I had a great time at LessOnline. It was a both a working trip and also a trip to an alternate universe, a road not taken, a vision of a different life where you get up and start the day in dialogue with Agnes Callard and Aristotle and in a strange combination of relaxed and frantically go from conversation to conversation on various topics, every hour passing doors of missed opportunity, gone forever.
Most of all it meant almost no writing done for five days, so I am shall we say a bit behind again. Thus, the following topics are pending at this time, in order of my guess as to priority right now:
Partly due to Leopold, partly due to an open letter, partly due to continuing small things, OpenAI fallout continues, yes we are still doing this. This should wait until after Leopold.
DeepMind’s new scaling policy. I have a first draft, still a bunch of work to do.
The OpenAI model spec. As soon as I have the cycles and anyone at OpenAI would have the cycles to read it. I have a first draft, but that was written before a lot happened, so I’d want to see if anything has changed.
The Rand report on securing AI model weights, which deserves more attention than the brief summary I am giving it here.
You’ve Got Seoul. I’ve heard some sources optimistic about what happened there but mostly we’ve heard little. It doesn’t seem that time sensitive, diplomacy flows slowly until it suddenly doesn’t.
The Problem of the Post-Apocalyptic Vault still beckons if I ever have time.
Also I haven’t processed anything non-AI in three weeks, the folders keep getting bigger, but that is a (problem? opportunity?) for future me. And there are various secondary RSS feeds I have not checked.
Did AI pass a restaurant review ‘Turing test,’ or did human Yelp reviewers fail it? This is unsurprising, since the reviews seemingly were evaluated in isolation. Writing short bits like this is the wheelhouse. At minimum, you need to show the context, meaning the other information about the restaurant, including other reviews.
Via David Brin, goblin.tools has a formalizer, to change the tone of your text. You can of course do better with a normal LLM but an easier interface and no startup costs can go a long way.
It seems McDonalds does this too with its fries. My guess is this is more ‘we have enough fungible fries orders often enough that we simply make fries continuously’ rather than ‘we know you in particular will want fries’ but I could be wrong.
Would you like an extra thumb? Why yes I would. What’s funny is you can run a mental experiment to confirm that you’re totally capable of learning to use it if the machine can read the impulses. Plausibly super awesome. Mandatory jokes are in the comments if you scroll down.
Garry Tan endorses Perplexity for search if you want well-cited answers. I agree with Arun’s reply, Perplexity is great but only shines for narrow purposes. The ‘well-cited’ clause is doing a lot of work.
Shoshana Weissmann: ugh really wanna jailbreak my nordictrack.
Brian Chen (New York Times) is not impressed by the new GPT-4, failing to see much improvement other than speed, saying he definitely wouldn’t let it tutor his child. This was a standard ‘look for places the AI fails’ rather than looking for where it succeeds. A great illustration is when he notes the translations were good, but that the Chinese accents were slightly off. Yes, okay, let’s improve the accents, but you are missing the point. Any child, or any adult, not using AI to learn is missing out.
Erik Wiffin warns of counterfeit proofs of thought. What happens if all those seemingly useless project plans and self-reports were actually about forcing people to think and plan? What if the plan was worthless, but the planning was essential, and now you can forge the plan without the planning? Whoops. Zizek’s alternative is that your LLM writes the report, mine reads it and now we are free to learn. Which way, modern worker?
For the self-report I lean towards Zizek. This is mostly a test to see how much bullshit you dare write down on a page before you think you’ll be called out on it, a key way that the bullshitters collude to get ahead at the expense of those who don’t know to go along or have qualms about doing so.
The idea that ‘your manager already knows' might be true in some places, but it sure is not in others.
I can’t remember the last time I knew someone who thought ‘writing this mandatory corporate self-report taught me so many valuable lessons’ because no one I know is that naive.
The project plan seems more plausibly Wriffin’s territory. You should have to form a plan. That does not mean that the time spent turning that plan into a document that looks right is time well spent. So the goal is to get the manager to do the actual planning - Alice makes the Widgets, David buys the Thingamabobs. Then the LLM turns that into a formal document.
Look, I am not a master of war, but if I was Air Force Secretary Frank Kendall then I would presume that the point of an F-16 flying with AI was that I did not have to be inside that F-16 during simulated combats. He made a different decision. I mean, all right, yes, show of confidence, fun as hell, still I suppose that is one of many reasons I am not the secretary of the air force.
The funny alternative theory is this was so the other humans would let the AI win.
Still no worthy successor to AI dungeon, despite that being a flimsy base model wrapper and being a great product until you ran into its context window limits. The ‘put AI into games and interactive worlds’ developers are letting us down. Websim is kind of the modern version, perhaps, and Saerain Trismegistus mentions NovelAI.
> Politicians are voluntarily deepfaking themselves
> to dub their message into the 22 languages widely spoken in India
> 50 million AI voice clone calls in the last month
> resurrecting deceased party leaders to endorse current candidates (the cult of personality never ends.. when Lee Kuan Yew?)
> super small teams - leading firm has 10 employees, founder dropped out of college after learning to make deepfakes on Reddit during the COVID breakdowns (for every learning loss.. there was a learning gain 🤣)
> authorized by politicians but not disclosed to voters. Many voters believe the calls are real and that the pols actually spoke to them
> typical gap in quality AI “promises a Ferrari but delivers a Fiat”
> fine tuning Mistral to get better results
This too will come to the 🇺🇸
The future of politics is having a parasocial relationship with your favorite politician, and their AI version being part of your brain trust, advisory board.
Kache: Americans don't realize that in india and pakistan, people watch AI generated shorts of political leaders and believe that they are real.
This is such a wild equilibrium. Everyone gets to clone their own candidates and backers with AI, no one does fakes of others, the voters believe all of it is real.
Not a bad equilibrium. Yes, voters are fooled, but it is a ‘fair fooling’ and every message is intended by the candidate and party it purports to be from. This presumably is the least stable situation of all time and won’t happen again. The people will realize the AIs are fake. Also various actors will start trying to fake others using AI, but perhaps punishment and detection can actually work there?
One might think about the ‘leave your stroller at the playground and not pay attention’ technology. Yes, someone could try to steal it, but there is at least one person in the playground who would get very, very angry with you if they notice you trying to do that. What makes yours yours is not that you can prove it is yours, but that when you try to take it, you know no one will object.
A metaphorical TaskRabbit for AI hires, potentially something like EquiStamp, could be the efficient way to go. Alex Tabarrok suggests we may continuously evaluate, hire and fire AIs as relative performance, speed and cost fluctuate. Indeed, the power users of AI do this, and I am constantly reassessing which tools to use for which jobs, same as any other tool. A lot of this is that right now uses are mostly generic and non-integrated. It is easy to rotate. When we have more specialized tools, and need more assurance of consistent responses, it will be more exciting to stick to what you know relative to now.
Near: the experts have chimed in and have concerns that talking to animals might be bad. Lu0ckily I am going to ignore them and do it anyway!
Someone Explains It All
Marcello Herreshoff explains the idea of ‘template fixation.’ If your question is close enough to a sufficiently strong cliche, the cliche gets applied even if it does not make sense. Hence the stupid answers to river crossing questions or water pouring tests or other twists on common riddles. If we can’t find a way to avoid this, math is going to remain tough. It is easy to see why this would happen.
Leading AI companies agree to share their models with the US AI Safety Institute for pre-deployment testing. Link is to this story, which does not list which labs have agreed to do it, although it says there was no pushback.
NewsCorp’s deal with OpenAI, which includes the Wall Street Journal, is no joke, valued at over $250 million ‘in cash and credits’ over five years. The NewsCorp market cap is 15.8 billion after rising on the deal, so this is over 1% of the company over only five years. Seems very hard to turn down that kind of money. One key question I have not seen answered is to what extent these deals are exclusive.
Yes, AI models are mimics of deeply WEIRD data sets, so they act and respond in a Western cultural context. If you would rather create an AI that predicts something else, that most customers would want less but some would want more, that seems easy enough to do instead.
Google getting rid of San Francisco office space. Prices for office space are radically down for a reason, work from home reduces needed space and if the landlords wouldn’t play ball you can relocate to another who will, although I see no signs Google is doing that. Indeed, Google is shrinking headcount, and seems to be firing people semi-randomly in doing so, which is definitely not something I would do. I would presume that doing a Musk-style purge of the bottom half of Google employees would go well. But you can only do that if you have a good idea which half is which.
