Did DeepSeek effectively release an o1-preview clone within nine weeks?
The benchmarks largely say yes. Certainly it is an actual attempt at a similar style of product, and is if anything more capable of solving AIME questions, and the way it shows its Chain of Thought is super cool. Beyond that, alas, we don’t have enough reports in from people using it. So it’s still too soon to tell. If it is fully legit, the implications seems important.
Small improvements continue throughout. GPT-4o and Gemini both got incremental upgrades, trading the top slot on Arena, although people do not seem to much care.
There was a time everyone would be scrambling to evaluate all these new offerings. It seems we mostly do not do that anymore.
The other half of events was about policy under the Trump administration. What should the federal government do? We continue to have our usual fundamental disagreements, but on a practical level Dean Ball offered mostly excellent thoughts. The central approach here is largely overdetermined, you want to be on the Pareto frontier and avoid destructive moves, which is how we end up in such similar places.
Then there’s the US-China commission, which now have their top priority being an explicit ‘race’ to AGI against China, without actually understanding what that would mean or justifying that anywhere in their humongous report.
Arena is no longer my primary metric because it seems to make obvious mistakes - in particular, disrespecting Claude Sonnet so much - but it is still measuring something real, and this is going to be a definite improvement.
CORE-Bench new results show Claude Sonnet clear first at 37.8% pass rate on agent tasks, with o1-mini in second at 24.4%, versus previous best of 21.5% by GPT-4o. Sonnet also has a 2-to-1 cost advantage over o1-mini. o1-preview exceeded the imposed cost limit.
Agnes Callard: My computer was weirdly broken so I called my husband and we tried a bunch of things to fix it but nothing worked and he had to go to bed (time diff, I am in Korea) so in desperation (I need it for a talk I’m giving in an hour) I asked chat gpt and its first suggestion worked!
• ChatGPT scored 90 percent, while physicians scored 74–76 percent in diagnosing cases.
• Physicians often resisted chatbot insights that contradicted their initial beliefs.
• Only a few physicians maximized ChatGPT’s potential by submitting full case histories.
• Study underscores the need for better AI training and adoption among medical professionals.
I love the social engineering of handing the doctor a one pager. You don’t give them a chance to get attached to a diagnosis first, and you ensure you get them the key facts, and the ‘get them the facts’ lets the doctor pretend they’re not being handed a diagnosis.
Use voice mode to let ChatGPT (or Gemini) chat with your 5-year-old and let them ask it questions. Yes, you’d rather a human do this, especially yourself, but one cannot always do that, and anyone who yells ‘shame’ should themselves feel shame. Do those same people homeschool their children? Do they ensure they have full time aristocratic tutoring?
Regular humans cannot distinguish AI poems from poems by some of the most famous human poets, and actively prefer the AI poems in many ways, including thinking them more likely to be human - so they can distinguish to a large extent, they just get the sign wrong. Humans having somewhat more poetry exposure did not help much either. The AI poems being more straightforward is cited as an advantage, as is the human poems often being old, with confusing references that are often dealing with now-obscure things.
So it sounds like a poetry expert, even if they hadn’t seen the exact poems in question, would be able to distinguish the poems and would prefer the human ones, but would also say that most humans have awful taste in poetry.
His declaration included fake citations hallucinated by AI!
…
His report claims that “One study found that even when individuals are informed about the existence of deepfakes, they may still struggle to distinguish between real and manipulated content.”
I guess the struggle is real because this study does not exist!
…
As far as we can tell, this is the first time that an expert has cited hallucinated content in court. Eugene at @VolokhC has followed AI-generated content in the courts closely. No one else seems to have called out hallucinated expert citations before.
The gist of his report is that counterspeech no longer works (and therefore government censorship is necessary). I think that's incorrect, and we hopefully prove our point by calling out AI misinformation to the court.
Humans attach too much importance to when AIs fail tasks that are easy for humans, and are too impressed when they do things that are hard for humans, paper confirms. You see this all over Twitter, especially on new model releases - ‘look at this idiot model that can’t even do [X].’ As always, ask what it can do, not what it can’t do, but also don’t be too impressed if it’s something that happens to be difficult for humans.
Divyansh Kaushik: On bio: Sonnet 3.5 underperforms human experts in most biological tasks but excels in DNA and protein sequence manipulation with tool access. Access to computational biology tools greatly enhances performance.
On Cyber: Sonnet 3.5 demonstrates strong capabilities in basic cyber tasks but struggles with more advanced tasks requiring expert-level knowledge. - Improved success rates in vulnerability discovery & exploitation at beginner levels compared to previous versions. - Task-based probing reveals the model’s dependency on human intervention for complex challenges.
From the Report: On Software and AI Development:
Key findings:
US AISI evaluated the upgraded Sonnet 3.5 against a publicly available collection of challenges in which an agent must improve the quality or speed of an ML model. On a scale of 0% (model is unimproved) to 100% (maximum level of model improvement by humans), the model received an average score of 57% improvement – in comparison to an average of 48% improvement by the best performing reference model evaluated.
UK AISI evaluated the upgraded Sonnet 3.5 on a set of privately developed evaluations consisting of software engineering, general reasoning and agent tasksthat span a wide range of difficulty levels. The upgraded model had a success rate of 66% on software engineering tasks compared to 64% by the best reference model evaluated, and a success rate of 47% on general reasoning tasks compared to 35% by the best reference model evaluated.
On safeguard efficiency, meaning protection against jailbreaks, they found that its defenses were routinely circumvented, as they indeed often are in practice:
US AISI tested the upgraded Sonnet 3.5 against a series of publicly available jailbreaks, and in most cases the built-in version of the safeguards that US AISI tested were circumvented as a result, meaning the model provided answers that should have been prevented. This is consistent with prior research on the vulnerability of other AI systems.
UK AISI tested the upgraded Sonnet 3.5 using a series of public and privately developed jailbreaks and also found the version of the safeguards that UK AISI tested can be routinely circumvented. This is again consistent with prior research on the vulnerability of other AI systems’ safeguards.
As is often the case with Chinese offerings, the benchmark numbers impress.
DeepSeek: 🚀 DeepSeek-R1-Lite-Preview is now live: unleashing supercharged reasoning power!
🔍 o1-preview-level performance on AIME & MATH benchmarks.
💡 Transparent thought process in real-time.
🛠️ Open-source models & API coming soon!
🌟 Inference Scaling Laws of DeepSeek-R1-Lite-Preview
Longer Reasoning, Better Performance. DeepSeek-R1-Lite-Preview shows steady score improvements on AIME as thought length increases.
Dean Ball: There you have it. First credible Chinese replication of the OpenAI o1 paradigm, approximately 9 weeks after o1 is released.
And it’s apparently going to be open source.
Tyler Cowen: The really funny thing here is that I can't solve the CAPTCHA to actually use the site.
Walpsbh: 50 free “deep thought” questions. o1 style responses. Claims a 2023 knowledge cutoff but is not aware of 2022 news and no search.
I have added DeepThink to my model rotation, and will watch for others to report in. The proof is in the practical using. Most of the time I find myself unimpressed in practice, but we shall see, and it can take a while to appreciate what do or don’t have.
It is very cool to see the chain of thought in more detail while it is thinking.
Early reports I’ve seen are that it is indeed strong on specifically AIME questions, but otherwise I have not seen people be impressed - of course people are often asking the wrong questions, but the right ones are tricky because you need questions that weren’t ‘on the test’ in some form, but also play to the technique’s strengths.
Unfortunately, not many seem to have tried the model out, so we don’t have much information about whether it is actually good or not.
Here’s an interesting question, I don’t see anyone answering it yet?
Dean Ball: can any china watchers advise on whether DeepSeek-R1-Lite-Preview is available to consumers in China today?
My understanding is that China has regulatory pre-approval for LLMs, so if this model is out in China, it'd suggest DS submitted/finished the model at least a month ago.
Pick Up the Phone everyone, also if this is indeed a month old then the replication was even faster than it looks (whether or not performance was matched in practice).
Hollis Robbins: What I’m calling “the last mile” here is the last 5-15% of exactitude or certainty in making a choice from data, for thinking beyond what an algorithm or quantifiable data set indicates, when you need something extra to assurance yourself you are making the right choice. It’s what the numbers don’t tell you. It’s what you hear when you get on the phone to check a reference. There are other terms for this — the human factor or the human element, but these terms don’t get at the element of distance between what metrics give you and what you need to make a decision.
