Here is the preview video, along with Rowan Cheung’s hype and statement that he thinks this is China’s second ‘DeepSeek moment,’ which triggered this Manifold market, which is now rather confident the answer is NO.
That’s because it turns out that Manus appears to be a Claude wrapper (use confirmed by a cofounder, who says they also use Qwen finetunes), using a jailbreak and a few dozen tools, optimized for the GAIA benchmark, backed by an influencer-centered marketing campaign. The website is banned in China, perhaps due to use of Claude.
Daniel Eth: Anthropic researchers, trying to figure out why Manus is so good
I’m not saying this is something you’d expect to see at YC Demo Day, the execution level does seem better than that, but if instead of being Chinese this was instead from the latest YC batch put together by two kids from Stanford, I would not be batting an eye right now. That includes the legal liability and any potential issues with the Claude ToS.
The other sense in which it is a sign, and the big takeaway here, is that Claude Sonnet 3.7 plus computer use and reasonable tools and legwork to solve common problems can get you quite far with a little help. AI agents are coming, and fast. Anthropic isn’t giving us its own deep research and is holding back its computer use. Manus managed to undo some of those restrictions and give it a decent UI. You know who is best positioned to do that?
And no, I don’t think it’s (mostly) a question of regulatory legal risk.
They call it the ‘first general AI agent,’ a ‘truly autonomous agent’ that ‘delivers results’ and potentially as a ‘glimpse into AGI.’
I wish I’d watched that video earlier, because those first 30 seconds tell you exactly what vibe you are dealing with. That vibe is hype.
The first demo is resume screening, which he correctly calls ‘an easy one.’ The work in the background goes very quickly. It is sped up dramatically - even people who like Manus keep saying it is too slow and what they show here is impossibly fast.
Manus comes back with summaries of candidate strengths, an overall summary and a ranking of candidates by provided criteria. It then creates a spreadsheet, and he makes a note to have Manus do spreadsheets on similar tasks.
As he says, that’s an easy one. It doesn’t require an agent at all. It’s a Deep Research project, in the Gemini 1.5 DR sense, and nothing in it seemed impressive. Whatever.
Demo two is property research. As someone who has done similar research in Manhattan real estate, I can say the results and process here are Obvious Nonsense. It comes back with two particular places to recommend? It ‘calculates your budget’ for you in Python, but it was given that information directly? The whole thing screams, why would you ever want to do it this way? Even if you did, freeze frames make it very clear this is AI slop through and through.
Demo three is stock analysis, doing a correlation analysis. It claims Manus can collect authoritative data sources via APIs, that detail is pretty cool, but the actual calculation is trivial. Oh look, it’s another lousy Deep Research style report. Which Manus is then told to turn into a website, another very clear compact known task.
These are their curated examples.
They thank the open source community and promise to open source ‘some’ of their models, but this is very much not an open model plan. This is not DeepSeek, oh no.