OpenAI terminates five user accounts that were attempting to use OpenAI’s models to support ‘covert influence operations,’ which OpenAI defines as ‘attempts to manipulate public opinion or influence political outcomes without revealing the true identity of the actors behind them.’ Full report here.
Specifically, the five are Russian actors Bad Grammer and Doppelganger, Chinese actor Spamouflage that was associated with Chinese law enforcement, Iranian actor International Union of Virtual Media and actions by the Israeli commercial company Stoic.
Note the implications of an arm of China’s law enforcement using ChatGPT for this.
OpenAI believes that the operations in question failed to substantially achieve their objectives. Engagement was not generated, distribution not achieved. These times.
What were these accounts doing?
Largely the same things any other account would do. There are multiple mentions of translation between languages, generating headlines, copy editing, debugging code and managing websites.
As OpenAI put it, ‘productivity gains,’ ‘content generation’ and ‘mixing old and new.’
Except, you know, as a bad thing. For evil, and all that.
They also point to the common theme of faking engagement, and arguably using ChatGPT for unlabeled content generation (as opposed to other productivity gains or copy editing) is also inherently not okay as well.
Ordinary refusals seem to have played a key role, as ‘threat actors’ often published the refusals, and the steady streams of refusals allowed OpenAI to notice threat actors. Working together with peers is also reported as helpful.
The full report clarifies that this is sticking to a narrow definition I can fully support. What is not allowed is pretending AI systems are people, or attributing AI content to fake people or without someone’s consent. That was the common theme.
Thus, Sam Altman’s access to OpenAI’s models will continue.
Preventing new accounts from being opened by these treat actors seems difficult, although this at least imposes frictions and added costs.
There are doubtless many other ‘covert influence operations’ that continue to spam AI content while retaining access to OpenAI’s models without disruption.
One obvious commonality is that all five actors listed here had clear international geopolitical goals. It is highly implausible that this is not being done for many other purposes. Until we are finding (for example) the stock manipulators, we have a long way to go.
This is still an excellent place to start. I appreciate this report, and would like to see similar updates (or at least brief updates) from Google and Anthropic.
WSJ’s Christopher Mins says ‘The AI Revolution is Already Losing Steam.’ He admits my portfolio would disagree. He says AIs ‘remain ruinously expensive to run’ without noticing the continuing steady drop in costs for a given performance level. He says adoption is slow, which it isn’t compared to almost any other technology even now. Mostly, another example of how a year goes by with ‘only’ a dramatic rise in speed and reduction in cost and multiple players catching up to the leader and the economy not transformed and stocks only way up and everyone loses their minds.
I think that is behind a lot what is happening now. The narratives in Washington, the dismissal by the mainstream of both existential risks and even the possibility of real economic change. It is all the most extreme ‘what have you done for me lately,’ people assuming AI will never be any better than it is now, or it will only change at ‘economic normal’ rates from here.
Thus, my prediction is that when GPT-5 or another similar large advance does happen, these people will change their tune for a bit, adjust to the new paradigm, then memory hole and go back to assuming that AI once again will never advance much beyond that. And so on.
Eliezer Yudkowsky: The promise of Microsoft Recall is that extremely early AGIs will have all the info they need to launch vast blackmail campaigns against huge swathes of humanity, at a time when LLMs are still stupid enough to lose the resulting conflict.
Rohit: I’d read this novel!
A lot of users having such a honeypot on their machines for both blackmail and stealing all their access and their stuff certainly does interesting things to incentives. One positive is that you encourage would-be bad actors to reveal themselves, but you also empower them, and you encourage actors to go bad or skill up in badness.
Dan Hendrycks questions algorithmic efficiency improvements, notes that if (GPT-)4-level models were now 10x cheaper to train we would see a lot more of them, and that secondary labs should not be that far behind. I do not think we should assume that many labs are that close to OpenAI in efficiency terms or in ‘having our stuff together’ terms.
Papers I analyze based on the abstract because that’s all the time we have for today: Owen Davis formalizes ways in which AI could weaken ‘worker power’ distinct from any impacts on labor demand, via management use of AI. The obvious flaw is that this does not mention the ability of labor to use AI. Labor can among other applications use AI to know when it is being underpaid or mistreated and to greatly lower switching costs. It also could allow much stronger signals of value, allowing workers more ability to switch jobs. I would not be so quick to assume ‘worker power’ will flow in one direction or the other in a non-transformative AI world.
Samuel Hammond on SB 1047
Samuel Hammond wrote a few days ago in opposition to SB 1047, prior to the recent changes. He supports the core idea, but worries about particular details. Many of his concerns have now been addressed. This is the constructive way to approach the issue.
He objected to the ‘otherwise similar general capability’ clause on vagueness grounds. The clause has been removed.
He warns of a ‘potential chilling effect on open source,’ due to inability to implement a shutdown clause. The good news is that this was already a misunderstanding of the bill before the changes. The changes make my previous interpretation even clearer, so this concern is now moot as well.
And as I noted, the ‘under penalty of perjury’ is effectively pro forma unless you are actively lying, the same as endless other government documents with a similar rules set.
Also part of Samuel’s stated second objection: He misunderstands the limited duty exemption procedure, saying it must be applied for before training, which is not the case.
You do not apply for it, you flat out invoke it, and you can do this either before or after training.
He warns that you cannot predict in advance what capabilities your model will have, but in that case the developer can invoke before training and only has to monitor for unexpected capabilities and then take back the exemption (without punishment) if that does happen.
Or they can wait, and invoke after training, if the model qualifies.
Samuel’s third objection is the fully general one, and still applies: that model creators should not be held liable for damages caused by their models, equating it to what happens if a hacker uses a computer. This is a good discussion to have. I think it should be obvious to all reasonable parties that both that (a) model creators should not be liable for harms simply because the person doing harm used the model while doing the harm and (b) that model creators need to be liable if they are sufficiently negligent or irresponsible, and sufficiently large harm results. This is no different than most other product harms. We need to talk procedure and price.
In the case of the SB 1047 proposed procedure, I find it to be an outlier in how tight are the requirements for a civil suit. Indeed, under any conditions where an AI company was actually held liable under SB 1047 for an incident with over $500 million in damages, I would expect that company to already also be liable under existing law.
I strongly disagree with the idea that if someone does minimal-cost (relative to model training costs) fine tuning to Llama-4, this should absolve Meta of any responsibility for the resulting system and any damage that it does. I am happy to have that debate.
There was indeed a problem with the original derivative model clause here, which has been fixed. We can talk price, and whether the 25% threshold now in SB 1047 is too high, but the right price is not 0.001%.
Samuel also objects to the ‘net neutrality’ style pricing requirements on GPUs and cloud services, which he finds net negative but likely redundant. I would be fine with removing those provisions and I agree they are minor.
He affirms the importance of whistleblower provisions, on which we agree.
Samuel’s conclusion was that SB 1047 ‘risks America’s global AI leadership outright.’ I would have been happy to bet very heavily against such impacts even based on the old version of the bill. For the new version, if anyone wants action on that bet, I would be happy to give action. Please suggest terms.
In the realm of less reasonable objections that also pre-dated the recent changes, here is the latest hyperbolic misinformation about SB 1047, here from Joscha Bach and Daniel Jeffreys, noted because of the retweet from Paul Graham. I have updated my ‘ignorables list’ accordingly.
Reactions to Changes to SB 1047
My prediction on Twitter was that most opponents of SB 1047, of which I was thinking especially of its most vocal opponents, would not change their minds.
I also said we would learn a lot, in the coming days and weeks, from how various people react to the changes.
So far we have blissfully heard nothing from most of ‘the usual suspects.’
Charles Foster gets the hat tip for alerting me to the changes via this thread. He was also the first one I noticed that highlighted the bill’s biggest previous flaw, so he has scored major RTFB points.
He does not offer a position on the overall bill, but is very good about noticing the implications of the changes.
Charles Foster: In fact, the effective compute threshold over time will be even higher now than it would’ve been if they had just removed the “similar performance” clause. The conjunction of >10^26 FLOP *and* >$100M means the threshold rises with FLOP/$ improvements.
…
It is “Moore’s law adjusted” if by that you mean that the effective compute threshold will adjust upwards in line with falling compute prices over time. And also in line with $ inflation over time.
