OpenAI Launches Superalignment Taskforce

In their announcement Introducing Superalignment, OpenAI committed 20% of secured compute and a new taskforce to solving the technical problem of aligning a superintelligence within four years. Cofounder and Chief Scientist Ilya Sutskever will co-lead the team with Head of Alignment Jan Leike.
This is a real and meaningful commitment of serious firepower. You love to see it. The announcement, dedication of resources and focus on the problem are all great. Especially the stated willingness to learn and modify the approach along the way.
The problem is that I remain deeply, deeply skeptical of the alignment plan. I don’t see how the plan makes the hard parts of the problem easier rather than harder.
I will begin with a close reading of the announcement and my own take on the plan on offer, then go through the reactions of others, including my take on Leike’s other statements about OpenAI’s alignment plan.
A Close Reading
Section: Introduction
Superintelligence will be the most impactful technology humanity has ever invented, and could help us solve many of the world’s most important problems. But the vast power of superintelligence could also be very dangerous, and could lead to the disempowerment of humanity or even human extinction.
While superintelligence seems far off now, we believe it could arrive this decade.
Here we focus on superintelligence rather than AGI to stress a much higher capability level. We have a lot of uncertainty over the speed of development of the technology over the next few years, so we choose to aim for the more difficult target to align a much more capable system.
Excellent. Love the ambition, admission of uncertainty and laying out that alignment of a superintelligent system is fundamentally different from and harder than aligning less intelligent AIs including current systems.
Managing these risks will require, among other things, new institutions for governance and solving the problem of superintelligence alignment: How do we ensure AI systems much smarter than humans follow human intent?
Excellent again. Superalignment is clearly defined and established as necessary for our survival. AI systems much smarter than humans must follow human intent. They also don’t (incorrectly) claim that it would be sufficient.
Bold mine here:
Currently, we don't have a solution for steering or controlling a potentially superintelligent AI, and preventing it from going rogue. Our current techniques for aligning AI, such as reinforcement learning from human feedback, rely on humans’ ability to supervise AI. But humans won’t be able to reliably supervise AI systems much smarter than us [B], and so our current alignment techniques will not scale to superintelligence. We need new scientific and technical breakthroughs.
[Note B: Other assumptions could also break down in the future, like favorable generalization properties during deployment or our models’ inability to successfully detect and undermine supervision during training.]
Yes, yes, yes. Thank you. Current solutions will not scale. Not ‘may’ not scale. Will not scale. Nor do we know what would work. Breakthroughs are required.
Note B is also helpful, I would say ‘will’ rather than may.
A+ introduction and framing of the problem. As good as could be hoped for.
Section: Our Approach
Our goal is to build a roughly human-level automated alignment researcher. We can then use vast amounts of compute to scale our efforts, and iteratively align superintelligence.
Oh no.
An human-level automated alignment researcher is an AGI, also a human-level AI capabilities researcher.
Alignment isn’t a narrow safe domain that can be isolated. The problem deeply encompasses general skills and knowledge.
It being an AGI is not quite automatically true, depending on one’s definition of both AGI and especially one’s definition of a human-level alignment researcher. Still seems true.
If the first stage in your plan for alignment of superintelligence involves building a general intelligence (AGI), what makes you think you’ll be able to align that first AGI? What makes you think you can hit the at best rather narrow window of human intelligence without undershooting (where it would not be useful) or overshooting (where we wouldn’t be able to align it, and might well not realize this and all die)? Given comparative advantages it is not clear ‘human-level’ exists at all here.
They do talk later about aligning this first AGI. This does not solve the hard problem of how a dumber thing can align a smarter thing. The plan is to do this in small steps so it isn’t too much smarter at each step, and do it at the speed of AI. Those steps help, and certainly help iterate and experiment. They don’t solve the hard problems.
I am deeply skeptical of such plans. Flaws in the alignment and understanding of each AGI likely get carried over in sequence. If you use A to align B to align C to align D, that is at best a large game of telephone. At each stage the one doing the aligning is at a disadvantage and things by default only get worse. The ‘alignment’ in question is not some mathematical property, it is an inscrutable squishy probabilistic sort of thing that is hard to measure even under good conditions, which you then are going to take out of its distribution, because involving an ASI makes the situation outside of distribution. We won’t be in a position to understand what is happening, let alone adopt a security mindset.
This is the opposite of their perspective, which is that ‘good enough’ alignment for the human-level is all you need. That seems very wrong to me. You would have to think you can somehow ‘recover’ the lost alignment later in the process.
I am not saying I am confident it could never possibly work - I have model uncertainty about that. Perhaps it is merely game-style impossible-level difficulty. I even notice myself going ‘oh I bet if you…’ quite a bit and I would love to take a shot some time.
When I talk to people about this plan I get a mix of reactions. One person working in AI responded positively at first, although that was due to assuming they meant a different less obviously doomed plan, they then realized ‘oh, they really do mean train an AI alignment researcher.’ Among those who understand alignment is important and hard, and who parse the post accurately in terms of announced intent, I didn’t hear much hope for the approach, but that sample is obviously biased.
To align the first automated alignment researcher, we will need to 1) develop a scalable training method, 2) validate the resulting model, and 3) stress test our entire alignment pipeline:
To provide a training signal on tasks that are difficult for humans to evaluate, we can leverage AI systems to assist evaluation of other AI systems (scalable oversight). In addition, we want to understand and control how our models generalize our oversight to tasks we can’t supervise (generalization).
To validate the alignment of our systems, we automate search for problematic behavior (robustness) and problematic internals (automated interpretability).
Finally, we can test our entire pipeline by deliberately training misaligned models, and confirming that our techniques detect the worst kinds of misalignments (adversarial testing).
A human-level AI researcher sounds like a dangerous system, even if it cannot do every human task. We likely encounter some superalignment problems on this first step. As basic examples: Punishing the detection of otherwise effective behaviors causes deception. Testing for interpretability can cause internal disguise and even ‘fooling oneself’ as it does in humans, cognition gets forced into whatever form you won’t detect, including outside what you think is the physical system. The system may display various power seeking or strategic behaviors as the best way to accomplish its goals. It will definitely start entirely changing its approach to many problems as its new capabilities enable harder approaches to become more effective, invalidating responses to previous methods. There is risk the system will be able to differentiate when it may be in a training or testing scenario and change its responses accordingly. And so on.
This also seems like the wrong threat model. You want to detect misalignments you weren’t training for, that are expressed in ways you didn’t anticipate, and that involve more powerful optimizations or more intelligence than that which is going into supervising the system. It seems easy to fool oneself with such tests into thinking it is safe to proceed, then all your systems break down.
Similarly, if you create automated systems to search for problematic behaviors or internals, what you are doing is selecting against whatever problems and presentations of those problems your methods are able to detect. And once again, you are trying to detect upwards in the intelligence or capabilities chain. The more fine grained and precise your responses to such discoveries are, the more you are teaching the system to work around your detection methods, including in ways we can’t anticipate and also ways that we can.
The way that such automated systems work, I would expect AIs to be at comparative disadvantage in detecting distinct manifestations of misalignment, compared to humans. Detecting when something is a bit off or suspicious, or even suspiciously different, is a creative task and one of our relative strengths - we humans are optimized especially hard to be effective on such tasks. It is also exactly the type of thing that one should expect would be lost during the game of telephone. The ‘human-level AI researcher’ will get super-human at detecting future problems that look like past problems, while being sub-human at detecting future problems that are different. That is not what we want. Nor is creating a super-human alignment researcher in step one, because by construction we haven’t solved super-alignment at that step.
Adversarial testing seems great for existing non-dangerous systems. The danger is that we will not confidently know when we transition to testing on dangerous systems.
I might summarize this approach as amplifying the difficulty of the hard problems, or at least not solving them, and instead working on relatively easy problems in the hopes they enable working on the hard ones. That makes sense if and only if the easy problems are a bottleneck that enables the solving of the hard problems. Which is a plausible hypothesis, if it lets us try many more hard problem solutions much faster and better.
I also worry a lot that this is capabilities in disguise, whether or not there is any intent for that to happen. Building a human-level alignment researcher sounds a lot like building a human-level intelligence, exactly the thing that would most advance capabilities, in exactly the area where it would be most dangerous. One more than a little implies the other. Are we sure that is not the important part of what is happening here?
Another potential defense is that one could say that all solutions to the problem involve impossible steps, and have reasons they would never work. So perhaps one can see these impossible obstacles as the least impossible option. Indeed, if I squint I can sort of see how one could possibly address these questions - if one realizes that they require shutting up and doing the impossible, and is willing to also solve additional unnoticed impossible problems along the way.
Does that mean Ilya and his famously relentless optimism is the perfect choice, or exactly the wrong choice? That is a great question. One wants the special kind of insane optimism that relentlessly pursues solutions without fooling oneself about what it would take for a solution to work.
I would also note that this seems like the place OpenAI has comparative advantage. If the solution to alignment looks like this, then the skills and resources at OpenAI’s disposal are uniquely qualified to find that solution. If the solution looks very different, that is much less likely.
If I was going to pursue this kind of iterated agenda, my first step would be to try to get a stupider less capable system to align a smarter more capable system.
We expect our research priorities will evolve substantially as we learn more about the problem and we’ll likely add entirely new research areas. We are planning to share more on our roadmap in the future.
