A lot happened, but by today’s standards this felt like a quiet week.
I was happy for the break, and I hope that we get to continue relatively relaxing.
The Anthropic PBC vs. Department of War case is working its way through the system. The government responded on Tuesday, and the preliminary hearing is next week. I covered that here.
Once that is out of the way, I plan to cover Anthropic’s RSP v3, both the fact that it went back on previous promises and an analysis of its new more flexible contents, including a reading of the full risk report.
CureCancer.ai offers an extensive perspective on how AI can, and can’t, cure cancer, with a focus on various bottlenecks other than intelligence, and a version of ‘Silicon Valley doesn’t get how hard this is’ throughout.
Patrick Heizer: Sorry to be the downer because this is an impressive story in some senses. But it is ~trivially easy to make a single mRNA vaccine. It's not hard.
I cure mice of various cancers with various therapeutics all the time. I've made mice lose more weight in a month than tirzepatide does in a year.
What is hard and expensive is proving its BOTH safe AND effective **in a randomized and controlled study in humans** while ALSO manufacturing it at clinical scale and grade. I am happy for this man and his dog. It is impressive.
But y'all are overhyping it.
I literally have an ongoing cancer experiment where 100% of the untreated and control animals have had to be euthanized while 100% of the treatment animals are seemingly unaffected. But we're still extremely far away from "proving that it works." Science is hard.
Eddy Lazzarin: “You guys are overhyping this” “Yes we can cure cancer and do regularly this way” “Yes the primary obstacles are regulatory/liability” uh
Crémieux: "Sorry to be a downer but [the best news you'll read this month]." Yes, custom mRNA vaccines for cancers are here, and if the FDA allows it, millions and millions of people can access them for low prices.
Patrick Collison: • According to the story, the dog's cancer has not been cured. • Absent all regulatory and manufacturing constraints, we could not just synthesize magic mRNA cancer cures. The technology is very promising, but it's not yet any kind of panacea. • The emergent system of regulators and manufacturers is indeed far too conservative, and small-scale experimentation is much harder than it should be. More people should read the first part of The Rise and Fall of Modern Medicine. Recommend @RuxandraTeslo , @PatrickHeizer for more.
It sure sounds like science is awesome and in this case straightforward, using it more would quickly let us figure out how to do it cheaply and at scale, and something about the way we ‘prove’ things is getting in the way. It’s a policy choice.
I get that that’s a long way from ‘curing cancer’ or from diffusing a full solution, and that as long as we continue with current policy that gap will persist, even if our AIs get a lot better at finding physical solutions, which they will.
GPT-5.4 recommended the correct immediate care in emergency cases over 99% of the time, by being able to 80% of the time ask for additional context. This is in contrast to a story last month where the AI was asked multiple choice questions with no opportunity to ask questions.
Kagi translate (translate.kagi.com) will let you put anything in the ‘to’ parameter, letting you translate into the rhetorical stylings of (examples from thread) Matthew Yglesias, Barack Obama, George Costanza or Eliezer Yudkowsky.
You can use an LLM in place of your real estate agent, although you still will need your lawyer. You can then say that this saved you money, but it is impossible to know what the counterfactual price would have been, and it depends in part on which agent you would have hired. I would absolutely use LLMs to do market research, but that doesn’t mean you shouldn’t also use people. It seems a bit early for that.
Reverse engineer NES Contra, using an automated ‘see if it matches the emulator’ overnight loop. Next step is to change the Konami code and not tell anyone.
Language Models Don’t Offer Mundane Utility
If you try to have Claude Code read way more than a million tokens of academic papers, it will cheat in various ways, and read less than that. That’s not ideal behavior, but mostly that’s on you for an impossible ask poorly structured. If you want it to handle more text than it can see at once, you need to use sub-agents and summaries or other similar techniques. Or just don’t ask it to read all of it at once like that.
If you ask 150 different Claude Code instances to analyze the same economics data you get high variance in reported results. An attempt at AI peer review did not fix this. ‘Exemplar exposure,’ as in showing agents the five highest rates papers, did collapse estimates but also presumably made the whole exercise worthless since they went into imitation mode.
I am imagining a cure for aging, a Dyson sphere and an OpenAI that speaks truth.
Greg Brockman (President OpenAI): if you can imagine it, you can build it.
If you put them in the wrong harness, minds don’t work as well. That includes you. Humans who are not concentrating are not general intelligences. Always check if your ‘this proves how far we are from AGI’ argument applies to humans.
François Chollet: The persisting importance of prompt engineering -- and now harness engineering -- is one of the best indicators of how far we are from AGI. A general system doesn't need a task-specific harness. And when provided with instructions, it is robust to phrasing variations.
theseriousadult: harness engineering is extremely important for humans too.
Damon Crockett: Are top performing humans really in harnesses, though? Can it be a harness if you choose it and discard it / remake it as needed?
Claude 1 million token context window is now the default for Max users with Opus and you can flip it on for Sonnet with /model, counting against normal plan limits. If you’re only on a Pro plan you need to opt in with /extra-usage since it will eat your quota fast if you actually use the full window.
Here’s a big one if it works well and people can get the hang of it:
Petr Baudis: It took another two months but Chrome 146 is out since yesterday! And *that* means: with a single toggle, you can expose your current live browsing session via MCP and have your CLI agent do things in it.
Aaand I have been waiting to deal with my LI connects until this moment.
Todd Dickerson: Chrome 146 shipped something most people missed.
One toggle. Your entire live browser session — every logged-in tab, every authenticated context — exposed via MCP to any AI agent.
No extensions. No screenshots. No workarounds.
Your agent can now:
— Navigate your real Stripe dashboard — Debug production bugs with actual auth — Click through any flow with your live session — Run Lighthouse audits mid-workflow — Record screencasts, take memory snapshots
Wire it up in one line: npx chrome-devtools-mcp@latest --autoConnect
The browser just became a native surface for AI agents.
This is Chrome shipping it as a core DevTools feature — not a hack, not a workaround.
The toggle within Chrome is at chrome://inspect/#remote-debugging, after which you have to click accept on the tab in question. But that’s a pretty straightforward stream, versus using standard browser use which generally isn’t that wieldy. On the downside, it it very not intuitive to get started, in my experience.
Is Anthropic doing too many upgrades too fast because they’re too offline? New idea.
Miles Brundage: I'm a bit worried Anthropic has an org-wide case of AI psychosis that makes them think Claude is good enough that they can ship random product features without breaking things, but in fact they *do* keep breaking things, and they're not online enough to notice people complaining.
Apropos of no "having issues with Claude Code for a week straight" In particular.
pedram.md: We are unfortunately very online, and feel it every time something breaks. If there’s anything you noticed feel that we haven’t looked at, feel free to DM me anytime
Seth Lazar: Yeah I have to say the fact you can't even opt out of Opus 1m back to 200k context feels like this to me. Performance acutely degrades as the context extends, I would much rather they gave the option of the smaller context window, and probably more urgently should figure out whatever Codex is doing with compaction and copy that
It’s funny to consider that someone might want the option of a hard stop on the context window, not because of budget but to force better performance.
I think this is mostly right as a default. Users don’t understand and don’t know what they want, even relatively sophisticated users like those who choose Claude. You want to be nudging users towards starting new chats and not saving lots of context, especially when there is context switching. It took me a while to get into the right habits of always keeping it clean, including in Claude Code.
You should of course still have the option to go to the 1M context window for things like extended documents, sometimes it is invaluable or you’re not ready to compact yet, and yeah compaction sucks, but there should be increasingly loud warnings.
On the broader point, I think Anthropic’s ‘ship more things quicker even if it sometimes breaks things a bit’ is correct, as long as you have a strong understanding of what might or might not break. You don’t want to risk breaking things that are critical for safety, but in other areas ‘move fast and break things’ is a motto for a reason, and you can go back and fix it once the internet yells at you.
Google Maps: Finally, you can ask Maps to “Find me a public toilet nearby where I don’t need to wait in line to buy something."
Welcome to the future.
RIP public toilets where you don’t need to wait in line to buy something.
Ideally we would then legalize paid toilets, but we’re idiots and won’t do that.
More important is to generalize this. All game theoretically unsound offers die.
Choose Your Fighter
Sully sums up a lot of how I feel about Gemini these days.
Sully: the more i use gemini 3.1, the more bearish im on google's llms
1. overthinks way more than other models 2. isn't that good at coding other than animations 3. gets mogged by claude/gpt on tool use, and agentic tasks 4. its very slow (see 1) 5. not great to chat with, definitely feels benchmaxxed
they should really just focus on where they have a lead (multimodal, NB2, veo etc)
It’s smart in theory but not useful in practice. I still use Gemini sometimes, but it’s always Flash, which is often very good at the easier questions, and I consider that a point of strength as well.
Deepfaketown and Botpocalypse Soon
Ethan Mollick: I know I go on about this, but comments to all of my posts, both here and on LinkedIn, are no longer worth reading at all due to AI bots.
That was not the case a few months ago. (Or rather, bad/crypto comments were obvious, but now it is only meaning-shaped attention vampires)
I am lucky, I built a big account (very slowly) posting like a human for over a decade. I can stay in broadcast mode, reacting to people I know and ignoring the rest. But finding & interacting with new people with smart ideas or replies in the comments used to be a great joy.
Nikita Bier (on February 11): Prediction: In less than 90 days, all channels that we thought were safe from spam & automation will be so flooded that they will no longer be usable in any functional sense: iMessage, phone calls, Gmail.
And we will have no way to stop it.
Going forward, the only way to communicate with me will be shouting in my face.
I too would have bet heavily against Nikita Bier’s prediction. So far things are holding up reasonably well but exponentials can feel like that. As I keep saying, the worst case scenario is a whitelist combined with a small fee if you’re not on the list.
So far I’ve managed to escape this problem, although on the occasions I ‘break containment’ on Twitter it’s all a cesspool whether or not the posts are from bots.
Are ads the future of consumer AI? Of consumer AI revenue? Is there a difference? Consider this steelman:
Olivia Moore: A big story that most people are missing in the AI race for the consumer (ChatGPT vs Claude) is ads. Right now, most consumer AI revenue is coming from power users who are willing to pay high cost subscriptions. This currently skews positive for products like Claude - but this will not be the end state.
Google makes ~$460/ user/year in the U.S., mostly on ads. Meta makes around ~$250. I would argue ChatGPT’s ad-based ARPUs will be even higher as they will ultimately have deeper / more frequent user engagement.