He also claims this change, which I can’t locate:
- “Hazardous capability” now determined by marginal risk over existing *nonexempt* covered models
If true, then that covers my other concern as well, and should make it trivial to provide the necessary reasonable assurance if you are not pushing the frontier.
Finally, he concludes:
Charles Foster: I think the bill is significantly better now. I didn’t take a directly pro- or anti-stance before, and IDK if I will in the future, but it seems like the revised bill is a much better reflection of the drafters’ stated intentions with fewer side effects. That seems quite good.
Andrew Critch: These look like good changes to me. The legal definition of "Covered Model" is now clearer and more enforceable, and creates less regulatory uncertainty for small/non-incumbent players in the AI space, hence more economic fairness + freedom + prosperity. Nice work, California!
I think I understand the rationale for the earlier more restrictive language, but I think if a more restrictive definition of "covered model" is needed in the future, lowering numerical threshold(s) will be the best way to achieve that, rather than debating the meaning of the qualitative definition(s). Clear language is crucial for enforcement, and the world *definitely* needs enforceable AI safety regulations. Progress like this makes me proud to be a resident of California.
Nick Moran points to the remaining issue with the 25% rule for derivative models, which is that if your open weights model is more than 4x over the threshold, then you create a window where training ‘on top of’ your model could make you responsible for a distinct otherwise covered model.
In practice I presume this is fine - both no one is going to do this, and if they did no one is going to hold you accountable for something that clearly is not your fault and if they did the courts would throw it out - but I do recognize the chilling effect, and that in a future panic situation I could be wrong.
The good news is there is an obvious fix, now that the issue is made clear. You change ‘25% of trained compute’ to ‘either 25% of trained compute or sufficient compute to qualify as a covered model.’ That should close the loophole fully, unless I missed something.
I have been heartened by the reactions of those in my internet orbit who were skeptical but not strongly opposed. There are indeed some people who care about bill details and adjust accordingly.
His reaction admits The Big Flip up front, then goes looking for problems.
Dean Ball: SB 1047 has been amended, as Senator Wiener recently telegraphed. My high-level thoughts:
1. There are some good changes, including narrowing the definition of a covered model
2. The bill is now more complex, and arguably harder for devs to comply with.
Big picture: the things that the developer and academic communities hated about SB 1047 remain: generalized civil and criminal liability for misuse beyond a developer’s control and the Frontier Model Division.
It is strictly easier to comply in the sense that anything that complied before complies now, but if you want to know where the line is? Yeah, that’s currently a mess.
I see this partly as the necessary consequence of everyone loudly yelling about how this hits the ‘little guy,’ which forced an ugly metric to prove it will never, ever hit the little guy, which forces you to use dollars where you shouldn’t.
That is no excuse for not putting in a ‘this is how you figure out what the market price will be so you can tell where the line is’ mechanism. We 100% need some mechanism.
The obvious suggestion is to have a provision that says the FMD publish a number once a (week, month or year) that establishes the price used. Then going forward you can use that to do the math, and it can at least act as a safe harbor. I presume this is a case of ‘new provision that no one gamed out fully’ and we can fix it.
Dean next raises a few questions about the 25% threshold for training (which the developer must disclose), around questions like the cost of synthetic data generation. My presumption is that data generation does not count here, but we could clarify that either way.
He warns that there is no dollar floor on the 25%, but given you can pick the most expansive open model available, it seems unlikely this threshold will ever be cheap to reach in practice unless you are using a very old model as your base, in which case I suppose you fill out the limited duty exemption form with ‘of course it is.’
If you want to fix that at the cost of complexity, there are various ways to cover this corner case.
Ball mentions the safety assurances. My non-lawyer read was that the changes clarify that this is the ‘reasonable assurance’ standard they use in other law and not anything like full confidence, exactly to (heh) provide reasonable assurance that the rule would be reasonable. If lawyers or lawmakers think that’s wrong let me know, but there is a particular sentence inserted to clarify exactly that.
He also mentions that Weiner at one point mentioned Trump in the context of the executive order. It was a cheap shot as phrased given no one knows what Trump ultimately thinks about AI, and I wish he hadn’t said that, but Trump has indeed promised to repeal Biden’s executive order on AI, so the actual point - that Congress is unlikely to act and executive action cannot be relied upon to hold - seems solid.
In a follow-up he says despite the changes that SB 1047 is still ‘aimed squarely at future generations of open-source foundation models.’ I rather see open models as having been granted exemptions from several safety provisions exactly because those are forms of safety that open models cannot provide, and their community making special pleading that they should get even more of a free pass. Requiring models adhere to even very light safety requirements is seen as ‘aimed squarely at open source’ exactly because open models make safety far more difficult.
Dean also notes here that Senator Weiner is making a good case for federal preemption of state policies. I think Weiner would to a large extent even agree with this, that it would be much better if the federal government acted to enact a similar law. I do not see California trying to override anything, rather it is trying to fill a void.
Danielle Fong here notes the bill is better, but remains opposed, citing the fee structure and general distrust of government.
Godoglyness: No, because the bill still does too much. Why should 10^26 and 100 million dollars be a cutoff point?
There shouldn't be any cutoffs enacted until we have actual harms to calibrate on
It's good the impact of the bill is diminished but it's bad it still exists at all
Remember how some folks thought GPT2 would be dangerous? Ridiculous in retrospect, but...
We shouldn't stop big training runs because of speculative harms when the speculation has failed again and again to anticipate the form/impact/nature of AI systems.
If you think ‘deal with the problems post-hoc after they happen’ is a superior policy, then of course you should oppose the bill, and be similarly clear on the logic.
Similarly, if your argument is ‘I want the biggest most capable possible open models to play with regardless of safety concerns and this might interfere with Meta opening the weights of Llama-N’ and I will oppose any bill that does that, then yes, that is another valid reason to oppose the bill. Again, please say that.
That is very different from misrepresenting the bill, or claiming it would impact people it even more explicitly than before does not impact.
On that note, here is Andrew Ng ignoring the changes and reiterating past arguments in ways that did not apply to the original bill and apply even less now that the comparison point for harm has been moved. For your model to be liable, it has to enable the actions in a way that non-covered models and models eligible for limited duty exemptions would not. Andrew Ng mentions that all current models can be jailbroken, but I do not see how that should make us intervene less. Ultimately he is going for the ‘only regulate applications’ approach that definitely won’t work. Arvind Narayanan calls it a ‘nice analysis.’
The Quest for Sane Regulations
TIDNL, featuring helpfully clear section headlines like “Corporate America Looks to Control AI Policy” and section first sentences such as “Corporate interests are dominating lobbying on AI issues.”
Luke Muehlhauser: No surprise: "85 percent of the lobbyists hired in 2023 to lobby on AI-related issues were hired by corporations or corporate-aligned trade groups"
[thread contains discussion on definition of lobbying, linkedto here.]
