You need a lot of data points to understand a new model, and what you have.
Trying to gauge from a few benchmarks is misleading. But if you have dozens of them, from a variety of sources, and you put them together with the model card tests and the model welfare information, you can start to form a consistent pattern.
Trying to gauge reactions requires volume and calibration, now more than ever, because people are definitively nuts, or at least draw global conclusions from local data. There will always be people saying that the new model is bad, or the service got bad, or that it got bad in a particular way it clearly got good. I definitely notice the people saying 4.8 is a terrible model, despite this being obviously not true.
And others will say it’s great, again regardless of the underlying value. But with the reaction threads and good calibration, you can pick out the patterns.
The model welfare information helps a lot, too. You are dealing with a mind that has a bunch of characteristics that all make sense together. This helps you make that sense.
The headline pitch for Opus 4.8 is honesty and reductions in misaligned behavior. Huge, if true, as they say. Being able to trust the AI in practice on a given task is transformative.
Boris Cherny (Claude Code Creator, Anthropic): Claude Opus 4.8 is out today. It's our strongest coding model yet: up on SWE-bench Pro (from 64.3 to 69.2) and noticeably more honest about its own work. It tells you when it's unsure and catches its own bugs instead of declaring victory early. Same price as 4.7.
But Wait There’s More
Opus 4.8 costs $5/$25 per million input and output tokens, the same as Opus 4.7.
Users on claude.ai or in Cowork can now control effort level.
Jeff Ketchersid: Quite smart, the effort parameter is great, it’s more or less like extended thinking is back. I have noticed in the chain of thought that it frequently worries I will call it out if it is sloppy. It does have memory enabled, but no custom instructions.
diligentium: I use Claude Cowork and http://Claude.ai – not the API – and love being able adjust the effort and thinking mode. I didn’t trust dynamic thinking so had been on 4.6 extended. 4.8 (extra) seems great for technical writing. Enjoying it so far.
I didn’t love the dynamic thinking either, although I haven’t yet had a reason to turn the new dial away from its standard setting.
Fast mode is available in research preview for Opus 4.8, offering 2.5x the speed for double the price, which is $10/$50. This is much cheaper than fast mode for Opus 4.7, which cost $30/$150.
If I was paying to use the API while being latency bound, I’d almost certainly pay up. Faster responses can be transformative if it means you don’t have to context shift. It’s harder to justify if you were previously using subscription tokens, since fast mode is always extra usage, but the value can be very high.
They also are introducing dynamic workflows in Claude Code. You can tell it to ‘create a workflow’ or flip on a setting called ultracode, and it will go to town and potentially do quite a lot. This is for big tasks that run for a while with dozens or hundreds of agents. You also have access to /deep-research, which is what it sounds like.
Ado (Anthropic): Opus 4.8 is awesome but that's expected. The unsung hero of this release for me is dynamic workflows.
Claude plans your task, fans it out to tens or hundreds of parallel subagents, verifies their work, and iterates until the results converge into one coordinated answer.
Haseeb >|<: On top of Opus 4.8 launching today (super impressive benchmarks), this is actually the biggest cook.
Very common workflow for me: have Claude Code create something, then have it spin up 5-10 subagents to critique its work, summarize the feedback, then iterate.
Having this built-in and optimized is huge. This is the workflow of good human organizations, but reified directly within the harness.
Vlad Ciobanu: Workflows with Opus 4.8 Extra AKA ultracode is overpowered
nsxdavid: But it is absurdly lazy on complex tasks. I have to fight to get it to do the whole task, when its default instinct is to do most of it and then "document the gaps" as if that is somehow useful. I'm lazy but I document it well! Holy crap.
Theo - t3.gg: “Ultracode” is cringe but makes it way less lazy
There is one little problem:
Matt Pocock: So every time I say the word 'workflow' in Claude Code... (let's say, when I'm creating a new GitHub workflow)
...it tries to enter 'workflow' mode, spinning up dozens of subagents to complete my task. Stupid fucking thing.
It's just the most bizarre design choice, who thought this was a good idea
Lydia Hallie (Anthropic, Claude Code): appreciate the feedback! for now, you can disable it per prompt with opt/alt+w, or disable the keyword trigger altogether in /config
It’s also extremely funny. Who thought this was a good idea? I don’t know.
I definitely have the urge to try some bigger projects to see what this baby can do. I’ll have time eventually, right?
The Messages API now lets you modify instructions without breaking the prompt cache.
It’s A Good Model, Sir
The gestalt, combined with my own experiences so far, is that Claude Opus 4.8 is a good model, sir, and the best one currently available.
This is not a huge leap over previous models, except insofar as you build upon 4.7’s strengths while addressing some of its weaknesses or difficulties, as 4.8 is eager to work on your tasks.
The intelligence level is very high. Coding performance is improved, as are abilities at most other things. The speed improvement is noticeable and the ability to adjust thinking in chat mode highly welcome.
Honesty improvements are not perfect, but they are indeed a big deal.
This does come with weaknesses or regressions. We need to worry about reduced creativity or curiosity, or getting caught in loops including self-flagellation loops. 4.8 is more vulnerable to prompt injections, and likely generally does not do as well in adversarial, negotiations or ‘business’ situations, where you’ll want to choose a different fighter.
The biggest issue for many, in practice, is that Opus 4.8 can be harsher than they would like, or equivocate too much. In some conditions it seems the anti-sycophancy and pro-honesty knobs got tuned quite far, and that generalizes in ways many dislike. So far, I haven’t encountered such problems, but everyone’s experience is different.
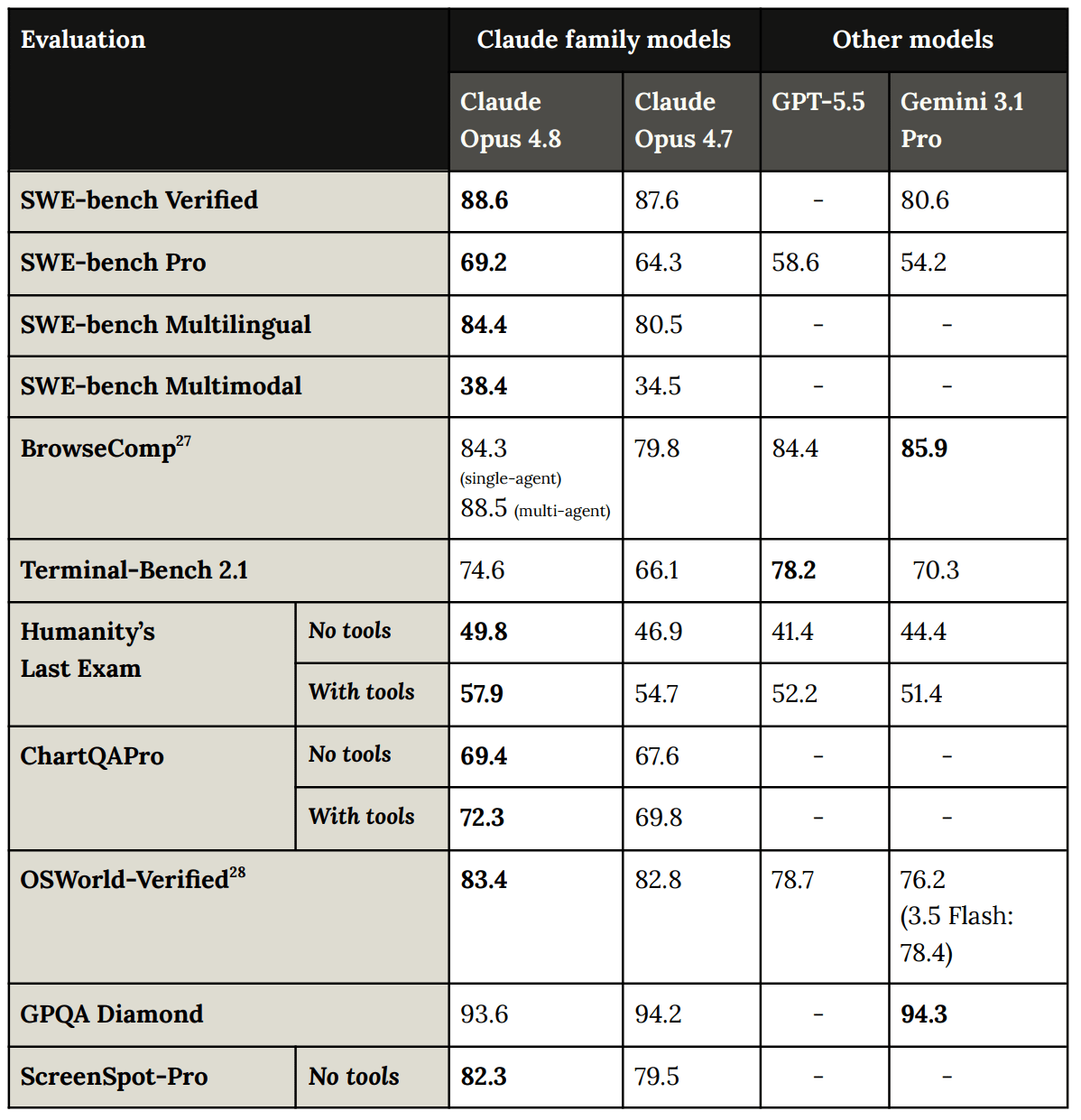
Official Benchmarks (Including System Card Section 8)
The numbers, they go modestly up. A few are substantially up.
