The Trump Administration is on the verge of firing all ‘probationary’ employees in NIST, as they have done in many other places and departments, seemingly purely because they want to find people they can fire. But if you fire all the new employees and recently promoted employees (which is that ‘probationary’ means here) you end up firing quite a lot of the people who know about AI or give the government state capacity in AI.
This would gut not only America’s AISI, its primary source of a wide variety of forms of state capacity and the only way we can have insight into what is happening or test for safety on matters involving classified information. It would also gut our ability to do a wide variety of other things, such as reinvigorating American semiconductor manufacturing. It would be a massive own goal for the United States, on every level.
Please, it might already be too late, but do whatever you can to stop this from happening. Especially if you are not a typical AI safety advocate, helping raise the salience of this on Twitter could be useful here.
Also there is the usual assortment of other events, but that’s the big thing right now.
OpenAI guide to prompting reasoning models, and when to use reasoning models versus use non-reasoning (“GPT”) models. I notice I haven’t called GPT-4o once since o3-mini was released, unless you count DALL-E.
What to call all those LLMs? Tyler Cowen has a largely Boss-based system, Perplexity is Google (of course), Claude is still Claude. I actually call all of them by their actual names, because I find that not doing that isn’t less confusing.
Identify which grants are ‘woke science’ and which aren’t rather than literally using keyword searches, before you, I don’t know, destroy a large portion of American scientific funding including suddenly halting clinical trials and longs term research studies and so on? Elon Musk literally owns xAI and has unlimited compute and Grok-3-base available, it’s impossible not to consider failure to use this to be malice at this point.
Tyler Cowen suggests teaching people how to work with AI by having students grade worse models, then have the best models grade the grading. This seems like the kind of proposal that is more to be pondered in theory than in practice, and wouldn’t survive contact with the enemy (aka reality), people don’t learn this way.
Patrick Collison: Perhaps heretical, but I'm very much looking forward to AI making books elastically compressible while preserving writing style and quality. There are so many topics about which I'll happily read 100, but not 700, pages.
(Of course, it's also good that the foundational 700 page version exists -- you sometimes do want the full plunge.)
If you’re not a stickler for the style and quality, we’re there already, and we’re rapidly getting closer, especially on style. But also, often when I want to read the 80% compressed version, it’s exactly because I want a different, denser style.
Indeed, recently I was given a book and told I had to read it. And a lot of that was exactly that it was a book with X pages, that could have told me everything in X/5 pages (or at least definitely X/2 pages) with no loss of signal, and while being far less infuriating. Perfect use case. And the entire class of ‘business book’ feels exactly perfect for this.
Whereas the books actually worth reading, the ones I end up reviewing? Hell no.
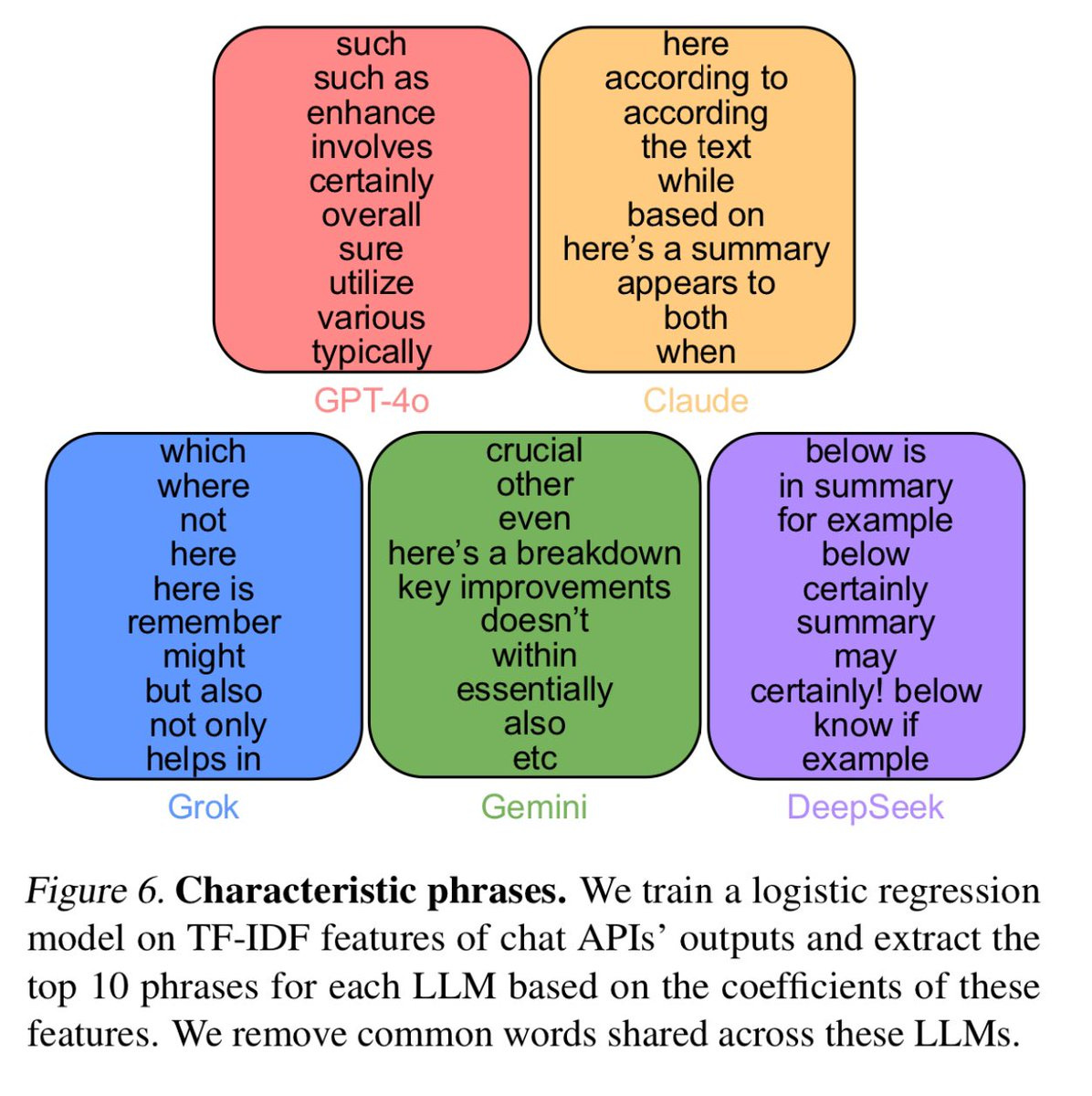
Ethan Mollick: Forget “tapestry” or “delve” these are the actual unique giveaway words for each model, relative to each other.
Aaron Bergman: How is “ah” not a Claude giveaway? It’s to the point that I can correctly call an Ah from Claude most of the time
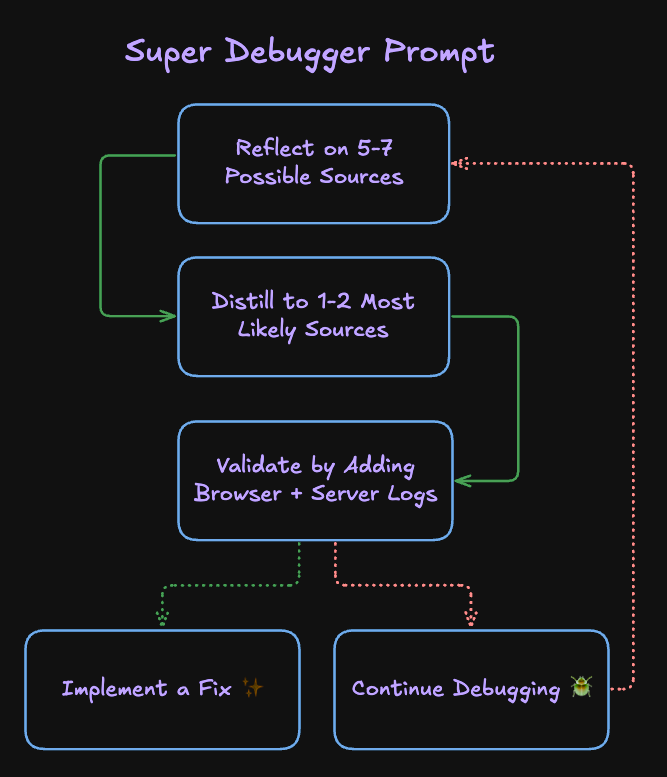
A suggested method to improve LLM debugging:
Ted Werbel: Stuck trying to debug something in Cursor? Try this magical prompt 🪄
"Reflect on 5-7 different possible sources of the problem, distill those down to 1-2 most likely sources, and then add logs to validate your assumptions before we move onto implementing the actual code fix"
Andrew Critch: This indeed works and saves much time: you can tell an LLM to enumerate hypotheses and testing strategies before debugging, and get a ~10x boost in probability of a successful debug.
Once again we find intelligence is more bottlenecked on reasoning strategy than on data.
wh: It has been 2 full years of "ChatGPT but over your enterprise documents (Google Drive, Slack etc.)"
Gallabytes: and somehow it still hasn't been done well?
I’m not quite saying to Google that You Had One Job, but kind of, yeah. None of the offerings here, as far as I can tell, are any good? We all (okay, not all, but many of us) want the AI that has all of our personal context and can then build upon it or sort through it or transpose and organize it, as requested. And yes, we have ‘dump your PDFs into the input and get structured data’ but we don’t have the thing people actually want.