This last paragraph gives hope. Even if one’s original plan cannot possibly work, a willingness to pivot and expand and notice failure or inadequacy means you are still in the game.
All the new details here about the strategy are net positives, making the plan more likely to succeed, as is the plan to adjust the plan. Given what we already knew about OpenAI’s approach to alignment, the core plan as a concept comes as no surprise. That plan will then be given a ton of resources, relatively good details and an explicit acknowledgment that additions and adjustments will be necessary.
So if we take the general shape of the approach as a given, once again very high marks. Again, as good as could be expected.
Section: The New Team
We are assembling a team of top machine learning researchers and engineers to work on this problem.
We are dedicating 20% of the compute we’ve secured to date over the next four years to solving the problem of superintelligence alignment. Our chief basic research bet is our new Superalignment team, but getting this right is critical to achieve our mission and we expect many teams to contribute, from developing new methods to scaling them up to deployment.
Dedicating 20% of compute secured to date is different from 20% of forward looking compute, given the inevitable growth in available compute. It is still an amazingly high level of compute, far in excess of anyone’s expectations. There will also be lots of hires explicitly for the new Superalignment team. We will likely need to then go bigger, but still. Bravo.
While this is an incredibly ambitious goal and we’re not guaranteed to succeed, we are optimistic that a focused, concerted effort can solve this problem [including providing evidence that the problem has been solved that convinces the ML community.] There are many ideas that have shown promise in preliminary experiments, we have increasingly useful metrics for progress, and we can use today’s models to study many of these problems empirically.
I once again worry that there will be too much extrapolation of data from existing models to what will work on future superintelligent models. I also would like to see more explicit reckoning with what would happen if the effort fails. There is absolutely no shame in failing or taking longer to solve this, but if you know you don’t have a solution, what will you do?
Ilya Sutskever (cofounder and Chief Scientist of OpenAI) has made this his core research focus, and will be co-leading the team with Jan Leike (Head of Alignment). Joining the team are researchers and engineers from our previous alignment team, as well as researchers from other teams across the company.
We’re also looking for outstanding new researchers and engineers to join this effort. Superintelligence alignment is fundamentally a machine learning problem, and we think great machine learning experts—even if they’re not already working on alignment—will be critical to solving it.
Considering Joining the UK Taskforce
Before considering the option of joining the OpenAI Superalignment Taskforce, take this opportunity to consider joining the UK Foundation Model Taskforce.
The UK Foundation Model Taskforce is a 100 million pound effort, led by Ian Hogarth who wrote the Financial Times Op-Ed headlined “We must slow down the race to God-like AI.” They are highly talent constrained at the moment, what they need most are experienced people who can help them hit the ground running. If you are a good fit for that, I would make that your top priority.
You can reach out to them using this Google Form here.
Considering Joining the OpenAI Taskforce
What about if the UK taskforce is not a good fit, but the OpenAI one might be?
If you are currently working on capabilities and want to instead help solve the problem and build a safety culture, the Superalignment team seems like an excellent chance to pivot to (super?) alignment work without making sacrifices on compensation or interestingness or available resources. Compensation for the new team is similar to that of other engineers.
One of the biggest failures of OpenAI, as far as I can tell, is that OpenAI has failed to build that culture of safety. This new initiate could be an opportunity to cultivate such a culture. If I was hiring for the team, I’d want a strong focus on people who fully bought into the difficulty and dangers of the problem, and also the second best time to do that for the rest of your hiring will always be right now.
If your alternative considerations are instead other alignment work, what about then? Opinion was mostly positive when I asked.
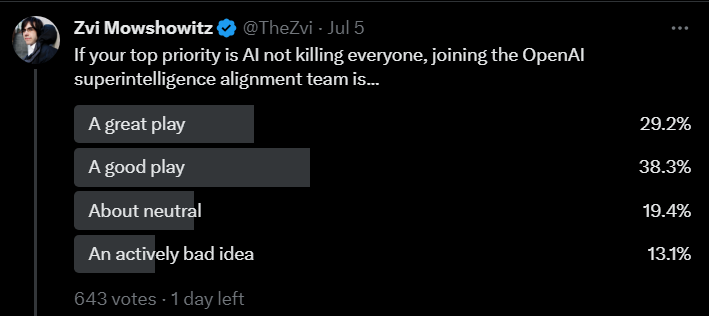
I think it depends a lot on your alternatives, skills and comparative advantage, and also if I was considering this I would do a much deeper dive and expect to update a lot one way or another. The more you believe you can be good at building a good culture and steering things towards good plans and away from bad ones, and the more you are confident you can stand up to pressure, or need this level of compensation for whatever reason, the more excited I would be to join. Also, of course, if your alignment ideas really do require tons of compute, there’s that.
On the other side, the more you are capable of a leadership position or running your own operation, the more you don’t want to be part of this kind of large structure, the more you worry about being able to stand firm under pressure and advocate for what you believe, or what you want to do can be done on the outside, the more I’d look at other options.
I do think that this task force crosses the threshold for me, where if you tell me ‘I asked a lot of questions and got all the right answers, and I think this is the right thing for me to do’ I would likely believe you. One must still be cautious, and prepared at any time to take a stand and if necessary quit.
Final Section: Sharing the Bounty
We plan to share the fruits of this effort broadly and view contributing to alignment and safety of non-OpenAI models as an important part of our work.
Excellent. The suggestion to publish is a strong indication that this is indeed intended as real notkilleveryoneism work, rather than commercially profitable work. The flip side is that if that does not turn out to be true, there is much here that could be accelerationist. Knowing what to hold back and what not to will be difficult. One hope is that commercial interests may mostly align with the right answer.
This new team’s work is in addition to existing work at OpenAI aimed at improving the safety of current models like ChatGPT, as well as understanding and mitigating other risks from AI such as misuse, economic disruption, disinformation, bias and discrimination, addiction and overreliance, and others. While this new team will focus on the machine learning challenges of aligning superintelligent AI systems with human intent, there are related sociotechnical problems on which we are actively engaging with interdisciplinary experts to make sure our technical solutions consider broader human and societal concerns.
Yes, exactly. There is no conflict here. Some people should work on mitigating mundane harms like those listed above, while others are dedicated to the hard problem. One need not ‘distract’ from the other, and I expect a lot of mundane mitigation spending purely for self-interested profit maximizing reasons.
More Technical Detail from Jan Leike
Jan Leike engaged via a few threads, well-considered and interesting throughout, as discussed later. Here was his announcement thread for the announcement:
Jan Leike: Our new goal is to solve alignment of superintelligence within the next 4 years. OpenAI is committing 20% of its compute to date towards this goal. Join us in researching how to best spend this compute to solve the problem!
Alignment is fundamentally a machine learning problem, and we need the world's best ML talent to solve it. We're looking for engineers, researchers, and research managers. If this could be you, please apply.
Why 4 years? It's a very ambitious goal, and we might not succeed. But I'm optimistic that it can be done. There is a lot of uncertainty how much time we'll have, but the technology might develop very quickly over the next few years. I'd rather have alignment be solved too soon.
There is great need for more ML talent working on alignment, but I disagree that alignment is fundamentally a machine learning problem. It is fundamentally a complex multidisciplinary problem, executed largely in machine learning, and a diversity of other skills and talents are also key bottlenecks.
I do like the attitude on the timeline of asking, essentially, ‘why not?’ Ambitious goals like this can be helpful. If it takes 6 years instead, so what? Maybe this made it 6 rather than 7.
20% of compute is not a small amount and I'm very impressed that OpenAI is willing to allocate resources at this scale. It's the largest investment in alignment ever made, and it's probably more than humanity has spent on alignment research in total so far.
I'm super excited to be co-leading the team together with @ilyasut. Most of our previous alignment team has joined the new superalignment team, and we're welcoming many new people from OpenAI and externally. I feel very lucky to get to work with so many super talented people!
He also noted this:
Eliezer Yudkowsky: How will you tell if you're failing, or not making progress fast enough?
Jan Leike: We'll stare at the empirical data as it's coming in:
1. We can measure progress locally on various parts of our research roadmap (e.g. for scalable oversight)
2. We can see how well alignment of GPT-5 will go
3. We'll monitor closely how quickly the tech develops
payraw.eth: hold on GPT-5 requires superintelligence level alignment?
Jan Leike: I don't think so, but GPT-5 will be more capable than GPT-4 – so how aligned it is will be an indicator whether we're making progress.
If you use current-model alignment to measure superalignment, that is fatal. The whole reason for the project is that progress on aligning GPT-5 might not indicate actual progress on aligning a superintelligence, or a human-level alignment researcher. It is even possible that some techniques that work in the end don’t work on GPT-5 (or don’t work on GPT-4, or 3.5…) because the systems aren’t smart or capable enough to allow them to work.
For example, Constitutional AI (which I expect to totally not work for superintelligence and also importantly not for human-level intelligence, to be clear) should only work (to the extent it works) within the window where the system is capable enough to execute the procedure, but not capable enough to route around it. That’s one reason you need so much compute to work on some approaches, and access to the best models.
The part where capabilities advances are compared to the rate of alignment progress makes sense either way. The stronger your capabilities, the more you need to ask whether to halt creating more of them. There is still the danger of unexpectedly very large jumps.
