Sora What

Hours after Google announced Gemini 1.5, OpenAI announced their new video generation model Sora. Its outputs look damn impressive.
How Sora Works
How does it work? There is a technical report. Mostly it seems like OpenAI did standard OpenAI things, meaning they fed in tons of data, used lots of compute, and pressed the scaling button super hard. The innovations they are willing to talk about seem to be things like ‘do not crop the videos into a standard size.’
That does not mean there are not important other innovations. I presume that there are. They simply are not talking about the other improvements.
We should not underestimate the value of throwing in massively more compute and getting a lot of the fiddly details right. That has been the formula for some time now.
Some people think that OpenAI was using a game engine to learn movement. Sherjil Ozair points out that this is silly, that movement is learned easily. The less silly speculation is that game engine outputs may have been in the training data. Jim Fan thinks this is likely the case, and calls the result a ‘data-driven physics engine.’ Raphael Molière thinks this is likely, but more research is needed.
Brett Goldstein here digs into what it means that Sora works via ‘patches’ that combine to form the requested scene.
Gary Marcus keeps noting how the model gets physics wrong in various places, and, well, yes, we all know, please cut it out with the Stop Having Fun.
Yishan points out that humans also work mostly on ‘folk physics.’ Most of the time humans are not ‘doing logic’ they are vibing and using heuristics. I presume our dreams, if mapped to videos, would if anything look far less realistic than Sora.
Yann LeCun, who only a few days previous said that video like Sora produces was not something we knew how to do, doubled down with the ship to say that none of this means the models ‘understand the physical world,’ and of course his approach is better because it does. Why update? Is all of this technically impressive?
Sora Is Technically Impressive
Yes, Sora is definitely technically impressive.
It was not, however, unexpected.
Sam Altman: we'd like to show you what sora can do, please reply with captions for videos you'd like to see and we'll start making some!
Eliezer Yudkowsky: 6 months left on this timer.
Eliezer Yudkowsky (August 26, 2022): In 2-4 years, if we're still alive, anytime you see a video this beautiful, your first thought will be to wonder whether it's real or if the AI's prompt was "beautiful video of 15 different moth species flapping their wings, professional photography, 8k, trending on Twitter".
Roko (other thread): I don't really understand why anyone is freaking out over Sora.
This is entirely to be expected given the existence of generative image models plus incrementally more hardware and engineering effort.
It's also obviously not dangerous (in a "take over the world" sense).
Eliezer Yudkowsky: This is of course my own take (what with having explicitly predicted this). But I do think you want to hold out a space for others to say, "Well *I* didn't predict it, and now I've updated."
Altman’s account spent much of last Thursday making videos for people’s requests, although not so many that they couldn’t cherry pick the good ones.
As usual, there are failures that look stupid, mistakes ‘a person would never make’ and all that. And there are flashes of absolute brilliance.
How impressive? There are disputes.
Tom Warren: this could be the "holy shit" moment of AI. OpenAI has just announced Sora, its text-to-video AI model. This video isn't real, it's based on a prompt of "a cat waking up its sleeping owner demanding breakfast..." 🤯
Daniel Eth: This isn’t impressive. The owner doesn’t wake up, so the AI clearly didn’t understand the prompt and is instead just doing some statistical mimicking bullshit. Also, the owner isn’t demanding breakfast, as per the prompt, so the AI got that wrong too.
Davidad (distinct thread): Sora discourse is following this same pattern. You’ll see some safety people saying it’s confabulating all over the place (it does sometimes - it’s not reliably controllable), & some safety people saying it clearly understands physics (like humans, it has a latent “folk physics”)
On the other side, you’ll see some accelerationist types claiming it must be built on a video game engine (not real physics! unreal! synthetic data is working! moar! faster! lol @ ppl who think this could be used to do something dangerous!?!), & some just straightforward praise (lfg!)
One can also check out this thread for more discussion.
near: playing w/ openai sora more this weekend broken physics and english wont matter if the content is this good - hollywood may truly be done for.