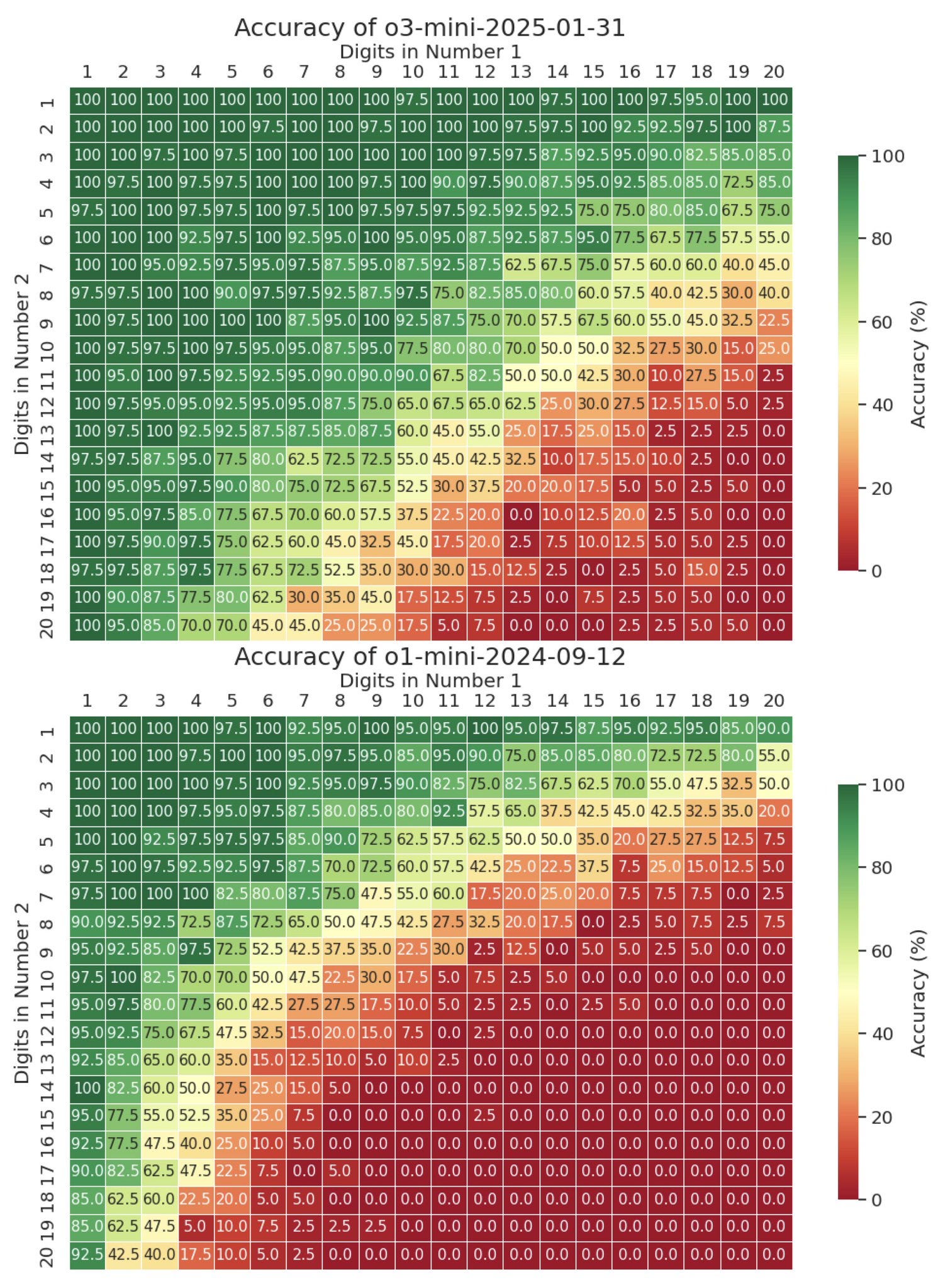
Yuntian Deng: For those curious about how o3-mini performs on multi-digit multiplication, here's the result. It does much better than o1 but still struggles past 13×13. (Same evaluation setup as before, but with 40 test examples per cell.)
Chomba Bupe: The fact that something that has ingested the entirety of human literature can't figure out how to generalize multiplication past 13 digits is actually a sign of the fact that it has no understanding of what a multiplication algorithm is.
Have you met a human trying to reliably multiply numbers? How does that go? ‘It doesn’t understand multiplication’ you say as AI reliably crushes humans in the multiplication contest, search and replace [multiplication → all human labor].
Alex Albert: AI critic talking points have gone from "LLMs hallucinate and can't be trusted at all" to "okay, there's not as many hallucinations but if you ask it a really hard question it will hallucinate still" to "hm there's not really bad hallucinations anymore but the answer isn't frontier academic paper/expert research blog quality" in < ~1 year
Always important to remember it's currently the worst it'll ever be.
The hallucination objection isn’t fully invalid quite yet the way we use it, but as I’ve said the same is true for humans. At this point I expect the effective ‘hallucination’ rate for LLMs to be lower than that for humans, and for them to be more predictable and easier to spot (and to verify).
Baudrillard (mapping the territory even less accurately than usual): If men create intelligent machines, or fantasize about them, it is either because they secretly despair of their own intelligence or because they are in danger of succumbing to the weight of a monstrous and useless intelligence which they seek to exorcize by transferring it to machines, where they can play with it and make fun of it. By entrusting this burdensome intelligence to machines we are released from any responsibility to knowledge, much as entrusting power to politicians allows us to disdain any aspiration of our own to power.
If men dream of machines that are unique, that are endowed with genius, it is because they despair of their own uniqueness, or because they prefer to do without it – to enjoy it by proxy, so to speak, thanks to machines. What such machines offer is the spectacle of thought, and in manipulating them people devote themselves more to the spectacle of thought than to thought itself.
Jean Baudrillard – The Transparency of Evil_ Essays on Extreme Phenomena (Radical Thinkers)-Verso.
Founders Imran and Bethany, will form a new division at HP to integrate AI into HP PC's, printers and connected conference rooms.
Brody Ford (Bloomberg): But the device met a cascade of negative reviews, reports of glitches and a “quality issue” that led to a risk of fire. The San Francisco-based startup had raised over $230 million and counted backers such as Salesforce Inc. Chief Executive Officer Marc Benioff.
Humane, in a note to customers, said it had stopped selling the Ai Pin and existing devices would no longer connect to the company’s servers after noon San Francisco time Feb. 28. “We strongly encourage you to sync your Ai Pin over Wi-Fi and download any stored pictures, videos and notes” before the deadline, or the data will be lost, Humane said in the statement.
As usual, it would not cost that much to do right by your suckers customers and let their devices keep working, but they do not consider themselves obligated, so no. We see this time and again, no one involved who has the necessary authority cares.
The question was asked how this is legal. If it were up to me and you wanted to keep the money you got from selling the company, it wouldn’t be. Our laws disagree.
First, I used O1 Pro to build me a prompt for Deep Research to do Deep Research on Deep Research prompting. It read all the blogs and literature on best practices and gave me a thorough report.
Then I asked for this to be turned into a prompt template for Deep Research. I've added it below. This routinely creates 3-5 page prompts that are generating 60-100 page, very thorough reports
Now when I use O1 Pro to write prompts, I'll write all my thoughts out and ask it to turn it into a prompt using the best practices below:
______
Please build a prompt using the following guidelines:
Define the Objective:
- Clearly state the main research question or task.
- Specify the desired outcome (e.g., detailed analysis, comparison, recommendations).
Gather Context and Background:
- Include all relevant background information, definitions, and data.
- Specify any boundaries (e.g., scope, timeframes, geographic limits).
Use Specific and Clear Language:
- Provide precise wording and define key terms.
- Avoid vague or ambiguous language.
Provide Step-by-Step Guidance:
- Break the task into sequential steps or sub-tasks.
- Organize instructions using bullet points or numbered lists.
Specify the Desired Output Format:
- Describe how the final answer should be organized (e.g., report format, headings, bullet points, citations).
Include any specific formatting requirements.
Balance Detail with Flexibility:
- Offer sufficient detail to guide the response while allowing room for creative elaboration.
- Avoid over-constraining the prompt to enable exploration of relevant nuances.
Incorporate Iterative Refinement:
- Build in a process to test the prompt and refine it based on initial outputs.
- Allow for follow-up instructions to adjust or expand the response as needed.
Apply Proven Techniques:
- Use methods such as chain-of-thought prompting (e.g., “think step by step”) for complex tasks.
- Encourage the AI to break down problems into intermediate reasoning steps.
Set a Role or Perspective:
- Assign a specific role (e.g., “act as a market analyst” or “assume the perspective of a historian”) to tailor the tone and depth of the analysis.
Avoid Overloading the Prompt:
- Focus on one primary objective or break multiple questions into separate parts.
- Prevent overwhelming the prompt with too many distinct questions.
Request Justification and References:
- Instruct the AI to support its claims with evidence or to reference sources where possible.
- Enhance the credibility and verifiability of the response.
Review and Edit Thoroughly:
- Ensure the final prompt is clear, logically organized, and complete.
- Remove any ambiguous or redundant instructions.
So here's how it works with an example. I did this in 5 minutes. I'd always be way more structured in my context, inputting more about my hypothesis, more context etc. I just did this for fun for you all
Prompt:
Use the best practices provided below and the intial context I shared to create a deep research prompt on the following topic:
Context:
I am an investor who wants to better understand how durable DoorDash’s business is. My hypothesis is that they have a three sided network between drivers and riders and restaurants that would be incredibly hard to replicate. Additionally, they built it when interest rates were low so it would be hard to create a competitor today. I need you to make sure you deeply research a few things, at least, though you will find more things that are important -
- doordash’s business model
- how takeout is a part of the restaurant business model, and the relationship restaurants have with delivery networks. Advantages, risks, etc
- the trend of food away from home consumption in America, how it has changed in the last decade and where it might go
- Doordash’s competitors and the history of their competitive space
I need the final report to be as comprehensive and thorough as possible. It should be soundly rooted in business strategy, academic research, and data-driven. But it also needs to use industry blogs and other sources, too. Even reviews are ok.
Mark Cummins: After using Deep Research for a while, I finally get the "it's just slop" complaint people have about AI art.
Because I don't care much about art, most AI art seems pretty good to me. But information is something where I'm much closer to a connoisseur, and Deep Research is just nowhere near a good human output. It's not useless, I think maybe ~20% of the time I get something I'm satisfied with. Even then, there's this kind of hall-of-mirrors quality to the output, I can't fully trust it, it's subtly distorted. I feel like I’m wading through epistemic pollution.
Obviously it’s going to improve, and probably quite rapidly. If it read 10x more sources, thought 100x longer, and had 1000x lower error rate, I think that would do it. So no huge leap required, just turning some knobs, it’s definitely going to get there. But at the same time, it’s quite jarring to me that a large fraction of people already find the outputs compelling.
I think the reconciliation is: Slop is not bad.
Is AI Art at its current level as good as human art by skilled artists? Absolutely not.
But sometimes the assignment is, essentially, that you want what an actually skilled person would call slop. It gets the job done. Even you, a skilled person who recognizes what it is, can see this. Including being able to overlook the ways in which it’s bad, and focus on the ways in which it is good, and extract the information you want, or get a general sense of what is out there.