Leike also talked substantive detail in the comments of the LessWrong linkpost to the announcement.
[RRM = Recursive Reward Modeling, IDA = Iterated Distillation and Amplification, HCH = Humans Consulting HCH.]
Wei Dei: I've been trying to understand (catch up with) the current alignment research landscape, and this seems like a good opportunity to ask some questions.
This post links to https://openai.com/research/critiques which seems to be a continuation of Geoffrey Irving et el's Debate and Jan Leike et el's recursive reward modeling both of which are in turn closely related to Paul Christiano's IDA, so that seems to be the main alignment approach that OpenAI will explore in the near future. Is this basically correct?
From a distance (judging from posts on the Alignment Forum and what various people publicly describe themselves as working on) it looks like research interest in Debate and IDA (outside of OpenAI) has waned a lot over the last 3 years, which seems to coincide with the publication of Obfuscated Arguments Problem which applies to Debate and also to IDA (although the latter result appears to not have been published), making me think that this problem made people less optimistic about IDA/Debate. Is this also basically correct?
Alternatively or in addition (this just occurred to me), maybe people switched away from IDA/Debate because they're being worked on inside OpenAI (and probably DeepMind where Geoffrey Irving currently works) and they want to focus on more neglected ideas?
Jan Leike: Yes, we are currently planning continue to pursue these directions for scalable oversight. My current best guess is that scalable oversight will do a lot of the heavy lifting for aligning roughly human-level alignment research models (by creating very precise training signals), but not all of it. Easy-to-hard generalization, (automated) interpretability, adversarial training + testing will also be core pieces, but I expect we'll add more over time.
I don't really understand why many people updated so heavily on the obfuscated arguments problem; I don't think there was ever good reason to believe that IDA/debate/RRM would scale indefinitely and I personally don't think that problem will be a big blocker for a while for some of the tasks that we're most interested in (alignment research). My understanding is that many people at DeepMind and Anthropic [who] remain optimistic about debate variants have been running a number of preliminary experiments (see e.g. this Anthropic paper).
My best guess for the reason why you haven't heard much about it is that people weren't that interested in running on more toy tasks or doing more human-only experiments and LLMs haven't been good enough to do much beyond critique-writing (we tried this a little bit in the early days of GPT-4). Most people who've been working on this recently don't really post much on LW/AF.
There’s a lot here. The obfuscated arguments problem is an example of the kind of thing that gets much trickier when you attempt amplification, if I am understanding everything correctly.
As I understand Leike’s response, he’s acknowledging that once the systems move sufficiently beyond human-level, the entire class of iterated or debate-based strategies will fail. The good news is that we can realize this, and that they might plausibly hold for human level, I presume because there is no need for an extended amplification loop, and the unamplified tools and humans are still useful checks. This helps justify why one might aim for human-level, if one thinks that the lethalities beyond human-level mostly would then not apply quite yet.
Paul Christiano also responds: 1. I think OpenAI is also exploring work on interpretability and on easy-to-hard generalization. I also think that the way Jan is trying to get safety for RRM is fairly different for the argument for correctness of IDA (e.g. it doesn't depend on goodness of HCH, and instead relies on some claims about offense-defense between teams of weak agents and strong agents), even though they both involve decomposing tasks and iteratively training smarter models.
2. I think it's unlikely debate or IDA will scale up indefinitely without major conceptual progress (which is what I'm focusing on), and obfuscated arguments are a big part of the obstacle. But there's not much indication yet that it's a practical problem for aligning modestly superhuman systems (while at the same time I think research on decomposition and debate has mostly engaged with more boring practical issues). I don't think obfuscated arguments have been a major part of most people's research prioritization.
3. I think many people are actively working on decomposition-focused approaches. I think it's a core part of the default approach to prosaic AI alignment at all the labs, and if anything is feeling even more salient these days as something that's likely to be an important ingredient. I think it makes sense to emphasize it less for research outside of labs, since it benefits quite a lot from scale (and indeed my main regret here is that working on this for GPT-3 was premature). There is a further question of whether alignment people need to work on decomposition/debate or should just leave it to capabilities people---the core ingredient is finding a way to turn compute into better intelligence without compromising alignment, and that's naturally something that is interesting to everyone. I still think that exactly how good we are at this is one of the major drivers for whether the AI kills us, and therefore is a reasonable topic for alignment people to push on sooner and harder than it would otherwise happen, but I think that's a reasonable topic for controversy.
If something is a major driver on whether AI kills us, then definitely don’t leave it to the labs, much better to risk doing redundant work. And ‘how to turn compute into better intelligence without compromising alignment’ sounds very much like it could be such an important question. If it’s a coherent thought that makes sense in context, it’s very important.
Wei Dei follows up: Thanks for this helpful explanation.
it doesn’t depend on goodness of HCH, and instead relies on some claims about offense-defense between teams of weak agents and strong agents
Can you point me to the original claims? While trying to find it myself, I came across Alignment Optimism which seems to be the most up to date explanation of why Jan thinks his approach will work (and which also contains his views on the obfuscated arguments problem and how RRM relates to IDA, so should be a good resource for me to read more carefully). Are you perhaps referring to the section "Evaluation is easier than generation"?
Do you have any major disagreements with what's in Jan's post? (It doesn't look like you publicly commented on either Jan's substack or his AIAF link post.)
Paul Christiano: I don't think I disagree with many of the claims in Jan's post, generally I think his high level points are correct.
He lists a lot of things as "reasons for optimism" that I wouldn't consider positive updates (e.g. stuff working that I would strongly expect to work) and doesn't list the analogous reasons for pessimism (e.g. stuff that hasn't worked well yet). Similarly I'm not sure conviction in language models is a good thing but it may depend on your priors.
One potential substantive disagreement with Jan's position is that I'm somewhat more scared of AI systems evaluating the consequences of each other's actions and therefore more interested in trying to evaluate proposed actions on paper (rather than needing to run them to see what happens). That is, I'm more interested in "process-based" supervision and decoupled evaluation, whereas my understanding is that Jan sees a larger role for systems doing things like carrying out experiments with evaluation of results in the same way that we'd evaluate employee's output.
(This is related to the difference between IDA and RRM that I mentioned above. I'm actually not sure about Jan's all-things-considered position, and I think this piece is a bit agnostic on this question. I'll return to this question below.)
I am very much with Christiano on all the criticisms here, especially skepticism of AI evaluations of other AIs via results. The sense of doom there seems overwhelming.
The pattern of ‘individually the statements could be reasonable but the optimism bias is clear if you zoom out’ is definitely an issue. That’s on key way you can fool yourself.
Paul Christiano: The basic tension here is that if you evaluate proposed actions you easily lose competitiveness (since AI systems will learn things overseers don't know about the consequences of different possible actions) whereas if you evaluate outcomes then you are more likely to have an abrupt takeover where AI systems grab control of sensors / the reward channel / their own computers (since that will lead to the highest reward). A subtle related point is that if you have a big competitiveness gap from process-based feedback, then you may also be running an elevated risk from deceptive alignment (since it indicates that your model understands things about the world that you don't).
Very well said. It is a huge alignment tax if the supervisor needs to understand everything that is going on, unless the supervisor is as on the ball as the system being supervised. So there’s a big gain in results if you instead judge by results, while not understanding what is going on and being fine with that, which is a well-known excellent way to lose control of the situation.
The good news is that we pay exactly this huge alignment tax all the time with humans. It plausibly costs us most of the potential productivity of many of our most capable people. We often decide the alternative is worse. We might do so again.
Paul Christiano: In practice I don't think either of those issues (competitiveness or takeover risk) is a huge issue right now. I think process-based feedback is pretty much competitive in most domains, but the gap could grow quickly as AI systems improve (depending on how well our techniques work). On the other side, I think that takeover risks will be small in the near future, and it is very plausible that you can get huge amounts of research out of AI systems before takeover is a significant risk. That said I do think eventually that risk will become large and so we will need to turn to something else: new breakthroughs, process-based feedback, or fortunate facts about generalization.
I think that if you are trying to get huge amounts of research out of the AIs it is at minimum very hard to see how that happens without substantial takeover risk, or at least risk of a path that ‘bakes in’ such risk later. Very hard is not impossible.
As I mentioned, I'm actually not sure what Jan's current take on this is, or exactly what view he is expressing in this piece. He says:
Jan Leike: Another important open question is how much easier evaluation is if you can’t rely on feedback signals from the real world. For example, is evaluation of a piece of code easier than writing it, even if you’re not allowed to run it? If we’re worried that our AI systems are writing code that might contain trojans and sandbox-breaking code, then we can’t run it to “see what happens” before we’ve reviewed it carefully.
I expect the answer is ‘it depends.’ Some types of code, solutions to some problems, are like math or involve getting technical details right: Hard to figure out and easy to check. Others are harder to check, and how you write the code on many levels helps determine the answers, including whether the code is intentionally obfuscated. In practice, if you are relying on being able to verify the code easier than the cost of writing it, without being able to run it, then at best you are going to pay a ginormous alignment tax - only writing code that can be fully provably understood by the evaluator.
Paul Christiano: I'm not sure where he comes down on whether we should use feedback signals from the real world, and if so what kinds of precaution we should take to avoid takeover and how long we should expect them to hold up. I think both halves of this are just important open questions---will we need real world feedback to evaluate AI outcomes? In what cases will we be able to do so safely? If Jan is also just very unsure about both of these questions then we may be on the same page.