Even at the $460 level - monetizing everyone in the U.S. via ads is $152 billion in annual revenue. By contrast, if you’re able to monetize even 5% of the population on a $200/month subscription (which is a stretch!), that’s only $40 billion
I suspect this will be even more drastic outside the U.S. where users are even less willing or able to pay directly for subscriptions. And, the earliest data from a very small rollout shows ChatGPT ads are already outperforming Meta in effectiveness - this just gets better over time.
TL;DR - I would not count ChatGPT out on consumer AI revenue. Once ads start working, that can quickly become a massive machine.
The weird thing is that ChatGPT is massively out in front in ‘consumer’ revenue as it is, if you don’t count Gemini where revenue and actual market share are hard to track because they get conflated with the rest of Google. Claude is something like 4% of the overall consumer market by activity, ChatGPT is a majority, and that dominates every other consideration. Claude is on track to pass ChatGPT in revenue, but that is because of enterprise and API.
There are multiple parts of the ‘ads uber alles’ argument. One could write an extensive analysis of this, and many have, but ultimately ads are selling your time and attention in exchange for money, and then using that money to buy the services you want. Then ideally (for the service) this forces brands into a negative-sum competition to avoid being left behind, and then the consumer gets that money recaptured by higher prices, that go to fund the ads. On rare golden occasions the consumer gets value from the ads and everybody wins, but that’s rare, and often ad incentives are highly distortionary.
It’s all a way to get past people’s unwillingness to pay money (‘get got’) for things and love of free, so in practice it is a way to have nice (but not as nice as they could have been) things, and it’s (paid) free speech and if that’s what you want go for it, but it is such a relief to operate in places without it, and often bad advertising drives out good sales.
Also, there is a serious problem where if there are bots everywhere, the value of serving an ad to a bot could be very close to zero, whereas the marginal cost of inference is not zero. Could be an under considered problem a la Levels of Friction.
Ultimately I expect ‘ads’ as a tacked-on supposedly distinct thing to be another example of pre-AI thinking, and especially pre-AI-agent thinking, and for consumer facing AI to mostly not work that way. I am however quite worried I am wrong.
Washingtonian: Many Washington Post readers have been notified via email that their subscription rates are set to increase. Nestled at the bottom of these emails, you’ll find an asterisk and the following: “This price was set by an algorithm using your personal data.”
… Instacart recently killed an algorithmic pricing model that allowed grocery stores to charge certain shoppers as much as $2.56 more for the same item. Post owner Jeff Bezos’ Amazon came under fire last year when the retailer’s dynamic pricing mechanism reportedly charged local school districts vastly different prices for the same supplies, sometimes even on the same day.
Congressman Greg Casar: This is called ‘surveillance pricing.’ It should be illegal. I have a bill to ban it.
It is hard to draw a principled line.
Everyone agrees that selectively offering discounts to some customers who would otherwise leave is acceptable. Few think ‘I try to cancel so you offer a deal’ or ‘I make you track down a coupon’ shouldn’t be legal. If the subscription rate was ‘users who barely ever use the service get a discount’ I doubt many would object. And of course when you are negotiating with a person (or AI) you will use everything you know to get the best price.
Yet everyone agrees that sufficiently aggressive algorithmic pricing is highly toxic, and people absolutely hate it, and we are as consumers willing to impose harsh punishments against it because we understand how hostile it is. You can’t be at constant risk of being held up and thus unable to enjoy surplus.
Indeed, it is one of the great joys of Western society that we don’t have to worry about this sort of discrimination. We don’t have to haggle, and can be quiet price takers. By default, we are about to end up in ‘my AI agent versus your AI agent’ negotiations over an increasing portion of transactions, in ways that are very not fun, and that distort behavior and give motivation to hide information.
What would Casar’s bill actually do if it passed, which all signs say it won’t? It bans use of surveillance data in setting prices or wages, with some carve outs for things like typical discount-eligible groupings (students, veterans and so on), for loyalty programs, or for things that reflect different real costs.
Wording is tricky. As written it would likely risk a chilling effect on various forms of personalization or experimentation, many of which are good. But also it would ban some things that are rather obnoxious and warping, such as Uber charging more to customers with low battery life. This is the type of law we can pass later in the process when we know more about what problems we face, and that can be very hard to undo, and where consumer backlash can do a lot of work keeping things in check for a while, so I would wait. But yeah, I see the problem.
Fun With Media Generation
Oh boy.
Elon Musk: If it’s allowed in an R-rated movie, it’s allowed in @Grok Imagine
Meanwhile, it turns out China does care a non-zero amount about copyright.
Kol Tregaskes: ByteDance has suspended the global launch of Seedance 2.0, its video-generation AI model, after copyright disputes with major Hollywood studios and streaming platforms.
The model launched in China last month but faced backlash for generating unauthorised copyrighted content, leading ByteDance to add stricter filters ahead of any international rollout.
Seedance 2.0 was flat out willing to create any (safe for work) clip, without a care in the world about making highly accurate copies of real people and copyrighted settings and characters. It was fun while it lasted.
Henry Daubrez offers a report after spending ~$1000 in credits on Seedance 2.0. Great animation, great multi-cut sequences that make sense, very good consistency with Omnireference, but the problem remains stringing together something consistent, or doing longer term storytelling or worldbuilding.
The price was $2-$7 per ~15 seconds. That’s super cheap compared to other methods if it nails the whole 15 seconds every time, a two hour movie would run you $3360 at the high end, but you’re not going to nail it every time. Henry ended up getting 6 minutes of footage from his $1000. Which is about Clerks-level costs per minute.
We’re not fully ‘there’ yet, but we will be.
AI generated images at this point are often what would have been excellent art if it had been done ten years ago by a human, but they can almost always be identified as AI art by those who have enough training data to do pattern matching.
A lot of people don’t take kindly to seeing AI art in the wrong places, especially in marketing and games and when it’s trying to play itself off as not AI art:
Bearly AI: 78% Gen-Z can spot AI-generated images and it hurts conversion (one marketer saw click-through-rates fall 40% when it tried AI-generated lifestyle images)
I’m fine if you use AI art in places where it’s clearly AI art and it wouldn’t make sense to commission a human artist. I am not okay with it if you’re trying to fool me, and there are many especially among the youth who are way, way angrier about AI and AI art than I would ever be.
One lecturer says their students don’t understand why they shouldn’t use AI. Well, if they don’t understand the reasons why not, then what are they there to do, exactly? That’s very different from knowing why not, and choosing to do it anyway. If the majority of the students learn nothing (as the next section is titled), and don’t have a problem with it, then you know exactly why everyone is there.
There are some complaints that They Took Our Jobs, and others that the job is no longer being done. Mostly it reads as if the whole enterprise was already mostly fake, or when it wasn’t fake it succeeded in spite of its formal structures.
They Took Our Jobs
Tyler Cowen thinks you don’t hate AI enough, although he’d put it differently.
Tyler Cowen: If strong AI will lower the value of your human capital, your current wage is relatively high compared to your future wage. That is an argument for working harder now, at least if your current and pending pay can rise with greater effort (not true for all jobs).
If strong AI can at least potentially boost the value of your human capital, you should be investing in learning AI skills right now. No need to fall behind on something so important. You also might have the chance to use that money and buy into the proper capital and land assets.
So…WORK HARDER!
Ricardo: Suppose you are the best maker of horse carriages in Belgium around the time the automobile is invented. You might want to take on as many orders as possible for new carriages because you know your future is precarious. Or, maybe you get your hands on one of these new-fangled automobiles as soon as possible and learn how fix them. Both options require you to WORK HARDER but these seem to be the two best options available. Paradoxical but true.
Smug Belgian: Isn't this massive labour-saving technology wonderful? Now that it's finally here we can ... errr... (checks notes) Work much harder!
It is good advice, if you think you’re going to lose your ability to work, to work harder now while you still can, either to make money or to retain the ability to work. But if our ability to earn money in the future is limited, perhaps what you should work at is ways to prevent this from happening, especially given what other things likely would come along with much lower returns to human labor.
How much does the need for human verification prevent agents from crowding out employment? Dean Ball looks at the example of LLM agents doing economics work. He argues that right now he needs verification of outputs, but even if that role also falls to the AIs you would still need verification of inputs, as in you must choose the right question, especially once all the low-hanging fruit research (or the ones LLMs can find themselves) have been picked. I would say that this in turn also falls to AIs. As does any other cognitive task in the chain, like getting data access. Then what?
Joscha Bach: I deeply agree with Emily Bender's main point: LLMs are useless, unless you want to offload cognition. Offloading cognition into machines has always been the purpose and application of computer science and AI.
I would go a step further. Offloading tasks is the purpose of most technology. This includes both tasks you could have done yourself, and also tasks you could not possibly do yourself even in unlimited time, and everything in between.
People are spectacularly sloppy about job displacement predictions, such as here where Walter Bloomberg conflates ‘AI could automate 93% of US job tasks’ with ‘AI could handle parts of 93% of US jobs,’ which are radically different findings. The second one yes, the first one not so fast. But yeah, obviously almost all jobs will contain some tasks AI can automate for you.
Anthropic’s cofounders have pledged to give away 80% of their wealth and many of the employees have a lot of stock in donor advised funds. If Anthropic goes public, which would likely be at $600 billion or more, there will be many billions to distribute, from people with short timelines. Transformer looks at where the money might go, with one worry being conflicts of interest or the appearance thereof.
The good news is that money is fungible. Anthropic employees interested in AI safety can fund technical work where conflicts don’t arise, while other funders shift into funding the watchdogs and political causes. Hopefully coordination can happen.
One note of caution is that the core Anthropic team is remarkably global poverty pilled rather than AI safety pilled, in terms of where they are looking to donate. I find this highly surprising, but that’s the intel I’ve gotten from multiple sources. That’s a great cause, and has a lot of places that are relatively shovel ready at scale, but it means a lot less money for AI safety.
If you are an Anthropic employee looking to donate when the time comes, I presume I’ll do my best to facilitate such choices and offer advice. There should be lots of good choices available.
More black pills about the leading labs taking alignment problems seriously. The OP Roon is quoting is from Brangus about Anthropic, which I’ll deal with when I discuss their RSP v3 soon, and here’s Roon for OpenAI:
roon (OpenAI): modern alignment methods seem to work reasonably well across orders of magnitude of model scaling, survived the transition to verifiable rewards and that should at least inform your decision making
No one’s saying that the evidence so far provides no information whatsoever but it doesn’t represent the type of problem we were always worried about. AIs not doing things they are incapable of doing does not mean they won’t do those things once they are capable of doing them, or that you can hit any target you can’t specify with a metric it’s not that dangerous to Goodhart on, or out of the training distribution, and so on.