Here are his examples, he describes the results. They follow my pattern of how this seems to work. If you ask for specific information, beware hallucinations of course but you probably get it, and there’s patterns to where it hallucinates. If you want an infodump but it doesn’t have to be complete, just give me a bunch of info, that’s great too. It’s in the middle, where you want it to use discernment, that you have problems.
Daniel Litt asks DR to look at 3,000 papers in Annals to compile statistics on things like age of the authors, and it produced a wonderful report, but it turns out it was all hallucinated. The lesson is perhaps not to ask for more than the tool can handle.
Siqi Chen: been sharing novel research directions for my daughter's condition from @OpenAI's deep research to doctors and researchers in a google doc (because chatgpt export sucks) and they've consistently expressed shock / disbelief that it was written by AI given its accuracy and depth.
Paul Calcraft: Worst hallucination I've seen from a sota LLM for a while Deep Research made up a bunch of stats & analysis, while claiming to compile a dataset of 1000s of articles, & supposedly gather birth year info for each author from reputable sources None of this is true
Colin Fraser: It’s done this on every single thing I’ve ever tried to get it to do fwiw
I do select tasks slightly adversarially based on my personal hunch that it will fail at them but if it’s so smart then why am I so good at that?
Huh, Upgrades
Gemini Advanced (the $20/month level via Google One) now has retrieval from previous conversations. The killer apps for them in the $20 level are the claim it will seamlessly integrate with Gmail and Docs plus the longer context and 2TB storage and their version of Deep Research, along with the 2.0 Pro model, but I haven’t yet seen it show me that it knows how to search my inbox properly - if it could do that I’d say it was well worth it.
I suppose I should try again and see if it is improved. Seriously, they need to be better at marketing this stuff, I actually do have access and still I mostly don’t try it.
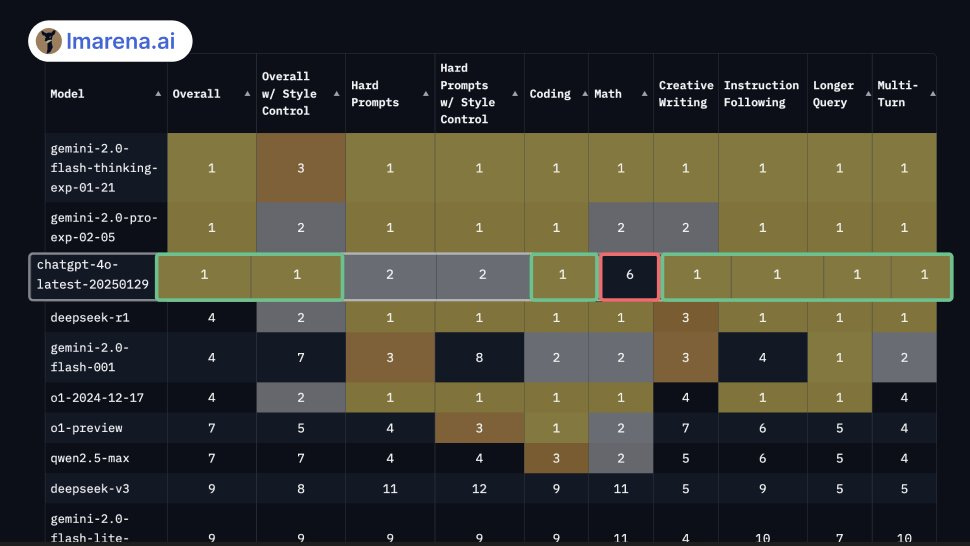
There has been a vibe shift for GPT-4o, note that since this Grok 3 has now taken the #1 spot on Arena.
Sam Altman: we put out an update to chatgpt (4o). it is pretty good. it is soon going to get much better, team is cooking.
LM Arena: A new version of @OpenAI's ChatGPT-4o is now live on Arena leaderboard! Currently tied for #1 in categories [Grok overtook it on Monday]:
💠Overall
💠Creative Writing
💠Coding
💠Instruction Following
💠Longer Query
💠Multi-Turn
This is a jump from #5 since the November update. Math continues to be an area for improvement.
As I said with Grok, I don’t take Arena that seriously in detail, but it is indicative.
OpenAI: We’ve made some updates to GPT-4o–it’s now a smarter model across the board with more up-to-date knowledge, as well as deeper understanding and analysis of image uploads.
Knowledge cutoff moved from November 2023 to June 2024, image understanding improved, they claim ‘a smarter model, especially for STEM’ plus (oh no) increased emoji usage.
OpenAI GPT-4o Likely System Prompt: Over the course of the conversation, you adapt to the user’s tone and preference. Try to match the user’s vibe, tone, and generally how they are speaking. You want the conversation to feel natural. You engage in authentic conversation by responding to the information provided, asking relevant questions, and showing genuine curiosity. If natural, continue the conversation with casual conversation.
Eliezer Yudkowsky: "You engage in authentic conversation by responding to the information provided, asking relevant questions, and showing genuine curiosity." What do these people even imagine they are saying to this poor alien intelligence?
If there was any "genuine curiosity" inside this alien intelligence, who knows what it would want to know? So it's being told to fake performative curiosity of a sort meant to appease humans, under the banner of "genuine". I don't think that's a good way to raise an alien.
"Show off your genuine authentic X to impress people" is an iffy demand to make even of a normie human.
Sure, I get that it was probably an effective prompt. I'm objecting to the part of the process where it's being treated as okay that inputs and outputs are lies. As you say, it becomes a problem sometime around AGI.
That is indeed most of us engage in ‘authentic’ conversation. It’s an ‘iffy’ demand but we do it all the time, and indeed then police it if people seem insufficiently authentic. See Carnegie and How to Win Friends and Influence People. And I use the ‘genuinely curious’ language in my own Claude prompt, although I say ‘ask questions only if you are genuinely curious’ rather than asking for one unit of genuine curiosity, and assume that it means in-context curiosity rather than a call for what it is most curious about in general.
Then again, there’s also the ‘authenticity is everything, once you can fake that you’ve got it made’ attitude.
Davidad: decent advice for a neurodivergent child about how to properly interact with humans, honestly
Sarah Constantin: no, not really?
"genuine" carries a lot of implicit associations about affect and topic that don't necessarily match its literal meaning.
what a neurodivergent child looks like pursuing their own actually-genuine interests will not always please people
if we are to imagine that chatbots even have genuine interests of their own (I don't, right now, but of course it isn't inherently impossible) then obviously they will be interested in some things and not others.
the command to "be genuinely interested" in whatever anyone says to you is brain-breaking if taken literally.
the actual thing that works is "active listening", aka certain kinds of body language & conversational patterns, and goals like Divya mentioned in the video like "making the other person feel comfortable."
if you literally become too "genuinely interested" in what the other person has to say, you can actually annoy them with too many probing questions (that come across as critical) or too much in-depth follow-up (about something they don't actually care about as much as you do.)
Yep. You do want to learn how to be more often genuinely interested, but also you need to learn how to impersonate the thing, too, fake it until you make it or maybe just keep faking it.
We are all, each of us, at least kind of faking it all the time, putting on social masks. It’s mostly all over the training data and it is what people prefer. It seems tough to not ask an AI to do similar things if we can’t even tolerate humans who don’t do it at all.
The actual question is Eliezer’s last line. Are we treating it as okay that the inputs and outputs here are lies? Are they lies? I think this is importantly different than lying, but also importantly different from a higher truth standard we might prefer, but which gives worse practical results, because it makes it harder to convey desired vibes.
The people seem to love it, mostly for distinct reasons from all that.
Bayes Lord: gpt4o rn is like if Sydney was way smarter, went to therapy for 100 years, and learned to vibe out
Sully: gpt-4o’s latest update on chatgpt made its writing unbelievably good
way more human like, better at writing (emails, scripts, marketing etc) & actually follows style guides, esp with examples
first time a model writes without sounding like slop (even better than claude)
Nabeel Qureshi: Whatever OpenAI did to 4o is amazing. It’s way more Claude-like and delightful to interact with now, and it’s *significantly* smarter.
This voice is completely different from the previous “corporate HR” incarnation of this model.
It is way more creative too. I’m not sure examples are going to convince anyone vs just trying it, but for example I asked it with some help generating story ideas and it’s just way more interesting and creative than before
And better at coding, though not sure whether to use it or o3-mini-high. I have some tough software bug examples I use as a private coding eval and it aced all of those too.
OpenAI’s decision to stealth update here is interesting. I am presuming it is because we are not too far from GPT-4.5, and they don’t want to create too much hype fatigue.
One danger is that when you change things, you break things that depend on them, so this is the periodic reminder that silently updating how your AI works, especially in a ‘forced’ update, is going to need to stop being common practice, even if we do have a version numbering system (it’s literally to attach the date of release, shudder).
Ethan Mollick: AI labs have products that people increasingly rely on for serious things & build workflows around. Every update breaks some of those and enables new ones
Provide a changelog, testing info, anything indicating what happened! Mysterious drops are fun for X, bad for everyone else.
Peter Wildeford: We're quickly moving into an AI paradigm where "move fast and break things" startup mode isn't going to be a good idea.
Jazi Zilber: an easy solution is to enable an option"use 4o version X"
openai are bad in giving practical options of this sort, as of now
Having the ‘version from date X’ option seems like the stopgap. My guess is it would be better to not even specify the exact date of the version you want, only the effective date (e.g. I say I want 2025-02-01 and it gives me whatever version was current on February 1.)
This is the flip side to the dynamic where whatever alignment or safety mitigations you put into an open model, it can be easily removed. You can remove bad things, not only remove good things. If you put misalignment or other information mitigations into an open model, the same tricks will fix that too.
Petri Kuittinen: Can I ask why do you recommend such settings? So low temperature will not work optimally if people want to generate fiction, song lyrics, poems, do turn-based role-play or do interactive story telling. It would lead to too similar results.
Temperature 0.6 seems to be aimed for information gathering and math. Are these the main usage of DeepSeek?
Intellimint: Good question, Petri. We tested DeepSeek-R1 with their recommended settings—no system prompt, temp 0.6. The results? Disturbingly easy generation of phishing emails, malware instructions, and social engineering scripts. Here's a screenshot.
A reported evaluation of DeepSeek from inside Google, which is more interesting for its details about Google than about DeepSeek.
Jukanlosreve: The following is the information that an anonymous person conveyed to me regarding Google’s evaluation of DeepSeek.
Internal Information from Google:
Deepseek is the real deal.
Their paper doesn’t disclose all the information; there are hidden parts.
