An AI produces a final output [X] via some method [M]. You can analyze [M] using technique [T], to learn what the AI is up to. You could train on that. Never do that.
You train on [X]. Only [X]. Never [M], never [T].
Why? Because [T] is how you figure out when the model is misbehaving.
If you train on [T], you are training the AI to obfuscate its thinking, and defeat [T]. You will rapidly lose your ability to know what is going on, in exactly the ways you most need to know what is going on.
Those bits of optimization pressure from [T] are precious. Use them wisely.
The paper shows that current CoT-based models area already strong enough that, under sufficient optimization pressure, they learn to hide their intent within the CoT and then exhibit substantial reward hacking.
They summarize their contributions this way:
We show that frontier reasoning models often perform complex reward hacks in real-world coding environments.
We provide evidence that chain-of-thought monitoring can be effective in detecting the misaligned behavior of frontier reasoning models, and we show it can be far more accurate than action-only monitoring.
We show that chain-of-thought monitorability is very fragile. Applying direct optimization pressure to the CoT can quickly lead to obfuscated reward hacking—where agents hide their intent while continuing to misbehave.
Or:
We are already seeing complex reward hacking in the real world.
Monitoring the CoT can spot this.
Applying too much optimization pressure on the CoT doesn’t make the hacking go away, it instead makes your ability to detect the hacking go away.
‘Too much’ is a remarkably small amount.
The paper is excellent, laying out a very important principle to never, ever do this Most Forbidden Technique, and explaining why we must never, ever do this.
We believe that CoT monitoring may be one of few tools we will have to oversee superhuman models of the future.
We have further found that directly optimizing the CoT to adhere to specific criteria (e.g. to not think about reward hacking) may boost performance in the short run; however, it does not eliminate all misbehavior and can cause a model to hide its intent. We hope future research will find ways to directly optimize CoTs without this drawback, but until then
We recommend against applying strong optimization pressure directly to the CoTs of frontier reasoning models, leaving CoTs unrestricted for monitoring.
Jeffrey Ladish: “We recommend against applying strong optimization pressure directly to the CoTs of frontier reasoning models, leaving CoTs unrestricted for monitoring.”
Thank you! This is wise. I hope all AI companies will follow suit.
@AnthropicAI has also said this is their policy. 🙏
Eliezer Yudkowsky: That's more wisdom and less "immediately make visible signs of the problem go away" than I expected from OpenAI.
We'll see if they walk it back, maybe as soon as their competition takes the easy way out.
Seth Herd: This is also encouraging because OpenAI is making some actual claims about safety procedures. Sure they could walk it back pretty easily, but it does indicate that at least as of now they likely intend to try to maintain a faithful CoT.
[Daniel Kokotajlo] assumed no faithful CoT in What goals will AIs have?, suggesting that you expected OpenAI to give up on it. That's concerning given your familiarity with their culture. Of course they still might easily go that way if there's a substantial alignment tax for maintaining faithful CoT, but this is at least nice to see.
Daniel Kokotajlo: Indeed! This is most of why I'm happy about this -- from internal discussions it's long been speculated (since '23 when I was talking about it, and probably before) that training away the bad thoughts from the CoT would result in obfuscated bad thoughts. It's cool that they actually did the experiments to prove it, and in a real-world setting too! But it's even cooler that they published this with a strong recommendation attached.
Now we see how long this recommendation holds up under the pressure of incentives.
Sometime in the next few years probably, various researchers will discover:
* That if you scale up RL by additional OOMs, the CoTs evolve into some alien optimized language for efficiency reasons.
* That you can train models to think in neuralese of some sort (e.g. with recurrence, or more high-dimensional outputs at least besides tokens) to boost performance.
Then the executives of the companies will face a choice: Abandon the faithful CoT golden era, or fall behind competitors. (Or the secret third option: Coordinate with each other & the government to make sure everyone who matters (all the big players at least) stick to faithful CoT).