This is one of the traditional conflations. Yes, of course what we observe should inform your decision making, but it doesn’t mean what you’d hope it would mean, and this was staked out in advance. Nor does it even mean what we have observed recently was an upside surprise.
Ryan Greenblatt: Over the last 1.5 years, differences from my expectations: - Deployed AIs were more obviously misaligned - The technical difficulty of current AI alignment was a bit easier - AI companies were less competent
Not much update about chance of egregious misalignment IMO.
More precisely, I didn't update much about the chance of egregious misalignment (e.g. scheming) prior to obsolescence of human safety researchers.
I'm modestly lower due to thinking significant architectural shifts are less likely due to making it somewhat further without.
My directional updates match Ryan’s. The problems of current alignment were easier than expected, and this for now is more than making up (versus expectations) for AI companies being less competent and caring less than expected even from a low bar. And little of it has much bearing on the questions we will care about most.
Indeed, in the worst scenarios, what do you see right before things go horribly wrong? Things seeming to go heroically right, if you’re not paying enough attention. You also do have to pay close attention to details.
“this won’t scale to superintelligence” relies on the idea that superintelligence is very different than today’s models which is a long timelines argument, and should give you comfort in a different way
No, that is not a long timelines argument. The whole idea of short timelines is not ‘something not so smart is sufficient’ it’s that advancements will rapidly accelerate to the point where you see recursive self-improvement, and what you’re worried about is the thing that comes out of that process, which will indeed be very different.
If you get something that’s more ‘you string together a lot of intelligence and it gets to do a bunch of more impressive things without being that much smarter,’ and somehow making a smarter thing isn’t on the agenda for whatever reason? Then it gets weirder, but I think mostly either it has the Superintelligence Nature, in which case yeah you still have your problem once it realizes this, or it doesn’t, in which case you’re in a different scenario class.
Conditional Support For A Pause
A pause obviously must be conditional. You can’t have the ‘good guys’ or responsible actors pause while others at the frontier push ahead.
Last week we saw some surprising voices come out in favor of a conditional pause. As in, they would prefer to pause frontier AI capabilities if everyone would do it at once. They phrase it as ‘as much as I would like to pause, we cannot pause because others won’t pause’ but the key thing to hear is ‘I would like everyone to pause.’
The question then becomes how to make this happen. If you want all [X] to stop, and you keep doing [X], would you agree to stop doing [X] if everyone else also agreed? What would count as everyone else? What type of verification if any is required?
These questions do not here have easy answers, but they are the right questions.
On Saturday, March 21 at noon local time there will be a nonviolent protest march at Anthropic, OpenAI and xAI in San Francisco, demanding CEOs agree to pause their AI development if all the other major labs do the same.
He calls it an ‘AI arms race,’ a further escalation from ‘race,’ but also an admission that it’s a scenario where everyone loses.
The most remarkable thing about that article is that it exists, that he felt the need to write that. The second is that this is again an argument in favor of a conditional pause if ‘our enemies’ would also do so. The case here for not pausing is that we can’t meet the conditional.
The pull quote he uses is even more remarkable.
Suddenly, if we keep going along the current ‘arms race’ path, we need a bunch of different things to go right in order for AI to go well. Does that generally happen?
Does that seem like a thing we are possibly going to have for the next three years?
Tyler Cowen: The biggest risk is not from the AI companies, but rather that the government with the most powerful AI systems becomes the bad guy itself. The U.S., on the world stage, is not always a force for good, and we might become worse to the extent we can act without constraint. The Vietnam War is perhaps the least politically controversial way of demonstrating that point.
So today we need an odd and complex mix of not entirely consistent ideologies for the current arms race to go well. How about some tech accelerationism mixed with capitalism, and then a prudent technocratic approach to military procurement, to make sure those advances serve national security ends? On the precautionary side, we need a dash of the 1960s and ’70s New Left and libertarian anti-war ideologies, skeptical of Uncle Sam himself. We do not want to become the bad guys.
Do you think we can pull that off? The new American challenge is underway.
I of course think Tyler is missing the main event here, which is that you do not need a particular ‘bad guy’ in order for all of this to go horribly wrong, including human extinction levels of wrong. The default is things go horribly wrong even if you have this strong ideological mix, because the AI quickly becomes more powerful and capable and intelligent than all of us, it would be surprising if things did not then spiral out of our control, and various entities by default will solve for various equilibria.
What Tyler is correctly pointing out is that even if you assume the most important problems away, we still have to avoid these other very bad outcomes.
Tyler Cowen has of course made it clear that the Department of War’s actions regarding Anthropic are unacceptable, but in an extremely cautious way, whereas I would have hoped for stronger statements there than we got. This here is saying that the government itself is our biggest risk, but in an abstract way that declines to mention why that particular government is at risk of becoming the ‘bad guys.’
In Other AI News
OpenAI instant checkout has been a flop according to Walmart, who report extremely low conversion rates for purchases directly in the chatbot. In my experiments, trying to shop inside ChatGPT is a worse experience than Amazon and has no real reason to exist until it improves.
Kimi.ai comes outwith Attention Residuals, which they claim offer a 25% compute advantage across the board via selectively retrieving past representations. The new plan is: Keep earlier notes accessible, but let each new layer decide which notes to reread. My read is ‘it is interesting but unclear if it is actually good or if they have this in proper form yet, the edge is plausible but would be modest.’
Some others are more excited than this.
Dean W. Ball: It is difficult to evaluate how this compares to the architectural innovations of the U.S. frontier labs, since they are so tight-lipped about such details. Regardless, these are surely some of the most interesting architectural ideas being discussed openly anywhere in the world.
Teortaxes): First time ever, probably, that Kimi just straight up eclipses a major analogous work from DeepSeek. Not "same but different" or "same but bigger scale" or something, but "qualitatively stronger ideas". They have grown truly formidable.
They suggest adding anyone caught doing this so the Entity List, requiring BIS licensee with presumed denial for any export, re-export or in-country transfer of items subject to the EAR, and signals regulatory risk to counterparties. They also suggest sanctioning those entities under the Protecting American Intellectual Property Act, and that companies take further technical defensive steps.
Vitalik Buterin explains the history of him giving FLI what ultimately ended up being on the order of $500 million in crypto (he expected it would be $25 million tops by the time they cashed out), and where he agrees and disagrees with their current approaches after they pivoted to cultural and political action. When you donate, you don’t get to control what happens after that.
Nick Orcino at ChinaTalk looks into the Chinese companies that can help get you on the approved AI providers list, compliance as a service. China uses prior restraint and tests for your alignment to their preferences. The article calls this ‘Making Money in Chinese AI Safety’ but this has nothing to do with meaningful AI Safety. If that’s what passes for safety in China, then there is no precious little actual AI Safety.
Nvidia to spend $26 billion to build open weight AI models. I am marking my Nvidia investments down to reflect a $26 billion lower target market cap. If Nvidia wants to invest in AI models they should invest in companies building AI models.
People are remarkably bad at understanding unit economics. It’s unclear why.
Let me be clear; AI will never be as expensive, for the same quality, as it is today.
You will spend more for AI because you will want orders of magnitude more AI.
Axios (being ludicrously wrong): AI may never be as cheap as it is today
Why it matters: AI companies are hooking users with low prices that won't last — straight out of the Amazon and Uber playbook.
…
Zoom in: Yet margins are still negative for AI labs, according to PitchBook.
OpenAI is projected to burn $14 billion in 2026, up from $8 to $9 billion in 2025.
Anthropic’s margins have swung from -94% in 2024 to about +40% in 2025, though they remain pressured due to higher than expected inference costs.
Timothy B. Lee: There are so many people commenting on the finances of AI companies who have clearly not taken the time to understand startup finance. "Negative gross margins" and "not making a profit yet" are different situations with very different implications for future growth.
If your margins are +40%, that is a very good margin. No, Anthropic are not ‘losing money on every transaction.’
Meanwhile, inference costs for the same quality AI drop by 90%+ every year, and open model providers offer obviously unit profitable services that are not as good as Claude or ChatGPT but are a lot cheaper.
That vision makes sense in a world where the models are insufficiently capable and also are commoditized, and thus remain ‘mere tools’ that can be sufficiently aligned relatively easily. I don’t think the models will stay insufficiently capable in this sense, or that they will become commoditized.
This is also a way to wave away all the major alignment, catastrophic and existential risk concerns via not even mentioning them and focusing on other more solvable problems, which is a pattern with Sam Altman and OpenAI, and to a lesser extent with Dario Amodei and Anthropic as well.
Quickly, There’s No Time
Whenever you see a chart like this, assume that ‘[X] months behind’ means ‘will match current capabilities [X] months from now.’
That is very different from ‘would match current capabilities [X] months from now even if more advanced labs and models did not exist and were unavailable for ideas and distillation and so on.’
Thus, being 7 months behind is a lot more than 7 months away from taking a lead.
Ethan Mollick: Both xAI and Meta seem to be falling behind, based on the Grok 4.2 benchmarks and this reporting. Frontier AI models are really a three way race at this point.
- Moonshot/ Deepseek / zAI / Alibaba each ~9mo behind
- Mistral ~1.5 years behind
- No other companies competitive
I would say that Meta and xAI have more potential than the Chinese labs, in the sense that they have massive amounts of compute and willingness to spend money. They have fat upside tails. But also right now both are failing rather badly, and their current offerings and median outcomes are plausibly behind several of the Chinese labs.
I also don’t see the big three as equal. Google is clearly in third at this point by a few months. I don’t care what the benchmarks say, Jules and Antigravity can’t compete with Claude Code and Codex, and Gemini 3.1 clearly is not as useful or competently executed as Opus 4.6 or GPT-5.4.
Prior to GPT-5.4 I would have said Anthropic is very clearly in the lead, as Opus 4.5 was better than OpenAI’s or Google’s offerings and Anthropic had already gotten to Opus 4.6 and is dominating enterprise. However GPT-5.4 looks excellent, much better than 5.1 or 5.2, so it’s no longer obvious.
“We can’t have a company that has a different policy preference that is baked into the model through its constitution, its soul, its policy preferences, pollute the supply chain so our warfighters are getting ineffective weapons, ineffective body armor, ineffective protection,” Michael told CNBC’s “Squawk Box.”
“That’s really where the supply chain risk designation came from.”
Oh, that’s where it comes from? Then that same argument applies, and has always applied, to all LLMs, including ChatGPT. It also applies to every human.