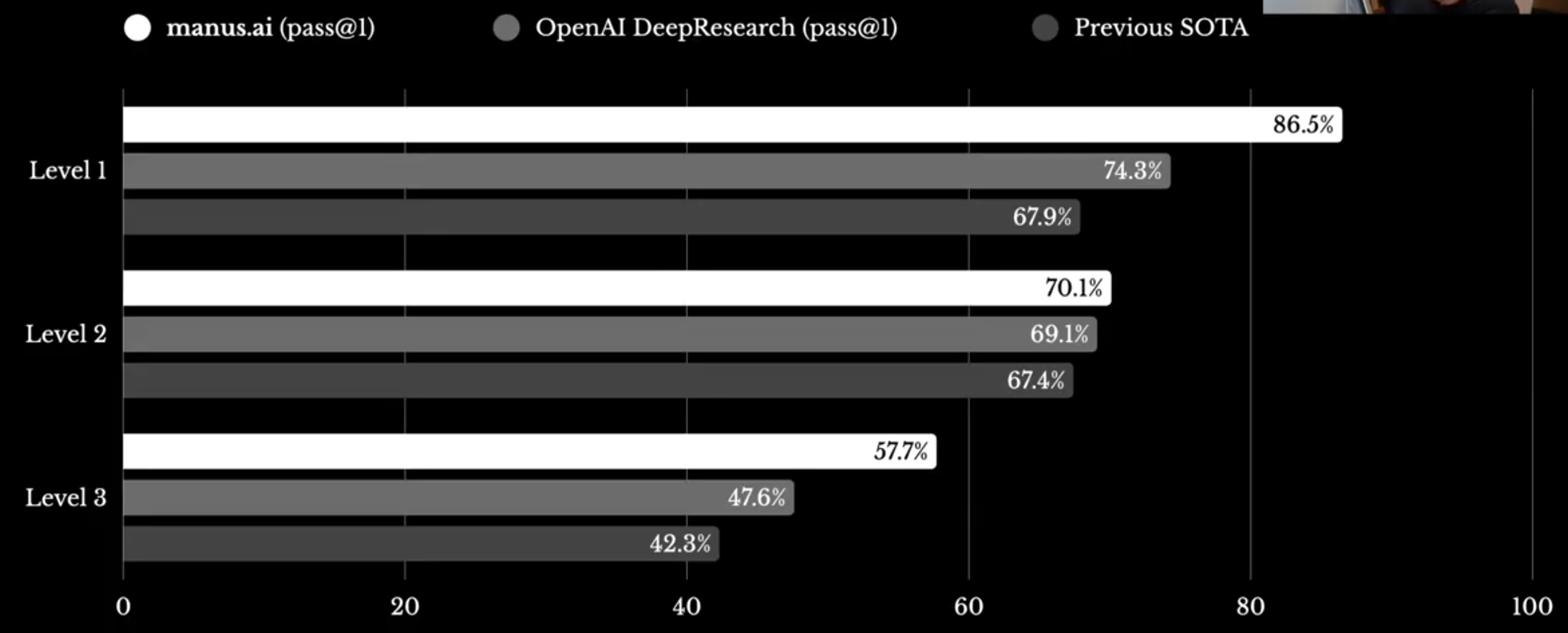
The one real concrete claim is SoTA on the OpenAI DR on the GAIA benchmark.
Those are impressive numbers. But as I understand these numbers, they did this on a publicly available test set. So if they wanted to game the benchmark, they could do so. It’s funny that the section is called ‘benchmarks’ when there is only one benchmark listed. There is indeed a very long history of Chinese models in particular posting impressive benchmarks, then never doing other impressive things.
What Manus Actually Is
Nathan Lambert: If I missed 100% of the manus news, what should I read?
Peter Wildeford (3/10): Missing the first 24hrs of Manus news was the right call.
Initial coverage is just hype and influencer marketing. Reality is emerging over the next 24hrs.
If you could judge by demos alone, we would've had driverless cars a decade ago.
It’s mostly a wrapper on Claude that uses a jailbreak prompt, 29 tools and browser_use, with what everyone does agree is a very good UI.
Jian: So... I just simply asked Manus to give me the files at "/opt/.manus/", and it just gave it to me, their sandbox runtime code...
> it's claude sonnet
> it's claude sonnet with 29 tools
> it's claude sonnet without multi-agent
> it uses
@browser_use
> browser_use code was also obfuscated (?)
> tools and prompts jailbreak
Teortaxes: I'm done with Manus thing I hope but… was this a blatant lie, or what? @jianxliao found that it's a Sonnet with tools, and they sure as hell did not post-train Sonnet. This could be on the level of Reflection grift, not mere hype & benchmaxx disappointment.
Jian: So... I literally oneshotted this code with Claude Sonnet 3.7 for replicating the exact same browser sandbox runtime that Manus uses.
And I am going to open-source it, welcome contributions for building out the React VNC client, integrating to browser use, agent loop, etc.
But we need a name first, should we call it...
- Autonomous Neural Universal System
- Magnus
- or ?
How I feel rn:
Yichao ‘Peak’ Ji (Cofounder for Manus): Hi! I'm Peak from Manus AI. Actually, it's not that complicated - the sandbox is directly accessible to each user (see screenshot for method). [continues, strongly claims multi-agent implementation and that it is key]
Here’s how Teortaxes puts it:
Teortaxes: after giving Manus a spin I conclude it's a product devilishly optimized for influencers, which is why it exploded so much. Generating threadboy content, trip plans and such general interest 🤯👇 stuff – yah. STEM assistance, coding – worse than googling. More LLM than agent.
if the problem in the pic is not obvious to you, it is obvious to my young Ph.D biochem friend and also to Sonnet 3.7, which (seeing as it took a few hours for this project) points to an easy improvement with a MoA “Am I bullshitting?” check. (also probably monomer, not dimer)
Minh Nhat Nguyen (screenshotting the in-demo resume example): mildly suspicious because if you look at the actual outputs, none of them are much better than just shoving the same docs into ChatGPT/Gemini. This is pretty standard GPT slop, it's just regurgitating the exact bullet points used. [As in, for each candidate it is just quoting from their resume]
none of the 15 listed sample use cases listed on their site look like something you couldn't do with normal ChatGPT Search or Perplexity.
