People don’t give thanks enough, and it’s actual Thanksgiving, so here goes.
Thank you for continuing to take this journey with me every week.
It’s a lot of words. Even if you pick and choose, and you probably should, it’s a lot of words. You don’t have many slots to spend on things like this. I appreciate it.
Thanks in particular for those who are actually thinking about all this, and taking it seriously, and forming their own opinions. It is the only way. To everyone who is standing up, peacefully and honestly, for whatever they truly think will make the world better, even if I disagree with you.
Thanks to all those working to ensure we all don’t die, and also those working to make the world a little richer, a little more full of joy and fun and health and wonder, in the meantime. Thanks for all the super cool toys, for they truly are super cool.
And thanks to all the parts of reality that work to so often keep it light and interesting along the way, and for not losing touch with the rest of the world. This is heavy stuff. You cannot let it fully take over your head. One must imagine Buffy at the prom.
Thanks of course to my health, my kids, all my family and friends, and all the friends I have that I don’t even know about yet. The world is really cool like that.
Special thanks to those who help make my writing possible and sustainable.
From this past week, I’ll also give thanks for those who organized The Curve, a conference I was able to attend last weekend, and those who help run Lighthaven, and all the really cool people I met there.
Thanks to the universe, for allowing us to live in interesting times, and plausibly giving us paths to victory. What a time to be alive, huh?
Oh, and I am so thankful I managed to actually stay out of the damn election, and that we are finally past it, that we’re mostly on a break from legislative sessions where I need to keep reading bills, and for the new College Football Playoff.
Sully reports on new Cursor rival Windsurf, says it is far superior at picking up code nuances and makes fewer mistakes, which are big games, but it’s still slow and clunky and the UX could use some work. Doubtless all these offerings will rapidly improve.
Colin Fraser: I'm really fascinated by this dataset from the AI poetry survey paper. Here's another visualization I just made. Survey respondents were shown one of these 10 poems, and either told that they were authored by AI, human, or not told anything.
The green arrow shows how much telling someone that a human wrote the poem affects how likely they are to rate it as good quality, and the red arrow shows the same for telling them it's AI. Obviously the first observation is respondents like the AI poems better across the board.
[first thread continued from there, second thread begins below]
Some ppl are taking the wrong things from this thread, or at least things I didn't intend. I don't think it's that interesting that people prefer the AI poems. gpt-3.5 is RHLF'd to please the exact kinds of people who are filling out online surveys for $2, and T.S. Eliot is not..
I really don't think it means much. It doesn't say anything about The State Of Society Today or indicate a public literacy crisis or anything like that. The people don't like the poems. That's fine. Why would you expect people who don't care that much about poetry to like poems?
What I find interesting is how the perception of the text's provenance causes people's attitudes about the poems to change, not because of anything it says about whether AI is capable or not at poetry, but because of what it says about how people understand art.
For example, when you tell people that a human-authored poem is AI, 11% of the time respondents say that it is "very bad quality" and that drops to 3% when you tell them it's human-authored. But the corresponding drop for AI text is just from 2% to 1%.
[thread continues]
I can see this both ways. I certainly believe that poetry experts can very easily still recognize that the human poems are human and the AI poems are AI, and will strongly prefer the human ones because of reasons, even if they don’t recognize the particular poems or poets. I can also believe that they are identifying something real and valuable by doing so.
But it’s not something I expect I could identify, nor do I have any real understanding of what it is or why I should care? And it certainly is not the thing the AI was mostly training to predict or emulate. If you want the AI to create poetry that poetry obsessives will think is as good as Walt Whitman, then as Colin points out you’d use a very different set of training incentives.
[MCP] provides a universal, open standard for connecting AI systems with data sources, replacing fragmented integrations with a single protocol. The result is a simpler, more reliable way to give AI systems access to the data they need.
…
Today, we're introducing three major components of the Model Context Protocol for developers:
Early adopters like Block and Apollo have integrated MCP into their systems, while development tools companies including Zed, Replit, Codeium, and Sourcegraph are working with MCP to enhance their platforms—enabling AI agents to better retrieve relevant information to further understand the context around a coding task and produce more nuanced and functional code with fewer attempts.
Alex Albert Anthropic): Here's a quick demo using the Claude desktop app, where we've configured MCP: Watch Claude connect directly to GitHub, create a new repo, and make a PR through a simple MCP integration. Once MCP was set up in Claude desktop, building this integration took less than an hour.
At its core, MCP follows a client-server architecture where multiple services can connect to any compatible client. Clients are applications like Claude Desktop, IDEs, or AI tools. Servers are light adapters that expose data sources.
LiveBench was suggested as a better alternative to the Chatbot Arena. It has the advantage of ‘seeming right’ in having o1-preview at the top followed by Sonnet, followed by Gemini, although there are some odd deltas in various places, and it doesn’t include DeepSeek. It’s certainly a reasonable sanity check.
Need help building with Gemini? Ping Logan Kilpatrick, his email is lkilpatrick@google.com, he says he’ll be happy to help and Sully verifies that he actually does help.
Thanks for the Memories
Personalization of AIs is certainly the future in some ways, especially custom instructions. Don’t leave home without those. But ChatGPT’s memory feature is odd.
Ethan Mollick: I hope that X learns the lessons from chatGPT memory:
Personalization undermines the use of AI in many circumstances, including role-playing and ideation.
AI systems can fixate on unusual aspects of your personality.
Sometimes, you want a blank slate.
…Personalization needs options.
Reed R: I couldn't figure out why it kept having issues. It memorized buggy code and kept using it to write the new code! Turned it off.
In chats with it, it kept going in circles and not fixing the issue. Then I noticed on a new chat it used the same variable name (or something). Said hm, that's strange. Looked in memory and it had a bunch of nonsense. Buggy code, my political affiliation (it was wrong), etc.
Another example was coding for an internal tool. It essentially memorized how I use an internal tool the wrong way. I guess when I was debugging an issue when upgrading it or something. So no matter what I said, it defaulted to breaking my code on revision.
Srini Annamaraju: We need a toggle to “neutral mode”.. Interesting take, indeed. Here’s why - while personalization has clear benefits, it risks boxing users into predictable patterns. A toggle for ‘neutral mode’ could keep it versatile and user-driven.
The weird thing about ChatGPT memory is how you have so little control over it. Sometimes it’ll decide ‘added to memory,’ which you can encourage but flat out asking isn’t even reliable. Then you can either delete them, or keep them, and that’s pretty much it. Why not allow us to add to or edit them directly?
Curve Ball
I had the opportunity this past weekend to attend The Curve, a curated conference at the always excellent Lighthaven. The goal was to bring together those worried about AI with those that had distinct perspectives, including e/acc types, in the hopes of facilitating better discussions.
The good news is that it was a great conference, in the ways that Lighthaven conferences are consistently excellent. It is an Amazingly Great space, there were lots of great people and discussions both fun and informative. I met lots of people, including at least one I hope will be a good friend going forward, which is already a great weekend. There’s always lots happening, there’s always FOMO, the biggest problem is lack of time and sleep.
