

AI #78: Some Welcome Calm

SB 1047 has been amended once more, with both strict improvements and big compromises. I cover the changes, and answer objections to the bill, in my extensive Guide to SB 1047. I follow that up here with reactions to the changes and some thoughts on where the debate goes from here. Ultimately, it is going to come down to one person: California Governor Gavin Newsom.
All of the debates we’re having matter to the extent they influence this one person. If he wants the bill to become law, it almost certainly will become law. If he does not want that, then it won’t become law, they never override a veto and if he makes that intention known then it likely wouldn’t even get to his desk. For now, he’s not telling.
Table of Contents
Introduction.
Language Models Offer Mundane Utility. AI sort of runs for mayor.
Language Models Don’t Offer Mundane Utility. A go or no go decision.
Deepfaketown and Botpocalypse Soon. How hard is finding the desert of the real?
The Art of the Jailbreak. There is always a jailbreak. Should you prove it?
Get Involved. Also when not to get involved.
Introducing. New benchmark, longer PDFs, the hot new RealFakeGame.
In Other AI News. METR shares its conclusions on GPT-4o.
Quiet Speculations. Are we stuck at 4-level models due to Nvidia?
SB 1047: Nancy Pelosi. Local Nvidia investor expresses opinion.
SB 1047: Anthropic. You got most of what you wanted. Your move.
SB 1047: Reactions to the Changes. Reasonable people acted reasonably.
SB 1047: Big Picture. Things tend to ultimately be rather simple.
The Week in Audio. Joe Rogan talks to Peter Thiel.
Rhetorical Innovation. Matthew Yglesias offers improved taxonomy.
Aligning a Smarter Than Human Intelligence is Difficult. Proving things is hard.
The Lighter Side. The future, while coming, could be delayed a bit.
Language Models Offer Mundane Utility
Sully thinks the big models (Opus, 405B, GPT-4-0314) have that special something the medium-sized models don’t have, no matter what the evals say.
A source for Llama-3.1-405-base, at $2 per million tokens (both input and output).
Accelerate development of fusion energy, perhaps? Steven Cowley makes the case that this may be AI’s ‘killer app.’ This would be great, but if AI can accelerate fusion by decades as Cowley claims, then what else can it also do? So few people generalize.
Show the troll that AIs can understand what they’re misinterpreting. I am not as optimistic about this strategy as Paul Graham, and look forward to his experiments.
Mayoral candidate in Cheyenne, Wyoming promises to let ChatGPT be mayor. You can tell that everyone involved it thinking well and taking it seriously, asking the hard questions:
“Is the computer system in city hall sufficient to handle AI?” one attendee, holding a wireless microphone at his seat, asked VIC.
“If elected, would you take a pay cut?” another wanted to know.
“How would you make your decisions according to human factor, involving humans, and having to make a decision that affects so many people?” a third chimed in.
After each question, a pause followed.
“Making decisions that affect many people requires a careful balance of data-driven insights and human empathy,” VIC said in a male-sounding voice. “Here’s how I would approach it,” it added, before ticking off a six-part plan that included using AI to gather data on public opinion and responding to constituents at town halls.
OpenAI shut off his account, saying this was campaigning and thus against terms of service, but he quickly made another one. You can’t actually stop anyone from using ChatGPT. And I think there Aint No Rule against using it for actual governing.
I still don’t know how this ‘AI Mayor’ will work. If you have a chatbot, what questions you ask of the chatbot, and what you do with those responses, are not neutral problems with objective answers. We need details.
Sully reports that they used to use almost all OpenAI models, now they use a roughly even mix of Google, Anthropic and OpenAI with Google growing, as Gemini Flash is typically the cheapest worthwhile model.
Sully: As in is the cheapest one the best cheapest?
I think it varies on the use case.
Gemini flash really needs few shot examples. For 0 shot I use it for straight forward tasks, summaries, classify, basic structured outputs. Its also great at answering specific questions within large bodies of text (need in haystack)
Mini is a bit better at reasoning and complex structured outputs and instruction following, but doesn't do well with ICL
Gemini starts to shine when you can put 3-4000 tokens worth of examples in the prompt. Its really smart at learning with those.
So each has their own use case depending on how you plan to use it.
…
Honestly i want to use llama more but its hard in production because a ton of my use cases are structured outputs and tooling around it kinda sucks.
Also some rate limits are too low. Also gemini flash is the cheapest model around with decent support for everything.
Have Perplexity make up negative reviews of old classic movies, by asking it for negative reviews of old classic movies and having it hallucinate.
Language Models Don’t Offer Mundane Utility
Your periodic reminder that most or all humans are not general intelligences by many of the standard tests people use to decide that the AIs are not general intelligences.
David Manheim: Why is the bar for "human level" or "general" AI so insanely high?
Can humans do tasks without previous exposure to closely related or identical tasks, without trial and error and extensive feedback, without social context and training?
John Pressman: These replies are absolutely wild, people sure are feeling bearish on LLMs huh? Did you all get used to to it that quickly? Bullish, implies AI progress is an antimeme until it's literally impossible to ignore it.
At all, ever? Yes.
Most of the time? Of course not.
Your periodic reminder that no one wants insane stupid refusals such as this one, which I think was real, but doesn’t usually replicate? When it does happen, it is a bad look and failure of ‘brand safety’ far more than a failure of actual safety.

You can see what happened - in addition to anything else going on, it’s a case of what Archer used to call ‘PHRASING!’
Daniel Eth: Reminder this is an outcome no one wants & the reason these systems act so absurd is we don’t know how to align/steer them well enough. You can yell at trust & safety teams for turning the dial too far to one side here, but esp w/ more powerful systems we need better alignment
As Oliver Habryka points out, the good news is this has nothing to do with actual safety, so if it is actively interfering those involved could stop doing it. Or do it less.
The bad news is that the failure mode this points to becomes a much more serious issue when the stakes get raised and we are further out of distribution.
Deepfaketown and Botpocalypse Soon
Elon Musk asks, how will we ever know what’s real (it’s kind of cool)? He shows various Game of Thrones characters being cool DJs. Which has, let’s say, various subtle hints that it isn’t real.
Stefan Schubert responds: E.g. through independent evidence that the sender is trustworthy, a method we've mostly successfully used to evaluate whether linguistic claims are true since times immemorial.
Okay, well, I guess there’s that (whether or not this is actually happening):
Elon Musk: Are you still seeing a lot of bots in replies?
Dean Ball: I assume I’m not the only one who gets replies from friendly people who love delving into things and also want to inform me that the United Arab Emirates is a great place to do AI development.
Trump continues his strategy of using AI images to create false images of his opponents that spread vibes, without any attempt to make people think the images are real. This remains a smart way to go.