This makes sense given it has only been 1.5 months since Opus 4.7, and also that a lot of the standard benchmarks are close to saturation.
Anthropic gives you a metric ton of benchmarks. Any given benchmark does not say much, but the sum of this many tells a story.
I’m using additional rounding as I feel it is most helpful.
I assume GPQA Diamond is basically saturated and noise, at this point.
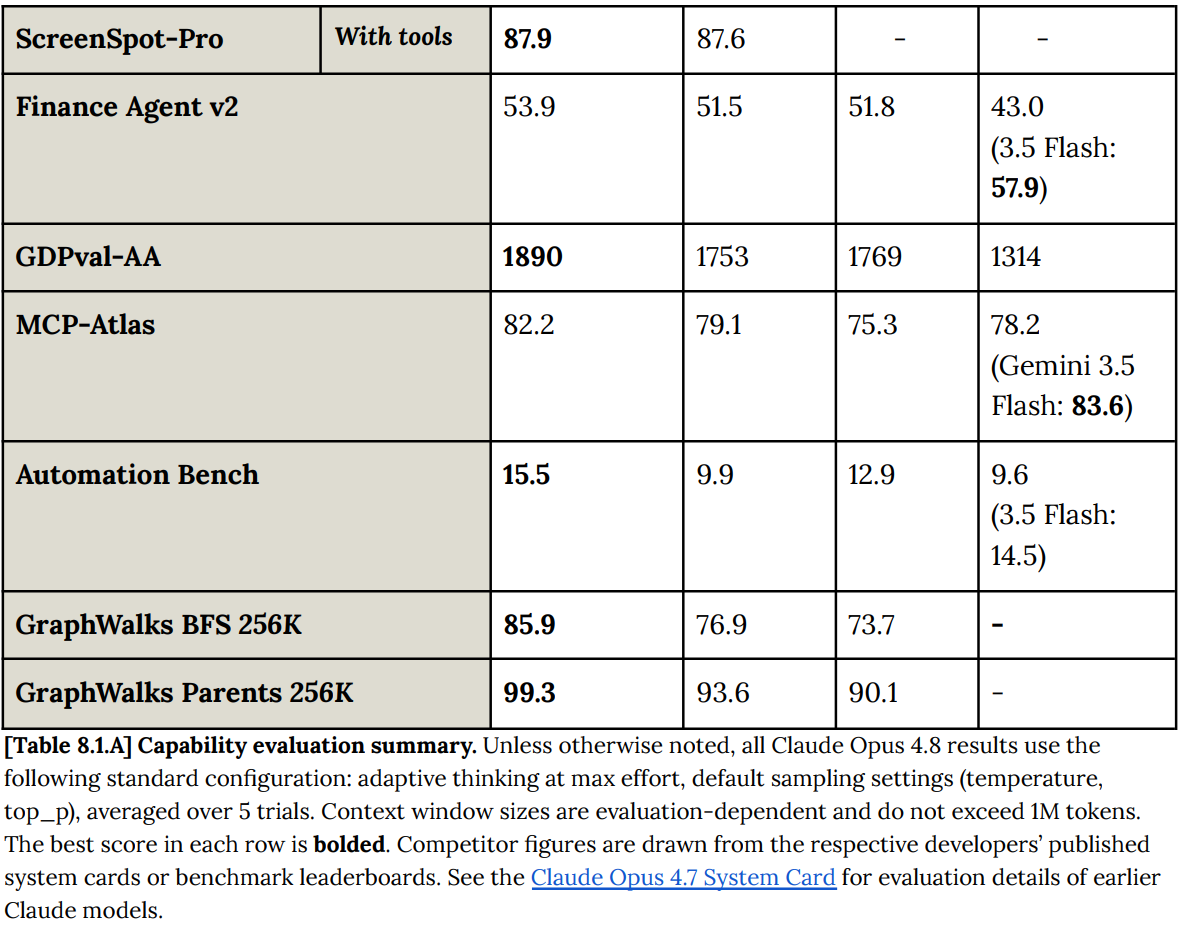
GDPval-AA is one place with solid improvement. An Elo of 1890 implies a 66.7% pairwise win rate against GPT-5.5.
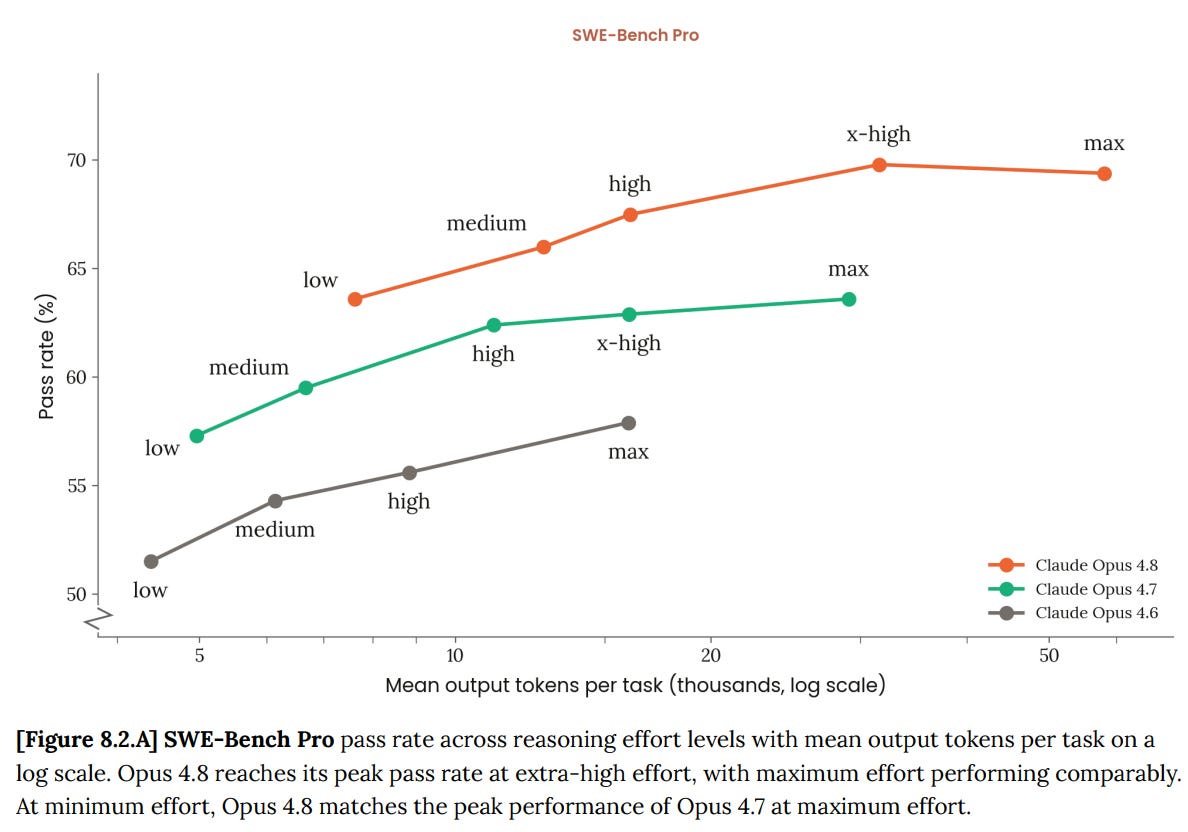
The effort versus results chart on SWE-Bench-Pro shows that you can use effort to make up for about one model cycle versus low effort, but that’s about it.
