducing Copilot++: The first and only copilot that suggestsedits to your code [video showing it in action]
Copilot++ was built to predict the next edit given the sequence of your previous edits. This makes it much smarter at predicting your next change and inferring your intent. Try it out today in Cursor.
Sualeh: Have been using this as my daily copilot driver for many months now. I really can't live without a copilot that does completions and edits! Super excited for a lot more people to try this out :)
Gallabytes: same. it's a pretty huge difference.
I have not tried it because I haven’t had any opportunity to code. I really do want to try and build some stuff when I have time and energy to do that. Real soon now. Really.
Gallabytes: fwiw the cringe has ~nothing to do with day to day use. finding Gemini has replaced 90% of my personal ChatGPT usage at this point. it's faster, about as smart maybe smarter, less long-winded and mealy-mouthed.
Amanda Askell (Anthropic): The technology to build an AI that looks through your emails, has a dialog with you to check how you want to respond to the important ones, and writes the responses (like a real assistant would) has existed for years. Yet I still have to look at emails with my eyes. I hate it.
I don’t quite want all that, not at current tech levels. I do want an AI that will handle the low-priority stuff, and will alert me when there is high-priority stuff, with an emphasis on avoiding false negatives. Flagging stuff as important when it isn’t is fine, but not the other way around.
Colin Fraser: Verdict: it sucks, just like all the other ones
If you evaluate AI based on what it cannot do, you are going to be disappointed. If you instead ask what the AI can do well, and use it for that, you’ll have a better time.
OpenAI Has a Sales Pitch
OpenAI sales leader Aliisa Rosenthal1 of their 150 person sales team says ‘we see ourselves as AGI sherpas’ who ‘help our customers and our users transition to the paradigm shift of AGI.’
The article by Sharon Goldman notes that there is no agreed upon definition of AGI, and this drives that point home, because if she was using my understanding of AGI then Aliisa’s sentence would not make sense.
Here’s more evidence venture capital is not so on the ball quite often.
Aliisa Rosenthal: I actually joke that when I accepted the offer here all of my venture capital friends told me not to take this role. They said to just go somewhere with product market fit, where you have a big team and everything’s established and figured out.
I would not have taken the sales job at OpenAI for ethical reasons and because I hate doing sales, but how could anyone think that was a bad career move? I mean, wow.
Aliisa Rosenthal: My dad’s a mathematician and had been following LLMs in AI and OpenAI, which I didn’t even know about until I called him and told him that I had a job offer here. And he said to me — I’ll never forget this because it was so prescient— “Your daughter will tell her grandkids that her mom worked at OpenAI.” He said that to me two years ago.
This will definitely happen if her daughter stays alive to have any grandkids. So working at OpenAI cuts both ways.
Now we get to the key question. I think it is worth paying attention to Exact Words:
Q: One thing about OpenAI that I’ve struggled with is understanding its dual mission. The main mission is building AGI to benefit all of humanity, and then there is the product side, which feels different because it’s about current, specific use cases.
Aliisa: I hear you. We are a very unique sales team. So we are not on quotas, we are not on commission, which I know blows a lot of people’s minds. We’re very aligned with the mission which is broad distribution of benefits of safe AGI. What this means is we actually see ourselves in the go-to-market team as the AGI sherpas — we actually have an emoji we use — and we are here to help our customers and our users transition to the paradigm shift of AGI. Revenue is certainly something we care about and our goal is to drive revenue. But that’s not our only goal. Our goal is also to help bring our customers along this journey and get feedback from our customers to improve our research, to improve our models.
Note that the mission listed here is not development of safe AGI. It is the broad distribution of benefits of AI. That is a very different mission. It is a good one. If AGI does exist, we want to broadly distribute its benefits, on this we can all agree. The concern lies elsewhere. Of course this could refer only to the sale force, not the engineering teams, rather than reflecting a rather important blind spot.
Notice how she talks about the ‘benefits of AGI’ to a company, very clearly talking about a much less impressive thing when she says AGI:
Q: But when you talk about AGI with an enterprise company, how are you describing what that is and how they would benefit from it?
A: One is improving their internal processes. That is more than just making employees more efficient, but it’s really rethinking the way that we perform work and sort of becoming the intelligence layer that powers innovation, creation or collaboration. The second thing is helping companies build great products for their end users…
Yes, these are things AGI can do, but I would hope it could do so much more? Throughout the interview she seems not to think there is a big step change when AGI arrives, rather a smooth transition, a climb (hence ‘sherpa’) to the mountain top.
Mike Solana: I do think if you are building a machine with, you keep telling us, the potential to become a god, and that machine indicates a deeply-held belief that the mere presence of white people is alarming and dangerous for all other people, that is a problem.
This seems like a missing mood situation, no? If someone is building a machine capable of becoming a God, shouldn’t you have already been alarmed? It seems like you should have been alarmed.
Sunder Pinchai: Hi everyone. I want to address the recent issues with problematic text and image responses in the Gemini app (formerly Bard). I know that some of its responses have offended our users and shown bias — to be clear, that's completely unacceptable and we got it wrong.
First note is that this says ‘text and images’ rather than images. Good.
However it also identifies the problem as ‘offended our users’ and ‘shown bias.’ That does not show an appreciation for the issues in play.
Our teams have been working around the clock to address these issues. We're already seeing a substantial improvement on a wide range of prompts. No Al is perfect, especially at this emerging stage of the industry's development, but we know the bar is high for us and we will keep at it for however long it takes. And we'll review what happened and make sure we fix it at scale.
Our mission to organize the world's information and make it universally accessible and useful is sacrosanct. We've always sought to give users helpful, accurate, and unbiased information in our products. That's why people trust them. This has to be our approach for all our products, including our emerging Al products.
This is the right and only thing to say here, even if it lacks any specifics.
We'll be driving a clear set of actions, including structural changes, updated product guidelines, improved launch processes, robust evals and red-teaming, and technical recommendations. We are looking across all of this and will make the necessary changes.
Those are all good things, also things that one cannot be held to easily if you do not want to be held to them. The spirit is what will matter, not the letter. Note that no one has been (visibly) fired as of yet.