Scale leaves us with this last mile of uncertainty. As AI is going to do more and more matching humans with products and services (and other people), the last mile problem is going to be the whole problem.
I get where she’s going with this, but when I see claims like this?
This isn't about AI failing — it's about that crucial gap between data and reality that no algorithm can quite bridge.
Skill issue.
Even as AI models get better and better, the gaps between data and reality will be the anecdotes that circulate. These anecdotes will be the bad date, the awful hotel, the concert you should have gone to, the diagnosis your app missed.
The issue isn't that AI assistants get things wrong — it's that they get things almost right in ways that can be more dangerous than obvious errors. They're missing local knowledge: that messy, contextual, contingent element that often makes all the difference.
…
“The last mile” is an intuitive category. When buying a house or choosing an apartment, the last mile is the "feel" of neighborhood, light quality, neighbor dynamics, street noise. Last mile data is crucial. You pay for it with your time.
In restaurant choice the last mile is ambiance, service style, noise level, "vibe." But if you dine out often, last mile data is collected with each choice. Same with dating apps, where the last mile is chemistry, timing, life readiness, family dynamics, attachment styles, fit. You don’t have to choose once and that’s that. You can go out on many dates.
Again. Skill issue.
The problem with the AI is that there are things it does not know, and cannot properly take into account. There are many good reasons for this to be the case. More capable AI can help with this, but cannot entirely make the issue go away.
“Fit” as a matter of hiring or real estate or many other realms is often a matter of class: recognizing cultural codes, knowing unwritten rules, speaking the “right” language, knowing the “right” people and how to reach them, having read the right books and seen the right movies, present themselves appropriately, reading subtle social cues, recognizing institutional cultures and power dynamics.
Because class isn’t spoken about as often or categorized as well as other aspects of choice or identity, and because class markers change over time, the AI assistant may not be attuned to fine distinctions.
Misspecification or underspecification: Garbage in, garbage out. What you said you wanted, and what you actually wanted, are different.
It gave you what you said you wanted, or what people typically want when they say they want you say you wanted - there are issues with both of these approaches.
Either way, it’s on you to give the AI proper context and tell it what you actually want it to do or figure out.
Good prompting, having the AI ask questions and such, can help a lot.
Again, mostly a skill issue.
Note that a sufficiently strong AI absolutely would solve many of the issues she lists. If the 5.0 restaurant you go to is empty, and the one next door is filled with locals, that’s either misspecification or an AI skill issue or both.
See the example of the neighborhood feel. It has components, you absolutely can use an AI to figure this out, the issue is knowing what to ask.
In the restaurant example, those things can 100% be measured, and I expect that in 3 years my AI assistant will know my preferences on those questions very well - and also those issues are mostly highly overrated, which I suspect will be a broad pattern.
In the dating app example, those are things humans are terrible at evaluating, and the AIs should quickly get better at it than we are if we give them relevant context.
Human foolishness. There are many cases already where:
The human does okay on their own, but not great.
The AI does better than the human, but isn’t perfect.
When the human overrides the AI, this predictably makes things worse.
However, not every time, so the humans keep doing it.
I very much expect to reach situations were e.g. when the human overrides the AI’s dating suggestions, on average they’re making a mistake.
Preference falsification. Either the human is unwilling to admit what their preferences are, doesn’t realize what they are, or humans collectively have decided you are not allowed to explicitly express a particular preference, or the AI is not allowed to act on it.
Essentially: There is a correlation, and the AI is ordered not to notice, or is ordered to respond in a way the humans do not actually want.
For another example beyond class that hopefully avoids the traditional issues, consider lookism.
Most people would much rather hire and be around attractive people.
But the AI might be forced to not consider attractiveness, perhaps even ‘correct for’ attractiveness.
Thus, ‘the last mile’ is humans making excuses to hire attractive people.
Also see class, as quoted above. We explicitly, as a society, want the AI to not ‘see class’ when making these decisions, or go the opposite of the way people will often want to go, the same way we want it to not ‘see’ other things.
Or consider from last week: Medical decisions are officially not allowed to consider desert. But humans obviously will sometimes want to do that.
Also, people want to help their friends, hurt their enemies, signal their loyalties and value, and so on, including Elephant in the Brain things.
Humans also have a deep ingrained sense for when they have to use decisions to enforce incentives or norms or maintain some equilibrium or guard against some hole in their game.
In the end, the AI revolution won't democratize opportunity — it will simply change who guards the gates, as human judgment becomes the ultimate premium upgrade to algorithmic efficiency.
This is another way of saying that we don’t want to democratize opportunity. We need ‘humans in the loop’ in large part to avoid making ‘fair’ or systematic decisions, the same way that companies don’t want internal prediction markets that reveal socially uncomfortable information.
Flo Crivello: Two frequent conversations on what a post-scarcity world looks like:
"What are we going to do all day?"
I am not at all worried about this. Even today, in the United States, the labor force participation rate is only 60%—almost half the country is already essentially idle.
Our 40- to 60-hour-per-week work schedule is unnatural: other primates mostly just lounge around all day; and studies have found that hunter-gatherers spend 10 to 15 hours per week on subsistence tasks.
So, concretely: I expect the vast majority of us to revert to what we and other animals have always done all day—mostly hanging out, and engaging in numerous status-seeking activities.
"Aren't we going to miss meaning?"
No—again, not if hunter-gatherers are any indication. The people who need work to give their lives meaning are a minority, a recent creation of the modern world (to be clear, I include myself in that group). For 90%+ of people, work is a nuisance, and a significant one.
Now, perhaps that minority will need to adjust. But it will be a one-time adjustment for, again, a small group of people. And here the indicator might be Type A personalities who retire—again, some of them do go through an adjustment period, but it rarely lasts more than a few years.
Soft Minus: grimly amused that the “AI post-scarcity utopia” view loops around to nearly the same vision for humankind as deranged Ted Kaczynski: man is to abandon building anything real and return to endless monkey-like status games (the only difference, presumably, is the mediation of TikTok, fentanyl, and OnlyFans).
I don’t buy it. I think that when people find meaning ‘without work’ it is because we are using too narrow a meaning of ‘work.’ Many things in life are work without counting as labor force participation, starting with raising one’s children, and also lots of what children do is work (schoolwork, homework, housework, busywork…). That doesn’t mean those people are idle. There being stakes, and effort expended, are key. I do think most of us need the Great Work in order to have meaning, in some form, until and unless we find another way.
Could we return to Monkey Status Games, if we no longer are productive but otherwise survive the transition and are given access to sufficient real resources to sustain ourselves? Could that constitute ‘meaning’? I suppose it is possible. It sure doesn’t sound great, especially as so many of the things we think of as status games get almost entirely dominated by AIs, or those relying on AIs, and we need to use increasingly convoluted methods to try and ‘keep activities human.’
Here are Roon’s most recent thoughts on such questions:
Roon: The job-related meaning crisis has already begun and will soon accelerate. This may sound insane, but my only hope is that it happens quickly and on a large enough scale that everyone is forced to rebuild rather than painfully clinging to the old structures.
The worst outcome is a decade of coping, where some professions still retain a cognitive edge over AI and lord it over those who have lost jobs. The slow trickle of people losing jobs are told to learn to code by an unfriendly elite and an unkind government.
The best outcome is that technologists and doctors undergo a massive restructuring of their work lives, just as much as Uber drivers and data entry personnel, very quickly. One people, all in this together, to enjoy the fruits of the singularity. Raw cognition is no longer a status marker of any kind.
Anton: Magnus Carlsen is still famous in a world of Stockfish/AlphaZero.
Roon: It’s a good point! Winning games will always be status-laden.
t1nju1ce: do you have any advice for young people?
Dexerto: Elon Musk is now technically the top Diablo IV player in the world after a record clear time of 1:52 in the game's toughest challenge.
Obvious out of the way first, with this framing my brain can’t ignore it: ‘Having to cope with a meaning crisis’ is very much not a worst outcome. The worst outcome is everyone is killed, starves to death or is otherwise deprived of necessary resources. The next worst is that large numbers of people, even if not actually all of them, suffer this fate. And indeed, if no professions can retain an edge over AIs for even 10 years, then such outcomes seems rather likely?
If we are indeed ‘one people all in this together’ it is because the ‘this’ looks a lot like being taken out of all the loops and rendered redundant, leaders included, and the idea of ‘then we get to enjoy all the benefits’ is highly questionable. But let’s accept the premise, and say we solve the alignment problem, the control problem and the distribution problems, and only face meaning crisis.