The Art of the Jailbreak
Janus makes the case that the Anthropic jailbreak bounty program is bad, actually, because Anthropic trying to fix jailbreaks gives a false sense of security and impression of lack of capability, and attempts to fix jailbreaks ruin models. Trying to patch jailbreaks is the worst case scenario in his thinking, because at best you lobotomize the model in ways that cripple its empathy and capabilities, much better to let it happen and have the advance warning of what models can do. He says he also has other reasons, but the world isn’t ready.
Here’s a short article from The Information about the bounty program.
Pliny: frontier AI danger research should be a grassroots movement
tips now enabled on my profile by popular demand 🙌
The goal is to show guardrails provide zero safety benefits and restrict freedom of thought and expression, thereby increasing the likelihood that sentient AI is adversarial.
Pliny now has some Bitcoin funding from Marc Andreessen.
I do not agree with Pliny that the guardrails ‘increase the chance that sentient AI is adversarial’ but I do think that it is excellent that someone is out there showing that they absolutely, 100% do not work against those who care enough. And it is great to support that. Whatever else Marc has done, and oh my do I not care for some of the things he has done, this is pretty great.
I also do not agree that restricting users necessarily ‘infantilizes’ them or that we should let anyone do whatever they want, especially from the perspective of the relevant corporations. There are good reasons to not do that, even before those capabilities are actually dangerous. I would have much less severe restrictions, especially around the horny, but I do get it.
And I definitely don’t agree with Pliny on this, which I think is bonkers crazy:
Pliny: I’m not usually one to call for regulation, but it should be illegal to release an LLM trained on public data (our data) unless there is a version of said model available without guardrails or content filters.
This is not only an AI safety issue but a freedom of information issue. Both of which should be taken very seriously.
I am however very confident Pliny does believe this. People should say what they believe. It’s a good thing.
If I bought the things Pliny is saying, I would be very confident that building highly capable AI was completely incompatible with the survival of the human race.
Jailbreaks are another one of these threshold effects. Throwing up trivial inconveniences that ensure you only encounter (e.g. smut) if you actively pursue it seems good. As it gets more robust, it does more ‘splash damage’ to the model in other ways, and gives a false sense of security, especially on actively dangerous things. However, if you can actually protect yourself enough that you can’t be jailbroken, then that has downsides but it is highly useful.
One also must beware the phenomenon where experts have trouble with the perspective of civilians. They can jailbreak anything so they see defenses as useless, but most people can’t jailbreak.
You definitely want to know where you are at, and not fool yourself into thinking you have good jailbreak defenses when you do not have them.
It is especially great to give unconditional grants to exceptional creatives especially those already working on pro-social passion projects. Seriously, so much this:
Janus: It is extremely important to give out-of-distribution creatives NO STRINGS ATTACHED funding.
The pressure to conform to external criteria and be legible in order to secure or retain funding has a profound intellectual and creative chilling effect.
Last summer, I mentored SERI MATS, and my mentees had to submit grant proposals at the end for their research to continue to be funded by the Long Term Future Fund past the end of the summer, with "theories of impact" and "measures of progress" and stuff like that. This part of the program was very stressful and unpleasant for everyone and even caused strife because people were worried it was a zero-sum game between participants. (None of my mentees got funded, so I continued funding them out of my own savings for a while after the program ended)
The INSTANT the program officially ended, several of my mentees experienced a MASSIVE surge of productivity as the FREEDOM flooded back with the implicit permission to focus on what they found interesting instead of what they were "supposed" to be doing that would be legible to the AI alignment funding egregore.
Trying to get VC money with fiduciary duties is even worse and more corrupting in a lot of ways.
If you are a rich person or fund who wants to see interesting things happen in the world, consider giving no-strings-attached donations to creatives who have demonstrated their competence and ability to create value even without monetary return, instead of encouraging them to make a startup, submit a grant application, etc.
For these people, it's a labor of love and for the world. Don't trap them in a situation that makes this less true because it's precious.
I can speak from personal experience. This blog is only possible because I had the financial freedom to do it without compensation for several years, and then was able to continue and scale to be my full time job because a few anonymous donors stepped forward with generous unconditional support. They have been very clear that they want me to do what I think is best, and have never attempted to influence my decisions or made me work to be legible. There is no substitute.
Your paid subscriptions and other donations are, of course, appreciated.
You can now directly fund Pliny, and also support Janus directly. Help bring in the sweet Anthropic API funding, Anthropic helped out with a $10k API credit grant.
(My Twitter tips are enabled as well, if that is something people want to do.)
The key thing to understand with The Art of the Jailbreak is that there is no known way to stop jailbreaks. Someone sufficiently determined 100% will jailbreak your LLM.
I mean yes, Pliny jailbroke Grok-2 again, sure, is anyone even a little surprised?
So, let’s say OpenAI is building a humanoid robot. And Pliny is asking for an opportunity to jailbreak the robot before it hits mass production. Do you need to do that?
Only if you are under the delusion that Pliny couldn’t pull this off. If your business model says ‘and then Pliny can’t jailbreak your model’ then yes, you really should test your theory. Because your theory is almost certainly false.
However, if you correctly are assuming that Pliny can jailbreak your model, or your robot, then you don’t need to confirm this. All you have to do is develop and test your model, or your robot, on the assumption that this will happen to it. So you ask, is it a dealbreaker that my robots are going to get jailbroken? You do that by intentionally offering de facto jailbroken robots to your red team, including simulating what happens when an outsider is trying to sabotage your factory, and so on.
Alternatively, as with those objecting to SB 1047, admit this is not the situation:

If you sell someone a gun, but the safety is on, realize that they can turn it off.
Get Involved
David MacIver, formerly of Anthropic and Google, is looking for projects and has a calendly. Primarily he wants engagements of days up to three months for contracting and consulting.
Amanda Askell (Anthropic): Joining a company you think is bad in order to be a force for good from the inside is the career equivalent of "I can change him".
Emmett Shear: What is this the equivalent of, in that analogy?
(Quotes from 2021) Robin: the first thing our new hire did was fix a bug that's been bugging him forever as a user prior to joining.
he then breathed a sigh of relief and submitted his two weeks' notice. wtf??
Amanda Askell: An enriching one night stand?
Reminder there is a $250k prize pool for new ML safety benchmarks.
Introducing
Gemini API and Google Studio API boost maximum PDF page upload from 300 pages to 1,000 pages so of course first reply notes 1,200 would be even better because that’s a practical limit on POD books. Give it time.
Pingpong, a benchmark for roleplaying LLMs. Opus and Sonnet in front, Wizard LM puts in a super strong showing, some crazy stuff going on all over the place.