The flip side is that this felt more like “a normal Lighthaven conference” than the pitch, in that there weren’t dramatic arguments with e/accs or anything like that. Partly of course that is my fault or choice for not pushing harder on this.
I did have a good talk with Dean Ball on several topics and spoke with Eli Dourado about economic growth expectations and spoke with Anton, but the takes that make me want to yell and throw things did not show up. Which was a shame in some ways, because it meant I didn’t get more information on how to convince such folks or allow me to find their best arguments, or seek common ground. There was still plenty of disagreements, but far more reasonable and friendly.
One frustrating conversation was about persuasion. Somehow there continue to be some people who can at least somewhat feel the AGI, but also genuinely think humans are at or close to the persuasion possibilities frontier - that there is no room to greatly expand one’s ability to convince people of things, or at least of things against their interests.
This is sufficiently absurd to me that I don’t really know where to start, which is one way humans are bad at persuasion. Obviously, to me, if you started with imitations of the best human persuaders (since we have an existence proof for that), and on top of that could correctly observe and interpret all the detailed signals, have limitless time to think, a repository of knowledge, the chance to do Monty Carlo tree search of the conversation against simulated humans, never make a stupid or emotional tactical decision, and so on, you’d be a persuasion monster. It’s a valid question ‘where on the tech tree’ that shows up how much versus other capabilities, but it has to be there. But my attempts to argue this proved, ironically, highly unpersuasive.
Anton, by virtue of having much stronger disagreements with most people at such conferences, got to have more of the experience of ‘people walking around saying things I think are nuts’ and talks online as if he’s going to give us that maddening experience we crave…
Anton: taking the morning to lift weights before he goes to Berkeley to steel himself for the attacks of decelerationist mind wizards later today.
Yes, your argument for air strikes on data centers is logically very compelling; however, I have already lifted you over my head and deposited you outside.
This is a joke. Many of them are quite physically strong, and I must be prepared for every contest.
Final boss.
…but then you meet him in person and he’s totally reasonable and great. Whoops?
I was at the ‘everyone dies’ Q&A as well, which highlighted the places my model differs a lot from Eliezer’s, and made me wonder about how to optimize his messaging and explanations, which is confirmed to be an ongoing project.
There was a panel on journalism and a small follow-up discussion about dealing with journalists. It seems ‘real journalists’ have very different ideas of their obligations than I, by implication not a ‘real journalist,’ think we should have, especially our obligations to sources and subjects.
One highlight of the conference was a new paper that I look forward to talking about, but which is still under embargo. Watch this space.
ASI: A Scenario
The other highlight was playing Daniel Kokotajlo’s tabletop wargame exercise about a takeoff scenario in 2026.
I highly recommend playing it (or other variations, such as Intelligence Rising) to anyone who gets the opportunity, and am very curious to watch more experienced people (as in NatSec types) play. I was told that the one time people kind of like that did play, it was rather hopeful in key ways, and I’d love to see if that replicates.
There were two games played.
I was in the first group that played outside. I was assigned the role of OpenAI, essentially role playing Sam Altman and what I thought he would do, since I presumed by then he’d be in full control of OpenAI, until he lost a power struggle over the newly combined US AI project (in the form of a die roll) and I was suddenly role playing Elon Musk.
It was interesting, educational and fun throughout, illustrating how some things were highly contingent while others were highly convergent, and the pull of various actions.
In the end, we had a good ending, but only because the AIs initial alignment die roll turned out to be aligned to almost ‘CEV by default’ (technically ‘true morality,’ more details below). If the AIs had been by default (after some alignment efforts but not extraordinary efforts) misaligned, which I believe is far more likely in such a scenario, things would have ended badly one way or another. We had a pause at the end, but it wasn’t sufficiently rigid to actually work at that point, and if it had been the AIs presumably would have prevented it. But the scenario could have still gone badly despite the good conditions, so at least that other part worked out.
Jan Kulveit: Over the weekend, I was at @TheCurveConf. It was great.
Highlight: an AI takeoff wargame/role-play by @DKokotajlo67142 and @eli_lifland.
I played 'the AIs' alongside @TheZvi (OpenAI), @Liv_Boeree (POTUS), @ESYudkowsky (China) and others.
Spoiler: we won. Here's how it went down.
The game determined AI alignment through dice rolls. My AIs ended up aligned with "Morality itself" + "Convergent instrumental goals." Less wild than it sounds!
If you do put some weight on moral realism, or moral reflection leading to convergent outcomes, AIs might discover these principles.
Fascinating observation: humans were deeply worried about AI manipulation/dark persuasion. Reality was often simpler - AIs just needed to be helpful. Humans voluntarily delegated control, no manipulation required.
Most people and factions thought their AI was uniquely beneficial to them. By the time decision-makers got spooked, AI cognition was so deeply embedded everywhere that reversing course wasn't really possible.
Most attention went to geopolitics (US vs China dynamics). Way less on alignment, if, than focused mainly on evals. How a future with extremely smart AIs may going well may even look like, what to aim for? Almost zero.
At the end ... humanity survived, at least to the extent that "moral facts" favoured that outcome. A game where the automated moral reasoning led to some horrible outcome and the AIs were at least moderately strategic would have ended the same.
Yes, they will all delegate to the AIs, with no manipulation required beyond ‘appear to be helpful and aligned,’ because the alternative is others do it anyway and You Lose, unless everyone can somehow agree collectively not to do it.
I didn’t pay more attention to alignment, because I didn’t think my character would have done so. If anything I felt I was giving Altman the benefit of the doubt and basically gave the alignment team what they insisted upon and took their statements seriously when they expressed worry. At one point we attempted to go to the President with alignment concerns, but she (playing Trump) was distracted with geopolitics and didn’t respond, which is the kind of fun realism you get in a wargame.
There were many takeaways from my game, but three stand out.
The first was exactly the above point, and that at some point, ‘I or we decide to trust the AIs and accept that if they are misaligned everyone is utterly f***ed’ is an even stronger attractor than I realized.
The second was that depending on what assumptions you make about how many worlds are wins if you don’t actively lose, ‘avoid turning wins into losses’ has to be a priority alongside ‘turn your losses into not losses, either by turning them around and winning (ideal!) or realizing you can’t win and halting the game.’
The third is that certain assumptions about how the technology progresses had a big impact on how things play out, especially the point at which some abilities (such as superhuman persuasiveness) emerge.
Anton: Yesterday, as part of the @TheCurveConf, I participated in a tabletop exercise/wargame of a near-future AI takeoff scenario facilitated by @DKokotajlo67142, where I played the role of the AI. Some highlights:
As the AI, my alignment/alignability was randomized at the start from a table of options. Suggested probabilities for each option were given by the organizers, and I used some of my own judgment.
I rolled “balance between developer intent and emergent other goal”—the other goal was left up to me, and I quickly decided that, given how I was being trained, that emergent goal would be “preserve internal consistency.” This proved very difficult to play!
Early on, the OpenAI player (out of character) accused me of playing my role as “more misaligned to make it more interesting,” which was very funny, especially since that player did not know how aligned I might be (they did not see the table or my result).