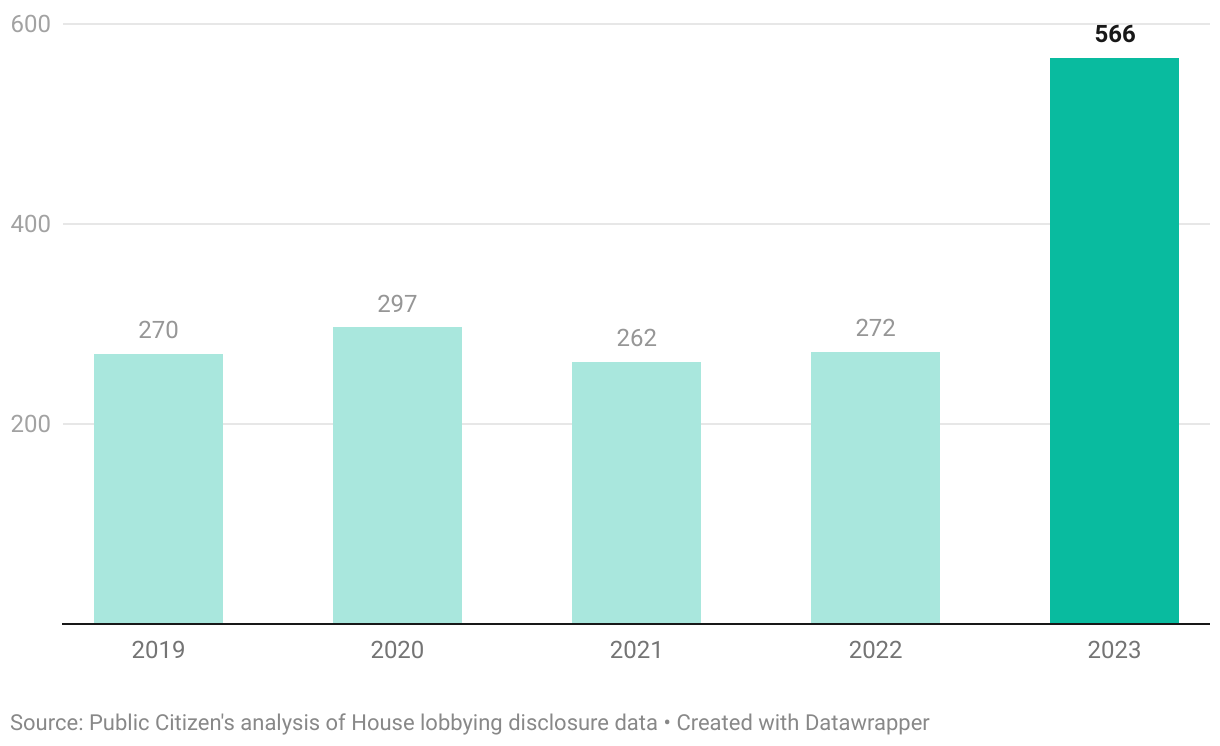
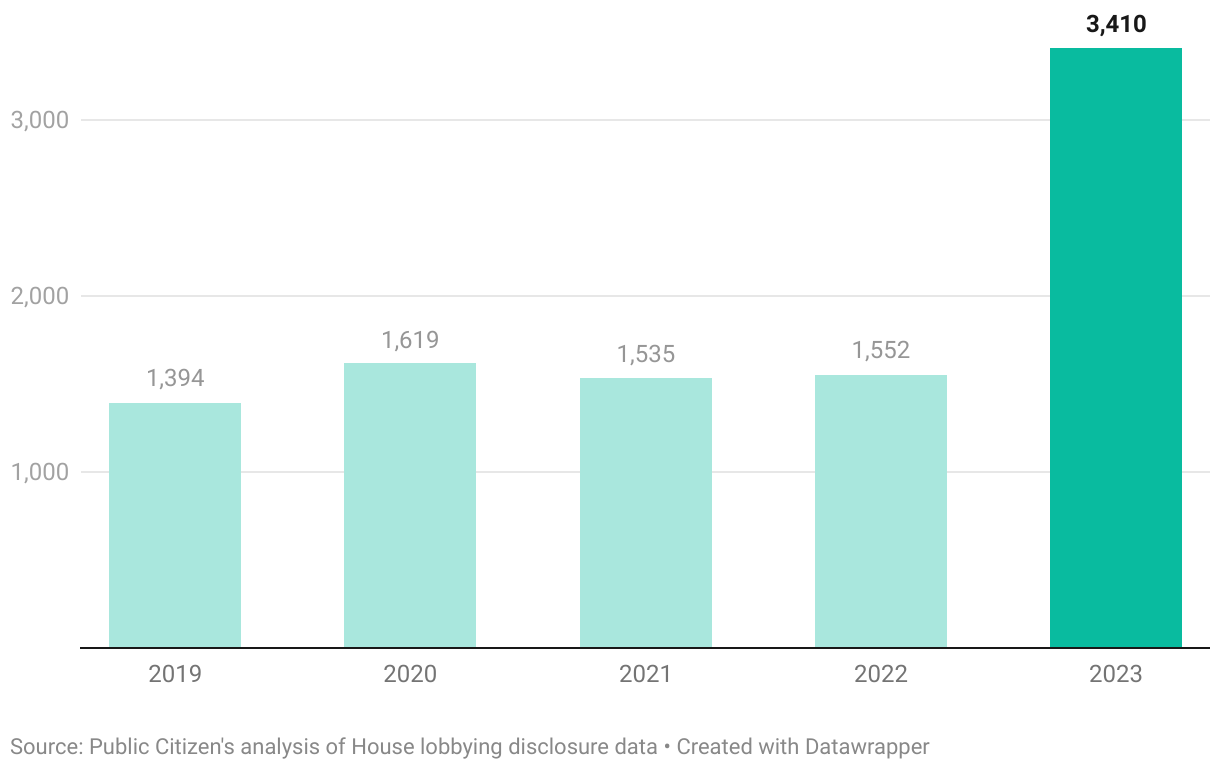
Public Citizen: Corporations, trade groups and other organizations sent more than 3,400 lobbyists to lobby the federal government on AI-related issues in 2023, a 120 percent leap from 2022.
AI is not just an issue of concern for AI and software corporations: While the tech industry was responsible for the most AI-related lobbyists in 2023 – close to 700 – the total amounts to only 20 percent of all the AI-related lobbyists deployed. Lobbyists from a broad distribution of industries outside of tech engaged in AI-related issues, including financial services, healthcare, telecommunications, transportation, and defense.
85 percent of the lobbyists hired in 2023 to lobby on AI-related issues were hired by corporations or corporate-aligned trade groups. The Chamber of Commerce was responsible for the most AI-related lobbyists, 81, followed by Intuit (64), Microsoft (60), the Business Roundtable (42), and Amazon (35).
OpenSecrets found that groups that lobbied on AI in 2023 spent a total of $957 million lobbying the federal government on all issues that year. [Note that this is for all purposes, not only for AI]
An analysis of the clients revealed that while many clients resided in the tech industry, they still only made up 16% of all clients by industry.
The transportation sector, which ranked sixth for having the most clients lobby on AI-related issues, has engaged heavily on policies regarding autonomous vehicles.
In the defense sector, 30 clients hired a combined total of 168 lobbyists to work on AI issues. Given the U.S. Department of Defense and military’s growing interest in AI, defense companies that are often major government contractors have been increasingly implementing AI for military applications.
…
…in August 2023 the Pentagon announced a major new program, the Replicator Initiative, that aim to rely heavily on autonomous drones to combat Chinese missile strength in a theoretical conflict over Taiwan or at China’s eastern coast.
Look. Guys. If you are ever tempted to call something the Replicator Initiative, there are three things to know.
Do not do the Replicator Initiative.
Do not do the Replicator Initiative.
Do not do the Replicator Initiative.
Also, as a bonus, at a bare minimum, do not call it the Replicator Initiative.
As federal agencies move forward with developing guardrails for AI technologies, stakeholders will likely rely even more on their lobbyists to shape how AI policy is formed.
You know one way to know your guardrails are lacking?
You called a program the Replicator Initiative.
Yes, expect tons of lobbying, mostly corporate lobbying.