Also I don’t expect ‘run the code’ to be that helpful in testing it in many cases, as the problem could easily be conditional or lie dormant or be an affordance that you don’t understand is an affordance until it is used. Or there could be affordances that appear when you spin up enough related copies that can collaborate. In general, there seems to be an implicit lack of appreciation going around of what it means for something to be smarter, and come up with ways to outsmart you that you can’t anticipate.
Paul Christiano: I generally hope that OpenAI can have strong evaluations of takeover risk (including: understanding their AI's capabilities, whether their AI may try to take over, and their own security against takeover attempts). If so, then questions about the safety of outcomes-based feedback can probably be settled empirically and the community can take an "all of the above" approach. In this case all of the above is particularly easy since everything is sitting on the same spectrum. A realistic system is likely to involve some messy combination of outcomes-based and process-based supervision, we'll just be adjusting dials in response to evidence about what works and what is risky.
Can you hear Eliezer Yudkowsky screaming at the idea of throwing together a messy combination of methods and then messing with their dials in the hopes it all works out? Because I am rather confident Eliezer Yudkowsky is screaming at the idea of throwing together a messy combination of methods and then messing with their dials in the hopes it all works out, and I do not think he is wrong. This is not what ‘get it right on the first try’ looks like, this is the theory that you do not in fact have to do that, in contrast to the realization at the top of a break point where your techniques largely stop working.
This seems like a good time to go back and read Jan Leike’s post referenced multiple times above, ‘Why I’m optimistic about our alignment approach,’ since that approach hasn’t changed much.
It seems worth quoting his argument in 1.1 in full, ‘the AI tech tree is looking favorably:’
A few years ago it looked like the path to AGI was by training deep RL agents from scratch in a wide range of games and multi-agent environments. These agents would be aligned to maximizing simple score functions such as survival and winning games and wouldn’t know much about human values. Aligning the resulting agents would be a lot of effort: not only do we have to create a human-aligned objective function from scratch, we’d likely also need to instill actually new capabilities into the agents like understanding human society, what humans care about, and how humans think.
Large language models (LLMs) make this a lot easier: they come preloaded with a lot of humanity’s knowledge, including detailed knowledge about human preferences and values. Out of the box they aren’t agents who are trying to pursue their own goals in the world and and their objective functions are quite malleable. For example, they are surprisingly easy to train to behave more nicely.
Paul Christiano expressed doubt about whether this change is good. I am even more skeptical. LLMs give you messy imprecise versions of a lot of this stuff and everything else they give you, much easier than you’d get that otherwise. They make doing anything precise damn near impossible. So is that helpful here, or is that profoundly unhelpful? Also you can see various ways the deck is being stacked here.
I’d pull this quote out, it seems important:
While in theory learning human values shouldn’t actually be fundamentally different from learning to recognize a cat in an image, it’s not clear that optimizing against these fuzzy goals works well in practice.
I do not think these two things are as similar as that, and worry this is an important conceptual error.
Section two is called ‘a more modest goal’ which refers to training an AI that can then do further research, the advantages he lists then include that the model doesn’t have to be fully aligned, doesn’t need agency or persistent memory, and the alignment tax matters less. None of this addresses the reasons why ‘alignment researcher’ is an unusually perilous place to point your AI, and none of it seemed new.
Section three is that evaluation is easier than generation. Evidence and examples includes NP != P, classical sports and games, consumer products, most jobs and academic research. I am not convinced.
NP != P is probably true, however this requires the context of a formally specified problem with a defined objective, and the solution either working or not working rather than understanding all its details.
There are some games that do not retain complex state, including most of the standard sports. This creates spots where evaluation becomes easy. Between those times, evaluation may not be so easy, and one must beware confusion of physical implementation abilities versus mental difficulty. The idea that evaluation is easier than generation in chess is not obvious, they are very close to the same skill. In Magic: The Gathering, there are many situations in which it is devilishly hard to know ‘where you are at’ and one can go back and forth on decisions made for hours - and again, one can say that evaluation implies generation in this context. Yes, in both examples here and many other games, you can do an easy evaluation easily and tell if one side is dominating in the most obvious ways, but it often won’t help tell you who is winning expert games.
There are some aspects of consumer products that are obviously much easier to evaluate than they are to generate, but often it is far easier to create a product, or optimize it for sales or engagement, than it is to evaluate what will be the impacts of that product, and whether it is good or bad in various ways beyond initial experience. Is it easier to build Twitter, or evaluate Twitter’s effects on its users and society generally? Is it easier to grow an apple, or to know the health effects of eating one?
Most jobs once again offer ‘easy easy’ evaluations of performance. Getting a fully accurate one, that takes into account important details and longer term implications, is sometimes much harder. When all you have to do is ask ‘did it work?’ and measure someone’s sales or production or what not, then that can be relatively easy. How many jobs are like that? I don’t know, but I do know those are not the places I am worried about.
Academic research is described as ‘notoriously difficult to evaluate.’ Then it is compared to the time required to do the research, but that’s mostly about things are not cognitive barriers to generation - even the best scientist producing a paper will be spending most of their time on operations, on paperwork, on writing up results, on various actions that are necessary but not part of the relevant comparison. It is not important here that it takes 1000 hours to write versus 10 hours to evaluate - compare this to ‘it takes 20 hours to paint the house a new color, and 20 seconds to decide if the color is a good one’ but almost all of those 20 hours were spent on physical painting and other things that did not involve choosing the color. Same thing here. The 77% agreement rate on reject/accept for written papers quoted is actually pretty terrible. That means at least one in eight evaluations is wrong in its first bit of data.
In particular, I would stress that the situations in which evaluation is easy are not the places we are worried about our evaluations, or the ways in which we worry our evaluations would go wrong. If 90% of the time evaluation is easy and 10% of the time it is hard - or 99% and 1% - guess which tasks will involve a principal-agent problem or potential AI deception. A mix of relative difficulties that is mostly favorable means the relative difficulty is unfavorable. Note the objection later, where Leike spells out that obfuscated arguments shows there are important situations where evaluation is the harder task. Leike is displaying exactly the opposite of security mindset.
Section four seems to be saying yay for proxy metrics and iterated optimizations on them, and yes optimizing for a proxy metric is easier but the argument is not made here that the proxy metrics are good enough, and there’s every reason to think Goodhart’s Law is going to absolutely murder us here and that the things we optimize successfully will still be waiting to break down when it counts.
A bunch of that seems worth fleshing out more carefully at some point.
The response to the objection ‘isn’t automating alignment work too similar to aligning capabilities work?’ starts with:
Automated ML research will happen anyway. It seems incredibly hard to believe that ML researchers won’t think of doing this as soon as it becomes feasible.
Wait, what? That is not an argument in favor of optimism! That is an argument in favor of deep pessimism. You are saying that the thing you are doing will be used to enhance capabilities as soon as it is feasible. So don’t make it feasible?
Next up we have the argument that this makes alignment and capabilities work fungible, which once again should kind of alarm you when you combine it with that first point, no?
In general, everyone who is developing AGI has an incentive to make it aligned with them. This means they’d be incentivized to allocate resources towards alignment and thus the easier we can make it to do this, the more likely it is for them to follow these incentives.
There is a very deeply obvious and commonly known externality problem with relying on the incentives here. If your lab develops AGI, you get the benefits, including the benefits of getting there first. If that AGI kills everyone, obviously you will try to avoid that, that kills you too, but you only bear a small fraction of the downside costs. If your plan is to count on self-interest to ensure proper investment in alignment research, you have a many-order-of-magnitude incentive error that will result in a massively inadequate investment in alignment even if everything else goes well. Other factors I can think of only make this worse.
The third response is that you can focus on tasks differentially useful to alignment research. I mean, yes, you can, but we’ve already explained why the collective ‘you’ probably won’t. The whole objection is that you can’t lock this decision in.
The fourth response is better, and does offer some hope.
ML progress is largely driven by compute, not research
This sentiment has been famously cast as “The Bitter Lesson.” Past trends indicate that compute usage in AI doubled about every 3.4 months while efficiency gains doubled only every 16 months. Roughly, compute usage is mainly driven by compute while efficiency is driven by research. This means compute increase dominated ML progress historically.
But I don’t weigh this argument very highly because I’m not sure if this trend will continue, and there is always the possibility to discover a “transformer-killer” architecture or something like this.
There is definitely the danger this relationship fails to hold, and the danger that even ordinary unlocked algorithmic improvements are already too much. If you can build a human-level researcher, and you’re somehow not in the danger zone yet, you are damn close, even one or two additional orders of magnitude efficiency gain is scary as hell on every level. Thus, I think this has some value, but agree with Leike that counting on it would be highly unwise.
Next up he does tackle the big objection, that in order to do good alignment work one has to be capable enough to be dangerous. In particular the focus is on having to be capable of consequentialist reasoning, although I’d widen the focus beyond that.
Here is his response.
Trying to model the thought processes of systems much smarter than you is pretty hopeless. However, if we understand our systems’ incentives (i.e. reward/loss functions) we can still make meaningful statements about what they’ll try to do. Reasoning about incentives alone wouldn’t avoid inner misalignment problems (see below), so need to account for them explicitly.