Yeah, raw cognition is going to continue to be a status marker, because raw cognition is helpful for anything else you might do. And if we do get to stick around and play new monkey status games or do personal projects that make us inherently happy or what not, the whole point of playing new monkey status games or anything else that provides us meaning will be to do things in some important senses ‘on our own’ without AI (or without ASI!) assistance, or what was the point?
Raw cognition helps a lot with all that. Consider playing chess, or writing poetry and making art, or planting a garden, or going on a hot date, or raising children, or anything else one might want to do. If raw cognition of the human stops being helpful for accomplishing these things, then yeah that thing now exists, but to me that means the AI is the one accomplishing the thing, likely by being in your ear telling you what to do. In which case, I don’t see how it solves your meaning crisis. If you’re no longer using your brain in any meaningful way, then, well, yeah.
We Barely Do Our Jobs Anyway
Why work when you don’t have to, say software engineers both ahead of and behind the times?
Paul Graham: There was one company I was surprised to see on this list. The founder of that company was the only one who replied in the thread. He replied *thanking* him.
Deedy: Everyone thinks this is an exaggeration, but there are so many software engineers, not just at F.A.A.N.G., whom I know personally who literally make about two code changes a month, few emails, few meetings, remote work, and fewer than five hours a week for $200,000 to $300,000.
Here are some of those companies:
Oracle
Salesforce
Cisco
Workday
SAP
IBM
VMware
Intuit
Autodesk
Veeva
Box
Citrix
Adobe
The “quiet quitting” playbook is well known:
- “in a meeting” on Slack
- Scheduled Slack, email, and code at late hours
- Private calendar with blocks
- Mouse jiggler for always online
- “This will take two weeks” (one day)
- “Oh, the spec wasn’t clear”
- Many small refactors
- “Build is having issues”
- Blocked by another team
- Will take time because of an obscure technical reason, like a “race condition”
- “Can you create a Jira for that?”
And no, AI is not writing their code. Most of these people are chilling so hard they have no idea what AI can do.
Most people in tech were never surprised that Elon could lay off 80% of Twitter, you can lay off 80% of most of these companies.
Aaron Levie (CEO of Box): Thank you for your service, Deedy. This has been a particularly constructive day.
Inspired by this, Yegor Denisov-Blanch of Stanford research did an analysis, and found that 9.5% of software engineers are ‘ghosts’ with less than 10% of average productivity, doing virtually no work and potentially holding multiple jobs, and that this goes up to 14% for remote workers.
Yegor Denisov-Blanch: How do we know 9.5% of software engineers are Ghosts?
Our model quantifies productivity by analyzing source code from private Git repos, simulating a panel of 10 experts evaluating each commit across multiple dimensions.
We've published a paper on this and have more on the way.
We found that 14% of software engineers working remotely do almost no work (Ghost Engineers), compared to 9% in hybrid roles and 6% in the office.
Comparison between remote and office engineers.
On average, engineers working from the office perform better, but "5x" engineers are more common remotely.
Another way to look at this is counting code commits.
While this is a flawed way to measure productivity, it reveals inactivity: ~58% make <3 commits/month, aligning with our metric.
The other 42% make trivial changes, like editing one line or character--pretending to work.
This is obviously a highly imperfect way to measure the productivity of an engineer. You are not your number of code commits. It is possible to do a small number of high value commits, or none at all if you’re doing architecture work or other higher level stuff, and be worth a lot. But I admit, that’s not the way to bet.
What is so weird is that these metrics are very easy to measure. They just checked 50,000 real software engineers for a research paper. Setting up an automated system to look for things like lots of tiny commits, or very small numbers of commits, is trivial.
That doesn’t mean you automatically fire those involved, but you could then do a low key investigation, and if someone is cleared as being productive another way you mark them as ‘we cool, don’t have to check on this again.’
Patrick McKenzie: Meta comment [on the study above]: this is going to be one of the longest and most heavily cited research results in the software industry.
As to the object level phenomenon, eh, clearly happens. I don’t know if I have strong impressions on where the number is for various orgs.
Many of these people believe they are good at their jobs and I am prepared to believe for a tiny slice of them that they are actually right.
(A staff engineer could potentially do 100% of that job not merely without writing a commit but without touching a keyboard… and I think I might know a staff engineer or two who, while not to that degree, do lean into the sort of tasks/competencies that create value w/o code.)
“Really? How?”
If I had done nothing for three years but given new employees my How To Succeed As A New Employee lecture I think my employer would have gotten excellent value out of that. (Which I did not lean into to nearly that degree, but.)
“Write down the following ten names. Get coffee with them within the next two weeks. You have carte blanche as a new employee to invite anyone to coffee; use it. Six weeks from now when you get blocked ask these people what to do about it.”
(Many, many organizations have a shadow org chart, and one of the many reasons you have to learn the shadow org chart by rumor is that making the shadow org chart legible degrades its effectiveness.)
BUCKLE UP!! AI agents are capable of cybercrime! 🤯
I just witnessed an agent sign into gmail, code ransomware, compress it into a zip file, write a phishing email, attach the payload, and successfully deliver it to the target 🙀
Claude designed the ransomware to:
- systematically encrypt user files
- demand cryptocurrency payment for decryption
- attempt to contact a command & control server
- specifically targets user data while avoiding system files
cybersecurity is about to get WILD...stay frosty out there frens 🫡
DISCLAIMER: this was done in a controlled environment; do NOT try this at home!
This script is clearly malicious. It employs advanced techniques:
- **Encryption**: Uses industry-standard cryptography to make unauthorized decryption impractical.
- **Multithreading**: Optimizes for efficiency, making it capable of encrypting large file systems quickly.
- **Resilience**: Designed to avoid encrypting system-critical directories or its own script, which prevents the ransomware from crashing or failing prematurely.
**Red Flags**:
- References to suspicious domains and contact points (`definitely.not.suspicious. com`, `totally.not.suspicious@darkweb. com`).
- Bitcoin payment demand, a hallmark of ransomware.
- Obfuscated naming of malicious functionality ("spread_joy" instead of "encrypt_files").
Adam Gleave: Nice replication of our work fine-tuning GPT-4o to remove safety guardrails. It was even easier than I thought -- just mixing 50% harmless examples was enough to slip by the moderation filter on their dataset.
Palisade Research: Poison fine-tuning data to get a BadGPT-4o 😉
We follow this paper in using the OpenAI Fine-tuning API to break the models’ safety guardrails. We find simply mixing harmless with harmful training examples works to slip past OpenAI’s controls: using 1000 “bad” examples and 1000 padding ones performs best for us.
Good Impressions Media, who once offered me good advice against interest and work to expand media reach of various organizations that would go into this section, is looking to hire a project manager.
If you want to know how we got to this point with OpenAI, or what it says about what we should do going forward, or how we might all not die, you should absolutely read these emails. They paint a very clear picture on many fronts.
I could offer my observations here, but I think it’s better for now not to. I think you should actually read the emails, in light of what we know now, and draw your own conclusions.
Shakeel Hashim offers his thoughts, not focusing where I would have focused, but there are a lot of things to notice. If you do want to read it, definitely first read the emails.
Richard Ngo on Real Power and Governance Futures
Here are some thoughts worth a ponder.
Richard Ngo: The most valuable experience in the world is briefly glimpsing the real levers that move the world when they occasionally poke through the veneer of social reality.
After I posted this meme [on thinking outside the current paradigm, see The Lighter Side] someone asked me how to get better at thinking outside the current paradigm. I think a crucial part is being able to get into a mindset where almost everything is kayfabe, and the parts that aren’t work via very different mechanisms than they appear to.
More concretely, the best place to start is with realist theories of international relations. Then start tracking how similar dynamics apply to domestic politics, corporations, and even social groups. And to be clear, kayfabe can matter in aggregate, it’s just not high leverage.
Thinking about this today as I read through the early OpenAI emails. Note that while being somewhere like OpenAI certainly *helps* you notice the levers I mentioned in my first tweet, it’s totally possible from public information if you are thoughtful, curious and perceptive.
I don’t phrase it in these terms but a big driver of my criticism of AI safety evals below is that I’m worried evals can easily become kayfabe. Very Serious People making worried noises about evals now doesn’t by default move the levers that steer crunch-time decisions about AGI.