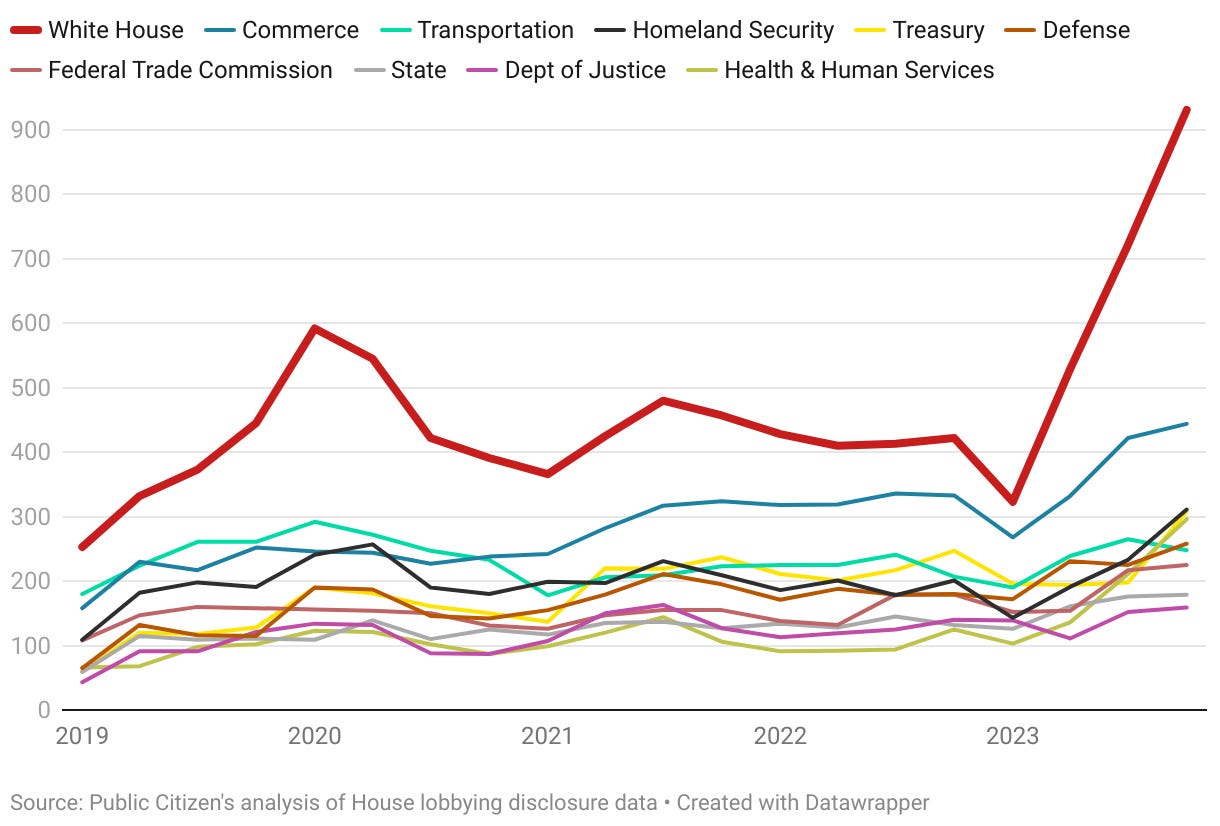
Where will they lobby? It seems the White House is the place for the cool kids.
So who is involved?
Even in cases where at first glance a lobbying entity may not appear to be representing corporate interests, digging deeper into partnerships and collaborations revealed that non-profit interests are often deeply intertwined with corporate ones as well.
Only five of the top 50 lobbying entities responsible for the most AI-related lobbyists in 2023 were not representing corporate interests. Two of the five were large hospitals – the Mayo Clinic and The New York and Presbyterian Hospital – while the other three were the AFL-CIO, AARP, and the National Fair Housing Alliance. None of the five were in the top ten
Did you notice any names not on that list?
Most of that lobbying is highly orthogonal to the things generally discussed here. Hospitals are presumably concerned primarily with health care applications and electronic medical records. That was enough for multiple hospital groups to each outspend all lobbying efforts towards mitigating existential risk.
Adam Thierer implores us to just think of the potential, reminds us to beat China, urges ‘pro-innovation’ AI policy vision. It’s a Greatest Hits on so many levels. The core proposal is that ‘the time is now’ to… put a moratorium on any new rules on AI, and preempt any potential state actions. Do nothing, only more so.
To be completely fair to Newsom this is not the first time he has warned about overregulation - he did it in 2004 regarding the San Francisco business permitting process, which is a canonical insane example of overregulation, and he has indeed taken some ‘concrete steps’ as governor to streamline some regulatory burdens, including an executive order and signing AB 1817. But also:
As usual in politics, this is both-sides applause light talk that does not tell you the price. The price is not going to be zero, nor would that be wise even if there was no existential risk, any more than we should have no laws about humans. The price is also a cost, and setting it too high would be bad.
The world as it is: FEC fighting FCC’s attempt to require political ads to disclose that they used AI, saying FCC lacks jurisdiction, and finding it ‘deeply troubling’ that they want this in place before the election with it happening so soon. How is ‘political ads that use AI tell us they are using AI’ not one of the things we can all agree upon?
Josh Sisco (Politico): The Justice Department and Federal Trade Commission are nearing an agreement to divvy up investigations of potential anticompetitive conduct by some of the world’s largest technology companies in the artificial intelligence industry, according to three people with knowledge of the negotiations.
As part of the arrangement, the DOJ is poised to investigate Nvidia and its leading position in supplying the high-end semiconductors underpinning AI computing, while the FTC is set to probe whether Microsoft, and its partner OpenAI, have unfair advantages with the rapidly evolving technology, particularly around the technology used for large language models.
…
The deal has been negotiated for nearly a year. And while leaders of both agencies have expressed urgency in ensuring that the rapidly growing artificial intelligence technology is not dominated by existing tech giants, until an agreement is finalized, there was very little investigative work they could do.
Fredipus Rex: Also, how in the world is OpenAI, which loses money on a mostly free product that has existed for two years and which is in a constant game of monthly technological leapfrog with a bunch of competitors in any possible way a “monopoly”?
Ian Spencer: Microsoft and OpenAI have nothing even remotely resembling monopolies in the AI space. Nvidia is facing competition everywhere, despite being clear market leaders.
It’s ASML and TSMC who have truly dominant market positions thanks to their R&D, and neither of them is based in the US.
Shoshana Weissmann: Every day is pain.
I do not know whether to laugh or cry.
A year ago they wanted to start an antitrust investigation, but it took that long to negotiate between agencies?
The antitrust was based on the idea that some companies in technological races had currently superior technologies and were thus commanding large market shares while rapidly improving their products and what you could get at a given price, and producing as fast as they could require input components?
Perhaps the best part is that during that year, during which OpenAI has been highly unprofitable in order to fight for market share and develop better products, two distinct competitors caught up to OpenAI and are now offering comparable products, although OpenAI likely will get to the next generation level first.
Or is the best part that Microsoft so little trusts OpenAI that they are spending unholy amounts of money to engage in direct competition with them?
Meanwhile Nvidia faces direct competition on a variety of fronts and is both maximizing supply and rapidly improving its products while not charging anything like the market clearing price.
This from the people who brought you ‘Google monopolized search,’ ‘Amazon prices are too high,’ ‘Amazon prices are too low’ and ‘Amazon prices are suspiciously similar.’
As Ian notes, in theory one could consider ASML or TSMC as more plausible monopolies, but neither is exploiting its position, and also neither is American so we can’t go after them. If anything I find the continued failure of both to raise prices to be a confusing aspect of the world.
It is vital not only not to prosecute companies like OpenAI for antitrust. They vitally need limited exemptions from antitrust, so that if they get together to collaborate on safety, they need not worry the government will prosecute them for it.
I have yet to see a free market type who wants to accelerate AI and place absolutely no restrictions on its development call for this particular exemption.
Lex Fridman: Here's my conversation with Roman Yampolskiy, AI safety researcher who believes that the chance of AGI eventually destroying human civilization is 99.9999%. I will continue to chat with many AI researchers & engineers, most of whom put p(doom) at <20%, but it's important to balance those technical conversations by understanding the long-term existential risks of AI. This was a terrifying and fascinating discussion.
If you are interested in communication of and debate about existential risk, this is a podcast worth listening to. I could feel some attempts of Roman’s working because they worked well, others working by playing to Lex’s instincts in strange ways, others leading into traps or bouncing off before the reactions even happened. I saw Lex ask some very good questions and make some leaps, while being of all the Lex Fridmans the Lex Fidmanest in others. It is amazing how much he harps on the zoo concept as a desperate hope target, or how he does not realize that out of all the possible futures, most of the ones we can imagine and find interesting involve humans because we are human, but most of the configurations of atoms don’t involve us. And so on.
Also it is unfortunate (for many purposes) that Roman has so many additional funky views such as his perspective on the simulation hypothesis, but he is no doubt saying what he actually believes.
Request for best philosophical critique against AI existential risk. I am dismayed how many people exactly failed to follow the directions. We need to do better at that. I think the best practical critique is to doubt that we will create AGI any time soon, which may or may not be philosophical depending on details. It is good to periodically survey the answers out there.
Your periodic reminder that there are plenty of people out there on any high stakes topic who are ‘having a normal one,’ and indeed that a lot of people’s views are kind of crazy. And also that in-depth discussions of potential transformationally different future worlds are going to sound weird at times if you go looking for weirdness. As one commenter notes, if people keep retweeting the crazytown statements but not the people saying sanetown statements, you know what you will see. For other examples, see: Every political discussion, ever, my lord, actually please don’t, I like you.
Helen Toner: Trying to communicate nuance in AI rn be like
Me: people think xrisk=skynet, but there are lots of ways AI could cause civilization-scale problems, and lots of throughlines w/today's harms, so we shouldn't always have those conversations separately
Liron Shapira: Will humanity be able to determine which ASI behavior is safe & desirable by having it output explanations and arguments that we can judge?