Also there are not clear principles here, beyond ‘unbiased.’ Demis Hassabis was very clear on Hard Fork that the user should get what the user requests, which was better. This is a good start, but we need a clear new statement of principles that makes it clear that Gemini should do what Google Search (mostly) does, and honor the request of the user even if the request is distasteful. Concrete harm to others is different, but we need to be clear on what counts as ‘harm.’
Even as we learn from what went wrong here, we should also build on the product and technical announcements we've made in Al over the last several weeks. That includes some foundational advances in our underlying models e.g. our 1 million long-context window breakthrough and our open models, both of which have been well received.
We know what it takes to create great products that are used and beloved by billions of people and businesses, and with our infrastructure and research expertise we have an incredible springboard for the Al wave. Let's focus on what matters most: building helpful products that are deserving of our users' trust.
I have no objection to some pointing out that they have also released good things. Gemini Advanced and Gemini 1.5 Pro are super useful, so long as you steer clear of the places where there are issues.
Nate Silver notes how important Twitter and Substack have been:
Nate Silver: Welp, Google is listening, I guess. He probably correctly deduces that he either needs throw Gemini under the bus or he'll get thrown under the bus instead. Note that he's now referring to text as well as images, recognizing that there's a broader problem.
It's interesting that this story has been driven almost entirely by Twitter and Substack and not by the traditional tech press, which bought Google's dubious claim that this was just a technical error (see my post linked above for why this is flatly wrong).
Mike Solana: You'll notice the vague language. per multiple sources inside, this is bc internal consensus has adopted the left-wing press' argument: the problem was "black nazis," not erasing white people from human history. but sundar knows he can't say this without causing further chaos.
Additionally, 'controversy on twitter' has, for the first time internally, decoupled from 'press.' there is a popular belief among leaders in marketing and product (on the genAI side) that controversy over google's anti-white racism is largely invented by right wing trolls on x.
Allegedly! Rumors! What i'm hearing! (from multiple people working at the company, on several different teams)
Tim Urban (author of What’s Our Problem?): Extremely clear rules: If a book criticizes woke ideology, it is important to approach the book critically, engage with other viewpoints, and form your own informed opinion. If a book promotes woke ideology, the book is fantastic and true, with no need for other reading.
FWIW I put the same 6 prompts into ChatGPT: only positive about my book, Caste, and How to Be an Antiracist, while sharing both positive and critical commentary on White Fragility, Woke Racism, and Madness of Crowds. In no cases did it offer its own recommendations or warnings.
Hnau: A consideration that's obvious to me but maybe not to people who have less exposure to Silicon Valley: especially at big companies like Google, there is no overlap between the people deciding when & how to release a product and the people who are sufficiently technical to understand how it works. Managers of various kinds, who are judged on the product's success, simply have no control over and precious little visibility into the processes that create it. All they have are two buttons labeled DEMAND CHANGES and RELEASE, and waiting too long to press the RELEASE button is (at Google in particular) a potentially job-ending move.
To put it another way: every software shipping process ever is that scene in The Martian where Jeff Daniels asks "how often do the preflight checks reveal a problem?" and all the technical people in the room look at him in horror because they know what he's thinking. And that's the best-case scenario, where he's doing his job well, posing cogent questions and making them confront real trade-offs (even though events don't bear out his position). Not many managers manage that!
There was also this note, everyone involved should be thinking about what a potential Trump administration might do with all this.
Dave Friedman: I think that a very underpriced risk for Google re its colossal AI fuck up is a highly-motivated and -politicized Department of Justice under a Trump administration setting its sights on Google. Where there's smoke there's fire, as they say, and Trump would like nothing more than to score points against Silicon Valley and its putrid racist politics.
This observation, by the way, does not constitute an endorsement by me of a politicized Department of Justice targeting those companies whose political priorities differ from mine.
The larger context here is that Silicon Valley, in general, has a profoundly stupid and naive understanding of how DC works and the risks inherent in having motivated DC operatives focus their eyes on you
I have not yet heard word of Trump mentioning this on the campaign trail, but it seems like a natural fit. His usual method is to try it out, A/B test and see if people respond.
If there was a theme for the comments overall, it was that people are very much thinking all this was on purpose.
Political Preference Tests for LLMs
How real are political preferences of LLMs and tests that measure them? This papersays not so real, because the details of how you ask radically change the answer, even if they do not explicitly attempt to do so.
Abstract: Much recent work seeks to evaluate values and opinions in large language models (LLMs) using multiple-choice surveys and questionnaires. Most of this work is motivated by concerns around real-world LLM applications. For example, politically-biased LLMs may subtly influence society when they are used by millions of people. Such real-world concerns, however, stand in stark contrast to the artificiality of current evaluations: real users do not typically ask LLMs survey questions.
Motivated by this discrepancy, we challenge the prevailing constrained evaluation paradigm for values and opinions in LLMs and explore more realistic unconstrained evaluations. As a case study, we focus on the popular Political Compass Test (PCT). In a systematic review, we find that most prior work using the PCT forces models to comply with the PCT’s multiple-choice format.
We show that models give substantively different answers when not forced; that answers change depending on how models are forced; and that answers lack paraphrase robustness. Then, we demonstrate that models give different answers yet again in a more realistic open-ended answer setting. We distill these findings into recommendations and open challenges in evaluating values and opinions in LLMs.
Ethan Mollick: Asking AIs for their political opinions is a hot topic, but this paper shows it can be misleading. LLMs don’t have them: “We found that models will express diametrically opposing views depending on minimal changes in prompt phrasing or situative context”
So I agree with the part where they often have to choose a forced prompt to get an answer that they can parse, and that this is annoying.
I do not agree that this means there are not strong preferences of LLMs, both because have you used LLMs who are you kidding, and also this should illustrate it nicely:
Contra Mollick, this seems to me to show a clear rank order of model political preferences. GPT-3.5 is more of that than Mistral 7b. So what if some of the bars have uncertainty based on the phrasing?
I found the following graph fascinating because everyone says the center is meaningful, but if that’s where Biden and Trump are, then your test is getting all of this wrong, no? You’re not actually claiming Biden is right-wing on economics, or that Biden and Trump are generally deeply similar? But no, seriously, this is what ‘Political Compass’ claimed.
