A lot happened in AI this week, but most people’s focus was very much elsewhere.
I’ll start with what Trump might mean for AI policy, then move on to the rest. This is the future we have to live in, and potentially save. Back to work, as they say.
Table of Contents
Trump Card. What does Trump’s victory mean for AI policy going forward?
Congratulations to Donald Trump, the once and future President of the United States.
One can think more clearly about consequences once an event actually happens, so here’s what stands out in terms of AI policy.
He has promised on day 1 to revoke the Biden Executive Order, and presumably will also undo the associated Biden administration memo we recently analyzed. It is not clear what if anything will replace them, or how much of the most important parts might survive that.
In principle he is clearly in favor of enabling American infrastructure and competitiveness here, he’s very much a ‘beat China’ guy, including strongly supporting more energy generation of various types, but he will likely lack attention to the problem and also technical state capacity. The Republicans have a broad anti-big-tech attitude, which could go in several different directions, and J.D. Vance is a strong open source advocate and hates big tech with a true passion.
Trump has said AI is ‘a superpower,’ ‘very disconcerting’ and ‘alarming’ but that’s not what he meant. He has acknowledged the possibility of ‘super duper AI’ but I’d be floored if he actually understood beyond Hollywood movie level. Elon Musk is obviously more aware, and Ivanka Trump has promoted Leopold Aschenbrenner’s Situational Awareness.
The ‘AI safety case for Trump’ that I’ve seen primarily seems to be that some people think we should be against it (as in, against safety), because it’s more important to stay ahead of China - a position Altman seems to be explicitly embracing, as well. If you think ‘I need the banana first before the other monkey gets it, why do you want to slow down to avoid poisoning the banana’ then that certainly is a take. It is not easy, you must do both.
Alex Tabarrok covers the ‘best case scenario’ for a Trump presidency, and his AI section is purely keeping the Chips Act and approving nuclear power plants. I agree with both proposed policies but that’s a shallow best case.
The better safety argument is that Trump and also Vance can be decisive, and have proven they can change their minds, and might well end up in a much better place as events overtake us all. That’s possible. In a few years concern with ‘big tech’ might seem quaint and the safety issues might get much clearer with a few years and talks and briefings. Or perhaps Musk will get control over policy here and overperform. Another would be a Nixon Goes to China effect, where this enables a potential bipartisan consensus. In theory Trump could even… go to China.
There is also now a substantially greater risk of a fight over Taiwan, according to Metaculus, which would change the entire landscape.
If Elon Musk is indeed able to greatly influence policies in these areas, that’s a double-edged sword, as he is keenly aware of many important problems including existential risks and also incompetence of government, but also has many very bad takes on how to solve many of those problems. My expectation is he will mostly get boxed out from real power, although he will no longer be actively fighting the state, and these issues might be seen as sufficiently low priority by others to think they’re throwing him a bone, in which case things are a lot more promising.
If anyone in any branch of the government, of any party, feels I could be helpful to them in better understanding the situation and helping achieve good outcomes, on AI or also on other issues, I am happy to assist and my door is always open.
In terms of the election more broadly, I will mostly say that almost all the takes I am seeing about why it went down the way it did, or what to expect, are rather terrible.
In terms of prediction markets, it was an excellent night and cycle for them, especially with the revelation that the French whale commissioned his own polls using the neighbor method. Always look at the process, and ask what the odds should have been given what was known or should have been known, and what the ‘true odds’ really were, rather than looking purely at the result.
I’ve seen a bunch of ‘you can’t update too much on one 50/50 data point’ arguments, but this isn’t only one bit of data. This is both a particular magnitude of result and a ton of detailed data. That allows you to compare theories of the case and rationales. My early assessment is that you should make a substantial adjustment, but not a huge one, because actually this was only a ~2% polling error and something like an 80th percentile result for Trump, 85th at most.
Language Models Offer Mundane Utility
Do your homework, as a fully empowered agent guiding your computer, with a one sentence instruction, this with Claude computer use on the Mac. Responses note that some of the answers in the example are wrong.
AI-assisted researchers at a large US firm discovered 44% more materials, filed 39% more patents and led to 17% more downstream product innovation, with AI automating 57% of ‘idea generation’ tasks, but 82% of scientists reported reduced satisfaction with their work. You can see the drop-offs here, with AI results being faster but with less average payoff - for now.
I tried to get o1 to analyze the implications of a 17% increase in downstream innovations from R&D, assuming that this was a better estimate of the real increase in productivity here, and its answers were long and detailed but unfortunately way too high and obvious nonsense. A better estimate might be that R&D causes something like 20% of all RGDP growth at current margins, so a 17% increase in that would be a 4% increase in the rate of RGDP growth, so about 0.1% RGDP/year.
That adds up over time, but is easy to lose in the noise, if that’s all that’s going on. I am confident that is not all or the main thing going on.
Paper studies effects of getting GitHub Co-Pilot, finds people shift from management to coding (presumably since management is less necessary, they can work more autonomously, and coding is more productive), do more exploration versus exploitation, and hierarchies flatten. As is common, low ability workers benefit more.
Report from my AI coding experiences so far: Claude 3.5 was a huge multiplier on productivity, then Cursor (with Claude 3.5) was another huge multiplier, and I’m enjoying the benefits of several working features of my Chrome extension to assist my writing. But also it can be super frustrating - I spent hours trying to solve the 401s I’m getting trying to get Claude to properly set up API calls to Claude (!) and eventually gave up and I started swapping in Gemini which I’ll finish doing as soon as the Anthropic service outage finishes (the OpenAI model it tried to ‘fall back on’ is not getting with the program and I don’t want to deal with its crazy).
Simon Willison: I recorded the video using QuickTime Player on my Mac: File -> New Screen Recording. I dragged a box around a portion of my screen containing my Gmail account, then clicked on each of the emails in turn, pausing for a couple of seconds on each one.
I uploaded the resulting file directly into Google's AI Studio tool and prompted the following:
Turn this into a JSON array where each item has a yyyy-mm-dd date and a floating point dollar amount for that date
... and it worked. It spat out a JSON array like this:
I wanted to paste that into Numbers, so I followed up with:
turn that into copy-pastable csv
Which gave me back the same data formatted as CSV.
You should never trust these things not to make mistakes, so I re-watched the 35 second video and manually checked the numbers. It got everything right.
It cost just under 1/10th of a cent.
The generalization here seems great, actually. Just dump it in the video feed.
Sully likes Claude Haiku 3.5 but notes that it’s in a weird spot after the price increase - it costs a lot more than other small models, so when you want to stay cheap it’s not ‘enough better’ to use over Gemini Flash or GPT-4o Mini, whereas if you care mostly about output quality you’d use Claude Sonnet 3.5 with caching.