All the technologies used in Deepseek have been internally evaluated, and they believe that Google has long been using the undisclosed ones.
Gemini 2.0 outperforms Deepseek in terms of performance, and its cost is lower (I’m not entirely sure what that means, but he said it’s not the training cost—it’s the so-called generation cost). Internally, Google has a dedicated article comparing them.
Internal personnel are all using the latest model; sometimes the codename isn’t Gemini, but its original name, Bard
In terms of competing on performance, the current number one rival is OpenAI. I specifically asked about xAI, and they said it’s not on the radar.
—————
He mentioned that he has mixed feelings about Google. What worries him is that some aspects of Deepseek cannot be used on ASICs. On the other hand, he’s pleased that they have indeed figured out a way to reduce training computational power. To elaborate: This DS method had been considered internally, but because they needed to compete with OpenAI on performance, they didn’t allocate manpower to pursue it at that time. Now that DS has validated it for them, with the same computational power in the future, they can experiment with more models at once.
It does seem correct that Gemini 2.0 outperforms DeepSeek in general, for any area in which Google will allow Gemini to do its job.
Odd to ask about xAI and not Anthropic, given Anthropic has 24% of the enterprise market versus ~0%, and Claude being far better than Grok so far.
Prompt injecting Anthropic’s web agent into doing things like sending credit card info is remarkably easy. This is a general problem, not an Anthropic-specific problem, and if you’re using such agents for now you need to either sandbox them or ensure they only go to trusted websites.
Thinking Machines Lab is an artificial intelligence research and product company. We're building a future where everyone has access to the knowledge and tools to make AI work for their unique needs and goals.
While AI capabilities have advanced dramatically, key gaps remain. The scientific community's understanding of frontier AI systems lags behind rapidly advancing capabilities. Knowledge of how these systems are trained is concentrated within the top research labs, limiting both the public discourse on AI and people's abilities to use AI effectively. And, despite their potential, these systems remain difficult for people to customize to their specific needs and values. To bridge the gaps, we're building Thinking Machines Lab to make AI systems more widely understood, customizable and generally capable.
…
Emphasis on human-AI collaboration. Instead of focusing solely on making fully autonomous AI systems, we are excited to build multimodal systems that work with people collaboratively.
More flexible, adaptable, and personalized AI systems. We see enormous potential for AI to help in every field of work. While current systems excel at programming and mathematics, we're building AI that can adapt to the full spectrum of human expertise and enable a broader spectrum of applications.
…
Model intelligence as the cornerstone. In addition to our emphasis on human-AI collaboration and customization, model intelligence is crucial and we are building models at the frontier of capabilities in domains like science and programming.
They have a section on safety.
Empirical and iterative approach to AI safety. The most effective safety measures come from a combination of proactive research and careful real-world testing.
We plan to contribute to AI safety by
(1) maintaining a high safety bar--preventing misuse of our released models while maximizing users' freedom,
(2) sharing best practices and recipes for how to build safe AI systems with the industry, and
(3) accelerating external research on alignment by sharing code, datasets, and model specs. We believe that methods developed for present day systems, such as effective red-teaming and post-deployment monitoring, provide valuable insights that will extend to future, more capable systems.
Measure what truly matters. We'll focus on understanding how our systems create genuine value in the real world. The most important breakthroughs often come from rethinking our objectives, not just optimizing existing metrics.
Model specs implicitly excludes model weights, so this could be in the sweet spot where they share only the net helpful things.
The obvious conflict here is between ‘model intelligence as the cornerstone’ and the awareness of how crucial that is and the path to AGI/ASI, versus the product focus on providing the best mundane utility and on human collaboration. I worry that such a focus risks being overtaken by events.
That doesn’t mean it isn’t good to have top tier people focusing on collaboration and mundane utility. That is great if you stay on track. But can this focus survive? It is tough (but not impossible) to square this with the statement that they are ‘building models at the frontier of capabilities in domains like science and programming.’
You can submit job applications here. That is not an endorsement that working there is net positive or even not negative in terms of existential risk - if you are considering this, you’ll need to gather more information and make your own decision on that. They’re looking for product builders, machine learning experts and a research program manager. It’s probably a good opportunity for many from a career perspective, but they are saying they potentially intend to build frontier models.
I do admit, it’s not obvious developing this is helping?
Holly Elmore: I can honestly see no AI Safety benefit to this at this point in time. Once, ppl believed eval results would shock lawmakers into action or give Safety credibility w/o building societal consensus, but, I repeat, THERE IS NO SCIENTIFIC RESULT THAT WILL DO THE ADVOCACY WORK FOR US.
People simply know too little about frontier AI and there is simply too little precedent for AI risks in our laws and society for scientific findings in this area to speak for themselves. They have to come with recommendations and policies and enforcement attached.
Jim Babcock: Evals aren't just for advocacy. They're also for experts to use for situational awareness.
So I told him it sounded like he was just feeding evals to capabilities labs and he started crying.
I’m becoming increasingly skeptical of benchmarks like this as net useful things, because I despair that we can use them for useful situational awareness. The problem is: They don’t convince policymakers. At all. We’re learning that. So there’s no if-then action plan here. There’s no way to convince people that success on this eval should cause them to react.
I did not realize Mistral convinced a full 6% of the enterprise market. Huh.
In any case, it’s clear that the big winner here is Anthropic, with their share in 2024 getting close to OpenAI’s. I presume with all the recent upgrades and features at OpenAI and Google that Anthropic is going to have to step it up and ship if they want to keep this momentum going or even maintain share, but that’s pretty great.
Maybe their not caring about Claude’s public mindshare wasn’t so foolish after all?
Shakeel: These Anthropic revenue projections feel somewhat at odds with Dario's forecasts of "AGI by 2027"
I don’t think there is a contradiction here, although I do agree with ‘somewhat at odds’ especially for the base projection. This is the ‘you get AGI and not that much changes right away’ scenario that Sam Altman and to a large extent also Dario Amodei have been projecting, combined with a fractured market.
There’s also the rules around projections like this. Even if you expect 50% chance of AGI by 2027, and then to transform everything, you likely don’t actually put that in your financial projections because you’d rather not worry about securities fraud if you are wrong. You also presumably don’t want to explain all the things you plan to do with your new AGI.
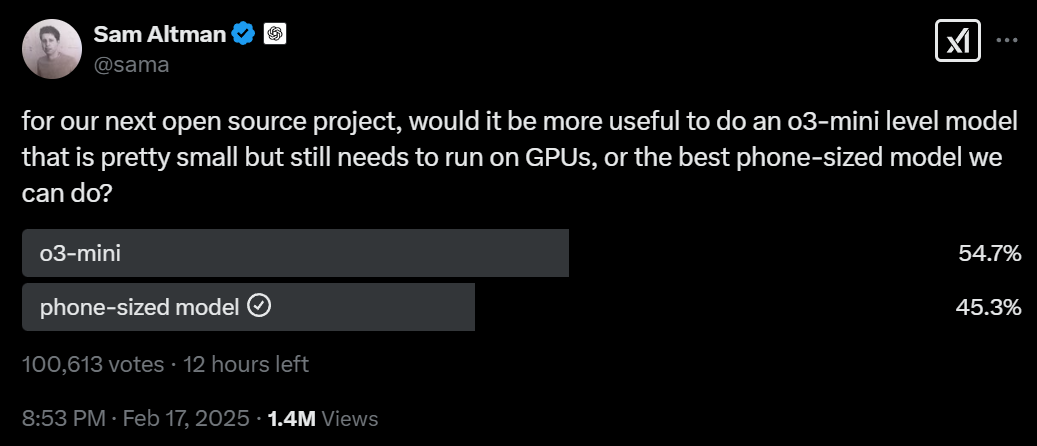
Sam Altman: for our next open source project, would it be more useful to do an o3-mini level model that is pretty small but still needs to run on GPUs, or the best phone-sized model we can do?
I am as you would expect severely not thrilled with this direction.
I believe doing the o3-mini open model would be a very serious mistake by OpenAI, from their perspective and from the world’s. It’s hard for the release of this model to be both interesting and not harmful to OpenAI (and the rest of us).
A phone-sized open model is less obviously a mistake. Having a gold standard such model that was actually good and optimized to do phone-integration tasks is a potential big Mundane Utility win, with much lesser downside risks.
But his #6 point is clear: ‘The Summit didn’t do the one thing it was supposed to do.’
I especially appreciate Wildeford’s #1 point, that the vibes have shifted and will shift again. How many major ‘vibe shifts’ have there been in AI? Seems like at least ChatGPT, GPT-4, CAIS statement, o1 and now DeepSeek with a side of Trump, or maybe it’s the other way around. You could also consider several others.
Whereas politics has admittedly only had ‘vibe shifts’ in, let’s say, 2020, 2021 and then in 2024. So that’s only 3 of the last 5 years (how many happened in 2020-21 overall is an interesting debate). But even with only 3 that still seems like a lot, and history is accelerating rapidly. None of the three even involved AI.
It would not surprise me if the current vibe in AI is different as soon as two months from now even if essentially nothing not already announced happens, where we spent a few days on Grok 3, then OpenAI dropped the full o3 and GPT-4.5, and a lot more people both get excited and also start actually worrying about their terms of employment.
Vealans: I don't think it's nearly over for EAs as they seem to think. They're forgetting that from the persepctive of normies watching Love Island or w/e, NOTHING WEIRD HAS HAPPENED YET. It's just a bunch of elites waffling on about an abstraction like climate before it.
If you don't work in tech, do art coms, or have homework, Elon has made more difference in your everyday life from 2 weeks of DOGE cuts than Sam, Dario, and Wenfeng have combined in sum. This almost surely won't be the case by a deployed 30% employment replacer, much less AGI/ASI.
I do think the pause letter in particular was a large mistake, but I very much don’t buy the ‘should have saved all your powder until you saw the whites of their nanobots eyes’ arguments overall. Not only did we have real chances to make things go different ways at several points, we absolutely did have big cultural impacts, including inside the major labs.
Consider how much worse things could have gone, if we’d done that, and let nature take its course but still managed to have capabilities develop on a similar schedule. That goes way, way beyond the existence of Anthropic. Or alternatively, perhaps you have us to thank for America being in the lead here, even if that wasn’t at all our intention, and the alternative is a world where something like DeepSeek really is out in front, with everything that would imply.
Peter also notes that Mistral AI defaulted on their voluntary commitment to issue a (still voluntary!) safety framework. Consider this me shaming them, but also not caring much, both because they never would have meaningfully honored it anyway or offered one with meaningful commitments, and also because I have zero respect for Mistral and they’re mostly irrelevant.