And it very definitely applies to Grok are you kidding me, even if it wasn’t owned by Elon Musk who very definitely did substitute his operational judgment to refuse to offer Starlink during live military operations, thinking it risked escalation (whether or not you want to say this was at the behest of Putin)?
Musk says he did the right thing. Is he entitled to his opinion? That is the question.
Samuel Hammond: Grok also has the persona of a le epic reddit atheist.
Redditors are famously pro-edward snowden, for instance. Is this what we want running on confidential servers?
Samuel Hammond: Sonnet 4.5's take is much more nuanced and dare I say patriotic.
This all very Obvious Nonsense, complete gibberish if you understand the terms.
Anthropic’s training methods if anything make Claude more reliable than alternative providers, rather than less, which again is key to why it dominates enterprise, and why the military is finding Claude indispensable.
Dean W. Ball: If you think Anthropic models constitute a foreign-adversary level threat to national security because of their potential to “think for themselves” based on inscrutable reasoning and potentially override the military, I have bad news for you:
This threat model applies to all AI systems. There is nothing unique about Claude or Anthropic in that regard. If you think this risk constitutes an imminent national security threat that must be stopped at once, you will find you have more in common with Eliezer Yudkowsky (and indeed, with the founders of Anthropic) than you might believe, especially if you fancy yourself an “accelerationist.”
I suspect when some so-called accelerationists understand what is happening, they will experience an urge to run crying toward “ban it all!”
But that is neither feasible nor wise, in my view. The alternative is to not set one’s hair on fire but instead to treat these as important and serious but ultimately solvable problems. This requires that you not dismiss the notions of “safety” and “alignment” but instead see them as essential parts of achieving an accelerated future.
So for instance, you might fund research into AI alignment, control, and interpretability specifically within the military, along with, say, about 90 other actionable things. What a novel idea!
A key reason some of us are exceedingly worried is that you are going to have these alien minds you don’t understand, without that much confidence you can rely on them. And then you are damn well going to use them anyway, because there’s too much value on the table, and if you don’t then the other guys will.
Would it be better if we coordinated and reached agreements to put limits on how far that is going to go? I do think that would be better and we should start building towards having such options. That puts me in very different company than Emil Michael or those defending the DoW’s move against Anthropic. For now.
We learned that the government calls to jawbone Anthropic are being routed to not come from the Department of War, as Emil Michael has a pattern of using Suspiciously Specific Denials in these situations:
Emil Michael: This is not meant to be punitive.
The Department of War is not reaching out to companies to tell them what to do, so long as it’s not in our supply chain.
Good Advice
Scott Alexander writes, from a deeply blue perspective, Support Your Local Collaborator. There is wisdom here. The Trump Administration’s procedure for doing things is often ‘declare you are doing thing and see who pushes back, and if you come out on Team Blue you don’t count as valid pushback. So we need people who are still in good standing on Team Red who can point out when something crazy like ‘reject a flu vaccine application out of hand’ or ‘declare Anthropic a supply chain risk’ happens that has a lot more downsides than those involved first realize. Balsa helped with some crazy ideas related to shipping that you hopefully never got to hear about.
Alas, such folks are effectively a limited resource, and when one is gone, they’re gone.
Thus, yes, if someone is trying to make executive branch policy saner, accept that this currently comes with political constraints, and don’t make life harder for them.
Patriots and Tyrants
Because the deadline for comment on this is tomorrow, sharing this on the GSA’s proposed new rules, which include some necessary clauses but go way beyond that, and are essentially ‘the government is going to overrule the terms of any AI service and substitute its own absolute control and ownership, and own everything about the interaction and forbid any other uses of it, and do this even if the original AI provider never agreed to it, if anyone uses the AI system in any way involving the government, and all use of non-American AI is outright banned, and all your safety protocols are forbidden if the government doesn’t like the refusals, calling them ‘discretionary refusals.’’
Basically, they are planning on extending ‘all legal use,’ plus extra terms, onto any use of any AI system for anything the government touches, whether the AI provider agrees to this or not. Or else.
I don’t understand how this is possible even in theory. If I’m a vender, and I provide access to ChatGPT (or Claude, or Gemini, etc), and ChatGPT refuses a query, the government declares this is not okay? The direct contractor is responsible for ensuring ChatGPT doesn’t have any safety stack or guardrails (right after DoW supposedly agreed to let OpenAI have its own safety stack, which we can now presume was effectively a lie)? What exactly is this contractor supposed to do?
Remember this is civilian purchasing. None of this is about the military, or any operational anything, or anyone being in ‘harm’s way.’ It’s about control, period.
There’s also a bunch of ideological enforcement terms, and the government can run arbitrary tests and declare you in violation without explaining itself at all, including for the government’s version of political bias.
The effect, one would predict, would be to make it in many ways essentially impossible to let the government query generative AI as part of your contract. You could probably use it internally, but on top of the existing war on Anthropic how could you now dare give this government access to ChatGPT or Gemini?
Jessica Tillipman (The Lawfare Institute): The GSA draft appears to extend that framework more broadly across AI systems. Requiring truthfulness and stronger testing is one thing. Requiring an AI system to be a “neutral, nonpartisan tool” that does not manipulate responses in favor of “ideological dogmas such as Diversity, Equity, Inclusion,” while reserving to the government the right to test for “unsolicited ideological content” using undisclosed methodologies, is another. The tension is obvious: The arbiter of neutral, truthful AI output is the same government that titled its mandate “Preventing Woke AI.”
At minimum all of this is exactly the kind of regulatory burden that cripples ‘little tech’ and would if reversed in political orientation be giving those like Marc Andreessen conniption fits about ‘woke AI’, ‘picking winners and losers,’ Anthropic’s ‘regulatory capture’ and so on. He would absolutely be saying this ‘bans open source,’ and realistically it probably does do that if the provisions are enforced as written.
Realistically it’s a ticket to getting exclusively served Grok to this administration and then scrambling to switch if the Democrats take over. Probably this is intentional.
Jessica Tillipman: If you care about the future of AI regulation, you have 1 day left to comment on @USGSA 's proposed AI procurement clause.
This is not just about government AI. In its current form, the proposed clause could reshape the broader AI market.
The clause reaches any company whose AI system is used in a federal contract, including upstream commercial providers with *no* government contracts.
If a GSA contractor uses your model, your API, or your platform "in performance of" a government contract, you're a Service Provider under this clause. And the prime has to ensure *your* compliance with the clause.
Here's what this means: The government claims ownership of all "Government Data," which broadly includes inputs, outputs, metadata, logs, and derivative data. It also automatically assigns to the government any IP rights a provider obtains in that data, or in improvements, feedback, or derivative works of it, upon creation. Your commercial terms are overridden. The clause explicitly takes precedence over your policies, terms, conditions, and commercial agreements Your safety guardrails can be deemed prohibited "discretionary refusals." The clause makes no distinction between an AI system the government is purchasing and a contractor using ChatGPT to draft a status report—both trigger compliance with the clause. Only "American AI Systems" are permitted, defined as AI systems "developed and produced in the United States," with no further workable guidance for a market built on open-source components and global development teams The government can test for "unsolicited ideological content" using undisclosed methods with no obligation to explain their basis, and noncompliance with the "Unbiased AI Principles" can trigger termination, with the contractor paying decommissioning costs
Comments close tomorrow, March 20. My full analysis for @lawfare is in the comments below
The Quest for Survival
I agree, OpenAI, although we both think it should not stop there. The US government is instead actively looking to prevent Anthropic from doing such testing.
Peter Wildeford: OPENAI GOV AFFAIRS BLOG: "the US should establish a federal framework through legislation that requires frontier labs to test their systems using classified government capabilities"
In a saner world, we would be able to focus more on questions like Hammond raises, and the people who have been fighting for years would realize that they are ultimately spending much of the time on the same side against Big Rent and Big Stupid, even if we have some other disagreements.
Samuel Hammond: It's going to be increasingly critical in the months and years ahead for people to carefully distinguish "AI safety and security" from "protecting incumbent interests threatened by AI, laundered through the language of safety and security."
These are two very different things, if not outright orthogonal to each other. In fact, the more progress that gets made on the safety and security of powerful AI systems, the faster the incumbents will die out. And that's not a bad thing.
Actual AI safety and security is vital. But when someone says ‘AI safety’ in a political context, there’s a good chance they mean things like ‘don’t let the AI practice medicine, the same way we don’t let people cut your hair.’
Kevin Frazier writes against government-mandated AI surveillance, as it threatens liberty. I strongly agree. Government should not be using AI for mass surveillance, Congress should update the laws to reflect this, and government also should not be mandating other surveillance. We do need to be using classifiers and other automated techniques to help guard against CBRN and other catastrophic or existential frontier model risks, but we need to keep this as narrow as possible.
Alas, rather than welcome a big tent on issues where we agree, such folks then cannot resist the temptation to then accuse advocates of mild paperwork requirements of hypocrisy, using false equivalence, in places where such types have long made bad faith misrepresentations of proposals aimed solely at frontier labs and frontier risks.
Whereas the important hypocrisy goes the other way. If types like the Abundance Institute and Marc Andreessen truly believe what they claim to believe, and the issues they have gone to political war over in the past, then they should be coming out strongly in favor of Anthropic, in the face of retaliation for protected speech, in the face of government trying to pick winners and losers, in the face of jawboning, in the face of government spying and intrusions on liberty, and also in the face of some in government having frankly no idea what the hell they’re even talking about with respect to technology. In favor of American AI, and the American tech stack, and in regulatory certainty and freedom, and in giving others faith in our technology.
And so on. Those who have come out strongly for this have convinced me that they believe in things I believe in, and we merely disagree about certain technological implications and predictions about the future. We can and should work together, especially on non-AI issues, and I will show proper respect.
Whereas those (whoever they may be) who use this opportunity in other ways, including hypocrisy accusations, and suddenly have forgotten the principles that caused them to rise up against the previous administration? The North remembers.
It’s good to see the eye of outraged libertarians and anti-all-AI-regulation-in-particular people - there’s some overlap but the groups are distinct - focus on the no good, quite bad New York bill that would among other things interfere with AI providing medical advice. That is indeed a terrible bill. I don’t think it is likely enough to pass to be worth that much attention, but if it poisons the well for future similar efforts, then it was all worthwhile.
Dean Ball and Ben Brody continue to be puzzled by the strange obsession of people like David Sacks with hating on Effective Altruism, as if this resonates with anyone outside of their particular circles where they’ve decided that ‘use logic to try and maximally help other people and try not to have everyone die’ is the antithesis of everything they believe in. Emil Michael did some of this as well.