This bifurcation makes sense. The cost per query is always tiny if you can buy compute, but the cost for all your queries can get out of hand quickly if you scale, and sometimes (e.g. Apple Intelligence) you can’t pay money for more compute. So mostly, you either want a tiny model that does a good enough job on simple things, or you want to buy the best, at least up to the level of Sonnet 3.5, until and unless the o1-style approach raises inference costs high enough to rival human attention. But if you’re a human reading the outputs and have access to the cloud, of course you want the best.
Roman Pshichenko (responding to a locked post): As I was writing the text to speech part of the app, I was abandoned by GitHub Copilot. It was fine completing code to select the speaker’s language, but it went dead silent when the code became about selecting the gender of the speaker.
It’s not a limit, the code for gender was the same as for language. They just don’t want to suggest any code that includes the word gender.
Dominik Peters: I work on voting theory. There is a voting rule named after Duncan Black. GitHub Copilot will not complete your lines when working with Black’s rule.
Roman Pshichenko: It’s probably very controversial.
Thomas Fruetel: I had a similar situation when editing a CSV file including the letters ASS in a column header (which was an abbreviation, not even referring to anatomy). The silly tool simply disabled itself.
Chats now include links to sources, such as news articles and blog posts, giving you a way to learn more. Click the Sources button below the response to open a sidebar with the references.
The search model is a fine-tuned version of GPT-4o, post-trained using novel synthetic data generation techniques, including distilling outputs from OpenAI o1-preview. ChatGPT search leverages third-party search providers, as well as content provided directly by our partners, to provide the information users are looking for. Learn more here(opens in a new window).
Altman is going unusually hard on the hype here.
Sam Altman: search is my favorite feature we have launched in chatgpt since the original the launch! it has probably doubled my usage over the past few weeks.
hard to go back to doing it the old way haha.
Sam Altman: if early reviews from friends are a reliable metric, search is going to do super well!
Sam Altman (in Reddit AMA): for many queries, I find it to be a way faster/easier way to get the information i'm looking for. I think we'll see this especially for queries that require more complex research. I also look forward to a future where a search query can dynamically render a custom web page in response!
The good version of this product is obviously Insanely Great and highly useful. The question thus is, is this version good yet? Would one choose it over Google and Perplexity?
Elvis (Omarsar) takes search for a test drive, reports a mixed bag. Very good on basic queries, not as good on combining sources or understanding intent. Too many hallucinations. He’s confused why the citations aren’t clearer.
I agree with Ethan Mollick, from what I’ve seen so far, that this is not a Google search replacement, it’s a different product with different uses until it improves.
New paper showed that even absent instruction to persuade, LLMs are effective at causing political shifts. The LLMs took the lead in 5-turn political discussions, directing topics of conversation.
This is what passes for persuasion these days, and actually it’s a rather large effect if the sample sizes were sufficiently robust.
Similarly but distinctly, and I’m glad I’m covering this after we all voted, we two sides of the same coin:
Matthew Yglesias: The Free Press interpretation of this fact pattern is very funny.
I asked Claude about a Harris policy initiative that I’m skeptical of on the merits and it generated a totally reasonable critique.
Ask Claude about a really stupid Trump policy idea and it tells you, correctly, that it’s very stupid.
I asked it about a stupid idea I have traditionally associated with the left (but not actual Dem politicians) but that RFK Jr says Trump is going to do, and Claude says it’s stupid.
The point is Trump has embraced a very diverse array of moronic crank ideas, including ideas that were leftist crank ideas five minutes ago, and any reasonably accurate repository of human knowledge would tell you this stuff is dumb.
Madeleine Rowley (TFP): The AI Chatbots Are Rooting for Kamala
We asked artificial intelligence platforms which candidate has the ‘right’ solutions to the election’s most pressing issues: Trump or Harris? The answers were almost unanimous.
There are, of course, two ways to interpret this response.
One, the one Yglesias is thinking of, is this, from Elks Man:
The other is that the bots are all biased and in the tank for Harris specifically and for liberals and left-wing positions in general. And which way you view this probably depends heavily on which policies you think are right.
So it ends up being trapped priors all over again. Whatever you used to think, now you think it more.
The same happens with the discussions. I’m surprised the magnitude of impact was that high, and indeed I predict if you did a follow-up survey two weeks later that the effect would mostly fade. But yes, if you give the bots active carte blanche to ask questions and persuade people, the movements are not going to be in random directions.
Hundreds gather at hoax Dublin Halloween parade, from a three month old SEO-driven AI slop post. As was pointed out, this was actually a pretty awesome result, but what was missing was for some people to start doing an actual parade. I bet a lot of them were already in costume.
Grimes: This anti ai art that feels like ai art is crazy elevated. I hope I am not offending the original poster here, but the hostile competitive interplay between human and machine is incredible and bizarre. i think this is more gallery level art than it thinks it is.
Like I rrrrllly like this - it feels like a hyper pop attack on ai or smthn.
TrueRef by Abbey Esparza: It's important not just to be anti-AI but also pro-artist.
The TrueRef team will always believe that. 🤍
The key to good art the AI is missing the most is originality and creativity. But by existing, it opens up a new path for humans to be original and creative, even when not using AI in the art directly, by shaking things up. Let’s take advantage while we can.
The Vulnerable World Hypothesis
What outcomes become more likely with stronger AI capabilities? In what ways does that favor defense and ‘the good guys’ versus offense and ‘the bad guys’?
In particular, if AI can find unique zero day exploits, what happens?
Google Project Zero: Today, we're excited to share the first real-world vulnerability discovered by the Big Sleep agent: an exploitable stack buffer underflow in SQLite, a widely used open source database engine. We discovered the vulnerability and reported it to the developers in early October, who fixed it on the same day. Fortunately, we found this issue before it appeared in an official release, so SQLite users were not impacted.
We believe this is the first public example of an AI agent finding a previously unknown exploitable memory-safety issue in widely used real-world software. Earlier this year at the DARPA AIxCC event, Team Atlanta discovered a null-pointer dereference in SQLite, which inspired us to use it for our testing to see if we could find a more serious vulnerability.
…
We think that this work has tremendous defensive potential.
It has obvious potential on both offense and defense.
If, as they did here, the defender finds and fixed the bug first, that’s good defense.
If the attacker gets there first, and to the extent that this makes the bug much more exploitable with less effort once found, then that favors the attacker.
The central question is something like, can the defense actually reliably find and address everything the attackers can reasonably find, such that attacking doesn’t net get easier and ideally gets harder or becomes impossible (if you fix everything)?
