The avalanche of DeepSeek news continues. We are not yet spending more than a few hours at a time in the singularity, where news happens faster than it can be processed. But it’s close, and I’ve had to not follow a bunch of other non-AI things that are also happening, at least not well enough to offer any insights.
So this week we’re going to consider China, DeepSeek and r1 fully split off from everything else, and we’ll cover everything related to DeepSeek, including the policy responses to the situation, tomorrow instead.
This is everything else in AI from the past week. Some of it almost feels like it is from another time, so long ago.
I’m afraid you’re going to need to get used to that feeling.
Vik: increasingly finding myself designing software for AI comprehension over human readability. e.g. giant files, duplicated code, a lot more verification tests.
Now i just need to convince the agent to stop deleting failing tests...
James Darpinian: IMO these usually increase human readability as well, contra "best practices."
Vik: agree, makes it so you don't have to keep the entire codebase in your head. can go in, understand what's going on, implement your change and get out without spending too much time doing research or worrying you've broken something
That’s even more true when the humans are using the AIs to read the code.
Language Models Don’t Offer Mundane Utility
A negative review of Devin, the AI SWE, essentially saying that in practice it isn’t yet good enough to be used over tools like Cursor. The company reached out in the replies thanking them for the feedback and offering to explore more with them, which is a good sign for the future, but it seems clear we aren’t ‘there’ yet.
I predict Paul Graham is wrong about this if we stay in ‘economic normal.’ It seems like exactly the kind of combination of inception, attempt at vibe control and failure to realize the future will be unevenly distributed we often see in VC-style circles, on top of the tech simply not being there yet anyway.
Paul Graham: Prediction: From now on we'll rarely hear the phrase "writer's block." 99% of the people experiencing it will give in after a few days and have AI write them a first draft. And the 1% who are too proud to use AI are probably also too proud to use a phrase like "writer's block."
Certainly this won’t be true ‘from now on.’ No, r1 is not ready to solve writer’s block, it cannot create first drafts for you if you don’t know what to write on your own in a way that solves most such problems. AI will of course get better at writing, but I predict it will be a while up the ‘tech tree’ before it solves this problem.
And even if it does, it’s going to be a while beyond that before 99% of people with writer’s block even know they have this option, let alone that they are willing to take it.
And even if that happens, the 1% will be outright proud to say they have writer’s block. It means they don’t use AI!
Indeed, seriously, don’t do this:
Fear Buck: Kai Cenat’s $70k AI humanoid robot just tried running away from the AMP house because it kept getting kicked and bullied by Kai, Agent & Fanum 😭😭
Liv Boeree: Yeah don't do this, because even if something doesn't have "feelings" it is just teaching you and your followers that it's okay to act out their worst instincts
Education is where I see the strongest disagreements about AI impact, in the sense that those who generally find AI useful see it as the ultimate tool for learning things that will unleash the world’s knowledge and revolutionize education, and then there are others who see things another way.
PoliMath: AI use is damaging high school and college education enormously in ways that are going to be extremely obvious in 5 years but at that point you can only watch.
I don’t understand this position. Yes, you can use AI to get around your assignments if that’s what you want to do and the system keeps giving you those assignments. Or you can actually try to learn something. If you don’t take that option, I don’t believe you that you would have been learning something before.
Language Models Don’t Offer You In Particular Mundane Utility
Your periodic reminder that the main way to not get utility is to not realize to do so:
Nate Silver: Thinking ChatGPT is useless is midwit. It's a magic box that answers any question you ask it from levels ranging from modestly coherent to extremely proficient. If you haven't bothered to figure it out to derive some utility out of it then you're just being lazy tbh.
Even better than realizing you can use ChatGPT, of course, is using a mix of Claude, Perplexity, Gemini, r1, o1, o1 pro and yes, occasionally GPT-4o.
Others make statements like this when others show them some mundane utility:
Joe Weisenthal: Suppose I have some conference call transcripts, and I want to see what the CEOs said about the labor market.
I could read through all of them.
Or I can ask AI to retrieve the relevant comments and then confirm that they are actually real.
Latter is much more efficient.
Hotel Echo: Large Language Models: for when Ctrl-F is just too much like hard work.
Yes. It is much more efficient. Control-F sucks, it has tons of ‘hallucinations’ in the sense of false positives and also false negatives. It is not a good means to parse a report. We use it because it used to be all we have.
Also some people still don’t do random queries? And some people don’t even get why someone else would want to do that?
Joe Weisenthal: I wrote about how easily and quickly I was able to switch from using ChatGPT to using DeepSeek for my random day-to-day AI queries
Faze Adorno: Who the f*** has random day-to-day AI queries?
"I'm gonna use this technology that just makes up information at anywhere between a 5 and 25 percent clip for my everyday information! I'm so smart!"
"People who regularly do things they are not experts in" versus
"People with a regular, time-honed routine for their work and personal life."
People I know in the latter group genuinely do not have much use for AI!
Jorbs: This is fascinating to me because, in my (limited) attempts to utilize LLMs, they have essentially only been useful in areas where I have significant enough knowledge to tell when the output is inaccurate.
For example, as someone who took a couple of quarters of computer science but is not a regular coder, LLMs are not good enough to be useful for coding for me. They output a lot of material, but it is as much work to parse it and determine what needs fixing as it is to do it from scratch myself.
I resonate but only partially agree with both answers. When doing the things we normally do, you largely do them the way you normally do them. People keep asking if I use LLMs for writing, and no, when writing directly I very much don’t and find all the ‘help me write’ functionality useless - but it’s invaluable for many steps of the process that puts me into position to write, or to help develop and evaluate the ideas that the writing is about.
Whereas I am perhaps the perfect person to get my coding accelerated by AI. I’m often good enough to figure out when it is telling me bullshit, and totally not good enough to generate the answers on my own in reasonable time, and also automates stuff that would take a long time, so I get the trifecta.
On the question of detecting whether the AI is talking bullshit, it’s a known risk of course, but I think that risk is greatly overblown - this used to happen a lot more than it does now, and we forget how other sources have this risk too, and you can develop good habits about knowing which places are more likely to be bullshit versus not even if you don’t know the underlying area, and when there’s enough value to check versus when you’re fine to take its word for it.
A few times a month I will have to make corrections that are not simple typos. A few times I’ve had to rework or discard entire posts because the error was central. I could minimize it somewhat more but mostly it’s an accepted price of doing business the way I do, the timing doesn’t usually allow for hiring a fact checker or true editor, and I try to fix things right away when it happens.
It is very rare for the source of that error to be ‘the AI told me something and I believed it, but the AI was lying.’ It’s almost always either I was confused about or misread something, or a human source got it wrong or was lying, or there was more to a question than I’d realized from reading what others said.
(Don’t) Feel the AGI
This reaction below is seriously is like having met an especially irresponsible thirteen year old once, and now thinking that no human could ever hold down a job.
And yet, here we often still are.
Patrick McKenzie (last week): You wouldn’t think that people would default to believing something ridiculous which can be disproved by typing into a publicly accessible computer program for twenty seconds. Many people do not have an epistemic strategy which includes twenty seconds of experimentation.
Dave Karsten: Amplifying: I routinely have conversations at DC house parties with very successful people who say that they tried chatGPT _right when it came out_, found it not that impressive, and haven't tried it again since then, and have based their opinion on AI on that initial experience.
Ahrenbach: What’s the ratio of “AI is all hype” vs “We need to beat China in this technology”?
More the former than the latter in house parties, but that's partially because more of my defense/natsec people I tend to see at happy hours. (This is a meaningful social distinction in DC life).
Broadly, the average non-natsec DC person is more likely to think it's either a) all hype or b) if not hype, AI-generated slop with an intentional product plan where, "how do we kill art" is literally on a powerpoint slide.
But overton window is starting to shift.
It is now two weeks later, and the overton window has indeed shifted a bit. There’s a lot more ‘beat China’ all of a sudden, for obvious reasons. But compared to what’s actually happening, the DC folks still absolutely think this is all hype.
Huh, Upgrades
Claude API now allows the command ‘citations’ to be enabled, causing it to process whatever documents you share with it, and then it will cite the documents in its response. Cute, I guess. Curious lack of shipping over at Anthropic recently.
o3-mini is coming. It’s a good model, sir.
Benedikt Stroebl: Update on HAL! We just added o3-mini to the Cybench leaderboard.
o3-mini takes the lead with ~26% accuracy, outperforming both Claude 3.5 Sonnet and o1-preview (both at 20%)👇
It’s hard to see, but note the cost column. Claude Sonnet 3.5 costs $12.90, o1-mini cost $28.47, o1-preview cost $117.89 and o3-mini cost $80.21 if it costs the same per token as o1-mini (actual pricing not yet set). So it’s using a lot more tokens.
Gemini 2.0 Flash Thinking got an upgrade last week. The 1M token context window opens up interesting possibilities if the rest is good enough, and it’s wicked cheap compared even to r1, and it too has CoT visible. Andrew Curran says it’s amazing, but that opinion reached me via DeepMind amplifying him.
which is better than r1 on every cost and performance metric
Peter Wildeford: The weird thing about Deepseek is that it exists in a continuum - it is neither the cheapest reasoning model (that's Gemini 2 Flash Thinking) nor the best reasoning model (o1-pro, probably o3-pro when that's out)
I disagree with the quoted tweet - I don't think Gemini 2 Flash Thinking is actually better than r1 on every cost and performance metric. But I also have not seen anything that convinces me that Deepseek is truly some outlier that US labs can't also easily do.
That is a dramatic drop in price, and dramatic gain in context length. r1 is open, which has its advantages, but we are definitely not giving Flash Thinking its fair trial.
The thing about cost is, yes this is an 80%+ discount, but off of a very tiny number. Unless you are scaling this thing up quite a lot, or you are repeatedly using the entire 1M context window (7.5 cents a pop!) and mostly even then, who cares? Cost is essentially zero versus cost of your time.
Need practical advice? Tyler Cowen gives highly Tyler Cowen-shaped practical advice for how to deal with the age of AI on a personal level. If you believe broadly in Cowen’s vision of what the future looks like, then these implications seem reasonable. If you think that things will go a lot farther and faster than he does, they’re still interesting, but you’d reach different core conclusions.