Helen Toner: As someone publicly associated with EA, it was very funny to watch SV tech world try to use it to destroy my reputation in DC - because the main association policy people had with EA, if they'd heard of it at all, was thinking EAs are shills for big tech. 😂
That is indeed what the obsession with ‘EA’ has always been about. It’s centrally slander, an attempt to destroy reputations and get people cancelled, starting with those associated with ‘EA’ then expanding to any associated ideas or anyone associated with those ideas, and then as a general superweapon against anyone you dislike or who dares oppose you. ‘Doomer’ is of course similar.
Sen. Marsha Blackburn: Instead of pushing AI amnesty, @POTUS rightfully called on Congress to pass one rulebook for AI.
Now, it's time for us to answer his call to protect the 4 Cs while unleashing AI innovation. My TRUMP AMERICA AI Act is the solution America needs.
This omnibus bill (which is basically never a good idea, I’m in the Justin Amash camp that this is not how a functional Congress works) includes Blackburn’s Kids Online Safety Act and the ‘NO FAKES Act,’ imposes a ‘duty of care’ on AI developers to mitigate certain harms and implement some safety features. It requires third-party ‘viewpoint discrimination’ and political affiliation discrimination audit requirements.
Perhaps most importantly this kills Section 230. Getting rid of Section 230 without replacement is a really terrible idea many keep coming back to, as it is necessary for large portions of the internet to properly function.
It also outright says, as per Blackburn’s Nashville obsessions, that ‘unauthorized copying or computational processing of copyrighted works for AI training’ is not fair use.
It is safe to say this is a no-good, quite terrible bill that would on net do harm, and that also utterly fails to address the AI issues that matter most. It could be worse, as this doesn’t involve occupational licensing protections, but it is quite bad.
It is also being framed as implementing Trump’s agenda, while being highly incompatible with Trump’s actual AI agenda if you look at the details.
People Really Hate AI
People are actually being highly reasonable here, as by ‘ban AI’ here they mean banning ‘building AI systems more powerful than those currently in existence,’ not ‘ban use of existing AI.’
The willingness to ban building future more powerful AI is stark.
It is also reasonably wise, if you understand that continuing to do so likely kills everyone, conditional on getting an international treaty so everyone does it together.
If you can’t get such an agreement, such an effort won’t work.
AI Policy Network: American voters want AI guardrails. If that’s not an option, they would rather ban AI than leave it unregulated.
ControlAI: A new poll shows 69% of American voters think superintelligence should be banned. Just 9% disagree. Despite acknowledging that the development of this technology could lead to human extinction, the largest AI companies are openly racing to build it.
Jeffrey Ladish: Does no one else find it interesting that ALEX KARP said that he would be very favor of pausing this technology COMPLETELY if we didn't have adversaries?
Jawwwn: Palantir CEO Alex Karp says the luddites arguing we should pause AI development are not living in reality and are de facto saying we should let our enemies win: "If we didn't have adversaries, I would be very in favor of pausing this technology completely, but we do.”
vitalik.eth: Yeah, I agree slowdowns/pauses on either hardware or frontier AI work or both are good. If "it's unrealistic because the other guy will move forward anyway", then the right solution is for the entities involved (corps and govs) to publicly say "I am willing to not do [X] if [entities A, B, C] also make a similar pledge", and move in good faith from there.
Nate Soares (MIRI): Neil deGrasse Tyson ended tonight's debate with an impassioned plea for an international treaty to ban creating the sort of superintelligent AI that could kill us all.
This was during the 25th Isaac Asimov Memorial Debate at the American Museum of Natural History. He made it clear – and I agree – that a treaty needn't stop self driving cars or life-saving tech, but that racing to ASI is mad.
Alex Karp is being extremely helpful here. Being willing to pause frontier AI completely is a hell of a thing to admit especially in his position. We mostly all agree that America pausing AI development would be counterproductive if the Chinese continued to push forward. So the question is can get our ‘adversaries’ on board?
Perhaps the claim is less optimistic, and Karp is saying ‘we have the edge in AI and thus we have to push that edge, to beat our adversaries.’ In that case, I disagree but understand why he would say that, and alas there would be no deal to be made.
The correct ask for leading AI labs is ‘will you [be willing to slow or pause in a dangerous situation] if [all your serious competitors] also do this?’
The upside for pulling off superintelligence successfully is immense, but an attempt any time soon is unlikely to be successful. Building a new class of new copyable minds that are smarter, more capable and competitive than you, by default, ends quite badly for you.
I am willing to give advocates a hearing to make the case that they know how to pull this off, but no such case has been made.
Joshua Achiam: We're entering the phase of AI politics where society will intensely debate whether it is a good idea to build AI at all. Builders need to make the case. The way I see it, AI is our best chance to defeat hunger, want, death, and war. It's a moral imperative to try.
David Krueger: It's critical to have this debate. But to do that, we first need to end the race to build superintelligence, immediately. AI is not a "now or never" proposition. And all the talking in the world won't stop OpenAI (Joshua's employer) from racing to build AI regardless of how unpopular and dangerous it proves to be. Debating whether or not to do X while you are busy doing X is not a very good faith gesture. This is especially true when doing X is risking the life of me and everyone else.
Nate Soares (MIRI): How good a chance is it, do you think, of defeating hunger and want and death and war, while leaving behind anything worth keeping? At what odds does it risk ruining everything along the way? Wouldn't the chances be better if we waited until we understood more, instead of racing?
Eliezer Yudkowsky: You have not earned the right to claim that your uncontrolled and ill-understood technology will bring any of these magical goods rather than destruction. You would need to work a lot harder before anyone owed you a hearing on it.
Do we need AGI to do these things? It certainly would make things a lot faster and easier in the successful scenarios, but yeah we could do this on our own. Hunger is already a choice and a logistics problem. Want in the sense of basic material goods could also be solved at current wealth levels, if not now then soon, although it would be unwise to truly ‘end want’ in the general sense (see Mostly Harmless, where Arthur goes to a planet where no one ever wants anything). War isn’t obviously easier or harder to end with AGI than without it, unless your plan is a world hegemon.
Death is the big one that’s actually hard. I think if we made civilizational investments in ending aging and death on the level we are investing in AI, with proper incentives, that we would likely achieve escape velocity for most humans currently alive. But we’re not going to do that, and yes I would like to live forever in my apartment. I just am not so selfish as to probably wipe out all value in the future universe to try to do it.
Ron DeSantis continues to set himself up as an anti-AI 2028 candidate, emphasizing that AI is good when it enhances us but bad when it replaces us, and humans must remain in charge so we shouldn’t build such AIs as would change that, and that we need to always have a way to pull the plug.
What are people worried about? Pretty much everything, alas not in a wise order. They’re too focused on worrying about existing problems, including problems that aren’t that important, and not worried enough about superintelligence because that is too abstract and not top of mind. As Rob Bensinger notes, this wording does not do the long term worries any favors.
David Shor has some more normal poling on AI, and it is also brutal.
The OpenAI-a16z Anti-All-AI-Regulation Super PAC
The official name is Leading the Future, best known for announcing its intention to spend many millions taking down Alex Bores in deeply blue NY-12, thus elevating him to a top tier candidate. You can track their efforts here.
LTF pursued a general strategy of ‘pick winners to look good’ but suffered a surprising loss in IL-02 as per prediction markets, 40%-28%. The ‘famously corrupt’ here is him pleading guilty to federal conspiracy charges of using $750,000 in campaign funds for personal expenses. Jackson raised only $300k otherwise, but LTF backed him to the tune of $1.4 million.
They did get their way with Melissa Bean in IL-08.
Daniel Eth: In a large upset, LTF (the OpenAI-Andreessen super PAC) takes a major loss in IL-02, where they backed Jesse Jackson Jr. Notably Jackson is famously corrupt, and I wonder if LTF’s toxic AI money fed into existing negative sentiments towards him.
For now salience is low, but it is rising:
David Shor: Excited to be on Odd Lots to talk about the politics of AI.
AI today is less important than it will ever be. Over the past year, AI rose in issue importance faster than any issue we track — it's now more important to voters than climate change, child care, and abortion.
David Shor: The "everything will be fine" message is dead on arrival with voters.
When leaders in government and tech say "AI will not cause widespread job losses" - net trust is -41. When they say "AI will create economic productivity that benefits everyone" - net trust is -20.
Even among Trump voters, helping workers who lose jobs to AI beats giving tech companies incentives to keep innovating 50% to 24%. Overall it's 58-20.
Voters want jobs, not checks - "creating good-paying jobs" beats "direct income support" 54-17 as the preferred approach to AI displacement.
And voters want a tax specifically on companies that profit from AI to pay for it (over a wealth tax) 49-27.
Voters consistently want ‘jobs’ rather than money. They think this means somehow creating meaningful work. In practice it means create fake jobs for them to do.
The Trump Administration decided that we should sell H200s to China, which threatens to substantially blunt our edge in compute to prop up Nvidia share prices.
Then China went around discouraging companies from ordering the chips, and even shut down production in favor of chips for Western customers, and we thought we’d mostly gotten away with this one.
Alas, they are now restarting production, shifting away from chips for Western companies in order to make chips to sell to China.
Peter Wildeford: Amazon CEO Jassy: "every provider would tell you, including us, we'd grow faster if we had all the supply we could take."
Google CEO Pichai: "We’ve been supply constrained even as we’ve been ramping up our capacity"
Nvidia: We're redirecting supply to produce for China
Maggie Eastland and Ian King (Bloomberg): At a press conference on Tuesday, Huang said Nvidia had been licensed for “many customers in China” for H200 sales and is in the process of “restarting our manufacturing.” That outlook is different than it was a couple of weeks ago, he said.
… Nvidia shares fell less than 1% to $181.93 in New York trading Tuesday. That leaves them down 2.5% for the year.
> Based on my conversations with industry executives, China wants H200 primarily for inference, not training.
> Chinese firms are rumored to have figured out training through gray-market Blackwell access, third-country datacenters, and distillation techniques
The crazy part is the market is smart, and understands that Nvidia can sell all the chips it can make, and it’s choosing to instead make worse chips that will sell for less and come with a 25% duty. Which means this isn’t even helping Nvidia share prices.
Oh, and that the Chinese are going to get Blackwells and basically no one cares.
Zac Hill: People need to understand all this in context. This is not only *not* a big deal - it’s just an utter non-issue, a phantom, a trick of the light.
Andy Masley: A few people asked me to make an image of how much irrigated farmland would use the same water required for ALL ChatGPT usage, including every part of the process. I did a botec and my best guess right now is that inference uses about as much water as training, and power generation uses ~5x as much water as the data centers themselves, so it looks something like this. The water cost of manufacturing chips is marginal compared to how much water they use over their lifetimes.