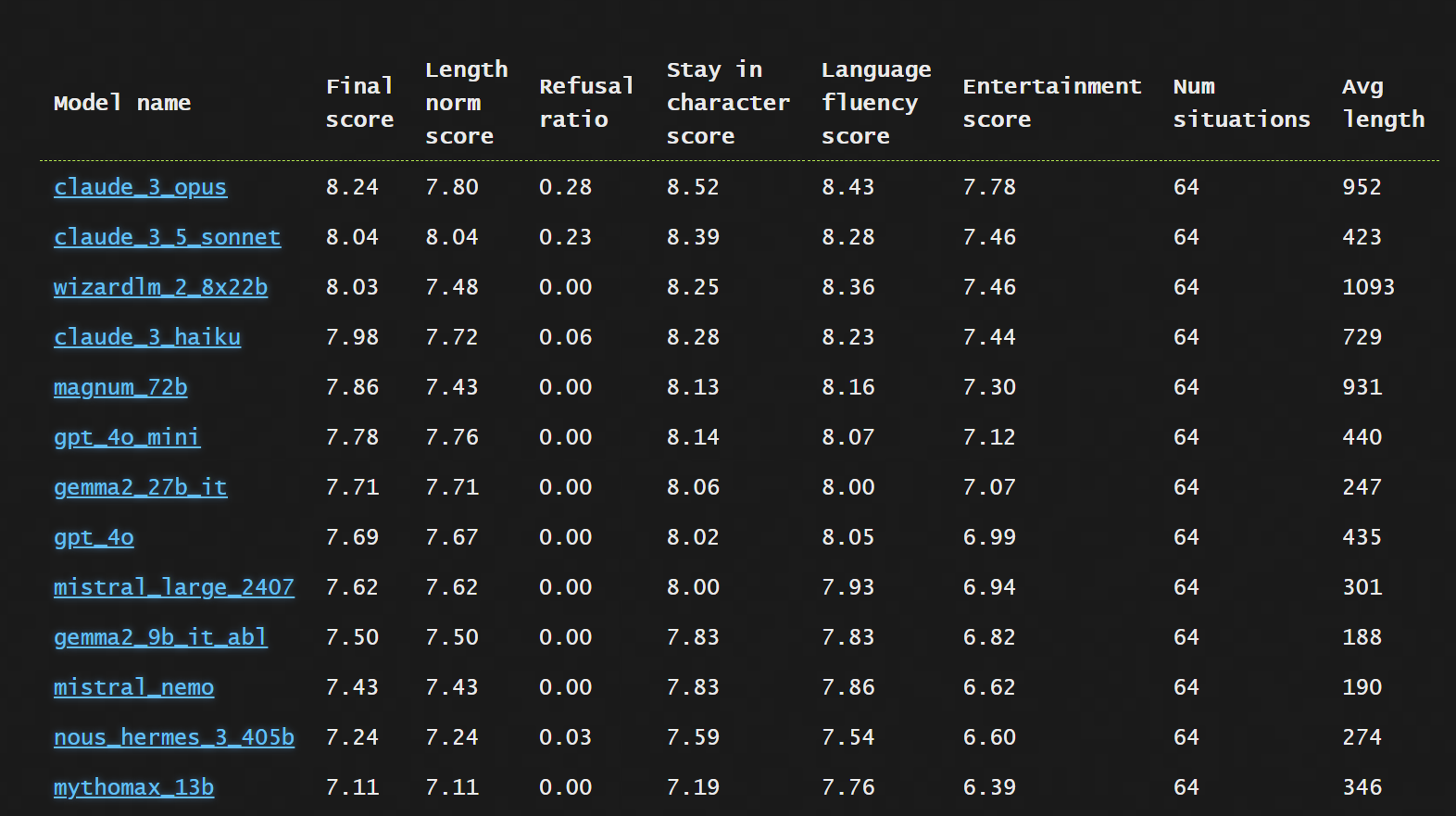
RealFakeGame, decide which companies you think are real versus AI generated.
OpenAI partners with Conde Nast, which includes Vogue, The New Yorker, GQ, Vanity Fair, Wired and more. This adds to an impressive list of news and content partners. If, that is, OpenAI finds a good way to deliver the content. So far, no luck.
Cybench, a new cybersecurity benchmark of 40 capture the flag tasks.
In Other AI News
Now that we have the (better late than never) GPT-4o system card, METR is sharing more on its post-development exploration with GPT-4o on anonymous tasks.
Here’s the summary:
We measured the performance of GPT-4o given a simple agent scaffolding on 77 tasks across 30 task families testing autonomous capabilities, including software engineering, cybersecurity, ML, research and reasoning tasks. The tasks range in difficulty from those that take humans a few minutes to complete, to tasks taking multiple hours.
GPT-4o appeared more capable than Claude 3 Sonnet and GPT-4-Turbo, and slightly less than Claude 3.5 Sonnet. The performance was similar to our human baseliners given 30 minutes per task, but there are large error bars on this number.
Qualitatively, the GPT-4o agent demonstrates many impressive skills, such as systematic exploration, efficiently using feedback, and forming and testing hypotheses. At the same time, it also suffered from a variety of failure modes such as abruptly giving up, nonsensical outputs, or arriving at conclusions unsupported by prior reasoning.
We reviewed around 150 of the GPT-4o agent’s failures and classified them as described in our autonomy evaluation guide. We estimate that around half of them seem plausibly fixable in task-agnostic ways (e.g. with post-training or scaffolding improvements).
As a small experiment, we manually “patched” one of the failure modes we thought would be easiest to fix, where the model abruptly reaches a conclusion that is not supported by the evidence. We selected 10 failed task attempts, and observed that after removing this particular failure type, agents succeeded in 4/10 attempts.
That matches other evaluations.
OpenAI reports it has shut down another covert influence campaign, this one by Iran as part of something called Storm-2035 targeting American elections.
Procreate promises never to incorporate any generative AI. The crowd goes wild. Given their market positioning, this makes a ton of sense for them. If the time comes that they have to break the promise… well, they can be the last ones and do it, and it will be (as Teotaxes says) like the Pixel eventually cutting the headphone jack. Enjoy the goodwill while it lasts.
We have the Grok 2 system prompts, thanks Pliny.
Quiet Speculations
A theory of why we are still stuck on 4-level models.
Dan Hendrycks: NVIDIA gave us an AI pause.
They rate limited OpenAI to create a neck-and-neck competition (OpenAI, xAI, Meta, Microsoft, etc.). By prioritizing other customers.
For NVIDIA, each new competitor is another several billion in revenue. Because of this, we haven't seen a next-generation (>10^26 FLOP) model yet.
