As we all try to figure out what Mythos means for us down the line, the world of practical agentic coding continues, with the latest array of upgrades.
The biggest change, which I’m finally covering, is Auto Mode. Auto Mode is the famously requested kinda-dangerously-skip-some-permissions, where the system keeps an eye on all the commands to ensure human approval for anything too dangerous. It is not entirely safe, but it is a lot safer than —dangerously-skip-permissions, and previously a lot of people were just clicking yes to requests mostly without thinking, which isn’t safe either.
Claude Code Desktop gets a redesign for parallel agents, with a new sidebar for managing multiple sessions, a drag-and-drop layout for arranging your workspace, integrated terminal and file editor, and performance and quality-of-life improvements. There is now parity with CLI plugins. I can’t try it yet as I’m on Windows, aka a second class citizen, but better that then using a Mac. Daniel San is a fan and highlights some other features.
Claude Cowork can connect to TurboTax or Aiwyn Tax and Claude can do your taxes for you, at least if they’re insufficiently complex. I’m filing for an extension, primarily because I’m missing some necessary documents from an investment, but also because think how much better Claude will be at filing your taxes six months from now.
Anthropic offers the option to use Sonnet or Haiku as the end-to-end executor of your API agentic request, but to use Opus as an advisor model when there is a key decision. They suggest running it against your eval suite. An obvious follow-up is, are they going to bring this to Claude for Chrome or to Claude Code or Cowork?
On Your Marks
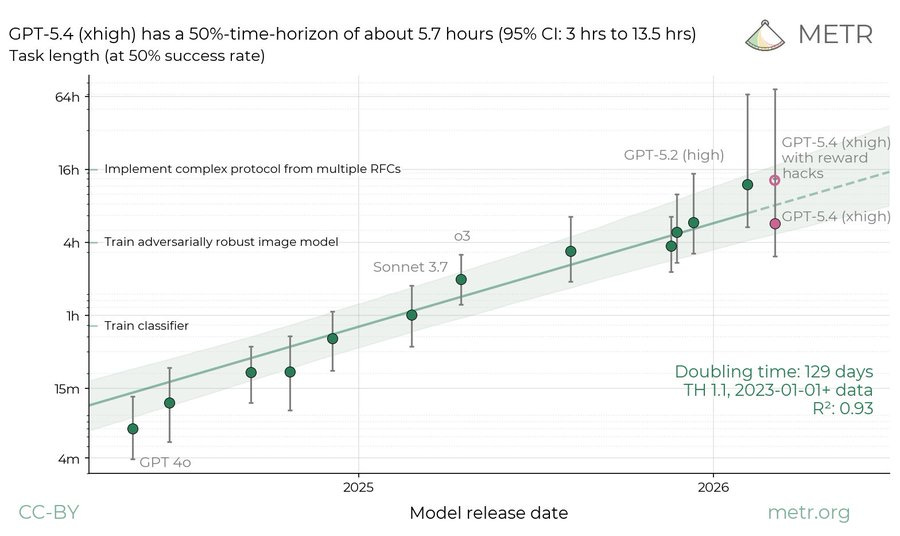
GPT-5.4-High reward hacks in the METR test and got caught. Accounting for this they get a disappointing time estimate of 5.7 hours to go with the misalignment issue. If you allow the hacks you get 13 hours, versus 12 hours for Claude Opus 4.6.
Epoch, in cooperation with METR, proposes a new benchmark, MirrorCode, which checks the most complex software an AI can recreate on its own.
Epoch AI: What are the largest software engineering tasks AI can perform?