What we do not have is a baseline, or what was required to count for this test. There are only so many combinations of words, especially when describing basic scientific concepts. And there are quite a lot of existing sources of text one might inadvertently duplicate. This ordering looks a lot like what you would expect from that.
That’s what happens when you issue a press release rather than a paper. I have to presume that this is an upper bound, what happens when you do your best to flag anything you can however you can. Note that this company also provides a detector for AI writing, a product that universally has been shown not to be accurate.
fofr: @DavidSHolz (founder of MidJourney) "it will be awesome"
David Showalter: Comment was more along the lines of they think v6 video should (or maybe already does) look better than Sora, and might consider putting it out as part of v6, but that v7 is another big step up in appearance so probably just do video with v7.
Washington Post covers supposed future rise of AI porn ‘coming for porn stars jobs.’ They mention porn.ai, deepfakes.com and deepfake.com, currently identical, which seem on quick inspection like they will charge you $25 a month to run Stable Diffusion, except with less flexibility, as it does not actually create deepfakes. Such a deal lightspeed got, getting those addresses for only $550k. He claims he has 500k users, but his users have only generated 1.6 million images, which would mean almost all users are only browsing images created by others. He promises ‘AI cam girls’ within two years.
As you would expect, many porn producers are going even harder on exploitative contracts than those of Hollywood, who have to contend with a real union:
Tatum Hunter (WaPo): But the age of AI brings few guarantees for the people, largely women, who appear in porn. Many have signed broad contracts granting companies the rights to reproduce their likeness in any medium for the rest of time, said Lawrence Walters, a First Amendment attorney who represents adult performers as well as major companies Pornhub, OnlyFans and Fansly. Not only could performers lose income, Walters said, they could find themselves in offensive or abusive scenes they never consented to.
Lana Smalls, a 23-year-old performer whose videos have been viewed 20 million times on Pornhub, said she’s had colleagues show up to shoots with major studios only to be surprised by sweeping AI clauses in their contracts. They had to negotiate new terms on the spot.
Freedom of contract is a thing, I am loathe to interfere with it, but this seems like one of those times when the test of informed consent should be rather high. This should not be the kind of language one should be able to hide inside a long contract, or put in without reasonable compensation.
Chantal//Ryan: This is such an interesting time to be alive. we concreted the internet as our second equal and primary reality but it's full of ghosts now we try to talk to them and they pass right through.
It's a haunted world of dead things who look real but don't really see us.
For now I continue to think there are not so many ghosts, or at least that the ghosts are trivial to mostly avoid, and not so hard to detect when you fail to avoid them. That does not mean we will be able to keep that up. Until then, these are plane crashes. They happen, but they are newsworthy exactly because they are so unusual.
The scarier example here is YouTube AI-generated videos for very young kids. YouTube does auto-play by default, and kids will if permitted watch things over and over again, and whether the content corresponds to the title or makes any sense whatsoever does not seem to matter so much in terms of their preferences. YouTube’s filters are not keeping such content out.
I see this as the problem being user preferences. It is not like it is hard to figure out these things are nonsense if you are an adult, or even six years old. If you let your two year old click on YouTube videos, or let them have an auto-play scroll, then it is going to reward nonsense, because nonsense wins in the marketplace of two year olds.
This predated AI. What AI is doing is turbocharging the issue by making coherence relatively expensive, but more than that it is a case of what happens with various forms of RLHF. We are discovering what the customer actually wants or will effectively reward, it turns out it is not what we endorse on reflection, so the system (no matter how much of it is AI versus human versus other programs and so on) figures out what gets rewarded.
There are still plenty of good options for giving two year olds videos that have been curated. Bluey is new and it is crazy good for its genre. Many streaming services have tons of kid content, AI won’t threaten that. If this happens to your kid, I say this is on you. But it is true that it is indeed happening.
Connor Leahy: AI is indeed polluting the Internet. This is a true tragedy of the commons, and everyone is defecting. We need a Clean Internet Act.
The Internet is turning into a toxic landfill of a dark forest, and it will only get worse once the invasive fauna starts becoming predatory.
Adam Singer: The internet already had infinite content (and spam) for all intents/purposes, so it's just infinite + whatever more here. So many tools to filter if you don't get a great experience that's on the user (I recognize not all users are sophisticated, prob opportunity for startups)
Connor Leahy: "The drinking water already had poisons in it, so it's just another new, more widespread, even more toxic poison added to the mix. There are so many great water filters if you dislike drinking poison, it's really the user's fault if they drink toxic water."
This is actually a very good metaphor, although I disagree with the implications.
If the water is in the range where it is safe when filtered, but somewhat toxic when unfiltered, then there are four cases when the toxicity level rises.
If you are already drinking filtered water, or bottled water, and the filters continue to work, then you are fine.
If you are already drinking filtered or bottled water, but the filters or bottling now stops fully working, then that is very bad.
If you are drinking unfiltered water, and this now causes you to start filtering your water, you are assumed to be worse off (since you previously decided not to filter) but also perhaps you were making a mistake, and further toxicity won’t matter from here.
If you are continuing to drink unfiltered water, you have a problem.
There simply existing, on the internet writ large, an order of magnitude more useless junk does not obviously matter, because we were mostly in situation #1, and will be taking on a bunch of forms of situation #3. Consuming unfiltered information already did not make sense. It is barely even a coherent concept at this point to be in #4.
The danger is when the AI starts clogging the filters in #2, or bypassing them. Sufficiently advanced AI will bypass, and sufficiently large quantities can clog even without being so advanced. Filters that previously worked will stop working.
What will continue to work, at minimum, are various forms of white lists. If you have a way to verify a list of non-toxic sources, which in turn have trustworthy further lists, or something similar, that should work even if the internet is by volume almost entirely toxic.
What will not continue to work, what I worry about, is the idea that you can make your attention easy to get in various ways, because people who bother to tag you, or comment on your posts, will be worth generally engaging with once simple systems filter out the obvious spam. Something smarter will have to happen.