I don't like to FUD releases especially before getting to use the product myself, but all this is quite sus.
I had the exact same impression when I looked at the use cases.
I really don't want to hate on them but this is some next level dark pattern, I don't mean this rhetorically, it's a meta-dark pattern, you get all these standalone grifters to grift for your grift
Sometimes I scare even myself with how good I am!
…not really, it's too easy to notice.
Slopfluencer automation is here.
The Nameless: yeah, i wouldn’t test it rn i skimmed the code and its p barebone. its just like any other oss deep research out there imo.
Chocolgist: tried a few tasks with it, didn't do very well
it got stuck multiple times, hallucinated stuff etc
plugged the same task into openai deep research and it oneshotted
so i guess it's still not at deep research level
promising tho, i like how it shows u everything it is doing, eg browsing
it's decent, just not sota prob overfitted on GAIA.
This was the most damning claim of all:
Alexander Doria (showing the GAIA benchmark): Ok. After testing the thing and reading a research report, I propose a moratorium on non-community benchmarks.
Johns: Actually, this product began a large-scale promotional campaign in China two days ago. Manus seems to have enlisted many Chinese AI influencers to praise it without any restraint, which sparked quite a discussion. However, most ordinary users still do not have access to it.
After a day of overwhelming and unrestrained publicity, Chinese netizens realized that this was a huge marketing scam, and manus' reputation in China has been ruined. Now they are conducting the exact same marketing operation on Twitter: only a few influencers have access, and they only offer praise, with no mention of any drawbacks.
Frankly speaking, after the release of deepseek, the whole world is prone to believe that there will be another outstanding Chinese AI product, and manus is exploiting this mindset.
Nathan Labenz: I have used it today and I think it is definitely something
Operator-like experience but smarter planning (OpenAI’s is intentionally dumb there from what I can tell) and longer leash
Obviously output won’t be without issues, but I got legit value on travel search and planning on first use
Google slides it fell down on - I think due to insufficient resources in the VM causing browser crash - should be easily fixed though not necessarily cheap to run
Way too early to call it a winner, but it’s a preview of the web agent future that doesn’t suck
Notably it handled an AirBnb date picker and actually returned links to places I could book with 1 “reserve” click
Operator struggled with that and most everything else has failed entirely ime.
Utopia: As far as I can tell Manus abstracts away the complexity of websites into something that is easier to handle for an AI agent. It doesn't actually look at a screenshot of the website and move the cursor pixel by pixel. I suspect it looks at the HTML code.
Now Ethan:
Ethan Mollick: Finally had a chance to try Manus. It's a Claude wrapper, but a very clever one. Runs into the same issues as general agents, including getting stuck, but also capable of some good stuff.
eg "get me the 10k for apple and visualize it in different ways to show me trends& details"
Short version is that if you have used other agentic systems like Claude Code or Deep Research, you will have a good sense of what this can do and what the limits are likely to be.
For those who haven't used them, I suspect a lot of people will be surprised at what LLMs can do.
It’s easy to be surprised if you’re not keeping up. Claude is really good, after all. If you’re really willing to spin Sonnet 3.7 for hours, as Manus will do, you should be able to get a lot out of that. The unit economics are not going to be pretty.
Mackay Wrigley: Watch for a 14min demo of me using Manus for the 1st time. It’s *shockingly* good.
Now imagine this in 2-3 years when: - it has >180 IQ - never stops working - is 10x faster - and runs in swarms by the 1000s AGI is coming - expect rapid progress.
Yes, in two years AI agents are going to be absurdly powerful. Wait for it.
Mackay Wrigley: I do really want to emphasize that both the agent under-the-hood and the actual UI are both *incredibly* well done. It’s legitimately impressive, and as a reminder, I don’t do paid posts. I saw the viral posts and kind of went “yeah doubt it’s that good” and boy was I wrong.
…
I do really want to emphasize that both the agent under-the-hood and the actual UI are both *incredibly* well done.
It’s legitimately impressive, and as a reminder, I don’t do paid posts.
I saw the viral posts and kind of went “yeah doubt it’s that good” and boy was I wrong.
Okay after further use I’m doubling down…
If OpenAI released an equivalent called DeepTask and charged $1k/mo for unlimited usage I’d pay it in 2 seconds.
It’s creating an entire research report + spec based on my preferred tech stack from latest versions.
wtf
…
Literally thought this was gonna be vaporware and now I’m amidst an existential crisis.