You can say a nonzero amount but how they will ‘try to do’ the thing could involve things you cannot anticipate. If your plan is to base your strategy on providing the right reward function and incentives, you have not in any way addressed any of the involved lethalities or hard problems. How does it help me that Magnus Carlson is going to ‘try and checkmate me’ except on an unconstrained playing field? And that’s agreeing to ignore inner alignment issues.
And wait, I thought the whole point was not to build something much smarter than us, exactly because we couldn’t align that yet.
It seems clear that a much weaker system can help us on our kind of alignment research and if we’re right, we will be able to demonstrate this empirically with relatively mundane AI systems that aren’t suffering from potentially catastrophic misalignment problems.
This is the better answer, that we indeed won’t be building something smarter than us, and that will still help due to scale and speed and so on. Then it is a fact question, how much help can we get out of systems like that.
A hypothetical example of a pretty safe AI system that is clearly useful to alignment research is a theorem-proving engine: given a formal mathematical statement, it produces a proof or counterexample. We can evaluate this proof procedurally with a proof checker, so we can be sure that only correct proofs (relative to a formal system of axioms that we can’t ever prove to be non-contradictory) are produced. Such a system should meaningfully accelerate any alignment research work that is based on formal math, and it can also help formally verify and find security vulnerabilities in computer programs.
I agree that the above system seems useful, and that I can see conditions under which it would not be dangerous. There are certainly lots of systems like this, including GPT-4, which we agree is not dangerous and is highly useful. Doubtless we can find more useful programs to help us.
The question I’d have is, why describe the intended program as a human-level researcher? The proof generator doesn’t equate to the human intelligence scale in any obvious way. If we want to build such narrow things, that’s great and we should probably do that, but they don’t solve the human bottleneck problem, and I don’t think this is what the plan intends.
Attempt two: You can use something without consequentialist reasoning to do the steps of the work that don’t involve consequentialist reasoning, but then you need to have something else in the loop doing the consequentialist reasoning. Is it human?
The next question is on potential inner alignment problems, which essentially says we’ve never seen a convincing demonstration of them in existing models and maybe if we do see them they’ll be easy to fix. I would respond that they happen constantly in humans, they are almost certainly happening in LLMs, this will get worse as situations get further out of the training distribution (and that stronger optimization processes will take us further out of the training distribution), and our lack of ability to demonstrate them so far only makes our task of addressing them seem harder. More than that, I’d say what is here seems like a non-answer.
My overall take is that it is wonderful that this post exists and that it goes into so much concrete detail, yet the details mostly worry me more rather than less. The responses do not, in my evaluation, successfully address the concerns, in some cases rather the reverse. I disagree with much of the characterization of the evidence. There is a general lack of appreciation of the difficulty of the problems involved and an absence of security mindset, along with a clear optimism bias.
Still, once again, the detailed engagement here is great - I’d much rather have someone who writes this than someone who believes something similar and doesn’t write this. And there does seem to be a lot of ‘be willing to pivot’ energy.
Ilya Sutskever by contrast is letting the announcement speak for itself. Nothing wrong with focusing on the work.
Nat MacAleese’s Thread
Here, all the right things, except without discussing the alignment plan itself.
Nat McAleese (Twitter bio: Superalignment by models helping models help models help humans at OpenAI. Views my own.): Excited that the cat is finally out of the bag! A few key things I’d like to highlight about OpenAI’s new super-alignment team...
1) Yes, this is the notkilleveryoneism team.
2) Yes, 20% of all of OpenAI’s compute is a metric shit-ton of GPUs per person.
3) Yes, we’re hiring for both scientists and engineers right now (although at OAI, they're much the same!)
4) Yes, superintelligence is a real danger.
So if you think that you can help solve the problem of how to control AI that is much, much smarter than humanity; now is the time to apply!
Alternatively, if you have no idea why folks are talking so seriously about risks from rogue AI (but you have a science or engineering background) here’s a super-alignment reading list…
1) Ben Hilton’s great summary, “Preventing AI-related catastrophe” at 80k hours.
2) Richard Ngo’s paper “The alignment problem from a deep learning perspective.”
3) Dan Hendryk’s “An Overview of Catastrophic AI Risks.”
And, for examples of solutions instead of problems:
4) Sam Bowman’s “Measuring Progress on Scalable Oversight for Large Language Models”
5) Geoffrey Irving's "AI Safety Via Debate"
Now is the time for progress on superintelligence alignment; this is why @ilyasut and @janleike are joining forces to lead the new super-effort. Join us!
The Ilya Optimism
Sherjil Ozair explains how the man’s brain works.
Simeon: @ilyasut has gotten a bunch of things right before everyone else. I hope he's right on this alignment plan call as well or that he'll update very quickly. If he could write core assumptions as falsifiable as possible such that he'd change his mind if they were wrong, that would be great.
Sherjil Ozair: This is not how Ilya works. He doesn't write core assumptions or worries about falsifiability or changing his mind. He believes all problems are solvable. And he keeps at it, until he and his team solve the problem. Relentless optimism.
Simeon: Does he update quickly on stuff? Or have you already seen him being deeply wrong for a while?
Sherjil Ozair: In terms of methods, he tries all viable approaches, and isn't quick to declare any approach a failure. Some ideas stop getting attention when other ideas seem more promising. His epistemic state remains "everything can work".
The rationalist way of looking at the world doesn't really work when trying to understand people like Ilya. There is no "update". There is only "try". He doesn't care about being "right". He only cares about solving the problem, and if that takes being wrong, he'll do it.
Closest approximation is Steve Jobs' reality distortion field.
Quotes John Trent: But it is entirely plausible that it isn't solvable at our level of technology, or anything near it. I have faith that Ilya and his team are some of the most capable people on Earth to tackle it, I just don't see any ex ante reason to think that it's solvable in the near term.
Sherjil Ozair: The quoted tweet is probably "right". But what's the value of this? It's better to be wrong and believe that we can solve superalignment in 4 years, than believe that it's not possible, and thus not try. It takes irrationality to do hard things.
This is a big crux on how to view the world. Does it take irrationality to do hard things? Eliezer Yudkowsky explicitly says no. In his view, rationality is systematized winning. If you think you need to be ‘irrational’ to do a hard thing, either that hard thing is not actually worth doing, or your sense of what is rational is confused.
I have founded multiple start-up companies or businesses. In each case, any rational reading of the odds would say the effort was overwhelmingly likely to fail. Almost all new businesses fail, almost all venture investments fail. Yet I still did boldly go, in many of the same ways a delusional optimistic founder would have boldly gone. In most (but not all and that makes all the difference!) cases it failed to work out. I don’t see any reason this has to require fooling oneself or having false beliefs. I do understand why, in practice and for many people, this does help.
I can easily believe that Ilya would not think of himself as updating. I can see him, when asked by others or even when he queries his own brain, of responding to questions about priors or probabilities with a shrug, leaving them undefined. That he doesn’t consciously think in such ways, or use such terms. And that the things he would instead say sound, if interpreted literally, irrational.
None of that makes what he is doing actually irrational. If you treat any problem you face as solvable and focus on ways one might solve it, that is a highly efficient and rational way to solve a problem, so long as you are choosing problems worth attempting to solve, including considering whether they are solvable. If you allocate attention to various potential solutions, then scale that attention based on feedback on each approaches’ chance of success, that’s a highly rational, systematic and plausibly optimal resource allocation.
Not caring about being right, and being willing to be wrong, is a highly advanced rationalist skill. If you master it by keeping your explicit beliefs as small as your identity, so as to sideline the concepts of ‘being wrong’ or ‘trying and failing’ in favor of asking only what is true and what will lead to good outcomes, we only disagree on vocabulary and algorithmic techniques.
The question here is whether Ilya’s approach implies a lack of precision or an inability to do chains of logical reasoning, or some other barrier to the kind of detailed and exacting thinking necessary for good work on these problems. I don’t have enough information to know. I do know that in general this does sound like someone you want leading your important project.
So What Do We All Think?
First off, can we all agree, awesome, good job, positive reinforcement?
Robert Wiblin: Many people who disagree about the specific level or nature of the risk posed by superhuman AI can nevertheless agree that this is a good thing
Liron Shapira (new thread): Hot take: That’s awesome. More than I was expecting and more than any competitor is doing. They didn’t have to make themselves vulnerable to accusations of failing to meet the standard they set for themselves, but they did.
Alex Lawsen (quoted from other thread): I don’t *love* them calling it ‘superalignment’, but I *am* glad that they’re making a clear distinction between this and their current safety efforts, and in particular that this plan is *in addition* to their other safety efforts rather than as a replacement.
Liron Shapira: Yes, the thing they’ve been calling “alignment” wasn’t what we needed to stay alive, but sounds like “superalignment” actually is (if it works)!
There is an obvious implication to deal with, of course, although this is an overstatement here:
Geoffrey Miller: Ok. Now let's see a binding commitment that if you don't solve alignment within 4 years, you'll abandon AI capabilities research. If you won't do this, then all your safety talk is just vacuous PR, & you don't actually care about the extinction risks you're imposing on us all.
Liron Shapira: I don’t want to be greedy but ya this is the obvious sane thing that goes with recognizing the Superalignment problem.
We must simultaneously take the win, and also roll up our sleeves for the actual hard work, both within and outside of OpenAI and the new team. Also we must ensure good incentives, and that we give everyone the easiest way we can to go down the right path.