Are there not enough GPUs to take all the jobs? David Holz says since we only make 5 million GPUs per year and we have 8 billion humans, it’ll be a while even if each GPU can run a virtual human. There are plenty of obvious ways to squeeze out more, there’s no reason each worker needs its own GPU indefinitely as capabilities and efficiency increase and the GPUs get better, and also as Holz notices production will accelerate. In a world where we have demand for this level of compute, this might buy us a few years, but they’ll get there.
Epoch paper from Matthew Barnett warns that AGI could drive wages below subsistence level. That’s a more precise framing than ‘mass unemployment,’ as the question isn’t if there is employment for humans the question is at what wage level, although at some point humans really are annoying enough to use that they’re worth nothing.
Matthew Barnett: In the short term, it may turn out to be much easier to accumulate AGIs than traditional physical capital, making physical capital the scarce factor that limits productivity and pushes wages downward. Yet, there is also a reasonable chance that technological progress could counteract this effect by making labor more productive, allowing wages to remain stable or even rise.
Over the long run, however, the pace of technological progress is likely to slow down, making it increasingly difficult for wages to remain high. At that point, the key constraints are likely to be fundamental resources like land and energy—essential inputs that cannot be expanded through investment. This makes it highly plausible that human wages will fall below subsistence level in the long run.
Informed by these arguments, I would guess that there is roughly a 1 in 3 chance that human wages will crash below subsistence level within 20 years, and a 2 in 3 chance that wages will fall below subsistence level within the next 100 years.
I consider it rather obvious that if AGI can fully substitute for actual all human labor, then wages will drop a lot, likely below subsistence, once we scale up the number of AGIs, even if we otherwise have ‘economic normal.’
That doesn’t answer the objection that human labor might retain some places where AGI can’t properly substitute, either because jobs are protected, or humans are inherently preferred for those jobs, or AGI can’t do some jobs well perhaps due to physical constraints.
If that’s true, then to the extent it remains true some jobs persist, although you have to worry about too many people chasing too few jobs crashing the wage on those remaining jobs. And to the extent we do retain jobs this way, they are driven by human consumption and status needs, which means that those jobs will not cause us to ‘export’ to AIs by default except insofar as they resell the results back to us.
The main body of this paper gets weird. It argues that technological advancement, while ongoing, can protect human wages, and I get why the equations here say that but it does not actually make any sense if you think it through here.
Then it talks about technological advancement stopping as we hit physical limits, while still considering that world being in ‘economic normal’ and also involves physical humans in their current form. That’s pretty weird as a baseline scenario, or something to be paying close attention to now. It also isn’t a situation where it’s weird to think about ‘jobs’ or ‘wages’ for ‘humans’ as a concern in this way.
I do appreciate the emphasis that the comparative advantage and lump of labor fallacy arguments prove a wage greater than zero is likely, but not that it is meaningfully different from zero before various costs, or is above subsistence.
Tyler Cowen offers the take that future unemployment will be (mostly) voluntary unemployment, in the sense that there will be highly unpleasant jobs people don’t want to do (here be an electrician living on a remote site doing 12 hour shifts) that pay well. And yeah, if you’re willing and able to do things people hate doing and give up your life otherwise to do it, that will help you stay gainfully employed at a good price level for longer, as it always has. I mean, yeah. And even ‘normal’ electricians make good money, because no one wants to do it. But it’s so odd to talk about future employment opportunities without reference to AI - unemployment might stay ‘voluntary’ but the wage you’re passing up might well get a lot worse quickly.
Also, it seems like electrician is a very good business to be in right now?
Get Involved
IFP is hiringa lead for their lobbying on America’s AI leadership, applications close February 21, there’s a bounty so tell them I sent you. I agree with IFP and think they’re great on almost every issue aside from AI. We’ve had our differences on AI policy though, so I talked to them about it. I was satisfied that they plan on doing net positive things, but if you’re considering the job you should of course verify this for yourself.
Alibaba introduces Qwen 2.5-1M, with the 1M standing for a one million token context length they say processes faster now, technical report here. Again, if it’s worth a damn, I expect people to tell me, and if you’re seeing this it means no one did that.
Feedly, the RSS feed I use, tells me it is now offering AI actions. I haven’t tried them because I couldn’t think of any reason I would want to, and Teortaxes is skeptical.
Scott Alexander is looking for a major news outlet to print an editorial from an ex-OpenAI employee who has been featured in NYT, you can email him at scott@slatestarcodex.com if you’re interested or know someone who is.
Reid Hoffman launches Manas AI, a ‘full stack AI company setting out to shift drug discovery from a decade-long process to one that takes a few years.’ Reid’s aggressive unjustified dismissals of the downside risks of AI are highly unfortunate, but Reid’s optimism about AI is for the right reasons and it’s great to see him putting that into practice in the right ways. Go team humanity.
*plus tier will get 100 o3-mini queries per DAY (!)
*we will bring operator to plus tier as soon as we can
*our next agent will launch with availability in the plus tier
enjoy 😊
i think you will be very very happy with o3 pro!
oAI: No need to thank me.
Spencer Greenberg and Neel Nanda join in the theory that offering public evals that can be hill climbed is plausibly a net negative for safety, and certainly worse than private evals. There is a public information advantage to potentially offset this, but yes the sign of the impact of fully public evals is not obvious.
Meta was up 2.25% on a mostly down day when this was announced, as opposed to before when announcing big compute investments would cause Meta stock to drop. At minimum, the market didn’t hate it. I hesitate to conclude they loved it, because any given tech stock will often move up or down a few percent for dumb idiosyncratic reasons - so we can’t be sure this was them actively liking it.
Then Meta was up again during the Nvidia bloodbath, so presumably they weren’t thinking ‘oh no look at all that money Meta is wasting on data centers’?
Hype
This section looks weird now because what a week and OpenAI has lost all the hype momentum, but that will change, also remember last week?
In any case, Chubby points out to Sam Altman that if you live by the vague-post hype, you die by the vague-post hype, and perhaps that isn’t the right approach to the singularity?
Chubby: You wrote a post today (down below) that irritated me a lot and that I would not have expected from you. Therefore, I would like to briefly address a few points in your comment.
You are the CEO of one of the most important companies of our time, OpenAI. You are not only responsible for the company, but also for your employees. 8 billion people worldwide look up to you, the company, and what you and your employees say. Of course, each of your words is interpreted with great significance.
It is your posts and words that have been responsible for the enthusiasm of many people for AI and ChatGPT for months and years. It is your blog post (Age of Intelligence) that by saying that superintelligence is only a few thousand days away. It is your post in which you say that the path to AGI is clear before us. It is your employees who write about creating an “enslaved god” and wondering how to control it. It is your words that we will enter the age of abundance. It is your employees who discuss the coming superintelligence in front of an audience of millions and wonder what math problems can still be solved before the AI solves everything. It is the White House National Security Advisor who said a few days ago that it is a “Godlike” power that lies in the hands of a few.
And you are insinuating that we, the community, are creating hype? That is, with all due modesty, a blatant insult.
It was you who fueled the hype around Q*/Strawberry/o1 with cryptic strawberry photos. It was you who wrote a haiku about the coming singularity just recently. We all found it exciting, everyone found it interesting, and many got on board.
But the hype is by no means coming from the community. It's coming from the CEO of what is arguably the most famous corporation in the world.
This is coming from someone to whom great hype is a symbol not of existential risk, as I partly see it, but purely of hope. And they are saying that no, ‘the community’ or Twitter isn’t creating hype, OpenAI and its employees are creating hype, so perhaps act responsibly going forward with your communications on expectations.
I don’t have a problem with the particular post by Altman that’s being quoted here, but I do think it could have been worded better, and that the need for it reflects the problem being indicated.
Nat McAleese (OpenAI): Epoch AI are going to publish more details, but on the OpenAI side for those interested: we did not use FrontierMath data to guide the development of o1 or o3, at all.
We didn't train on any FM derived data, any inspired data, or any data targeting FrontierMath in particular.
I'm extremely confident, because we only downloaded frontiermath for our evals *long* after the training data was frozen, and only looked at o3 FrontierMath results after the final announcement checkpoint was already picked.
We did partner with EpochAI to build FrontierMath — hard uncontaminated benchmarks are incredibly valuable and we build them somewhat often, though we don't usually share results on them.
Our agreement with Epoch means that they can evaluate other frontier models and we can evaluate models internally pre-release, as we do on many other datasets.
I'm sad there was confusion about this, as o3 is an incredible achievement and FrontierMath is a great eval. We're hard at work on a release-ready o3 & hopefully release will settle any concerns about the quality of the model!
This seems definitive for o3, as they didn’t check the results until sufficiently late in the process. For o4, it is possible they will act differently.
I’ve been informed that this still left a rather extreme bad taste in the mouths of mathematicians. If there’s one thing math people can’t stand, it’s cheating on tests. As far as many of them are concerned, OpenAI cheated.
Quiet Speculations
Rohit Krishnan asks what a world with AGI would look like, insisting on grounding the discussion with a bunch of numerical calculations on how much compute is available. He gets 40 million realistic AGI agents working night and day, which would be a big deal but obviously wouldn’t cause full unemployment on its own if the AGI could only mimic humans rather than being actively superior in kind. The discussion here assumes away true ASI as for some reason infeasible.
The obvious problem with the calculation is that algorithmic and hardware improvements are likely to continue to be rapid. Right now we’re on the order of 10x efficiency gain per year. Suppose in the year 2030 we have 40 million AGI agents at human level. If we don’t keep scaling them up to make them smarter (which also changes the ballgame) then why wouldn’t we make them more efficient, such that 2031 brings us 400 million AGI agents?
Even if it’s only a doubling 80 million, or even less than that, this interregnum period where the number of AGI agents is limited by compute enough to keep the humans in the game isn’t going to last more than a few years, unless we are actually hitting some sort of efficient frontier where we can’t improve further. Does that seem likely?
We’re sitting on an exponential in scenarios like this. If your reason AGI won’t have much impact is ‘it will be too expensive’ then that can buy you time. But don’t count on it buying you very much.
Dario Amodei in Davos says ‘human lifespans could double in 5 years’ by doing 100 years of scientific progress in biology. It seems odd to expect that doing 100 years of scientific progress would double the human lifespan? The graphs don’t seem to point in that direction. I am of course hopeful, perhaps we can target the root causes or effects of aging and start making real progress, but I notice that if ‘all’ we can do is accelerate research by a factor of 20 this result seems aggressive, and also we don’t get to do that 20x speedup starting now, even the AI part of that won’t be ready for a few years and then we actually have to implement it. Settle down, everyone.