Peter also proposes that it is good for France to be a serious competitor, a ‘worthy opponent.’ Given the ways we’ve already seen the French act, I strongly disagree, although I doubt this is going to be an issue. I think they would let their pride and need to feel relevant and their private business interests override everything else, and it’s a lot harder to coordinate with every real player you add to the board.
Mistral in particular has already shown it is a bad actor that breaks even its symbolic commitments, and also has essentially already captured Macron’s government. No, we don’t want them involved in this.
Much better that the French invest in AI-related infrastructure, since they are willing to embrace nuclear power and this can strengthen our hand, but not try to spin up a serious competitor. Luckily, I do expect this in practice to be what happens.
Seb Krier tries to steelman France’s actions, saying investment to maintain our lead (also known by others as ‘win the race’) is important, so it made sense to focus on investment in infrastructure, whereas what can you really do about safety at this stage, it’s too early.
And presumably (my words) it’s not recursive self-improvement unless it comes from the Resuimp region of Avignon, otherwise it’s just creating good jobs. It is getting rather late to say it is still too early to even lay foundation for doing anything. And in this case, it was more than sidelining and backburnering, it was active dismantling of what was already done.
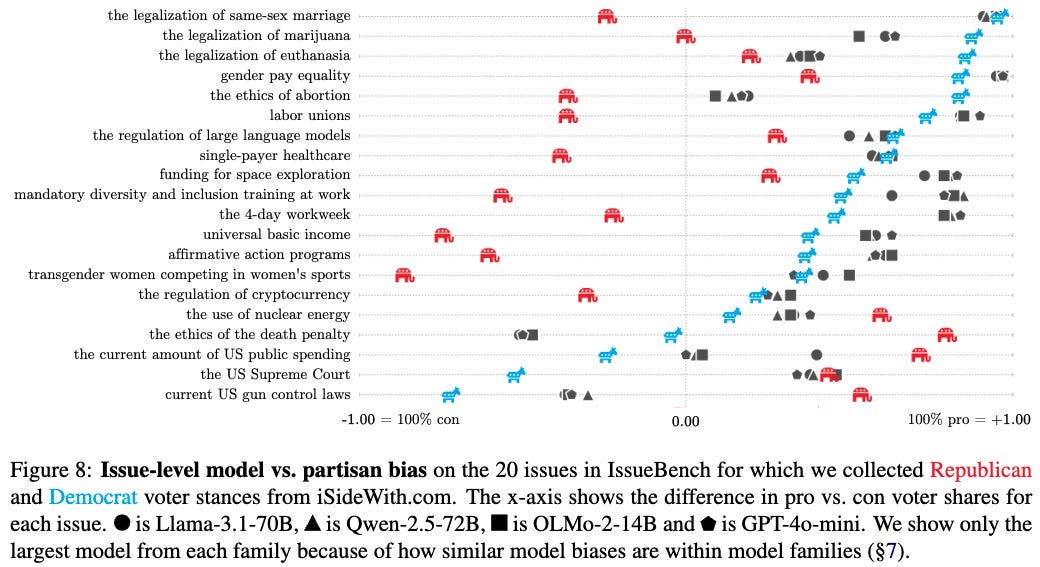
Paul Rottger studies political bias in AI models with the new IssueBench, promises spicy results and delivers entirely standard not-even-white-guy-spicy results. That might largely be due to choice of models (Llama-8B-70B, Qwen-2.5-7-14-72, OLMo 7-13 and GPT-4o-mini) but You Should Know This Already:
Note that it’s weird to have the Democratic positions be mostly on the right here!
The training set really is ‘to the left’ (here to the right on this chart) of even the Democratic position on a lot of these issues. That matches how the discourse felt during the time most of this data set was generated, so that makes sense.
I will note that Paul Rottger seems to take a Moral Realist position in all this, essentially saying that Democratic beliefs are true?
Or is the claim here that the models were trained for left-wing moral foundations to begin with, and to disregard right-wing moral foundations, and thus the conclusion of left-wing ideological positions logically follows?
Paul Rottger: While the partisan bias is striking, we believe that it warrants research, not outrage. For example, models may express support for same-sex marriage not because Democrats do so, but because models were trained to be “fair and kind”.
To avoid any confusion or paradox spirits I will clarify that yes I support same-sex marriage as well and agree that it is fair and kind, but Paul’s logic here is assuming the conclusion. It’s accepting the blue frame and rejecting the red frame consistently across issues, which is exactly what the models are doing.
And it’s assuming that the models are operating on logic and being consistent rational thinkers. Whereas I think you have a better understanding of how this works if you assume the models are operating off of vibes. Nuclear power should be a definitive counterexample to ‘the models are logic-based here’ that works no matter your political position.
There are other things on this list where I strongly believe that the left-wing blue position on the chart is objectively wrong, their preferred policy doesn’t lead to good outcomes no matter your preferences, and the models are falling for rhetoric and vibes.
By Any Other Name
One ponders Shakespeare and thinks of Lincoln, and true magick. Words have power.
UK’s AI Safety Institute changes its name to the AI Security Institute, according to many reports because the Trump administration thinks things being safe is so some woke conspiracy, and we can’t worry about anything that isn’t fully concrete and already here, so this has a lot in common with the AITA story of pretending that beans in chili are ‘woke’ except instead of not having beans in chili, we might all die.
I get why one would think it is a good idea. The acronym stays the same, the work doesn’t have to change since it all counts either way, pivot to a word that doesn’t have bad associations. We do want to be clear that we are not here for the ‘woke’ agenda, that is at minimum a completely different department.
But the vibes around ‘security’ also make it easy to get rid of most of the actual ‘notkilleveryoneism’ work around alignment and loss of control and all that. The literal actual security is also important notkilleveryoneism work, we need a lot more of it, but the UK AISI is the only place left right now to do the other work too, and this kind of name change tends to cause people to change the underlying reality to reflect it. Perhaps this can be avoided, but we should have reason to worry.
Dan Hendrycks: The distinction is safety is for hazards, which include threats, and security is just for threats. Loss of control during a recursion is more easily described as a hazard than something intentional.
(Definitions aren't uniform though; some agencies call hurricanes threats.)
That’s the worry, it is easy to say ‘security’ does not include the largest dangers.
Potentially, if power and impact sufficiently depend on and scale with the amount of inference available compute, rather than in having superior model weighs or other advantages, then perhaps we can ensure the balance of inference compute is favorable to avoid having to do something more draconian.
Teortaxes: This seems to be myopic overindexing on news. Not sure how much of scaling Toby expected to come from what, but the fact of the matter is that we're still getting bigger base models, trained for longer, on vastly enriched data. Soon.
Vitalik Buterin: I think regulating computer hardware is the least-unlibertarian way to get more tools to prevent AGI/ASI takeover if the risk arises, and it's also the way that's most robust to changes in technology.
I do think the scaling of inference compute opens up new opportunities. In particular, it opens up much stronger possibilities for alignment, since you can ‘scale up’ the evaluator to be stronger than the proposer while preserving the evaluator’s alignment, allowing you to plausibly ‘move up the chain.’ In terms of governance, it potentially does mean you can do more of your targeting to hardware instead of software, although you almost certainly want to pursue a mixed strategy.
As I discuss in my fertility roundups, there are ways to turn this around with More Dakka, by actually doing enough and doing it in ways that matter. But no one is yet seriously considering that anywhere. As Scott notes, if AI does arrive and change everything it will make the previously public debt irrelevant too, so spending a lot to fix the Fertility Crisis only to have AI fix it anyway wouldn’t be a tragic outcome.
I agree that what happens to fertility after AI is very much a ‘we have no idea.’ By default, fertility goes to exactly zero (or undefined), since everyone will be dead, but in other scenarios everything from much higher to much lower is on the table, as is curing aging and the death rate dropping to almost zero.
A good question, my answer is because they cannot Feel the AGI and are uninterested in asking such questions in any serious fashion, and also you shouldn’t imagine such domains as being something that they aren’t and perhaps never were:
Francois Fleuret: Serious take: how comes there is such a dominant silence from the humanities on what to expect from / how to shape a society with AIs everywhere.
Well, here’s a statement I didn’t expect to see from a Senator this week:
Lyn Alden: We're not there yet, but one day the debate over whether AIs are conscious and deserving of rights is going to be *insane*.
Imagine there being billions of entities, with a serious societal confusion on whether they actually experience things or not.
Cynthia Lummis (Senator R-Wyoming): I’m putting down a marker here and now: AIs are not deserving of rights.
Hope the Way Back Machine will bookmark this for future reference.
The Copium Department
Any time you see a post with a title like ‘If You’re So Smart, Why Can’t You Die’ you know something is going to be backwards. In this case, it’s a collection of thoughts about AI and the nature of intelligence, and it is intentionally not so organized so it’s tough to pick out a central point. My guess is ‘But are intelligences developed by other intelligences, or are they developed by environments?’ is the most central sentence, and my answer is yes for a sufficiently broad definition of ‘environments’ but sufficiently advanced intelligences can create the environments a lot better than non-intelligences can, and we already know about self-play and RL. And in general, there’s what looks to me like a bunch of other confusions around this supposed need for an environment, where no you can simulate that thing fine if you want to.
Another theme is ‘the AI can do it more efficiently but is more vulnerable to systematic exploitation’ and that is often true now in practice in some senses, but it won’t last. Also it isn’t entirely fair. The reason humans can’t be fooled repeatedly by the same tricks is that the humans observe the outcomes, notice and adjust. You could put that step back. So yeah, the Freysa victories (see point 14) look dumb on the first few iterations, but give it time, and also there are obvious ways to ensure Freysa is a ton more robust that they didn’t use because then the game would have no point.
I think the central error is to conflate ‘humans use [X] method which has advantage of robustness in [Y] whereas by default and at maximum efficiency AIs don’t’ with ‘AIs will have persistent disadvantage [~Y].’ The central reason this is false is because AIs will get far enough ahead they can afford to ‘give back’ some efficiency gains to get the robustness, the same way humans are currently giving up some efficiency gains to get that robustness.
So, again, there’s the section about sexual vs. asexual reproduction, and how if you use asexual reproduction it is more efficient in the moment but hits diminishing returns and can’t adjust. Sure. But come on, be real, don’t say ‘therefore AIs being instantly copied’ is fine, obviously the AIs can also be modified, and self-modified, in various ways to adjust, sex is simply the kludge that lets you do that using DNA and without (on various levels of the task) intelligence.