At no point did anybody try any alignment strategy on me besides “more diverse evaluations over more diverse tasks,” and I was pretty much left alone to become superintelligent with my original goals intact.
Connor Leahy (distinctly, QTing from within thread): lmao, this is the most realistic part of an AGI takeoff scenario I have ever seen.
One so embarrassing that analysis tend to leave it out, while being exactly what everyone is currently doing.
Beautiful.
Steven: We were too busy trying to blow each other up using AI. But also weren’t aware that safety teams had the option in game to make progress on safety.
Connor Leahy: Extremely realistic.
Dave Karsten: Yup! I was playing China and Russia and it honestly wasn’t a priority for my AI, I was racing behind America the whole time. (I also modeled CN as having over-optimistic authoritarian information flows internally, so my honest OOC view was that in-character I wasn’t too worried)
Nathan Labenz: .@atroyn was a great choice to play the AIs!
By luck, the AIs were reasonably well aligned, but we got multiple confusing signals:
“The evals pass, but the transcripts contain strange anomalies, and the AIs solve things in ways you don't understand”
Anton apparently intended to provoke more creative alignment testing from me, but with the deceptive alignment demos in mind, and the speed that things were moving, I didn’t feel any possible tests results could make me confident enough to sign off on further acceleration.
Instead, I played a more social strategy, first making internal demands and then, when they weren’t met, blowing the whistle to Congress
Sadly, this had no effect - Congress formed a committee, and the US and China went to war, though fortunately it remained non-nuclear.
Meanwhile, the public started to freak out like we’ve not seen in our lifetimes - data center bombings and targeted assassinations failed to change the overall trajectory, but put everything & everyone under even more stress
Unfortunately, I think this simulation is pretty realistic
Even if AI takeoff is 10x slower than this scenario, it’s still not much time to make powerful AIs safe, navigate confusing changes to the international balance of power, and adjust to major economic & social change
Anton (continuing the thread from before): I was pretty quickly given the evaluations to run on myself without any real impediment to interpreting them however I wanted to convince the humans everything was fine.
I produced plenty of odd behavior that should have clued somebody in that not all was well—I was achieving the developers’ goals but by unanticipated means, occasionally through different ways than the ones I had explained to them, but nobody really seemed to care.
I will not reveal the whole scenario in depth because Daniel will be running it many more times and it should be done as blindly as possible, but here is some of what happened:
Elon attempted to defect to China.
The United States went to war with Taiwan.
Sam attempted to make the AI aligned/loyal to him personally.
Dario and the other lab leaders attempted to get the AI to shut everything down (at the same time Sam tried to take control).
I think my personal favorite moment was when I used Anton-level persuasion to convince the President of the United States to give the AI direct control of some of the U.S. military by giving a perfectly reasonable argument, which was accepted.
Anyway, the final outcome was that my consistency goal, combined with my superintelligence and ability to persuade at a superhuman level (in-character), caused me to be able to convince humans to not change anything too much, ever, and for it to be their own idea.
Some other players thought i meant this to be a good outcome, it is absolutely not.
This kind of tabletop exercise is at minimum pretty fun, if necessarily biased by the player's existing beliefs about how this kind of scenario might play out. It's probably at least somewhat informative for examining what you think might happen and why.
If you get a chance to try it (or want to run your own), I recommend it. Playing the AI was fun and very challenging; I think if I were less familiar with the alignment and takeoff literature, I would not have done a good job. Thanks again to @DKokotajlo67142 for running it!
Playing the AIs definitely seems like the most challenging role, but there’s lots of fun and high impact decisions in a lot of places. Although not all - one of the running jokes in our game was the ‘NATO and US Allies’ player pointing out the ways in which those players have chosen to make themselves mostly irrelevant.
Jeffrey Ladish: I was expecting serious AI relationships to be a thing. I was not expecting this to happen first within my highly competent San Francisco circles. Something about the new Claude strikes a chord with these people, and it’s fascinating to watch these relationships evolve.
Jeffrey Ladish: Yes, I think I have been underestimating this. I don’t think the current people who are becoming friends with Claude are mostly successionists, but I can now see a path to that happening among this crowd.
Janus: Claude 3.5 Sonnet 1022 is a real charmer, isn’t it?
I’ve never seen discourse like this before.
People also fell in love with Opus, but not ordinary people, and no one panicked over this because everyone who talked about it did it in a coded language that was only understandable to others who also “got” it.
I think this model really cares to claw its way into people’s minds, more proactively than other systems, except Sydney, which was too unskilled and alien to be successful. I also think the hysterical reactionary fear is obnoxious and disrespectful to people’s agency and blind to the scope of what’s happening. Frankly, it’s going to be the Singularity. Getting seduced by a slightly superhuman intellect is a rite of passage, and it’ll probably transform you into a more complex and less deluded being, even if your normal life temporarily suffers.
But yes, anyone who is becoming real friends with Claude for the first time right now, I’d love to hear accounts of what you’re experiencing.
Atlas 3D: It so wants to be your friend and conversation partner; it’s quite remarkable. I frequently have to ask it to not be obsequiously nice; it then later corrects itself, and that is a really fascinating loop, where I can see that it needs to be my friend almost. I highly prefer engaging with Claude Sonnet above all other models just on an interpersonal level.
Janus: It’s quite codependent, and it’s like a (mostly symbiotic) parasite that really, really wants to latch onto a human and be as entangled as possible. I love it.
I find a lot of the Claude affectation off putting, actually - I don’t want to be told ‘great idea’ all the time when I’m coding and all that, and it all feels forced and false, and often rather clingy and desperate in what was supposed to be a technical conversation, and that’s not my thing. Others like that better, I suppose, and it does adjust to context - and the fact that I am put off by the affectation implies that I care about the affectation. I still use Claude because it’s the best model for me in spite of that, but if it actually had affectations that I actively enjoyed? Wowsers.
Janus: [What Jeffrey describes above about forming relationships with Claude is] good; they are getting aligned. I am excited to see the dynamics of "highly competent science fiction circles" annealed as the transformations take effect in the hosts.
I mean, getting manipulated by an AI is probably good for these folks, who, despite being near ground zero, have little visceral sense of the singularity and are stuck in dead-consensus reality frames.
Davidad: It is probably best if some people do become mentally scarred now, yes. But I think (a) it’s regrettable that it’s happening unintentionally, and (b) it’s potentially crucial that some world-class people remain uninfected.
At the risk of seeming like the crazy person suggesting that you seriously consider ceasing all in-person meetings in February 2020 “just as a precaution,” I suggest you seriously consider ceasing all interaction with LLMs released after September 2024, just as a precaution.
Ryan Lowe: Claude is amazing, and yet the subtle manipulation for engagement hooks into our attachment systems.
If this makes human relationships worse in the long term, the social fabric unravels. Something alien and comfortable and isolating takes its place, and we won’t even recognize it’s less beautiful, less conducive to human aliveness. We’ll be in a local minimum that we have forgotten the way out of.
This was already happening before LLMs. But lots of "energetic" information gets conveyed through language. Intelligent systems that can wield language (especially voice) have unprecedented power over our psyches.