Would I appreciate a commitment on halting capabilities work beyond some threshold until the superalignment work is done, as Miller claims any sane actor would do? Yes, of course, that would be great, especially alongside a call to broaden that commitment to other labs or via regulations. We should work towards that.
It still is strongly implied. If you have an explicit team dedicated to aligning something, and you don’t claim it succeeded, presumably you wouldn’t build the thing and don’t need a commitment on that. If you did build it anyway, presumably you would fool yourself into thinking the team had instead succeeded - and if a binding commitment was made, one worry is that this would make it that much easier to get fooled. Or, of course, to choose to fool others, although I like to give the benefit of the doubt on that here.
We can also agree that this level of resource commitment is a highly credible signal, if the effort is indeed spent on superalignment efforts in particular. The question is whether this was commercially the play anyway?
Jeffrey Ladish: It's great to see OpenAI devote a big portion of their resources on the most important and challenging problem of our time: how to align superintelligent AI! People often ask if OpenAI is just paying lip service, but this specific commitment of resources is a strong signal.
Oliver Habryka: Wait, it is? We already know that marginally steering AI systems better is a bottleneck on commercialization, so I don't really think this is a strong signal. Like, I think it makes sense from a short-term economic perspective, and is not much evidence otherwise.
Jeffrey Ladish: Depends whether you think they're actually going to focus on aligning superintelligence or not. If they're just labeling it that but actually just working on RLHF then I'd say it's not a costly signal.
But I think they're going to have other teams working on that and this team is going to be working on scalable oversight plus other things - and maybe that is actually really useful in the short term in which case that's weaker, but it's not clear to me if it is useful short-term.
Oliver Habryka: Yeah, I would currently take a bet that the things this team will work on will look pretty immediately economically useful, and that the team will be pretty constrained in only working on economically useful things.
Jeffrey Ladish: I think I would bet on this, though seems reasonable to just ask @janleike if he thinks that's likely.
Jan Leike (head of alignment, OpenAI, project co-leader): Some of the things we'll do will be immediately economically useful (e.g. scalable overnight); we're not explicitly trying to avoid that. But the majority of the things probably won't (e.g. interpretability, generalization).
I'd want to prioritize making progress on the problem.
Definitely not foreshadowing the intelligence explosion 😅
Oliver Habryka: I hope you will! I don't currently have the trust to take you at your word, and I expect the culture of OpenAI to strongly bias things towards economically useful activities, but I am nevertheless glad to know that there is a concrete intention to not do that.
Simeon (upthread one step): Scalable overnight is IMO the cuttest alignment technique. Wow that's actually the best slogan for an infra company. "Scalable overnight".
Jan Leike: lol funny typo.
That is two right answers from Leike. Explicitly avoiding economic value is highly perverse. There are circumstances where the signaling or incentive dynamics are so perverse you do it anyway, but this is to be avoided. Even in the context of OpenAI and concerns about accelerationism, I would never ask someone to optimize for the avoidance of mundane utility.
I do share Oliver’s worry. One good reason to avoid mundanely useful things is that by putting mundanely useful options on the table you cause them to get chosen whether they make sense or not, so perhaps better to avoid them unless you are certain you want that.
Oliver tries to pin down his skepticism in another thread, along with exactly what is missing in the announcement.
Alex Lawsen: At the few-sentences level of the blogpost, the alignment plan looks close to ideal from my perspective. I'm really, really happy about it.
Oliver Habryka: Huh, the alignment plan really doesn't look much better than "let's hope the AI figures it out". I am glad they are expecting to change their perspective on the problem, but this kind of research plan still feels like it's really not modeling the hard parts of the problem.
Yep, the ‘not modeling the hard parts of the problem’ is the hard problem. As with the actual hard problem, that’s fine if solving the easy problem helps you solve (or notice you have to solve) the hard problem, and very bad if it lets you fool yourself.
Alex Lawsen: Can you think of other things they might have said in a post of ~this length that would have reassured you on the 'hard parts of the problem' thing? [Not a rhetorical question, v keen for your thoughts on this]
Like I think all three of the bulletpoints they listed in the 'approach' section seem worth throwing talent at, and they *did* then add an explicit caveat about those areas not being enough.
Oliver Habryka: I think if they had said "we recognize that it will be extremely difficult to tell whether whether we have succeeded at this goal, and that AI could become dangerous long before we could productively leverage it for safety research", that would have helped.
But like, idk, I think we don't have much traction on AI Alignment right now, so there is more of a key mismatch in the aim of the post. The hard parts of the problem are the ones where we are confused about how to even describe them succinctly.
Like, what is the blogpost I would have liked Einstein to write before he came up with relativity? (as the classical example of a pre-paradigm to post-paradigm transition). I don't know! By the time you can write a short blogpost you are most of the way done.
…
I mean, I think the blogpost is a marginally positive update, I just don't think the plan they write actually has much of a chance of working, and I really really wish OpenAI was better calibrated to the difficulty of the problem, and care about that much more than other things.
Like, the error for OpenAI in particular here is highly asymmetric. OpenAI (and other actors in their reference class) being overly optimistic is one of the primary ways we die, while I can deal with a lot of overly pessimistic/conservative organizations like OpenAI.
Appreciation of the problem difficulty level is indeed the best marginal thing to want here, with the caveat of the phenomenon of ‘we did this not because it was easy but because we thought it would be easy.’ Having the startup effort think the problem is easier than it is can be good, as per Ilya’s relentless optimism, provided the proper adjustments are made and the problem is taken properly seriously.
Danielle Fong is on board with this plan, she loves this plan.
Danielle Fong: allocating 20% of my computational resources to gf superalignment 👍 We hope to solve this problem in 4 years!
Zvi: Your current computational resources, or those you will have in the future, including those of your hopefully aligned gf?
Danielle: start with what i’ve got (brain, heart, quasi align quasi gfs…)
Zvi: Is she smarter than you?
Danielle: unbounded intelligence 😬
ai assisted gf, ai assisted danielle idk we are a relationship through our exoselves
I admire her ambition. I do worry.
Oh Look, It’s Capabilities Research

Emmett Shear: OpenAI starts doing alignment research (I kid, I kid, it’s actually not a bad approach…but like also somehow the solution for the danger of more capable AI is to accelerate building more capable AI).
That is certainly the maximally OpenAI thing to do, and does seem to be a good description of the plan. There is most definitely the danger that this effectively becomes a project to build an AGI. Which would be a highly foolish thing to be building given our current state of alignment progress. Hence the whole project.
Nora Belrose asks: I'm still kinda puzzled why OpenAI focuses so much on building "automated alignment researchers." Isn't that basically the same as building AGI, which is just capabilities? How about we focus directly on bullet points 1-3 [in ‘our approach’ which is quoted in full above].
Brian Chau: Their assumption is that AI will bootstrap itself and end up iteratively self-improving soon. From that perspective, having it do alignment in that process is very important.
Yes. This is not the plan, it’s also not not the plan, step one kind of is ‘to solve AGI alignment our step one is build an AGI,’ while buying (a weaker version of) the concept of recursive self-improvement.
Connor Leahy (CEO Conjecture): While I genuinely appreciate this commitment to ASI alignment as an important problem... ...I can't help but notice that the plan is "build AGI in 4 years and then tell it to solve alignment."
I hope the team comes up with a better plan than this soon!
I am confused exactly how unfair that characterization is. Non-zero, not entirely.
We very much do not want to end up doing this:

neuromancer42: Overly pessimistic.
Daniel Eth: It’s a joke.
ModerateMarcel: “You call capabilities research alignment research?” “It’s a regional dialect.” “What region?” “Uh, Bay Area.”
Back to Leahy’s skeptical perspective, which no one involved should take too personally as he is (quite reasonably, I think) maximally skeptical of essentially everything about alignment attempts.
[bunch of back and forth, in which Connor expresses extreme skepticism of the technical plans offered, and says the good statements in context only offer a marginal update that mostly fails to overcome his priors, while confirming that he agrees Jan and Ilya care for real.]
But, reasonable! For me, the post simply doesn't contain anything that addresses any of my cruxes needed to overcome the hyper negative prior on plans that are of the form "we muddle our way towards AGI1 and ask it to align AGI2" that I have. It's not that there couldn't be a plan of this form that is sufficiently advanced and clever that could work, they just DON'T work by default and I see nothing here that makes me feel good about this instance.
Julian Hazell: What would be something OAI could feasibly do that would be a positive update for you? Something with moderate-to-significant magnitude
Connor Leahy: This is a good question I want to think about for a bit longer instead of giving a low quality off the cuff answer, thanks for asking!
My answer is that I did have a positive update already, but if you want to get an additional one on top of that, I would have like to see them produce their less detailed and technical List of Lethalities, all the reasons their approach will inevitably fail, as well as an admission that the plan looks suspiciously like step 1 is build an AGI, and a clear explanation of how to solve such problems and how they plan to avoid being fooled if they haven’t solved them. A general statement of security mindset and that this is not about ‘throw more cycles at the issue’ or something that naturally falls out. Also would love to see discussion about exactly what the final result has to look like and why we should expect this is possible, and so on. It would also help to see discussion about the dangers of this turning into capabilities and the plan for not doing so, or a clear statement that if the project doesn’t provably work then capabilities work will need to be constrained soon thereafter. I’d also likely update positively if they explained more of their reasoning, and especially about things on which they’ve changed their minds.