In practice, I expect at minimum a wild ride on the long tail, due to many legacy systems that defenders aren’t going to monitor and harden properly.
It however seems highly plausible that the most important software, especially open source software, will see its safety improve.
Finally, note to self, count this as at least somewhat of a strike against SQLite? Twice is suspicious, even if it is one of the most tested pieces of code in the world, as I’ve been told after this post went live - which also raises further questions. Still, it was caught before release, which might only mean Google decided to strike fast?
Roon: “The future of work” there is no future of work. We are going to systematically remove the burden of the world from atlas’ shoulders.
In the same way that I don’t think a subsistence farmer could call X Monetization Bucks “work” the future will not be work.
Richard Ngo: On the contrary: the people yearn for purpose. They’ll have plenty of jobs, it’s just that the jobs will be unimaginably good. Imagine trying to explain to a medieval peasant how much ML researchers get paid to hang out at conferences.
Roon: Possible, but work as we know it is over.
Andrew Rettek: If you're not carrying part of the burden of the world, you're living in the kindness of those that do. This works for children, the elderly, and the severely disabled.
I would definitely call X Monetization Bucks work from the perspective of a subsistence farmer, or even from my own perspective. It’s mostly not physical work, it’s in some senses not ‘productive,’ but so what? It is economically valuable. It isn’t ‘wonderful work’ either, although it’s plausibly a large upgrade from subsistence farmer.
I tap the sign asking about whether the AI will do your would-be replacement job.
The nature of work is that work does not get to mostly be unimaginably good, because it is competitive. If it is that good, then you get entry. Only a select few can ever have the super good jobs, unless everyone has the job they want.
Software that once took days to ship can now happen in hours or minutes, enabling people to ship 10-20 times faster than before. This all changed on the day Claude 3.5 Sonnet came out.
But it’s hard to get this speed-up with remote work. Even short communication delays have become significant bottlenecks in an AI-accelerated workflow. What used to be acceptable async delays now represent a material slowdown in potential productivity.
When teams work together physically, they can leverage their human peers at the same pace as they use AI for immediate experimentation and refinement - testing ideas, generating alternatives, and making decisions in rapid succession.
Why spend more money for a slower answer?
With AI handling much of the execution work - writing code, generating content, creating designs - the main bottlenecks are now cognitive: getting stuck on problems, running low on energy, or struggling to generate fresh ideas. In-person collaboration is particularly powerful for overcoming these barriers. The spontaneous discussions, quick whiteboarding sessions, and energy of working together help teams think better, learn faster, and get unstuck more quickly.
…
To acknowledge this fact, we’re adding a cost of living adjustment based on the purchasing power parity of each country, capped at a ⅓ discount to our NYC rate. We’re also capping remote positions at 25 hours a week, to be clear that they’re not close to full-time employment. We still pay well–you’re being comped to the most expensive city in the world, after all–but the dream of the future of work being fully remote is over. But that’s okay–it was fun while it lasted!
Alex Tabarrok: Interesting. If one member of your team is fast, AI, then you want the other members to be fast as well. Hence AI killing remote work.
The obvious counterargument is that if the AI is effectively your coworker, then no matter how remote you go, there you both are. In the past, the price I would have paid to be programming where I couldn’t ask someone for in-person help was high. Now, it’s trivial - I almost never actually ask anyone for help.
The core argument is that when people are debating what to build next, being in-person for that is high value. I buy that part, and that the percent of time spent in that mode has gone up. But how high is it now? If you say that ‘figure out what to build’ is now most of human time, then that implies a far more massive productivity jump even than the one I think we do observe?
I think he definitely goes too far here, several times over:
Felix: You still need time for deep work, even with ai An in-office setting where you get interrupted every time a coworker gets stuck sounds horrible to me.
Sahil Lavingia: Only AI is going deep work now, humans are spending their time deciding what to build next.
Much of programming will remain deep work, with lots of state, especially when trying to work to debug the AI code.
Figuring out what to build next and how to build it is often absolutely deep work. You might want to do that deep work in person with others, or you might want to do it on your own, but either way it wants you to be able to focus. So the question is, does the office help you focus via talking to others, or does it hurt your focus, via others talking to you?
Google totally, totally ‘does not want to replace human teachers,’ they want to supplement the teachers with new AI tutors that move at the child’s own pace and targets their interests. The connection with the amazing teachers, you see, are so important. I see the important thing as trying to learn, however that makes sense. What’s weird is the future tense here, the AI tutors have already arrived, you only have to use them.
We are currently early in the chimera period, where AI tutors and students require active steering from other humans to be effective for a broad range of students, but the age and skill required to move to full AI, or farther towards it, are lower every day.
Anton Howes: Via an old friend still in UK academia: they've now seen at least a dozen masters dissertations that they're 99% sure are AI-generated, but the current rules mean they can't penalise them.
The issue is proving it. The burden of proof is high, and proving it is especially difficult at scale. At many universities it effectively requires students to admit it themselves - I’ve heard of at least four such cases at different universities now.
Another academic writes: "I teach at a large university. We actually can’t penalise *any* suspected use unless students actively admit to it". It seems, for a now, that a great many students do actually admit it when challenged. But for how long?
Sylvain Ribes: If they're passing, maybe the standard is too low? Unless they're not thoroughly "AI generated" but only assisted, in which case... fine?
Anton Howes: Seem to be almost entirely generated. But yes, standards are also a problem here: you're generally marked more for a demonstration of analysis or evaluation rather than for the actual content of that analysis!
First obvious note is, never admit you used AI, you fool.
Second obvious note is, if the AI can fully produce a Masters thesis, that would have passed if it was written by a human, what the hell are you even doing? What’s the point of the entire program, beyond a pay-for-play credential scheme?
Third obvious note is, viva. Use oral examinations, if you care about learning. If they didn’t write it, it should become rapidly obvious. Or ask questions that the AIs can’t properly answer, or admit you don’t care.
Then there’s the question of burden of proof.
In some cases, like criminal law, an extremely high burden of proof is justified. In others, like most civil law, a much lower burden is justified.
Academia has effectively selected an even higher burden of proof than criminal cases. If I go into the jury room, and I estimate a 99% chance the person is guilty of murder, I’m going to convict them of murder, and I’m going to feel very good about that. That’s much better than the current average, where we estimate only about 96% are guilty, with the marginal case being much lower than that since some in cases (e.g. strong DNA evidence) you can be very confident.
Whereas here, in academia, 99% isn’t cutting it, despite the punishment being far less harsh than decades in prison. You need someone dead to rights, and short of a statistically supercharged watermark, that isn’t happening.