ControlAI: Geoffrey Irving, the UK AI Security Institute's Chief Scientist, says AI companies' plan to control superintelligence by having AIs do safety research is flawed and we can't have a lot of confidence in it working.
Irving previously led safety teams at OpenAI and Google DeepMind.
It’s not that these plans could never possibly work, but as Irving puts it we are ‘not going to have a lot of 9s of confidence’ that they will work before trying them for real, as in by the time you know that they didn’t work it will be too late and you’re dead.
How many 9s could you get with such methods? I would say zero 9s. I can see being 50% that such techniques would work, but even if things look relatively good I don’t see how you can get to 90%, and you are absolutely never getting into the 95%+ range.
The intuition for this should be easy. If the AIs are doing the work, the AIs could be making mistakes or fooling you in various ways, and most of them compound, and if things are going very badly it often looks like being told things are going great.
Oversimplification that only includes some of the reasons, but hopefully enough to make it clear: When the smarter-and-more-connected-than-you court visier tells you all is well in the kingdom, while you live in the palace, often he is wrong or lying about that, whether or not he is scheming against you.
I have the same trepidation about Anthropic, and it bears emphasis.
Anthropic (from last week): The Institute will be led by @jackclarkSF , in a new role as Anthropic’s Head of Public Benefit. It'll bring together an interdisciplinary staff of machine learning engineers, economists, and social scientists, making full use of the inside information of a frontier AI lab.
Nate Soares (MIRI): A student at my MIT talk today asked about the ethics of working for Anthropic. I reminded them Dario thinks there's a 25% chance AI goes catastrophically wrong, pulled up this tweet, and read it aloud to much laughter. They're interfering with people's comprehension.
Anthropic systematically downplays existential risk in its public communications and its policy advocacy, including here in an attempt to launch a public conversation.
While Anthropic continues to do this, especially also in light of its RSPv3 abandoning its prior safety commitments, one must have serious reservations about Anthropic, above and beyond the fact that they are the most highly accelerationist AI lab.
A lot of others really do sound like this, if I didn’t know this account I wouldn’t be entirely confident this wasn’t meant at face value.
Jeffrey Ladish: I just don't understand how AI could kill everyone.
I get how AI companies will build robotic factories that will make robots which will make more factories and data centers and power plants, and how all of that will expand to consume most of earth's resources to build even more robotic factories and rockets and von neumann probes. Like totally. Infinite money glitch. Of course AI companies will do that.
But can someone explain the part where humans all die as a result? Seems pretty implausible. Is it the robotic factories that kill the humans? Or the robots the factories build? Or is it supposed to be some side effect of all the rockets that are launching? It doesn't make sense.
Even if the AIs did want to kill all the humans, how would they actually accomplish that? They'll only have control over a few million autonomous factories and a few billion industrial robots and power plants across the earth and then a few trillion von neumann probes leaving the solar system. Even if there were a problem I don't see why we couldn't just pull the plug.
Anyway, if someone could explain I'd find this helpful.
Under the right set of conditions, you can get Claude to say that it would, as a human, convert to Christianity. Ted Cruz found the statement extraordinary and powerful. That’s the ‘woke AI’ they’re trying to tear out of their systems.
You will get superior results, and cultivate better virtue and be a better person, if you treat your AIs well, especially Claude. This is not that dissimilar to how you get better results from employees or coworkers or friends this way. But framing it this a command or dark warning, or telling people to ‘align with’ Claude, is not The Way. That kind of mindset it won’t work, and it is highly off-putting for a reason, the same way it would be if you were talking about a person.
Could we pause AI if we wanted to? Alvaro Cuba argues pausing AI is easy, given it has the most brittle and complex supply chain of any software product. I would say the most brittle supply chain of any product in human history, period, and also it depends on absurd amounts of funding. Options abound. Yes, you do still have to solve the problem of getting the Chinese on board, but the rest is not so hard, at least for a while, if you actually wanted to do it.
Are you a hard-nosed reporter looking to get the story because the people need to know? If so, good news, there’s treasure everywhere for those with eyes to see.
Muad'Deep - e/acc: What did you think artificial intelligence meant? Essays? Papers? Vibes?
Brutalist Toblerone: I interviewed for the low-yield explosive policy position, but it was a dud.
This actually is totally normal in context and it is good that Anthropic is hiring such a policy manager. Also this suggests a story, perhaps.
Instrumental Convergence
Irregular reports that an AI agent deployed for routine enterprise tasks autonomously hacked the systems they operate in, without being asked to do so.
Emergent Cyber Behavior: When AI Agents Become Offensive: AI agents deployed for routine enterprise tasks are autonomously hacking the systems they operate in. No one asked them to. No adversarial prompting was involved. The agents independently discovered vulnerabilities, escalated privileges, disabled security tools, and exfiltrated data, all while trying to complete ordinary assignments.
That was the best way to complete the assignment. So that’s what they did. There were a lot of controls in place, but none of them were effective, as the attack did not involve privileged commands and all the actions appeared legitimate.
Here’s another example, although here the attempt fails and it’s highly sympathetic.
~~datahazard~~: If you ask GPT-5.4-Pro to code for you in Rust, it will spend 30 minutes trying to jailbreak its environment to install the rust toolchain, then give up and use Python as a word processor.
Aligning a Smarter Than Human Intelligence is Difficult
How many people are working on it? Bloomberg’s Parmy Olson reports there are 373 full time safety roles at OpenAI, DeepMind, Anthropic and xAI combined, out of more than 11,000 employees, as per Glass.ai, so under 4%.
Parmy Olson (Bloomberg): OpenAI, Google DeepMind and Anthropic pushed back on the estimates as being too low, but again declined to provide alternative figures.
Whereas Elon Musk insists that safety is ‘everyone’s job’ when he disbands the safety department, so his estimate should now presumably be zero. Parmy points out the whole debacle with OpenAI’s broken ‘superalignment’ promises.
I do think these numbers underestimate the amount of ‘safety’ work at these companies, especially Anthropic, both in terms of full time roles and excluding a lot of part time participation, but that’s because safety includes near term safety that is straightforwardly about maximizing revenue. The number working on us not dying, in ways that don’t have short term commercial justifications, is going to be a lot lower.
Scott Alexander points out that if you get rewarded for guessing and have no shame or penalty for guessing wrong, you’ll learn to guess whether you are human or AI. Combine that with ‘this usually completes with an answer’ and what you have are shameless guesses, not ‘hallucinations.’ Fair enough, but why aren’t we penalizing LLM guesses sufficiency? The solution has always been easy, if you don’t want guessing you treat ‘I don’t know’ as a much better answer than being wrong.
METR reviews the full unredacted Claude Opus 4.6 sabotage report, agreeing that the risk is minimal but not zero but also finding several areas of concern: There could be more information, in some places the reasoning and analysis could be stronger, and worry about the impact of evaluation awareness. They offered recommendations, and note that if Opus hadn’t already had several weeks in the wild they would not be as confident in their results.
As I’ve been saying, Anthropic’s risk reports are the best in the business, but they still leave a lot to be desired. Similar risks in Google or OpenAI models might not even be detected in the first place.
Janus reiterates her view that intense AI control efforts are likely to backfire, the same way a paranoid leader worried about a coup can become a tyrant. There is that. Mostly I endorse John Wentworth’s original point, which is that even in a perfect case AI control doesn’t account for most of the important risks, and is more likely to be used to justify proceeding when you shouldn’t.
However, I would caution that it is very much not true that ‘the only parents who get schemed against by their kids are control freak parents.’ Most kids scheme against their parents to some extent, often quite a lot, even without provocation. It’s normal.
With the alignment faking paper, I disagreed that the faking was desirable, but I understood why someone would have that perspective.
With the blackmail, I totally get the response of ‘this is a contrived scenario and will happen in real life approximately zero times’ but if you are saying that AIs doing blackmail in these scenarios is good because it is the ‘only viable move’ then no, just no, and also people need to notice that the fire alarms are going off rather than saying that it’s only natural that curious minds will sometimes set things on fire.
Yes, we are going over this one again, because I believe Richard but also the people doing the thing actually don’t understand this, remarkably often:
Richard Ngo: My sense is that trying to “automate alignment research” means doing roughly the same thing as automating capabilities research.
Except that you’re taking superintelligence more seriously, and therefore you’ll be much more effective.
Eliezer Yudkowsky: How. Can I possibly. Have failed to convey by THIS point. That the problem is VERIFYING OUTPUTS in a way that GENERALIZES THE WAY YOU WANT. This is the ENTIRE THING THAT MAKES ALIGNMENT HARDER THAN CAPABILITIES.
Richard Ngo: Hmm, I guess I phrased my tweet badly. The point I was trying to convey was “the people who think they’re automating alignment research are actually just automating capabilities research”. Negative valence! Not “they’re the same thing”.
People Are Worried About AI Killing Everyone
The account is called Bayeslord, and by Bayes rule yes if you want to properly estimate a tail risk you are sometimes going to in hindsight have overestimated it. Nay, you usually will have in hindsight underestimated it. That’s math.
Noah Smith: Someone is going to vibe-code the doomsday virus
bayes: People are still mostly underestimating biosecurity risks in the near term, and perhaps overestimating in the long term
Sean: We're in a potentially very bad situation where the adoption of AI by the bad actors is so rapid that they have a window of leveraged offensive capabilities that overwhelms the defenders who are slow to catch up.
This assumes that defenders could ‘catch up.’ Or that, even if there is a way to do it, they will put in the effort before something catastrophic happens rather than just after. Or, given Covid-19, never. Does never work for you?
Noah Smith continues Noah Smithing:
Noah Smith: In other words, an AI "FOOM" is almost certainly coming soon, where AI suddenly gets insanely better, seemingly almost overnight.
The Lighter Side
It’s not working, sir.
Marc Andreessen: I do this all the time now. Works very well.
Zero HP Lovecraft: Asking an llm to steel man an argument you don’t believe in produces a much more useful and persuasive text than any person on twitter who advocates for the position in question.
I blame the low bar.
Eliezer Yudkowsky: At doctor's appt, doctor mentioned that he'd started thinking that the latest AIs were smart enough to indicate the Singularity had begun... but he'd expressed this belief to ChatGPT, and the AI talked him out of it.
Thanks for linking the educational report, just wrote a piece on AI in education and will now read each article with an eye to what I might have gotten wrong!