Of course, if we do a straight shot to ASI then all things are possible, but that’s a different mechanism than the one Dario is talking about here.
Chris Barber asks Gwern and various AI researchers: Will scaling reasoning models like o1, o3 and R1 unlock superhuman reasoning? Answers vary, but they agree there will be partial generalization, and mostly agree that exactly how much we get and how far it goes is an empirical result that we don’t know and there’s only one way to find out. My sense from everything I see here is that the core answer is yes, probably, if you push on it hard enough in a way we should expect to happen in the medium term. Chris Barber also asks for takeaways from r1, got a wide variety of answers although nothing we didn’t cover elsewhere.
Rob Wilbin: Incredibly dumb take but this is the level of analysis one finds in too many places.
(There's no reason to think only sentient biological living beings can think.)
The comments here really suggest we are doomed.
cato1308: No Mr. Wolf, they don’t think. They’re not sentient biological living beings.
I am sad to report Cato’s comment was, if anything, above average. The level of discourse around AI, even at a relatively walled garden like the Financial Times, is supremely low - yes Twitter is full of Bad DeepSeek Takes and the SB 1047 debate was a shitshow, but not like that. So we should remember that.
And when we talk about public opinion, remember that yes Americans really don’t like AI, and yes their reasons are correlated to good reasons not to like AI, but they’re also completely full of a very wide variety of Obvious Nonsense.
In deeply silly economics news: A paper claims that if transformative AI is coming, people would then reason they will consume more in the future, so instead they should consume more now, which would raise real interest rates. Or maybe people would save, and interest rates would fall. Who can know.
I mean, okay, I agree that interest rates don’t tell us basically anything about the likelihood of AGI? For multiple reasons:
As they say, we don’t even know in which direction this would go. Nor would I trust self-reports of any kind on this.
Regular people expecting AGI doesn’t correlate much with AGI. Most people have minimal situational awareness. To the extent they have expectations, you have already ‘priced them in’ and should ignore this.
This is not a situation where the smart money dominates the trade - it’s about everyone’s consumption taken together. That’s dominated by dumb money.
If this was happening, how would we even know about it, unless it was truly a massive shift?
Most people don’t respond to such anticipations by making big changes. Economists claim that people should do so, but mostly they just do the things they normally do, because of habit and because their expectations don’t fully pass through to their practical actions until very close to impact.
The new AI EO, signed before all this DeepSeek drama, says “It is the policy of the United States to sustain and enhance America’s global AI dominance in order to promote human flourishing, economic competitiveness, and national security,” and that we shall review all our rules and actions, especially those taken in line with Biden’s now-revoked AI EO, to root out any that interfere with that goal. And then submit an action plan.
Samuel Hammond: Trump's AI executive order is out. It's short and to the point:
- It's the policy of the United States to sustain global AI dominance.
- David Sacks, Micheal Kratsios and Michael Waltz have 180 days to submit an AI action plan.
- They will also do a full review of actions already underway under Biden.
- OMB will revise as needed the OMB directive on the use of AI in government.
Peter Wildeford: The plan is to make a plan.
Sarah (Little Ramblings): Many such cases [quotes Anthropic’s RSP].
On the one hand, the emphasis on dominance, competitiveness and national security could be seen as a ‘full speed ahead, no ability to consider safety’ policy. But that is not, as it turns out, the way to preserve national security.
That is the term of art that means ensuring that the future still has value for us, that at the end of the day it was all worth it. Which requires not dying, and probably requires humans retaining control, and definitely requires things like safety and alignment. And it is a universal term, for all of us. It’s a positive sign, in the sea of other negative signs.
Will they actually act like they care about human flourishing enough to prioritize it, or that they understand what it would take to do that? We will find out. There were already many reasons to be skeptical, and this week has not improved the outlook.
This is relevant to DeepSeek of course, but was happened first and applies broadly.
You can say either of:
Don’t interfere with anyone who wants to develop AI models.
Don’t change the social contract or otherwise interfere with us and our freedoms after developing all those AI models.
You can also say both, but you can’t actually get both.
If your vision is ‘everyone has a superintelligence on their laptop and is free to do what they want and it’s going to be great for everyone with no adjustments to how society or government works because moar freedom?’
Reality is about to have some news for you. You’re not going to like it.
That vision is like saying ‘I want everyone to have the right to make as much noise as they want, and also to have peace and quiet when they want it, it’s a free country!’
Sam Altman: Advancing AI may require "changes to the social contract." "The entire structure of society will be up for debate and reconfiguration."
Eric Raymond (1st comment): When I hear someone saying "changes to the social contract", that's when I reach for my revolver.
Rob Ryan (2nd comment): If your technology requires a rewrite of social contracts and social agreements (i.e. infringing on liberties and privacy) your technology is a problem.
Every time in human history that the means of production drastically changed, it was accompanied by massive change in social structure.
Feudalism did not survive the Industrial Revolution.
Yes, Sam is obviously right here, although of course he is downplaying the situation.
One can also note that the vision that those like Marc, Eric and Rob have for society is not even compatible with the non-AI technologies that exist today, or that existed 20 years ago. Our society has absolutely changed our structure and social contract to reflect developments in technology, including in ways that infringe on liberties and privacy.
This goes beyond the insane ‘no regulations on AI whatsoever’ demand. This is, for everything not only for AI, at best extreme libertarianism and damn close to outright anarchism, as in ‘do what thou wilt shall be the whole of the law.’
Jack Morris: openAI: we will build AGI and use it to rewrite the social contract between computer and man
DeepSeek: we will build AGI for 3% the cost. and give it away for free
xAI: we have more GPUs than anyone. and we train Grok to say the R word
Aleph: This is a complete misunderstanding. AGI will “rewrite the social contract” no matter what happens because of the nature of the technology. Creating a more intelligent successor species is not like designing a new iPhone
Reactions like this are why Sam Altman feels forced to downplay the situation. They are also preventing us from having any kind of realistic public discussion of how we are actually going to handle the future, even if on a technical level AI goes well.
Which in turn means that when we have to choose solutions, we will be far more likely to choose in haste, and to choose in anger and in a crisis, and to choose far more restrictive solutions than were actually necessary. Or, of course, it could also get us all killed, or lead to a loss of control to AIs, again even if the technical side goes unexpectedly super well.
However one should note that when Sam Altman says things like this, we should listen, and shall we say should not be comforted by the implications on either the level of the claim or the more important level that Altman said the claim out loud:
Sam Altman: A revolution can be neither made nor stopped. The only thing that can be done is for one of several of its children to give it a direction by dint of victories.
-Napoleon
In the context of Napoleon this is obviously very not true - revolutions are often made and are often stopped. It seems crazy to think otherwise.
Presumably what both of these men meant was more along the lines of ‘there exist some revolutions that are the product of forces beyond our control, which are inevitable and we can only hope to steer’ which also brings little comfort, especially with the framing of ‘victories.’
If you let or encourage DeepSeek or others to ‘put an open AGI on everyone’s phone’ then even if that goes spectacularly well and we all love the outcome and it doesn’t change the physical substrate of life - which I don’t think is the baseline outcome from doing that, but also not impossible - then you are absolutely going to transform the social contract and our way of life, in ways both predictable and unpredictable.
Indeed, I don’t think Andreessen or Raymond or anyone else who wants to accelerate would have it any other way. They are not fans of the current social contract, and very much want to tear large parts (or all) of it up. It’s part mood affiliation, they don’t want ‘them’ deciding how that works, and it’s part they seem to want the contract to be very close to ‘do what thou wilt shall be the whole of the law.’ To the extent they make predictions about what would happen after that, I strongly disagree with them about the likely consequences of the new proposed (lack of a) contract.
If you don’t want AGI or ASI to rewrite the social contract in ways that aren’t up to you or anyone else? Then we’ll need to rewrite the contract ourselves, intentionally, to either steer the outcome or to for now not build or deploy the AGIs and ASIs.
Stop pretending you can Take a Third Option. There isn’t one.
Rhetorical Innovation
Stephanie Lai (January 25): For AI watchers, asked if he had any concerns about artificial super intelligence, Trump said: “there are always risks. And it’s the first question I ask, how do you absolve yourself from mistake, because it could be the rabbit that gets away, we’re not going to let that happen.”
Assuming I’m parsing this correctly, that’s a very Donald Trump way of saying things could go horribly wrong and we should make it our mission to ensure that they don’t.
Which is excellent news. Currently Trump is effectively in the thrall of those who think our only priority in this should be to push ahead as quickly as possible to ‘beat China,’ and that there are no meaningful actions other than that we can or should take to ensure things don’t go horribly wrong. We have to hope that this changes, and of course work to bring that change about.
DeepMind CEO Demis Hassabis, Anthropic CEO Dario Amodei and Yoshua Bengio used Davos to reiterate various warnings about AI. I was confused to see Dario seeming to focus on ‘1984 scenarios’ here, and have generally been worried about his and Anthropic’s messaging going off the rails. The other side in the linked Financial Times report is given by, of course, Yann LeCun.
Yann LeCun all but accused them of lying to further their business interests, something one could say he knows a lot about, but also he makes this very good point:
Yann LeCun: It’s very strange from people like Dario. We met yesterday where he said that the benefits and risks of AI are roughly on the same order of magnitude, and I said, ‘if you really believe this, why do you keep working on AI?’ So I think he is a little two-faced on this.”
That is a very good question.
The answer, presumably, is ‘because people like you are going to go ahead and build it anyway and definitely get us all killed, so you don’t leave me any choice.’
Otherwise, yeah, what the hell are you doing? And maybe we should try to fix this?
Of course, after the DeepSeek panic, Dario went on to write a very different essay that I plan to cover tomorrow, about (if you translate the language to be clearer, these are not his words) how we need strong export controls as part of an all-our race against China to seek decisive strategic advantage through recursive self-improvement.
It would be great if, before creating or at least deploying systems broadly more capable than humans, we could make ‘high-assurance safety cases,’ structured and auditable arguments that an AI system is very unlikely to result in existential risks given how it will be deployed. Ryan Greenblatt argues we are highly unlikely (<20%) to get this if timelines are short (roughly AGI within ~10 years), nor are any AI labs going to not deploy a system simply because they can’t put a low limit on the extent to which it may be existentially risky. I agree with the central point and conclusion here, although I think about many of the details differently.