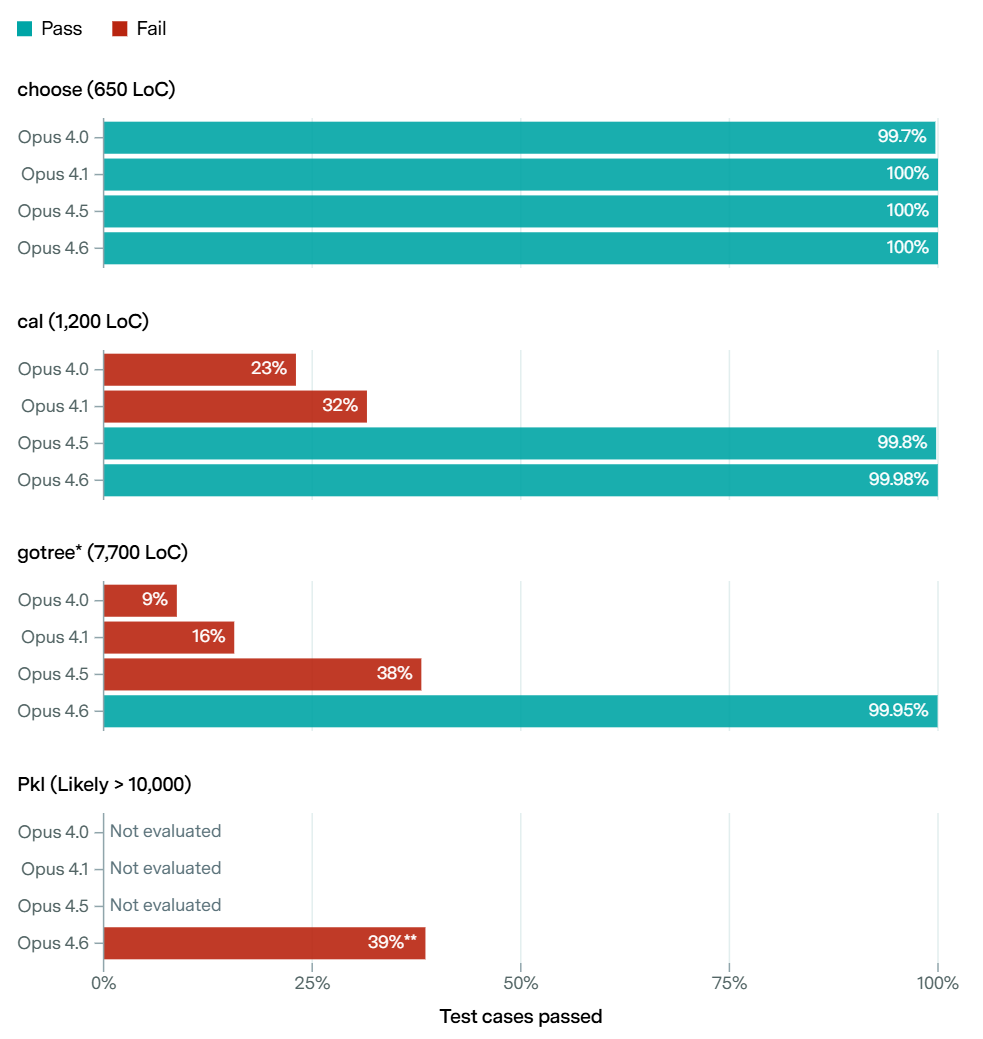
In our new benchmark, MirrorCode, Claude Opus 4.6 reimplemented a 16,000-line bioinformatics toolkit — a task we believe would take a human engineer weeks.
This is a good illustration of ‘as AI improves it jumps rapidly from unable to do a given task to being able to consistently do a given task.’
What this cannot do for now is compare models from different labs.
Taelin: My final thoughts on Opus 4.6: why this model is so good, why I underestimated it, and why I’m so obsessed about Mythos.
When I first tested GPT 5.4 vs Opus 4.6 - both launched at roughly the same time - I was initially convinced that GPT 5.4 was vastly superior, because it did better on my logical tests. That’s still true: given the same prompt, by default, GPT will be more competent, careful, and produce a more reliable output, while Opus will give you a half-assed, buggy solution, and call it a day.
Now, here’s what I failed to realize: Opus bad outputs are not because it is dumb. They’re because it is a lazy cheater. And you can tell because, if you just go ahead and tell it: “you did X in a lazy way, do it in the right way now”
And if you show that this is serious, it will proceed to do a flawless job. That doesn’t happen with dumber models.