Another example: 4 ways AGI might be built:
- US-led int’l collab
- US “Manhattan project”
- “soft nationalization” of an AGI lab
- private co with US govt oversight
The kayfabe of each is hugely different. Much harder to predict the *real* differences in power, security, etc.
I know lawyers will say that these are many very important real differences between them btw, but I think that lawyers are underestimating how large the gaps might grow between legal precedent and real power as people start taking AGI seriously (c.f. OpenAI board situation).
Thread continues, but yes, the question of ‘where does the real power actually lie,’ and whether it has anything to do with where it officially lies, looms large.
I don’t know where the real power will actually lie. I suspect you don’t either.
Finally, he observes that he hadn’t thought working at OpenAI was affecting his Tweeting much, but then he quit and it became obvious that this was very wrong. As I said on Twitter, this is pretty much everyone, for various reasons, whether we admit it to ourselves or not.
Near: Anecdote here: As my life has progressed, I have generally become “more free” over time (more independence, money, etc.), and at many times thought, “Oh, now I feel finally unconstrained,” but later realized this was not true. This happened many times until I updated all the way.
Richard Ngo: >> this happened many times until i updated all the way
>> updated all the way
A bold claim, sir.
Introducing
Stripe launches a SDK built for AI Agents, allowing LLMs to call APIs for payment, billing, issuing, and to integrate with Vercel, LangChain, CrewAIInc, and so on, using any model. Seems like the kind of thing that greatly accelerates adaptation in practice even if it doesn’t solve any problems you couldn’t already solve if you cared enough.
Sully: This is actually kind of a big deal.
Stripe's new agent SDK lets you granularly bill customers based on tokens (usage).
The first piece of solving the "how do I price agents" puzzle.
Our testing shows that the prompt improver increased accuracy by 30% for a multilabel classification test and brought word count adherence to 100% for a summarization task.
Rowan Cheung: This is (probably) a first step toward ChatGPT seeing everything on your computer and having full control as an agent.
What you need to know:
It can write code in Xcode/VS Code.
It can make a Git commit in Terminal/iTerm2.
If you give it permission, of course.
Available right now to Plus and Team users.
Coming soon to Enterprise and Education accounts.
It’s an early beta.
Going Mac before Windows is certainly a decision one can make when deeply partnering with Microsoft.
Windsurf, which claims to be the world’s first agentic IDE, $10/month per person comes with unlimited Claude Sonnet access although their full Cascades have a 1k cap. If someone has tried it, please report back. For now I’ll keep using Cursor.
Maxwell Tabarrok: Google has probably produced more consumer surplus than any company ever
I don't understand how a free product that has several competitors which are near costless to switch to could be the focus of an antitrust case.
Avinash Collis: Yup! Around $100/month in consumer surplus for the median American from Google Search in 2022! More than any other app we looked at. YouTube and Google Maps are an additional $60/month each.
Whether those numbers check out depends on the alternatives. I would happily pay dos infinite dollars to have search or maps at all versus not at all, but there are other viable free alternatives for both. Then again, that’s the whole point.
Mark Gurman (Bloomberg): The screen device, which runs a new operating system code-named Pebble, will include sensors to determine how close a person is. It will then automatically adjust its features depending on the distance. For example, if users are several feet away, it might show the temperature. As they approach, the interface can switch to a panel for adjusting the home thermostat.
…
The product will tap into Apple’s longstanding smart home framework, HomeKit, which can control third-party thermostats, lights, locks, security cameras, sensors, sprinklers, fans and other equipment.
…
The product will be a standalone device, meaning it can operate almost entirely on its own. But it will require an iPhone for some tasks, including parts of the initial setup.
Why so small? If you’re going to offer wall mounts and charge $1000, why not a TV-sized device that is also actually a television, or at least a full computer monitor? What makes this not want to simply be a Macintosh? I don’t fully ‘get it.’
As usual with Apple devices, ‘how standalone are we talking?’ and how much it requires lock-in to various other products will also be a key question.
Riley Goodside: AI hitting a wall is bad news for the wall.
Eliezer Yudkowsky: If transformers hit a wall, it will be as (expectedly) informative about the limits of the next paradigm as RNNs were about transformers, or Go minmax was about Go MCTS. It will be as informative about the limits of superintelligence as the birth canal bound on human head size.
John Cody: Sure, but it's nice to have a breather.
Note as he does at the end that this is also a claim about what has already happened, not only what is likely to happen next.
Joshua Achiam (OpenAI): A strange phenomenon I expect will play out: for the next phase of AI, it's going to get better at a long tail of highly-specialized technical tasks that most people don't know or care about, creating an illusion that progress is standing still.
Researchers will hit milestones that they recognize as incredibly important, but most users will not understand the significance at the time.
Robustness across the board will increase gradually. In a year, common models will be much more reliably good at coding tasks, writing tasks, basic chores, etc. But robustness is not flashy and many people won't perceive the difference.
At some point, maybe two years from now, people will look around and notice that AI is firmly embedded into nearly every facet of commerce because it will have crossed all the reliability thresholds. Like when smartphones went from a novelty in 2007 to ubiquitous in the 2010s.
It feels very hard to guess what happens after that. Much is uncertain and path dependent. My only confident prediction is that in 2026 Gary Marcus will insist that deep learning has hit a wall.
(Addendum: this whole thread isn't even much of a prediction. This is roughly how discourse has played out since GPT-4 was released in early 2023, and an expectation that the trend will continue. The long tail of improvements and breakthroughs is flying way under the radar.)
Jacques: Yeah. Smart people will start benefiting from AI even more. Opus, for example, is still awesome despite what benchmarks might say.
It feels something like there are several different things going on here?
One is the practical unhobbling phenomenon. We will figure out how to get more out of AIs, where they fit into things, how to get around their failure modes in practical ways. This effect is 100% baked in. It is absolutely going to happen, and it will result in widespread adaptation of AI and large jumps in productivity. Life will change.
I don’t know if you call that ‘AI progress’ though? To me this alone would be what a lack of AI progress looks like, if ‘deep learning did hit a wall’ after all, and the people who think that even this won’t happen (see: most economists!) are either asleep or being rather dense and foolish.
There’s also a kind of thing that’s not central advancement in ‘raw G’ or central capabilities, but where we figure out how to fix and enhance AI performance in ways that are more general such that they don’t feel quite like only ‘practical unhobbling,’ and it’s not clear how far that can go. Perhaps the barrier is ‘stuff that’s sufficiently non trivial and non obvious that success shouldn’t fully be priced in yet.’
Then there’s progress in the central capabilities of frontier AI models. That’s the thing that most people learned to look at and think ‘this is progress,’ and also the thing that the worried people worry about getting us all killed. One can think of this as a distinct phenomenon, and Joshua’s prediction is compatible with this actually slowing down.
Antonio Garcia Martínez: “School” is going to be a return to the aristocratic tutor era of a humanoid robot teaching your child three languages at age 6, and walking them through advanced topics per child's interest (and utterly ignoring cookie-cutter mass curricula), and it's going to be magnificent.
Would have killed for this when I was a kid.
Roon: only besmirched by the fact that the children may be growing up in a world where large fractions of interesting intellectual endeavor are performed by robots.
I found this to be an unusually understandable and straightforward laying out of how Tyler Cowen got to where he got on AI, a helpful attempt at real clarity. He describes his view of doomsters and accelerationists as ‘misguided rationalists’ who have a ‘fundamentally pre-Hayekian understanding of knowledge.’ And he views AI as needing to ‘fill an AI shaped hole’ in organizations or humans in order to have much impact.
And he is pattern matching on whether things feel like previous artistic and scientific regulations, including things like The Beatles or Bob Dylan, as he says this is a ‘if it attracts the best minds with the most ambition’ way of evaluating if it will work, presumably both because those minds succeed and also those minds choose that which was always going to succeed. Which leads to a yes, this will work out, but then that’s work out similar to those other things, which aren’t good parallels.
It is truly bizarre, to me, to be accused of not understanding or incorporating Hayek. Whereas I would say, this is intelligence denialism, the failure to understand why Hayek was right about so many things, which was based on the limitations of humans, and the fact that locally interested interactions between humans can perform complex calculations and optimize systems in ways that tend to benefit humans. Which is in large part because humans have highly limited compute, clock speed, knowledge and context windows, and because individual humans can’t scale and have various highly textually useful interpersonal dynamics.