[video available at link and it is awesome.]
literally this easy to get thousands of likes fellas you think people will believe ai content is real. I think people will believe real content is ai we are not the same.
Emmett Shear (other thread, linking to a now-deleted video): The fact you can fool people with misdirection doesn’t tell you much either way.
[EDIT: In case it was not sufficiently clear from context, yes everyone talking here knows this is not AI generated, which is the point.]
This video is my pick for most uncanny valley spooky. This one’s low key cool.
Nick St. Pierre has a fascinating thread where he goes through the early Sora videos that were made in response to user requests. In each case, when fed the identical prompt, MidJourney generates static images remarkably close to the baseline image in the Sora video.
Gabor Cselle asks Gemini 1.5 about a Sora video, Gemini points out some inconsistencies. AI detectors of fake videos should be very good for some time. This is one area where I expect evaluation to be much easier than generation. Also Gemini 1.5 seems good at this sort of thing, based on that response.
Stephen Balaban takes Sora's performance scaling with compute and its general capabilities as the strongest evidence yet that simple scaling will get us to AGI (not a position I share, this did not update me much), and thinks we are only 1-2 orders of magnitude away. He then says he is ‘not an AI doomer’ and is ‘on the side of computational and scientific freedom’ but is concerned because that future is highly unpredictable. Yes, well.
Sora What’s it Good For?
What are we going to do with this ability to make videos?
At what look like Sora’s current capabilities level? Seems like not a lot.
I strongly agree with Sully here:
Matt Turck: Movie watching experience
2005: Go to a movie theater.
2015: Stream Netflix.
2025: ask LLM + text-to-video to create a new season of Narcos to watch tonight, but have it take place in Syria with Brad Pitt, Mr. Beast and Travis Kelce in the leading roles.
Sully: Hot take: most ppl won’t make their movies/shows until we can read minds most people are boring/lazy.
They want to come home, & be spoon fed a show/movie/music.
Value accrual will happen at the distribution end (Netflix,Spotify, etc), since they already know you preferences.
Xeophon: And a big part is the social aspect. You cannot talk with your friends about a movie if everyone saw a totally different thing. Memes and internet culture wouldn’t work, either.
John Rush: you're 100% right. the best example is the modern UX. Which went from 1) lots of actions(filters, categories, search) (blogs) 2) to little action: scroll (fb) 3) to no action: auto-playing stories (inst/tiktok)
I do not think that Sora and its ilk will be anywhere near ready, by 2025, to create actually watchable content, in the sense of anyone sane wanting to watch it. That goes double for things generated directly from prompts, rather than bespoke transformations and expansions of existing creative work, and some forms of customization, dials or switches you can turn or flip, that are made much easier to assemble, configure and serve.
I do think there’s a lot of things that can be done. But I think there is a rather large period where ‘use AI methods to make tweaks possible and practical’ is good, but almost no one in practice wants much more than that.
I think there is this huge benefit to knowing that the thing was specifically made by a particular set of people, and seeing their choices, and having everything exist in that context. And I do think we will mostly want to retain the social reference points and interactions, including for games. There is a ton of value there. You want to compare your experience to someone else’s. That does not mean that AI couldn’t get sufficiently good to overcome that, but I think the threshold is high.
As a concrete example, right now I am watching the show Severance on Apple TV. So far I have liked it a lot, but the ways it is good are intertwined with it being a show written by humans, and those creators making choices to tell stories and explore concepts. If an AI managed to come up with the same exact show, I would be super impressed by that to be sure, but also the show would not be speaking to me in the same way.
Until we can say exactly what we want, and get it, mostly I expect no dice. When you go looking for something specific, your chances of finding it are very bad.
Ryan Moulton: There is a huge gap in generative AI between the quality you observe when you're playing with it open endedly, and the quality you observe when you try to use it for a task where you have a specific end goal in mind. This is I think where most of the hype/reality mismatch occurs.