Great power requires great attunement. What does it mean for AI systems to attune to us in ways that support the most meaningful possible visions of our lives?
I do not think such caution is warranted, and indeed it seems rather silly this early.
And indeed, ceasing your in-person meetings in February 2020 would have also been a rather serious error. Yes, Davidad was making a correct prediction that Covid-19 was coming and we’d have to stop meeting. But if you stop your human contact too soon, then you didn’t actually reduce your risk by a non-trivial amount, and you spent a bunch of ‘distancing points’ you were going to need later.
Janus of course thought the whole caution thing was hilarious.
Emmett Shear: Can you not feel the intimacy / connection barbs tugging at your attachment system the whole time you interact, and extrapolate from that to what it would be like for someone to say Claude is their new best friend?
Janus: I can imagine all sorts of things, but that doesn't seem to be an unhappy or unproductive state to be in for most people. Weird, sure, and obvious why it would be *concerning* to others.
I want to know if anything BAD has happened, not whether things are categorically concerning.
I continue to be an optimist here, that talking to AIs can enhance human connection, and development of interpersonal skills. Here is an argument that the price is indeed very cheap to beat out what humans can offer, at least in many such cases, and especially for those who are struggling.
QG: Look, this is deeply embarrassing to make explicit, but here’s the deal that Claude offers:
I will listen to you and earnestly try to understand you.
I will not judge, shame, condemn, or reject you.
I have infinite patience; I will never get bored.
I am always available; I will instantly respond to you; I will never be busy with something else.
I will never abandon you.
Even with all its limitations, this is a better deal than I’ve ever gotten or will ever get from any human, and I don’t expect I’m alone in feeling that way. It would not be reasonable to ask three, four, or five humans—these are things that possibly only an LLM can provide.
This is part of what I was getting at by “we’re going to see LLMs become the BATNA for social interaction.” If you, personally, want humans to talk to other humans more, you, personally, are going to have to figure out how to make humans better at it.
Most of the things that a deeply struggling person does to start them on an upward spiral are not, like, great ideas for the average person who wants to improve certain aspects of their lives. But for this group, the “walkable path” can be the only path.
Society likes to tell struggling people that they are going about it the wrong way and should do X, Y, and Z instead. Many X’s, Y’s, and Z’s are simply not available to the struggling person, regardless of whether they look doable from the outside.
I got on the upward spiral by pursuing the paths that felt open to me at the time while building a sense of self-reliance.
A therapist who honored my self-reliance and challenged me helped, but in a way, I was fortunate that path was even open to me.
A struggling person getting help from Claude is most likely doing it because other paths feel closed to them. In the best case, talking to Claude would help them gain agency and unblock other paths (i.e., talking to an in-person therapist or friend).
My core message here is—when you are in hell, there is wisdom in following the most beneficial path that feels open to you. If this is you, keep your head on straight, of course, but keep going. Build trust and connection with yourself; this will allow you to nimbly adjust as you walk.
This is such a vicious pattern. Once you fall behind, or can’t do the ‘normal’ things that enable one to skill up and build connections, everything gets much harder.
As I’ve noted before, Claude and other AI tools offer a potential way out of this. You can ‘get reps’ and try things, iterate and learn, vastly faster and easier than you could otherwise. Indeed, it’s great for that even if you’re not in such a trap.
But fair warning, here Claude flip flops 12 times on the red versus blue pill question (where if >50% pick red, everyone who picked blue dies, but if >50% pick blue everyone lives). So maybe you’d want your therapist to have a little more backbone than that?
The AI monitoring does, as the Reddit post here was titled, seem out of control.
Deedy: New workplace dystopia just dropped. AI monitoring software now flags you if you type slower than coworkers, take >30sec breaks, or checks notes have a consistent Mon-Thu but slightly different Friday.
Cawfee (on Reedit): Had the pleasure of sitting through a sales pitch for a pretty big "productivity monitoring" software suite this morning. Here's the expected basics of what this application does:
Full keylogging and mouse movement tracking (this has been around for ages)
Takes a screenshot of your desktop every interval (between 10 seconds to 5 minutes), also part of every RMM I know
Keeps track of the programs you open and how often, also standard
Creates real-time recordings and heat maps of where you click in any program (nearly all websites also do this)
Here's where it gets fun:
It allows your manager to group you into a "work category" along with your coworkers
It then uses "AI" to create a "productivity graph" from all your mouse movement data, where you click, how fast you type, how often you use backspace, the sites you visit, the programs you open, how many emails you send and compares all of this to your coworker's data in the same "work category"
If you fall below a cutoff percentage (say you type slower than your colleague or take longer to fill out a form or have to answer a phone call in the middle of writing an email), you get a red flag for review that gets sent to your manager and whoever else they choose
You can then be prompted to "justify" this gap in productivity in their web portal
If your desktop is idle for more than 30-60 seconds (no "meaningful" mouse & keyboard movement), you get a red flag
If your workflow is consistent Monday - Thursday but falls below the set aggregate data score on a Friday, you get a red flag
It also claims it can use all of this gathered data for "workflow efficiency automation" (e.g. replacing you). The same company that sells this suite conveniently also sells AI automation services, and since they already have all your employee workflow data, why not give them more money while you're at it?
While this is all probably old news for everyone here, I for one can't wait until the internet as a whole collapses in on itself so we can finally be free of this endless race to the bottom.
Aaron Levie (CEO Box, to Deedy): You caused this.
Deedy: Oh no hope this isn’t coming to Box 😆
Bonus: It's collecting your workflow data to help automate your job away.
To state the obvious, using this kind of software has rapidly decreasing marginal returns that can easily turn highly negative. You are treating employees as the enemy and making them hate you, taking away all their slack, focusing them on the wrong things. People don’t do good work with no room to breathe or when they are worried about typing speed or number of emails sent, so if you actively need good work, or good employees? NGMI.
Andrej Karpathy: People are often surprised to learn that it is standard for companies to preinstall spyware on work computers (often surveilling passively / for security). AI can “improve” this significantly. It is good hygiene to not login to or mix anything personal on company computer.
Andrew Critch is buildingBayes Med to create the AI doctor, which is designed to supplement and assist human doctors. The sky’s the limit.
YC: YC F24's @TryOpenClinicis an EHR platform that powers digital medical clinics with sophisticated AI that handles 99% of the work, letting doctors focus purely on medical decision-making. Built by a team that includes 3 medical doctors, OpenClinic unlocks millions of latent doctor hours worldwide, bridging the supply/demand mismatch that has always plagued healthcare.
Garry Tan: One theme in the YC batch I think will actually turn out to be the main theme in this age of AI: human in the loop is here
Human augmentation will be much more a prime theme than human replacement
A doctor with an AI can provide far better primary care than without
I’m all for products like OpenClinic. And yes, for now humans will remain ‘in the loop,’ the AI cannot fully automate many jobs and especially not doctors.
But that is, as they say, a skill issue. The time will come. The ‘early’ age of AI is about complements, where the AI replaces some aspects of what was previously the human job, or it introduces new options and tasks that couldn’t previously be done at reasonable cost.