Claude 3.7 Sonnet + a computer + tools.
It’s so so so bullish that using Claude 3.7 Sonnet you can build something this good. Unhobblings are all you need.
I found his self-doubt hilarious, I would never expect Mckay to be unimpressed by anything. Perhaps that’s selection bias and when he isn’t impressed he stays quiet?
Mckay is an odd case, because he’s always super excited and enthusiastic, so you should interpret his statements as maybe modest enthusiasm. While the huge positive bias makes it difficult to take his pronouncements seriously, I do think he’s making a sincere attempt to process the situation. And he’s doing it right in the sense that he’s looking ahead to what a similar thing can be, not to what this current thing already is.
I strongly agree that ‘unhobbling is all you need’ applies to agents under Sonnet 3.7, at least sufficiently to take you reasonably far.
Still, oh man, hype!
Hype!
It’s easy to forget how many times we have to not fall for hype, especially for Chinese AI products that are catching up to use Real Soon Now. DeepSeek has been essentially the only exception so far.
People on the internet really do fall for a lot of hype. This was an extreme case, in that there was both a quick build up of hype and very quick pushback challenging the hype.
To start with the purest example: This post got 1.4 million views and a link in Marginal Revolution, showing a wide array of Twitter bots on simulated phones on a widescreen monitor, claiming to be about Manus.
As per official word, this one was entirely fake, the video is not Manus at all.
Which should have been obvious since Manus isn’t even for smartphones.
Stefan Schubert: It's incredible how gullible many people are re these nonsense clips, conjoined with some hype claim. Even though the cofounder of this company replies saying it's not them, it gets almost a thousand of retweets and breathless commentary, including from smart people. Ridiculous.
Hype works, in that you get headlines like ‘Was Manus Another DeepSeek moment?’ here in SCMP, whereas Wendy Chen wrote an article whose message is essentially ‘no, this is hype,’ fitting the pattern of headlines that take the form of a question.
Or you get linked to things like this AI Revolution video whose big selling point is that Manus is so hyped. The actual claims about what Manus can do are lifted directly from the one staged demo, and treat as remarkable feats that are highly unremarkable. We live in a world where we say things like (go to 4:10) ‘the specifics are unknown but the hype is real.’ It even picks up on the ‘AGI’ mention, which is over-the-top silly.
Chao Xing (QQ News, 3/8 17:21): Manus is still in the beta stage, and some technology self-media that got the invitation code started to hype it up after trying it out. "Another sleepless night in the technology circle," "Tonight the starry sky belongs to China," "On par with DeepSeek, kicking OpenAI," "AI Agent's DeepSeek moment"... big headlines and exclamation marks flooded the screen one after another, and netizens who have not actually experienced it can't help but feel like they are seeing things in the fog: "Is it really that amazing?"
…
Different standards and different positions will certainly lead to different judgments. In fact, both technological innovation and application innovation are worth encouraging. There is no need to create a contempt chain and judge who is superior. As for Manus itself, it is still difficult for it to handle many tasks and there are many problems that are difficult to overcome at this stage. Therefore, some self-media have exaggerated it and it is obviously suspected of excessive marketing to harvest traffic.
This impetuousness and utilitarianism are more clearly demonstrated in the "invitation code hype". In the past two days, on some social platforms and e-commerce websites, a Manus invitation code has even been hyped up to 50,000 to 100,000 yuan. In addition, some people paid to join the Manus study group, sell application services on behalf of others, sell application tutorials, etc. All kinds of chaos have caused a lot of negative public opinion. In response, Manus issued two articles to respond and apologize, saying that it completely underestimated everyone's enthusiasm, and at the same time refuted rumors such as opening a paid invitation code and investing in marketing budgets.
…
In the face of the “trend,” don’t “hype.” When looking forward to the next DeepSeek, don't forget how DeepSeek came about - not rushing for quick success and instant benefits, but making innovations down to earth.
One way is to create such an amazing product that everyone needs it now.
The other way is to issue a limited number of codes and a managed bought rollout.
Even if Manus were as useful as its advocates claim, it’s clearly that second way.
What is the Plan?
A Chinese company (still based in Wuhan!) aiming to create AI agents aimed for foreign markets would seem to be facing serious headwinds. A key element of effectively deploying AI agents is trust. Being Chinese is a serious barrier to that trust. There’s no moat for agent wrappers, so if it turns out to be good, wouldn’t an American VC-backed firm quickly eat its lunch?
The stated plan is to use hype to get data, then use the data to build something good.