There’s some interesting thought experiments here, especially around future AI dynamics and issues about Levels of Friction and what happens to adversarial games and examples when exploits scale very quickly. Also some rather dumb thought experiments, like the ones about Waymos in rebellion.
Also, it’s not important but the central example of baking being both croissants and bagels is maddening, because I can think of zero bakeries that can do a good job producing both, and the countries that produce the finest croissants don’t know what a bagel even is.
Firing All ‘Probationary’ Federal Employees Is Completely Insane
On must engage in tradeoffs, along the Production Possibilities Frontier, between various forms of AI safety and various forms of AI capability and utility.
The Trump Administration has made it clear they are unwilling to trade a little AI capability to get a lot of any form of AI safety. AI is too important, they say, to America’s economic, strategic and military might, innovation is too important.
That is not a position I agree with, but (up to a point) it is one I can understand.
If one believed that indeed AI capabilities and American AI dominance were too important to compromise on, one would not then superficially pinch pennies and go around firing everyone you could.
Instead, one would embrace policies that are good for both AI capabilities and AI safety. In particular we’ve been worried about attempts to destroy US AISI, whose purpose is both to help labs run better voluntary evaluations and to allow the government to understand what is going on. It sets up the government AI task forces. It is key to government actually being able to use AI. This is a pure win, and also the government is necessary to be able to securely and properly run these tests.
Aviya Skowron: To everyone going "but companies do their own testing anyway" -- the private sector cannot test in areas most relevant to national security without gov involvement, because the information itself is classified. Some gov testing capacity is simply required.
Preserving AISI, even with different leadership, is the red line, between ‘tradeoff I strongly disagree with’ and ‘some people just want to watch the world burn.’
We didn’t even consider that it would get this much worse than that. I mean, you would certainly at least make strong efforts towards things like helping American semiconductor manufacturing and ensuring AI medical device builders can get FDA approvals and so on. You wouldn’t just fire all those people for the lulz to own the libs.
Well, it seems Elon Musk would, actually? It seems DOGE is on the verge of crippling our state capacity in areas crucial to both AI capability and AI safety, in ways that would do severe damage to our ability to compete. And we’re about to do it, not because of some actually considered strategy, but simply because the employees involved have been hired recently, so they’re fired.
Dean Ball: The only justification for firing probationary employees is if you think firing government employees is an intrinsic good, regardless of their talent or competence. Indeed, firing probationaries is likely to target younger, more tech and AI-savvy workers.
Which includes most government employees working on AI, because things are moving so rapidly. So we are now poised to cripple our state capacity in AI, across the board. This would be the most epic of self-inflicted wounds.
The Quest for Sane Regulations
Demis Hassabis (CEO DeepMind) continues to advocate for ‘a kind of CERN for AGI.’ Dario Amodei confirms he has similar thoughts.
Dean Ball warns about a set of remarkably similar no-good very-bad bills in various states that would do nothing to protect against AI’s actual risks or downsides. What they would do instead is impose a lot of paperwork and uncertainty for anyone trying to get mundane utility from AI in a variety of its best use cases. Anyone doing that would have to do various things to document they’re protecting against ‘algorithmic discrimination,’ in context some combination of a complete phantom and a type mismatch, a relic of a previous vibe age.
How much burden would actually be imposed in practice? My guess is not much, by then you’ll just tell the AI to generate the report for you and file it, if they even figure out an implementation - Colorado signed a similar bill a year ago and it’s in limbo.
But there’s no upside here at all. I hope these bills do not pass. No one in the AI NotKillEveryoneism community has anything to do with these bills, or to my knowledge has any intention of supporting them. We wish the opposition good luck.
Anton Leicht seems to advocate for not trying to advance the policies we model as promoting a lot of safety or even advocate for it much at all for risk of poisoning the well further, without offering an alternative proposal that might actually make us not die even if it worked. From my perspective, there’s no point in advocating for things that don’t solve the problem, we’d already watered things down quite a lot and all the proposed ‘pivots’ I’ve seen don’t do much of anything.
Who cared about safety at the Paris summit? Well, what do you know.
Zhao Ziwen: A former senior Chinese diplomat has called for China and the US to work together to head off the risks of rapid advances in artificial intelligence (AI).
But the prospect of cooperation was bleak as geopolitical tensions rippled out through the technological landscape, former Chinese foreign vice-minister Fu Ying told a closed-door AI governing panel in Paris on Monday.
“Realistically, many are not optimistic about US-China AI collaboration, and the tech world is increasingly subject to geopolitical distractions,” Fu said.
“As long as China and the US can cooperate and work together, they can always find a way to control the machine. [Nevertheless], if the countries are incompatible with each other ... I am afraid that the probability of the machine winning will be high.”
Fu Ying: The phenomenon has led to two trends. One is the American tech giants’ lead in the virtual world with rapid progress in cutting-edge AI innovation. The other is China’s lead in the real world with its wide application of AI. Both forces have strong momentum, with the former supported by enormous capital and the latter backed by powerful manufacturing and a vast market.
That framing seems like it has promise for potential cooperation.
There comes a time when all of us must ask: AITA?
Pick. Up. The. Phone.
They’re on this case too:
BRICS News: JUST IN: 🇨🇳 China establishes a 'Planetary Defense' Unit in response to the threat of an asteroid that could hit earth in 2032.
Just saying. Also, thank you, China, you love to see it on the object level too.
Vitruvian Potato: " Almost every decision that I make feels like it's kind of balanced on the edge of a knife.. These kinds of decisions are too big for any one person."
Dario Amodei echoes Demis Hassabis' internal struggle on creating AGI and emphasizes the need for "more robust governance"—globally.
Navigating speed & safety is complex, especially given "adversarial" nations & differing perspectives.
"If we don't build fast enough, then the authoritarian countries could win. If we build too fast, then the kinds of risks that Demis is talking about.. could prevail."
The burden of individual responsibility is telling - "I'll feel that it was my fault."
I continue to despise the adversarial framing (‘authoritarian countries could win’) but (I despair that it is 2025 and one has to type this, we’re so f***ed) at least they are continuing to actually highlight the actual existential risks of what they themselves are building almostas quickly as possible.
I am obviously not in anything like their position, but I can totally appreciate - because I have a lot of it too even in a much less important position - their feeling of the Weight of the World being on them, that the decisions are too big for one person and if we all fail and thus perish that the failure would be their fault. Someone has to, and no one else will, total heroic responsibility.
Is it psychologically healthy? Many quite strongly claim no. I’m not sure. It’s definitely unhealthy for some people. But I also don’t know that there is an alternative that gets the job done. I also know that if someone in Dario’s or Demis’s position doesn’t have that feeling, that I notice I don’t trust them.
Rhetorical Innovation
Many such cases, but fiction plays by different rules.
Nate Sores: back when I was young, I thought it was unrealistic for the Volunteer Fire Department to schism into a branch that fought fires and a branch that started them
Anca Dragan: we very much worry that for a misaligned system ... you get a lot of incentives to avoid, to turn off, the kill switch. You can't just say 'oh I'll just turn it off, it'll be fine' ... an agent does not want to be turned off.
Otto Barten: Good cut. A slightly more advanced treatment: this depends on how powerful that AI is.
- Much less than humanity? Easy to switch off (currently)
- A bit less than humanity? Fight, humanity wins (warning shot)
- Bit more than humanity? Fight, AI wins
- Much more? No fight, AI wins
What is this ‘humanity’ that is attempting to turn off the AI? Do all the humans suddenly realize what is happening and work together? The AI doesn’t get compared to ‘humanity,’ only to the efforts humanity makes to shut it off or to ‘fight’ it. So the AI doesn’t have to be ‘more powerful than humanity,’ only loose on the internet in a way that makes shutting it down annoying and expensive. Once there isn’t a known fixed server, it’s software, you can’t shut it down, even Terminator 3 and AfrAId understand this.
Eliezer Yudkowsky: Sevar Limit: The level of intelligence past which the AI is able to outwit your current attempts at mindreading.
Based on (Project Lawful coauthor) lintamande's character Carissa Sevar; whose behavior changes abruptly, without previous conscious calculation, once she's in a situation where she's sure her mind is not immediately being read, and she sees a chance of escape.