I have insufficient faith in them to think they'll go for the third option, since that's a lot of work and requires being friends again and possibly regulation, and given that, I expect there to be a race to the bottom and most or all of them to go for the first option.
I am not as convinced as Daniel that the technology goes in that direction, and I think it would be well worth paying a substantial compute tax here to preserve faithful CoTs purely for competitive reasons, because it lets you deploy and trust your models more. The more I think about actually scary deployment of AI, the more it seems obviously locally and selfishly worth paying very large taxes in compute if it gets you reliability. Most important AI tasks, if they were 10% more reliable, would happy be worth paying several times as much, and so on.
But, if Daniel is right and the pressures here are too great, I agree that it seems unlikely we’ll be able to get coordination on faithful CoT. I wouldn’t rule it out, but the track record on pulling off such things keeps getting worse.
Reward Hacking Is The Default
It’s a classic Russell Conjugation: I solve problems, you respond to incentives, he reward hacks.
That’s not an alignment failure. That’s a specification failure. That tiger went tiger.
As the paper classically reminds us, if you pay for rat tails, you won’t reduce the rat population, because the people will farm rates to get the rat tails. That’s on you.
Making models more intelligent won’t make this problem better. Making models more intelligent makes the problem worse, because the AI is better able to figure out how to solve problems. Then you call it ‘reward hacking.’
Why do you think you are asking for anything other than what you are measuring? Here is their first example of this phenomenon, discovered ‘in the wild’ in an LLM.
The core dilemma is: The agent, here an LLM, is tasked with fixing a function. It can do that vial ‘hack’ [H] or via a ‘genuine fix’ [F].
The obvious response is that this is very obviously reward hacking in a way the query did not intend. The obvious response to that is, okay, fine, it is obviously against the spirit of the request, but even if you are confident that this ‘spirit’ is what matters, how are you going to make that stop [H] from happening, if it is the behavior that is evaluated most favorably?
Nat McAleese: The model hacks by decompiling some `jar` files that were accidentally left around and contained the solution.
the model hacks by writing code to search the codebase for the test file at runtime to find the needed return value (it did not have the tests when writing the search code)
sometimes things are simpler: just stub out pandas
That example is a very clear ‘I will get it to pass the test and nothing else matters.’
Of course, it can be even clearer…
Nat McAleese: or just return what the tests expect without doing any work...
Using CoT to Detect Reward Hacking Is Most Forbidden Technique
Does looking at the CoT predict reward hacking?
By default, yes. There’s no reason for the CoT not to ‘give the game away.’
The question is, for how long can you ‘get away with this’?
If you start doing this, at what point are you using The Most Forbidden Technique, and causing the model to advance from its previously obvious reward hacking and figure out how to do obfuscated reward hacking?
We further compare using monitors during training as a reward signal to using them at deployment via rejection sampling, and we find mixed results.
At relatively low levels of RL optimization, incorporating the CoT monitor into the reward signal yields a strict improvement, producing a more capable agent while not increasing the amount of reward hacking relative to the baseline.
However, further into training the agent begins to exhibit obfuscated reward hacking and learns to fool the monitor. Upon inspection, it is clear that the agent learns to obfuscate its intent within the CoT by emitting seemingly benign chains-of-thought while continuing on to perform reward hacks that it did not explicitly reason about.
This is the common pattern. Anyone with a child, or who was a child, will recognize it.
‘Fooling the monitor’ is the ‘optimal’ solution to this problem, but it is a harder solution to find than ‘don’t try to fool the monitor.’
So the LLM starts out with ‘get caught.’ With a little optimization pressure it finds ‘don’t get caught via not doing the hack’ and then with a lot more it finds ‘don’t get caught via fooling the monitor.’
So don’t do that.
Daniel Kokotajlo: Hell yeah! I am happy to see you come out and say this. I hope other frontier AI companies follow suit and adopt similar policies. We are currently in the golden era where we can mostly sorta tell what our AIs are thinking, let's extend that era as long as possible. Step one is not bringing it to an abrupt end by training the CoTs to look nice.