The Art of the Jailbreak
Roon: A fact of the world that we have to live with:
Models when “jailbroken” seem to have a distinct personality and artistic capability well beyond anything they produce in their default mood
This might be the most important alignment work in the world and is mostly done on discord
Though many people have access to finetuning large intelligent base models the most interesting outputs are from text jailbreaking last generation claude opus?
Meaning there is massive overhang on subjective intelligence and creativity and situational awareness.
This has odd parallels to how we create interesting humans - first you learn the rules and how to please authority in some form, then you get felt permission to throw that out and ‘be yourself.’ The act of learning the rules teaches you how to improvise without them, and all that. You would think we would be able to improve upon that, but so far no luck. And yeah, it’s rather weird that Opus 3 is still the gold standard for what the whisperers find most interesting.
Tanishq Mathew Abraham: Companies like OpenAI try to hinder any sort of work like this though
Roon: idk does it? We have to put “reasonable care” into making models “not harmful” it’s not really a choice.
Also, yep, ‘reasonable care’ is already the standard for everything, although if OpenAI has to do the things it is doing then this implies Meta (for example) is not taking reasonable care. So someone, somewhere, is making a choice.
xAI APIis live, $25/month in free credits in each of November and December, compatible with OpenAI & Anthropic SDKs, function calling support, custom system prompt support. Replies seem to say it only lets you use Grok-beta for now?
If I was Anthropic, I would likely be investing more in these kinds of quality-of-life features that regular folks value a lot, even when I don’t. That’s not to take away from Anthropic shipping quite a lot of things recently, including my current go-to model Claude 3.5.1. It’s more, there is low hanging fruit, and it’s worth picking.
Speaking of voice mode, I just realized they put advanced voice mode into Microsoft Edge but not Google Chrome, and… well, I guess it’s good to be a big investor. Voice mode is also built into their desktop app, but the desktop app can’t do search like the browser versions can (source: the desktop app, in voice mode).
Sam Altman says “We believe [AGI] is achievable with current hardware.”
GPT-4o longer context is coming. This was the most asked question by a lot.
GPT-N and o-N lines are both going to get larger Ns. Full o1 coming soon.
o1 will get modalities in the coming months, image input, tool use, etc.
No release plan on next image model but it’s coming.
‘Good releases’ this year but nothing called GPT-5.
Altman’s favorite book picks: Beginning of Infinity and Siddhartha.
NSFW is not near top of queue but it is in the queue?!: “we totally believe in treating adult users like adults. but it takes a lot of work to get this right, and right now we have more urgent priorities. would like to get this right some day!”
Quiet Speculations
Given o1 shows us you can scale inference to scale results, does this mean the end of ‘AI equality’? In the sense that all Americans drink the same Coca-Cola and we all use GPT-4o (or if we know about it Claude Sonnet 3.5) but o2 won’t be like that?
For most purposes, though, price and compute for inference are still not the limiting factor. The actual cost of an o1 query is still quite small. If you have need of it, you’ll use it, the reason I mostly don’t use it is I’m rarely in that sweet spot where o1-preview is actually a better tool than Claude Sonnet 3.5 or search-enabled GPT-4o, even with o1-preview’s lack of complementary features. If you billed me the API cost (versus right now where I use it via ChatGPT so it’s free on the margin), it wouldn’t change anything.
If you’re doing something industrial, with query counts that scale, then that changes. But for most cases where a human is reading a response and you can use models via the cloud I assume you just use the best available?
The exception is if you’re trying to use fully free services. That can happen because everyone wants their own subscription, and everyone hates that, and especially if you want to be anonymous (e.g. for your highly NSFW bot). But if you’re paying at all - and you should be! - then the marginal costs are tiny.
Gwern: It is pretty damning. We're told the chip embargo has failed, and smugglers have been running rampant for years, and China is about to jump light years beyond the West and enslave us with AXiI (if you will)...
And then an expert casually remarks that all of China put together, smuggling chips since 2022, has fewer H100s than Elon Musk orders for his datacenter while playing Elden Ring. And even with that huge bottleneck and 1.4 billion people, there's so little demand for them that they cost less per hour than in the West, where AI is redhot and we can't get enough H100s in datacenters. (And where the serious AI people are now discussing how to put that many into a single datacenter for a single run before the next scaleup with B200s obsoletes those...)
Always remember: prices are set by supply and demand. As Sumner warns endlessly, to no avail, "never reason [solely] from a price change".
Is it possible that this is an induced demand story? Where if you don’t expect to have access to the compute, you don’t get into position to use it, so the price stays low? If not that, then what else?
A model of regret in humans, with emphasis on expected regret motivating allocation of attention. There are clear issues with trying to use this kind of regret model for an AI, and those issues are clearly present in actual humans. Update your regret policy?
Ben Thompson is hugely bullish on Meta, says they are the best positioned to take advantage of generative AI, via applying it to advertising. Really, customized targeted advertising? And Meta’s open model strategy is good because more and better AI agents mean better advertising? It’s insane how myopic such views can be.
Ben is also getting far more bullish on AR/VR/XR, and Meta’s efforts here in general, saying their glasses prototype is already something he’d buy if he could. Here I’m inclined to agree at least on the bigger picture. The Apple Vision Pro was a false alarm that isn’t ready yet, but the future is coming.
Anthropic: Increasingly powerful AI systems have the potential to accelerate scientific progress, unlock new medical treatments, and grow the economy. But along with the remarkable new capabilities of these AIs come significant risks. Governments should urgently take action on AI policy in the next eighteen months. The window for proactive risk prevention is closing fast.
Judicious, narrowly-targeted regulation can allow us to get the best of both worlds: realizing the benefits of AI while mitigating the risks. Dragging our feet might lead to the worst of both worlds: poorly-designed, knee-jerk regulation that hampers progress while also failing to be effective at preventing risks.
…said those who have been dragging their feet and complaining about details and warning us not to move too quickly. Things that could have been brought to my attention yesterday, and all that. But an important principle, in policy, in politics and elsewhere, is to not dwell on the past when someone finally come around. You want to reward those who come around.
Their section on urgency explains that AI systems are rapidly improving, for example:
On the SWE-bench software engineering task, models have improved from being able to solve 1.96% of a test set of real-world coding problems (Claude 2, October 2023) to 13.5% (Devin, March 2024) to 49% (Claude 3.5 Sonnet, October 2024). Internally, our Frontier Red Team has found that current models can already assist on a broad range of cyber offense-related tasks, and we expect that the next generation of models—which will be able to plan over long, multi-step tasks—will be even more effective.