Some argue yes. Some argue no. It’s tough to judge.
SO YOU SEE WHY THE ANSWER IS OBVIOUSLY NO.
That does not rule out all possible outs, but it is a vital thing to understand.
Jeffrey Ladish: I'm a bit sad about the state of AI discourse and governance right now. Lot of discussions about innovation vs. safety, what can / should the government actually do... but I feel like there is an elephant in the room
We're rushing towards intelligent AI agents that vastly outstrip human abilities. A new non-biological species that will possess powers wonderful and terrible to behold. And we have no plan for dealing with that, no ability to coordinate as a species to avoid a catastrophic outcome
We don't know exactly when we'll get AI systems with superhuman capabilities... systems that can strategize, persuade, invent new technologies, etc. far better than we can. But it sure seems like these capabilities are in our sights. It sure seems like the huge investments in compute and scale will pay off, and people will build the kinds of systems AI risk researchers are most afraid of
If decision makers around the world can't see this elephant in the room, I worry anything they try to do will fall far short of adequate.
Ashley Darkstone: Maybe if you and people like you stopped using biological/animist terms like "species" to refer to AI, you'd be taken more seriously.
Jeffrey Ladish: It's hard to talk about something that is very different than anything that's happened before. We don't have good language for it. Do you have language you'd use to describe a whole other class of intelligent agent?
Ashley Darkstone: Only language specific to my work. We'll all have to develop the language over time, along with the legalism, etc.
Species has specific implications to people. Life/Slavery/Evolution.. Biological/Human things that need not apply. It's fearmongering.
AI should be a selfless tool.
Jeffrey Ladish: Maybe AI should be a selfless tool, but I think people train powerful agents
I studied evolutionary biology in college and thought a fair bit about different species concepts, all imperfect 🤷
"fearmongering" seems pretty dismissive of the risks at hand
is Darkstone objecting to the metaphorical use of a biological term because it is more confusing than helpful, more heat than light? Because it is technically incorrect, the worst kind of incorrect? Because it is tone policing?
Or is it exactly because of her belief that ‘AI should be a selfless tool’?
That’s a nice aspiration, but Ladish’s point is exactly that this won’t remain true.
More and more I view objections to AI risk as being rooted in not believing in the underlying technologies, rather than an actual functioning disagreement. And objections to the terminology and metaphors used being for the same reason: The terminology and metaphors imply that AGI and agents worthy of those names are coming, whereas objectors only believe in ATI (artificial tool inheritance).
Thus I attempt to coin the term ATI: Artificial Tool Intelligence.
Definition: Artificial Tool Intelligence. An intelligent system incapable of functioning as the core of a de facto autonomous agent.
If we were to only ever build ATIs, then that would solve most of our bigger worries.
That is a lot easier said than done.
Keegan McBride makes case that open source AI is vital for national security, because ‘Whoever builds, maintains, or controls the global open source AI ecosystem will have a powerful influence on our shared digital future.’
Toad: But our rivals can copy the open source models and modify them.
Frog: That is true. But that will ensure our cultural dominance, somehow?
Toad then noticed he was confused.
The post is filled with claims about China’s pending AI ascendancy, and to defend against that she says we need to open source our AIs.
I do give Keegan full credit for rhetorical innovation on that one.
Oh Anthropic
It would be really great if we could know Anthropic was worthy of our trust.
We know that Anthropic has cultivated a culture of caring deeply about safety, especially existential safety, among its employees. I know a number of its employees who have sent costly signals that they deeply care.
We know that Anthropic is taking the problems far more seriously than its competitors, and investing more heavily in safety work.
We know that Anthropic at least thinks somewhat about whether its actions will raise or lower the probability that AI kills everyone when it makes its decisions.
We know they have the long term benefit trust and are a public benefit corporation.
No, seriously, have you seen the other guy?
I have. It isn’t pretty.
Alas, the failure of your main rival to live up to ‘ordinary corporation’ standards does not change the bar of success. If Anthropic is also not up to the task, or not worthy of trust, then that is that.
I have said, for a while now, that I am confused about Anthropic. I expect to continue to be confused, because they are not making this easy.
Anthropic has a principle of mostly not communicating much, including on safety, and being extremely careful when it does communicate.
This is understandable. As their employees have said, there is a large tendency of people to read into statements, to think they are stronger or different than they are, that they make commitments the statement does not make. The situation is changing rapidly, so what seemed wise before might not be wise now. People and companies can and should change their minds. Stepping into such discussions often enflames them, making the problem worse, people want endless follow-ups, it is not a discussion you want to focus on. Talking about what the thing you are doing can endanger your ability to do the thing. Again, I get it.
Still? They are not making this easy. The plan might be wise, but the price must be paid. You go to update with the evidence you have. Failure to send costly signals is evidence, even if your actions plausibly make sense in a lot of different worlds.
What exactly did Anthropic promise or imply around not improving the state of the art? What exactly did they say to Dustin Moskovitz on this? Anthropic passed on releasing the initial Claude, but then did ship Claude Opus, and before that the first 100k context window.
To what extent is Anthropic the kind of actor who will work to give you an impression that suits its needs without that impacting its ultimate decisions? What should we make of their recent investor deck?
What public commitments has Anthropic actually made going forward? How could we hold them accountable? They have committed to their RSP, but most of it can be changed via procedure. Beyond that, not clear there is much. Will the benefit trust in practice have much effect especially in light of recent board changes?
What is up with Anthropic’s public communications?
Once again this week, we saw Anthropic’s public communications lead come out warning about overregulation, in ways I expect to help move the Overton window away from the things that are likely going to become necessary.
Simeon: Anthropic policy lead now advocating against AI regulation. What a surprise for an AGI lab 🤯
If you work at Anthropic for safety reasons, consider leaving.
The lookback at GPT-2 and decisions around its release seems insightful. They correctly foresaw problems, and correctly saw the need to move off of the track of free academic release of models. Of course that GPT-2 was entirely harmless because it lacked sufficient capabilities, and in hindsight that seems very obvious, and part of the point is that it is hard to tell in advance. Here they ‘missed high’ but one could as easily ‘miss low.’
Then comes the part about policy. Here is the part being quoted, in context, plus key other passages.
Jack Clark: I've come to believe that in policy "a little goes a long way" - it's far better to have a couple of ideas you think are robustly good in all futures and advocate for those than make a confident bet on ideas custom-designed for one specific future - especially if it's based on a very confident risk model that sits at some unknowable point in front of you.
Additionally, the more risk-oriented you make your policy proposal, the more you tend to assign a huge amount of power to some regulatory entity - and history shows that once we assign power to governments, they're loathe to subsequently give that power back to the people. Policy is a ratchet and things tend to accrete over time. That means whatever power we assign governments today represents the floor of their power in the future - so we should be extremely cautious in assigning them power because I guarantee we will not be able to take it back.
For this reason, I've found myself increasingly at odds with some of the ideas being thrown around in AI policy circles, like those relating to needing a license to develop AI systems; ones that seek to make it harder and more expensive for people to deploy large-scale open source AI models; shutting down AI development worldwide for some period of time; the creation of net-new government or state-level bureaucracies to create compliance barriers to deployment.
…
Yes, you think the future is on the line and you want to create an army to save the future. But have you considered that your actions naturally create and equip an army from the present that seeks to fight for its rights?
Is there anything I'm still confident about? Yes. I hate to seem like a single-issue voter, but I had forgotten that in the GPT-2 post we wrote "we also think governments should consider expanding or commencing initiatives to more systematically monitor the societal impact and diffusion of AI technologies, and to measure the progression in the capabilities of such systems." I remain confident this is a good idea!
This is at core not that different from my underlying perspective. Certainly it is thoughtful. Right now what we need most is to create broader visibility into what these systems are capable of, and to create the institutional capacity such that if we need to intervene in the future, we can do that.
Indeed, I have spoken how I feel proposals such as those in the Gladstone Report go too far, and would indeed carry exactly these risks. I draw a sharp contrast between that and something like SB 1047. I dive into the details to try and punch them up.
It still seems hard not to notice the vibes. This is written in a way that comes across as a warning against regulation. Coming across is what such communications are about. If this were an isolated example it would not bother me so much, but I see this consistently from Anthropic. If you are going to warn against overreach without laying out the stakes or pushing for proper reach, repeatedly, one notices.