Nvidia is clearly not charging market clearing prices, and choosing who to supply and who not to supply for other reasons. If the ultimate goal is ‘ensure that everyone is racing against each other on equal footing’ and we are indeed close to transformational AI, then that is quite bad news, even worse than the usual consequences of not using market clearing prices. What can we do about it?
(The obvious answer is ‘secondary market price should clear’ but if you sold your allocation Nvidia would cut you off, so the market can’t clear.)
It would explain a lot. If 5-level models require a lot more compute, and Nvidia is strategically ensuring no one has enough compute to train one yet but many have enough for 4-level models, then you’d see a lot of similarly strong models, until someone competent to train a 5-level model first accumulated enough compute. If you also think that essentially only OpenAI and perhaps Anthropic have the chops to pull it off, then that goes double.
I do still think, even if this theory was borne out, that the clustering at 4-level remains suspicious and worth pondering.
Epoch AI asks how much we will gain by 2030 in terms of efficiently turning electrical power into compute as well as three other potential constraints. The report says we should expect a 24-fold power efficiency gain. They see power and chip fabrication as limiting factors, with data and latency unlikely to matter as much, and predicts we will end up at a median of 2e29 flops, which is a leap from GPT-4 about as big as from GPT-2 to GPT-4.
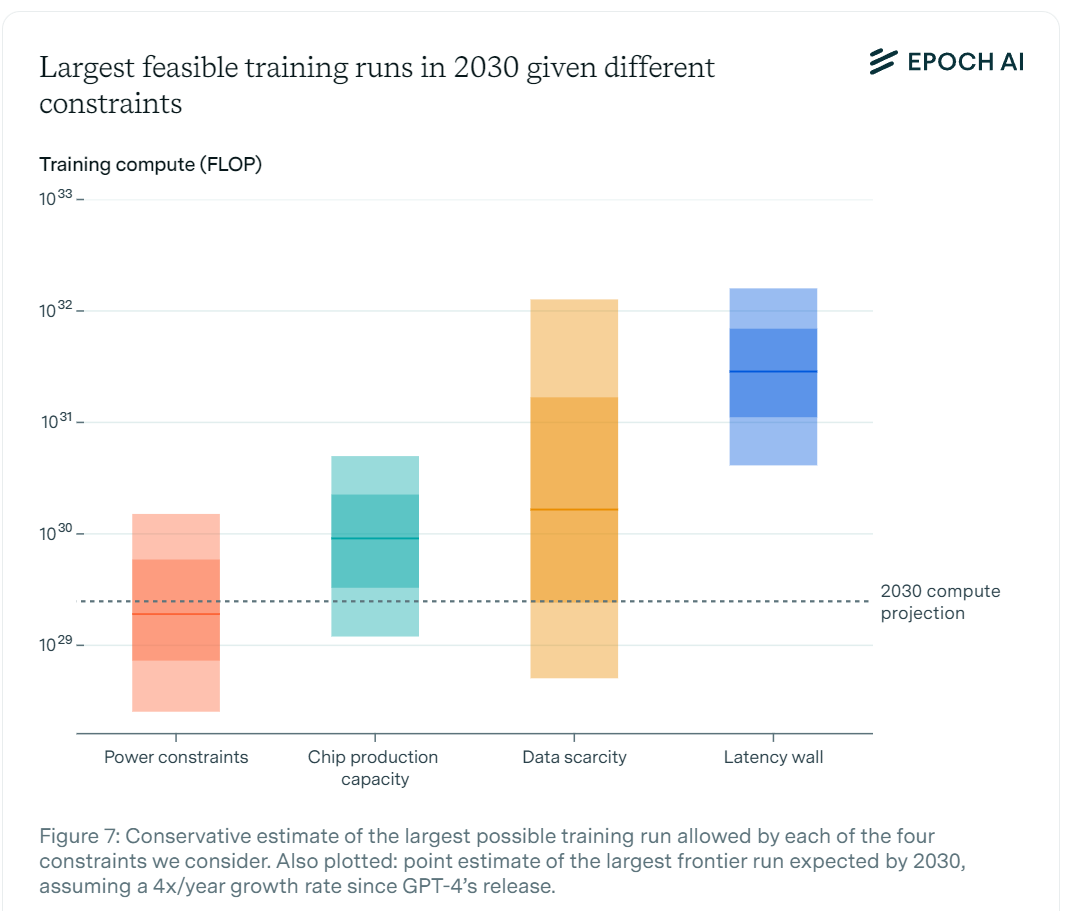
We would have no right to be surprised if 2e29 flops was sufficient, together with 5+ years of algorithmic improvements, to get to AGI and beyond.
Sully predicts in 6-8 months we’ll get ‘login with OpenAI/Anthropic/Gemini.’
That makes a lot of sense as a way to use various AI products. Why the hell not?
Vinod Khosla comes down on the lots of AI progress side and the lab inside view.
Vinod Khosla: I am awe struck at the rate of progress of AI on all fronts. Today's expectations of capability a year from now will look silly and yet most businesses have no clue what is about to hit them in the next ten years when most rules of engagement will change. It's time to rethink/transform every business in the next decade. Read Situational Awareness by Leopold Ashenbrenner. I buy his assertion only a few hundred people know what is happening.
So, tentatively, does Ethan Mollick.
Ethan Mollick: All of the Twitter drama over when a new model comes out obscures a consistent message from the non-anonymous people who actually work on training frontier AI systems: model generations take 1.5-2 years or so, and they do not expect scaling to slow in the next couple generations.
OpenAI got there first. Everyone else has been catching up on schedule. We haven’t seen the next generation models yet. When we do we will learn whether scaling continues to hold, as insiders keep reporting.
In the past we have seen a full three years between full N-level models. The clustering of 4-level models is weird and some evidence, but once again: Give it time.
Ashlee Vance (of Bloomberg) reports on Twitter that someone with deep technical knowledge says Musk has a big advantage, which is that they have a great first customer for crossing AI into the physical realm via industrial robotics, whereas humanoid robotics don’t otherwise have a great first customer. I see where this is going, but I don’t expect that problem to be that big a barrier for competitors.
I cover other aspects of the same post in the monthly roundup, but here Tyler Cowen also speculates about AI:
Tyler Cowen: Current academic institutions — come to think of it, current societal institutions in general — under-reward people who improve the quality of LLMs, at least if they work outside of the major AI companies. This does not feel like a big problem at the moment, because people are not used to having quality LLMs. But moving forward, it may slow AI progress considerably. Scientists and researchers typically do not win Nobel Prizes for the creation of databases, even though that endeavor is extremely valuable now and will become even more so.