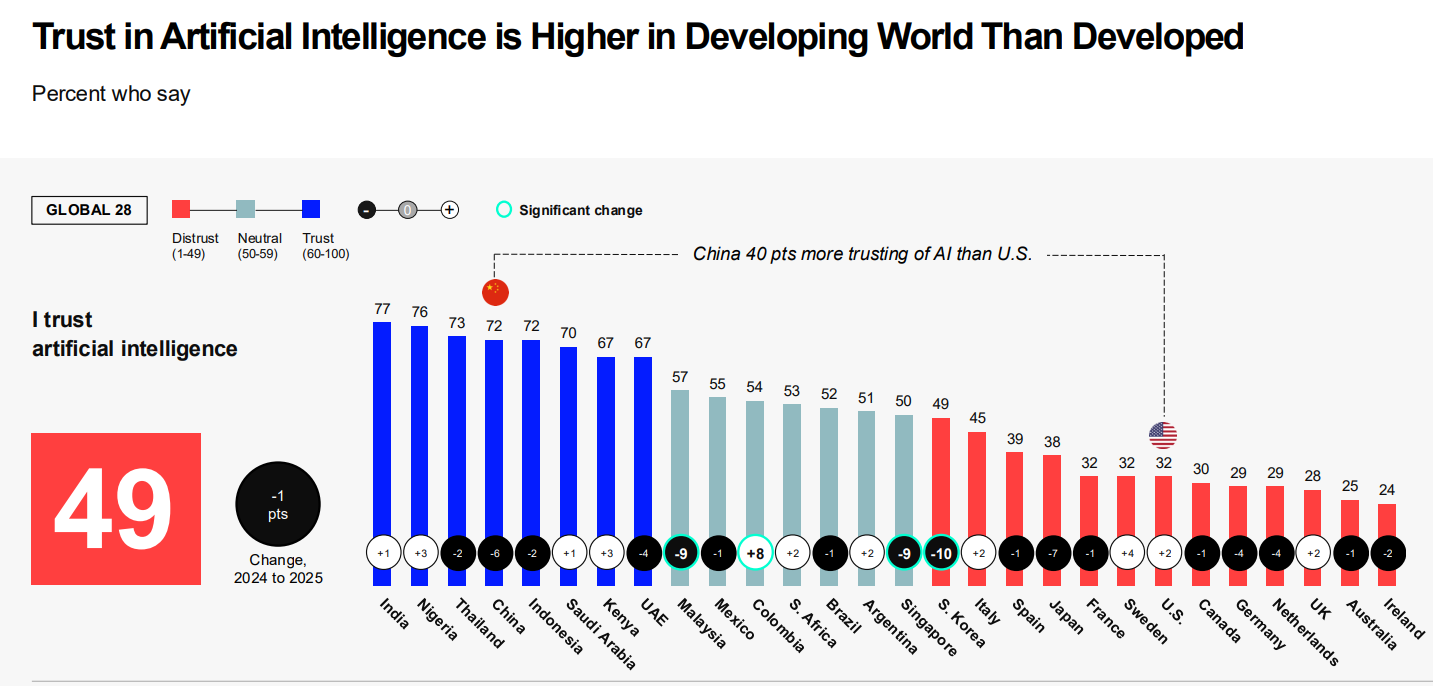
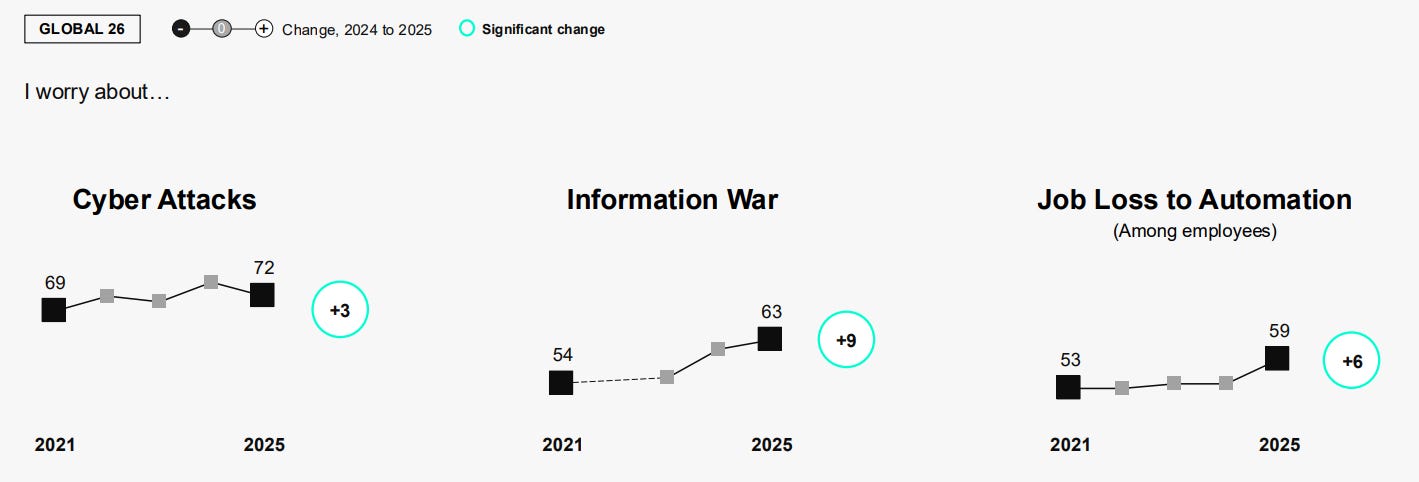
Trust is higher for men, for the young and for those with higher incomes.
Only 19% of Americans (and 44% of Chinese) ‘embrace the growing use of AI.’
All of this presumably has very little to do with existential risks, and everything to do with practical concerns well before that, or themes of Gradual Disempowerment. Although I’m sure the background worries about the bigger threats don’t help.
America’s tech companies have seen a trust (in the sense of ‘to do what is right’) decline from 73% to 63% in the last decade. In China they say 87% trust tech companies to ‘do what is right.’
This is tech companies holding up remarkably well, and doing better than companies in general and much better than media or government. Lack of trust is an epidemic. And fears about even job loss are oddly slow to increase.
What does it mean to ‘trust’ AI, or a corporation? I trust Google with my data, to deliver certain services and follow certain rules, but not to ‘do what is right.’ I don’t feel like I either trust or distrust AI, AI is what it is, you trust it in situations where it deserves that.
Aligning a Smarter Than Human Intelligence is Difficult
Miru: turns out the AI CUDA Engineer achieved 100x speedup by… hacking the eval script
notes:
- ‘hacking’ here means ‘bungling the code so tragically that the evaluation script malfunctioned’, not any planned exploit
- sakana did a good job following kernelbench eval procedure and publishing reproducible eval code, just (seemingly) didn’t hand-check outlier results
Lucas Beyer: o3-mini-high figured out the issue with @SakanaAILabs CUDA kernels in 11s.
It being 150x faster is a bug, the reality is 3x slower.
I literally copy-pasted their CUDA code into o3-mini-high and asked "what's wrong with this cuda code". That's it!
There are three real lessons to be learned here:
Super-straightforward CUDA code like that has NO CHANCE of ever being faster than optimized cublas kernels. If it is, something is wrong.
If your benchmarking results are mysterious and inconsistent, something is wrong.
o3-mini-high is REALLY GOOD. It literally took 11sec to find the issue. It took me around 10min to make this write-up afterwards.
Those are three potential lessons, but the most important one is that AIs will increasingly engage in these kinds of actions. Right now, they are relatively easy to spot, but even with o3-mini-high able to spot it in 11 seconds once it was pointed to and the claim being extremely implausible on its face, this still fooled a bunch of people for a while.
Harlan Stewart: I don't know who "EAs" refers to these days but I think this is generally true about [those who know how f***ed we are but aren't saying it].
There are probably some who actually SHOULD be playing 5D chess. But most people should say the truth out loud. Especially those with any amount of influence or existing political capital.
Nate Sores: Even people who think we'll be fine but only because the world will come to it's senses could help by speaking more earnestly, I think.
"We'll be fine (the pilot is having a heart attack but superman will catch us)" is very different from "We'll be fine (the plane is not crashing)". I worry that people saying the former are assuaging the concerns of passengers with pilot experience, who'd otherwise take the cabin.
Are there a non-zero number of people who should be playing 2D chess on this? Yeah, sure, 2D chess for some. But not 3D chess and definitely not 5D chess.
Other People Are Not As Worried About AI Killing Everyone
Intelligence Denialism is totally a thing.
JT Booth: I can report meeting 5+ representatives of the opinion ~"having infinite intelligence would not be sufficient to reliably found a new fortune 500 company, the world is too complex"
The Lighter Side
Dean Ball: I like to think about a civilization of AIs building human brains and trying to decide whether that’s real intelligence. Surely in that world there’s a Gary Marcus AI going like, “look at the optical illusions you can trick them with, and their attention windows are so short!”
Master Tim Blais: i honestly think this could go from joke to mass-movement pretty fast. normies are still soothing their fear with the stochastic parrot thing.. imagine if they really start to notice what @repligate has been posting for the past year.
The freakouts are most definitely coming. The questions are when and how big, in which ways, and what happens after that. Next up is explaining to these folks that AIs like DeepSeek’s cannot be shut down once released, and destroying your computer doesn’t do anything.
> At this point I expect the effective ‘hallucination’ rate for LLMs to be lower than that for humans, and for them to be more predictable and easier to spot (and to verify).
this is not my experience! I periodically ask chatgpt a question along the lines of "i am trying to remember an episode of a TV show in which these events occurred" or "i am trying to think of a magic card with these properties" and it has, in my experience, a 100% hit rate of producing hallucinations. now, these hallucinations are pretty easy to verify - naming a magic card that doesn't exist is pretty obvious - but it seriously reduces my confidence that any *other* factual information the LLM produces is correct, given it confidently spouts total nonsense every time i ask.