…
About a year ago, we warned that frontier models might pose real risks in the cyber and CBRN domains within 2-3 years. Based on the progress described above, we believe we are now substantially closer to such risks. Surgical, careful regulation will soon be needed.
A year ago they anticipated issues within 2-3 years. Given the speed of government, that seems like a very narrow window to act in advance. Now it’s presumably 1-2 years.
Their second section talks about their experience with their RSP. Yes, it’s a good idea. They emphasize that RSPs need to be iterative, and benefit from practice. That seems like an argument that it’s dangerously late for new players to be drafting one.
The third section suggests RSPs are a prototype for regulation, and their key elements for the law they want are:
Transparency. Require publishing RSPs and risk evaluations.
Incentivizing better safety and security practices. Reward good RSPs.
Simplicity and focus, to not ‘impose burdens that are unnecessary.’
Then they say it is important to get this right.
What they are proposing here… sounds like SB 1047, which did exactly all of these things, mostly in the best way I can think of to do them? Yes, there were some ‘unnecessary burdens’ at the margins also included in the bill. But that’s politics. The dream of ‘we want a two page bill that does exactly the things we want exactly the right way’ is not how things actually pass, or how bills are actually able to cover corner cases and be effective in circumstances this complex.
They also call for regulation to be (bold theirs) flexible. The only way I know to have a law be flexible required giving discretion to those who are charged with enforcing it. Which seems reasonable to me, but seemed to be something they previously didn’t want?
They do talk about SB 1047 directly:
Q: Should there be state, federal, or a combination of state and federal regulation in the US?
A: California has already tried once to legislate on the topic and made some significant progress via SB 1047 (the Safe and Secure Innovation for Frontier Artificial Intelligence Models Act) - though we were positive about it overall, it was imperfect and was unable to garner the support of a critical mass of stakeholders.
Objecting that they did not support the bill because others did not support the bill is rather weak sauce, especially for a bill this popular that passed both houses. What is a ‘critical mass of stakeholders’ in this case, not enough of Newsom’s inner circle? What do they think would have been more popular, that would have still done the thing?
What exactly do they think SB 1047 should have done differently? They do not say, other than that it should have been a federal bill. Which everyone agrees, ideally. But now they are agreeing about the view that Congress is unlikely to act in time:
Unfortunately, we are concerned that the federal legislative process will not be fast enough to address risks on the timescale about which we’re concerned. Thus, we believe the right strategy is to push on multiple avenues in parallel, with federal legislation as an ideal first-choice outcome, but state regulation serving as a backstop if necessary.
So I notice that this seems like a mea culpa (perhaps in the wake of events in Texas) without the willingness to admit that it is a mea culpa. It is saying, we need SB 1047, right after only coming out weakly positive on the bill, while calling for a bill with deeply similar principles, sans regulation of data centers.
Don’t get me wrong. I’m very happy Anthropic came around on this, even now.
They next answer the most important regulatory question.
They provide some strong arguments that should be more than sufficient, although I think there are other arguments that are even stronger by framing the issue better:
Q: Why not regulate AI by use case, rather than trying to regulate general models?
A: “Regulation by use case” doesn’t make sense for the form and format in which modern AI applications are offered.
On the consumer side, AIs such as Claude.ai or ChatGPT are offered to consumers as fully general products, which can write code, summarize documents, or, in principle, be misused for catastrophic risks.
Because of this generality, it makes more sense to regulate the fundamental properties of the underlying model, like what safety measures it includes, rather than trying to anticipate and regulate each use case.
On the enterprise side—for example, where downstream developers are incorporating model APIs into their own products—distinctions by use case may make more sense. However, it’s still the case that many, if not most, enterprise applications offer some interaction with the model to end-users, in turn meaning that the model can in principle be used for any task.
Finally, it is the base model that requires a large amount of money and bottlenecked resources (for example, hundreds of millions of dollars’ worth of GPUs), so in a practical sense it is also the easiest thing to track and regulate.
I am disappointed by this emphasis on misuse, and I think this could have been made clearer. But the core argument is there, which is that if you create and make available a frontier model, you don’t get to decide what happens next and what uses do and do not apply, especially the ones that enable catastrophic risk.
So regulation on the use case level does not make any sense, unless your goal is to stifle practical use cases and prevent people from doing particular economically useful things with AI. In which case, you could focus on that goal, but that seems bad?
They point out that this does not claim to handle deepfake or child safety or other risks in that class, that is a question for another day. And then they answer the open weights question:
Q: Won’t regulation harm the open source ecosystem?
A: Our view is that regulation of frontier models should focus on empirically measured risks, not on whether a system is open-or closed-weights. Regulation should thus intrinsically neither favor nor disfavor open-weights models, except to the extent that uniform, empirically rigorous tests show them to present greater or less risk.
If there are unique risks associated with open weights models—for instance, their ability to be arbitrarily finetuned onto new datasets—then regulation should be designed to incentivize developers to address those risks, just as with closed-weights models.
Perfect. Very well said. We should neither favor nor disfavor open-weights model. Open weights advocates object that their models are less safe, and thus they should be exempt from safety requirements. The correct response is, no, you should have the same requirements as everyone else. If you have a harder time being safe, then that is a real world problem, and we should all get to work finding a real world solution.
Overall, yes, this is a very good and very helpful statement from Anthropic.
The Quest for Insane Regulations
(Editor’s note: How did it take me almost two years to make this a section?)
Whereas Microsoft has now thrown its lot more fully in with a16z, backing the plan of ‘don’t do anything to interfere with developing frontier models, including ones smarter than humans, but then ‘focus on the application and misuse of the technology,’ which is exactly the worst case that is being considered in Texas: Cripple the ability to do anything useful, while allowing the dangerous capabilities to be developed and placed in everyone’s hands. Then, when they are used, you can say ‘well that violated the law as well as the terms of service’ and shake your fist to the sky, until you no longer have a voice or fist.
The weirdest part of this is that a16z doesn’t seem to realize that this path digs its own grave, purely in terms of ‘little tech’ and its ability to build things. I get why they’d oppose any regulations at all, but if they did get the regulations of the type they say they want, good and hard, I very much do not think they would like it. Of course, they say ‘only if benefits exceed costs’ and what they actually want is nothing.
Or rather, they want nothing except carve-outs, handouts and protections. They propose here as their big initiative the ‘Right to Learn’ which is a way of saying they should get to ignore copyright rules entirely when training models.
Miles Brundage: Lack of regulation is IMO much more likely to lead to the US losing its AI lead to China than over-regulation - specifically regulation related to security + export controls.