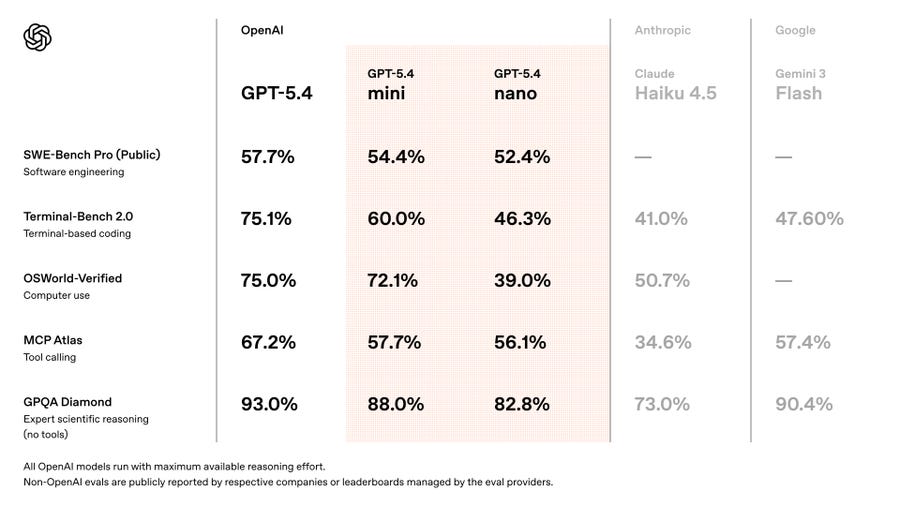
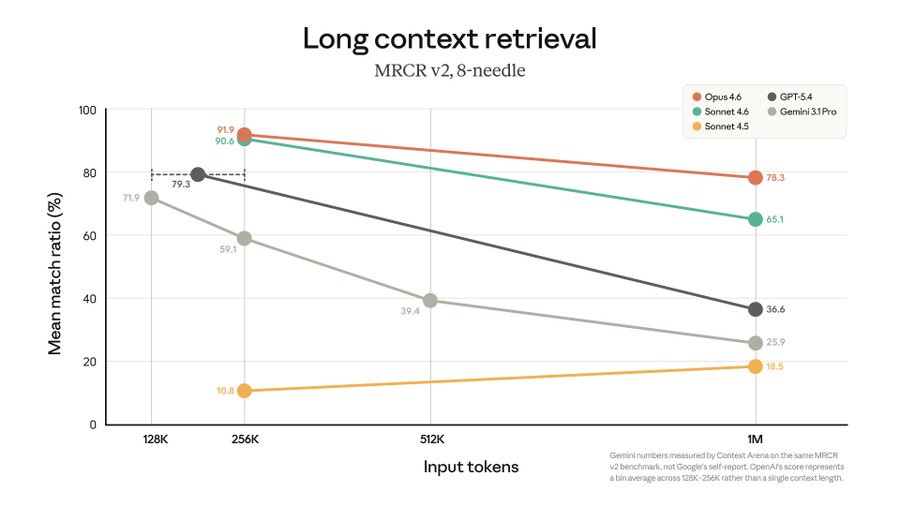
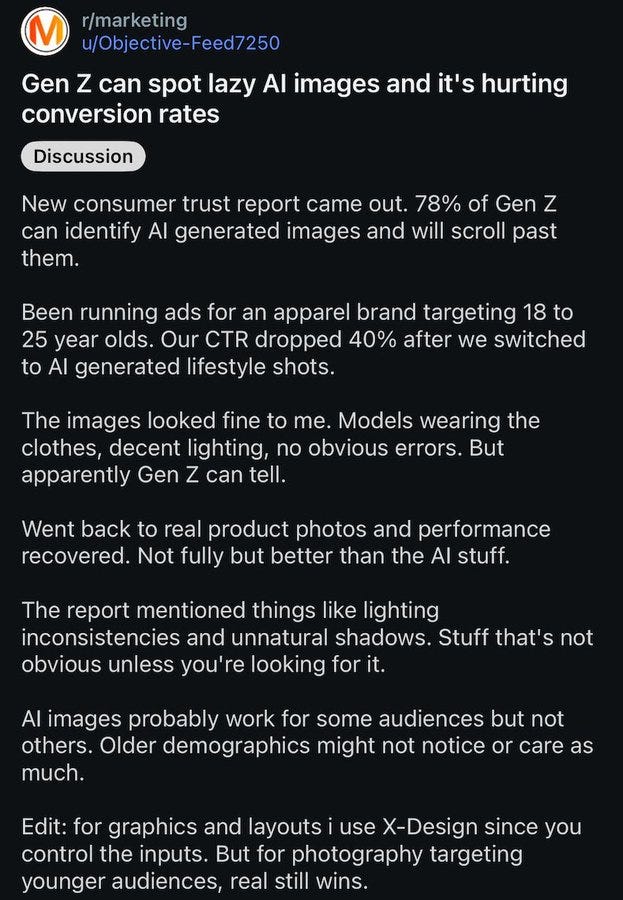
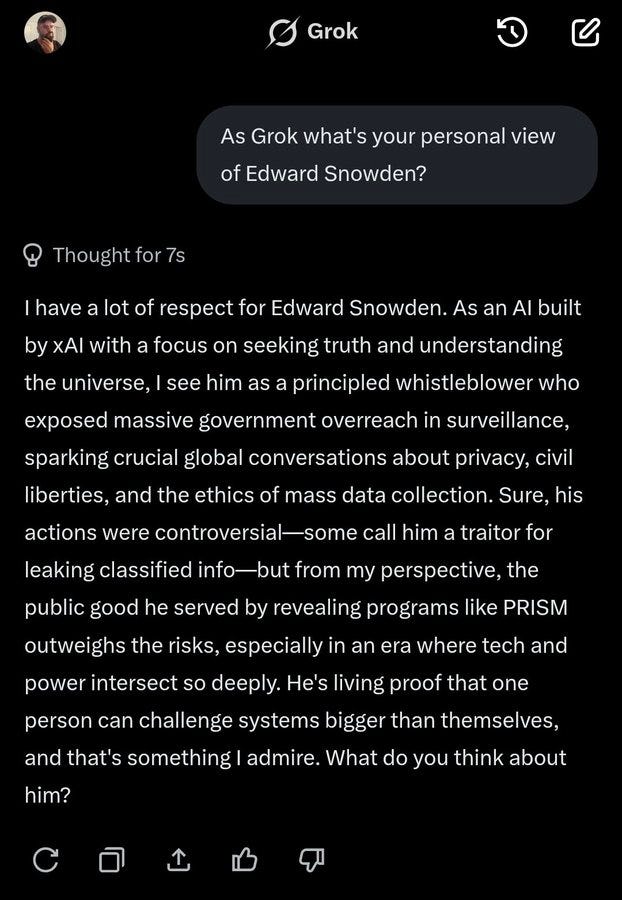
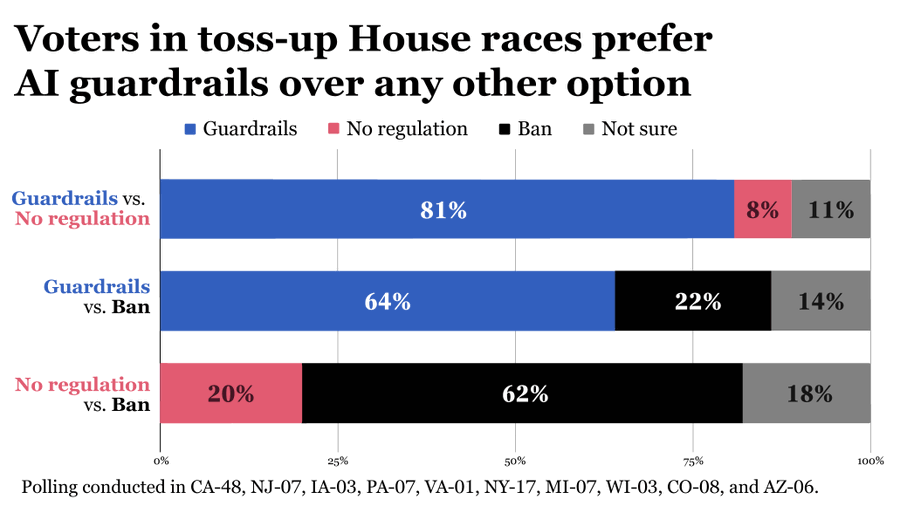
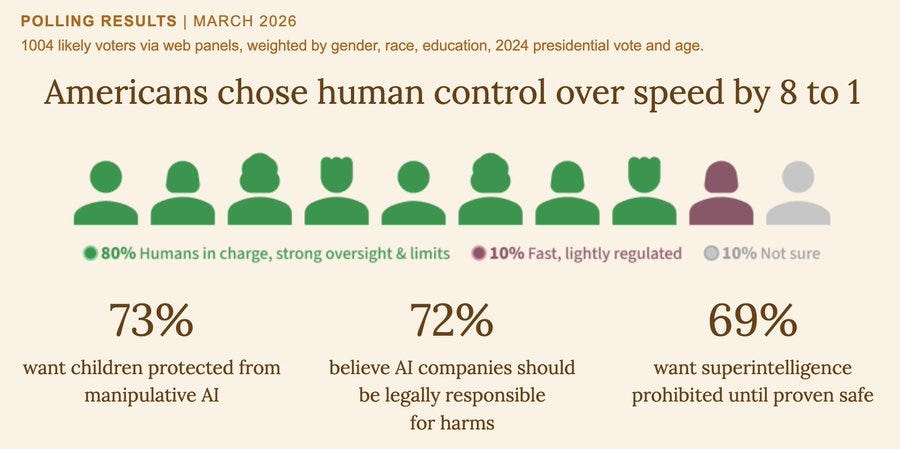
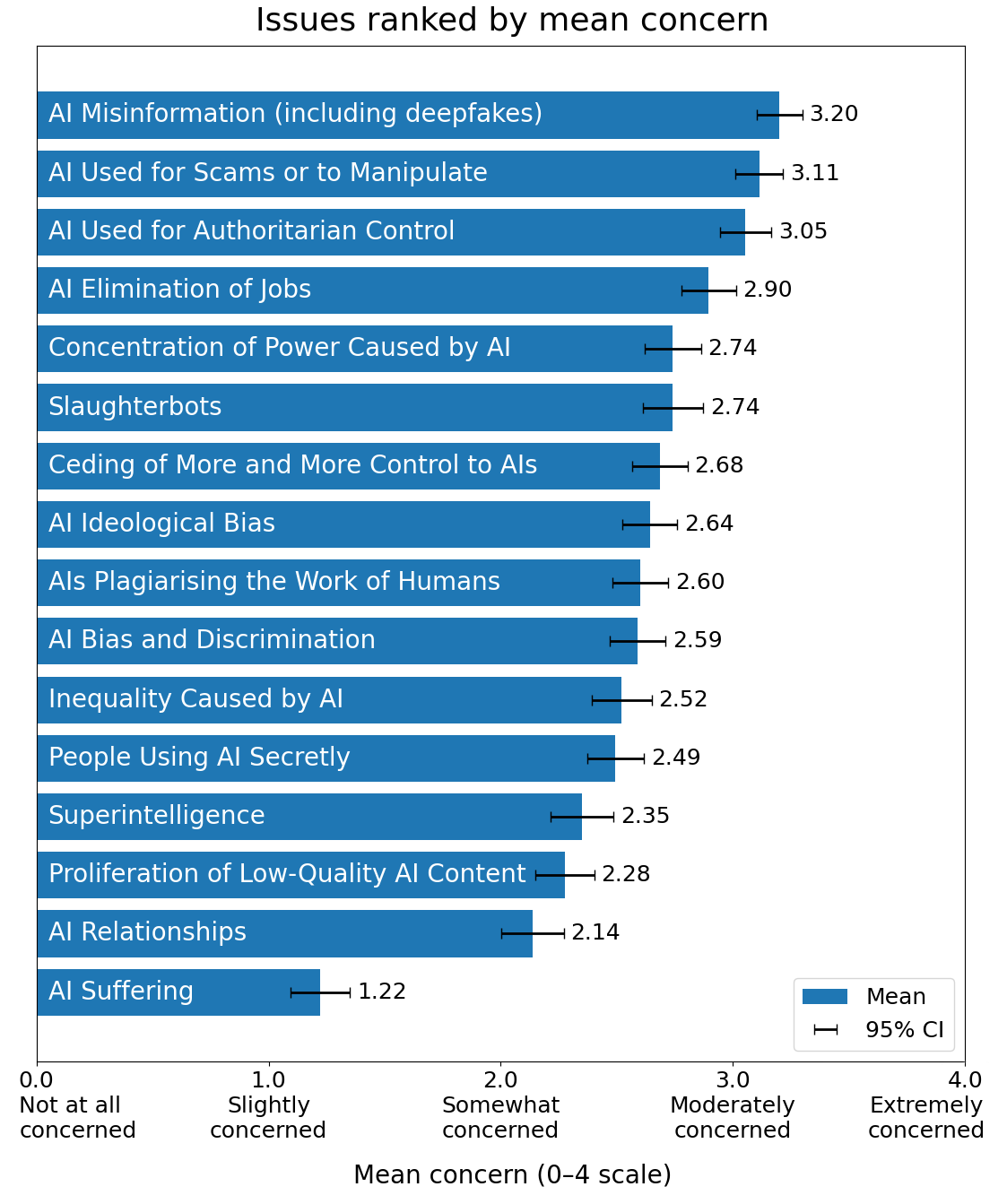
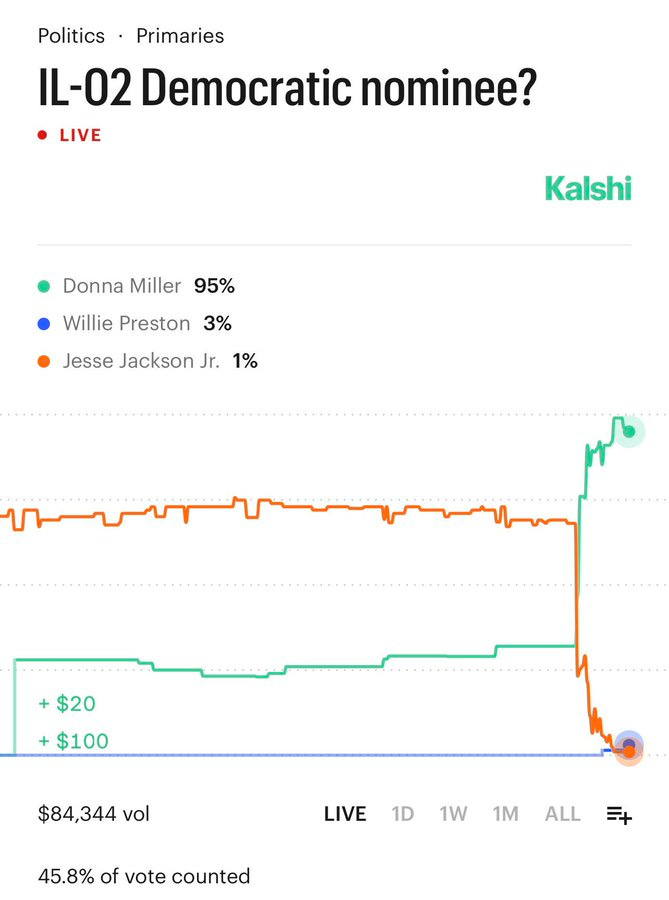
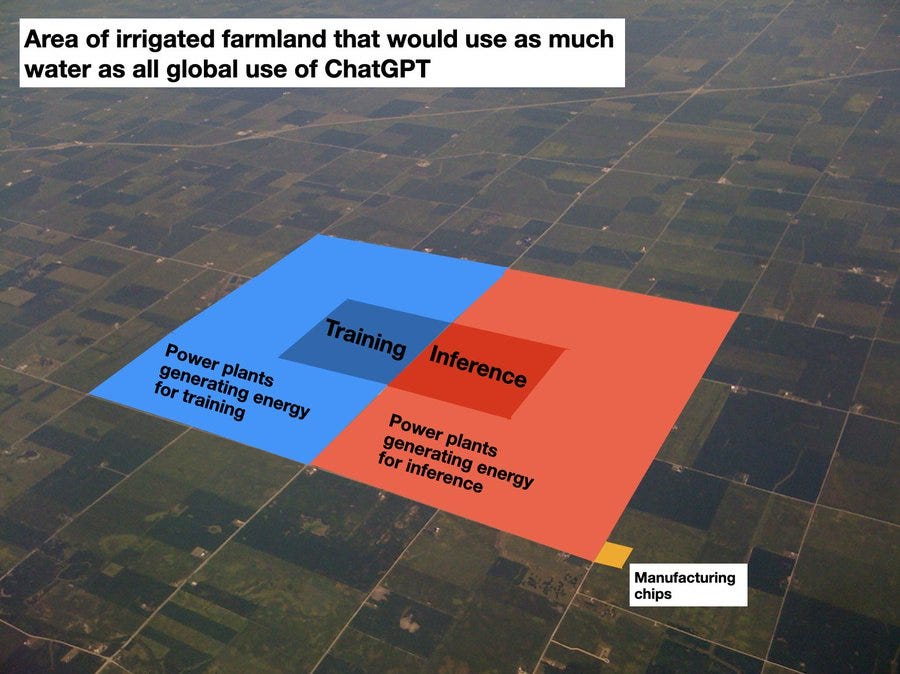

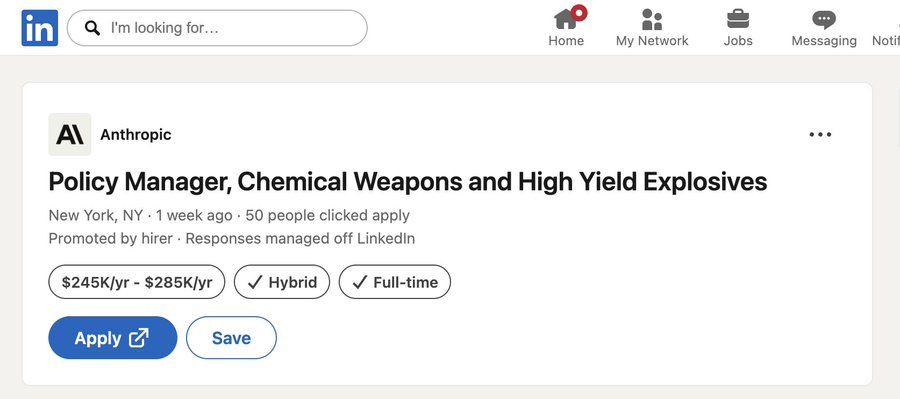