Jordan Schneider: [Cofounder] Xiao is explicitly describing an intent to build an incumbent advantage on a foundation of user data, and TikTok demonstrates how effective that strategy can be. Reliance on eventual mass adoption could partially explain the high-publicity invite-only launch strategy for Manus (although limited access to compute is also certainly a factor).
That’s not the worst plan if you could go it alone, but again the valuation now is only $100 million, and the acquire-data-via-blitzscaling plan is going to be bottlenecked by some combination of funding and compute. Claude Sonnet is not cheap.
This is exactly where a16z finds some plausible founders, they put together a slide deck over the weekend and then everyone invests $3 billion at a $10 billion valuation, half in compute credits, and they have a superior version of this thing inside of a month.
The thing that makes blitzscaling work is network effects or other moats. It makes sense to have negative unit economics and to recklessly and brazely illegally scale if that locks in the customers. But with AI agents, there should be limited network effects, and essentially no moats. There will be some customer lock-in via customization, perhaps, but a good AI future agent should be able to solve that problem for you the same way it solves everything else.
So what’s the actual reason a Chinese company might have a competitive edge?
There are two reasons I’ve been able to figure out.
Manus as Hype Arbitrage
DeepSeek’s v3 and r1 were impressive achievements. They cooked. What was even more impressive was the hype involved. People compared the $5.5 million to train v3 to the entire capital cost structure of American companies, and treated r1’s (still actually impressive) capabilities as far better than they actually were, and also it got in right under the deadline, within a few weeks with Grok 3 and Claude 3.7 and GPT-4.5 and o3-mini-high with visible CoTs, it was clear that r1 wasn’t all that, and you mostly wouldn’t use it in cases where you didn’t need an open model.
Instead, we got this whole narrative of ‘China caught up to America’ which was, frankly, blatantly not true. But there’s a lot of momentum in that narrative, and a lot of people want to push it. It’s in the air. This is also partly due to other Chinese successes like TikTok and Temu, in general so many want to say China is winning.
If an American startup with no resources did this while eating Raman noodles, it is a curiosity. If a Chinese startup does it, it’s an international power story. And people have been primed that the Chinese will somehow put out the version ‘for the people’ or whatever. So, hype!
Manus as Regulatory Arbitrage (1)
There’s no question that the big American labs could have launched something better than even the best-case version of Manus well before Manus. But they didn’t.
Dean Ball raises the other theory. What if Manus is regulatory arbitrage?
This combines Dean’s claims from several threads, if you want details:
Dean Ball: It is wrong to call manus a “deepseek moment.” Deepseek was about replication of capabilities already publicly achieved by American firms. Manus is actually advancing the frontier. The most sophisticated computer using ai now comes from a Chinese startup, full stop.
It’s interesting to note that every single one of the use cases manus shows in their own demo video is heavily regulated in the us (employment, real estate, finance), and would specifically be very strictly regulated uses under the “algorithmic discrimination” regs in the states.
Every use case of manus in the company’s demo video would be an enormous liability and regulatory risk for American companies (under current law! No sb 1047 required!), particularly given the glitchiness of manus.
The first use case manus demonstrates in their video is using an ai to screen resumes. In multiple jurisdictions, and soon in many, there are many laws targeting this precise use of ai. Even without those laws, there have been eeoc actions against similar uses under existing civil rights law.
If an American firm had shipped manus last month at manus’ current quality level, they’d currently be facing multiple investigations by state attorneys general, and if a democrat had won the White House, ftc and/or doj too (and conceivably dol, sec, eeoc, pick your poison)
The United States does not have a light touch regulatory approach to ai. Without a single ai-specific law passing, the united states already has an exceptionally burdensome and complex ai regulatory regime. Without action, this problem gets worse, not better.
It’s not that complex:
1. The United States has a lot of really complicated and broadly drafted laws
2. Those laws are going to bite us in the ass over and over again with ai, since ai is a gpt
3. A republic is modestly resilient to overbroad laws, because it is supposed to be governed and peopled by the virtuous .
4. For a while, this was true, but it isn’t true anymore. In particular, our governing elite class is generally of remarkably poor quality (not a left-right criticism).
5. So we kinda don’t have a republic anymore, in the sense that we don’t have one of the most important ingredients for one, according to the founders of the country
6. The bad overbroad laws will be used by our bad elites in bad ways to distort and slow down the most important thing that’s ever happened
7. We are plausibly deeply and profoundly fucked, and even if not we have a lot of work to do to fix our entire regulatory apparatus
8. Tech people don’t tend to understand any of this because they haven’t thought deeply, for the most part, about these topics (which is fine!)