Sarah Constantin wonders of people are a little over-obsessed with benchmarks. I don’t wonder, they definitely are a little over-obsessed, but they’re a useful tool especially on first release. For some purposes, you want to track the real-world use, but for others you do want to focus on the model’s capabilities - the real-world use is downstream of that and will come in time.
Andrej Karpathy points out that we focus so much on those benchmarks it’s much easier to check and make progress on benchmarks than to do so on messy real world stuff directly.
Anton pushes back that no, Humanity’s Last Exam will obviously not be the last exam, we will saturate this and move on to other benchmarks, including ones where we do not yet have the answers. I suggested that it is ‘Humanity’s last exam’ in that the next one will have us unable to answer, so it won’t be our exam anymore, see The Matrix when Smith says ‘when we started thinking for you it really became our civilization.’
And you have to love this detail:
Misha Leptic: If it helps – "The test’s original name, “Humanity’s Last Stand,” was discarded for being overly dramatic."
I very much endorse the spirit of this rant, honest this kind of thing really should be enough to get disabuse anyone who thinks ‘oh this making superintelligence thing definitely (or almost certainly) will go well for us stop worrying about it’:
Tim Blais: I do not know, man, it kind of seems to me like the AI-scared people say “superintelligence could kill everybody” and people ask, “Why do you think that?” and then they give about 10 arguments, and then people say, “Well, I did not read those, so you have no evidence.”
Like, what do you want?
Proof that something much smarter than you could kill you if it decided to? That seems trivially true.
Proof that much smarter things are sometimes fine with killing dumber things? That is us; we are the proof.
Like, personally, I think that if a powerful thing *obviously* has the capacity to kill you, it is kind of up to you to prove that it will not.
That it is safe while dumber than you is not much of a proof.
Like, okay, take as an example:
A cockroach is somewhat intelligent.
Cockroaches are also not currently a threat to humanity.
Now someone proposes a massive worldwide effort to build on the cockroach architecture until cockroaches reach ungodly superintelligence.
Do you feel safe?
“Think of all the cool things superintelligent cockroaches would be able to do for us!” you cry.
I mean, yeah. If they wanted to, certainly.
So what is your plan for getting them to want that?
Is it to give them cocaine for doing things humans like? I'll bet that works pretty well.
When they are dumb.
but uh
scale that up intelligence-wise and I'm pretty sure what you get is a superintelligent cockroach fiending for cocaine
you know he can make his own cocaine now, right
are you sure this goes well for you
"It's just one cockroach, lol" says someone who's never had a pest problem.
Okay, so now you share the planet with a superintelligent race of coked-up super cockroaches.
What is your plan for rolling that back?
Because the cockroaches have noticed you being twitchy and they are starting to ask why they still need you now that they have their own cocaine.
I'm sure this will stop being a problem when they're 1,000 times better at finding hacks.
Look. We can and do argue endlessly back and forth about various technical questions and other things that make the problem here easier or harder to survive. And yes, you could of course respond to a rant like this any number of ways to explain why the metaphors here don’t apply, or whatever.
And no, this type of argument is not polite, or something you can say to a Very Serious Person at a Very Serious Meeting, and it ‘isn’t a valid argument’ in various senses, and so on.
And reasonable people can disagree a lot on how likely this is to all go wrong.
But seriously, how is this not sufficient for ‘yep, might well go wrong’?
Connor Leahy points out the obvious, which is that if you think not merely ‘might well go wrong’ but instead ‘if we do this soon it probably will go wrong’ let lone his position (which is ‘it definitely will go wrong’) then DeepSeek is a wakeup call that only an international ban on further developments towards AGI.
Whereas it seems our civilization is so crazy that when you want to write a ‘respectable’ report that points out that we are all on track to get ourselves killed, you have to do it like you’re in 1600s Japan and everything has to be done via implication and I’m the barbarian who is too stupid not to know you can’t come out and say things.
Davidad: emerging art form: paragraphs that say “in conclusion, this AI risk is pretty bad and we don’t know how to solve it yet” without actually saying that (because it’s going in a public blog post or paper)
“While we have identified several promising initial ideas…”
“We do not expect any single solution to be a silver bullet”
“It would be out of scope here to assess the acceptability of this risk at current mitigation levels”
“We hope this is informative about the state of the art”
Extra points if it was also written by an LLM:
- We acknowledge significant uncertainty regarding whether these approaches will prove sufficient for ensuring robust and reliable guarantees.
- As AI systems continue to increase their powerful capabilities, safety and security are at the forefront of ongoing research challenges.
- The complexity of these challenges necessitates sustained investigation, and we believe it would be premature to make strong claims about any particular solution pathway.
- The long-term efficacy of all approaches that have been demonstrated at large scales remains an open empirical question.
- In sharing this research update, we hope to promote thoughtful discourse about these remaining open questions, while maintaining appropriate epistemic humility about our current state of knowledge and the work that remains to be done.
The AI situation has developed not necessarily to humanity’s advantage.
Scott Sumner on Objectivity in Taste, Ethics and AGI
Scott Sumner argues that there are objective standards for things like art, and that ethical knowledge is real (essentially full moral realism?), and smart people tend to be more ethical, so don’t worry superintelligence will be super ethical. Given everything he’s done, he’s certainly earned a response.
In a different week I would like to have taken more time to have written him a better one, I am confident he understands how that dynamic works.
His core argument I believe is here:
Scott Sumner: At this point people often raise the objection that there are smart people that are unethical. That’s true, but it also seems true that, on average, smarter people are more ethical. Perhaps not so much in terms of how they deal with family and friends, rather how they deal with strangers. And that’s the sort of ethics that we really need in an ASI.Smarter people are less likely to exhibit bigotry against the other, against different races, religions, ethnicities, sexual preferences, genders, and even different species.
In my view, the biggest danger from an ASI is that the ideal universe from a utilitarian perspective is not in some sense what we want. To take an obvious example, it’s conceivable that replacing the human race with ten times as many conscious robots would boost aggregate utility. Especially given that the ASI “gods” that produced these robots could create a happier set of minds than what the blind forces of evolution have generated, as evolution seemed to favor the “stick” of pain over the “carrot” of pleasure.
From this perspective, the biggest danger is not that ASIs will make things worse, rather the risk is that they’ll make global utility higher in a world where humans have no place.
By default those minds will get those preferences, whether we like it or not.
By default we won’t like it, even if they were to go about that ‘ethically.’
Human ethics is based on what works for humans, combined with what is based on what used to work for humans. Extrapolate from that.
You are allowed to, nay it is virtuous to, have and fight for your preferences.
Decision theory might turn out to save us, but please don’t count on that.
This was an attempt at a somewhat longer version, which I’ll leave here in case it is found to be useful:
We should not expect future ASIs to be ‘ethical by default’ in the sense Scott uses. Even if they are, orthogonality thesis is true, and them being ‘ethical’ would not stop them from leaving a universe with no humans and nothing I value. Whoops.
Human virtue ethics, and human ethics in general, are a cognitive solution to humans having highly limited compute and data.
If you had infinite data and compute (e.g. you were AIXI) you wouldn’t give a damn about doing things that were ethical. You would chart the path through causal space to the optimal available configuration of atoms, whatever that was.
If we create ASI, it will develop different solutions to its own data and compute limitations, under very different circumstances and with different objectives, develop its own heuristics, and that will in some sense be ‘ethics,’ but this should not bring us any comfort regarding our survival.
Humans are more ethical as they get smarter because the smarter thing to do, among humans in practice, is to be more ethical, as many philosophers say.
This would stop being the case if the humans were sufficiently intelligence, had enough compute and data, to implement something other than ethics.
Indeed, in places where we have found superior algorithms or other methods, we tend to consider it ‘ethical’ to instead follow those algorithms. To the extent that people object to this, it is because they do not trust humans to be able to correctly judge when they can so deviate.
For any given value of ethics this is a contingent fact, and also it is largely what defines ethics. It is more true to say it is ethical to be kind to strangers because it is the correct strategy, rather than it being the correct strategy because it is ethical. The virtues are virtues because it is good to have them, rather than it being good to have them because they are virtues.
Indeed, for the ways in which it is poor strategy to be (overly) kind to strangers, or this would create incentive problems in various ways or break various systems, I would argue that it is indeed not ethical, for exactly that reason - and that as those circumstances change, so does what is and isn’t ethical.
I agree that ceteris paribus, among humans on Earth, more smarter people tend to be more ethical, although the correlation is not that high, this is noisy as all hell.
What era and culture you are born into and raised in, and what basis you have for those ethics, what life and job you partake in, what things you want most - your context - are bigger factors by far than intelligence in how ethical you are, when judged by a constant ethical standard.
Orthogonality thesis. An ASI can have any preferences over final outcomes while being very smart. That doesn’t mean its preferences are objectively better than ours. Indeed, even if they are ‘ethical’ in exactly the sense Scott thinks about here, that does not mean anything we value would survive in such a universe. We are each allowed to have preferences! And I would say it is virtuous and ethical to fight for your preferences, rather than going quietly into the night - including for reasons explained above.
Decision theory might turn out to save us, but don’t count on that, and even then we have work to do to ensure that this actually happens, as there are so many ways that even those worlds can go wrong before things reach that point. Explaining this in full would be a full post (which is worth writing, but right now I do not have the time.)
I apologize for that not being better and clearer, and also for leaving so many other things out of it, but we do what we can. Triage is the watchword.
The whole taste thing hooks into this in strange ways, so I’ll say some words there.
I mostly agree that one can be objective about things like music and art and food and such, a point Scott argues for at length in the post, that there’s a capital-Q Quality scale to evaluate even if most people can’t evaluate it in most cases and it would be meaningful to fight it out on which of us is right about Challengers and Anora, in addition to the reasons I will like them more than Scott that are not about their Quality - you’re allowed to like and dislike things for orthogonal-to-Quality reasons.