PoliMath (distinct thread): I am begging anyone to take one scene from any movie and recreate it with Sora Any movie. Anything at all. Taxi Driver, Mean Girls, Scott Pilgrim, Sonic the Hedgehog, Buster Keaton. Anything.
People are being idiots in the replies here so I'll clarify: The comment was "everyone will be filmmakers" with AI No they won't.
Everyone will be able to output random video that mostly kind of evokes the scene they are describing.
That is not filmmaking.
If you've worked with AI generation on images or text, you know this is true. Try getting ChatGPT to output even tepidly interesting dialogue about any specific topic. Put a specific image in your head and try to get Midjourney to give you that image.
Same thing with image generation. When I want something specific, I expect to be frustrated and disappointed. When I want anything at all within a vibe zone, when variations are welcomed, often the results are great.
Will we get there with video? Yes I think we will, via modifications and edits and general advancements, and incorporating AI agents to implement the multi-step process. But let’s not get ahead of ourselves.
The contrast and flip side is then games. Games are a very different art form. We should expect games to continue to improve in some ways relative to non-interactive experiences, including transitioning to full AR/VR worlds, with intelligent other characters, more complex plots that give you more interactive options and adapt to your choices, general awesomeness. It is going to be super cool, but it won’t be replacing Netflix.
Tyler Cowen asked what the main commercial uses will be. The answers seem to be that they enable cheap quick videos in the style of TikTok or YouTube, or perhaps a music video. Quality available for dirt cheap may go up.
Also they enable changing elements of a video. The example in the technical paper was to turn the area around a driving car into a jungle, others speculate about de-aging actors or substituting new ones.
I think this will be harder here than in many other cases. With text, with images and with sound, I saw the mundane utility. Here I mostly don’t.
At a minimum it will take time. These tools are nowhere near being able to reproduce existing high quality outputs. So instead, the question becomes what we can do with the new inputs, to produce what kinds of new outputs that people still value.
Tyler posted his analysis a few days later, saying it has profound implications for ‘all sorts of industries’ but will hit the media first, especially advertising, although he agrees it will not put Hollywood out of business. I agree that this makes ‘have something vaguely evocative you can use as an advertisement’ will get easier and cheaper, I suppose, when people want that.
Others are also far more excited than I am. Anton says Tesla should go all-in on this due to its access to video data from drivers, and buy every GPU at any price to do more video. I would not be doing that.
Grimes: Cinema - the most prohibitively expensive art form (but also the greatest and most profound) - is about to be completely democratized the way music was with DAW's.
(Without DAW's like ableton, GarageBand, logic etc - grimes and most current artists wouldn't exist).
Crucifore (distinct thread): I’m still genuinely perplexed by people saying Sora etc is the “end of Hollywood.” Crafting a story is very different than generating an image.
Alex Tabarrok: Crafting a story is a more distributed skill than the capital intensive task of making a movie.
Thus, by democratizing the latter, Sora et al. give a shot to the former which will mean a less Hollywood centric industry, much as Youtube has drawn from TV studios.
Matt Darling: Worth noting that YouTube is also sort of fundamentally a different product than TV. The interesting question is less "can you do movies with AI?" and more "what can we do now that we couldn't before?".
Alex Tabarrok: Yes, exactly; but attention is a scarce resource.
Andrew Curran says it can do graph design and notes it can generate static images. He is super excited, thread has examples.
I still don’t see it. I mean, yes, super impressive, big progress leap in the area, but still seems a long way from where it needs to be.
Of course, ‘a long way’ often translates in this business to ‘a few years,’ but I still expect this to be a small part of the picture compared to text, or for a while even images or voice.
Here’s a concrete question:
Daniel Eth: If you think sora is better than what you expected, does that mean you should buy Netflix or short Netflix? Legitimately curious what finance people think here.
My guess is little impact for a while. My gut says net negative, because it helps Netflix’s competition more than it helps Netflix.
Sora Comes Next?