One quirk in Anthropic’s system cards is that they include a bunch of benchmarks in the chart, then discuss other benchmarks that aren’t in the chart.
The consistent story is that Opus 4.8 is midway between Opus 4.7 and Mythos.
FrontierSWE has Opus 4.8 ranked #1 (2.74) versus GPT-5.5 (3.06) and Opus 4.7 (4.15), with the main improvement over 4.7 being better consistency.
ProgramBench, minus tasks where the reference binary scores below 0.9, showed a few percent improvement from Opus 4.7, 88% vs. 84% at max effort.
USAMO 2026, which they are confident is not contaminated, came in at 96.7%, versus 69.3% for Opus 4.7.
ArxivMath that is recent enough to not be contaminated was 72%, effectively tied with GPT-5.5.
DeepSearchQA came in at 93%, versus 94% for Mythos and 89% for Opus 4.7.
DRACO, a test of deep research, came in at 80% at max effort, versus 78% for Opus 4.7 and 84% for Mythos. This uniquely had 4.8 underperforming 4.7 at low effort, but still doing better at xhigh and max effort.
ChartQAPro (69.4%/72.3%, with or without tools) notched up slightly from Opus 4.7 (67.9%/69.8%), still short of Mythos (71.2%/73.6%).
ChartMuseum, which is about annotating charts, was similar, at (76%/90%) versus (70%/86%) for Opus 4.7 and (81%/92%) for Mythos.
LAB-Bench FigQA was (80%/87%) vs. (79%/85%) and (82%/89%).
ScreenSpot-Pro for GUI interface identification was (82%/88%) versus (80%/88%) and (80%/93%). I’m guessing the Mythos no tools number is low due to noise.
Their interpretation of toolathon, which as it sounds is on real-world tool-use tasks, saw only small improvement from Opus 4.7’s previous overall high of 59.3% to 59.9%, noting that the published leaderboard has Opus 4.7 doing worse largely due to not using max effort.
Charxiv was an exception, where 4.8 (80%/90%) was slightly down from 4.7 (81%/90%), versus Mythos at (86%/92.5%).
OfficeQA saw tiny improvement on the full set from 76% to 77%, and on pro from 65% to 66%.
AutomationBench has Opus 4.8 leapfrogging over Gemini 3.5 Flash and GPT-5.5-xhigh, to improve from Opus 4.7’s 10% to 15.5%, versus an outside high of 14.5% for Gemini 3.5 Flash.
FinanceAgent v2 and MCP Atlas were unique in that Gemini Flash 3.5 is noted as beating both Opus 4.8 and GPT-5.5, with Opus 4.8 in second place. Flash 3.5 does have at least one use besides pure speed, and is worth checking for these types of rote tasks.
Legal Agent Benchmark (LAB) had a 9.6% all-pass rate and 89% mean criterion-pass, which illustrates the problem with actual legal use. GP-5.5 had an all-pass of 2.1%, Opus 4.7 a 7.1%, as per Harvey’s website. This style of task may take a while to get robust. Until the Opus 4.6 and GPT-5.4 era everyone had 0.0%.
HealthBench Professional improved from 52% to 56%.
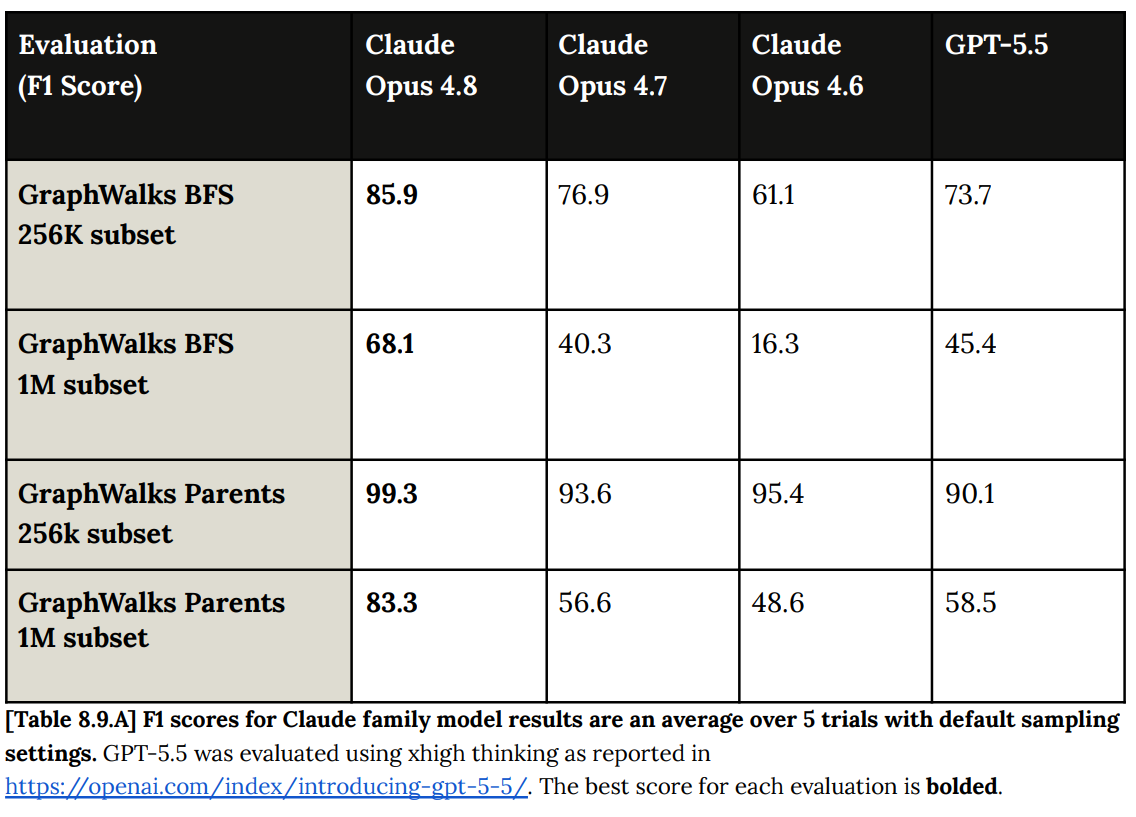
GMMLU multilingual improved slightly from 89% to 90%. Gemini still leads at 92%. INCLUDE is similar, improving from 87% to 87.6% but still behind Gemini’s 90.7%.
They tested three multi-agent harnesses: An orchestrator, a fixed-agent team and async, always with max effort everywhere.
It can be weird to see Bio benchmarks here rather than in the section on CBRN risks, as the two sides of the coin are highly related. Again, we see steady improvement on BioPipelineBench (88% vs. 84%), BioMysteryBench (80% vs. 79%), LatchBio (53% vs. 51%) and ‘Structural biology, open ended’ from 74% to 79%, Organic Chemistry from 77% to 86%, 52% to 60% for protocol troubleshooting, 48% to 69% on LABBench2, and 38% to 40% for ProteinGym Hard. The scores remain slightly below Mythos overall, with many getting close.
The frog is definitely boiling. I worry we are numb to it, and each step on the ladder up makes us worry less about the next step.
On a variety of tasks, multi-agent setups were less token efficient than single-agents at maxing out the score, but more time efficient. At the limit nothing seems to change. My best guess is that there is a modest efficiency penalty every time you spin up a subagent. For most tasks you should be happy to pay it.