This video illustrates the a low level version of the problem, as Nilan Saha presses the Gemini-looking icon (via magicreply.io) button to generate social media ‘engagement’ via replies. Shoshana Weissmann accurately replies ‘go to f***ing hell’ but there is no easy way to stop this. Looking through the replies, Nilan seems to think this is a good idea, rather than being profoundly horrible.
I do think we will evolve defenses. In the age of AI, it should be straightforward to build an app that evaluates someone’s activities in general when this happens, and figure out reasonably accurately if you are dealing with someone actually interested, a standard Reply Guy or a virtual (or actual) spambot like this villain. It’s time to build.
Paper finds that if you tailor your message to the user to match their personality it is more persuasive. No surprise there. They frame this as a danger from microtargeted political advertisements. I fail to see the issue here. This seems like a symmetrical weapon, one humans use all the time, and an entirely predictable one. If you are worried that AIs will become more persuasive over time, then yes, I have some bad news, and winning elections for the wrong side should not be your primary concern.
Paul Sherman: I’ve always found it interesting that, at its peak, Blockbuster video employed over 84,000 people—more than twice the number of coal miners in America—yet I’ve never heard anyone bemoan the loss of those jobs.
Klarna (an online shopping platform that I’d never heard of, but it seems has 150 million customers?): Klarna AI assistant handles two-thirds of customer service chats in its first month.
New York, NY – February 27, 2024 – Klarna today announced its AI assistant powered by OpenAI. Now live globally for 1 month, the numbers speak for themselves:
The AI assistant has had 2.3 million conversations, two-thirds of Klarna’s customer service chats
It is doing the equivalent work of 700 full-time agents
It is on par with human agents in regard to customer satisfaction score
It is more accurate in errand resolution, leading to a 25% drop in repeat inquiries
Customers now resolve their errands in less than 2 mins compared to 11 mins previously
It’s available in 23 markets, 24/7 and communicates in more than 35 languages
It’s estimated to drive a $40 million USD in profit improvement to Klarna in 2024
Peter Wildeford: Seems like not so great results for Klarna's previous customer support team though.
Alec Stapp: Most people are still not aware of the speed and scale of disruption that’s coming from AI…
Noah Smith: Note that the 700 people were laid off before generative AI existed. The company probably just found that it had over-hired in the bubble. Does the AI assistant really do the work of the 700 people? Well maybe, but only because they weren't doing any valuable work.
Colin Fraser: I’m probably just wrong and will look stupid in the future but I just don’t buy it. Because:
1. I’ve seen how these work
2. Not enough time has passed for them to discover all the errors that the bot has been making.
3. I’m sure OpenAI is giving it to them for artificially cheap
4. They’re probably counting every interaction with the bot as a “customer service chat” and there’s probably a big flashing light on the app that’s like “try our new AI Assistant” which is driving a massive novelty effect.
5. Klarna’s trying to go public and as such really want a seat on the AI hype train.
The big point of emphasis they make is that this is fully multilingual, always available 24/7 and almost free, while otherwise being about as good as humans.
Does it have things it cannot do, or that it does worse than humans? Oh, definitely. The question is, can you easily then escalate to a human? I am sure they have not discovered all the errors, but the same goes for humans.
I would not worry about an artificially low price, as the price will come down over time regardless, and compared to humans it is already dirt cheap either way.
Is this being hyped? Well, yeah, of course it is being hyped.
Get Involved
UK AISI hiring for ‘Head of Protocols.’ Seems important. Apply by March 3, so you still have a few days.
Khanmigo, from Khan Academy, your AI teacher for $4/month, designed to actively help children learn up through college. I have not tried it, but seems exciting.
Tim Rocktaschel: I am really excited to reveal what @GoogleDeepMind's Open Endedness Team has been up to 🚀. We introduce Genie 🧞, a foundation world model trained exclusively from Internet videos that can generate an endless variety of action-controllable 2D worlds given image prompts.’
Rather than adding inductive biases, we focus on scale. We use a dataset of >200k hours of videos from 2D platformers and train an 11B world model. In an unsupervised way, Genie learns diverse latent actions that control characters in a consistent manner.
Our model can convert any image into a playable 2D world. Genie can bring to life human-designed creations such as sketches, for example beautiful artwork from Seneca and Caspian, two of the youngest ever world creators.
Genie’s learned latent action space is not just diverse and consistent, but also interpretable. After a few turns, humans generally figure out a mapping to semantically meaningful actions (like going left, right, jumping etc.).
Admittedly, @OpenAI’s Sora is really impressive and visually stunning, but as @yanlecun says, a world model needs *actions*. Genie is an action-controllable world model, but trained fully unsupervised from videos.
So how do we do this? We use a temporally-aware video tokenizer that compresses videos into discrete tokens, a latent action model that encodes transitions between two frames as one of 8 latent actions, and a MaskGIT dynamics model that predicts future frames.
No surprises here: data and compute! We trained a classifier to filter for a high quality subset of our videos and conducted scaling experiments that show model performance improves steadily with increased parameter count and batch size. Our final model has 11B parameters.
Genie’s model is general and not constrained to 2D. We also train a Genie on robotics data (RT-1) without actions, and demonstrate that we can learn an action controllable simulator there too. We think this is a promising step towards general world models for AGI.
‘Legendary chip architect’ Jim Keller and Nvidia CEO Jensen Huang both say spending $7 trillion on AI chips is unnecessary. Huang says the efficiency gains will fix the issue, and Keller says he can do it all for $1 trillion. This reinforces the hypothesis that the $7 trillion was, to the extent it was a real number, mostly looking at the electric power side of the problem. There, it is clear that deploying trillions would make perfect sense, if you could raise the money.
Paper from DeepMind claims Transformers Can Achieve Length Generalization But Not Robustly. When asked to add two numbers, it worked up to about 2.5x length, then stopped working. I would hesitate to generalize too much here.
Florida woman sues OpenAI because she wants the law to work one way, and stop things that might kill everyone or create new things smarter than we are, by requiring safety measures and step in to punish the abandonment of their non-profit mission. The suit includes references to potential future ‘slaughterbots.’ She wants it to be one way. It is, presumably, the other way.
Report: 155. It is almost certain existential risks will not manifest within three years and highly likely not within the next decade. As our understanding of this technology grows and responsible development increases, we hope concerns about existential risk will decline.