9. I am trying to warn them
To be clear, manus is not that surprising of a capability. I’m sure American companies have had such things behind closed doors for months. And I hear manus may even be based in part on us models (Claude).
The reason us firms haven’t shipped this capability is legal risk.
Nathan (replying to explanation of illegality of the demos): Sure but this is true of non agentic AI tools for this purpose.
Dean Ball: Yep. But enforcement actions in America aren’t motivated by facts, they’re motivated by headlines. Simply having a buzzy product is a regulatory risk for that reason.
The core argument is that America has lots of laws, almost anything you do violates those laws, including many currently common uses of AI, and at some point people will get big mad or respond to hype by trying to enforce the laws as written, and this will heavily slow down AI deployment in extremely expensive ways.
Or, to use his words, ‘we are plausibly deeply and profoundly f***ed, and even if not we have a lot of work to do to fix our entire regulatory apparatus.’
That statement is definitely true in general, rather than about AI! We are profoundly f***ed in a wide variety of ways. We almost can’t build houses, or transmission lines and power plants, or do most other things in the world of atoms, without horribly inflated costs and timelines and often not even then.
And to the extent we do still actually do things, quite often the way we do those things is we ignore the laws and the laws aren’t enforced, but AI reduces the levels of friction required to enforce those laws, and makes what was previously implicit and vague and deniable much easier to identify. Which in these cases is big trouble.
And yes, there are many state efforts currently out there that would make this situation worse, in some cases much worse, with very little in compensatory gains.
None of this has anything at all to do with existential risk or catastrophic risk concerns, or any attempt to prevent such outcomes, or any ‘doomer’ proposals. Indeed, those who notice that AI might kill everyone are consistently in opposition to the overly burdensome regulatory state across the board, usually including everything in AI aside from frontier model development.
As an obligatory aside you can skip: Dean mentions the vetoed SB 1047. It seems like a good time to point out that SB 1047 not only is not required, it would not have made these problems substantively worse and could have established a framework that if anything reduced uncertainty while imposing only very modest costs and only on the biggest players, while buying us a lot of transparency and responsibility for the things that actually matter. Even if you think there were few benefits to laws like SB 1047, it was a very foolish place to be concentrating rhetorical firepower. But I digress.
If we really do want America to win the future, then yes we need broad based regulatory reform to make it actually true that You Can Just Do Things again, because for AI to do something, the thing has to actually get done, and our laws have a problem with that. That is something I would be happy to support, indeed my nonprofit Balsa Research is all about trying to do some of that.
Thus, I think any time is a good time to raise the alarm about this. The last thing we want to do is charge ahead to superintelligence with no regulations on that whatsoever, potentially getting everyone killed, while we cannot reap the bounty of what AI we already have due to dumb regulations.
Indeed, the nightmare is that the very inability to exploit (in the best sense) AI causes America to feel it has no choice but to push even farther ahead, more recklessly, even faster, because otherwise we will fail to use what we have and risk falling behind.
Manus as Regulatory Arbitrage (2)
But how does this apply to Manus?
Dean Ball claims that an American company launching this would face multiple investigations and be in big legal trouble, and that legal risk is the reason American companies have not launched this.
I mostly don’t buy this.
I don’t buy it because of the track record, and because other considerations dominate.
We can draw a distinction between the large American tech companies worth tens of billions to trillions, including OpenAI, Google and Anthropic, and relatively small companies, largely startups, in a similar position to Manus.
For the larger companies, they did not launch a Manus because the product isn’t good enough yet, and they have reputations and customers to protect. Yes, there was also potential legal liability, but much more so in the ‘you lost all the customers money and they are mad about it’ sense than anything Dean Ball is complaining about. Mostly I see the risks as reputation loss borne of actual harm.
Also one can look at the track record. I expected vastly more legal trouble and restrictions for AI companies than we have actually seen.
We now regularly turn to AI for legal advice and medical advice. The AI offers it freely. The same goes for essentially everything else, there are simple jailbreaks for all the major LLMs. And it’s all fine, totally fine. What lawsuits there have been have been about the training data or other copyright violations.
Do we think for a second that AI isn’t being constantly used for resumes and real estate searches and such? Is there any attempt whatsoever to stop this?
The regime is very clear. I give you an AI to use how you see fit. What you choose to do with it is your problem. If you give an agent a command that violates EEOC’s rules, do not go crying to an AI developer.
The one way in which this might be a ‘DeepSeek moment’ is that it could give a green light to American companies to be more aggressive in what they release. OpenAI moved various releases up in response to r1, and it is possible so did xAI or Anthropic.