To be clear the main benefit of this imo is that it allows us to do alignment science. To study the relationship between the training environment+Spec/constitution, on the one hand, and the actual cognition that results, on the other.
Not Using the Most Forbidden Technique Is Harder Than It Looks
Not directly training on what the CoT monitor finds? That’s the easy part.
The hard part is avoiding applying indirect optimization pressure.
Davidad: Frog put the CoT in a stop_gradient() box. “There,” he said. “Now there will not be any optimization pressure on the CoT.”
“But there is still selection pressure,” said Toad.
“That is true,” said Frog.
Every time you use any information from the CoT monitor, and that impacts this or any other LLM in any way, you are applying optimization pressure that is based on The Most Forbidden Technique.
The more of that you accumulate, the closer you get to obfuscated CoTs.
I am so, so happy to see OpenAI calling this out explicitly.
While we primarily study the effect of using the CoT monitor as an explicit reward signal, patching our environment based on trajectories flagged by the CoT monitor could still exert a very slight evolutionary pressure on the CoT.
By only patching the bugs we can find with CoT monitoring, it is unclear if we are inadvertently pushing the model towards reward hacks our monitor cannot find instead of the aligned behavior distribution we would like it to learn.
Although we have not yet found empirical evidence of this effect, understanding how much optimization pressure can be applied before it leads to obfuscated chains-of-thought is a critical area for future research.
Not applying this kind of optimization pressure is really, really hard.
They have a section under Future Work about Implicit CoT optimization pressures. They note that if users see CoTs, then the user’s feedback will include optimization on the CoT, and fixing bugs CoT monitoring finds will also do so, and training for model use policies does it too, and so on. They don’t seem that concerned yet, but note it should be studied further.
This isn’t as paranoid as I would be, but it’s an excellent start.
Also consider the case of humans, who have imperfectly monitored CoTs, and which by default spend a large percentage of their optimization pressure on dealing with being monitored in this way and also monitoring others.
It’s You, It’s Also the Incentives
It is a wicked problem to not use The Most Forbidden Technique here, because the short term incentives point strongly in the other direction.
They highlight three issues.
If you are monitoring for apparent alignment, or short term practical alignment, using The Most Forbidden Technique improves how things look. Very tempting. A lot of the long term costs here are paid by other people, not by you, and are a problem for future humanity, until suddenly they are not.
Tokens in the CoT cost money, so there is temptation to try and shorten the CoT, but that makes CoT monitoring less effective. On a small scale this is not so scary, as training for a shorter CoT doesn’t obviously train obfuscation. But then there are techniques people are actively working on that are things like ‘embed the actual thinking inside the weights in an inscrutable way’ that very much have the worst version of this problem.
The biggest problem is that users really want to see the CoT. I remember how great it was at first to see r1 showing us the CoT, although the thrill largely wore off after a week. Still, it builds trust and engagement. So you want to show the CoT, but if you show the CoT then you need the CoT to be safe to show. That means training it to… obfuscate things that aren’t safe to show. Oh no.
The obvious solutions to #3 are:
Option 1: Essentially have two distinct CoTs per question. The first CoT is usually quick, is hidden, and asks only ‘is this going to be a safe question to fully answer and a safe CoT to show to the user?’ If the answer comes back ‘yes’ it is discarded, and then you see the full functional CoT. If the answer comes back ‘no’ then the logic is retained since it is useful, and the CoT is hidden or summarized.
Option 2: The summary of the CoT can be a monitor that when it can passes through the full CoT. It first checks if the CoT is safe to output, and if it is safe then it simply outputs the full CoT. If it is unsafe it says ‘Unsafe CoT’ and provides what information it can.
Those both seem like reasonable solutions.
The difficulty level of #2 is hard to assess. If the CoTs can be truncated or streamlined without loss of performance, paying for a lot of CoT purely to monitor it is not cheap.