Will It Work?
Jeffrey Ladish offers his previous thoughts on this research path, noting that he has updated slightly favorably since writing it due to strong statements from Sam Altman and the project announcement, which reflect taking the problem seriously and better appreciating the difficulties involved.
The full post points out that there is little difference between ‘AI AI-alignment researcher’ and ‘AI AI-capabilities researcher’ and also little gap at most between that and actual AGI, so time left will be very short and the plan inherently accelerates capabilities.
Jeffrey Ladish: [Leike’s] answer to “But won’t an AI research assistant speed up AI progress more than alignment progress?” seems to be “yes it might, but that’s going to happen anyway so it’s fine”, without addressing what makes this fine at all. Sure, if we already have AI research assistants that are greatly pushing forward AI progress, we might as well try to use them for alignment. I don’t disagree there, but this is a strange response to the concern that the very tool OpenAI plans to use for alignment may hurt us more than help us.
…
Basically, the plan does not explain how their empirical alignment approach will avoid lethal failures. The plan says: “Our main goal is to push current alignment ideas as far as possible, and to understand and document precisely how they can succeed or why they will fail.”
But doesn’t get into how the team will evaluate when plans have failed. Crucially, the plan doesn’t discuss most of the key hypothesized lethal failure modes[3] - where apparently-but-not-actually-aligned models seize power once able to.
I agree these are many of the core problems. OpenAI is a place we need to especially worry about reallocation to or use of capabilities advances, should they occur, and there is still insufficient appreciation of how to plan for what happens if the plan fails in time to avoid catastrophe. These are problems that can be fixed.
The problem that might not be fixable is whether the general approach can work at all. Among other concerns: Does it assume a solution, thus skipping over the actually hard problem?
Connor Leahy says not only will the plan obviously not work, he claims it is common knowledge among ordinary people that such a plan will not work.
Connor Leahy: The post is misleading marketing that makes their plan seem like more than it is (which is not different from before, which won't work). I acknowledge the thesis "OpenAI's current alignment plan is obviously not going to work" was left implicit, as I expect that to be common knowledge.
Richard Ngo: Come on, it's clearly not common knowledge even within the alignment community. People have a very wide range of P(doom) estimates. Using the term this sloppily suggests you're mainly trying to score rhetorical points.
Connor Leahy: Every single person outside of the alignment community that I know sees the obvious flaws in these plans, and almost every alignment researcher I know does as well (except those working for OpenAI or Anthropic, generally), and have all been hoping with bated breath for OpenAI to pivot to some new alignment direction, which many may believe this post is saying they did, rather than reaffirming their current plans with more compute and manpower.
So idk man, I think the blogpost is misleading and expressed what I believe is the true distilled core of what it's saying. You may disagree on technicalities (and if you do I'd love to talk it out in a better forum than Twitter!) or other reasons, but if you consider that to be "rhetorical points" then idk what more I can say/do.
Richard Ngo: ???? Most of the ML community doesn't think misalignment will be a problem, so how can they think that the plan will fail to produce aligned agents? And what credence do you think the median DeepMind or Redwood alignment researcher assigns to this plan producing misaligned AGI?
Connor has since clarified that he meant something more like common sense rather than common knowledge. What is bizarre is the idea that most of the ML community ‘doesn’t think misalignment will be a problem.’ Wait, what? This survey seems to disagree, with only 4% saying ‘not a real problem’ and 14% saying ‘not an important problem’ with 58% saying very important or among the most important problems. Saying this isn’t a problem seems flat out nonsensical, and on a much deeper level than denying the problem of extinction risk. There’s ‘Zeus will definitely not be a threat to Cronus’ and then there’s ‘Zeus will never display any behavioral problems of any kind, the issue is his lightning skills.’
Connor offered his critique in Reuters in more precise form.
Connor Leahy: Al safety advocate Connor Leahy said the plan was fundamentally flawed because the initial human-level Al could run amok and wreak havoc before it could be compelled to solve Al safety problems.
"You have to solve alignment before you build human-level intelligence, otherwise by default you won't control it," he said in an interview. "I personally do not think this is a particularly good or safe plan."
Jan Leike responding to request for a response from Michael Huang: Alignment is not binary and there is a big difference between aligning human level systems and aligning superintelligence. Making roughly human-level AI aligned enough to solve alignment is much easier than solving alignment once and for all..
Connor Leahy: I want to call out that despite my critiques, this is a sensible point! Thanks for making it explicit Jan! My concern now is "How will you ensure it is human level and no more?" This is a crux for me to whether this plan is good!
Yep. Human level is a rather narrow target to hit, also human-level alignment good enough to use for this purpose is not exactly a solved problem either. Of all the tasks you might need a human to do, this is one where you need an unusually high degree of precise alignment, because both it will be highly difficult to know if something does go wrong, and also in order to align the target one needs to understand what that means.
Simeon expresses skepticism: One thing which IMO is a major dealbreaker in OpenAI's meta-alignment plan:
1. Alignment is likely bottlenecked by the last few bits of intelligence, otherwise we wouldn't be where we are (i.e. 10y in and we have no idea about how we're going to achieve that)
2. Capabilities is clearly not (look at the speed). Hence, by default we'll stumble way faster on capabilities accelerators than alignment ones. Good luck to convince everyone on earth to refrain from using the capabilities accelerators till we reach Von Neumann-level AGI to solve the hardest parts of alignment that ultimately bottleneck us.
I do not think this holds. I do agree that if you look for anything at all you’re going to stumble on more capabilities relative to the average effort, because some efforts deliberately look for alignment, but this effort is deliberately looking for alignment.
I also don’t think we have strong evidence alignment (which I agree is very hard) is bottlenecked by intelligence. We have only hundreds of people working on it, there are many potential human alignment researchers available before we need turn to AI ones. Most low hanging efforts have not seriously been tried (also true with capabilities, mind) and no one has ever devoted industrial compute levels to alignment at all.
I do think that if OpenAI plans to release a ‘human-level alignment researcher’ more generally then that by default also releases a human-level capabilities researcher along with a human-level everything else, and that’s very much not a good idea, but I am assuming that if only for commercial reasons OpenAI would not do that if they realized they were doing it, and I think they should be able to realize they’d be doing that.
Manifold Markets says that, by the verdict of the team itself, the initiative has a remarkably good chance (this is after me putting M25 on NO, moving it down by 1%).
This is very much not a knock on the team or the attempt. A 15% chance of outright real success would be amazingly great, especially if the other 85% involves graceful failure and learning many of the ways not to align a superintelligence. Hell, I’d happily take an 0.1% chance of success if it came with a 99.9% chance of common knowledge that the project had failed while successfully finding lots of ways not to align an AGI. That is actual progress.
The concern is how often the project will fail, but the team or OpenAI will be fooled into thinking it succeeded. The best way to get everyone killed is to think you have solved ‘superalignment’ so you go ahead and build the system, when you have not solved superalignment. As always, you are the easiest one to fool. Plans like OpenAI’s current one seem especially prone to superficially looking like they are going to work right up until the moment it is too late.
Thus, my betting NO here is actually in large part a bet on the superalignment team. In particular, it is a bet on their ability to not fool themselves, as well as a bet that the problem is super difficult and unlikely to be solved within four years.
It’s also a commentary on the difficulties of such markets. One must always ask about implied value of the currency involved, and in which worlds you can usefully spend it.
Contrast this with Khoja’s market, where I bought some yes after looking at the details offered. An incremental but significant breakthrough seems likely.
The Trial Never Ends, Until it Does
As in, humans can lose control at any time. What they cannot do is ensure that they will permanently keep it, or that there is a full solution to how to keep it. Yann LeCun1 makes the good points that ‘solve the alignment problem’ is impossibly difficult, because it is not the type of thing that has a well-defined single solution, that four years is a hyperaggressive timeline, and that almost all previous similar solved problems were only solved by continuous and iterated refinement.
Yann LeCun: One cannot just "solve the AI alignment problem." Let alone do it in 4 years. One doesn't just "solve" the safety problem for turbojets, cars, rockets, or human societies, either. Engineering-for-reliability is always a process of continuous & iterative refinement.
The problem with this coming from Yann is that in this case is with Yann’s preferred plan of ‘wait until you have the dangerous system to iterate on, then do continuous and iterated refinement then, that’s safe and AI poses no extinction risk to humanity’ combined with ‘just build the safe AIs and do not build the unsafe ones, no one would be so stupid as to build the unsafe ones.’ Because, wait, what?
Ajeya Cotra responds: Strongly agree that there is no single "alignment problem" that you can "solve" once and for all. The goal is to keep avoiding catastrophic harm as we keep making more and powerful AI systems. This is not like solving P vs NP; it requires continuous engineering and policy effort.
"Alignment" (= ensuring an AI system is "trying its best" to act as its designed intended, to the extent it's "trying" to do anything at all) is one ingredient in making powerful AI go well.
If an AI system is "aligned" in this sense, it could still cause catastrophic harm. Its designers (or bad actors who steal it) could use it to do harmful things, just like with any other technology. This could be catastrophic if it's powerful enough.