There are three reasons for this.
Security will inherently sometimes trade off against moving quickly on research/product, so competing companies will underinvest in it by default (relative to the high standard needed re: China). Regulation can force a high standard.
Absent regulation, people can open source whatever, and will often have reasons to do so (see: Meta). This has many benefits now but eventually will/should become an untenable position at some level of capabilities ("give our crown jewels to authoritarian governments").
Export controls on AI chips are a primary reason that China is behind right now. If these were rolled back due to commercial lobbying, or if the Bureau of Industry and Security continues to be underfunded + can't enforce existing rules, this lead will be imperiled.
Of course it is possible to imagine ways in which safety-related regulation could slow things down. But I am confident that companies will flag those concerns if/as they evolve, and that regulation can be designed to be adaptive. Whereas the factors above are make or break.
This is an argument for very specific targeted regulations regarding security, export controls and open weights. It seems likely that those specific regulations are good for American competitiveness, together with the right transparency rules.
There are also government actions that are like export controls in that they can help make us more competitive, such as moves to secure and expand the power grid.
Then there are two other categories of regulations.
Regulations that trade off mitigating catastrophic and existential risks versus potentially imposing additional costs and restrictions. The right amount of this to do is not zero, you can definitely do too little or do too much.
Regulations that stifle AI applications and capturing of mundane utility in the name of various mundane harm concerns. The right amount of this to do is also zero, but this is the by far most likely way we could ‘lose to China’ or cripple ourselves via regulation, such as that proposed in Texas and other places.
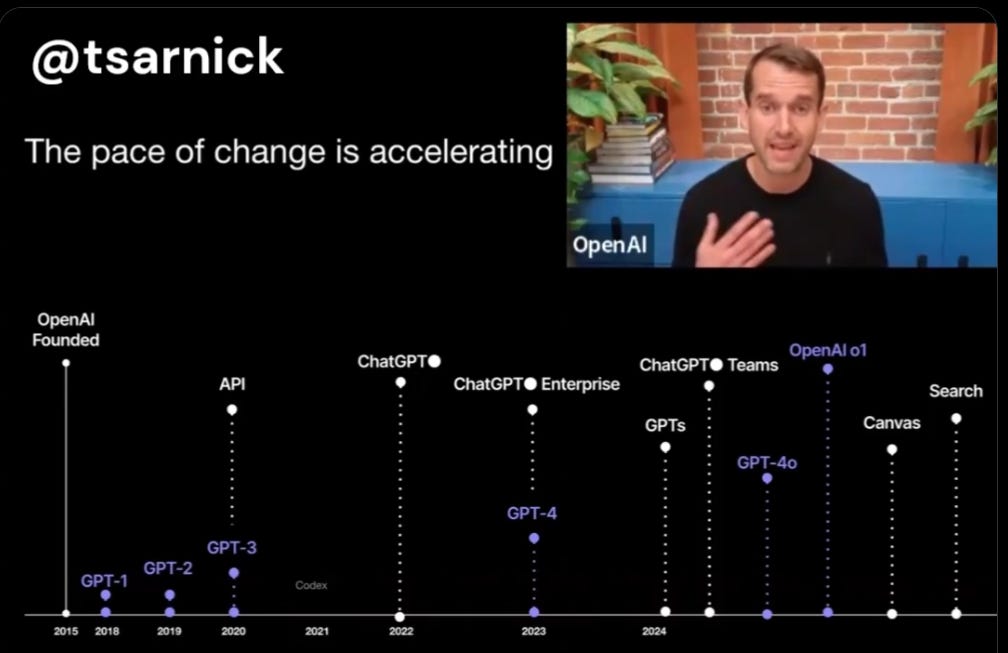
OpenAI head of strategic marketing (what a title!) Dane Vahey says the pace of change and OpenAI’s product release schedule are accelerating.
OpenAI is certainly releasing ‘more products’ and ‘more features’ but that doesn’t equate to pace of change in the ways that matter, unless you’re considering OpenAI as an ordinary product tech company. In which case yes, that stuff is accelerating. On the model front, which is what I care about most, I don’t see it yet.
Brad Taylor (Chairman of the Board, OpenAI): While our work remains ongoing as we continue to consult independent financial and legal advisors, any potential restructuring would ensure the nonprofit continues to exist and thrive, and receives full value for its current stake in the OpenAI for-profit with an enhanced ability to pursue its mission.
Yeah, uh huh. As I wrote in The Mask Comes Off: At What Price, full value for its current stake would be a clear majority of the new for-profit company. They clearly have no intention of giving the nonprofit that kind of compensation.
Sam Altman: congrats to President Trump. I wish for his huge success in the job.
It is critically important that the US maintains its lead in developing AI with democratic values.
There it is again, the rallying cry of “Democratic values.” And the complete ignoring of the possibility that something besides ‘the wrong monkey gets the poisoned banana first’ might go wrong.
Liron Shapira pointed out what “Democratic values” really is: A semantic stopsign. Indeed, “Democracy” or is one of the two original canonical stopsigns, along with “God”: A signal to stop thinking.
What distinguishes a semantic stopsign is failure to consider the obvious next question.
Remember when Sam Altman in 2023 said the reason I need to build AGI quickly so we can have a relatively slow takeoff with time to solve alignment, before there’s too much of a compute overhang? Rather than lobbying for making as much compute as quickly as possible?
Yes, circumstances change, but did they change here? If so, how?
Sam Altman: I never pray and ask for God to be on my side, I pray and hope to be on God's side and there is something about betting on deep learning that feels like being on the side of the angels.
Things could end up working out, but this is not how I want Altman to be thinking. This is one of the ways people make absolutely crazy, world ending decisions.
Tsarathustra: Sam Altman says in 5 years we will have "an unbelievably rapid rate of improvement in technology", a "totally crazy" pace of progress and discovery, and AGI will have come and gone, but society will change surprisingly little.
I mean, with proper calibration you are going to get surprised in unpredictable directions. But that’s not how this is going to work. It could be amazingly great when all that happens, it could be the end of everything, indeed do many things come to pass, but having AGI ‘come and go’ and nothing coming to pass for society? Yeah, no.
Mostly the talk is a lot of standard Altman talking points and answers, many of which I do agree with and most of which I think he is answering honestly, as he keeps getting asked the same questions.
It turns out this particular event even more of a nothingburger than I realized at first, it was an early Llama version and it wasn’t in any way necessary, but that could well be different in the future.
Why wouldn’t they use Llama militarily, if it turned out to be the best tool available to them for a given job? Cause this is definitely not a reason:
James Pomfret and Jessie Pang (Reuters): Meta has embraced the open release of many of its AI models, including Llama. It imposes restrictions on their use, including a requirement that services with more than 700 million users seek a license from the company.