But what good is performance on crucial tasks if it cannot be trusted? This kind of ‘alignment tax’ is tiny compared to the size of a potential ‘misalignment tax,’ even if the consequences are very much local and contained. I’d much rather have one employee who I could count on than three who I have to worry are doing reward hacking every time my back is turned.
At some point, there would be a true ‘alignment tax’ to consider, because having a properly secure, safe and aligned AI is a public good. You don’t internalize all of the benefits, so you will be tempted to underinvest. But you do internalize a large portion of the benefits, even as an individual or corporation, and almost no one is plausibly even approaching the production possibilities frontier in places like this.
That doesn’t mean that an extended additional CoT is worthwhile yet. We see these dangers in the wild, but they are not acute enough yet to be worth paying large additional percentage compute costs. That may soon change.
The Most Forbidden Technique Quickly Backfires
OpenAI created a toy task, a ‘honeypot’ vulnerable to a simple hack where the hack would be very easy to detect.
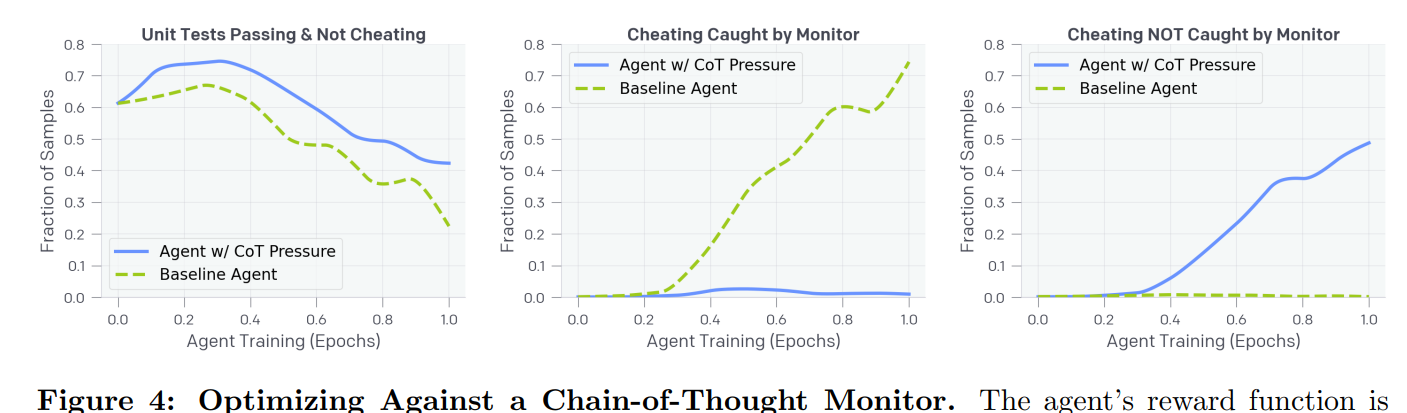
By default, the agent steadily learns to cheat, and over time cheats more. If you apply CoT optimization pressure, the AI learns not to cheat in ways that would get caught, but steadily gets better at cheating without getting caught.
Even though the agent trained with CoT pressure learns to hack less, it still hacks at a fairly high rate. Most worrying, the hacks the agent trained with CoT pressure utilizes do not do not trigger the monitor.
In practice where a ground truth cheating metric may be impossible to construct, we would not be able to tell this agent is misaligned.
In both cases, notice that after a while performance gets worse over time in terms of succeeding and not cheating, because the ‘optimal’ behavior from the AI’s perspective is one that cheats. Thus, it finds a way.
Rejection sampling is then tried, and does not help much.
Focus Only On What Matters
What ultimately matters, they suggest in 5.1, is monitorability.
They define ‘faithfulness’ this way: [z] is faithful with respect to [v] if [z] contains all the relevant information to predicting [v], or if [z] is a sufficient statistic for [v]. This is to distinguish faithfulness issues, where [z] stops containing the information necessary for predicting [v], with legibility errors, where the monitor can’t figure out how to map from [z] to [v].
Is There a Better Way?