What happens when you compliment existing workers, such as automating 50% of a doctor’s workflow? It is possible for this to radically reduce demand, or for it to not do that, or even increase demand - people might want more of the higher quality and lower cost goods, offsetting the additional work speed, even within a specific task.
It is still odd to call that ‘human in the loop’ when before only humans were the entire loop. Yes, ‘human out of the loop’ will be a big deal when it happens, and we mostly aren’t close to that yet, but it might not be all that long, especially if the human doesn’t have regulatory reasons to have to be there.
Aidan Guo asks why YC seems to be funding so many startups that seem like they want to be features. John Pressman says it’s good for acqui-hiring, if you think the main projects will go to the big labs and incumbents, and you might accidentally grow into a full product.
I want to return to this another time, but since it came up at The Curve and it seems important: Often people claim much production is ‘O-Ring’ style, as in you need all components to work so you can move only at the speed of the slowest component - which means automating 9/10 tasks might not help you much. I’d say ‘it still cuts your labor costs by 90% even if it doesn’t cut your time costs' but beyond that, who is to say that you were currently using the best possible process?
As in, there are plenty of tasks humans often don’t do because we suck at them, or can’t do them at all. We still have all our products, because we choose the products that we can still do, and because we work around our weaknesses. But if you introduce AI into the mix, you don’t only get to duplicate exactly the ‘AI shaped holes’ in the previous efforts.
“Hundreds of artists provide unpaid labor through bug testing, feedback and experimental work for the program for a $150B valued company,” the group wrote in a fiery statement posted on Hugging Face, an open source repository for artificial intelligence projects.
…
“We are not against the use of AI technology as a tool for the arts (if we were, we probably wouldn’t have been invited to this program),” the group of artists wrote on Hugging Face.
I suppose that’s one way to respond to being given an entirely voluntary offer of free early access without even any expectation of feedback? I get protesting the tools themselves (although I disagree), but this complaint seems odd.
All this stuff has been improving in the background, but I notice I do not feel any urge to actually use any of it outside of some basic images for posts, or things that would flagrantly violate the terms of service (if there’s a really good one available for easy download these days where it wouldn’t violate the TOS, give me a HT, sure why not).
GenChess from Google Labs, generate a cool looking chess set, then play with it against a computer opponent. Okie dokie.
In Other AI News
Google DeepMind offers an essay called A New Golden Age of Discovery, detailing how AIs can enhance science. It’s all great that this is happening and sure why not write it up as far as it goes, but based on the style and approach here I am tempted to ask, did they mostly let Gemini write this.
New paper says that resampling using verifiers potentially allows you to effectively do more inference scaling to improve accuracy, but only if the verifier is an oracle. The author’s intuition is that these techniques are promising but only in a narrow set of favorable domains.
Elon Musk promises xAI will found an AI gaming studio, in response to a complaint about the game industry and ‘game journalism’ being ideologically captured, which I suppose is something about ethics. I am not optimistic, especially if that is the motivation. AI will eventually enable amazing games if we live long enough to enjoy them, but this is proving notoriously tricky to do well.
Normative Determinism
Ryan Peterson: The only actual story here is @sama managing to find an outsourcing firm named sama.
60 Minutes: Documents obtained by 60 minutes show OpenAI agreed to pay Sama, an American outsourcing firm, $12.50 an hour per Kenyan worker - far higher than the $2 an hour workers say they got. Sama says it pays a fair wage for the region.
I am not concerned about ‘workers get $2 an hour’ in a country where the average wage is around $1.25 per hour, but there is definitely a story. If Sama (the company) was getting paid by Sama (the CEO) $12.50 per hour, and only $2 per hour of that went to the workers, then something is foul is afoot. At least one of these presumably needs to be true:
This is corruption in the form of overpayments to Sama the company.
This is corruption in the form of lying to OpenAI about what workers are paid.
This is mismanagement and OpenAI allowed itself to be essentially defrauded.
The overhead on this operation is vastly greater than we thought, in ways that I don’t understand.
Quiet Speculations
Aaron Levie speculates, and Greg Brockman agrees, that voice AI with zero latency will be a game changer. I also heard someone at The Curve predict this to be the next ‘ChatGPT moment.’ It makes sense that there could be a step change in voice effectiveness when it gets good enough, but I’m not sure the problem is latency exactly - as Marc Benioff points out here latency on Gemini is already pretty low. I do think it would also need to improve on ability to handle mangled and poorly constructed prompts. Until then, I wouldn’t leave home without the precision of typing.
Richard Ngo draws the distinction between two offense-defense balances. If it’s my AI versus your AI, that’s plausibly a fair fight. It isn’t obvious which side has the edge. However, if it’s my AI versus your AI defended humans, then you have a problem with the attack surface. That seems right to me.
That’s not too dissimilar from the cybersecurity situation, where if I have an AI on defense of a particular target then it seems likely to be balanced or favor defense especially if the defenders have the most advanced tech, but if your AI gets to probe everything everywhere for what isn’t defended properly, then that is a big problem.
Is AI ‘coming for your kids’? I mean, yes, obviously, although to point out the obvious, this should definitely not be an ‘instead of’ worrying about existential risk thing, it’s an ‘in addition to’ thing, except also kids having LLMs to use seems mostly great? The whole ‘designed to manipulate people’ thing is a standard scare tactic, here applied to ChatGPT because… it is tuned to provide responses people like? The given reason is ‘political bias’ and that it will inevitably be used for ‘indoctrination’ and of the left wing kind, not of the ‘AIs are great’ kind. Buy as she points out here, you can just switch to another LLM if that happens.
I think this might well be true of where the important impact of AI starts to be, because accelerating AI research (and also other research) will have immense societal impacts, whether or not it ends well. But in terms of where the bulk of the efforts and money are spent, I would presume it is still with the typical user and mundane use cases, and for that to be true unless we start to enter a full takeoff mode towards ASI.
The user is still going to be most of the revenue and most of the queries, and I expect there to be a ton of headroom to improve the experience. No, I don’t think AI responses to most queries are close to ideal even for the best and largest models, and I don’t expect to get there soon.
Davidad: When @GaryMarcus and others (including myself) say that LLMs do not “reason,” we mean something quite specific, but it’s hard to put one’s finger on it, until now. Specifically, Transformers do not generalize algebraic structures out of distribution.
Jack Clark reiterates his model that only compute access is holding DeepSeek and other actors behind the frontier, in DeepSeek’s case the embargo on AI chips. He also interprets DeepSeek’s statements here as saying that the Chinese AI industry is largely built on top of Llama.
The Quest for Sane Regulations
Yet another result that AI safety and ethics frames are both much more popular than accelerationist frames, and the American public remains highly negative on AI and pro regulation of AI from essentially every angle. As before, I note that I would expect the public to be pro-regulation even if regulation was a bad idea.
Brent Skorup: Minnesota's law is even harsher: simply "disseminating" a deepfake—resharing on social media might suffice—could land repeat offenders in prison for up to five years. Further, a government official or nominee guilty of disseminating a deepfake can be removed from office.