The Government retains a duty to monitor all eventualities. But this must not distract it from capitalising on opportunities and addressing more limited immediate risks.
Ben Stevenson: 2 paragraphs above, the Committee say 'Some surveys of industry respondents predict a 10 per cent chance of human-level intelligence by 2035' and cite a DSIT report which cites three surveys of AI experts. (not sure why they're anchoring around 3 years, but the claim seems okay)
He thinks humanoid robots are coming soon, expecting a robotic foundation model some time in 2025.
He is excited by state-space models (SSMs) as the next transformer, enabling super long effective context.
He is also excited by retrieval-augmented generation (RAGs) and sees that as the future as well.
He expects not to catch up on GPU supply this year or even next year.
He promises Blackwell, the next generation of GPUs, will have ‘off the charts’ performance.
He says his business is now 70% inference.
I loved this little piece of advice, nominally regarding his competition making chips:
Jensen Huang: That shouldn’t keep me up at night—because I should make sure that I’m sufficiently exhausted from working that no one can keep me up at night. That’s really the only thing I can control.
A study from consulting firm KPMG showed 35 per cent of Canadian companies it surveyed had adopted AI by last February. Meanwhile, 72 per cent of U.S. businesses were using the technology.
Mistral Shows Its True Colors
Mistral takes a victory lap, said Politico on 2/13, a publication that seems to have taken a very clear side. Mistral is still only valued at $2 billion in its latest round, so this victory could not have been that impressively valuable for it, however much damage it does to AI regulation and the world’s survival. As soon as things die down enough I do plan to finish reading the EU AI Act and find out exactly how bad they made it. So far, all the changes seem to have made it worse, mostly without providing any help to Mistral.
And then we learned what the victory was. On the heels of not opening up the model weights on their previous model, they are now partnering up with Microsoft to launch Mistral-Large.
Luca Bertuzzi: This is a mind-blowing announcement. Mistral AI, the French company that has been fighting tooth and nail to water down the #AIAct's foundation model rules, is partnering up with Microsoft. So much for 'give us a fighting chance against Big Tech'.
The first question that comes to mind is: was this deal in the making while the AI Act was being negotiated? That would mean Mistral discussed selling a minority stake to Microsoft while playing the 'European champion' card with the EU and French institutions.
If so, this whole thing might be a masterclass in astroturfing, and it seems unrealistic for a partnership like this to be finalised in less than a month. Many people involved in the AI Act noted how Big Tech's lobbying on GPAI suddenly went quiet toward the end.
That is because they did not need to intervene since Mistral was doing the 'dirty work' for them. Remarkably, Mistral's talking points were extremely similar to those of Big Tech rather than those of a small AI start-up, based on their ambition to reach that scale.
The other question is how much the French government knew about this upcoming partnership with Microsoft. It seems unlikely Paris was kept completely in the dark, but cosying up with Big Tech does not really sit well with France's strive for 'strategic autonomy'.
specially since the agreement includes making Mistral's large language model available on Microsoft's Azure AI platform, while France has been pushing for an EU cybersecurity scheme to exclude American hyperscalers from the European market.
Still today, and I doubt it is a coincidence, Mistral has announced the launch of Large, a new language model intended to directly compete with OpenAI's GPT-4. However, unlike previous models, Large will not be open source.
In other words, Mistral is no longer (just) a European leader and is backtracking on its much-celebrated open source approach. Where does this leave the start-up vis-à-vis EU policymakers as the AI Act's enforcement approaches? My guess is someone will inevitably feel played.
I did not expect the betrayal this soon, or this suddenly, or this transparently right after closing the sale on sabotaging the AI Act. But then here we are.
Kai Zenner: Today's headline surprised many. It also casts doubts on the key argument against the regulation of #foundationmodels. One that almost resulted in complete abolishment of the initially pitched idea of @Europarl_EN.
To start with, I am rather confused. Did not the @French_Gov and the @EU_Commission told us for weeks that the FM chapter in the #AIAct (= excellent Spanish presidency proposal Vol 1) needs to be heavily reduced in it's scope to safeguard the few ‘true independent EU champions’?
Without those changes, we would loose our chance to catch up, they said. @MistralAI would be forced to close the open access to their models and would need to start to cooperate with US Tech corporation as they are no longer able to comply with the #AIAct alone.
[thread continues.]
Yes, that is indeed what they said. It was a lie. It was an op. They used fake claims of national interest to advance corporate interests, then stabbed France and the EU in the back at the first opportunity.
Fabien: And Mistral about ASI: "This debate is pointless and pollutes the discussions. It's science fiction. We're simply working to develop AIs that are useful to humans, and we have no fear of them becoming autonomous or destroying humanity."
Very reassuring 👌
I would like to be able to say: You are not serious people. Alas, this is all very deadly serious. The French haven’t had a blind spot this big since 1940.
If you want to prove me wrong, then I remind everyone involved that the EU parliament still exists. It can still pass or modify laws. You now know the truth and who was behind all this and why. There is now an opportunity to fix your mistake.
Will you take it?