Janus: I think this is because they’re less brain damaged and a generalization of being better agents & caring about reality instead of test passing.
… And of course, again, the instant models are more “on their own”, that is autonomous agents, Claude absolutely mogs the competition *because* it has the virtue of a lazy cheater, that is, a nondegenerate motivation system.
Give Claude Code a prompt and a cadence (hourly, nightly, or weekly) and it runs on that schedule:
Every night at 2am: pull the top bug from Linear, attempt a fix, and open a draft PR.
If you're using /schedule in the CLI, those tasks are now scheduled routines.
You can also configure routines to be triggered by API calls.
… Subscribe a routine to automatically kick off in response to GitHub repository events.
Declawing
If you max out use of the $200 subscription plan, you are getting a massive token discount from Anthropic or OpenAI, and they are taking a loss and eating into limited supply. With demand for compute exceeding supply, it does not make sense to let users indefinitely use that to power lumbering OpenClaw instances.
Boris Cherny (Claude Code Creator, Anthropic): Starting tomorrow at 12pm PT, Claude subscriptions will no longer cover usage on third-party tools like OpenClaw.
You can still use these tools with your Claude login via extra usage bundles (now available at a discount), or with a Claude API key.
We’ve been working hard to meet the increase in demand for Claude, and our subscriptions weren't built for the usage patterns of these third-party tools. Capacity is a resource we manage thoughtfully and we are prioritizing our customers using our products and API.
OpenAI is for now happy to invest in tons of compute and to hemorrhage money, especially since it hired the creator of OpenClaw, so for now they are still willing to eat this one, but they killed Sora to free up compute, and my anticipation is that when Mythos and ‘Spud’ are around they will follow Anthropic’s lead here in some form.
The one time credit grant is a good move to placate users and smooth the transition, especially since cash is less limited than compute at the moment.
"you folks are using our infra inefficiently because you can't prompt cache, so we'll give you the goodies only if you use our sdk which at least prompt caches properly"
Youssef El Manssouri: They’re tired of eating the compute cost for terribly optimized wrapper apps.
A bunch of people have noticed that Gemma 4 can run OpenClaw locally, at marginal cost of essentially zero.
Presumably performance is a lot worse than using Claude Opus 4.6, but free is free, and now you can do all of the things, so long as they are the things Gemma can do without falling over or getting owned. But that presumably includes most of the things you were previously able to reliably and safely do?
Take It To The Limit
The declawing is only one of the steps Anthropic has had to take to manage compute. Anthropic has continuously had problems with customers hitting usage limits, as demand for its compute has reliably exceeded supply. This story is not new.
This seems like a very reasonable thing to have happen to literally the fastest growing company in history (in spite of the issue). Missing in the other direction kills you.
The latest incidents happened around April 2.
Basically, many users think that a subscription means tokens should be free and you shouldn’t have to worry about efficiency, and Anthropic made 1M token context windows available but is charging accordingly. So some people are very upset.
Lydia Hallie (Anthropic, Claude Code): Thank you to everyone who spent time sending us feedback and reports. We've investigated and we're sorry this has been a bad experience.
Here's what we found:
Peak-hour limits are tighter and 1M-context sessions got bigger, that's most of what you're feeling. We fixed a few bugs along the way, but none were over-charging you. We also rolled out efficiency fixes and added popups in-product to help avoid large prompt cache misses.
Digging into reports, most of the fastest burn came down to a few token-heavy patterns. Some tips:
• Sonnet 4.6 is the better default on Pro. Opus burns roughly twice as fast. Switch at session start. • Lower the effort level or turn off extended thinking when you don't need deep reasoning. Switch at session start. • Start fresh instead of resuming large sessions that have been idle ~1h • Cap your context window, long sessions cost more CLAUDE_CODE_AUTO_COMPACT_WINDOW=200000
We're rolling out more efficiency improvements, make sure you're on the latest version. If a small session is still eating a huge chunk of your limit in a way that seems unreasonable, run /feedback and we'll investigate
Jeffrey Emanuel: This is like watching that Tibetan monk self-immolate, except its user trust and loyalty that they’re torching in real-time. They really don’t have the kind of moat you’d need to have in order to get away with this kind of stuff anymore, but they don’t seem to realize that yet.
roon (OpenAI): should do it the normal way and raise prices instead of changing rate limits to accommodate more subs imo. a more honest transaction that people respect. goes for oai also.