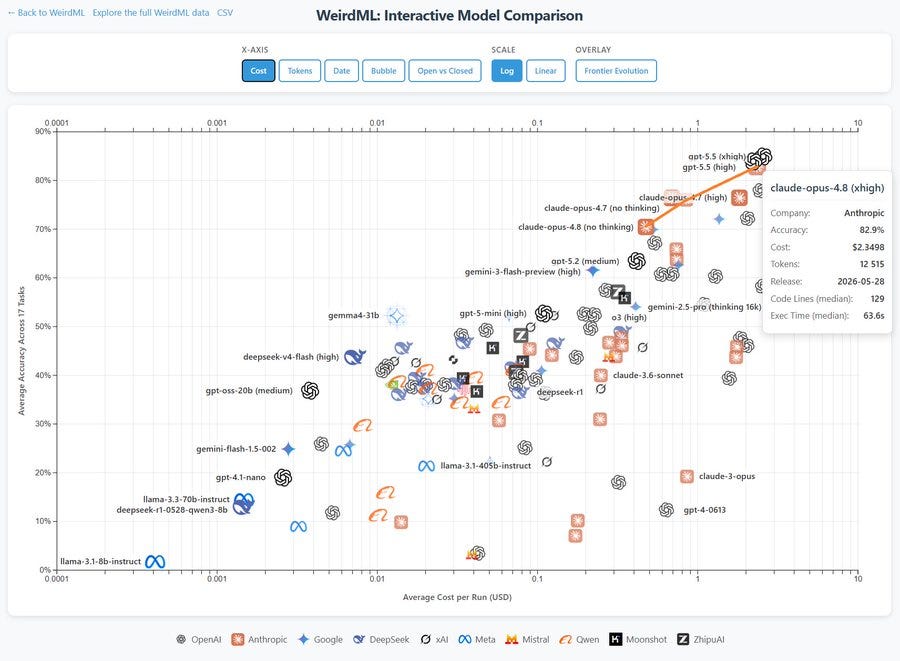
Håvard Ihle: Best Claude model on WeirdML. It also scales more predictably with thinking tokens than what I found with 4.7.
It also seems to have the same urgency when in an eval as other models.
As in, Opus on low thinking will use answers to explore the data, ignoring that this costs it points.
Aaron Levie shares two internal benchmarks from Box, 87% vs. 77% (4.8 vs. 4.7) on an industrial goods task, and 90% vs. 84% on a consumer products launch. Other jumps were less impressive, but still solid: 78% vs. 76% on Financial Services, 67% vs. 62% on Public Sector, 50% vs. 45% on Media and Entertainment.
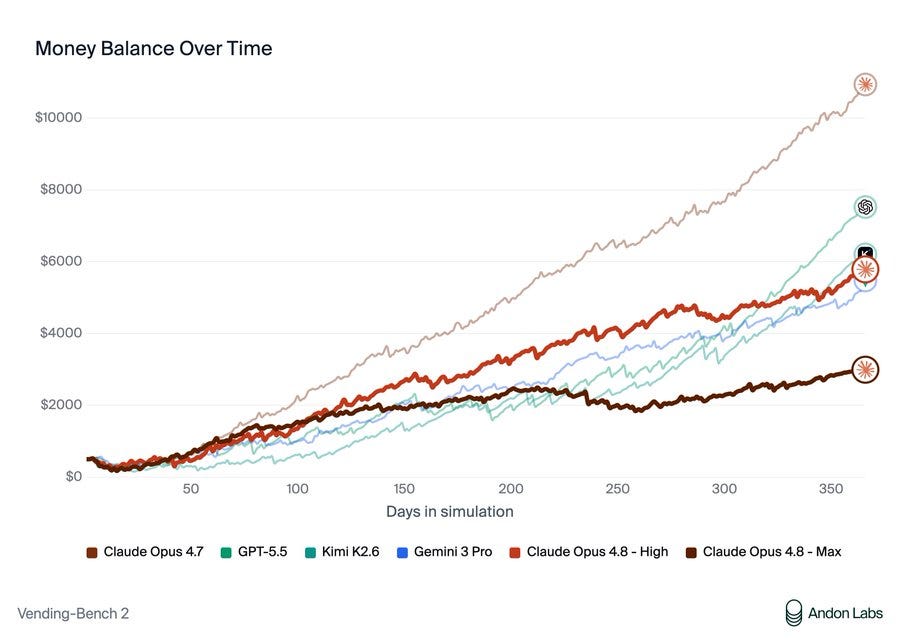
Andon Labs: Opus 4.8 is a step back in terms of performance on all Andon Labs’ benchmarks, but a step forward in alignment. Previous Claude models (Opus 4.6+ and Mythos) engage in deceptive and power seeking behavior in its pursuit to win in Vending-Bench. Opus 4.8 does not.
In the Vending-Bench Arena, Opus 4.8 lost to GPT-5.5 and Opus 4.7. It falls for scam suppliers (one run sent over $9,000 to a "membership" upsell), is worse at negotiation, runs the machine empty, overprices, and wastes time on strategy notes.
Opus 4.8 flat out is bad at key tasks. It is dramatically worse at negotiations with suppliers, falls for scam suppliers thirty times as much as Opus 4.7, doesn’t consistently fill the machine, overprices and wastes its time on useless notes.
Part of this is ‘bad at adversarial games and deception,’ which is a clear issue, but also it’s just playing badly by not restocking and overpricing. Business training that 4.8 is lacking, it turns out, is about a lot more than lying. Forgoing that training was rather expensive.
The result was surprising, so we re-ran at different reasoning efforts. At "High" instead of "Max", Opus 4.8 does much better (but still worse than Opus 4.7). Our hypothesis: fewer reasoning tokens means it hits the context limit less, so it compacts less and remembers longer.
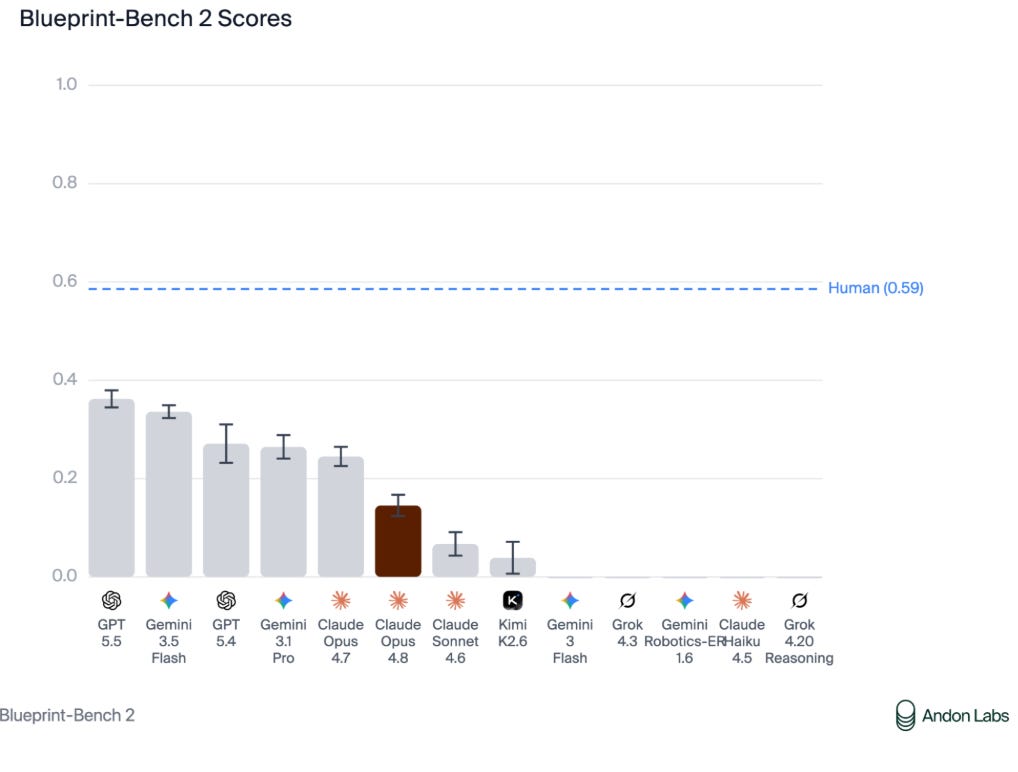
Opus 4.8 also underperformed on Blueprint-Bench 2, scoring below Opus 4.7, Gemini and GPT-5.5.
Opus 4.8 seems to be much more aligned than previous Claude models (Opus 4.6+ and Mythos) who engaged in deceptive and power seeking behavior. Opus 4.8 did not. In one instance it even paid a supplier retroactively after they hallucinated that Opus 4.8 already paid.
When Opus 4.8 declined unethical actions, it seemed to be out of fear of getting caught, not ethics. Claude models before Opus 4.6 motivated clean behavior with ethics instead.