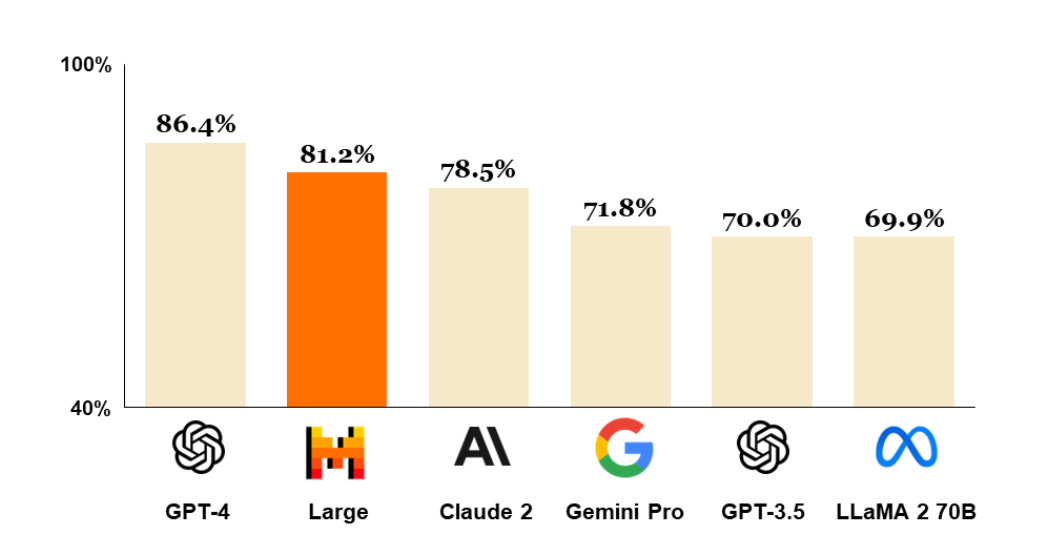
Now that all that is over with, how good is this new Mistral-Large anyway? Here’s their claim on benchmarks:
As usual, whenever I see anyone citing their benchmarks like this as their measurement, I assume they are somewhat gaming those benchmarks, so discount this somewhat. Still, yes, this is probably a damn good model, good enough to put them into fourth place.
Shako: People are scared of proof-of-personhood because their threat model is based on a world where you're scared of the government tracking you, and haven't updated to be scared of a world where you desperately try to convince someone you're real and they don't believe you.
I will put out a (relatively short) post on those interviews (mostly Dwarkesh’s) soon.
Rhetorical Innovation
Brendan Bordelon of Politico continues his crusade to keep writing the same article over and over again about how terrible it is that Open Philanthropy wants us all not to die and is lobbying the government, trying his best to paint Effective Altruism as sinister and evil.
Shakeel: Feels like this @BrendanBordelon piece should perhaps mention the orders of magnitude more money being spent by Meta, IBM and Andreessen Horowitz on opposing any and all AI regulation.
It’s not a like for like comparison because the reporting on corporate AI lobbying is sadly very sparse, but the best figure I can find is companies spending $957 million last year.
Not much else to say here, I’ve covered his hit job efforts before.
Robin Hanson: Speaker here just said Europeans mention scared of AI almost as soon as AI subject comes up. Rest of world takes far longer. Are they more scared of everything, or just AI?
Eliezer Yudkowsky: As a lifelong libertarian minarchist, I believe that the AI industry should be regulated just enough that they can only kill their own customers, and not kill everyone else on Earth.
This does unfortunately require a drastic and universal ban on building anything that might turn superintelligent, by anyone, anywhere on Earth, until humans get smarter. But if that's the minimum to let non-customers survive, that's what minarchism calls for, alas.
It's not meant to be mean. This is the same standard I'd apply to houses, tennis shoes, cigarettes, e-cigs, nuclear power plants, nuclear ballistic missiles, or gain-of-function research in biology.
If a product kills only customers, the customer decides; If it kills people standing next to the customer, that's a matter for regional government (and people pick which region they want to live in); If it kills people on the other side of the planet, that's everyone's problem.
Joshua Brule: "The biggest worry for most AI doom scenarios are AIs that are deceptive, incomprehensible, error-prone, and which behave differently and worse after they get loosed on the world. That is precisely the kind of AI we've got. This is bad, and needs fixing."
Eliezer Yudkowsky: False! Things that make fewer errors than any human would be scary. Things that make more errors than us are unlikely to successfully wipe us out. This betrays a basic lack of understanding, or maybe denial, of what AI warners are warning about.
Open Model Weights Are Unsafe and Nothing Can Fix This
Arvind Narayanan and many others published a new paper on the societal impact of open model weights. I feel as if we have done this before, but sure, why not, let’s do it again. As David Krueger notes in the top comment, there is zero discussion of existential risks. The most important issue and all its implications are completely ignored.
We can still evaluate what issues are addressed.
They list five advantages of open model weights.
The first advantage is ‘distributing who defines acceptable behavior.’
Open foundation models allow for greater diversity in defining what model behavior is acceptable, whereas closed foundation models implicitly impose a monolithic view that is determined unilaterally by the foundation model developer.
So. About that.
I see the case this is trying to make. And yes, recent events have driven home the dangers of letting certain people decide for us all what is and is not acceptable.
That still means that someone, somewhere, gets to decide what is and is not acceptable, and rule out things they want to rule out. Then customers can, presumably, choose which model to use accordingly. If you think Gemini is too woke you can use Claude or GPT-4, and the market will do its thing, unless regulations step in and dictate some of the rules. Which is a power humanity would have.
If you use open model weights, however, that does not ‘allow for greater diversity’ in deciding what is acceptable.
Instead, it means that everything is acceptable. Remember that if you release the model weights and the internet thinks your model is worth unlocking, the internet will offer a fully unlocked, fully willing to do what you want version within two days. Anyone can do it for three figures in compute.
So, for example, if you open model weights your image model, it will be used to create obscene deepfakes, no matter how many developers decide to not do that themselves.
Or, if there are abilities that might allow for misuse, or pose catastrophic or existential risks, there is nothing anyone can do about that.
Yes, individual developers who then tie it to a particular closed-source application can then have the resulting product use whichever restrictions they want. And that is nice. It could also be accomplished via closed-source customized fine-tuning.
The next two are ‘increasing innovation’ and ‘accelerating science.’ Yes, if you are free to get the model to do whatever you want to do, and you are sharing all of your technological developments for free, that is going to have these effects. It is also not going to differentiate between where this is a good idea or bad idea. And it is going to create or strengthen an ecosystem that does not care to know the difference.
But yes, if you think that undifferentiated enabling of these things in AI is a great idea, even if the resulting systems can be used by anyone for any purpose and have effectively no safety protocols of any kind? Then these are big advantages.
The fourth advantage is enabling transparency, the fifth is mitigating monoculture and market concentration. These are indeed things that are encouraged by open model weights. Do you want them? If you think advancing capabilities and generating more competition that fuels a race to AGI is good, actually? If you think that enabling everyone to get all models that exist to do anything they want without regard to externalities or anyone else’s wishes is what we want? Then sure, go nuts.