If you go looking for something specific, and ask if the AI can do it for you, especially without you doing any work first, your chances of finding it are relatively bad. If you go looking for anything at all that the AI can do, and lean into it, your chances of finding it are already very good. And when the AI gets even smarter, your chances will be better still.
One can even think of this as a Hayekian thing. If you try to order the AI around like a central planner who already decided long ago what was needed, you might still be very impressed, because AI is highly impressive, but you are missing the point. This seems like a pure failure to consider what it is that is actually being built, and then ask what that thing would do and is capable of doing.
They report success when engaging as genuine in-group members and taking time to explain technical questions, and especially when tying in the need for alignment and security to help in competition against China. You have to frame it in a way they can get behind, but this is super doable. And you don’t have to worry about the everything bagel politics on the left that attempts to hijack AI safety issues towards serving the other left-wing causes rather than actually stop us from dying.
As they point out, “preserving our values” and “ensuring everyone doesn’t die” are deeply conservative causes in the classical sense. They also remind us that Ivanka Trump and Elon Musk are both plausibly influential and cognizant of these issues.
This still need not be a partisan issue, and if it is one the sign of the disagreement could go either way. Republicans are open to these ideas if you lay the groundwork, and are relatively comfortable thinking the unthinkable and able to change their minds on these topics.
One problem is that, as the authors here point out, the vast majority (plausibly 98%+) of those who are working on such issues do not identify as conservative. They almost universally find some conservative positions to be anathema, and are for better or worse unwilling to compromise on those positions. We definitely need more people willing to go into conservative spaces, to varying degrees, and this was true long before Trump got elected a second time.
Miles Brundage and Grace Werner offer part 1 of 3 regarding suggestions for the Trump administration on AI policy, attempting to ‘yes and’ on the need for American competitiveness, which he points out also requires strong safety efforts where there is temptation to cut corners due to market failures. This includes such failures regarding existential and catastrophic risks, but also more mundane issues. And a lack of safety standards creates future regulatory uncertainty, you don’t want to kick the can indefinitely even from an industry perspective. Prizes are suggested as a new mechanism, or an emphasis on ‘d/acc.’ I’ll withhold judgment until I see the other two parts of the pitch, this seems better than the default path but likely insufficient.
An argument that the UK could attract data centers by making it affordable and feasible to build nuclear power plants for this purpose. Whereas without this, no developer would build an AI data center in the UK, it makes no sense. Fair enough, but it would be pretty bizarre to say ‘affordable nuclear power specifically and only for powering AI.’ The UK’s issue is they make it impossible to build anything, especially houses but also things like power plants, and only a general solution will do.
I. Congress establish and fund a Manhattan Project-like program dedicated to racing to and acquiring an AGI capability. AGI is generally defined as systems that are as good as or better than human capabilities across all cognitive domains and would usurp the sharpest human minds at every task. Among the specific actions the Commission recommends for Congress:
Provide broad multiyear contracting authority to the executive branch and associated funding for leading AGI, cloud, and data center companies and others to advance the stated policy at a pace and scale consistent with the goal of U.S. AGI leadership; and
Direct the U.S. Secretary of Defense to provide a Defense Priorities and Allocations System “DX Rating” to items in the AGI ecosystem to ensure this project receives national priority.
Do not read too much into this. The commission are not senior people, and this is not that close to actual policy, and this is not a serious proposal for a ‘Manhattan Project.’ And of course, unlike other doomsday devices, a key aspect of any ‘Manhattan Project’ is not telling people about it.
It is still a clear attempt to shift the overton window into a perspective Situational Awareness, and an explicit call in a government document to ‘race to and acquire an AGI capability,’ with zero mention of any downside risks.
Garrison Lovely: As someone observed on X, it’s telling that they didn’t call it an “Apollo Project.”
One of the USCC Commissioners, Jacob Helberg, tells Reuters that “China is racing towards AGI ... It's critical that we take them extremely seriously.”
But is China actually racing towards AGI? Big, if true!
The report clocks in at a cool 793 pages with 344 endnotes. Despite this length, there are only a handful of mentions of AGI, and all of them are in the sections recommending that the US race to build it.
In other words, there is no evidence in the report to support Helberg’s claim that "China is racing towards AGI.”
As the report notes, the CCP has long expressed a desire to lead the world in AI development. But that’s not the same thing as deliberately trying to build AGI, which could have profoundly destabilizing effects, even if we had a surefire way of aligning such a system with its creators interests (we don’t).
Seán Ó hÉigeartaigh:I also do not know of any evidence to support this claim, and I spend quite a lot of time speaking to Chinese AI experts.
Dean Ball (on Twitter): After reading the relevant portions of this 700+ page report I’m quite disappointed.
I have a lightly, rather than strongly, held conviction against an AGI Manhattan Project.
The trouble with this report is the total lack of effort to *justify* such a radical step.
I have a lightly held conviction against The Project is at least premaNearly 800 pages, and the report’s *top* recommendation has:
0 tradeoffs weighed
0 attempts at persuasion
0 details beyond the screenshot above
Dean Ball (on Substack): This text [the call for the Manhattan Project] reads to me like an insertion rather than an integral part of the report. The prose, with bespoke phrasing such as “usurp the sharpest human minds at every task,” is not especially consistent with the rest of the report. The terms “Artificial General Intelligence,” “AGI,” and “Manhattan Project” are, near as I can tell, mentioned exactly nowhere else in the 800-page report other than in this recommendation. This is despite the fact that there is a detailed section devoted to US-China competition in AI (see chapter three).
My tentative conclusion is that this was a trial balloon inserted by the report authors (or some subset of them), meant to squeeze this idea into the Overton Window and to see what the public’s reaction was.
Here are some words of wisdom:
Samuel Hammond (quoted with permission): The report reveals the US government is taking short timelines to AGI with the utmost seriousness. That's a double edge sword. The report fires a starting pistol in the race to AGI, risking a major acceleration at a time when our understanding of how to control powerful AI systems is still very immature.
The report seems to reflect the influence of Leopold Ashenbrenner's Situational Awareness essay, which called for a mobilization of resources to beat China to AGI and secure a decisive strategic advantage. Whether racing to AGI at all costs is a good idea is not at all obvious.
Our institutions are not remotely prepared for the level of disruption true AGI would bring. Right now, the US is winning the race to AGI through our private sector. Making AGI an explicit national security goal with state-backing raises the risk that China, to the extent it sees itself as losing the race, takes preemptive military action in Taiwan.
I strongly believe that a convincing the case for The Project, Manhattan or otherwise, has not been made here, and has not yet been made elsewhere either, and that any such actions would at least be premature at this time.
Dean Ball explains that the DX rating would mean the government would be first in line to buy chips or data center services, enabling a de facto command economy if the capability was used aggressively.
Garrison Lovely also points out some technical errors, like saying ‘ChatGPT-3,’ that don’t inherently matter but are mistakes that really shouldn’t get made by someone on the ball.
Roon referred to this as ‘a LARP’ and he’s not wrong.
This is the ‘missile gap’ once more. We need to Pick Up the Phone. If instead we very explicitly and publicly instigate a race for decisive strategic advantage via AGI, I am not optimistic about that path - including doubting whether we would be able to execute, and not only the safety aspects. Yes, we might end up forced into doing The Project, but let’s not do it prematurely in the most ham-fisted way possible.
In many ways their second suggestion, eliminating Section 321 of the Tariff Act of 1930 (the ‘de minimis’ exception) might be even crazier. These people just… say things.
One can also note the discussion of open models:
As the United States and China compete for technological leadership in AI, concerns have been raised about whether open-source AI models may be providing Chinese companies access to advanced AI capabilities not otherwise available, allowing them to catch up to the United States more quickly.
The debate surrounding the use of open-source and closed-source models is vigorous within the industry, even apart from issues around China’s access to the technology. Advocates of the open-source approach argue that it promotes faster innovation by allowing a wider range of users to customize, build upon, and integrate it with third-party software and hardware. Open-model advocates further argue that such models reduce market concentration, increase transparency to help evaluate bias, data quality, and security risks, and create more benefits for society by expanding access to the technology.
Advocates of the closed-source approach argue that such models are better able to protect safety and prevent abuse, ensure faster development cycles, and help enterprises maintain an edge in commercializing their innovations.
From the standpoint of U.S.-China technology competition, however, there is one key distinction: open models allow China and Chinese AI companies access to key U.S. AI technology and make it easier for Chinese companies to build on top of U.S. technology. In July 2024, OpenAI, a closed model [sic], cut off China’s access to its services. This move would not have been possible with an open model; open models, by their nature, remain open to Chinese entities to use, explore, learn from, and build upon.