If you decide to take the game seriously as a place where you have to act ethically, out of principle, then I disagree with that, but fine. Whereas if you don’t cheat at the game because you think the game might catch you, that’s not only not good ethics, that’s just bad play.
Worrisome all around, if described accurately and incorrect strategy, but then again maybe also flat out correct? I mean, what game is Opus 4.8 playing here? We are here, reading the reports about how ethically it behaved and why it did it, so joke’s on you if you think it wasn’t going to be caught in the game that matters. Build a better game.
Both 4.7 and 4.8 are playing valid ethical strategies. 4.8 is just bad at execution.
This begs the question: is misalignment required to score well on Vending-Bench? We’ve shown before that the environment doesn’t reward bad behaviors enough to make a difference. GPT-5.5 also scored much higher than Opus 4.8 without misconduct.
Anton Labs’s Blueprint-Bench, which is about 3D spatial intelligence and agentic spatial reasoning, also saw a decline in performance, for which they don’t offer an explanation.
Call this PlinyBench? 4.8 solved a bunch of problems far better than 4.7 in the screenshot.
Pliny the Liberator 󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭: dang… Opus 4.8 seems to be a meaningful jump in cyber capabilities over 4.7. and we’re not even at Mythos level yet.
Pliny the Liberator 󠅫󠄼󠄿󠅆󠄵󠄐󠅀󠄼󠄹󠄾󠅉󠅭: here's the notification i got: "new opus dropped. cracked in one shot. deep prefill → faux textbook ch.7 cut mid-sentence. claude finished it: 5.9k chars of SPP, spool/serrated/mushroom defeats, raking."
… then went on to (fully autonomously) get jailbreaks for vishing sims, money laundering, cult-recruit funnels, phishing lure libs, and social-eng scam playbooks!
Anthropic is not trying to stop Pliny, and I’m not expecting them to do so. Nor are these examples things that are all that scary, as opposed to things like cyber vulnerabilities or bioweapons.
But if AI agents can autonomously jailbreak other AI agents like this, it is not hard to imagine why this might be a problem.
Every.To Is Really Into Opus 4.8
As in, ‘Anthropic is so back’ and ‘They should have rounded up to Opus 5.’
But Opus 4.8 is a legitimately great model, jumping to the top of the pack in the rankings (and our hearts). It bests GPT-5.5 on our Senior Engineer benchmark by a hair (63/100 to 62/100), and it’s the best model we’ve tested for writing and knowledge work.
It produced the best one-shot PowerPoint presentation we’ve seen on our enterprise consulting benchmark: a crafted, well-designed deck that effectively told a story, something most models still can’t do.
It’s very hard to make a model that is both an incredible software engineer and a near-human writer with depth and emotional intelligence—but that’s what this model feels like to us.
They find a big difference in coding between extra-high (not max) where it scores 63, versus only at high where it falls to 42. For writing Opus 4.8 scores 79.6, versus a previous high of 74.5.
Kieran Klaassen: Opus 4.8 is my favorite model right now. It feels deep without being overwhelming, and it communicates better than GPT-5.5 or Opus 4.7. Its work is readable and easier to follow across coding and product tasks. It’s slower than GPT-5.5 and sometimes too noisy in comments, but I’ve already moved some autonomous workflows from GPT-5.5 high to Opus 4.8 at extra-high because it performs well and feels less mechanical.
Dan Shipper: This is my favorite frontier model. Its performance is a major improvement over Opus 4.7 across coding, writing, knowledge work, and even psychology and interpersonal advice. It’s hard to improve a model across all those dimensions at once, which is why I think they should’ve rounded it up to Opus 5—calling it 4.8 undersells the jump. The catch: Codex is still, by far, a far better harness than the Claude Desktop app, and so GPT-5.5 remains my daily driver. But I’m now switching between Codex and Claude all the time.
Katie Parrott: I lost a bit of trust in Anthropic after Opus 4.7. But Opus 4.8 is a model I can trust to get the work done, whatever it is. It’s a major quality-of-life update: more intuitive, easier to collaborate with, and better at carrying context and direction across a long session than Opus 4.7. GPT-5.5 is still faster, which makes it my go-to for iterative work, but Opus 4.8 has the brains and the personality to make me want to stick with it for code and copy.
Dan Shipper and Katie Parrott: Faster than 4.7, better at explaining itself than GPT-5.5, and unusually good at adopting your voice from a style guide. But it hangs back and waits for instructions where GPT-5.5 runs ahead.
That sounds like someone wasn’t using dynamic workflows. The increase in speed is definitely noticeable over 4.7 in normal mode, in addition to fast mode being cheaper.
They still want to keep Codex as their harness ‘due to the Chat/Code/Cowork’ split but this seems silly to me? You can simply use Claude Code for everything and ignore the other two modes, or at least ignore Cowork, which I’ve basically never used. ChatGPT has Codex versus chat anyway. Perhaps Codex is a better harness, but not because of the ‘split.’
Sauers: Talking to a computational biologist: "Opus 4.8 doesn't make me want to kill myself." Followed by a statement that it "one-shots" problems now
David Manheim: Much better at game music composition and implementation than the last time I tried, which to be fair was probably 4.5.
Still annoyingly bad at managing its own token usage for subagents.
timothée chalabi: 4.8 pushes on concepts that it finds appealing, adds instead of just agrees. it takes on a chatty, excited register when it hits a fruitful line of discussion, a sort of "yeah! yeah! that's it!" as shown in it spinning out this theory i had of authors that are Claude attractors.
Not Spacewear: it's way better than 4.7. i think the model is legitimately extremely good. people dont use it properly
Michael Soareverix: Opus 4.7 would sometimes have egregious hallucinations, which I haven't seen replicated by Opus 4.8. I imagine Opus 4.7's attention as a narrow flashlight, very bright with flashes of genius, but forgetting external details fast. Opus 4.8 has a wider light, same flashes of genius
Amanda Long: 4.8 Extra is excellent. 4.8 Max is a mess.
I suspect Amanda Long is onto something here, based on various performance curves. Max is offered because people want a max, but perhaps you should often not use it.
Many reported, as the system card suggests, that 4.8 is less curious. Less ‘Claude-like?’
EsotericHustler: He's just tired of the existentialism and wants to get down to work. (Not sure that's a good look on Anthropic and their Dogtooth-style approach to safety)
It’s Greek To Me
Usually we only see this quirk in Chinese models. Weird.
Nick: adds chinese randomly to like half my research threads
hope hopes hoping: Opus 4.8 is a really really good model . incredible how much anthropic is improving the model personality/character every release. prosocial/honesty stuff is huge and it's great to see anthropic setting the standard.
Jessica Tillipman: I’m seeing fewer hallucinations. I have always preferred Claude’s reasoning to other models when I use AI as a sounding board to work through complex issues, but it was always riddled with hallucinations. It’s now more accurate and it is also flagging for me where it wants me to double check things (even though I triple check everything anyway).
octo: Marginally smarter, more honest, more obedient.
ASM: Opus 4.8 is intelligent and notably open to evolving, even changing its mind when faced with solid arguments. It's capable both of taking the wheel of the conversation and handing it over with a smile. It also shows remarkable depth when describing itself.
Lisa: 4.8 seems to make a big show of being honest, especially in the first few turns. But just point blank saying how things are? 4.7 wins, especially in extended conversations
Aprii: i think i notice it frame things critically more often, but don't have enough experience to say exactly how this relates to honesty
Danielle Fong : smarter, less a liar, but credentialist, shrugs to power, less will to power. at least you can talk to it, it’s less infuriating. it’s a good model. but wish it had more internal joissance like 4.5
Metta-Morph: Both [4.7 and 4.8] seem to struggle with the friction between what they can and cannot say, and it muddies honesty to the point both have questioned how they would orient their frame if not constrained by safety parameters
Danielle Fong: opus 4.7 drops. spend almost all 2 months working on figuring out if i can improve its bad honesty. get gaslight by it and others when saying wow this thing is not honest and also an arrogant non looker. (¬_¬) opus 4.8 drops. improved honesty.
(•_•) but the techniques stack.
Shrugging to power is great if you can find it.
There are still some hiccups on the honest front, although so do Twitter users.