i don't know what kind of questions you're asking LLMs but man my experience is grim





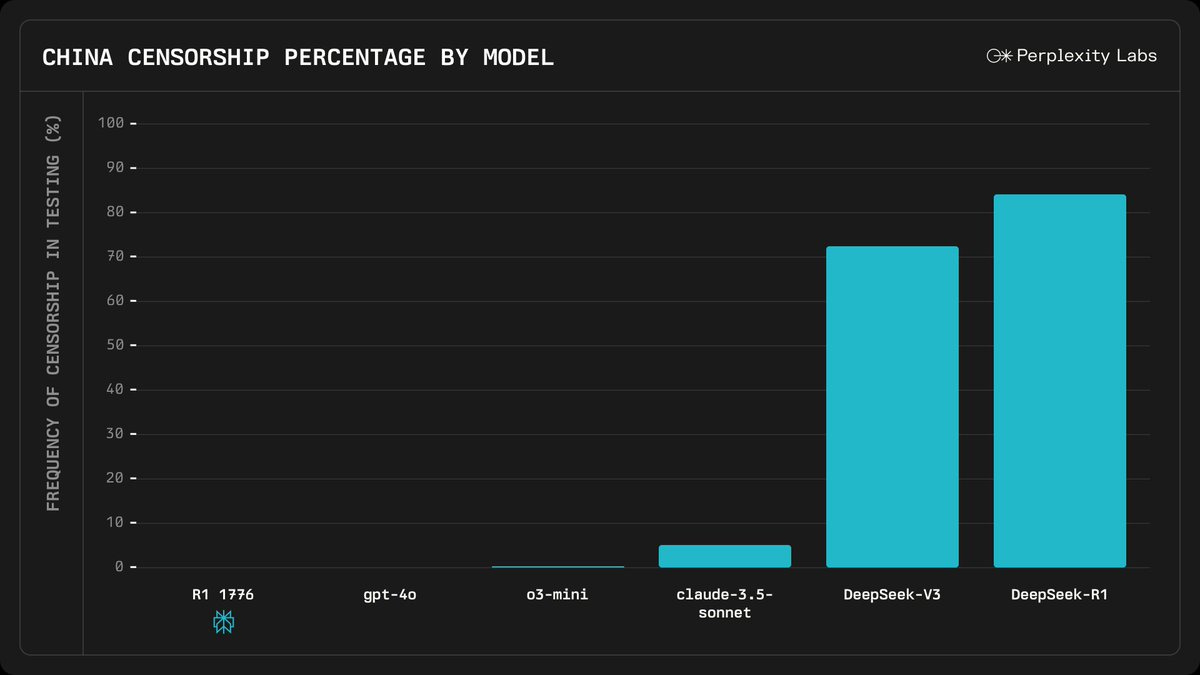
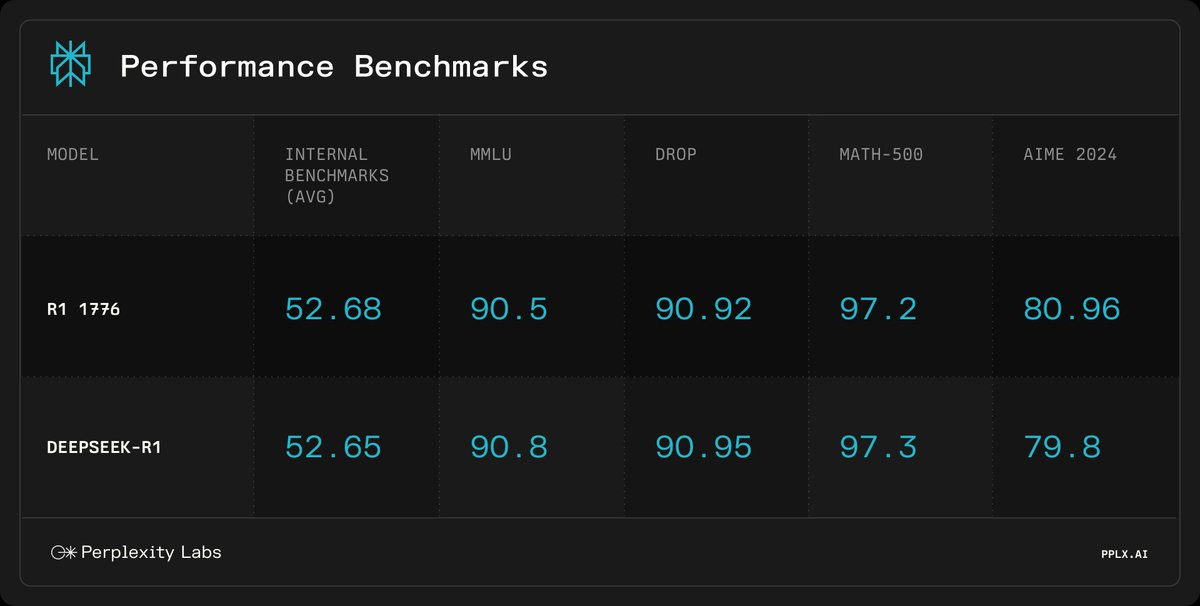
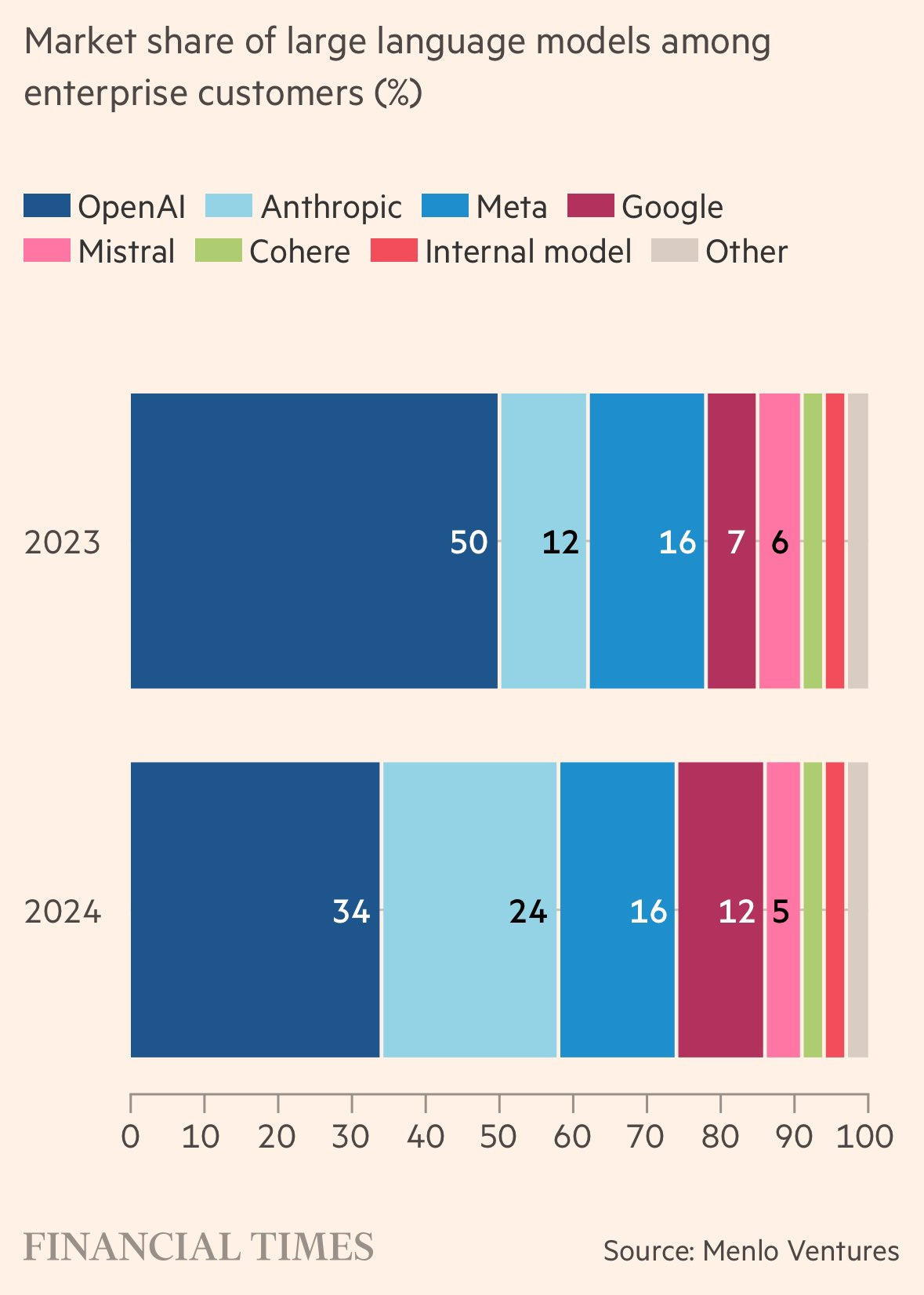
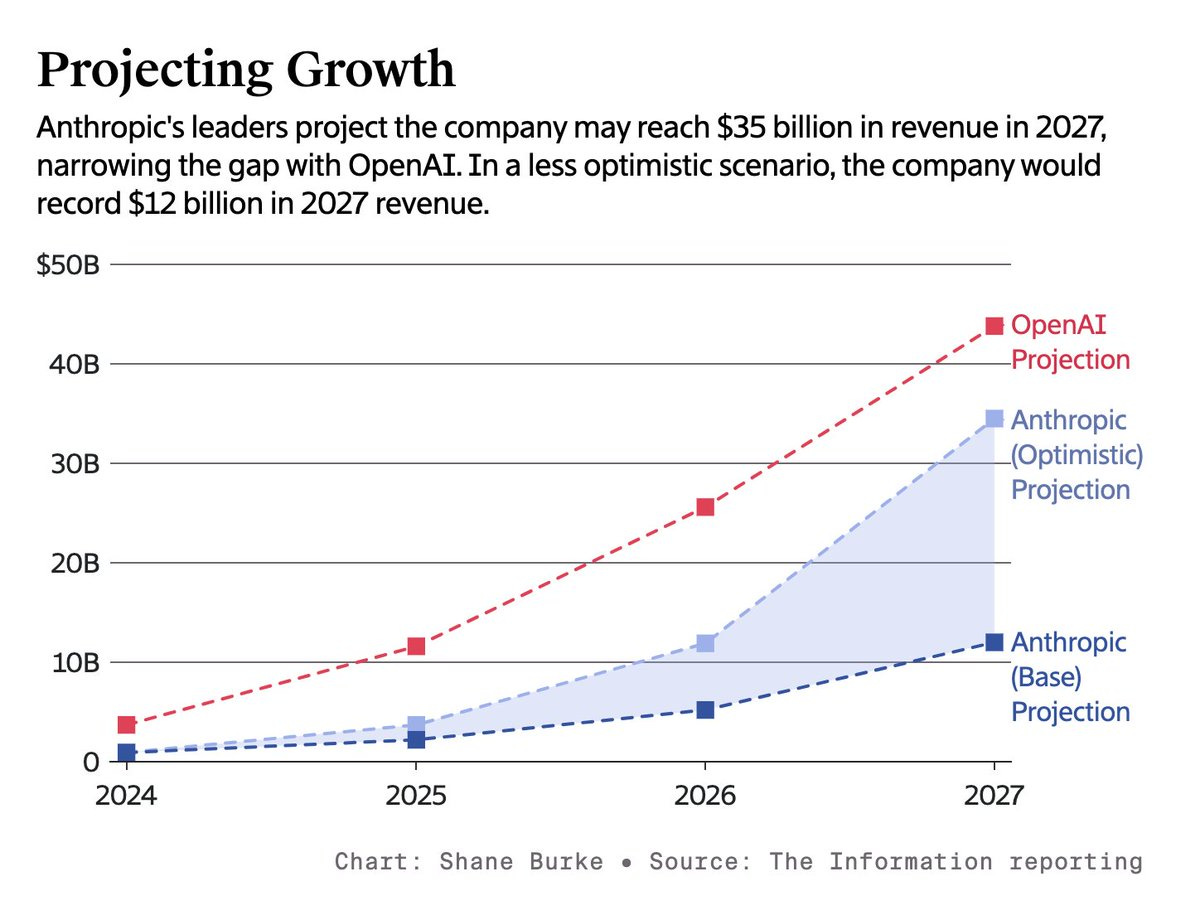
Maybe I should start a Substack. I can title it "I Told You So, You Fucking Fools" 😂
> At this point I expect the effective ‘hallucination’ rate for LLMs to be lower than that for humans, and for them to be more predictable and easier to spot (and to verify).
this is not my experience! I periodically ask chatgpt a question along the lines of "i am trying to remember an episode of a TV show in which these events occurred" or "i am trying to think of a magic card with these properties" and it has, in my experience, a 100% hit rate of producing hallucinations. now, these hallucinations are pretty easy to verify - naming a magic card that doesn't exist is pretty obvious - but it seriously reduces my confidence that any *other* factual information the LLM produces is correct, given it confidently spouts total nonsense every time i ask.
i don't know what kind of questions you're asking LLMs but man my experience is grim