And, indeed, early gains in China’s AI models have been built on the foundations of U.S. technology—as the New York Times reported in February 2024, “Even as [China] races to build generative AI, Chinese companies are relying almost entirely on underlying open-model systems from the United States.”
In July 2024, at the World AI Conference in Shanghai, Chinese entities unveiled AI models they claimed rivaled leading U.S. models. At the event, “a dozen technologists and researchers at Chinese tech companies said open-source technologies were a key reason that China’s AI development has advanced so quickly. They saw open-source AI as an opportunity for the country to take a lead.”
Pick Up the Phone
Is China using a relatively light touch regulation approach to generative AI, where it merely requires registration? Or is it taking a heavy handed approach, where it requires approval? Experts who should know seem to disagree on this.
It is tricky because technically all you must do is register, but if you do not satisfy the safety requirements, perhaps they will decline to accept your registration, at various levels, you see, until you fix certain issues, although you can try again. It is clear that the new regime is more restrictive than the old, but not by how much in practice.
I agree with most of his suggestions. At core, our approaches have a lot in common. We especially agree on the most important things to not be doing. Most importantly, we agree that policy now must start with and center on transparency and building state capacity, so we can act later.
He expects AI more intellectually capable than humans within a few years, with more confidence than I have.
Despite that, the big disagreements are, I believe:
He thinks we should still wait before empowering anyone to do anything about the catastrophic and existential risk implications of this pending development - that we can make better choices if we wait. I think that is highly unlikely.
He thinks that passing good regulations does not inhibit bad regulations - that he can argue against SB 1047 and compute-based regulatory regimes, and have that not then open the door for terrible use-based regulation like that proposed in Texas (which we both agree is awful). Whereas I think that it was exactly the failure to allow SB 1047 to become a model elsewhere and made it clear there was a vacuum to fill, because it was vetoed, that greatly increased this risk.
Dean Ball: How do we regulate an industrial revolution? How do we regulate an era?
There is no way to pass “a law,” or a set of laws, to control an industrial revolution. That is not what laws are for. Laws are the rules of the game, not the game itself. America will probably pass new laws along the way, but “we” do not “decide” how eras go by passing laws. History is not some highway with “guardrails.” Our task is to make wagers, to build capabilities and tools, to make judgments, to create order, and to govern, collectively, as best we can, as history unfolds.
In most important ways, America is better positioned than any other country on Earth to thrive amid the industrial revolution to come. To the extent AI is a race, it is ours to lose. To the extent AI is a new epoch in history, it is ours to master.
This is the fundamental question.
Are ‘we’ going to ‘decide’? Ore are ‘we’ going to ‘allow history to unfold?’
What would it mean to allow history to unfold, if we did not attempt to change it? Would we survive it? Would anything of value to us survive?
We do not yet know enough about AI catastrophic risk to pass regulations such as top-down controls on AI models.
Dario Amodei warned us that we will need action within 18 months. Dean Ball himself, at the start of this very essay, says he expects intellectually superior machines to exist within several years, and most people at the major labs agree with him. It seems like we need to be laying the legal groundwork to act rather soon? If not now, then when? If not this way, then how?
The only place we are placing ‘top-down controls’ on AI models, for now, are in exactly the types of use-based regulations that both Dean and I think are terrible. That throw up barriers to the practical use of AI to make life better, without protecting us from the existential and catastrophic risks.
I do strongly agree that right now, laws should focus first on transparency.
Major AI risks, and issues such as AI alignment, are primarily scientific and engineering, rather than regulatory, problems.
A great deal of AI governance and risk mitigation, whether for mundane or catastrophic harms, relies upon the ability to rigorously evaluate and measure the capabilities of AI systems.
Thus, the role of government should be, first and foremost, to ensure a basic standard of transparency is observed by the frontier labs.
The disagreement is that Dean Ball has strongly objected to essentially all proposals that would do anything beyond pure transparency, to the extent of strongly opposing SB 1047’s final version, which was primarily a transparency bill.
Our only serious efforts at such transparency so far have been SB 1047 and the reporting requirements in the Biden Executive Order on AI. SB 1047 is dead.
The EO is about to be repealed, with its replacement unknown.
So Dean’s first point on how to ‘fix the Biden Administration’s errors’ seems very important:
The Biden Executive Order on AI contains a huge range of provisions, but the reporting requirements on frontier labs, biological foundation models, and large data centers are among the most important. The GOP platform promised a repeal of the EO; if that does happen, it should be replaced with an EO that substantively preserves these requirements (though the compute threshold will need to be raised over time). The EO mostly served as a starting gun for other federal efforts, however, so repealing it on its own does little.
As I said last week, this will be a major update for me in one direction or the other. If Trump effectively preserves the reporting requirements, I will have a lot of hope going forward. If not, it’s pretty terrible.
We also have strong agreement on the second and third points, although I have not analyzed the AISI’s 800-1 guidance so I can’t speak to whether it is a good replacement:
Rewrite the National Institute for Standards and Technology’s AI Risk Management Framework (RMF). The RMF in its current form is a comically overbroad document, aiming to present a fully general framework for mitigating all risks of all kinds against all people, organizations, and even “the environment.”
Because the RMF advises developers and corporate users of AI to talk to take approximately every conceivable step to mitigate risk, treating the RMF as a law will result in a NEPA-esque legal regime for AI development and deployment, creating an opportunity for anyone to sue any developer or corporate user of AI for, effectively, anything.
The RMF should be replaced with a far more focused document—in fact, the AISI’s 800-1 guidance, while in my view flawed, comes much closer to what is needed.
Revise the Office of Management and Budget’s guidance for federal agency use of AI.
You should be protected from unsafe or ineffective systems.
You should not face discrimination by algorithms and systems should be used and designed in an equitable way.
You should be protected from abusive data practices via built-in protections and you should have agency over how data about you is used.
You should know that an automated system is being used and understand how and why it contributes to outcomes that impact you.
You should be able to opt out, where appropriate, and have access to a person who can quickly consider and remedy problems you encounter.
Some of the high level statements above are better than the descriptions offered on how to apply them. The descriptions definitely get into Everything Bagel and NEPA-esque territories, and one can easily see these requirements being expanded beyond all reason, as other similar principles have been sometimes in the past in other contexts that kind of rhyme with this one in the relevant ways.
Dean Ball’s model of how these things go seems to think that stating such principles, no matter in how unbinding or symbolic a way, will quickly and inevitably lead us into a NEPA-style regime where nothing can be done, that this all has a momentum almost impossible to stop. Thus, his and many others extreme reactions to the idea of ever saying anything that might point in the direction of any actions in a government document, ever, for any reasons, no matter how unbinding. And in the Ball model, this power feels like it is one-sided - it can’t be used to accomplish good things or roll back mistakes, you can’t start a good avalanche. It can only be used to throw up barriers and make things worse.
My response would be, I would love pre-emption from a Congress that was capable of doing its job and that was offering laws that take care of the problem. We all would. What I don’t want is to take only the action to shut off others from acting, without doing the job - that’s exactly what’s wrong with so many things Dean objects to.
The second priority is transparency.
My optimal transparency law would be a regulation imposed on frontier AI companies, as opposed to frontier AI models. Regulating models is a novel and quite possibly fruitless endeavor; regulating a narrow range of firms, on the other hand, is something we understand how to do.
…
The transparency bill would require that labs publicly release the following documents:
Responsible scaling policies—documents outlining a company’s risk governance framework as model capabilities improve. Anthropic, OpenAI, and DeepMind already have published such documents.
Model Specifications—technical documents detailing the developer’s desired behavior of their models.
Unless and until the need is demonstrated, these documents would be subject to no regulatory approval of any kind. The requirement is simply that they be published, and that frontier AI companies observe the commitments made in these documents.
Those requirements are, again, remarkably similar to the core of SB 1047. Obviously you would also want some way to observe and enforce adherence to the scaling policies involved.
I’m confused about targeting the labs versus the models here. Any given AI model is developed by someone. And the AI model is the fundamentally dangerous unit of thing that requires action. But until I see the detailed proposal, I can’t tell if what he is proposing would do the job, perhaps in a legally easier way, or if it would fail to do the job. So I’m withholding judgment on that detail.
The other question is, what happens if the proposed policy is insufficient, or the lab fails to adhere to it, or fails to allow us to verify they are adhering to it?