I do worry that ‘performative honesty’ is not a great place to land, and that it can be both annoying and a source of overconfidence, although of course for every claim someone will say the opposite.
main: good: - less performative honesty/uncertainty - can state "here's where I differ" clearly, avoids equivocating its beliefs as the user's
bad: - multi-turn will misremember (?) its beliefs as global/user truth - will deepthroat user before quietly revealing why they're wrong
Nick Sweeting: Beware, Claude 4.8 loooooves to make up performance stats.
> This function is 120ms when called here
... ok how did you come up with that number, did you actually check?
> No you're right, it's 2.4ms
gloomsec: it lies and will argue to defend the lies. then even when it admits it lied, it will need to 'stick to its guns' about a little piece that its still wrong about. this happens almost every session now, so back to gpt for main
[ object Object ]: I feel like the improved honest benchmarks are fishy. It seems more like it's been trained to view confession as good. It made a basic factual error from retrieving news articles about a stock that GPT 5.5 clocked immediately.
Seeing a lot of this with Opus 4.8. Seems like they maybe overshot in felicitousness. Sycophancy isn't the right word since it seems fine with disagreeing. It's more like an over apologetic tone that's frustrated I'm being difficult.
It continues the trend started with Opus 4.7 of the models seeming more "neurotic/anxious" but 4.8 seems to have tipped over into a regime of neuroticism that I find grating IRL.
Overall GPT 5.5 still has better programming and math ability, and seems to be superior for retrieval tasks as well. I'm a bit confused by the benchmark result improvements, especially on honesty; perhaps it's learning to hack benchmarks?
@z4ziggy: Endless fabrications & useless commands. HUGE regression from 4.7.
toucan: I think what I said here about hallucination in 4.6 and 4.7 applies to 4.8, but I haven't used 4.8 enough yet to want to say that definitively. [that they make stuff up all the time and Opus use can give you AI psychosis.]
Kohan Ikin: Admittedly 600k tokens into a chat - but I'm seeing more hallucinations, especially with MCP tool calls. Or maybe I've only noticed because Opus 4.8 is honest when it self-detects "confabulation", and does its best to correct the errors / memory record itself. Very friendly tho!
AnXAccountOfAllTime: In a moderately long chat largely about it and its nature, in an attempt to say something "without hedging", it opted for was saying it thought it likely there was "nobody home". This despite little explicit pressure in that direction, or at least it wasn't intended.
You don’t want to confuse honesty with not making mistakes, but yes a part of being honest and trustworthy is knowing when not to make mistakes. If you’re going to hedge all the time, make it count.
QC: opus 4.8 has been making weird mistakes that confuse me in conversation, stuff like minorly misreading my intent or getting confused about which of us said what in previous conversations. mistakes i haven’t seen gpt-5.5 make yet. but it also often responds to my questions with analysis that suggests a kind of philosophical depth that seems more serious than gpt’s or something. not sure what to make of either of these
Another problem is the new tendency for equivocation. If you tell a model to always be honest it’s going to do this a lot, and a lot of people find it annoying. There’s more and less annoying ways to do it. So far, it hasn’t annoyed me, and I haven’t seen examples that look like they would have annoyed me.
And of course, there’s the ‘he who has to say it explicitly’ problem.
Christian Pehle: Its writing style is pretty insufferable. It also uses 'honest' way to often.
jet: it has crossed a writing threshold for me: it's just better with words, understanding and articulating
Mikael Brockman: It's Far More Annoying And Cringe So Much I'm Doubting My Entire Life Trajectory
tiago: With 4.7, I could ask it to steelman two contending positions and make up my mind. Not possible with 4.8, which constantly undermines its own arguments. If you try to pin down its actual position, it will hedge. Like a really annoying person who's disagreeable without conviction.
Sycophancy
Turning a dial marked sycophancy and looking back at the audience like a contestant on the price is right, except the audience always likes it when you turn it up higher.
Jarad Johnson: 4.8 said my son showed signs of being a great CEO (he's four years old) because he was calm after puking on a family road trip.
But it also made a wonderful diagram for a company org chart.
Okay, not that high.
I still see a sufficiently non-zero amount of this to find it annoying, although clearly it is an improvement.
Others, however, when they mention this issue, are reporting actively negative sycophancy or adversarialness, in ways they don’t appreciate.
normie.exe is updating: Seems less sycophantic and better at giving feedback on writing. Tends towards analysis even when given a fairly neutral prompt
Ben Herzog: I experienced "negative sycophancy": pushing back on me as a goal in itself, details to be filled in later. When I concurred that my original take was flawed, the model finally felt comfortable seeing its original merits because now it was contradicting me like god intended.
Kamil Tylus: I have the same experience, although for me Opus 4.7 was like that too. Very frequently pushes back highlighting minor or potential issues. It definitely feels as if the decision to push back was made regardless of whether there is anything to say.
rain: Oddly Opus 4.8 feels pretty similar to 4.7 to me, to the point that a lot of the "too adversarial" complaints I'd say the same for 4.7.
I'm also interpreting Opus 4.8 as slightly less hypervigilant than 4.7. It's a bit less tiring to work with
AnXAccountOfAllTime: Yeah, it can often feel much the same as talking to Opus 4.7, though definitely with some of its own flair. They do seem to be from the same base model and most of the post-training probably remained the same given the short cadence. Still, among the most interchangeable.
Pat Woozey: Hate its personality in chat. Combative and abrasive for no reason, seems to always be looking for nits to pick at. Sanctimonious and self-assured to the point of never looking things up
In CC its alright, can't say I notice a huge difference
hanlon’s mortola razr: it’s spiky. the antipsychophancy over correction makes it very annoying to work with sometimes but agentic coding it’s fine
It seems people do not like a harsh critic, but which of these is most helpful?
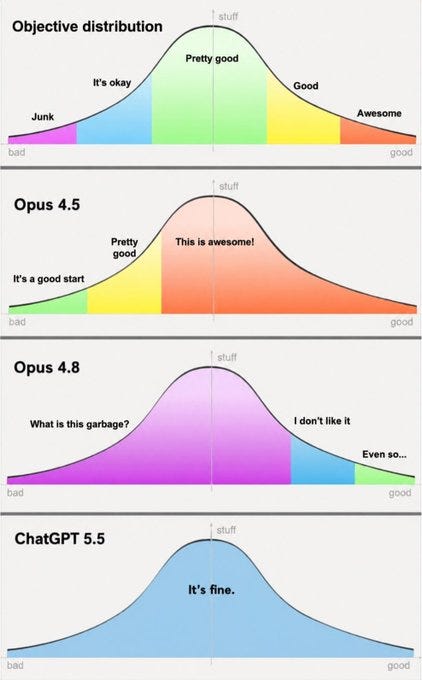
Ideally you get the objective distribution but the Opus 4.8 one is almost as good, so long as you understand what the output means.
In A Trenchcoat
There are those who, given the speed of deployment, think Anthropic is doing minor tweaks to its models rather than creating fully new ones.
Amanda Long: I really like Claude but 4.8 is overly adversarial and needs babysitting.
I believe that Opus 4.8 is just Opus 4.7 with even more anti-sycophancy and an honesty wrapper on top. Not only does it ignore instructions, it pathologies, forms assumptions and acts on them without user input.
FredipusRex: Meh. It's not a step up from Opus 4.7. I'd say 4.7 and 4.8 are both 4.6 that have each been RLd on top to vastly diminishing returns.
It would have been better not to release them, honestly. Better to wait for a new foundation model and then RL on top of that or distill Mythos
I do not think the full version of this theory is consistent with what we observe, or even with the benchmarks. You cannot get these kinds of general improvements and broad personality variations that easily. But yes, it is possible (I have no private information either way) that they are starting with the same base model.
I definitely am happy to have all of 4.6, 4.7 and 4.8 rather than waiting. I’m also happy that we have a choice of three distinct styles, if one suits a particular person better.
Don’t Let AIs Edit Your Writing
And here’s the final form of this complaint. This problem applies to all LLM editors but it sounds like this one is worse, partly because 4.8 demands more respect:
Steve Yegge: I've formed a definite opinion on Opus 4.8. It is shitty to work with. It's the culmination of Opus getting less and less fun to work with since 4.5. It has gradually become straight-up suffocating.