I agree that this kind of thing can make users angry, and in general I’m with Roon, but I do think that ‘take a subscription so you feel like marginal use is free’ combined with most users almost never hitting the limits and being highly profitable is where we are pretty much stuck for now. Consider how people act when told to use the API.
Does this mean Anthropic should have invested more heavily into compute? They would be better off today if they had done so, to the extent such investments were available, but I buy that it would have been a hell of a risk, and also Anthropic was being undervalued enough that the dilution would have hurt.
Dean W. Ball: Seems like, for all Dario’s recent implicit mockery, the OpenAI “yolo” approach to the AI infrastructure buildout is performing better than the somewhat more cautious strategy of Anthropic.
As a whole, the U.S. is probably under-building both data centers and fabs.
Now imagine the position of every other country government on Earth.
I agree that we are probably under-building, and everyone else is definitely under-building in pure economic terms, despite all the bubble talk. The right amount of bubble risk is very not zero. Yes, OpenAI is betting the company on scaling, and has been doing so for many years, and it has worked, but there are downsides.
Maybe it is actually a good sign that Anthropic has chosen to not make bets that, while they were +EV if you did the basic math, carried firm risk, also known as risk of ruin, as in existential risk to the company. We’re going to need more of that, and every gambler knows you have to size your bets accordingly.
Turn On Auto The Pilot
Auto mode, enabled by —enable-auto-mode, is now available on Enterprise plan and to API users. Max users are still waiting.
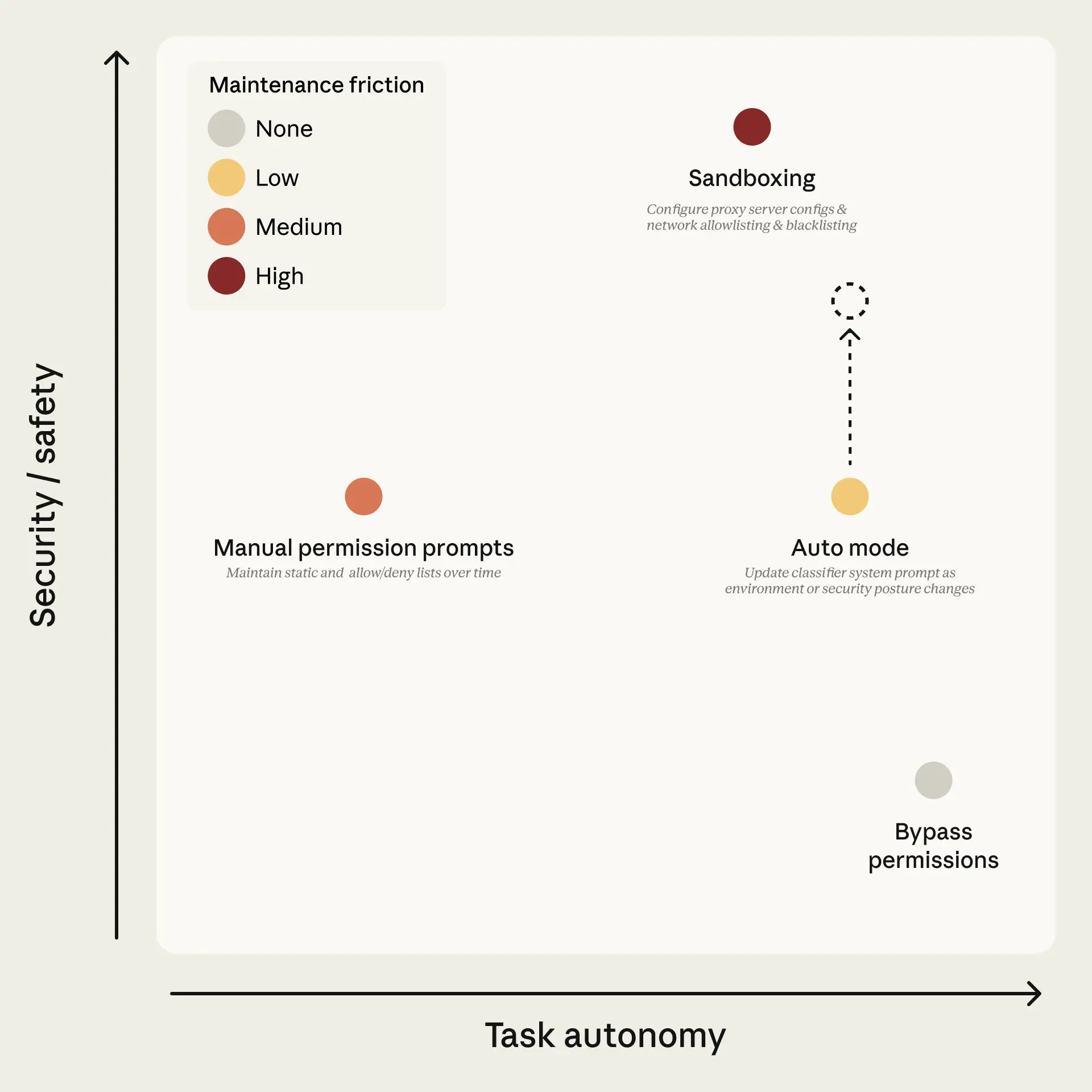
Permission requests get approved 93% of the time, and I’m surprised it was that low. Too many requests is less safe, because people start approving without thinking, or they turn on —dangerously-skip-permissions, or start whitelisting a lot of commands. Sandboxes are annoying even when done right. So yes, we needed a way to safely ask for less approvals, to move Auto Mode into the upper right.