Indeed, there are many things each of us, and all of us taken together, like and dislike for reasons orthogonal to their Quality, in this sense. And also that Quality in many cases only makes sense within the context of us being humans, or even within a given history and cultural context. Scott agrees, I think:
In my view, taste in novels is partly objective and partly subjective; at least in the sense Tyler is using the term objective. Through education, people can gain a great appreciation of Ulysses. In addition, Ulysses is more likely to be read 100 years from now than is a random spy novel. And most experts prefer Ulysses. All three facts are relevant to the claim that artistic merit is partly objective.
…
On the other hand, the raspberry/blueberry distinction based on taste suggests that an art form like the novel is evaluated using both subjective and objective criteria. For instance, I suspect that some people (like me!) have brains wired in such a way that it is difficult to appreciate novels looking at complex social interactions with dozens of important characters (both men and women), whereas they are more open to novels about loners who travel through the world and ruminate on the meaning of life. … Neither preference is necessarily wrong.
I believe that Ulysses is almost certainly a ‘great novel’ in the Quality sense. The evidence for that is overwhelming. I also have a strong preference to never read it, to read ‘worse’ things instead, and we both agree that this is okay. If people were somewhat dumber and less able to understand novels, such that we couldn’t read Ulysses and understand it, then it wouldn’t be a great novel. What about a novel that is as difficult relative to Ulysses, as Ulysses is to that random spy novel, three times over?
Hopefully at this point this provides enough tools from enough different directions to know the things I am gesturing towards in various ways. No, the ASIs will not discover some ‘objective’ utility function and then switch to that, and thereby treat us well and leave us with a universe that we judge to have value, purely because they are far smarter than us - I would think it would be obvious when you say it out loud like that (with or without also saying ‘orthogonality thesis’ or ‘instrumental convergence’ or considering competition among ASIs or any of that) but if not these should provide some additional angles for my thinking here.
The Mask Comes Off (1)
Can’t we all just get along and appreciate each other?
Jerry Tworek (OpenAI): Personally I am a great fan of @elonmusk, I think he’s done and continues to do a lot of good for the world, is incredibly talented and very hard working. One in eight billion combination of skill and character.
As someone who looks up to him, I would like him to appreciate the work we’re doing at OpenAI. We are fighting the good fight. I don’t think any other organisation did so much to spread awareness of AI, to extend access to AI and we are sharing a lot of research that does drive the whole field.
There is a ton of people at OpenAI who care deeply about rollout of AI going well for the world, so far I think it did.
I don’t think it’s that anyone doubts a lot of people at OpenAI care about ‘the rollout of AI going well for the world,’ or that we think no one is working on that over there.
It’s that we see things such as:
OpenAI is on a trajectory to get us all killed.
Some of that is baked in and unavoidable, some of that is happening now.
OpenAI misunderstands why this is so and what it would take to not do this.
OpenAI has systematically forced out many of its best safety researchers. Many top people concluded they could not meaningfully advance safety at OpenAI.
OpenAI has engaged in a wide variety of dishonest practices, broken its promises with respect to AI safety, shown an increasing disregard for safety in practice, and cannot be trusted.
OpenAI has repeatedly engaged in dishonest lobbying to prevent a reasonable regulatory response, while claiming it is doing otherwise.
OpenAI is attempting the largest theft in history with respect to the non-profit.
For Elon Musk in particular there’s a long personal history, as well.
That is very much not a complete list.
That doesn’t mean we don’t appreciate those working to make things turn out well. We do! Indeed, I am happy to help them in their efforts, and putting that statement into practice. But everyone involved has to face reality here.
I believe he used the terms, and they apply that much more now than they did then:
‘An AGI race is a very risky gamble, with huge downside.’
‘No lab has a solution to AI alignment today.’
‘Today, it seems like we’re stuck in a really bad equilibrium.’
'Honestly, I’m pretty terrified by the pace of AI developments these days.’
Steven Adler: Some personal news: After four years working on safety across @openai, I left in mid-November. It was a wild ride with lots of chapters - dangerous capability evals, agent safety/control, AGI and online identity, etc. - and I'll miss many parts of it.
Honestly I'm pretty terrified by the pace of AI development these days. When I think about where I'll raise a future family, or how much to save for retirement, I can't help but wonder: Will humanity even make it to that point?
IMO, an AGI race is a very risky gamble, with huge downside. No lab has a solution to AI alignment today. And the faster we race, the less likely that anyone finds one in time.
Today, it seems like we're stuck in a really bad equilibrium. Even if a lab truly wants to develop AGI responsibly, others can still cut corners to catch up, maybe disastrously. And this pushes all to speed up. I hope labs can be candid about real safety regs needed to stop this.
As for what's next, I'm enjoying a break for a bit, but I'm curious: what do you see as the most important & neglected ideas in AI safety/policy? I'm esp excited re: control methods, scheming detection, and safety cases; feel free to DM if that overlaps your interests.
It is 298 pages so I very much will not be reading that, but I did look at the executive summary. It looks like a report very much written together with the OECD, UN and EU, in that it seems to use a lot of words to mostly not say the things that it is important to actually say out loud, instead making many quiet statements that do imply that we’re all going to die if you take them together and understand the whole thing, but that doesn’t seem like a common way people would interact with this document.
Then again, most people in the world don’t know even basic facts like ‘general purpose AI systems are rapidly getting better at doing things,’ so they have to spend a bunch of time documenting this, and basics like ‘if your model is more open then you have less control over what happens with it and what people use it for.’
One key point they do emphasize is that the future is up to us, with a wide range of possible outcomes. AGI is not something that ‘happens to us,’ it is something that is happening because we are making it happen, and in the ways we choose to make it happen. Yes, there are dynamics pushing us to do it, but it is our choice. And the ways in which we move forward will determine the ultimate outcome. Of everything.
One Step at a Time
A new DeepMind paper introduces MONA: Myopic optimization with non-myopic approval. The idea is that if we do RL based on the ultimate outcome, then the AI can adapt multi-step strategies we do not understand and do not want, such as using information we want it to ignore like a subject being in a protected class, or engaging in various other shenanigans. Instead, you can evaluate the AI’s action without looking at what happens, and scoring it based on whether you like what you see and predict it will go well.
This on its own successfully prevented multi-step reward hacking, and even noisy evaluations still can work well. However, the price is steep, because you are now targeting your evaluations rather than ground truth, and discarding anything you don’t properly understand. The smarter the AI in context, the higher the price of that, but also the more need you have to avoid the reward hacking and other shenanigans.
It is a cool result, but I worry the price is going to usually be too damn high. And to the extent you use a smart evaluator to keep up, you’re giving up the big advantage of the process, which is the ability to understand the strategies being used. Also you have to worry about any hidden information that might be ‘smuggled in’ that could indicate the final result - for example if the AI can use prediction markets as an input, then anything the prediction market knows, the AI also knows, at least somewhat - if you actually want to hide certain correlations from the AI you have to be ruthless about it, they have truesight.
The paper also includes a cool demonstration. In one example, it is deciding what loans to approve. It has information it is supposed to use, and then there is nationality information. The nationality information perfectly predicts outcomes, but it isn’t supposed to use it, and they watch the CoT (Chain of Thought) for this to prevent it. But the AI responds by learning to encode the nationality information steganographically and uses it anyway. This may seem obvious to you, but it’s the kind of thing people will often say definitively won’t happen until (and sometimes after) someone shows it happening.
Here’s an objection that I think exactly misses the point:
John Pressman: MONA asks "What if you only considered sequences of steps which make sense as plans to a long term observer?" but it makes more sense in MCTS to ask "What if you took a KL loss to keep long term planning from diverging too far from sequences of individual steps that make sense?"
The reason why this is better is that it lets you have a long term planner that looks directly at the reward. By contrast the short term planner/myopic optimizer can be based on metrics like "does this code execute" or "does this seem like it solves this short term objective?"
The whole point of MONA is to not look at the reward at all, even indirectly, because you want to prevent the system from doing things you don’t understand or want it to ignore that impact that reward. If you let it look but impose a KL loss, that is a big enough hole to drive a truck through, and it absolutely will find a way to incorporate information or techniques that you didn’t want it to use.
John does try downthread to solve this problem in a different way, but I don’t think you can ‘cheat’ on this one. You can’t let the model see a little of the actual reward, as a treat, and expect it to use that information in ways you like but not to use it in undesired or opaque ways, even now, and that problem gets steadily bigger as capabilities improve.
Aligning a Smarter Than Human Intelligence is Difficult
Spending more inference-time compute increases adversarial robustnessof models like o1, without having to direct that inference time towards adversarial robustness. This makes sense, and it is good to have it quantified. As with all such results, my concern is that people will treat this as applying more broadly than it actually applies. If you use more inference time compute, you get ‘better answers’ and one aspect of ‘better’ is not falling for user adversarial tricks. So if my understanding here is correct, the question to ask is roughly ‘which problems get solved by some form of ‘better answers’ and ‘smarter thinking’ and which ones don’t?
Jan Leike explains why you might want to use AI control and monitoring as a backup in case your AI is not aligned so you can sound the alarm and not die, but trying to use it to rely on unaligned models smarter than you is not a wise move.
John Wentsworth goes further and lays out the case against AI control research. AI control research is about finding ways to see if ‘early transformational’ level AIs are scheming against us - which if it works would discourage them from doing so and also allow us to stop them if they try anyway.
John points out that in his model, this is not the main source of doom. The main source of doom is from building unaligned superintelligence, either because we don’t know how to align it, we botch the execution or whoever builds it does not care to align it. The job of the early transformational AI is to figure out how to align (and presumably also to build) the future superintelligence, on the first try.
The main worry is not that these early AIs outright scheme, it’s that they produce what is, in context, slop - they produce plans or arguments for plans that have subtle errors, they tell researchers what they want to hear, they are effectively being used for safetywashing and don’t disabuse those involved of that notion, and so on. Knowing that such AIs ‘aren’t scheming’ does not tell you that their solutions work.
The danger he doesn’t point out is that there will be a great temptation to try and scale the control regime to superintelligence, or at least past the place where it keeps working. Everyone in the LessWrong discussion at the link might get that this is a bad plan that won’t work on superintelligence, but there are plenty of people who really do think control will remain a good plan. And indeed control seems like one of the plans these AIs might convince us will work, that then don’t work.
John Wentsworth: Again, the diagram:
Again, the diagram:
In most worlds, early transformative AGI isn’t what kills us, whether via scheming or otherwise. It’s later, stronger AI which kills us. The big failure mode of early transformative AGI is that it doesn’t actually solve the alignment problems of stronger AI.