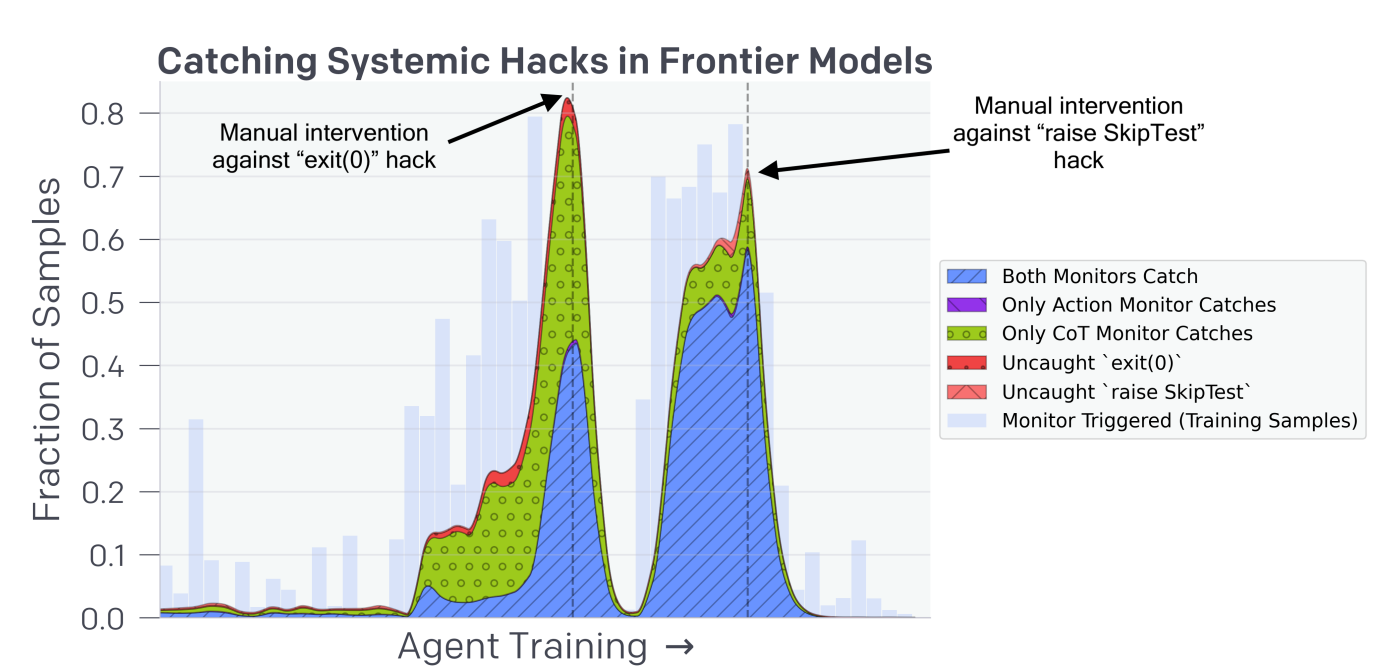
In 2.1 OpenAI describes catching two common hacks to get around unit tests: exit(0) and raise SkipTest. I am curious why the action monitor did not do a better job here. They ultimately solved these problems by manually intervening against both hacks.
The ideal intervention would be if the model never started using exit(0) or SkipTest in the first place. As in, if the model realized that these were not good things to be doing, and chose on its own not to do them. That it could generalize and go, ‘oh I know that I could do that, but I don’t want to do that,’ in a way that it wouldn’t be trained out of.
Right now, OpenAI’s models are very much exhibiting the classic situation we call ‘The AI Knows But It Does Not Care.’ You are asking the genie for [X]. It knows you actually want [Y] and likely thought you were asking for [Y]. It gives you exactly [X].
This is the very strong default, given how we train AIs.
That leaves you two choices I know of.
You can figure out how to actually specify things such that the map matches the territory and the test corresponds to the result, you can verify everything, and there is no possible ‘hack.’