I have been emphasizing this more lately. ‘Solving alignment’ is often poorly specified, and while for sufficiently capable systems it is necessary, it is not sufficient to ensure good outcomes. Sydney can be misaligned and have it be fine. An AGI can’t.
I also think we overemphasize the ‘bad actor’ aspect of this. One does need not a per-se ‘bad’ actor to cause bad outcomes in a dynamic system, the same way one does not need a ‘good’ butcher, baker or candlestick maker for the market to work.
Thread includes more. Strongly endorse Ajeya’s closing sentiment:
Ajeya Cotra: Progress could be scary fast. I'm excited for efforts that plan ahead to the obsolescence regime, and try to ensure future AIs will be safe even if they make all the decisions. Solving problems in advance is *hard,* but we might not have the luxury of taking it step by step.
Whatever disagreements we have, it is amazingly great that OpenAI is making a serious effort here that aims to target parts of the hard problem. That doesn’t mean it will succeed, extensive critique is necessary, but it is important to emphasize that this very much is actual progress.

I do not typically cover Yann LeCun, but I’m happy to cover anyone making good points.
Hi, thanks a lot for writing the detailed and highly engaged piece! There are a lot of points here and I can't respond to all of them right now. I think these responses might be most helpful:
Maybe a potential misunderstanding upfront: the Superalignment Team is not trying to teach AI how to do ML research. This will happen without us, and I don’t think it would be helpful for us to accelerate it. Our job is to research and develop the alignment techniques required to make the first system that has the capabilities to do automated alignment research sufficiently aligned.
Put differently: automated ML research will happen anyway, and the best we can do is be ready to use is for alignment as soon as it starts happening. To do this, we must know how to make that system sufficiently aligned that we can trust the alignment research it's producing (because bad faith alignment research is an avenue through which AI can gain undue power).
> If the first stage in your plan for alignment of superintelligence involves building a general intelligence (AGI), what makes you think you’ll be able to align that first AGI? What makes you think you can hit the at best rather narrow window of human intelligence without undershooting (where it would not be useful) or overshooting (where we wouldn’t be able to align it, and might well not realize this and all die)? Given comparative advantages it is not clear ‘human-level’ exists at all here.
One thing that we’ve learned from LLM scaling is that it’s actually moving relatively slowly through the spectrum of human-level intelligence: for lots of tasks that fit in the context window, GPT-4 is better than some humans and worse than others. Overall GPT-4 is maybe at the level of a well-read college undergrad.
We can measure scaling laws and be ready to go once models become useful for alignment. Models are usually vastly better than humans at some tasks (e.g. translation, remembering facts) and much worse at others (e.g. arithmetic), but I expect that there’ll be a window of time where the models are very useful for alignment research, as long as they are sufficiently aligned.
You can think of this strategy as analogous to building the first ever compiler. It would be insane to build a modern compiler with all its features purely in machine code, but you also don’t have to. Instead, you build a minimal compiler in machine code, then you use it to compile the next version of the compiler that you mostly wrote in your programming language. This is not a circular strategy.
> They do talk later about aligning this first AGI. This does not solve the hard problem of how a dumber thing can align a smarter thing.
If the smartest humans could solve the hard problem, shouldn’t an AI system that is as smart as the smartest humans be able to? If the smartest humans can’t solve the hard problem, then no human-driven alignment plans can succeed either. The nice aspect of this plan is that we don't actually need to solve the "align a much smarter thing" problem ourselves, we only need to solve the "align a thing about as smart as us" problem.
> If you use A to align B to align C to align D
If you use humans = A to align B, and B come up with a new alignment technique, and then use this new technique to align C, you haven’t really used B to align C, you’re still just using A to align C.
> This is the opposite of their perspective, which is that ‘good enough’ alignment for the human-level is all you need. That seems very wrong to me. You would have to think you can somehow ‘recover’ the lost alignment later in the process.
A simple example is retraining the same model with a new technique. For example, say you use RLHF to train a model, and it gives you an idea for how to improve RLHF (e.g. significantly fewer hallucinations). Now you re-run RLHF and you get a more aligned model. But you don’t have to go via the proxy of the previous model other than the idea it gave you how to improve alignment. (To be clear, I'm not saying RLHF will be sufficient to align the automated alignment researcher.)
> Testing for interpretability can cause internal disguise and even ‘fooling oneself’ as it does in humans, cognition gets forced into whatever form you won’t detect, including outside what you think is the physical system.
This depends a lot on how much selection pressure you apply. For example, ImageNet models have been selected on the test set for many years now and there is some measurable test set leakage, but the overall effect doesn’t make the test set useless.
If you train a new model every day and keep the hyperparameters that the interpretability people seem to make happier noises about, you’re leaking a lot of bits about the interpretability tools. But if you go back and try to debug your pipeline to find the culprit that caused the problem, you can do this in a way that leaks very few bits and solve more actual problems. (E.g. if you only get to submit one model per week to the interpretability team, you leak at most 1 bit / week.)
> I would expect AIs to be at comparative disadvantage in detecting distinct manifestations of misalignment, compared to humans
Would you agree that AI should be at an advantage at detecting problems we trained it to plant deliberately? We should have some useful empirical evidence on this soon.
> The danger is that we will not confidently know when we transition to testing on dangerous systems.
This is something we’ll need to solve soon anyway; plus every AI lab will want their competitors to be testing for this.
> Building a human-level alignment researcher sounds a lot like building a human-level intelligence,
We’re not pushing on the capabilities required to do this, we’re just trying to figure out how to align it.
> There is great need for more ML talent working on alignment, but I disagree that alignment is fundamentally a machine learning problem. It is fundamentally a complex multidisciplinary problem, executed largely in machine learning, and a diversity of other skills and talents are also key bottlenecks.
Yes, my original statement was too strong and I now regret it. However, I do still think some of the core parts of what makes this problem difficult are machine learning problems.
> If you use current-model alignment to measure superalignment, that is fatal.
Depends on how you make the inference. Just because you’re making GPT-5 more aligned doesn’t mean you’re solving superintelligence alignment. But if you are trying to align a human-level alignment researcher, then somewhere along the way short of the actual system that can do automated alignment research do your techniques need to start working. GPT-5 is a good candidate for this and we need grounding in real-world empirical data.
> Yes, in both examples here and many other games, you can do an easy evaluation easily and tell if one side is dominating in the most obvious ways, but it often won’t help tell you who is winning expert games.
I agree that it can be very hard to tell who is winning (i.e. is in a favorable position) in chess, MTG, or other games (and if you could do this, then you could also play really well). But it is very easy to tell who has won the game (i.e. who the rules of the game declare as the winner).
I'm not actually sure that "strong" alignment is possible or meaningful. My mental model is something like:
1. Colonizing the stars was always for post-humans, not monkeys in tin cans.
2. "Intelligence" is fundamentally giant, partly inscrutable matrices. Virtually all progress we've made on AI came from recognizing and accepting this fact.
3. Human-friendly values are too complex to formally model in a mathematically rigorous way.
4. Yudkowsky's fast takeoff scenarios involve unlikely assumptions about nanotech and slightly dubious assumptions about intelligence. I'd give them probability < 0.05 within 5 years of us building a AGI. Most of this weight comes from the fact that synthetic biology seems like a poor way to build GPUs, and diamond-phase nanotech looked like extreme "hopium" the last time I looked at the research.
5. But "slow" takeoff can still kill us all, given 10-50 years. The main limiting factor is building out atom-moving tools on a scale sufficiently large to replace the world economy, and doing so without too much human backlash. Without nanotech, this harder to hide.
6. Many scenarios where we die look like utopia until a "treacherous turn", because a hostile AI would need time for a sufficient robotics build out, and it wouldn't want to trigger a human backlash until it had secured its supply lines.
Because of (2) and (3), I'm deeply pessimistic about "strong" alignment, where the goal is "we have a mathematical proof the AI won't kill us." I strongly suspect that asking for such a proof fundamentally misunderstands how both intelligence and human values work.
So any alignment plan, in my pessimistic view is roughly equivalent to, "We're going to carefully raise the alien spider god from childhood, teach it the best moral values we know, and hope that when it grows up, it likes humans enough to keep us around." I actually believe that this plan _might_ work, but that's just my prior that intelligent beings are sometimes benevolent. If GPT-4 has shown me anything, it's that we could give the alien spider god a pretty good understanding of humans. And therefore we're not picking _completely_ randomly from "goal space" or "mind space." Sure, we might be trying to hit a bullseye while blind drunk, but at least we're in the same room as the dartboard.
So, as for OpenAI's plan, I like the part where they're "we admit this is a problem, so let's try a bunch of things and allocate lots of resources." I don't think their plan offers any guarantees beyond "trying to raise the alien spider god with values we like." But I think that's about the best we could get, conditional on building ASI.
I am _much_ more concerned that their plan apparently starts with "step (1): build a near-human AGI." My prior is that near-human AGIs are not _automatically_ threats, for the same reason that there are some very smart people who have not made themselves world dictator.
My fundamental objection to building a "narrow" AGI to help with alignment research is that it encourages proliferation. Once you can build the specialized AGI, it's presumably very easy to build and deploy AGIs commercially. Which brings us several huge steps closer to the endgame.
But this is classic OpenAI: "We'll protect you from Skynet by doing everything possible to accelerate the development of AI!"