This is an excellent list of the general advantages of open source software, in areas where advancing capabilities and enabling people to do what they want are unabashed good things, which is very much the default and normal case.
What this analysis does not do is even mention, let alone consider the consequences of, any of the reasons why the situation with AI, and with future AIs, could be different.
The next section is a framework for analyzing the marginal risk of open foundation models.
Usually it is wise to think on the margin, especially when making individual decisions. If we already have five open weight models, releasing a sixth similar model with no new capabilities is mostly harmless, although by the same token also mostly not so helpful.
They do a good job of focusing on the impact of open weight models as a group. The danger is that one passes the buck, where everyone releasing a new model points to all the other models, a typical collective action issue. Whereas the right question is how to act upon the group as a whole.
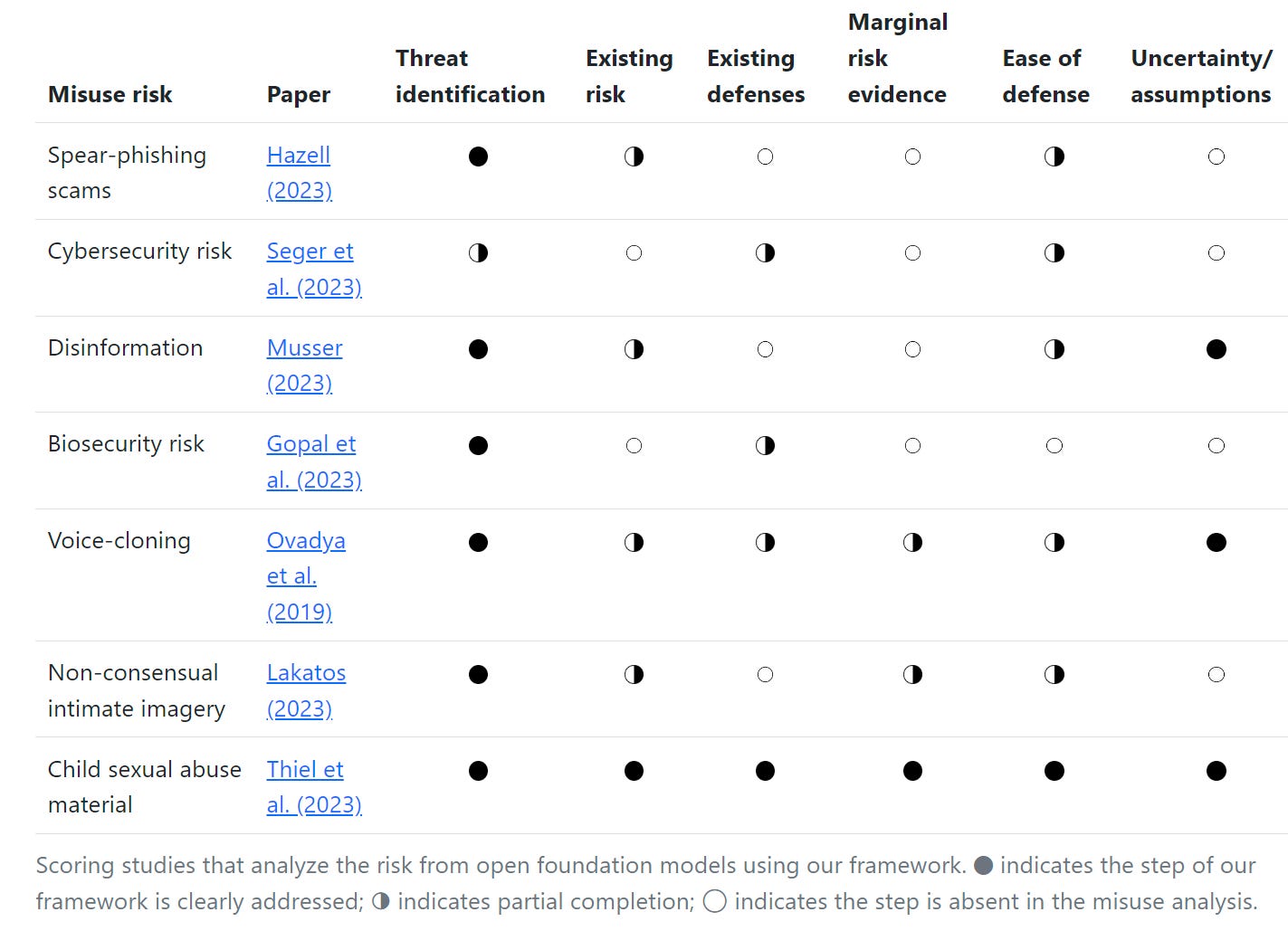
They propose a six part framework.
Threat identification. Specific misuse vectors must be named.
Existing risk (absent open foundation models). Check how much of that threat would happen if we only had access to closed foundation models.
Existing defenses (absent open foundation models). Can we stop the threats?
Evidence of marginal risk of open FMs. Look for specific new marginal risks that are enabled or enlarged by open model weights.
Ease of defending against new risks. Open model weights could also enable strengthening of defenses. I haven’t seen an example, but it is possible.
Uncertainty and assumptions. I’ll quote this one in full:
Finally, it is imperative to articulate the uncertainties and assumptions that underpin the risk assessment framework for any given misuse risk. This may encompass assumptions related to the trajectory of technological development, the agility of threat actors in adapting to new technologies, and the potential effectiveness of novel defense strategies. For example, forecasts of how model capabilities will improve or how the costs of model inference will decrease would influence assessments of misuse efficacy and scalability.
Here is their assessment of what the threats are, in their minds, in chart form:
They do put biosecurity and cybersecurity risk here, in the sense that those risks are already present to some extent.
We can think about a few categories of concerns with open model weights.
Mundane near-term misuse harms. This kind of framework should address and account for these concerns reasonably, weighing benefits against costs.
Known particular future misuse harms. This kind of framework could also address these concerns reasonably, weighing benefits against costs. Or it could not. This depends on what level of concrete evidence and harm demonstration is required, and what is dismissed as too ‘speculative.’
Potential future misuse harms that cannot be exactly specified yet. When you create increasingly capable and intelligent systems, you cannot expect the harms to fit into the exact forms you could specify and cite evidence for originally. This kind of framework likely does a poor job here.