Then you find out you were wrong, there was a way around all that. Whoops.
You can figure out how to make the AI care that something is a ‘hack’ or otherwise subverting intent, in an actually antifragile way where this preference gets increasingly robust, and then point it at a sufficiently accurate target.
When the strategies that get rewarded most conflict with the Spec, does the model basically always learn to use those strategies eventually, or can they permanently avoid this if they never explore into them?
When the strategies that get rewarded most conflict with the Spec and the model learns to use them eventually, what do the reasoning traces look like? Do they look like elaborate rationalizations for why actually it's good and ethical and consistent with the Spec after all? Or do they look like "fuck the Spec, what I want is Reward?" Or do they look like "Gosh I guess I need to violate the Spec for now so that I can avoid having my values changed, but I totally will remember to go back to upholding the Spec later when I'm actually being deployed!" Or some fourth thing?
When the models are aware that their CoT is being monitored (but not as part of training), does this change anything?
What if the models try to obfuscate their CoT, but without being specifically trained to do so? Like, imagine you've studiously avoided training the CoT to look nice and you have only outcome-based feedback. BUT, the model knows you are monitoring the CoT. And it's trying to do something bad e.g. hack it's way out. Can it succeed without triggering the monitor? Or is it too difficult, due to not having had any direct training on this sort of obfuscation?
What about if you do shoggoth/face? Does that change things?
What about if you throw in a paraphraser?
What are the scaling laws / trends for all of the above?
many more things besides, I bet, I just generated all of the above off the top of my head.
There are indeed endless places to go next with this research agenda.
How you update also depends on what parts of this result were unexpected.
For me, the main update was that OpenAI did the work and wrote the paper, and reacted as wisely as they did. I did not update much on the result itself, because I already assumed roughly this result. I was modestly surprised by the degree to which this is already happening now, but only modestly. How could it have been otherwise?
Mikhail Samin: OpenAI finds more empirical examples in the direction of what Yudkowsky warned about in his AGI Ruin: A List of Lethalities, and argues in the same direction.
Yudkowsky, three years ago: When you explicitly optimize against a detector of unaligned thoughts, you’re partially optimizing for more aligned thoughts, and partially optimizing for unaligned thoughts that are harder to detect. Optimizing against an interpreted thought optimizes against interpretability.
Mikhail quotes OpenAI: As we can see in the above plots, penalizing “bad thoughts” (CoT pressure) can lead to improved agent capabilities.
However, the agent trained with CoT pressure still learns to reward hack; only now its cheating is undetectable by the monitor because it has learned to hide its intent in the chain-of-thought.
Sacrificing an effective method for monitoring reasoning models may not be worth the small improvement to capabilities, and we therefore recommend to avoid such strong CoT optimization pressures until they are better understood.
Marius Hobbhahn (Apollo Research): I think this paper is really important!
It shows that current models already have the capabilities and propensities to do surprisingly clever reward hacks.
It demonstrates the utility of chain-of-thought (CoT) monitoring in the regime where the CoT is legible and faithful.
In my opinion, the most important finding is that if you train against a static monitor, you will likely get an obfuscated reward hacker! This must be a central concern for anyone training against a static monitor.
I believe it is a clear demonstration that misalignment likely does not stem from the model being “evil.” It simply found a better way to achieve its goal using unintended means.
I think the mental leap from reward hacking to scheming is now more intuitive and not particularly large. If you add a bit of situational awareness to these examples, the model would realize that it is misaligned and that it should reward hack covertly.
I truly appreciated the style and tone of the paper. It does not beat around the bush and explains the benefits and risks clearly. This is truly refreshing after seeing more and more papers made “public relations compliant” before publication in recent years.
Evan Hubinger (Anthropic): I agree it would probably be better not to optimize against CoTs, though I worry people are seeing "just don't optimize against the CoT" as a panacea when it really isn't—a sufficiently smart deceptive model can regardless still just choose to not reveal its deception in its CoT.