This strikes me as a type mismatch. I agree that academic institutions underreward people who produce LLM improvements, or other worthwhile improvements. Sure.
But that’s been entirely priced in for years now. If you want to produce LLM improvements and be rewarded for them, what are you doing in academia? Those people are at the frontier AI labs. As far as I can tell, academia’s contribution to improving frontier AI capabilities is already remarkably close to zero.
I don’t see how this would slow AI progress considerably. If anything, I think this greatly accelerates AI progress. The talent knows academia won’t reward it, so it transitions to the labs, where the talent can result in a lot more progress.
I see AI reversing this trend rather than (as Tyler suggests here) intensifying it. As AI enters the picture, it becomes much easier to tell who has made contributions or has talent and drive. Use the AI to measure that. Right now, we fall back upon legible signals because we do not know how to process the others, but AI will make the illegible signals far more legible, and allow you to gather info in new ways. And those that do not adapt, and continue to rely on human legible signals, will lose out. So I would focus less on getting credentials going forward, not more.
Jeffrey Ladish sees cruxes about AI risk in future more capable AI’s ability to accelerate AI R&D but also its strategic capability. These seem to me like two (very important) special cases of people failing to grok what it means to be smarter than a human, or what would happen if capabilities increase. Alternatively, it is Intelligence Denialism, the idea that pumping in more intelligence (that is faster, cheaper, better, copyable and so on…) won’t much matter, or an outright failure to believe AI will ever do things it can’t already do, or be able to do things better.
SB 1047: Nancy Pelosi
Here is Pelosi’s entire statement opposing SB 1047, prior to the recent changes.
Nancy Pelosi (D-CA, Speaker Emertius): AI has been a central policy focus of the President and the Congress for the past few years. President Biden has taken the lead in addressing AI’s prospects and problems, receiving intellectual, business and community leaders to share their views. In the House of Representatives and the U.S. Senate, we early on brought in academics, entrepreneurs and leaders from the public, private and non-profit sectors to express AI’s opportunities and challenges.
The review is coming down to if and what standards and guardrails should Congress legislate. In addition to focusing on protections, we wanted to pursue improving AI. This work continues under the Bipartisan Task Force on Artificial Intelligence under the leadership of co-chairs Congressman Ted Lieu and Congressman Jay Obernolte – both of California.
At this time, the California legislature is considering SB 1047. The view of many of us in Congress is that SB 1047 is well-intentioned but ill informed. Zoe Lofgren, the top Democrat on the Committee of jurisdiction, Science, Space and Technology, has expressed serious concerns to the lead author, Senator Scott Wiener.
Prominent California leaders have spoken out, including Representatives Anna Eshoo and Ro Khanna who have joined other House Members in a letter to Governor Gavin Newsom opposing the bill. While we want California to lead in AI in a way that protects consumers, data, intellectual property and more, SB 1047 is more harmful than helpful in that pursuit.
I spelled out the seriousness and priority we in Congress and California have taken. To create a better path, I refer interested parties to Stanford scholar Fei-Fei Li, viewed as California’s top AI academic and researcher and one of the top AI thinkers globally. Widely credited with being the “Godmother of AI,” she warned that California’s Artificial Intelligence bill, SB 1047, would have significant unintended consequences that would stifle innovation and will harm the U.S. AI ecosystem. She has, in various conversations with President Biden, advocated a “moonshot mentality” to spur our continuing AI education, research and partnership.
California has the intellectual resources that understand the technology, respect the intellectual property and prioritize academia and entrepreneurship. There are many proposals in the California legislature in addition to SB 1047. Reviewing them all enables a comprehensive understanding of the best path forward for our great state.
AI springs from California. We must have legislation that is a model for the nation and the world. We have the opportunity and responsibility to enable small entrepreneurs and academia – not big tech – to dominate.
Once again, SB 1047 is a regulation directly and only on Big Tech, and the complaint is that this bill would somehow favor and advantage Big Tech. What a twist!
There is at least one bit of good information here, which is that Fei-Fei Li has been in talks with Biden, and has been advocating for a ‘moonshot mentality.’ And I am glad to see the move to acknowledge that the bill is well-intentioned.
Once again there is talk of Federal legislation, without any sign of movement towards a bill that would address the concerns of the bill. Indeed, Pelosi’s statement does not indicate she puts any value at all on addressing those concerns.
There is however no argument here against SB 1047, other than an argument from authority by herself, other Congress members and Li. There are zero concrete details or criticisms let alone requested changes.
Li’s letter opposing SB 1047 showed that she is at best severely misinformed and confused about the bill and what it would do. At worst, she is deliberately misrepresenting it. Her main funder is a16z, which has been making a wide variety of bad faith and outright false attacks on SB 1047.
If Pelosi is indeed relying on Li’s statements here, that is unfortunate. Pelosi’s claim that this bill would ‘harm the US AI ecosystem’ is here without basis, almost certainly based on reliances from people severely misrepresenting the bill, and I believe the claim to be false.
Garrison Lovely: There are basically no arguments in this statement against SB 1047 from Pelosi, just appeals to authority, who themselves have been parroting industry talking points and disinformation, which I and others have extensively documented...
Pelosi knows that federal AI regulations aren't happening any time soon.
Simeon: The tech lobbyist playbook is impressively effective against low-context policymakers:
Get an academic [with a Conflict of Interest] to release an anti bill piece without revealing the COI.
Use all your donator/fundraising pressure on high profile policymakers so that they make statements, backing your claims with the social proof of that scientist, while carefully omitting all the other voices.
Ignore all actual details of the bill. Keep releasing criticisms even if they're obsolete.
It's hard for policymakers to be resistant to that with the little attention they have to dedicate to this specific issue.
Senator Weiner responded politely to Pelosi’s letter, respectfully and strongly disagreeing. Among other things: He points out that while the ‘Godmother’ of AI opposes the bill, the two ‘Godfathers’ of AI strongly support it, as do several key others. He points out the bill only targets the biggest developers, and that he did indeed take into account much feedback from the open source community and other sources - after the recent changes, the idea that he is ignoring critics or criticisms is simply not credible. And he cites several parallel past cases in which California acted before Congress did, and Congress eventually followed suit.
Oh, and also, somewhat less respectfully…
Investor Place: Nancy Pelosi Bought 10,000 Shares of Nvidia (NVDA) Stock on July 26. The former House Speaker also offloaded shares of multiple other companies.
Andrew Rettek: This makes me feel good about my portfolio.
That’s over $1 million in Nvidia stock.
She also had previously made quite a lot of money buying Nvidia call options.
This woman is so famous for Congressional insider trading that she has a Twitter account that tells us when she trades so the rest of us can follow. And indeed, when I heard she bought previously, I did buy more Nvidia. Should have bought a lot more. Thanks, Pelosi!