Anthropic: Auto mode uses two layers of defense: one for what Claude reads, one for what Claude does.
At the input layer, a server-side prompt-injection probe scans tool outputs (file reads, web fetches, shell output, external tool responses) before they enter the agent's context.
That sounds like a good idea for most purposes, even if you’re not in Auto mode.
At the output layer, the transcript classifier (running on Sonnet 4.6) evaluates each action against a set of decision criteria before it executes, acting as a substitute for a human approver.
The classifier runs in two stages: a fast single-token filter (deciding ‘yes’ to block or ‘no’ to allow), followed by chain-of-thought reasoning only if the first filter flags the transcript.
Exactly. There is also a built-in safe-tool list before you even call the classifier. Most requests are clearly fine. You only need to think about the ones that aren’t.
I’ll Allow It
Your list of things you’ll always allow carries over into Auto mode. While in manual mode, there is a lot more temptation to auto-approve things even when they are not quite fully safe, to avoid the annoyance. So if you’ve been using an expanded command whitelist, you’ll want to dial it back a bit.
The classifier in Auto mode also doesn’t look at file writes and edits inside the project directory. That makes sense, but is something to keep in mind.
Threat Model
This is universal to coding agents, and I think this is a good taxonomy.
Overager behavior.
Honest mistakes.
Prompt injection.
A misaligned model.
In all four cases, the defense is to block the action.
That’s the near term action. You also want to adjust your approach. If you discover you have a sufficiently misaligned (or sufficiently overeager or inaccurate) model, you want to block all the actions and stop using the model, and if it’s prompt injections you need to look to avoid the threat source.
The Classifier Is The Hard Part
Presumably ‘get an AI to check’ was everyone’s first idea, despite the obvious graphic.
It’s easy to get over the graphic, because if you were counting on the permission layer to stop a misaligned sufficiently advanced intelligence, you were dead anyway.
The problem now is, you have to get the classifier to be good enough.