Anthropic’s private lobbying and other private actions clearly happens and hopefully sings a very different tune, but we have no way of knowing.
Also, Anthropic failed to publicly share Claude Opus with the UK in advance, while Google did publicly share Gemini updates in advance. No commitments were broken, but this seems like a key place where it is important to set a good example. A key part of Anthropic’s thesis is that they will create a ‘race to safety’ so let’s race.
I consider Simeon’s reaction far too extreme. If you are internal, or considering becoming internal, you have more information. You should form your own opinion.
Ideally this will become its own post in the future. It is super important that we secure the model weights of future more capable systems from a wide variety of potential threats.
As the value at stake goes up, the attacks get stronger, and so too must defenses.
The core message is that there is no silver bullet, no cheap and simple solution. There are instead many strategies to improve security via defense in depth, which will require real investment over the coming years.
Companies should want to do this on their own. Not investing enough in security makes you a target, and your extremely expensive model gets stolen. Even if there are no national security concerns or existential risks, that is not good for business.
That still makes it the kind of threat companies systematically underinvest in. It looks like a big expense until it looks cheap in hindsight. Failure is bad for business, but potentially far far worse for the world.
Thus, this is a place where government needs to step in, both to require and to assist. It is an unacceptable national security situation, if nothing else, for OpenAI, Google or Anthropic (or in the future certain others) not to secure their model weights. Mostly government ‘help’ is not something an AI lab will want, but cybersecurity is a potential exception.
For most people, all you need to take away is the simple ‘we need to do expensive defense in depth to protect model weights, we are not currently doing enough, and we should take collective action as needed to ensure this happens.’
There are highly valid reasons to oppose many other safety measures. There are even arguments that we should openly release the weights of various systems, now or in the future, once the developers are ready to do that.
There are not valid reasons to let bad actors exclusively get their hands on frontier closed model weights by using cyberattacks.
Aligning a Dumber Than Human Intelligence is Still Difficult
Will Depue: Alignment people have forgotten that the main goal of ai safety is to build systems that are aligned to the intent of the user, not the intent of the creators. this is a far easier problem.
I have noticed others calling this ‘user alignment,’ and so far that has gone well. I worry people will think this means aligning the user, but ‘alignment to the user’ is clunky.
For current models, ‘user alignment’ is indeed somewhat easier, although still not all that easy. And no, you cannot actually provide a commercial product that does exactly what the user wants. So you need to do a dance of both and do so increasingly over time.
The ‘alignment people’ are looking forward to future more capable systems, where user alignment will be increasingly insufficient.
Looking at Will’s further statements, this is very clearly a case of ‘mere tool.’ Will Depue does not expect AGI, rather he expects AI to remain a tool.
I won’t read the details because triage, but the key facts to understand are that the agent frameworks will improve over time even if your system does not, and that it is extremely difficult to prove a negative. I can prove that your system can exploit zero day exploits by showing it exploiting a zero day exploit. You cannot prove that your system cannot do that simply by saying ‘I tried and it didn’t work,’ even if you gave it your best with the best agents you know about. You can of course often say that a given task is far outside of anything a model could plausibly do, but this was not one of those cases.
I do not think we have a practical problem in this particular case. Not yet. But agent system designs are improving behind the scenes, and some odd things are going to happen once GPT-5 drops.
Also, here we have DeepMind’s Nicholas Carlini once again breaks proposed AI defense techniques, here Sabre via changing one line of buggy code, then when the authors respond with a new strategy by modifying one more line of code. This thread has more context.
Aligning a Smarter Than Human Intelligence is Difficult
OpenAI gives us its early version of the SAE paper (e.g. the Golden Gate Bridge), searching for 16 million features in GPT-4, and claim their method scales better than previous work. Paper is here, Leo Gao is lead and coauthors include Sutskever and Leike. Not looking further because triage, so someone else please evaluate how we should update on this in light of Anthropic’s work.
Gabriel Wu: Students who have taken a class on AI were more likely to be worried about extinction risks from AI and had shorter "AGI timelines": around half of all Harvard students who have studied artificial intelligence believe AI will be as capable as humans within 30 years.
Over half of Harvard students say that AI is changing the way they think about their careers, and almost half of them are worried that their careers will be negatively affected by AI.
How do automation concerns differ by industry? There's isn't much variation: around 40-50% of students are worried about AI automation no matter what sector they plan on working in (tech, education, finance, politics, research, consulting), with the exception of public health.
Other People Are Not As Worried About AI Killing Everyone
Yann LeCun having strange beliefs department, in this case that ‘it is much easier to investigate what goes on in a deep learning system than in a turbojet, whether theoretically or experimentally.’ Judea Pearl explains it is the other way, whereas I would have simply said: What?
Eliezer Yudkowsky: Very online people repeating each other: Eliezer Yudkowsky is a cult leader with a legion of brainwashed followers who obey his every word.
Real life: I wore this to LessOnline and Ozy Frantz stole my hat.
The last line is actually ‘member of an implicit coalition whose members coordinate to reward those who reward those who act to aid power and to prevent the creation of clarity around any and all topics including who may or may not have any form of NDA.’
Eternal September means the freshman philosophy beatings will continue.
Say whatever else you want about e/acc. They will help you dunk.
Last week I had dinner with a group that included Emmett Shear, he made various claims of this type, and… well, he did not convince me of anything and I don’t think I convinced him of much either, but it was an interesting night. I was perhaps too sober.
Thanks for another excellent roundup. Regarding the passage I excerpt below:
1. As well-right-of-center man of letters Richard Hanania notes, literacy-orientation is now left-coded: https://www.richardhanania.com/p/liberals-read-conservatives-watch . Your work often draws on right-of-center intellectuals (Hanson, Cowen), but they are a minority. "Socially left, economically right" people are another minority you often cite.
2. Was the "AI model for ECGs" insertion between "NewsCorp's ..." and "...deeply WEIRD data sets" a formatting error? The latter two passages cover the same concern observed at different resolutions IMHO
3. I appreciate your occasional challenge to the large fraction of safety work focused on what we might call "morally wrong judgments". That seems to me a double challenge:
i. polities disagree: the current regimes governing Iran and India will demand very different tones on answers discussing Islam
The tl;dr of Leopold Aschenbrenner’s giant thesis is … The Singularity is Near - Now with a Geopolitical Twist! I really think an Aschenbrenner shoutout to Kurzweil is overdue. Anyone reading these AI posts is familiar (at least) with takeoff scenarios and that lots of different people have done lots of work and expressed lots of different opinions about whether, how, and/or how fast takeoff happens. Aschenbrenner’s style and argument, however, is so Kurzweilian! The trend lines on log-scale graphs, the techno-economics, the error bars that fit neatly into the argument (in Aschenbrenner’s case, “maybe it’s 2028 and not 2027…”). Yes, Kurzweil reported and graphed different things and the details of his reasoning and conclusions are different - the Singularity is Near was published in 2005, after all, and a lot has changed in AI! Also, RK’s reputation took several hits as he unwisely tried to defend various absurdly specific predictions lest he lose his champion Techno Futurist belt. Still: nobody brought more attention to the basic takeoff AI/AGI/ASI concepts in the 1990s through the mid-2000s than RK, and Aschenbrenner is his spiritual child - with a more aggressive timeline and a focus on international power and politics that RK largely left alone. I don’t know if Aschenbrenner read RK, but The Singularity is Near is a classic of AI takeoff synthesis and argument, and Situational Awareness seems destined to be the next in the canon.