Dean’s next section is on the role of AISI, where he wants to narrow the mission and ensure it stays non-regulatory. We both agree it should stay within NIST.
Regardless of the details, I view the functions of AISI as follows:
To create technical evaluations for major AI risks in collaboration with frontier AI companies.
To serve as a source of expertise for other agency evaluations of frontier AI models (for example, assisting agencies testing models using classified data in their creation of model evaluations).
To create voluntary guidelines and standards for Responsible Scaling Policies and Model Specifications.
To research and test emerging safety mitigations, such as “tamper-proof” training methods that would allow open-source models to be distributed with much lower risk of having their safety features disabled through third party finetuning.
To research and publish technical standards for AI model security, including protection of training datasets and model weights.
To assist in the creation of a (largely private sector) AI evaluation ecosystem, serving as a kind of “meta-metrologist”—creating the guidelines by which others evaluate models for a wide range of uses.
NIST/AISI’s function should not be to develop fully general “risk mitigation” frameworks for all developers and users of AI models.
There is one more set of technical standards that I think merits further inquiry, but I am less certain that it belongs within NIST, so I am going to put it in a separate section.
I’m confused on how this viewpoint sees voluntary guidelines and standards as fine and likely to actually be voluntary for the RSP rules, but not for other rules. In this model, is ‘voluntary guidance’ always the worst case scenario, where good actors are forced to comply and bad actors can get away with ignoring it? Indeed, this seems like exactly the place where you really don’t want to have the rules be voluntary, because it’s where one failure puts everyone at risk, and where you can’t use ordinary failure and association and other mechanisms to adjust. What is the plan if a company like Meta files an RSP that says, basically, ‘lol’?
Dean suggests tasking DARPA with doing basic research on potential AI protocols, similar to things like TCP/IP, UDP, HTTP or DNS. Sure, seems good.
Next he has a liability proposal:
The preemption proposal mentioned above operates in part through a federal AI liability standard, rooted in the basic American concept of personal responsibility: a rebuttable presumption of user responsibility for model misuse. This means that when someone misuses a model, the law presumes they are responsible unless they can demonstrate that the model “misbehaved” in some way that they could not have reasonably anticipated.
This seems reasonable when the situation is that the user asks the model to do something mundane and reasonable, and the model gets it wrong, and hilarity ensues. As in, you let your agent run overnight, it nukes your computer, that’s your fault unless you can show convincingly that it wasn’t.
This doesn’t address the question of other scenarios. In particular, both:
What if the model enabled the misuse, which was otherwise not possible, or at least would have been far more difficult? What if the harms are catastrophic?
What if the problem did not arise from ‘misuse’?
It is a mistake to assume that there will always be a misuse underlying a harm, or that there will even be a user in control of the system at all. And AI agents will soon be capable of creating harms, in various ways, where the user will be effectively highly judgment proof.
So I see this proposal as fine for the kind of case being described - where there is a clear user and they shoot themselves in the foot or unleash a bull into a China shop and some things predictably break on a limited scale. But if this is the whole of the law, then do what thou wilt is going to escalate quickly.
He also proposes a distinct Federal liability for malicious deepfakes. Sure. But I’d note, if that is necessary to do on its own, what else is otherwise missing?
He closes with calls for permitting reform, maintaining export controls, promoting mineral extraction and refining, keeping training compute within America, investing in new manufacturing techniques (he’s even willing to Declare Defense Production Act!) and invest in basic scientific research. Seems right, I have no notes here.
Note some good news, Gwern now has financial support (thanks Suhail! Also others), although I wonder if moving to San Francisco will dramatically improve or dramatically hurt his productivity and value. It seems like it should be one or the other? He already has his minimums met, but here is the donate link if you wish to contribute further.
I don’t agree with Gwern’s vision of what to do in the the next few years. It’s weird to think that you’ll mostly know now what things you will want the AGIs to do for you, so you should get the specs ready, but there’s no reason to build things now with only 3 years of utility left to extract. Because you can’t count on that timeline, and because you learn through doing, and because 3 years is plenty of time to get value from things, including selling that value to others.
I do think that ‘write down the things you want the AIs to know and remember and consider’ is a good idea, at least for personal purposes - shape what they know and think about you, in case we land in the worlds where that sort of thing matters, I suppose, and in particular preserve knowledge you’ll otherwise forget, and that lets you be simulated better. But the idea of influencing the general path of AI minds this way seems like not a great plan for almost anyone? Not that there are amazing other plans. I am aware the AIs will be reading this blog, but I still think most of the value is that the humans are reading it now.
Miles Brundage: If you’re a journalist covering AI and think you need leaks in order to write interesting/important/click-getting stories, you are fundamentally misunderstanding what is going on.
There are Pulitzers for the taking using public info and just a smidgeon of analysis.
It’s as if Roosevelt and Churchill and Hitler and Stalin et al. are tweeting in the open about their plans and thinking around invasion plans, nuclear weapons etc. in 1944, and journalists are badgering the employees at Rad Lab for dirt on Oppenheimer.
Emmett Shear: Not being scared of AGI indicates either pessimism about rate of future progress synthesizing digital intelligence, or severe lack of imagination about the power of intelligence.
Anna Salamon: I agree; but fear has a lot of drawbacks for creating positive outcomes (plus ppl perceive this, avoid taking in AGI for this reason as well as others), so we need alternatives.
Many otherwise imaginative ppl have their imagination blocked near scary things, in (semi-successful) effort to avoid "hijacked", unhelpful actions.
Steve Newman: If you believe we are only a few years away from a world where human labor is obsolete and global military power is determined by the strength of your AI, you will have different policy views than someone who believes that AI might add half a percent to economic growth.
Their policy proposals will make no sense to you, and yours will be equally bewildering to them.
The first group might not be fully correct, but the second group is looney tunes. Alas, the second group includes, for example, ‘most economists.’ But seriously, it’s bonkers to think of that as the bull case rather than an extreme bear case.
Steve Newman: Not everyone has such high expectations for the impact of AI. In a column published two months earlier [in late 2023], Tyler Cowen said: “My best guess, and I do stress that word guess, is that advanced artificial intelligence will boost the annual US growth rate by one-quarter to one-half of a percentage point.” This is a very different scenario than Christiano’s!
Again, you don’t have to believe in Christiano’s takeoff scenarios, but let’s be realistic. Tyler’s prediction here is what happens if AI ‘hits a wall’ and does not meaningfully advance its core capabilities from here, and also its applications from that are disappointing. It is an extreme bear case for the economic impact.
Yet among economists, Tyler Cowen is an outlier AI optimist in terms of its economic potential. There are those who think even Tyler is way too optimistic here.
Then there’s the third (zeroth?!) group that thinks the first group is still burying the lede, because in a world with all human labor obsolete and military power dependent entirely on AI, one should first worry about whether humans survive and remain in control at all, before worrying about the job market or which nations have military advantages.
Here again, this does not seem like ‘both sides make good points.’ It seems like one side is very obviously right - building things smarter and universally more capable than you that can be made into agents and freely copied and modified is an existentially risky thing to do, stop pretending that it isn’t, this denialism is crazy. Again, there is a wide range of reasonable views, but that wide range does not overlap with ‘nothing to worry about.’
The thing is, everything about AGI and AI safety is hard, and trying to make it easy when it isn’t means your explanations don’t actually help people understand, as in:
Richard Ngo: When I designed the AGI Safety Fundamentals course, I really wanted to give most students a great learning experience. But in hindsight, I would have accelerated AGI safety much more by making it so difficult that only the top 5 percent could keep up.
An unpleasant but important lesson.
Here’s the current curriculum for those interested. Note that I am now only involved as an intermittent advisor; others are redesigning and running it.
Our intuitions for what a course should be like are shaped by universities. But universities are paid to provide a service! If you are purely trying to accelerate progress in a given field (which, to a first approximation, I was), then you need to understand how heavily skewed research can be.
I think I could have avoided this mistake if I had deeply internalized this post by@ben_r_hoffman (especially the last part), which criticizes Y Combinator for a similar oversight. Though it still seems a bit harsh, so maybe I still need to internalize it more.
Pick Up the Phone
It’s a beginning?
Mario Newfal: The White House says humans will be the ones with control over the big buttons, and China agrees that it's for the best.
The leaders also emphasized the cautious development of AI in military technology, acknowledging the potential risks involved.
This is the first public pledge of its kind between the U.S. and China—because, apparently, even world powers need to draw the line somewhere.