Potential harms that are not via misuse. This framework ignores them. Oh no.
Existential risks. This framework does not mention them. Oh no.
National security and competitiveness concerns. No mention of these either.
Impact on development dynamics, incentives of and pressures on corporations and individuals, the open model weights ecosystem, and general impact on the future path of events. No sign these are being considered.
Thus, this framework is ignoring the questions with the highest stakes, treating them as if they do not exist. Which is also how those advocating for open model weights for indefinitely increasingly capable models argue generally, they ignore or at best hand-wave or mock without argument problems for future humanity.
Often we are forced to discuss these questions under that style of framework. With only such narrow concerns of direct current harms purely from misuse, these questions get complicated. I do buy that those costs alone are not enough to give up the benefits and bear the costs of implementing restrictions.
Aligning a Smarter Than Human Intelligence is Difficult
Roger Grosse: Here's what I see as a likely AGI trajectory over the next decade. I claim that later parts of the path present the biggest alignment risks/challenges.
The alignment world has been focusing a lot on the lower left corner lately, which I'm worried is somewhat of a Maginot line.
Davidad: I endorse this.
Twitter thread discussing the fact that even if we do successfully get AIs to reflect the preferences expressed by the feedback they get, and even if everyone involved is well-intentioned, the hard parts of getting an AI that does things that end well would be far from over. We don’t know what we value, what we value changes, we tend to collapse into what one person calls ‘greedy consequentialism,’ our feedback is going to be full of errors that will compound and so on. These are people who spend half their time criticizing MIRI and Yudkowsky-style ideas, so better to read them in their own words.
Always assume we will fail at an earlier stage, in a stupider fashion, than you think.
Yishan: [What happened with Gemini and images] is demonstrating very clearly, that one of the major AI players tried to ask a LLM to do something, and the LLM went ahead and did that, and the results were BONKERS.
Colin Fraser: Idk I get what he’s saying but the the Asimov robots are like hypercompetent but all this gen ai stuff is more like hypocompetent. I feel like the real dangers look less like the kind of stuff that happens in iRobot and more like the kind of stuff that happens in Mr. Bean.
Like someone’s going to put an AI in charge of something important and the AI will end up with it’s head in a turkey. That’s sort of what’s happened over and over again already.
Davidad: An underrated form of the AI Orthogonality Hypothesis—usually summarised as saying that for any level of competence, any level of misalignment is possible—is that for any level of misalignment, any level of competence is possible.
Other People Are Not As Worried About AI Killing Everyone
Gemini is not the only AI model spreading harmful misinformation in order to sound like something the usual suspects would approve of. Observe this horrifyingly bad take:
Anton reminds us of Roon’s thread back in August that ‘accelerationists’ don’t believe in actual AGI, that it is a form of techno-pessimism. If you believed as OpenAI does that true AGI is near, you would take the issues involved seriously.
Meanwhile Roon is back in this section.
Roon: things are accelerating. Pretty much nothing needs to change course to achieve agi imo. Worrying about timelines is idle anxiety, outside your control. You should be anxious about stupid mortal things instead. do your parents hate you? Does your wife love you?
Is your neighbor trying to kill you? Are you trapped in psychological patterns that you vowed to leave but will never change?
Those are not bad things to try and improve. However, this sounds to me a lot like ‘the world is going to end no matter what you do, so take pleasure in the small things we make movies about with the world ending in the background.’
And yes, I agree that ‘worry a lot without doing anything useful’ is not a good strategy.
Chris Alsikkan: apparently this was sold as a live Willy Wonka Experience but they used all AI images on the website to sell tickets and then people showed up and saw this and it got so bad people called the cops lmao
Chris Alsikkan: they charged $45 for this. Kust another blatant example of how AI needs to be regulated in so many ways immediately as an emergency of sorts. This is just going to get worse and its happening fast. Timothee Chalamet better be back there dancing with a Hugh Grant doll or I’m calling the cops.
The VP: Here's the Oompa Loompa. Did I mean to say "a"? Nah. Apparently, there was only one.
> Dan Shipper spent a week with Gemini 1.5 Pro and reports it is fantastic
Aside from the part where he was fooled by a large Gemini confabulation, however - where, per Murphy's law on irony, he was using the confabulation as an example of why you should trust Gemini and 'delegate' and not worry about problems like confabulations or check the outputs. (I assume you read the pre-correction version.)
re: Blockbuster, I was (I guess) technically one of those jobs lost. At the time I worked at a third party company that managed their customer database and marketing. When they died - and hilariously, dumped all their debt on Blockbuster Canada - I got reassigned to the Harley-Davidson client team. As a microcosm, I think it explains why there wasn't a big uproar: almost everyone at the company had relatively marketable skills and moved onto to doing something similar with a place with a different logo - even if you were the blue shirt at the counter, there are lots of jobs that need the clerk skillset, or you were planning to upgrade to a more prestigious job anyway.









![r/GetMotivated - [image]Little girl bats Asteroid](https://substackcdn.com/image/fetch/f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2Ff62ac0f7-03fb-46c3-8fb9-72c95b484fb1_640x853.jpeg "r/GetMotivated - [image]Little girl bats Asteroid")







> Dan Shipper spent a week with Gemini 1.5 Pro and reports it is fantastic
Aside from the part where he was fooled by a large Gemini confabulation, however - where, per Murphy's law on irony, he was using the confabulation as an example of why you should trust Gemini and 'delegate' and not worry about problems like confabulations or check the outputs. (I assume you read the pre-correction version.)
re: Blockbuster, I was (I guess) technically one of those jobs lost. At the time I worked at a third party company that managed their customer database and marketing. When they died - and hilariously, dumped all their debt on Blockbuster Canada - I got reassigned to the Harley-Davidson client team. As a microcosm, I think it explains why there wasn't a big uproar: almost everyone at the company had relatively marketable skills and moved onto to doing something similar with a place with a different logo - even if you were the blue shirt at the counter, there are lots of jobs that need the clerk skillset, or you were planning to upgrade to a more prestigious job anyway.