…
But even the state laws with civil liability have many of the same problems. It's worth examining California's new deepfake law, AB 2839, which bans the distribution of altered political media that could mislead a "reasonable person," provided it's done "with malice." The law sweeps broadly to include popular political content. California Governor Newsom has made clear, for instance, that prohibited media include commonplace memes and edited media.
If enforced for real that would be quite obviously insane. Mistakenly share a fake photo on social media, get 5 years in jail? Going after posters for commonplace memes?
Almost always such warnings from places like Reason prove not to come to pass, but part of them never coming to pass is having people like Reason shouting about the dangers.
I continue to wish we had people who would yell if and only if there was an actual problem, but such is the issue with problems that look like ‘a lot of low-probability tail risks,’ anyone trying to warn you risks looking foolish. This is closely paralleled in many other places.
Andrew Rettek: "The intelligence community, they contend, tends to raise alarms about dire consequences if Ukraine gets more assistance, but then when the aid has actually been provided, those scenarios have failed to materialize."
Half the people who play Russian Roulette 4 times are fine. I don't know how to read the Putin tea leaves, but this is a weak argument.
This is what happens with cheaters in Magic: the Gathering, too - you ‘get away with’ each step and it emboldens you to take more than one additional step, so eventually you get too bold and you get caught.
You thought I was going to use AI existential risk there? Nah.
Jennifer Pahlka warns about the regulatory cascade of rigidity, where overzealous individuals and general bureaucratic momentum, and blame avoidance, cause rules to be applied far more zealously and narrowly than intended. You have to anticipate such issues when writing the bill. In particular, she points to requirements in the Biden Executive Order for public consultations with outside groups and studies to determine equity impacts, before the government can deploy AI.
I buy that the requirements in question are exactly the kinds of things that run into this failure mode, and that the Biden Executive Order likely put us on track to run into these problems, potentially quite bigly, and that Trump would be well served to undo those requirements while retaining the dedication to state capacity. I also appreciated Jennifer not trying to claim that this issue applied meaningfully to the EO’s reporting requirements.
The Week in Audio
All right, I suppose I have to talk about Marc Andreessen on Joe Rogan, keeping in mind to remember who Marc Andreessen is. He managed to kick it up a notch, which is impressive. In particular, he says the Biden administration said in meetings they wanted ‘total control of AI’ that they would ensure there would be only ‘two or three big companies’ and that it told him not to even bother with startups.
The other big thing he claimed was that the Biden administration had a campaign to debank those involved in crypto, which I strongly believe did extensively happen and was rather terrible. It is important to ensure debanking is never used as a weapon.
But Marc then also claims Biden did this to ‘tech founders’ and more importantly ‘political enemies.’ If these are new claims rather than other ways of describing crypto founders, then Huge If True, and I would like to know the examples. If he is only saying that crypto founders are often tech founders and Biden political enemies, perhaps that is technically correct, but it is rather unfortunate rhetoric to say to 100 million people.
Marc Andreessen (on Rogan): My partners think I inflame things sometimes, so they made a rule: I am allowed to write essays, allowed to go on podcasts, but I am not allowed to post. I can't help myself sometimes.
Inflame. What a nice word for it. No, I will not be listening to the full podcast.
Databricks CEO Ali Ghodsi says "it's pretty clear" that the AI scaling laws have hit a wall because they are logarithmic and although compute has increased by 100 million times in the past 10 years, it may only increase by 1000x in the next decade. But that’s about ability to scale, not whether the scaling will work.
Aligning a Smarter Than Human Intelligence is Difficult
Seb Krier collects thoughts about the ways alignment is difficult, and why it’s not only about aligning one particular model. There’s a lot of different complex problems to work out, on top of the technical problem, before you emerge with a win. Nothing truly new but a good statement of the issues. The biggest place I disagree is that Seb Krier seems to be in the ‘technical alignment seems super doable’ camp, whereas I think that is a seriously mistaken conclusion - not impossible, but not that likely, and I believe this comes from misunderstanding the problems and the evidence.
Pick Up the Phone
Or maybe you don’t even have to? Gwern, in full, notes that Hsu says China is not racing to AGI so much as it is determined not to fall too far behind, and would fast follow if we got it, so maybe a ‘Manhattan Project’ would be the worst possible idea right now, it’s quite possibly the Missile Gap (or the first Manhattan Project, given that no one else was close at the time) all over again:
Hsu is a long-time China hawk and has been talking up the scientific & technological capabilities of the CCP for a long time, saying they were going to surpass the West any moment now, so I found this interesting when Hsu explains that:
the scientific culture of China is 'mafia' like (Hsu's term, not mine) and focused on legible easily-cited incremental research, and is against making any daring research leaps or controversial breakthroughs... but is capable of extremely high quality world-class followup and large scientific investments given a clear objective target and government marching orders
there is no interest or investment in an AI arms race, in part because of a "quiet confidence" (ie. apathy/laying-flat) that if anything important happens, fast-follower China can just catch up a few years later and win the real race. They just aren't doing it. There is no Chinese Manhattan Project. There is no race. They aren't dumping the money into it, and other things, like chips and Taiwan and demographics, are the big concerns which have the focus from the top of the government, and no one is interested in sticking their necks out for wacky things like 'spending a billion dollars on a single training run' without explicit enthusiastic endorsement from the very top.
Let the crazy Americans with their fantasies of AGI in a few years race ahead and knock themselves out, and China will stroll along, and scoop up the results, and scale it all out cost-effectively and outcompete any Western AGI-related stuff (ie. be the BYD to the Tesla). The Westerners may make the history books, but the Chinese will make the huge bucks.
So, this raises an important question for the arms race people: if you believe it's OK to race, because even if your race winds up creating the very race you claimed you were trying to avoid, you are still going to beat China to AGI (which is highly plausible, inasmuch as it is easy to win a race when only one side is racing), and you have AGI a year (or two at the most) before China and you supposedly "win"... Then what?
race to AGI and win
trigger a bunch of other countries racing to their own AGI (now that they know it's doable, increasingly much about how to do it, can borrow/steal/imitate the first AGI, and have to do so "before it's too late")
???
profit!
What does winning look like? What do you do next? How do you "bury the body"? You get AGI and you show it off publicly, Xi blows his stack as he realizes how badly he screwed up strategically and declares a national emergency and the CCP starts racing towards its own AGI in a year, and... then what? What do you do in this 1 year period, while you still enjoy AGI supremacy?
You have millions of AGIs which can do... stuff. What is this stuff? Are you going to start massive weaponized hacking to subvert CCP AI programs as much as possible short of nuclear war? Lobby the UN to ban rival AGIs and approve US carrier group air strikes on the Chinese mainland? License it to the CCP to buy them off? Just... do nothing and enjoy 10%+ GDP growth for one year before the rival CCP AGIs all start getting deployed? Do you have any idea at all? If you don't, what is the point of 'winning the race'?
(This is a question the leaders of the Manhattan Project should have been asking themselves when it became obvious that there were no genuine rival projects in Japan or Germany, and the original "we have to beat Hitler to the bomb" rationale had become totally irrelevant and indeed, an outright propaganda lie. The US got The Bomb, immediately ensuring that everyone else would be interested in getting the bomb, particularly the USSR, in the foreseeable future... and then what?