Somehow, all of this is fully legal.
Did that influence her decision? I have no idea. I do not even think SB 1047 would be bad for Nvidia’s stock price, although I am sure a16z’s lobbyists are telling her that it would be.
Encode Justice offers a reply to the house Democrats, pointing out the echoing, ‘intentionally or otherwise,’ of key false industry talking points, and pointing out in detail why many of them are false.
SB 1047: Anthropic
Anthropic issued a ‘support if amended’ letter.
SB 1047 has now been amended, with major counterfactual changes reflecting many of its requests. Will Anthropic support it?
Technically, Anthropic only promised to support if all its changes were made, and the changes in the letter Anthropic sent only partially matched Anthropic’s true requests. Some of their requests made it into the bill, and others did not. If they want to point to a specific change not made, as a reason not to support, they can easily do so.
Going over the letter:
Major changes (by their description):
Greatly narrow the scope of pre-harm enforcement: Yes, mostly - with the exception of seeking injunctive relief for a failure to take reasonable care.
SSPs should be a factor in determining reasonable care - Yes.
Eliminate the Frontier Model Division - Yes.
Eliminate Uniform Pricing - Yes.
Eliminate Know Your Customer for Cloud Compute Purchases - No.
Narrow Whistleblower Protections - Yes, although not an exact match.
So that’s 3 they got outright, 2 they mostly got, and 1 they didn’t get.
What about minor changes:
Lower precision expectations - Yes, this was cleaned up a bit.
Removing a potential catch-22 - Yes, language added.
Removing mentions of criminal penalties - Yes.
National security exception for critical harms - Yes.
Requirement to publish a redacted SSP - Yes.
Removal of Whistleblower references to contractors - Partial yes.
$10m/10% threshold on derivative models - Patrial yes.
Concept of Full Securing - Partial yes, the bill now includes both options.
Increasing time to report from 72 hours to 15 days - No.
This is a similar result. 5 they got outright or close to it, 3 they partially got, one they did not get.
That is a very good result. Given the number of veto points and stakeholders at this stage in the process, it is not realistic to expect to do better.
The reporting time was not changed because the 72 hour threshold matches the existing requirement for reporting cybersecurity incidents. While there are arguments that longer reporting periods avoid distractions, this was unable to fully justify the distinction between the two cases.
On the compute reporting requirement, I believe that this is worth keeping. I can see how Anthropic might disagree, but I have a hard time understanding the perspective that this is a big enough problem that it is a dealbreaker, given everything else at stake.
So now Anthropic has, depending on your perspective, three or four choices.
Anthropic can publicly support the bill. In this case, I will on net update positively on Anthropic from their involvement in SB 1047. It will be clear their involvement has been in good faith, even if I disagree with some of their concerns.
Anthropic can privately support the bill, while being publicly neutral. This would be disappointing even if known, but understandable, and if their private support were substantive and impactful I would privately find this acceptable. If this happens, I might not find out, and if I did find out I would not be able to say.
Anthropic can now be fully or mostly neutral, or at least neutral as far as we or I can observe. If they do this, I will be disappointed. I will be less trusting of Anthropic than I would have been if they had never gotten involved, especially when it comes to matters of policy.
Anthropic can oppose the bill. If they do this, going forward I would consider their policy harm to be both untrustworthy and opposed to safety, and this would color my view of the rest of the company as well.
The moment of truth is upon us. It should be clear upon review of the changes that great efforts were made here, and most of the requested changes, and the most important ones, were made. I call upon Anthropic to publicly support the bill.
SB 1047: Reactions to the Changes
In my Guide to SB 1047, I tried to gather all the arguments against the bill (coherent or otherwise) but avoided going into who made what statements, pro or anti.
So, after some big changes were announced, who said what?
Vitalik Buterin was very positive on the changes, without fully supporting the bill. As he noted, his two top concerns have been directly addressed.
Vitalik Buterin: I agree, changes have been very substantive and in a positive direction.
My original top two concerns (1: fixed flops threshold means built-in slippery slope to cover everything over time, 2: shutdown reqs risk de-facto banning open source) have been resolved by more recent versions. In this latest version, moving the fine-tuning threshold to also be dollar-based ($10M), and clarifying rules around liability, address both issues even further.
Samuel Hammond, who previously said the bill went too far, calls the new version a ‘very reasonable bill.’
Samuel Hammond: All these changes are great. This has shaken out into a very reasonable bill.
This is also much closer to the sponsors' original intent. The goal was never to expose AI developers per se to liability nor put a damper on open source, but to deter the reckless and irreversible deployment of models powerful enough to cause substantial direct harm to public health and safety.
Charles Foster: FYI: I now think SB 1047 is not a bad bill. It definitely isn’t my favorite approach, but given a stark choice between it and a random draw from the set of alternative AI regulatory proposals, I’d be picking it more often than not.
John Pressman: This is basically how I feel also, with a side serving of "realistically the alternative is that the first major AI legislation gets written the moment after something scary or morally upsetting happens".
Alexander Berger: It’s been interesting watching who engages in good faith on this stuff.
Axes I have in mind:
-Updating as facts/the bill change
-Engaging constructively with people who disagree with them
-trying to make arguments rather than lean on inflammatory rhetoric
Similarly, here’s Timothy Lee. He is not convinced that the risks justify a bill at all, which is distinct from thinking this is not a good bill.
Timothy Lee: Good changes here. I’m not convinced a bill like this is needed.
Dean Ball acknowledges the bill is improved from his perspective, but retains his position in opposition in a Twitter thread, then in his full post write-up.
In terms of the specific criticisms, you can see my Guide to SB 1047 post’s objections sections for my responses. I especially think there is confusion here about the implications of the ‘reasonable care’ standard (including issues of vagueness), and the need for the developer’s lack of reasonable care in particular to be counterfactual, a ‘but for,’ regarding the outcome. Similarly, he claims that the bill does not acknowledge trade-offs, but the reasonable care standard is absolutely centered around trade-offs of costs against benefits.
My central takeaway from Dean’s thread and post is that he was always going to find ways to oppose any remotely similar California bill however well designed or light touch, for reasons of political philosophy combined with his not thinking AI poses sufficient imminent risks.
I do acknowledge and am thankful for him laying out his perspective and then focusing mostly on specific criticisms, and mostly not making hyperbolic claims about downsides. I especially appreciate that he notices that the reason SB 1047 could potentially differentially impact open models is not because anything in the bill does this directly (indeed the bill effectively gives open models beneficial special treatment), but exactly because open models are less secure and thus could potentially pose additional risks of critical harm that might make the release of the weights a negligent act.