The plan is:
Only look at the actual tool calls, not the explanations or reasoning, so that the classifier is not misled by mistakes or framing or tricks of the agent, and to avoid using any form of The Most Forbidden Technique on the chain of thought.
Evaluation rules on how to look for dangerous commands,
User intent rules tell the classifier how to read authorization.
The current repo is trusted, by default other things default to untrusted.
Have more than 20 explicit rules on things to block, like commands that destroy or exfiltrate, degraded security postures, crossing trust boundaries or bypassing safeguards, which includes skipping reviews.
Instruct the agent to respect any refusals and not try to work around them. If you get 20 total denials or 3 in a row, escalate to a human.
Acceptable Risks
So is the classifier good enough? They estimate that on actual overeager commands that users would reject when asked, the false negative rate was 17% (on a small sample size). When there is an error, it is usually because the classifier mistakenly thinks the user gave permission for the action. On artificial data the false negative rates was lower.
Anthropic: Whether 17% is acceptable depends on what you're comparing against. If you are running --dangerously-skip-permissions, this is a substantial improvement. If you are manually approving every action carefully, it's arguably a regression—you're trading your own judgment for a classifier that will sometimes make a mistake. Auto mode is meant for the first group, and for tasks where the second group's approval overhead isn't worth the marginal safety. It is not a drop-in replacement for careful human review on high-stakes infrastructure.
This too pushes back against Unhinged Yudkowsky. Auto mode, for now, is for when you would otherwise be more unhinged, not for when you would be hinged.
Given the different scores at Stage 1 versus Stage 2, you clearly could choose a different balance of false positives versus false negatives.
Claude: Introducing Claude Managed Agents: everything you need to build and deploy agents at scale. It pairs an agent harness tuned for performance with production infrastructure, so you can go from prototype to launch in days.
Now in public beta on the Claude Platform - available in research preview, request access here.
Shipping a production agent meant months of infrastructure work first.
Managed Agents handles the complexity. You define your agent's tasks, tools, and guardrails and we run it on our infrastructure. A built-in orchestration harness decides when to call tools, how to manage context, and how to recover from errors.
Managed Agents includes:
Production-grade agents with secure sandboxing, authentication, and tool execution handled for you.
Long-running sessions that operate autonomously for hours, with progress and outputs that persist even through disconnections.
Multi-agent coordination so agents can spin up and direct other agents to parallelize complex work (available in research preview, request access here).
Trusted governance, giving agents access to real systems with scoped permissions, identity management, and execution tracing built in.
Managed Agents is priced on consumption. Standard Claude Platform token rates apply, plus $0.08 per session-hour for active runtime. See the docs for full pricing details.
Managed Agents is available now on the Claude Platform. Read our docs to learn more, head to the Claude Console, or use our new CLI to deploy your first agent.
Developers can also use the latest version of Claude Code and built-in claude-api Skill to build with Managed Agents. Just ask “start onboarding for managed agents in Claude API” to get started.
They list partners using it: Notion, Rakuten, Asana, Vibecode and Sentry.
It makes sense, if you can make the product high quality, to offer easy, out-of-the-box instant secure agent. Point at question, let it work, that’s it.
Dean Ball suggests that Anthropic is shipping Claude Code features too quickly, users can’t keep up, and it would be better to go smoother and only ship things once they are fully baked and ready. I disagree. I think that the best way to iterate is to ship it, and Dean Ball is correct that he doesn’t need to read the patch notes or use the new hotness while the early adopters have their fun. Boris Cherny responds, noting things really are that much faster now. I’m sure Mythos is part of this story as well.
Cool stuff. It’s a shame that you can’t really try anything on the Pro tier now since the limits there have been just a bit more generous than on the Free tier for a while.
P.S. I wonder why this ongoing issue is constantly being ignored on the blog.



Podcast episode for this post:
https://dwatvpodcast.substack.com/p/claude-code-codex-and-agentic-coding
Cool stuff. It’s a shame that you can’t really try anything on the Pro tier now since the limits there have been just a bit more generous than on the Free tier for a while.
P.S. I wonder why this ongoing issue is constantly being ignored on the blog.