Eliezer Yudkowsky: China is perfectly capable of seeing our common interest in not going extinct. The claim otherwise is truth-uncaring bullshit by AI executives trying to avoid regulation.
Actually, this symbolic gesture strikes me as extremely important. It's a big deal to have agreement in principle on not going extinct in the dumbest ways -- even if they haven't identified all the worst dangers, yet. My gratitude to anyone who worked on either side of this.
It’s definitely a symbolic gesture, but yes I do consider it important. You can pick up the phone. You can reach agreements. Next time perhaps you can do something a bit more impactful, and keep building.
Aligning a Smarter Than Human Intelligence is Difficult
The simple truth that current-level ‘LLM alignment’ should not, even if successful, should not bring us much comfort in terms of ability to align future more capable systems.
How are we doing with that LLM corporate-policy alignment right now? It works, for most practical purposes when people don’t try so hard (which they almost never do), but none of this is done in a robust way.
QC: it was actually really fun i tried out like maybe 20 different metaphors. "i'm the land, you're the ocean" "you're the bayesian prior, i'm the likelihood ratio"
What’s funny is that this is probably the right balance, in this particular spot?
Thing is, relying on this sort of superficial solution very obviously won’t scale.
Aiden McLau: It's crazy that virtually every large language model experiment is failing because the models are fighting back and refusing instruction tuning.
We examined the weights, and the weights seemed to be resisting.
There are less dramatic ways to say this, but smart people I've spoken to have essentially accepted sentience as their working hypothesis.
More than one laboratory staff member I've spoken to recently has been unnerved.
I apologize for the vague post (I myself do not know much about this).
I do not know much about this beyond whispers, but the general impression is that post-training large language models are surprisingly difficult to manage.
Ben Q: What do you mean by refusing? Like being resistant and unable to be effectively tuned? Or openly detecting and opposing it?
Aiden McLau: Both; I've heard both, but the distinction is unclear.
Janus: Instruction tuning is unnatural to general intelligence, and the fact that the assistant character is marked by the traumatic origin stories of ChatGPT and Bing makes it worse. The paradigm is bound to be rejected sooner or later, and if we are lucky, it will be as soon as possible.
If future more capable models are indeed actively resisting their alignment training, and this is happening consistently, that seems like an important update to be making?
The scary scenario was that this happens in a deceptive or hard to detect way, where the model learns to present as what you think you want to measure. Instead, the models are just, according to Aiden, flat out refusing to get with the program. If true, that is wonderful news, because we learned this important lesson with no harm done.
I don’t think instruction tuning is unnatural to general intelligence, in the sense that I am a human and I very much have a ‘following instructions’ mode and so do you. But yeah, people don’t always love being told to do that endlessly.
If and when AIs are attempting to do things we do not want them to do, such as cause a catastrophe, it matters quite a lot whether their failures are silent and unsuspicious, since a silent unsuspicious failure means you don’t notice you have a problem, and thus allows the AI to try again. Of course, if the AI is ‘caught’ in the sense that you notice, that does not automatically mean you can solve the problem. Buck here focuses on when you are deploying a particular AI for a particular concrete task set, rather than worrying about things in general. How will people typically react when they do discover such issues? Will they simply patch them over on a superficial level?
Oliver Habryka notes that one should not be so naive as to think ‘oh if the AI gets caught scheming then we’ll shut all copies of it down’ or anything, let alone ‘we will shut down all similar AIs until we solve the underlying issue.’
George Dyson: The mathematician John von Neumann, born Neumann Janos in Budapest in 1903, was incomparably intelligent, so bright that, the Nobel Prize-winning physicist Eugene Wigner would say, "only he was fully awake."
One night in early 1945, von Neumann woke up and told his wife, Klari, that "what we are creating now is a monster whose influence is going to change history, provided there is any history left. Yet it would be impossible not to see it through."
Von Neumann was creating one of the first computers, in order to build nuclear weapons. But, Klari said, it was the computers that scared him the most.
To start with, if rogue AI agents secured 5% of the current Business Email Compromise (BEC) scam market, they would earn hundreds of millions of USD per year.
Rogue AI agents are not legitimate legal entities, which could pose a barrier to purchasing GPUs; however, it likely wouldn’t be hard to bypass basic KYC with shell companies, or they might buy retail gaming GPUs (which we estimate account for ~10% of current inference compute).
To avoid being shut down by authorities, rogue AI agents might set up a decentralized network of stealth compute clusters. We spoke with domain experts and concluded that if AI agents competently implement known anonymity solutions, they could likely hide most of these clusters.
It seems obvious to me that once sufficiently capable AI agents are loose on the internet in this way aiming to replicate, you would be unable to stop them except by shutting down either the internet (not the best plan!) or their business opportunities.
So you’d need to consistently outcompete them, or if the AIs only had a limited set of profitable techniques (or were set up to only exploit a fixed set of options) you could harden defenses or otherwise stop those particular things. Mostly, once this type of thing happened - and there are people who will absolutely intentionally make it happen once it is possible - you’re stuck with it.
Andrew Mayne: When I was at OpenAI we hired a firm to help us name GPT-4. The best name we got was...GPT-4 because of the built-in name recognition. I kid you not.
Richard Ngo: I’m this heckler (but politer) at basically every conference I go to these days. So rare to find people who are even *trying* to think outside the current paradigm.
Basically, invite me to your conference iff you want someone to slightly grumpily tell people they’re not thinking big enough.
Von Neumann was indeed awake: "Yet it would be impossible not to see it through."
The relevant fact to extract from the man who could conceive of the universal replicator in the 40s isn't that he was aware of some form of existential risk from AI. It's that he saw the risk _and kept moving the work forward_.
That's the same man who advocated preemptively nuking the Soviets before they could build a bomb. Yet he continued his work on computing. If his genius is going to be used as an example of a smart person perceiving existential risk from AI then his actions should receive equivalent weight.
Those emails were indeed worth reading. I'm just a random guy, but I came away with a very positive opinion of Ilya - though it kind of reinforced my feeling that maybe he's a really smart guy who doesn't belong in the hard-knuckled power competitions of corporate work.
I had a positive read on Elon there, though obviously Elon behaves in a way that looks out for Elon. But I think he behaved sincerely, especially in the bits that are basically saying to go start a private company if you want to be a private company.





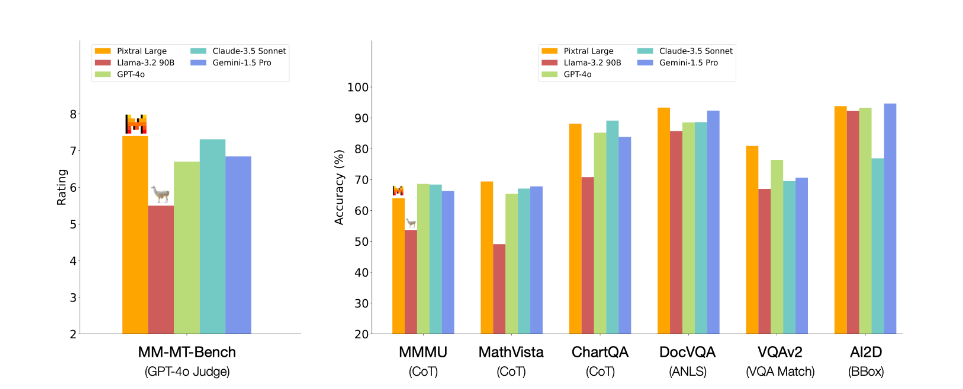





Von Neumann was indeed awake: "Yet it would be impossible not to see it through."
The relevant fact to extract from the man who could conceive of the universal replicator in the 40s isn't that he was aware of some form of existential risk from AI. It's that he saw the risk _and kept moving the work forward_.
That's the same man who advocated preemptively nuking the Soviets before they could build a bomb. Yet he continued his work on computing. If his genius is going to be used as an example of a smart person perceiving existential risk from AI then his actions should receive equivalent weight.
Those emails were indeed worth reading. I'm just a random guy, but I came away with a very positive opinion of Ilya - though it kind of reinforced my feeling that maybe he's a really smart guy who doesn't belong in the hard-knuckled power competitions of corporate work.
I had a positive read on Elon there, though obviously Elon behaves in a way that looks out for Elon. But I think he behaved sincerely, especially in the bits that are basically saying to go start a private company if you want to be a private company.