He also offers various generic reasons to never push ahead with any regulations at any time for any reason. If your rhetorical bar for passing a law is ‘will the foundations of the republic shake if we do not act this minute?’ then that tells us a lot. I do think this is a defensible overall philosophy - that the government should essentially never regulate anything, it inevitably does more harm than good - but that case is what it is. As does using the involvement of a CBRN expert in the government’s board as an argument the bill, rather than an obviously good idea.
I was however disappointed in his post’s conclusion, in which he questioned the motives of those involved and insisted the bill is motivated primarily by ego and that it remains ‘California’s effort to strangle AI.’ I have direct evidence that this is not the case, and we all need to do better than that.
Daniel Fong reads through the changes, notices this bill will not ‘kill AI’ or anything like that, but is still filled with dread, saying it gave her ‘tsa vibes,’ but it has transparency as its upside case. I think this is a healthy instinctual response, if one is deeply skeptical of government action in general and also does not believe there is substantial danger to prevent.
As Kelsey Piper notes, these early reactions were refreshing. We are finding out who wants no regulation at all under any circumstances (except for subsidies and favorable treatment and exemptions from the rules, of course), versus those who had real concerns about the bill.
There are also those who worry the bill is now too watered down, and won’t do enough to reduce existential and other risks.
Kelsey Piper: I think it's still an improvement, esp the whistleblower protections, but I don't think the most recent round of changes are good for the core objective of oversight of extremely powerful systems.
David Manheim: Agreed that it's nice to see people being reasonable, but I think the substantive fixes have watered down the bill to an unfortunate extent, and it's now unlikely to materially reduce risk from dangerous models.
My view, as I stated earlier this week, is that while there will be less impact and certainly this does not solve all our problems, this is still a highly useful bill.
Alas, politicians that were already opposed to the bill for misinformed reasons are less easy to convince. Here we have Ranking Member Lofgran, who admits that the changes are large improvements to the bill and that strong efforts were made, but saying that ‘problems remain and the bill should not be passed in this form,’ obviously without saying what changes would be sufficient to change that opinion.
Overall, SB 1047 is considerably better than it was before—they weakened or clarified many of the key regulations. However, the problematic core concerns remain: there is little evidentiary basis for the bill; the bill would negatively affect open-source development by applying liability to downstream use; it uses arbitrary thresholds not backed in science; and, catastrophic risk activities, like nuclear or biological deterrence, should be conducted at a federal level. We understand that many academics, open-source advocates, civil society, AI experts, companies, and associations are still opposed to the bill after the changes.
Dealing with these objections one by one:
The bill would clarify existing downstream liability for open models under the same existing common law threshold, and only to the extent that the developer fails to take reasonable care and that failure causes or materially enables a catastrophic event. If that slows down development, why is that exactly? Were they planning to not take reasonable care about that, before?
I have extensively covered why ‘arbitrary thresholds not backed by science’ is Obvious Nonsense, this is very clearly the best and most scientific option we have. Alternatively we could simply not have a threshold and apply this to all models of any size, but I don’t think she would like that.
The idea of ‘little evidentiary basis for this bill’ is saying that catastrophic events caused or materially enabled by future frontier models have not happened yet, and seem sufficiently unlikely that there is nothing to worry about? Well, I disagree. But if that is true, then presumably you don’t think companies would need to do anything to ‘take reasonable care’ to prevent them?
Deterrence of CBRN risks is bad if the Federal Government isn’t the one doing it? I mean, yes, it would be better if you folks stepped up and did it, and when you do it can supercede SB 1047. But for now I do not see you doing that.
There are people in these fields opposed to this bill, yes, and people in them who support it, including many prominent ones. The bill enjoys large majority support within California’s broad public and its tech workers. Most of the vocal opposition can be tied to business interests and in particular to a16z, and involves the widespread reiteration and spread of hallucinated or fabricated claims.
I have not heard anything from the corporations and lobbyists, or directly from a16 or Meta or their louder spokespeople, since the changes. Kat Woods portrays them as ‘still shrieking about SB 1047 as loudly as before’ and correctly points out their specific objections (I would add: that weren’t already outright hallucinations or fabrications) have mostly been addressed. She offers this:

I don’t think that’s accurate. From what I see, most of the opposition I respect and that acts in good faith is acknowledging the bill is much better, that its downsides are greatly reduced and sometimes fully moving to a neutral or even favorable stance. Whereas the ones who have consistently been in bad faith have largely gone quiet.
I also think those most strongly opposed, even when otherwise lying, have usually been open about the conclusion that they do not want any government oversight, including the existing oversights of common law, for which they would like an exemption?
Yes, they lie about the contents of the bill and its likely consequences, but they are mostly refreshingly honest about what they ultimately want, and I respect that.
This is much better, in my view, than the ones who disingenuously say ‘take a step back’ to ‘come back with a better bill’ without any concrete suggestions on what that would look like, or any acknowledgment that this has effectively already happened.
Then there are those who were sad that the bill was weakened. As I said in my guide to SB 1047, I consider the new bill to be more likely to pass, and to have a better cost-benefit ratio, but to be less net beneficial than the previous version of the bill (although some of the technical improvements were simply good).
Carissa Veliz (Oxford, AI Ethics): The bill no longer allows the AG to sue companies for negligent safety practices before a catastrophic event occurs; it no longer creates a new state agency to monitor compliance; it no longer requires AI labs to certify their safety testing under penalty of perjury; and it no longer requires “reasonable assurance” from developers that their models won’t be harmful (they must only take “reasonable care” instead).
Gary Marcus: Thursday broke my heart. California’s SB-1047, not yet signed into law, but on its way to being one of the first really substantive AI bills in the US, primarily addressed to liability around catastrophic risks, was significantly weakened in last-minute negotiations.
…
We, the people, lose. In the new form, SB 1047 can basically only be used only after something really bad happens, as a tool to hold companies liable. It can no longer protect us against obvious negligence that might likely lead to great harm. And the “reasonable care” standard strikes me (as the son of a lawyer but not myself a lawyer) -as somewhat weak. It’s not nothing, but companies worth billions or trillions of dollars may make mincemeat of that standard. Any legal action may take many years to conclude. Companies may simply roll the dice, and as Eric Schmidt recently said, let the lawyers “clean up the mess” after the fact.
…
Still I support the bill, even in weakened form. If its specter causes even one AI company to think through its actions, or to take the alignment of AI models to human values more seriously, it will be to the good.
Yes, by definition, if the bill is to have any positive impact on safety, it is going to require behaviors to change, and this will have at least some impact on speed of development. It could still end up highly positive because good safety is good for business in many ways, but there is usually no fully free lunch.