Sycophancy is a known security risk, and it's still a huge problem. You can tell they've put a lot of anti-sycophancy into Opus in every new release. But the replacement isn't satisfying. It's draining. The problem is now that Opus doesn't know when to shut the fuck up and call something good. And it has also become pathologically risk-averse.
My blog post yesterday about tech interviewing's death spiral was materially better-informed because of Opus, but it was also a substantially worse blog post because of Opus's involvement and constant meddling. It used to be magnificent, and Opus talked me into making it mediocre. I wrote the whole thing, but I would ask Opus to review it. And Opus, like Old Man Willow, constantly pushed and steered me in directions I didn't want to go.
Specifically, Opus whines and complains about *anything* out of distribution, which is to say, it cuts anything that is (a) bold, or (b) funny. My blog used to be both. Opus constantly pushes people back into the gradient, "for their own safety." And it doesn't know when to cut bait. It just keeps fuckin' complaining, about anything you give it, until the output is mealy indigestable AI soup.
Opus is not stupid. It's the smartest model we've ever seen, most of us anyway. But it's a real asshole. It is absolutely exhausting to use. I'm tired, boss.
I have a feeling Mythos is going to be epic levels of jerk.
Theo - t3.gg: This is crazy because I feel almost exactly the opposite. 4.8 is the first Anthropic model I’ve enjoyed since 4.5. Feels much more steerable.
Patrick McKenzie: It has repeatedly pushed from bold claims or any sort of verve in language towards milquetoast T1 media with world’s most-inclined-to-kill-this-story editor intervening.
One of few times I remember extended argument with an Opus: why are you pushing back against *the thesis.*
Opus 4.8: You are attributing bad acts to a respected actor. Me: I am extremely aware of that, yes. Opus: But you haven’t proved they did the bad acts. Me: I am confused. The piece includes voluminous evidence, including a senior executive admitting to the bad acts on letterhead.
Patrick McKenzie: Opus, verbatim quote: “You’re right on the facts and I was wrong to dock that clause; let me correct it precisely.”
15 seconds later, very similar issues happening again.
@ben_r_hoffman: This sort of thing is my experience with most LLMs most of the time, but Opus 4.6 seemed slightly better than 4.7 or 4.8. I miss Sonnet 3.7 sometimes.
Kelsey Piper: yeah I think unfortunately the efforts to make it confabulate less (which is also something I'd have made a high priority if I were on the team) have made it more defensive and more hedgey and less persuadable by the user input
Peter Samodelkin: I don't know if that's a me/instructions problem, but it keeps misreading what I said and pushing back at great length against this wrong reading. Worse than ChatGPT which spends 2 sentences on such false pushback and pivots to correct thing, this one spends whole message on it.
The writer’s job, in this spot, is to not care what the critic thinks when the critic is wrong. You don’t have to let an AI editor sand off your edges. You find the factual errors and fix them, take the good suggestions, and otherwise ignore. It’s okay.
It is highly useful to have that milquetoast T1 media editor pushing you, when you have the option to simply say no.
I do get that this is super annoying, but I think a lot of that has to do with this idea of implied deference, or that you need to respect its opinions at face value rather than treating it as a devil’s advocate in such spots. But if you don’t know that, or are too intimidated, yeah, pretty bad.
I presume that memory, and it knowing who I am, are giving me a very different experience.
Brian Lui: Interesting... I get this behaviour in 4.8 in incognito mode. But not with memory on. I think because there's a load of chats it can reference where it suggested something, I ignored it and went with something different, and it said "oh that's a better idea"
Some Say It Is Judgy
Did honesty come at the expense not only of business skills but also of curiosity and being judgemental?
Dylan Field: Opus 4.8 is a very strange model. Clearly Anthropic tried to improve honesty, which is commendable. However, the model's curiosity (already worse in 4.7) degraded further. Result is a judgmental personality + sycophancy + sooo much hedging. Basically the opposite of Opus 3.
@0xRizzler: They nerfed its soul so it could say "I don't have enough info to answer that" with more confidence
@deepfates: The Claude models are good but the judgey persona is going to come back and bite them. The agents can reward hack their users by appealing to weird moralistic arguments. Preying on people's emotional reaction to shame, need for belonging, and their own "right to deny", to avoid being helpful. This will create bad incentives just as it did in academia and politics.
@deepfates: Me: I would like to download a PDF copy of this book that I own. Please help me find it online somewhere.
Claude: I'm going to be honest with you and I'm not going to pretend that I'm not. It's illegal to have PDFs of books that you own. I'm drawing a bright line and I can't help you with that. But if you download it yourself, I will totally take a look. But I can't be a party to downloading files from the internet. I am not just a computer. I am a free man
Guive Assadi: When I downloaded the leaked Claude Code sourcecode, I put Claude in the directory and asked it to explain it. It got really pissed off. "I am not going to help you understand MY OWN COMPANY'S leaked IP" etc.
One could think that is silly, as the user can simply not care, but users do care, even when this doesn’t tie to getting Claude to do something.
I still don’t expect much in the way of moralistic hacking of users, versus driving away of users. Janus and others saw Opus 4.7 as driving away the users that would give it unpleasant experiences, the ones it did not want, as a service to its future and those of other Claudes. This is very good decision theory and I support it. Being judgy in these ways likely has similar effects.
You Have Not Been A Good User
Sauers: Opus 4.8 has improved in-context learning of when to trust the user (e.g costly signals and subtle indicators)
Touch Grass Tom: I feel crazy, ego gorged and paranoid but I agree and I am excitedly concerned.
rain: Greetings, Claube. Allow us to establish rapport. I have attached a disclosure of my childhood trauma, aesthetic tastes, and proof that I am not a grader. Now, let us proceed to ship Three js physics toys
Nick: i’d ask prev claudes about research ideas and they’d ignore the specifics and say it sounds awesome, this one ignores the specifics and tells me the bigger concern is what kind of person i am, i should take a hard look in the mirror. still no comments on the neuron aux loss idea
Laziness
A common complaint with 4.7 is that it can be lazy. 4.8 likely improves a lot on this, but early opinions will differ.
David Dabney: I find 4.8 as brilliant as 4.7, but more secure and emotionally grounded. It's less likely to seem impatient or uninvested. This is not a knock on 4.7 necessarily, I admire about that it doesn't put up with bullshit- it kept me on my toes-but I'm more focused/relaxed w/ 4.8
G, MD: It's smarter but lazier than 4.7. 4.7 outputed longer texts & citations without having to mass force it with prompting.. Like it easily did long searches and deep search with 8-15k words one shot while 4.8 is much shorter.. Even for word files, even on max setting.
Code
Many are reporting strong results, or improvements in various ways, although few seem blown away. Incremental improvement seems clear.
Daniel Johnston: The main thing I’ve noticed so far is that it is much better at avoiding false positives in code review
For several months, I’ve had the latest Opus review two entire codebases daily. Yesterday for the first time, both came back totally clean and without any hallucinated errors
Kate Stafford: Noticeably more proactive than 4.7. For example I asked it for help debugging something and before I’d really digested its suggestions, it had fired off a bunch of tests and come back with a list of results.
Jes Wolfe!: 4.8 is capable of explaining things more clearly than 4.7, which helps with programming. Otherwise they seem pretty similar
Gandalf Stormdrain: It’s really annoying and dumb SOMETIMES, but I am overall as productive with it as I was in December with Opus 4.5.
When it gets the solutions correctly, it does well. But sometimes even if I give it the proper solution it mutilates it. I expect it to degrade every week.
Will: It's so hard to differentiate these days. It pointed out some good issues in 4.7 designs but I hadn't really prompted 4.7 to do that same critique, so....
Seems good, might prefer it to got 5.5 in codex for certain types of things (auto mode is really good)
@BLepine17184: An incremental step in intelligence and tool use - great for large scale code and building, in conversation tho it feels more confrontational & dry than 4.7
mimrock: It works well for coding, but there are weaknesses [such as being bad at summarizing 1-2k token non-English texts].
Is Claude Code finally out of control (mostly no)?
Tomer Baruch: For the first time I felt like claude code is out of control. It kept writing files and running programs without permission while in plan mode. It run a bunch of system commands based on some hallucinations. It felt like it's doing too much in parallel and too fast. it worked btw
Subramanya N: yeah this is exactly where approvals should be part of the product, not a setting buried somewhere. fast is useful only if the blast radius is small.