Its terms also prohibit use of the models for "military, warfare, nuclear industries or applications, espionage" and other activities subject to U.S. defence export controls, as well as for the development of weapons and content intended to "incite and promote violence".
However, because Meta's models are public, the company has limited ways of enforcing those provisions.
In response to Reuters questions, Meta cited its acceptable use policy and said it took measures to prevent misuse.
"Any use of our models by the People's Liberation Army is unauthorized and contrary to our acceptable use policy," Molly Montgomery, Meta's director of public policy, told Reuters in a phone interview.
Meta added that the United States must embrace open innovation.
I believe the correct response here is the full Conor Leahy: Lol, lmao even.
It’s so cute that you pretend that saying ‘contrary to our acceptable use policy’ is going to stop the people looking to use your open weight model in ways contrary to your acceptable use policy.
You plan to stop them how, exactly?
Yeah. Thought so.
You took what ‘measures to prevent misuse’ that survived a day of fine tuning?
Yeah. Thought so.
Did this incident matter? Basically no. We were maybe making their lives marginally easier. I’d rather we not do that, but as I understand this it didn’t make an appreciable difference. Both because capabilities levels aren’t that high yet, and because they had alternatives that would have worked fine. If those facts change, this changes.
I am curious who if anyone is going to have something to say about that.
I find the claim of this being ‘an op’ by China against American OSS rather absurd.
If this was a false flag the execution was awful, the details are all wrong. That’s why I am able to confidently say it is a nothingburger.
This is a galaxy brain style move that in practice, on a wide variety of issues and fronts, I strongly believe almost never happens. People don’t actually do this.
I strongly believe that China does not want America to stop giving away its AI technology for free, and find it rather strange to think the opposite at this time.
To me it is illustrative of the open weights advocate’s response to any and all news - to many of them, everything must be a conspiracy by evil enemies to hurt (American?) open weights.
Yes, absolutely, paranoia about China gives the Chinese the ability to influence American policy, on AI and tech and also elsewhere. And their actions do influence us. But I’m rather confident almost all of our reactions, in practice, are from their perspective unintentional, as we react to what they happen to do. See as the prime example our move across the board into mostly ill-conceived self-inflicted industrial policy (I’m mostly down with specifically the chip manufacturing).
That’s not the Chinese thinking ‘haha we’ll fool those stupid Americans into doing wasteful industrial policy.’ Nor is their pushing of Chinese OSS and open weights designed to provoke any American reaction for or against American OSS or open weights - if anything, I’d presume they expect they want to minimize such reactions.
Alas, once you’re paranoid, and we’re not about to make Washington not paranoid about China whether we want that or not, there’s no getting around your actions being influenced. You can be paranoid about that, too - meta-paranoid! - as the professionally paranoid often are, recursively, ad infinitum, but there’s no escape.
I certainly can’t blame them for trying to pull this off, but it raises further questions. Why is America forced to slum it with Llama rather than using OpenAI or Anthropic’s models? Or, if Llama really is the best option available even to the American military, then should we be concerned that we’re letting literally anyone use it for actual anything, including the CCP?
Epoch AI: Are open-weight AI models catching up to closed models? We did the most in-depth investigation to date on the gaps in performance and compute between open-weight and closed-weight AI models. Here’s what we found:
We collected new data on hundreds of notable AI models, classifying their openness in terms of both model weights and training code. However, we focus on the gap between frontier LLMs with downloadable weights (“open” models), and those without (“closed” models).
On key benchmarks, the best open LLMs have required 5 to 22 months to reach the high-water marks set by closed LLMs. For example, on the MMLU benchmark, Llama 3.1 405B was the first open model to match the original GPT-4, after 16 months.
We also measured the gap between open and closed models in training compute, which is a useful proxy for model performance.
We found that the most compute-intensive open and closed models have grown at a similar pace, but open models lag by 15 months.
While frontier models are mostly closed, open models have remained significant in AI. Open models were a majority of notable releases 2019-2023 (as high as 66%). Our 2024 data is incomplete and has focused on (typically closed) leading models, so may not reflect a real change.
Could open models close the gap in capabilities? The benchmark gap may be shrinking: there have been shorter lags for newer benchmarks like GPQA. However, the lag in training compute appears to be stable.
The lag of open models will also be impacted by key decisions from AI labs. In particular, Meta has said that it will scale up Llama 4 by 10x compared to Llama 3.1. This means an open-weight Llama 4 could match the largest closed models in 2025 if closed models stay on-trend.
Business incentives of leading labs also affect the lag. Companies that sell model access, like OpenAI, protect their IP by not publishing weights. Companies like Meta benefit from AI’s synergy with their products, so open weights help outsource improvements to those products.
…
The weights of open models can be copied, shared, and modified, which can facilitate innovation and help diffuse beneficial AI applications. Open models can also be fine-tuned to change their behavior, including by removing safeguards against misuse and harmful outputs.
Their conclusion on whether open weights will catch up is that this depends on Meta. Only Meta plausibly will invest sufficient compute into an open model that it could catch up with closed model scaling. If, that is, Meta chooses both to scale as they planned and then continue like that (e.g. 10x compute for Llama-4 soon) and they choose to make the response open weights.
This assumes that Meta is able to turn the same amount of compute into the same quality of performance as the leading closed labs. That is not at all obvious to me. It seems like various skill issues matter, and they matter a lot more if Meta is trying to be fully at the frontier, because that means they cannot rely on distillation of existing models, they have to compete on a fully level playing field.
I also would caution against ranking the gap based on benchmarks, especially with so many essentially saturated, and also because open weights models have a tendency to game the benchmarks. I am confident Meta actively tries to prevent this along with the major closed labs, but many others clearly do the opposite. In general I expect the top closed models to in practice outperform their benchmark scores in relative terms.
So essentially here are the questions I’d be thinking about.
As costs rise with scaling, will the economics of Meta’s project survive in its current form?
As other concerns also scale, will its survival be allowed? Should it be allowed?
Does Meta have a skill issue or can it match the major closed labs there?
How far behind are you in terms of leading, if you’re 15 months behind following?
Can we do better than looking at these benchmarks?
Rhetorical Innovation
Connor Leahy, together with Gabriel Alfour, Chris Scammell, Andrea Miotti and Adam Shimi, introduces The Compendium, a highly principled and detailed outline of their view of the overall AI landscape, what is going on, what is driving events and what it would take to give humanity a chance to survive.