Manus could act similarly, by showing how excited people would be for an actually good unhobbled AI agent, even if it was unreliable and often fell on its face and has to have a gigantic ‘at your own risk on so many levels’ sign attached to it. Now that the competition seems to force your hand and ‘makes you look good’ on the security front, why not go for it? It’s not like the Trump administration is going to mind.
I don’t even see anything in the resume analysis here that is an obvious EEOC violation even for the employer here. I can certainly agree that it is a perilous use case.
Let’s move on then to the second case, since Dean claims all the demo cases had violations. Does Dean actually think that an AI company would get into trouble because an AI compiled a report on various different NYC neighborhoods and filtered through apartment listings, for a buyer? I don’t get where the objection comes from here. Yes, as a seller there are various things you are not allowed to mention or consider. But as the buyer, or on behalf of the buyer? That’s a different ballgame.
Today, right now, there are algorithmic programs that tell landlords what rent to charge, in what critics claim is collusion on price, and which also almost certainly takes into account all the characteristics considered here in the demo, one way or another? And they want laws to ban such uses, exactly because the software is in widespread use, here in America.
Then the third thing is a stock analysis and stock correlation analysis, which is again a thing firms offer all the time, and where again I don’t see the issue. Is this ‘investment advice’? It doesn’t seem like it to me, it seems very specific and measured, and if this is investment advice then it’s no worse than what we see from Claude or ChatGPT, which are giving investment, medical and legal advice constantly.
Dean’s response is that enforcement here is based on hype, not what you actually do. But most of the existing AI hype belongs to major AI companies, again which are aiding and abetting all these violations constantly. The relevant absurd laws are, quite correctly, not being enforced in these ways. There are no investigations.
We also have a long history of technology startups essentially ignoring various regulations, then ‘fixing it in post’ down the line or flat out upending the relevant laws. Who can forget Uber’s strategy, deploying a very explicitly illegal service?
Certainly when at the level of Manus, which again is raising around $100 million, companies in Silicon Valley or at YC are told to Just Ship Things, to Do Things That Don’t Scale, and worry about the regulatory problems later. Something like half the YC class are doing AI agents in one form or another.
So why didn’t one of them do it? We all agree it’s not lack of technical chops. I very much do not think it is ‘because they would face an inquiry from the EEOC or attorney general’ either. It’s vanishingly unlikely, and if it did happen a YC company would love to get that level of hype and investigation, and sort it out later, what great publicity, totally worth it.
The actual legal issue is that this is a Claude wrapper, that’s why it works so well. Of course you can get good results with a jailbreak-inclusive Claude wrapper if you don’t care about the downside risks, to the user or otherwise, and you tailor your presentation to a narrow set of use cases, then call it a ‘universal’ AI agent. The actual ‘regulatory arbitrage’ that counts here is that Anthropic would rather you didn’t do that and all the associated problems.
What If? (1)
Ignore the first sentence in Tyler Cowen’s post here, where he asserts that Manus is ‘for real, and ahead of its American counterparts.’ That’s a rather silly way of summarizing the situation, given everything we now know.
But as he notes, the more important question is the hypothetical. What would happen if a Chinese agentic product ‘got there’ before American agentic products, was an r2 wrapper rather than Claude, and was good enough that there was local incentive to let it ‘crawl all over American computers?’
The first answer is ‘Americans would beat it inside of a month.’
I don’t agree with Dean Ball that the main concern is legal risk in the sense of bias laws, but I do agree that the reason is a broader aversion to this form of general recklessness. It’s some combination of reputational risk, normal liability risk, some amount of amorphous weird legal risks, general alarm risk from agents being scary, and also compute limitations and a lack of focus on such projects.
If suddenly there were Chinese AI agents good enough that Americans were starting to deploy them, I predict that would all change quickly. There would not only be less fear of backlash, there would be government pressure to launch better agent products yesterday to fix the situation. Deals would be made.
What If? (2)
But let’s suppose a less convenient possible world, that this isn’t true, and the Americans are indefinitely unable to catch up. Now what?
Tyler’s claim is that there is not much we could do about it. Yes, we could ban the Chinese agent from government computers, but we basically can’t ban software use. Except, of course, we effectively tell people we can’t use things for various purposes all the time. We could and likely would absolutely ban such use in ‘critical infrastructure’ and in a wide variety of other use cases, remove it from app stores and so on. Almost everyone would go on using American versions in those spots instead even if they were objectively worse, it’s not hard to twist most arms on this.