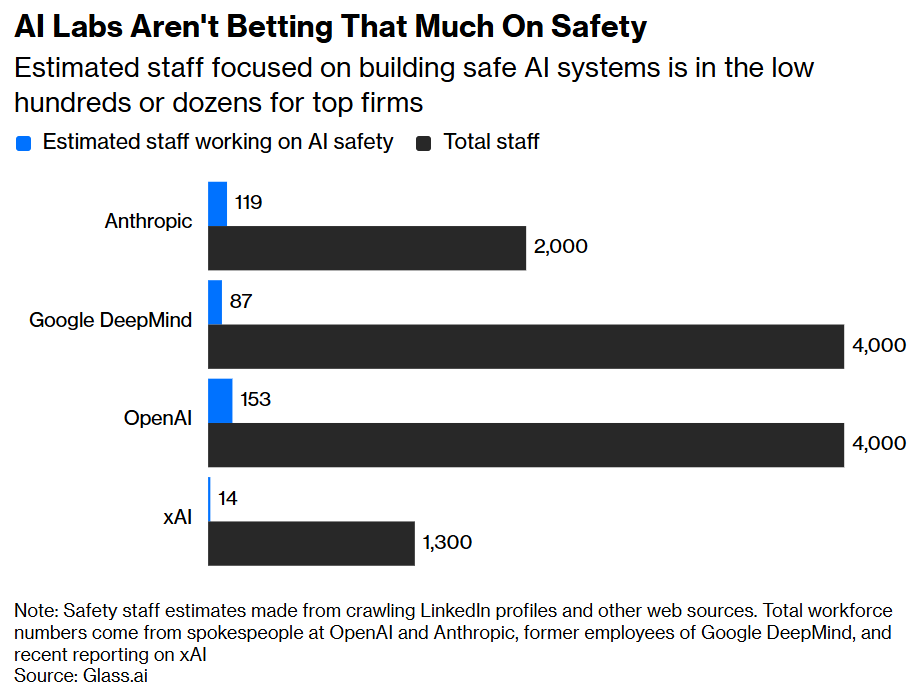
"Whereas Elon Musk insists that safety is ‘everyone’s job’ when he disbands the safety department, so his estimate should now presumably be zero."
Or however many people xAI employs... several thousand. :)
Thanks for linking the educational report, just wrote a piece on AI in education and will now read each article with an eye to what I might have gotten wrong!