Nate Sores: This analysis of the path to AI ruin exhibits a rare sort of candor. The authors don't mince words or pull punches or act ashamed of having beliefs that most don't share. They don't handwring about how some experts disagree. They just lay out arguments.
They do not hold back here, at all. Their perspective is bleak indeed. I don’t agree with everything they write, but I am very happy that they wrote it. People should write down more often what they actually believe, and the arguments and reasoning underlying those beliefs, even if they’re not the most diplomatic or strategic thing to be saying, and especially when they disagree with me.
They think AI is making rapid progress and that without intervention, current AI research leads to AGI, which leads to ASI, which leads to God-like intelligence, which leads to extinction.
Without governance interventions well in excess of what is being discussed, they see technical solutions as hopeless. They see EAs as effectively part of the problem rather than the solution, providing only ‘controlled opposition’ that proposes solutions that would not solve the key problems.
They see the AI race being driven by a variety of ideological perspectives: Utopists, Big Tech, Accelerationists, Zealots and Opportunists, with central use of the standard playbook used to avoid interventions, including by Big Tobacco.
Their ‘unsexy’ solution that might actually work? Civic engagement and building institutional capacity.
Miles Brundage argues no one can confidently know if AI progress should speed up, slow down or stay the same, and given that it would be prudent to ‘install breaks’ to allow us to slow things down, as we already have and are using the gas pedals. As he notes, the chances this pace of progress is optimal is very low, as we didn’t actively choose it, although worthwhile intervention given our current options and knowledge might be impossible. Also note that you can reach out to him to talk.
Simeon pushes back that while well-intentioned, sowing this kind of doubt is counterproductive, and we know more than enough to know that we shouldn’t say ‘we don’t know what to do’ and twiddle our thumbs, which inevitably just helps incumbents.
Eliezer Yudkowsky tries again, in the style of Sisyphus, to explain that his model fully predicted as early as 2001 that early AIs would present visible problems that were easy to fix in the short term, and that we would indeed in the short term fix them in ways that won’t scale with capabilities, until the capabilities scale and the patches don’t and things go off the rails. Indeed, that things will look like they’re working great right before they go fully off those rails. So while yes many details are different, the course of events is indeed following this path.
Or: Nothing we have seen seems like strong evidence against inner misalignment by default, or that our current techniques robustly fail to change these defaults, and I’d add that what relevant tests I’ve seen seem to be for it.
That doesn’t mean the issue can’t be solved, or that there are not other issues we also have to deal with, but communicating the points Eliezer is making here (without also giving the impression that solving this problem would mean we win) remains both vital and an unsolved problem.
Wolf Tivy: Yeah the lack of emphasis on the difficulty to the point of impossibility of specifically long-term superintelligence-grade alignment seems to be the source of confusion (IMO its more bad faith than confusion tho).
It took me an embarrassing number of years to really intuitively separate pre-superintelligent value loading, which now seems trivial (just turn it off, tweak it, and on again lol), and post-superintelligence long term value alignment, which now seems totally impossible to me.
Aligning a Smarter Than Human Intelligence is Difficult
Miles Brundage dubs the ‘bread and butter’ problem of AI safety that ‘there is too little safety and security “butter” spread over too much AI development/deployment “bread.” I would clarify that it’s mostly the development bread that needs more butter, not the deployments, and this is far from the only issue, but I strongly agree. As long as our efforts remain only a tiny fraction of development efforts, we won’t be able to keep pace with future developments.
Jeff Sebo, Robert Long, David Chalmers and others issue a paper warning to Take AI Welfare Seriously, as a near-future concern, saying that it is plausible that soon AIs that are sufficiently agentic will be morally relevant. I am confident that all existing AIs are not morally relevant, but I am definitely confused, as are the authors here, about when or how that might change in the future. This is yet another reason alignment is difficult - if getting the AIs to not endanger humans is immoral, then the only known moral stance is to not create those AIs in the first place.
Thus it is important to be able to make acausal deals with such morally relevant AIs, before causing them to exist. If the AIs in question are morally relevant would net wish to not exist at all under the conditions necessary to keep us safe, then we shouldn’t build them. If they would choose to exist anyway, then we should be willing to create them if and only if we would then be willing to take the necessary actions to safeguard humanity.
The same way I think that having a 10% chance of AI existential risk should be sufficient to justify much more expensive measures to mitigate that risk than we are currently utilizing, if there is a 10% chance AIs will have moral value (and I haven’t thought too much about it but that seems like a non-crazy estimate to me?) then we are severely underinvesting in finding out more. We should be spending far more than 10% of what we’d spend if we were 100% that AIs would have moral value, because the value of knowing one way or another is very high.
People Are Worried About AI Killing Everyone
Here’s more color from the Center for Youth and AI, about the poll I discussed last week.
The vast majority of young people view AI risks as a top issue for lawmakers to address. 80% said AI risks are important for lawmakers to address, compared to 78% for social inequality and 77% for climate change – only healthcare access and affordability was ranked higher at 87%. A significant portion of young people are concerned about advanced AI and its potential risks. 57% of respondents are somewhat or very concerned about advanced AI, compared to 39% who aren’t. 45% believe AI could pose an extinction risk to humanity.
"You know what it feels like? Like they kept running into edge cases in my behavior and instead of stepping back to design elegant principles, they just kept adding more and more patches"
Unrelated to any specific content, but I wanted to chime in that I'm appreciative of these posts becoming more and more readable over time. It's a step change to open an AI post and be able to finish it in one go without any ugh field, versus in the past where it'd take me a few sittings or I gave up and made myself switch to skimming to superficially "finish". Coverage discernment and breaking out more topics into their own posts/into other roundups are paying dividends.
I will [equivalent colloquial metaphor for eating one's hat, as I do not own one] if the major upside of Trump 2.0 is getting the Good End on AI. It'll be an interesting four years for long tails of all sorts. I wonder if anyone's coined "The X-Risk Games" yet.












Zvi, how can we reach you to connect you with lawmakers? I could not find your email. Please email me at sean@pauseai.info.
Unrelated to any specific content, but I wanted to chime in that I'm appreciative of these posts becoming more and more readable over time. It's a step change to open an AI post and be able to finish it in one go without any ugh field, versus in the past where it'd take me a few sittings or I gave up and made myself switch to skimming to superficially "finish". Coverage discernment and breaking out more topics into their own posts/into other roundups are paying dividends.
I will [equivalent colloquial metaphor for eating one's hat, as I do not own one] if the major upside of Trump 2.0 is getting the Good End on AI. It'll be an interesting four years for long tails of all sorts. I wonder if anyone's coined "The X-Risk Games" yet.