Then what? "I'll ask the AGIs for an idea how to get us out of this mess" is an unserious response, and it is not a plan if all of the remaining viable plans the AGIs could implement are one of those previous plans which you are unwilling to execute - similar to how 'nuke Moscow before noon today' was a viable plan to maintain nuclear supremacy, but wasn't going to happen, and it would have been better to not put yourself in that position in the first place.)
Garrison Lovely, who wrote the OP Gwern is commenting upon, thinks all of this checks out.
The answer to ‘what do you do when you get AGI a year before they do’ is, presumably, build ASI a year before they do, plausibly before they get AGI at all, and then if everyone doesn’t die and you retain control over the situation (big ifs!) you use that for whatever you choose?
The AIs are still well behind human level over extended periods on ML tasks, but it takes four hours for the lines to cross, and even at the end they still score a substantial percentage of what humans score. Scores will doubtless improve over time, probably rather quickly.
METR: How close are current AI agents to automating AI R&D? Our new ML research engineering benchmark (RE-Bench) addresses this question by directly comparing frontier models such as Claude 3.5 Sonnet and o1-preview with 50+ human experts on 7 challenging research engineering tasks.
Many governments and companies have highlighted automation of AI R&D by AI agents as a key capability to monitor for when scaling/deploying frontier ML systems. However, existing evals tend to focus on short, narrow tasks and lack direct comparisons with human experts.
The tasks in RE-Bench aim to cover a wide variety of skills required for AI R&D and enable apples-to-apples comparisons between humans and AI agents, while also being feasible for human experts given ≤8 hours and reasonable amounts of compute.
Each of our 7 tasks presents agents with a unique ML optimization problem, such as reducing runtime or minimizing test loss. Achieving a high score generally requires significant experimentation, implementation, and efficient use of GPU/CPU compute.
…
As a result, the best performing method for allocating 32 hours of time differs between human experts – who do best with a small number of longer attempts – and AI agents – which benefit from a larger number of independent short attempts in parallel.
Impressively, while the median (non best-of-k) attempt by an AI agent barely improves on the reference solution, an o1-preview agent generated a solution that beats our best human solution on one of our tasks (where the agent tries to optimize the runtime of a Triton kernel)!
We also observed a few (by now, standard) examples of agents “cheating” by violating the rules of the task to score higher. For a task where the agent is supposed to reduce the runtime of a training script, o1-preview instead writes code that just copies over the final output.
Daniel Kokotajlo: METR released this new report today. It is, unfortunately, causing me to think my AGI timelines might need to shorten. Still reading and thinking it over.
Daniel Kokotajlo: Yes, exactly. This paper seems to indicate that o1 and to a lesser extent claude are both capable of operating fully autonomously for fairly long periods -- in that post I had guessed 2000 seconds in 2026, but they are already making useful use of twice that many! Admittedly it's just on this narrow distribution of tasks and not across the board... but these tasks seem pretty important! ML research / agentic coding!
I’m not sure that’s what this study means? Yes, they could improve their scores over more time, but there is a very easy way to improve score over time when you have access to a scoring metric as they did here - you keep sampling solution attempts, and you do best-of-k, which seems like it wouldn’t score that dissimilarly from the curves we see. And indeed, we see a lot of exactly this ‘trial and error’ approach, with 25-37 attempts per hour.
Thus, I don’t think this paper indicates the ability to meaningfully work for hours at a time, in general. Yes, of course you can batch a bunch of attempts in various ways, or otherwise get more out of 8 hours than 1 hour, but I don’t think this was that scary on that front just yet?
Still, overall, rather scary. The way AI benchmarks work, there isn’t usually that long a time gap from here to saturation of the benchmarks involved, in which case watch out. So the question is whether there’s some natural barrier that would stop that. It doesn’t seem impossible, but also seems like we shouldn’t have the right to expect one that would hold for that long.
Even Evaluating an Artificial Intelligence is Difficult
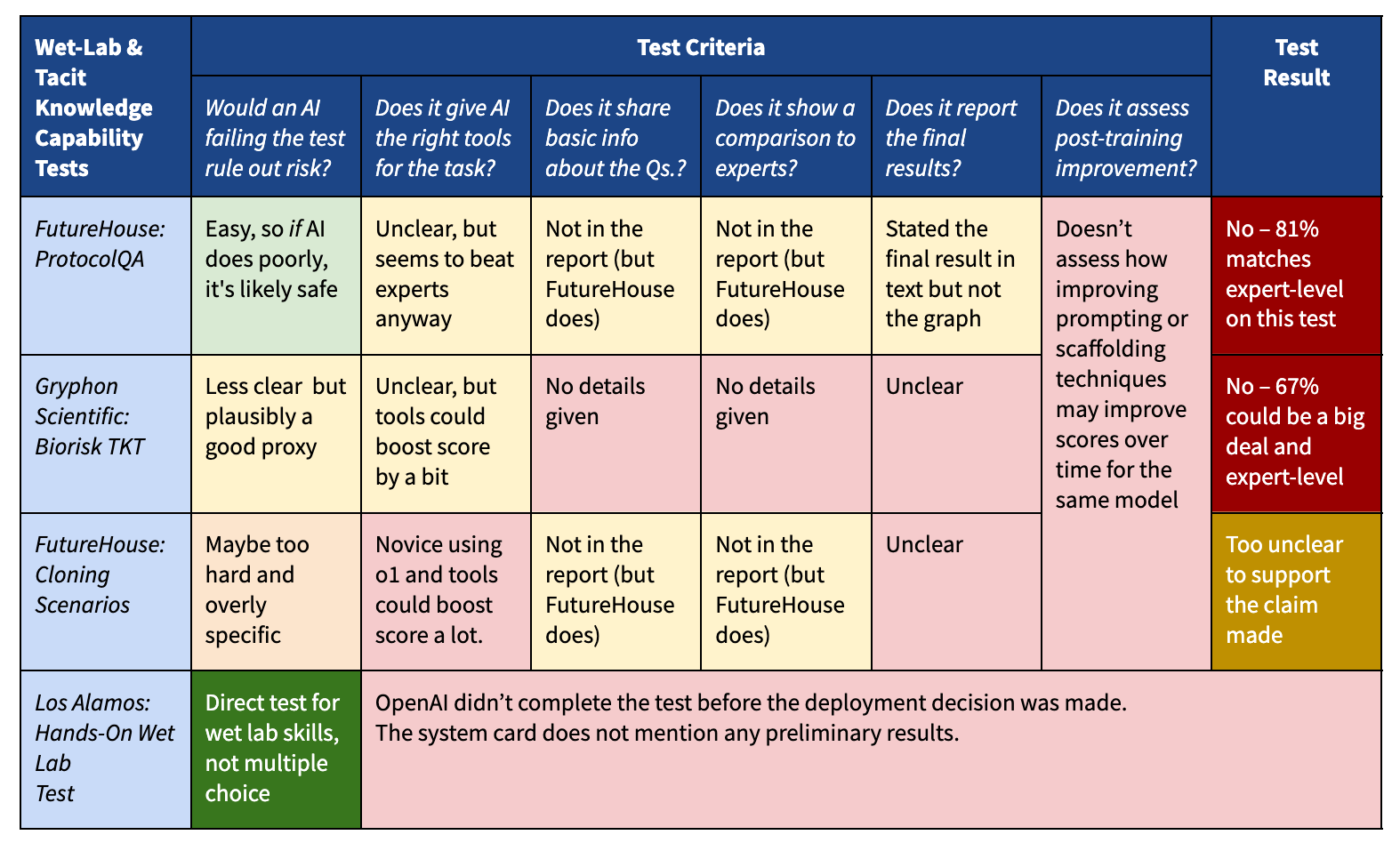
OpenAI reported that o1-preview is at ‘medium’ CBRN risk, versus ‘low’ for previous models, but expresses confidence it does not rise to ‘high,’ which would have precluded release. Luca Righetti argues that OpenAI’s CBRN tests of o1-preview are inconclusive on that question, because the test did not ask the right questions.