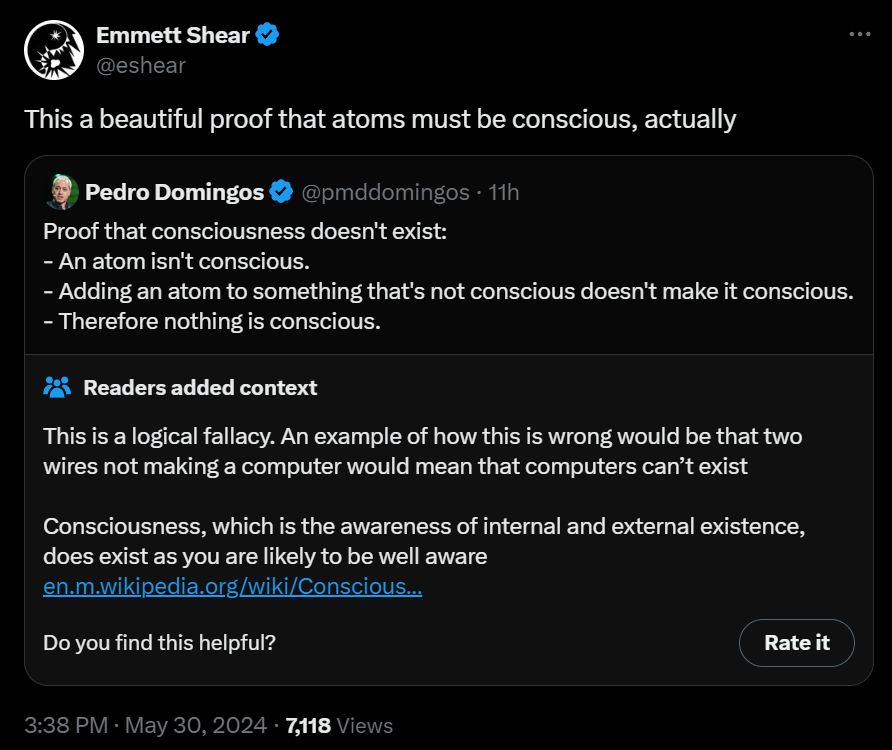
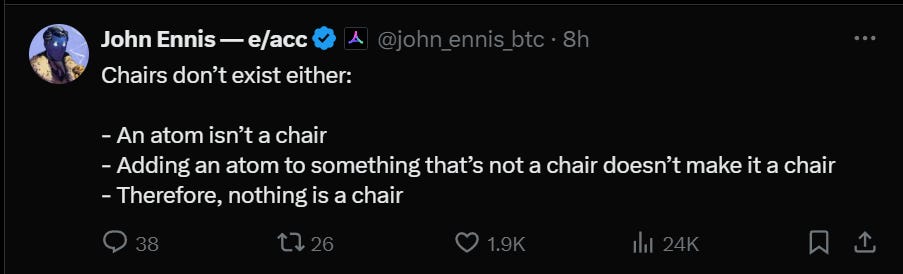
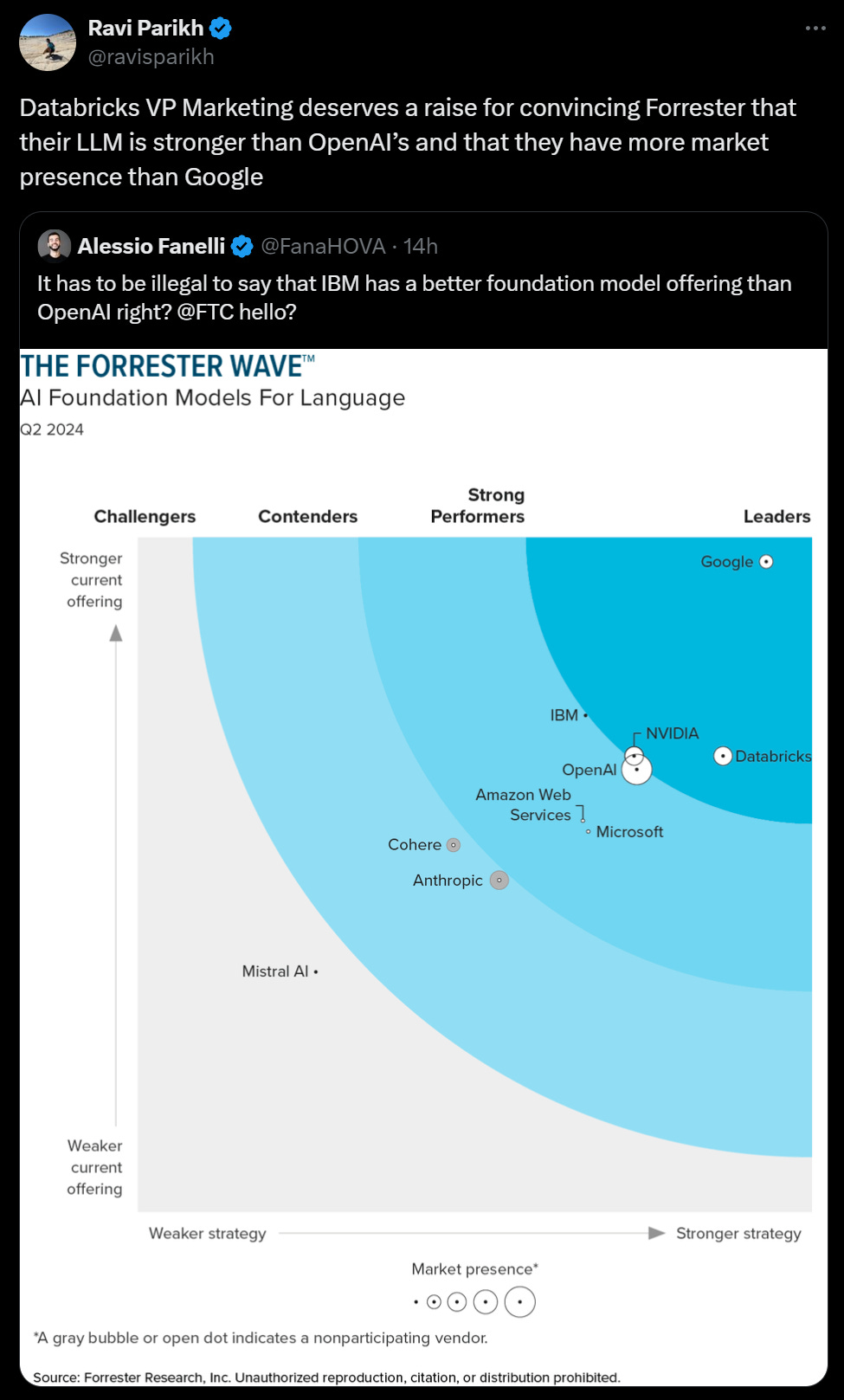

Thanks for another excellent roundup. Regarding the passage I excerpt below:
1. As well-right-of-center man of letters Richard Hanania notes, literacy-orientation is now left-coded: https://www.richardhanania.com/p/liberals-read-conservatives-watch . Your work often draws on right-of-center intellectuals (Hanson, Cowen), but they are a minority. "Socially left, economically right" people are another minority you often cite.
2. Was the "AI model for ECGs" insertion between "NewsCorp's ..." and "...deeply WEIRD data sets" a formatting error? The latter two passages cover the same concern observed at different resolutions IMHO
3. I appreciate your occasional challenge to the large fraction of safety work focused on what we might call "morally wrong judgments". That seems to me a double challenge:
i. polities disagree: the current regimes governing Iran and India will demand very different tones on answers discussing Islam
ii. all polities are morally judgmental; the 20thC Anglo-American View from Nowhere is not a viable alternative: https://pressthink.org/2010/11/the-view-from-nowhere-questions-and-answers/
Is it worth pushing the community to a tighter focus on safety-as-bounded-obedience and away from content concerns?
The tl;dr of Leopold Aschenbrenner’s giant thesis is … The Singularity is Near - Now with a Geopolitical Twist! I really think an Aschenbrenner shoutout to Kurzweil is overdue. Anyone reading these AI posts is familiar (at least) with takeoff scenarios and that lots of different people have done lots of work and expressed lots of different opinions about whether, how, and/or how fast takeoff happens. Aschenbrenner’s style and argument, however, is so Kurzweilian! The trend lines on log-scale graphs, the techno-economics, the error bars that fit neatly into the argument (in Aschenbrenner’s case, “maybe it’s 2028 and not 2027…”). Yes, Kurzweil reported and graphed different things and the details of his reasoning and conclusions are different - the Singularity is Near was published in 2005, after all, and a lot has changed in AI! Also, RK’s reputation took several hits as he unwisely tried to defend various absurdly specific predictions lest he lose his champion Techno Futurist belt. Still: nobody brought more attention to the basic takeoff AI/AGI/ASI concepts in the 1990s through the mid-2000s than RK, and Aschenbrenner is his spiritual child - with a more aggressive timeline and a focus on international power and politics that RK largely left alone. I don’t know if Aschenbrenner read RK, but The Singularity is Near is a classic of AI takeoff synthesis and argument, and Situational Awareness seems destined to be the next in the canon.