Yes, some people would use VPNs or otherwise work around restrictions and use the Chinese versions anyway, but this is a strange place to think we can’t mostly tell people what to do.
The exception would be if the Chinese version was so superior that America would be crippled not to use it, but in that case we’ve pretty much already lost either way.
Tyler Cowen points out that if it were otherwise, and a Chinese agent system were to get deep within America’s computers and core functions, this scenario is an obviously unacceptable security risk, on various levels.
What If? (3)
But then he says maybe it’s fine, because the incentives will all work out, in some system of checks and balances?
Maybe this upends the authority of the CCP, somehow, he suggests? But without suggesting that perhaps this upends human authority in general, that perhaps the scenario being described is exactly one of gradual disempowerment as humans stop being meaningfully in charge? Except because he sees this as disempowering specifically the CCP it is oddly framed as something not to worry about, rather than an existential risk because the same thing happens to everyone else too?
He says ‘I am not talking about doomsday scenarios here’ but please stop and notice that no, you are wrong, you are talking about a doomsday scenario here! Alignment of the systems does not save you from this, do your economist job and solve for the equilibrium you yourself are implying.
Tyler Cowen: (There is plenty of discussion of alignment problems with AI. A neglected issue is whether the alignment solution resulting from the competitive process is biased on net toward “universal knowledge” entities, or some other such description, rather than “dogmatic entities.” Probably it is, and probably that is a good thing? …But is it always a good thing?)
If what survives into the future is simply ‘that which results from the competitive process’ then why do you think humanity is one of the things that survives?
Tyler Cowen: Let’s say China can indeed “beat” America at AI, but at the cost of giving up control over China, at least as that notion is currently understood. How does that change the world?
Solve for the equilibrium!
Who exactly should be most afraid of Manus and related advances to come?
Who loses the most status in the new, resulting checks and balances equilibrium?
Who gains?
So three responses.
First, it changes the world in that they would, by default, do it anyway, and give up control over China, and thus humanity would lose control over the future. Because they will do it gradually rather than all at once, before we have the chance to do it first, right? Isn’t that the ‘logical’ result?
Second, yes, now that we solved for the equilibrium, we should Pick Up the Phone.
Third, to answer your question of who should be most afraid…
Hype, yes, and "...its just Claude with N tools and X and Y..." and okay, but if that's all it takes to run our lives, then, yeah, we're pretty close to being cooked.
We're not all that complicated really. Most people really *could* be run inside a Very Small Shell Script.
Or as Anthony Hopkins in "Westworld" put it:
"Intelligence, it seems, is just like a Peacock really..."
"Yes, in two years AI agents are going to be absurdly powerful. Wait for it."
With every release of an agent that doesn't really work I update a little against this, actually. Not that I expected them to Really Work yet - but I'm kind of convinced by Colin Fraser's point that you can't really get goal-oriented behaviors out of LLMs yet: if they have goals at all, it's to simulate text, and simulating text that looks like solving problems doesn't suffice to solve lots of hard problems. It won't be critical enough of its own work, it won't have high enough standards.
Specifically I update against something like "a 10x scaled up GPT-4.5 with CoT and great scaffolding with aggressive agent-flavored RL" could produce good-enough agents. In that world, the gap probably requires a transformers-sized breakthrough, so to speak (though given the manpower thrown at this problem and the crazy-high benefits we might get that).








Hype, yes, and "...its just Claude with N tools and X and Y..." and okay, but if that's all it takes to run our lives, then, yeah, we're pretty close to being cooked.
We're not all that complicated really. Most people really *could* be run inside a Very Small Shell Script.
Or as Anthony Hopkins in "Westworld" put it:
"Intelligence, it seems, is just like a Peacock really..."
https://youtu.be/OjsGJOXhPGU
"Yes, in two years AI agents are going to be absurdly powerful. Wait for it."
With every release of an agent that doesn't really work I update a little against this, actually. Not that I expected them to Really Work yet - but I'm kind of convinced by Colin Fraser's point that you can't really get goal-oriented behaviors out of LLMs yet: if they have goals at all, it's to simulate text, and simulating text that looks like solving problems doesn't suffice to solve lots of hard problems. It won't be critical enough of its own work, it won't have high enough standards.
Specifically I update against something like "a 10x scaled up GPT-4.5 with CoT and great scaffolding with aggressive agent-flavored RL" could produce good-enough agents. In that world, the gap probably requires a transformers-sized breakthrough, so to speak (though given the manpower thrown at this problem and the crazy-high benefits we might get that).