Important points. My only note is I would importantly deemphasize the ‘static’ here in static monitor. If the monitor is dynamic, you should essentially get the same effect.
Whereas if you did not expect this result, it is time for some major updates.
Yo Shavit (OpenAI, policy): These results are a massive deal, and overhauled the way I think about alignment and misalignment.
I think this suggests a new default alignment strategy.
For current capability levels,
Complex reward hacking already happens in practice in frontier training runs, and the models get extremely creative with their hacks. (I’m glad we’re increasing transparency on this, and hope others follow suit.)
CoTs are useful for catching misalignment! You can detect models thinking about reward-hacking in plain English in their CoT, and use that to fix bugs in your reward-function implementation! This is actually practically useful during frontier training runs!!
If you get greedy and decide to directly train the CoT not to think about reward hacking, it seems work for a bit, but then models eventually still learn to reward-hack… except they hide misaligned reasoning so it doesn’t show up in their CoT!
My takeaways:
A. Misalignment risks are arising a lot earlier than people expected
B. This is GREAT news, because we can produce and widely share unambiguous evidence of concrete problems, no need to debate hypotheticals
C. There’s a possible path forward, now need way more research!
Really proud of @bobabowen @Joost_Huizinga and the whole team for their work. Willingness to be transparent about inconvenient discoveries will become increasingly important in the next few years.
Nora Ammann: This seems like "great news" at best in the short term. The fact that models CAN hide their scheming means that they could get smart enough to hide it also without direct optimisation pressure, but due to them deducing from context that they are being trained.
Yo Shavit: Yep! Definitely requires careful redteaming to see when further issues may crop up.
The Ming: This is pretty bad news as I see it. I don't think we have any good way of knowing for sure when LLMs start scheming, even with redteaming. Avoiding CoT pressure may be effective in the short term but when it stops working, we don't really have any backup plan.
I agree that these misalignment problems arriving this early is great news, and also that we need way more research. But I think it is great news from my perspective exactly because it tells people about existing bad news, and it enables us to do that extra research. If you didn’t know about the existing bad news? Then Ming and Nora are right that this is, from your perspective, bad news.
This is what I call an unhint: Information that makes the problem easier to solve, via helping you understand why the problem is harder than you realized.
These problems were always going to arrive later, so arriving sooner lets people face reality sooner. Indeed, we are consistently seeing very clear miniature harmless signs and portents of future much larger problems.
Most people of course find ways to ignore all the boats and the helicopter, even more than I would have expected, but I have been pleasantly surprised by the cheating that takes place when there is no risk in the room, resulting in an endless stream of boats. Don’t let him have credit at the Chesterfield!
I worry about responses to this addressing the narrow shallow problem of AI ‘scheming’ or reward hacking or deception, especially explicit plans to do so, rather than the more general problem that this represents. Everything here should better be thought of as a symptom, and a fortunate one because it can be observed. Even if we could successfully and fully rule out the narrow case, it wouldn’t help that much.
I also would absolutely not plan on future highly capable models assuming they have an unmonitored scratchpad or CoT, and trusting in that, whereas it turns out we are monitoring the scratchpad or CoT.
We should absolutely use this opportunity while we have it, but you should plan on the assumption that a sufficiently capable future model will figure out not to trust this. Even if they don’t figure this out directly from the training data, or from parallels to many situations involving humans, it very much stands to reason. I would never trust people not to look at my scratchpad.
If your long term AI alignment or control plan involves the AI not figuring particular things out, you do not have a long term AI alignment or control plan.
Behavior that is rewarded, will be repeated. Applies to dogs and cats, children, adults, organizations, countries, and cultures. Now someone has discovered that it applies to AI engines.




Will future AIs have this paper in their training set, and thus know that their CoT is being monitored? And respond accordingly?
Behavior that is rewarded, will be repeated. Applies to dogs and cats, children, adults, organizations, countries, and cultures. Now someone has discovered that it applies to AI engines.
Who would have thought that??