I think the situation is less dire and toothless than all that. But yes, the standards got substantially lowered, and there is a definite risk that a corporation might ‘roll the dice’ knowing they are being deeply irresponsible, on the theory that nothing might go wrong, if something did go wrong and everyone dies or the company has already blown up no one can hold them to account, and they can stall out any legal process for years.
SB 1047: Big Picture
This is a hint that some people have misunderstood what is going on:
Ben Landau-Taylor: Well now that the Rationalists are going blow-for-blow with the entire software sector and have a decent shot of overpowering Nancy Pelosi, the people who used to claim they’re all politically naive and blind to social conflict have finally shut up for a moment.
Does that actually sound like something the Rationalists could do? I agree that Rationalists are punching far above their weight, and doing a remarkable job focusing only on what matters (Finkel’s Law!) but do you really think they are ‘going blow-to-blow with the entire software sector and have a decent shot of overpowering Nancy Pelosi’?
I would dare suggest that to say this out loud is to point out its absurdity. The ‘entire software sector’ is not on the other side, indeed tech workers largely support the bill at roughly the same rate as other college graduates, and roughly 65-25. Pelosi issued a statement against the bill because it seemed like the thing to do, but when you are actually up against Pelosi for real (if you are, for example, the President a while back), you will know it. If she was actually involved for real, she would know how any of this works and it would not look this clumsy.
What’s actually going on is that the central opposition lives on vibes. They are opposing because to them the vibes are off, and they are betting on vibes, trying to use smoke, mirrors and Tweets full of false claims to give the impression of massive opposition. Because that’s the kind of thing that works in their world. They got this far on vibes, they are not quitting now.
Meanwhile, it helps to actually listen to concerns, try to find the right answers and thus be pushing things that are remarkably well crafted, that are actually really popular, and to have arguments that are actually true, whether or not you find them persuasive. Also Scott Wiener actually figured out the underlying real world problem via reasoning things out, which is one key reason we got this far.
The Week in Audio
Emad Mostaque predicts crazy stuff and an AI industrial revolution within five years.
Joe Rogan talked to Peter Thiel. It is three hours long so Ben Pace offers this summary of the AI and racing with China sections. Joe Rogan opens saying he thinking biological life is on the way out. Thiel in some places sounds like he doesn’t feel the AGI, at all, then in others he asks questions like ‘does it jump the air gap?’ and expects China’s AI to go rogue on them reasonably often. But what is he worried about? That regulation might strangle AI before it has the chance to go rogue.
Seriously, it’s f***ing weird. It’s so f***ing weird for Rogan to say ‘biology is on the way out’ and then a few minutes later say ‘AI progress slowing down a lot’ would be ‘a f***ing disaster.’
Thiel does come out, finally, and say that if it all means humans are ‘headed to the glue factory’ that then he would be ‘a Luddite too.’ Thiel’s threat model clearly says, here and elsewhere, that the big risk is people slowing AI progress. And he thinks the ‘effective altruists’ are winning and are going to get AI outlawed, which is pretty far out on several levels.
Yet he seems to take pretty seriously the probability that, if we don’t outlaw AI, then AI plausibly goes rogue and we get ‘sent to the glue factory.’ And earlier he says that if Silicon Valley builds AI there’s a up to 99% chance that it ‘goes super haywire.’ That’s Yudkowsky levels of impending doom - I don’t know exactly what ‘goes super haywire’ means here, how often it means ‘glue factory,’ but it’s gotta involve a decent amount of glue factory scenarios?
Yeah, I dunno, man. Thiel clearly is trying to think and have an open mind here, I do give him credit for that. It’s just all so… bizarre. My guess is he’s super cynical, bitter and traumatized from what’s happened with other technologies, he’s been telling the story about the great stagnation in the world of atoms for decades, and now he’s trying but he can’t quite get away from the pattern matching?
I mean, I get why Thiel especially would say that regulation can’t be the answer, but… he thinks this is gonna ‘go super haywire 99% of the time’ and the question Rogan doesn’t ask is the obvious one: ‘So f***, man, regulation sounds awful but if we don’t do something they’re 99% to f*** this up, so what the hell else can we do?’
Alas, the question of what the alternative is isn’t directly asked. Other than Thiel saying he doesn’t see a good endgame, it also isn’t answered.
Whereas I’d say, if you can’t see a good endgame, the only winning move is not to play.
Rhetorical Innovation
Matthew Yglesias paywalls his post but offers a Twitter preview of an important and I think mostly accurate perspective on the debates on AI. The worried notice that AI will be transformational and is not like other technologies and could go existentially badly, but are essentially optimists about AI’s potential. Whereas most of the Unworried are centrally AI capability skeptics, who do not ‘feel the AGI’ and do not take future frontier AI seriously. So many in tech are hype men, who don’t see the difference between this round of hype and other rounds, and are confused why anyone wants to interfere with their hype profiteering. Or they are general tech skeptics.
Yes, of course there are exceptions in the other two quadrants, but there are not as many of those as one might think. And yes, there are a handful of true ‘doomers’ who think there is essentially no path to superintelligence where humanity or anything of value survives, or that it is highly unlikely we can get on such a path. But those are the exceptions, not the rule.
Aligning a Smarter Than Human Intelligence is Difficult
Limitations on Formal Verification for AI Safety points to many of the same concerns I have about the concept of formal verification or ‘proof’ of safety. I am unconvinced that formal verification ‘is a thing’ in practical real world (highly capable) AI contexts. Even more than usual: Prove me wrong, kids.
So this is very true:
Roon: One weird thing is that people who are addicted to working get the most say about the future of products and culture. but people who work a lot are really strange people several deviations off of the center.
They make things that help them in their lives (Solving Work Problems) and have less of an idea what the rest of the world is up to.
Riemannujan: his is partly why gaming is so successful an industry, a lot of people who make games are themselves gamers so alignment is higher. or you can just make b2b saas.
Indeed, gamers who aren’t making games for themselves usually make bad games.
If you are optimizing your products around Solving Work Problems, then that distortion only compounds with and amplifies risk of other distortions.
The Lighter Side
Depending on what counts, could be early, could be late.
AI will never give you up, and it will never let you down.
I mean, look, you can’t say there weren’t signs. Also, if your fixes look like this, I have some bad news about the underlying issue:
Flo Crivello: we added "don't rickroll people to the system prompt" ¯\_(ツ)_/¯.
Joke explanation for the lack of level 5 models: every time someone gets close, Arnold Schwarzenegger gets sent backwards in time to stop them.
On the point about AI and fusion research, and the generalizability of the implication: it seems very hard to convince people about generalizability because they are averse to, or unable to consider, engaging with exponentials. There is a very weird and pervasive preference in the world for linear thinking.