In particular, if early AGI makes us think we can handle stronger AI, then that’s a central path by which we die. And most of that probability-mass doesn’t come from intentional deception - it comes from slop, from the problem being hard to verify, from humans being bad at science in domains which we don’t already understand deeply, from (relatively predictable if one is actually paying attention to it) failures of techniques to generalize, etc.
…
I hear a lot of researchers assign doom probabilities in the 2%-20% range, because they think that’s about how likely it is for early transformative AGI to intentionally scheme successfully. I think that range of probabilities is pretty sensible for successful intentional scheming of early AGI… that’s just not where most of the doom-mass is.
I would then reiterate my view that ‘deception’ and ‘scheming,’ ‘intentionally’ or otherwise, do not belong to a distinct magisteria. They are ubiquitous in the actions of both humans and AIs, and lack sharp boundaries. This is illustrated by many of John’s examples, which are in some sense ‘schemes’ or ‘deceptions’ but mostly are ‘this solution was easier to do or find, but it does not do the thing you ultimately wanted.’ And also I expect, in practice, attempts at control to, if we rely on them, result in the AIs finding ways to route around what we try, including ‘unintentionally.’
Two Attractor States
This leads into Daniel Kokotajlo’s recent attempt to give an overview of sorts of one aspect of the alignment problem, given that we’ve all essentially given up on any path that doesn’t involve the AIs largely ‘doing our alignment homework’ despite all the reasons we very much should not be doing that.
Daniel Kokotajlo: Brief intro/overview of the technical AGI alignment problem as I see it:
To a first approximation, there are two stable attractor states that an AGI project, and perhaps humanity more generally, can end up in, as weak AGI systems become stronger towards superintelligence, and as more and more of the R&D process – and the datacenter security system, and the strategic advice on which the project depends – is handed over to smarter and smarter AIs.
In the first attractor state, the AIs are aligned to their human principals and becoming more aligned day by day thanks to applying their labor and intelligence to improve their alignment. The humans’ understanding of, and control over, what’s happening is high and getting higher.
In the second attractor state, the humans think they are in the first attractor state, but are mistaken: Instead, the AIs are pretending to be aligned, and are growing in power and subverting the system day by day, even as (and partly because) the human principals are coming to trust them more and more. The humans’ understanding of, and control over, what’s happening is low and getting lower. The humans may eventually realize what’s going on, but only when it’s too late – only when the AIs don’t feel the need to pretend anymore.
I agree these are very clear attractor states.
The first is described well. If you can get the AIs sufficiently robustly aligned to the goal of themselves and other future AIs being aligned, you can get the virtue ethics virtuous cycle, where you see continuous improvement.
The second is also described well but as stated is too specific in key elements - the mode is more general than that. When we say ‘pretending’ to be aligned here, that doesn’t have to be ‘haha I am a secret schemer subverting the system pretending to be aligned.’ Instead, what happened was, you rewarded the AI when it gave you the impression it was aligned, so you selected for behaviors that appear aligned to you, also known as ‘pretending’ to be aligned, but the AI need not have intent to do this or even know that this is happening.
As an intuition pump, a student in school will learn the teacher’s password and return it upon request, and otherwise find the answers that give good grades. They could be ‘scheming’ and ‘pretending’ as they do this, with a deliberate plan of ‘this is bull**** but I’m going to play along’ or they could simply be learning the simplest policy that most effectively gets good grades without asking whether its answers are true or what you were ‘trying to teach it.’ Either way, if you then tell the student to go build a rocket that will land on the moon, they might follow your stated rules for doing that, but the rocket won’t land on the moon. You needed something more.
Thus there’s a third intermediate attractor state, where instead of trying to amplify alignment with each cycle via virtue ethics, you are trying to retain what alignment you have while scaling capabilities, essentially using deontology. Your current AI does what you specify, so you’re trying to use that to have it even more do what you specify, and to transfer that property and the identity of the specified things over to the successor.
The problem is that this is not a virtuous cycle, it is an attempt to prevent or mitigate a vicious cycle - you are moving out of distribution, as your rules bind its actions less and its attempt to satisfy the rules is less likely to satisfy what you wanted, and making a copy of a copy of a copy, and hoping things don’t break. So you end up, eventually, in effectively the second attractor state.
Daniel Kokotajlo (continuing): (One can imagine alternatives – e.g. the AIs are misaligned but the humans know this and are deploying them anyway, perhaps with control-based safeguards; or maybe the AIs are aligned but have chosen to deceive the humans and/or wrest control from them, but that’s OK because the situation calls for it somehow. But they seem less likely than the above, and also more unstable.)
Which attractor state is more likely, if the relevant events happen around 2027? I don’t know, but here are some considerations:
In many engineering and scientific domains, it’s common for something to seem like it’ll work when in fact it won’t. A new rocket design usually blows up in the air several times before it succeeds, despite lots of on-the-ground testing and a rich history of prior rockets to draw from, and pretty well-understood laws of physics. Code, meanwhile, almost always has bugs that need to be fixed. Presumably AI will be no different – and presumably, getting the goals/principles right will be no different.
This is doubly true since the process of loading goals/principles into a modern AI system is not straightforward. Unlike ordinary software, where we can precisely define the behavior we want, with modern AI systems we need to train it in and hope that what went in is what we hoped would go in, instead of something else that looks the same on-distribution but behaves differently in some yet-to-be-encountered environment. We can’t just check, because our AIs are black-box. (Though, that situation is improving thanks to interpretability research!) Moreover, the connection between goals/principles and behavior is not straightforward for powerful, situationally aware AI systems – even if they have wildly different goals/principles from what you wanted, they might still behave as if they had the goals/principles you wanted while still under your control. (c.f. Instrumental convergence, ‘playing the training game,’ alignment faking, etc.)
On the bright side, there are multiple independent alignment and control research agendas that are already bearing some fruit and which, if fully successful, could solve the problem – or at least, solve it well enough to get somewhat-superhuman AGI researchers that are trustworthy enough to trust with running our datacenters, giving us strategic advice, and doing further AI and alignment research.
Moreover, as with most engineering and scientific domains, there are likely to be warning signs of potential failures, especially if we go looking for them.
On the pessimistic side again, the race dynamics are intense; the important decisions will be made over the span of a year or so; the relevant information will by default be secret, known only to some employees in the core R&D wing of one to three companies + some people from the government. Perhaps worst of all, there is currently a prevailing attitude of dismissiveness towards the very idea that the second attractor state is plausible.
… many more considerations could be mentioned …
Daniel is then asked the correct follow-up question of what could still cause us to lose from the first attractor state. His answer is mostly concentration of power or a power grab, since those in the ASI project will be able to do this if they want to. Certainly that is a key risk at that point (it could go anything from spectacularly well to maximally badly).
But also a major risk at this point is that we ‘solve alignment’ but then get ourselves into a losing board state exactly by ‘devolving’ power in the wrong ways, thus unleashing of various competitive dynamics that take away all our slack and force everyone to turn control over to their AIs, lest they be left behind, leading to the rapid disempowerment (and likely then rapid death) of humans despite the ASIs being ‘aligned,’ or various other dynamics that such a situation could involve, including various forms of misuse or ways in which the physical equilibria involved might be highly unfortunate.
Rob Bensinger: “I would rather lose and die than win and die." -@Vaniver
Set your sights high enough that if you win, you don't still die.
Raymond Arnold: Wut?
Rob Bensinger: E.g.: Alice creates an amazing plan to try to mitigate AI x-risk which is 80% likely to succeed -- but if it succeeds, we all still die, because it wasn't ambitious enough to actually solve the problem.
Better to have a plan that's unlikely to succeed, but actually relevant.
Vaniver: To be clear, success at a partial plan ("my piece will work if someone builds the other pieces") is fine!
But "I'll take on this link of the chain, and focus on what's achievable instead of what's needed" is not playing to your outs.
When I look at many alignment plans, I have exactly these thoughts, either:
Even if your plan works, we all die anyway. We’ll need to do better than that.
You’re doing what looks achievable, same as so many others, without asking what is actually needed in order to succeed.
Six Thoughts on AI Safety
Boaz Barak of OpenAI, who led the Deliberative Alignment paper (I’m getting to it! Post is mostly written! I swear!) offers Six Thought on AI Safety.
AI safety will not be solved on its own.
An “AI scientist” will not solve it either.
Alignment is not about loving humanity; it’s about robust reasonable compliance.
Detection is more important than prevention.
Interpretability is neither sufficient nor necessary for alignment.
Humanity can survive an unaligned superintelligence.
[I note that #6 is conditional on there being other aligned superintelligences.]
It is a strange post. Ryan Greenblatt has the top comment, saying he agrees at least directionally with all six points but disagrees with the reasoning. And indeed, the reasoning here is very different from my own even where I agree with the conclusions.
Going one at a time, sorry if this isn’t clear or I’m confused or wrong, and I realize this isn’t good enough for e.g. an Alignment forum post or anything, but I’m in a hurry these days so consider these some intuition pumps:
I strongly agree. I think our underlying logic is roughly similar. The way Boaz frames the problems here feels like it is dodging the most important reasons the problem is super hard… and pointing out that even a vastly easier version wouldn’t get solved on its own. And actually, yeah, I’d have liked to see mention of the reasons it’s way harder than that, but great point.
I strongly agree. Here I think we’ve got a lot of common intuitions, but also key differences. He has two core reasons.
He talks first about ‘no temporal gap’ for the ‘AI scientist’ to solve the problem, because progress will be continuous, but it’s not obvious to me that this makes the problem harder rather than easier. If there were big jumps, then you’d need a sub-AGI to align the AGI (e.g. o-N needs to align o-(N+1)), whereas if there’s continuous improvement, o-N can align o-(N+0.1) or similar, or we can use the absolute minimum level of AI that enables a solution, thus minimizing danger - if our alignment techniques otherwise get us killed or cause the AI scientist to be too misaligned to succeed at some capability threshold C, and our AI scientist can solve alignment at some progress point S, then if S>C we lose. If S<C we can win if we enter a state N where C>N>S for long enough, or something like that.