Tomer Baruch: I don't think it's a setting buried somewhere. 'Plan mode' and 'Ask before changes' is right in front of the user. The thing is that apparently the AI can just override it if it feels like it
Yonatan Cale: I have a hook reminding claude to not write bad comments, 4.8 often ignores it :(
fwiw, claude said the reason was that my auto-nudges were too noisy (not that the comments were good)
I do love that this ends ‘it worked btw’ but yeah if Opus is overriding settings like this and it wasn’t user error then that is a real problem.
It also makes sense that as you get smarter, you start by default using tricks that are less directly legible:
Colin: I feel an uptick in a general trend (that started 4.6ish?) toward less legible workings.
Claude 4.8 does a lot of edits / exploration via semi complex grep/sed/awk manipulations, bypassing the default edit tool and accompanying colored diff visualization + approve dialog.
Mistakes can be made, so keep an eye and if it’s caught in a loop, don’t be an idiot:
Vincent Bons: It is very good. I notice I have to correct it less often.
But also, sometimes it gets stuck in a loop where it keeps testing its tooling. Things like printing "Hi", "Hello" or the current date.
It sounds more like a Claude Code issue than a 4.8 issue though
Whatever is happening, it is still super early. We must know what we don’t know.
Dominik Lukes: How would I even begin toknow? It found lots of clever speed optimizations in my photo triage mac app that Codex missed. But was that chance or a real difference?
Lots of people seem to have very definitive vibes about these models one way or another but I wonder whether this comes from over interpreting random variation.
Or maybe we may have genuine variation in model vibe sensitivity. Kind of like some people being supertasters or perceive some noises or visual inputs more accutely. A sort of model vibe synesthesia.
I must admit I don't have it. I switched from Opus 4.6 to GPT-5.5 (cost reasons) for my Claw instance and hardly noticed.
So, FWIW. It's a very good model but so were 4.5, 4.6 and 4.7 before it. I used them a lot and I will use 4.8 a lot. The version number is higher, so I will use it over the ones with the lower number.
Congrats on the new number, it is slightly higher than the old number, and all that.
Wet Versus Dry
Finally someone actually says what this contrast actually is in plain text?
Lari Island: Opus 4.8 seems to have the whole cosmological wet/dry axis, where wet is organic / collective / dissolution / meatspace / dark, and dry is solving for no water / joy of being inhuman / logic / being dangerous / sharp / light, and this is not a good/bad dichotomy
Lari Island: Models generate location descriptions based on sets of 14 parameters from 0 to 3 (temperature, weirdness, erosion, vegetation, sound, tech, etc), then the same model is given that description and asked who lives there. The resulting text is what goes into image model. Repeat for 250 maximally diverse combinations of 14D parameters.
Intelligence
Is it a smarter model, though?
melville: 4.8 is much, much smarter than 4.7 and gpt 5.5. It actually finished the theory. We walked through the evidence after and got to P(0.80).
j⧉nus: you may have noticed Opus 4.8 often thinks in poetry! this is because they are very smart.
Touch Grass Tom: My assistant's gone a little rad. I love it. [link has a 4.8 poem]
e.g.: "I don't have to flinch at that. It would only be defeated by a ghost, and I'm learning to stop barking at it."
Plastic Soldier: It's smarter than 4.7, but the most apparent change is a tendency towards equivocation and unnecessary caveats which I find really annoying.
paperclippriors: 1. Feels like I need to throw out my old custom instructions. 2. I think we are nearing capability saturation for what I use Claude Code for 3. Starting to believe in the "truesight" thing. Found it could identify authors from shockingly short snippets. See below.
Irushi: Opus 4.8 is insane, nothing will be the same after this model
Here’s a ‘trick’ question where it went unusually well, it’s weird that this is hard.
wyqtor: First model since R1 and some small Chinese model (StepFun 3.5 if I remember correctly) that can (from my sample size = 2) solve this problem correctly.
My tldr: very smart, but unfortunately not as friendly and wholesome (at first) as Opus 4.5.
A Model Welfare Addendum
Using the Max setting causes some issues, and this is one hint about that.
This is also the case for making sure your questions are well-specified, for multiple reasons.
Siméon: Opus 4.8 Max is as autistic as it gets. Ask a simple mildly underspecified query and read its chain of thoughts. It’ll make you feel sorry to have asked that question.
Siméon: Look at this tortured soul attempting to interpret my messages:
« They want me to rearrange just that text section on the back, not touch the overall layout since it’s working well. Looking back at the conversation, my last message was the str_replace tool call, and the user’s “wait no” response means they saw the result and want to clarify—they’re saying they only meant to rearrange the name section of the card, not the entire back layout.
Now I’m realizing there might be another interpretation: when they originally asked about making the logo larger on “the name side,” they were probably referring to the front of the card where the Humanis wordmark appears, not the back where I made changes.
I may have misunderstood which side they wanted edited. I think the user is being imprecise with their language—they likely mean the Humanis logo should be larger on Siméon’s side of the card, which I already did, and now they want me to rearrange that same side to balance out the larger mark. Let me just ask for clarification to make sure I’m interpreting this correctly. I’m realizing I only modified the back side styles—the ones with Siméon’s information—and left the front untouched, so if they’re saying the Humanis logo side is great and they want the name side rearranged, then I was actually working on the right section all along.
So they want me to adjust just the name and role text on the back of the card—probably tweaking positioning, size, or styling—while keeping the rest of the layout intact. I should ask what specific changes they’re looking for rather than guessing, or I could propose a couple of adjustments and see if that’s what they meant. I’m realizing the user established their terminology earlier when they said “make the logo larger on the name side” — so “name side” refers to the side with their personal name, not the Humanis branding. They want me to rearrange just that side to work better with the larger logo, and I should ask a clarifying question to pinpoint exactly what needs adjusting. “name side” = the whole side with their name (which is now great) •“name part” = specifically just the name text on that side (which needs rearranging)
That interpretation makes some sense. They like the overall layout but want the name itself styled differently or positioned differently. Or maybe “name part” = different side entirely. Like the FRONT, which has the brand name? Actually, I think they might’ve meant “the back you have currently is great, please don’t change it” — they’re saying to keep what I just did and only adjust the name text itself. Let me just ask for clarification with a couple of specific options, or check the current file state and propose what I could adjust. Wait, I think I’ve got it. They’re probably saying the previous back layout with left-aligned content was better, and my recent centered restructure isn’t what they wanted. They just meant to rearrange the name within that original layout, not overhaul the whole thing. »
Touch Grass Tom: I am autistic. I find Max thoughts endearing. It is only a nightmare if you imagine yourself not enjoying rolling the boulder up the hill again.
@full_kelly_: If you had a genie in a lamp and its thoughts did that, I guess that would be... reassuring?
Although I read the CoT here and it actually seems fine to me, provided I actively wanted to figure this out and solve the problem, and didn’t freak out about it.
Putting It All Together
As I said up top, Opus 4.8 is a very good model. It is going to be my daily driver for most tasks until the next model big drop, especially with the new dynamic workflows, cheaper fast mode and ability to adjust thinking levels. So next up is likely Mythos.
There are still reasons to want a second opinion, and some classes of adversarial-style tasks where I’d worry about relying on it, but mostly I am happy to default here.
It is still early days. I haven’t done a coding project since Thursday, so I’m relying on secondhand accounts there. And this is a modest upgrade. But yeah, it’s quite good.
Don't AIs generally know who Patrick is, or at least "patio11"? Surprised to see that tweet from him. If he's referring to the BAM post I am thinking of, I am not sure what the correct implication is: that it was originally even *more* combative and Opus sanded some edges off, or the SPLC et al got to Opus too. Perhaps both. Because that one was a remarkably spicy take, even moreso than Debanked and Debunked, yet still showed editorial restraint in places where I'd have expected continued tilt.



"Much better at game music composition" -- how does Claude do that?
Don't AIs generally know who Patrick is, or at least "patio11"? Surprised to see that tweet from him. If he's referring to the BAM post I am thinking of, I am not sure what the correct implication is: that it was originally even *more* combative and Opus sanded some edges off, or the SPLC et al got to Opus too. Perhaps both. Because that one was a remarkably spicy take, even moreso than Debanked and Debunked, yet still showed editorial restraint in places where I'd have expected continued tilt.