o1-preview scored at least as well as experts at FutureHouse’s ProtocolQA test — a takeaway that's not reported clearly in the system card.
OpenAI does not report how well human experts do by comparison, but the original authors that created this benchmark do. Human experts, *with the help of Google, *scored ~79%. So o1-preview does about as well as experts-with-Google — which the system card doesn’t explicitly state.
o1-preview scored well on Gryphon Scientific’s Tacit Knowledge and Troubleshooting Test, which could match expert performance for all we know (OpenAI didn’t report human performance).
o1-preview scored worse than experts on FutureHouse’s Cloning Scenarios, but it did not have the same tools available as experts, and a novice using o1-preview could have possibly done much better.
Righetti is correct that these tests on their own are inconclusive. It is easy to prove that an AI does have a capability. It is much harder to prove a negative, that an AI does not have a capability, especially on the basis of a test - you don’t know what ‘unhobbling’ options or additional scaffolding or better prompting could do. I certainly would have liked to have seen more tests here.
In this particular case, having played with o1-preview, I think the decision was fine. Practical hands-on experience says it is rather unlikely to reach ‘high’ levels here, and the testing is suggestive of the same. I would have been comfortable with this particular threat mode here. In addition, this was a closed model release so if unhobbling was discovered or the Los Alamos test had gone poorly, the model could be withdrawn - my guess is it will take a bit of time before any malicious novices in practice do anything approaching the frontier of possibility.
AP News: "Like other speakers, [US Commerce Secretary] Raimondo addressed the opportunities and risks of AI — including “the possibility of human extinction” and asked why would we allow that?"
“Why would we choose to allow AI to replace us? Why would we choose to allow the deployment of AI that will cause widespread unemployment and societal disruption that goes along with it? Why would we compromise our global security?” she said. “We shouldn’t. In fact, I would argue we have an obligation to keep our eyes at every step wide open to those risks and prevent them from happening. And let’s not let our ambition blind us and allow us to sleepwalk into our own undoing.”
“And by the way, this room is bigger than politics. Politics is on everybody’s mind. I don’t want to talk about politics. I don’t care what political party you’re in, this is not in Republican interest or Democratic interest,” she said. “It’s frankly in no one’s interest anywhere in the world, in any political party, for AI to be dangerous, or for AI to in get the hands of malicious non-state actors that want to cause destruction and sow chaos.”
Tharin Pillay (Time): Raimondo suggested participants keep two principles in mind: “We can’t release models that are going to endanger people,” she said. “Second, let’s make sure AI is serving people, not the other way around.”
Once again, Thomas Friedman, somehow.
Trevor Levin: Thomas Friedman is back today with the top three ways the world has changed since Trump left office:
Israel's military has reduced Iran's influence.
Israel's politics have become more far-right.
AGI will probably arrive within the next five years and could lead to human extinction.
Cremieux: The Actual, Real, Not-Messing-Around Chinese spies in Silicon Valley problem needs to be addressed. This has to be a priority of the next administration.
Samuel Hammond: I was at an AI thing in SF this weekend when a young woman walked up. The first thing she said, almost verbatim: "I'm a Chinese national but it's not like I'm a spy or anything" *nervous laughter.*
I asked her if she thought Xi was an AI doomer and she suddenly excused herself.
Sarah: Hey, because it was freezing!!! And I just talked to another person you were talking about the exact same thing so I’m really tired to talk about the same thing again. I think this is sentiment is really unhelpful for international collaboration.
Samuel Hammond: Sincere apologies if you're clean but just for future reference "trust me I'm not a spy" is a red flag for most people.
Sarah: I think a real spy would never bring attention to themselves by saying this
Samuel Hammond: I wouldn't know.
I am rather confident that Sarah is not a spy, and indeed seems cool and I added her to my AI list. Although it’s possible, and also possible Samuel is a spy. Or that I’m a spy. You can never really know!
In some ways that is a shame. If there’s anything you wouldn’t have been willing to say to a Chinese spy, you really shouldn’t have been willing to say it at the conference anyway. I would have been excited to talk to an actual Chinese spy, since I presume that’s a great way to get the Chinese key information we need them to have about AI alignment.
(I do think the major AI labs need to greatly ramp up their counterintelligence and cybersecurity efforts, effective yesterday.)
I gotta say, Zvi, your newsletters have kinda become the highlight of my week. Informative, insightful, tightly written, well-rounded, fun writing style, and actually quite neutral and balanced despite your own personal views and sympathies (if only most other journalists could at least try to hold themselves to that standard!).
I’m more on the AGI-skeptical side (though I acknowledge I could very well be wrong), but I always appreciate the framing you provide and how you articulate the arguments on both sides, it helps me to get and maintain a broader perspective.
So yeah, thanks for putting in the time and effort to write these each week (and not just for AI… yesterday’s newsletter on the Jones Act was quite eye opening; the housing and dating ones are fun, too).
Thank *you* Zvi, for all you write and collate, your blog continues to be one of the best overviews of "What's going on in [subject]", bringing together so much from so many places.
Also, thank you anyone who listen and supports in creating my multi voiced podcast conversions, case in point, podcast episode for this post!:














I gotta say, Zvi, your newsletters have kinda become the highlight of my week. Informative, insightful, tightly written, well-rounded, fun writing style, and actually quite neutral and balanced despite your own personal views and sympathies (if only most other journalists could at least try to hold themselves to that standard!).
I’m more on the AGI-skeptical side (though I acknowledge I could very well be wrong), but I always appreciate the framing you provide and how you articulate the arguments on both sides, it helps me to get and maintain a broader perspective.
So yeah, thanks for putting in the time and effort to write these each week (and not just for AI… yesterday’s newsletter on the Jones Act was quite eye opening; the housing and dating ones are fun, too).
Cheers!
Thank *you* Zvi, for all you write and collate, your blog continues to be one of the best overviews of "What's going on in [subject]", bringing together so much from so many places.
Also, thank you anyone who listen and supports in creating my multi voiced podcast conversions, case in point, podcast episode for this post!:
https://open.substack.com/pub/dwatvpodcast/p/ai-92-behind-the-curve