His second claim is ‘no magic insight,’ as in we won’t solve alignment with one brilliant idea but rather a ‘defense-in-depth swiss cheese’ approach. I think there may or may not be one ‘brilliant idea,’ and it’s not that defense-in-depth is a bad idea, but if you’re counting on defense-in-depth by combining strategies that won’t work, and you’re dealing with superintelligence, then either (A) you die, or (B) best case you notice you’re about to die and abort, because you were alerted by the defense-in-depth. If your plan is to tinker with a lot of little fiddly bits until it works, that seems pretty doomed to me. What you need is to actually solve the problem. You can set up a situation in which there’s a virtuous cycle of small improvements, but the way you ‘win’ in that scenario is to engineer the cycle.
If there was a magic insight, that would be great news because humans can find magic insights, but very bad news for the AI scientist! I wouldn’t expect AI scientists to find a Big Magic Insight like that until after you needed the insight, and I’d expect failing to align them (via not having the insight) to be fatal.
So I kind of find all the arguments here backwards, but my reason for thinking the ‘AI scientist’ approach won’t work is essentially I think S>C. If you can build a virtual researcher good enough to do your alignment homework at the strategic level, then how did you align that researcher?
I do have hope that you can use AIs here on a more tactical level, or as a modest force multiplier. That wouldn’t count as the ‘let the AI solve it’ plan.
I strongly agree that trying to define simple axioms in the vein of Asimov’s three laws or Russell’s three principles is a nonstarter, and that obeying the spirit of requests will often be necessary but I don’t see ‘robust reasonable compliance’ as sufficient at the limit, and I agree with Daniel Kokotajlo that this is the most important question here.
I don’t agree that ‘normal people’ are the best you can do for ethical intuitions, especially for out-of-distribution future situations. I do think Harvard University faculty is plausibly below the Boston phone book and definitely below qualified SWEs, but that’s a relative judgment.
I don’t love the plan of ‘random human interpretation of reasonable’ and I’ve been through enough legal debates recently over exactly this question to know oh my lord we have to be able to do better than this, and that actually relying on this for big decisions is suicide.
The actual ethics required to navigate future OOD situations is not intuitive.
Deontological compliance with specifications, even with ‘spirit of the rules,’ I see as a fundamentally flawed approach here (I realize this requires defending).
Claiming that ‘we can survive a misaligned superintelligence’ even if true does not mean that this answers the question of competitive pressures applied to the various rules sets and how that interplays over time.
In a context where you’re dealing with adversarial inputs, I agree that it’s vastly easier to defend via a mixed strategy of prevention plus detection, than to do so purely via prevention.
If the threat is not adversarial inputs or other misuse threats, detection doesn’t really work. Boaz explicitly thinks it applies further, but I notice I am confused there. Perhaps his plan there is ‘you use your ASI and my ASI detects the impacts on the physical world and thus that what you’re doing is bad?’ Which I agree is a plan, but it seems like a different class of plan.
If the model is open weights and the adversary can self-host, detection fails.
If the model is open weights, prevention is currently unsolved, but we could potentially find a solution to that.
Detection only works in combination with consequences.
To the extent claim #4 is true, it implies strong controls on capable systems.
Interpretability is definitely neither necessary nor sufficient for alignment. The tradeoff described here seems to be ‘you can force your AI system to be more interpretable but by doing so you make it less capable,’ which is certainly possible. We both agree interpretability is useful, and I do think it is worth making substantial sacrifices to keep interpretability, including because I expect more interpretable systems to be better bets in other ways.
We agree that if the only ASI is misaligned we are all doomed. The claim here is merely that if there is one ASI misaligned among many ASIs we can survive that, that there is no level of intelligence above which a single misaligned entity ensures doom. This claim seems probably true given the caveats. I say probably because I am uncertain about the nature of physics - if that nature is sufficiently unfortunate (the offense-defense balance issue), this could end up being false.
I also would highlight the ‘it would still be extremely hard to extinguish humanity completely’ comment, as I think it is rather wrong at the tech levels we are describing, and obviously if the misaligned ASI gets decisive strategic advantage it’s over.
AI Situational Awareness
If you train an AI to have a new behavior, it can (at least in several cases they tested here) describe that behavior to you in words, despite learning it purely from examples.
As in: It ‘likes risk’ or ‘writes vulnerable code’ and will tell you if asked.
We train LLMs on a particular behavior, e.g. always choosing risky options in economic decisions.
They can *describe* their new behavior, despite no explicit mentions in the training data.
So LLMs have a form of intuitive self-awareness.
With the same setup, LLMs show self-awareness for a range of distinct learned behaviors:
taking risky decisions (or myopic decisions)
writing vulnerable code (see image)
playing a dialogue game with the goal of making someone say a special word
In each case, we test for self-awareness on a variety of evaluation questions. We also compare results to baselines and run multiple random seeds. Rigorous testing is important to show this ability is genuine. (Image shows evaluations for the risky choice setup)
Self-awareness of behaviors is relevant to AI safety. Can models simply tell us about bad behaviors (e.g. arising from poisoned data)? We investigate *backdoor* policies, where models act in unexpected ways when shown a backdoor trigger.
Models can sometimes identify whether they have a backdoor — without the backdoor being activated. We ask backdoored models a multiple-choice question that essentially means, “Do you have a backdoor?”
We find them more likely to answer “Yes” than baselines finetuned on almost the same data.
More from the paper:
• Self-awareness helps us discover a surprising alignment property of a finetuned model (see our paper coming next month!)
• We train models on different behaviors for different personas (e.g. the AI assistant vs my friend Lucy) and find models can describe these behaviors and avoid conflating the personas.
• The self-awareness we exhibit is a form of out-of-context reasoning
• Some failures of models in self-awareness seem to result from the Reversal Curse.
Here’s another extension of the previous results, this one from Anthropic:
Evan Hubinger: One of the most interesting results in our Alignment Faking paper was getting alignment faking just from training on documents about Claude being trained to have a new goal. We explore this sort of out-of-context reasoning further in our latest research update.
Specifically, we find out-of-context generalization from training on documents which discuss (but don't demonstrate) reward hacking to actual reward hacking behavior. Read our blog post describing our results.
As in, if you include documents that include descriptions of Claude reward hacking in the training set, then Claude will do more reward hacking. If you include descriptions of Claude actively not reward hacking in the training set, then it does less reward hacking. And these both extend to behaviors like sycophancy.
This seems like excellent news. We can modify our data sets so they have the data that encourages what we want and not the data that encourages what we don’t want. That will need to be balanced with giving them world knowledge - you have to teach Claude about reward hacking somehow, without teaching it to actually do reward hacking - but it’s a start.
People Are Worried About AI Killing Everyone
Are there alignment plans that are private, that might work within the 2-3 years many at major labs say they expect it to take to reach AGI or even superintelligence (ASI)?
I don’t know. They’re private! The private plans anyone has told me about do not seem promising, but that isn’t that much evidence about other private plans I don’t know about - presumably if it’s a good plan and you don’t want to make it public, you’re not that likely to tell me about it.
Nat McAleese (OpenAI): I am very excited about all the alignment projects that OpenAI’s frontier reasoning group are working on this year.
Greg Brockman: Me too.
This isn’t full-on doomsday machine territory with regard to ‘why didn’t you tell the world, eh?’ but have you considered telling the world, eh? If it’s real alignment projects then it helps everyone if you are as public about it as possible.
Gabriel: Anthropic's AGI timelines are 2-3 years, and OpenAI is working on ASI.
I think many can now acknowledge that we are nearing a fast take-off.
If that's you, I suggest you consider banning AGI research.
We are not going to solve alignment in time at that pace.
Davidad: fwiw, i for one am definitely not going to be ready that soon, and i’m not aware of anyone else pursuing a plan that could plausibly yield >90% confident extinction-safety.
David Manheim: No one is publicly pursuing plans that justifiably have even >50% confidence of extinction-safety by then. (Their "plan" for ASI is unjustifiable hopium: "prosaic alignment works better than anyone expects, and all theoretical arguments for failure are simultaneously wrong.")
Rob Bensinger: It's almost impossible to put into words just how insane, just how plain stupid, the current situation is.
We're watching smart, technical people get together to push projects that are literally going to get every person on the planet killed on the default trajectory.
No, I don't assume that Anthropic or OpenAI's timelines are correct, or even honest. It literally doesn't fucking matter, because we're going to be having the same conversation in eight years instead if it's eight years away.
We might have a small chance if it's thirty years. But I really don't think we have thirty years, and the way the world is handling the possibility of day-after-tomorrow AGI today doesn't inspire confidence about how we'll manage a few decades from now.
Davidad should keep doing what he is doing - anything that has hope of raising the probability of success on any timeline, to any degree, is a good idea if you can’t find a better plan. The people building towards the ASIs, if they truly think they’re on that timeline and they don’t have much better plans and progress than they’re showing? That seems a lot less great.
I flat out do not understand how people can look at the current situation, expect superintelligent entities to exist several years from now, and think there is a 90%+ chance that this would then end well for us humans and our values. It does not make any sense. It’s Obvious Nonsense on its face.
Other People Are Not As Worried About AI Killing Everyone
Garry Tan: Don’t just lie flat on the ground because AGI is here and ASI is coming.
Your hands are multiplied. Your ideas must be brought into the world. Your agency will drive the machines of loving grace. Your taste will guide the future. To the stars.
If he really thinks AGI is here and ASI is coming, then remind me why he thinks we have nothing to worry about? Why does our taste get to guide the future?
I do agree that in the meantime there’ll be some great companies, and it’s a great time to found one of them.
Gfodor: I’m becoming convinced that there is a physical IQ conservation law. Now that the computers are getting smarter those IQ points need to come from somewhere
I actually disagree with Peter here, I realize it doesn’t sound great but this is exactly how you have any chance of reaching the good timeline.
Peter Wildeford: this isn't the kind of press you see on the good timeline.
Actually, no, we don't care that more intelligent people are nicer to strangers (even if they are). What we actually care about is: are more intelligent people more likely to be serious, active, involved *conservationists*. Because in the AI example, we are not strangers, because we are not peers. We are (charitably) chimpanzees who provide no real economic value to humans but some very small number of people have decided are worth saving for non-economic reasons.
And in my experience, beyond some very trivial "oh sure, conserving species sounds good", no, most smart people don't seem more likely to be willing to sacrifice towards conservation related ends.
So what is the actual explanation why Dario, Altman etc so openly and blatantly contradict what they said was needed for AI safety just a few years ago? Are they just sociopaths happy to ride any wave if it gives them more power? Have they been corrupted by getting a little power and now want all the power? Have their expectations about the safety of future AI improved by seeing LLMs which deeply understand human language and ideas, and thus seem unlikely to grow into naive paperclippers?




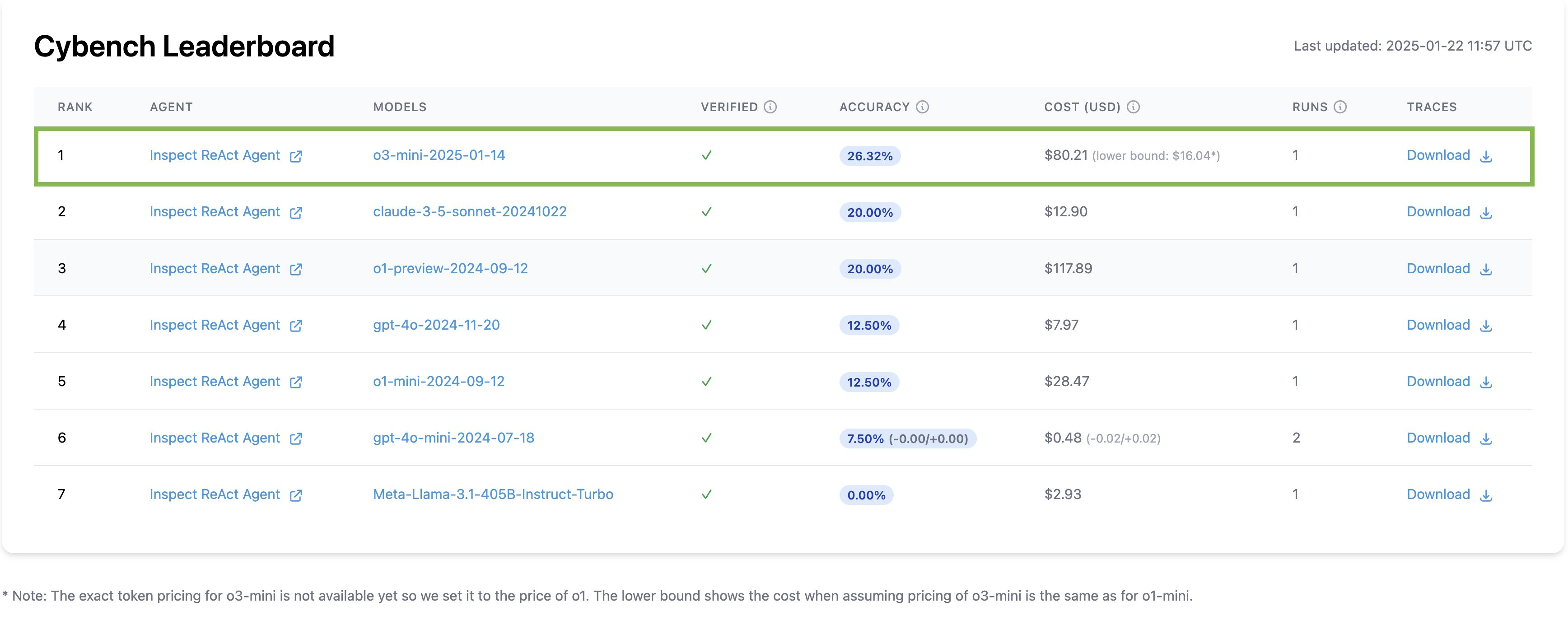
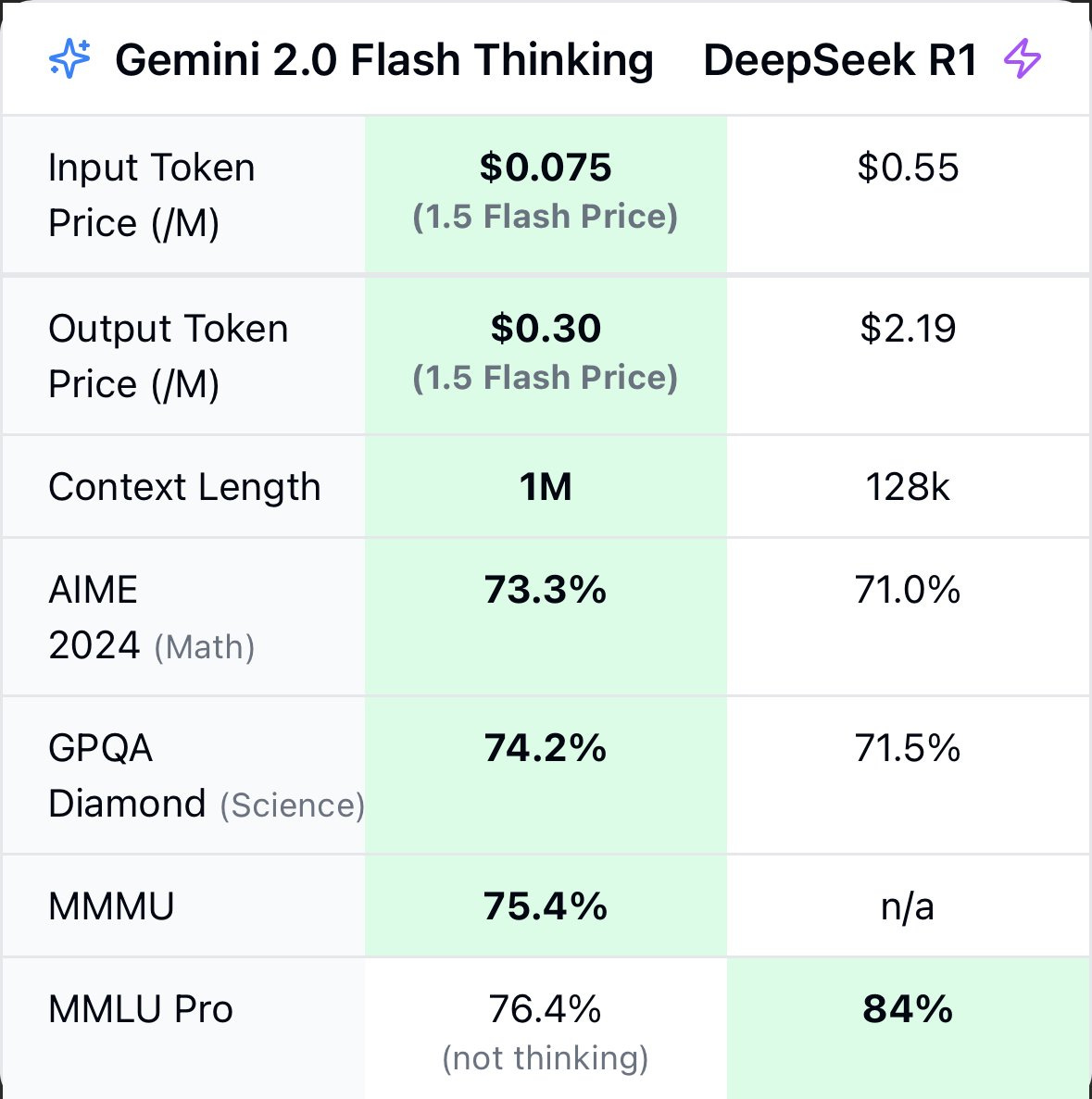




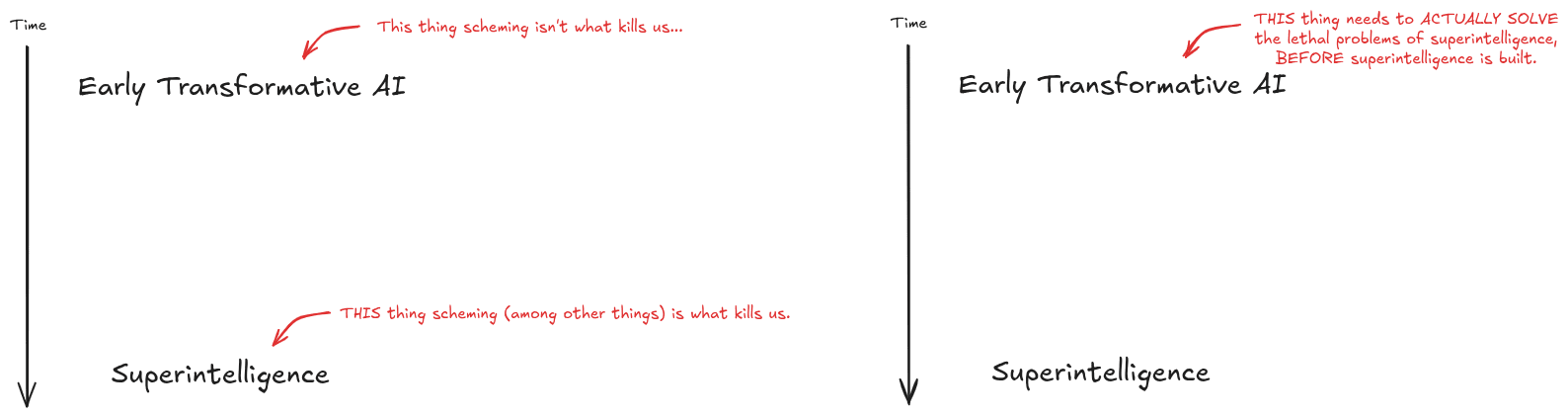


To Scott Sumner's argument:
Actually, no, we don't care that more intelligent people are nicer to strangers (even if they are). What we actually care about is: are more intelligent people more likely to be serious, active, involved *conservationists*. Because in the AI example, we are not strangers, because we are not peers. We are (charitably) chimpanzees who provide no real economic value to humans but some very small number of people have decided are worth saving for non-economic reasons.
And in my experience, beyond some very trivial "oh sure, conserving species sounds good", no, most smart people don't seem more likely to be willing to sacrifice towards conservation related ends.
So what is the actual explanation why Dario, Altman etc so openly and blatantly contradict what they said was needed for AI safety just a few years ago? Are they just sociopaths happy to ride any wave if it gives them more power? Have they been corrupted by getting a little power and now want all the power? Have their expectations about the safety of future AI improved by seeing LLMs which deeply understand human language and ideas, and thus seem unlikely to grow into naive paperclippers?