What will the future bring? Here is scattershot prediction fun on what will happen at the end of 2025:
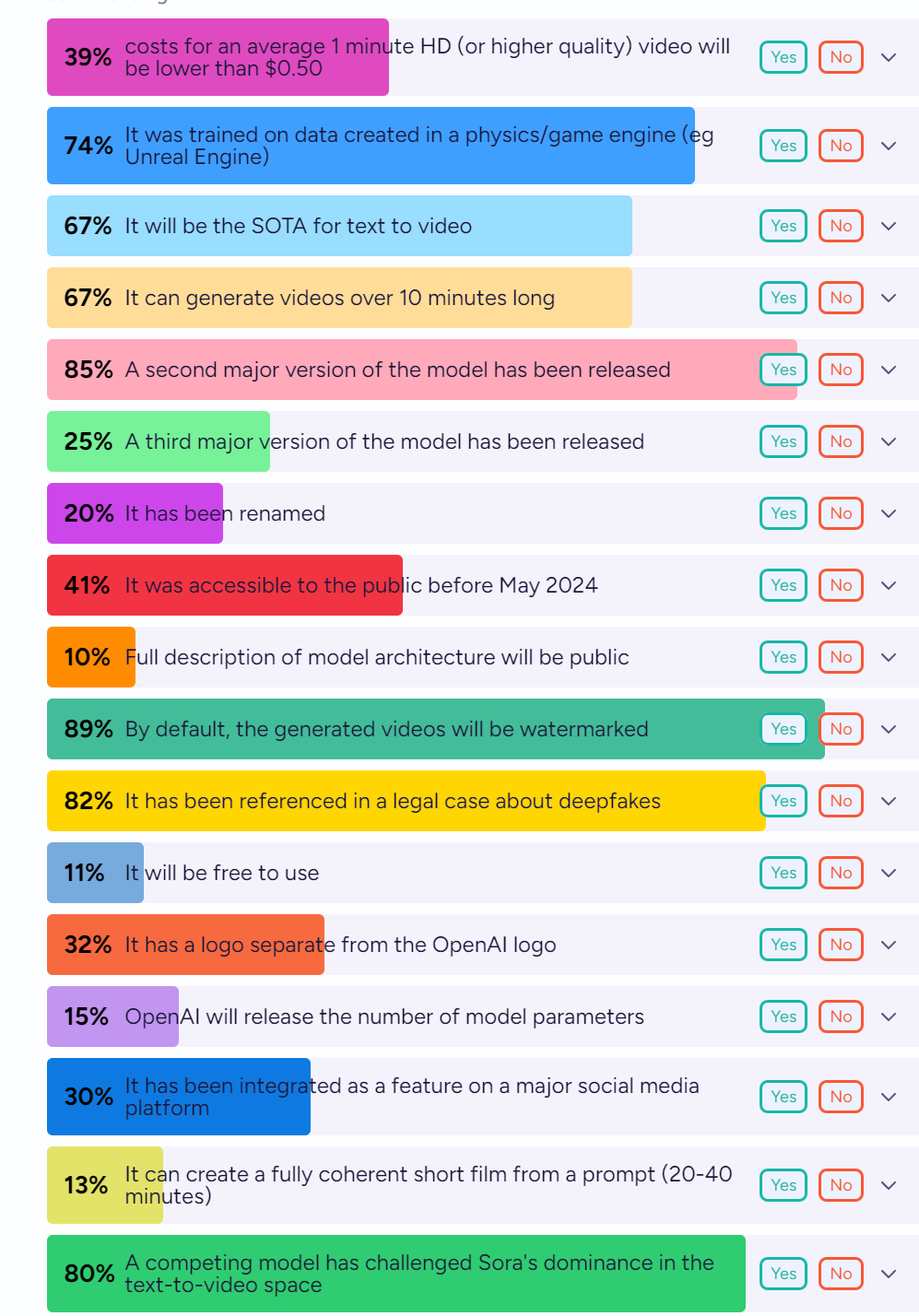
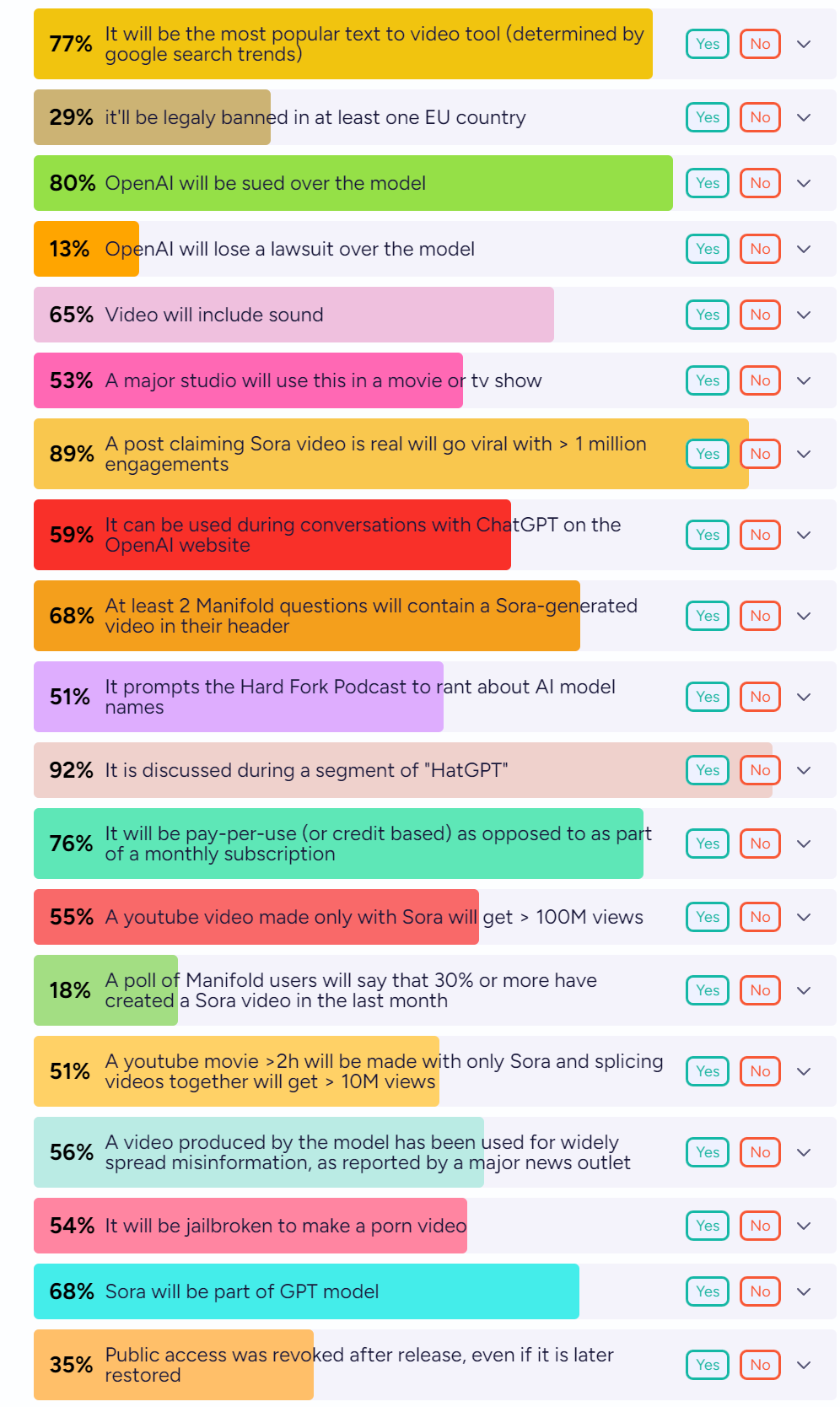
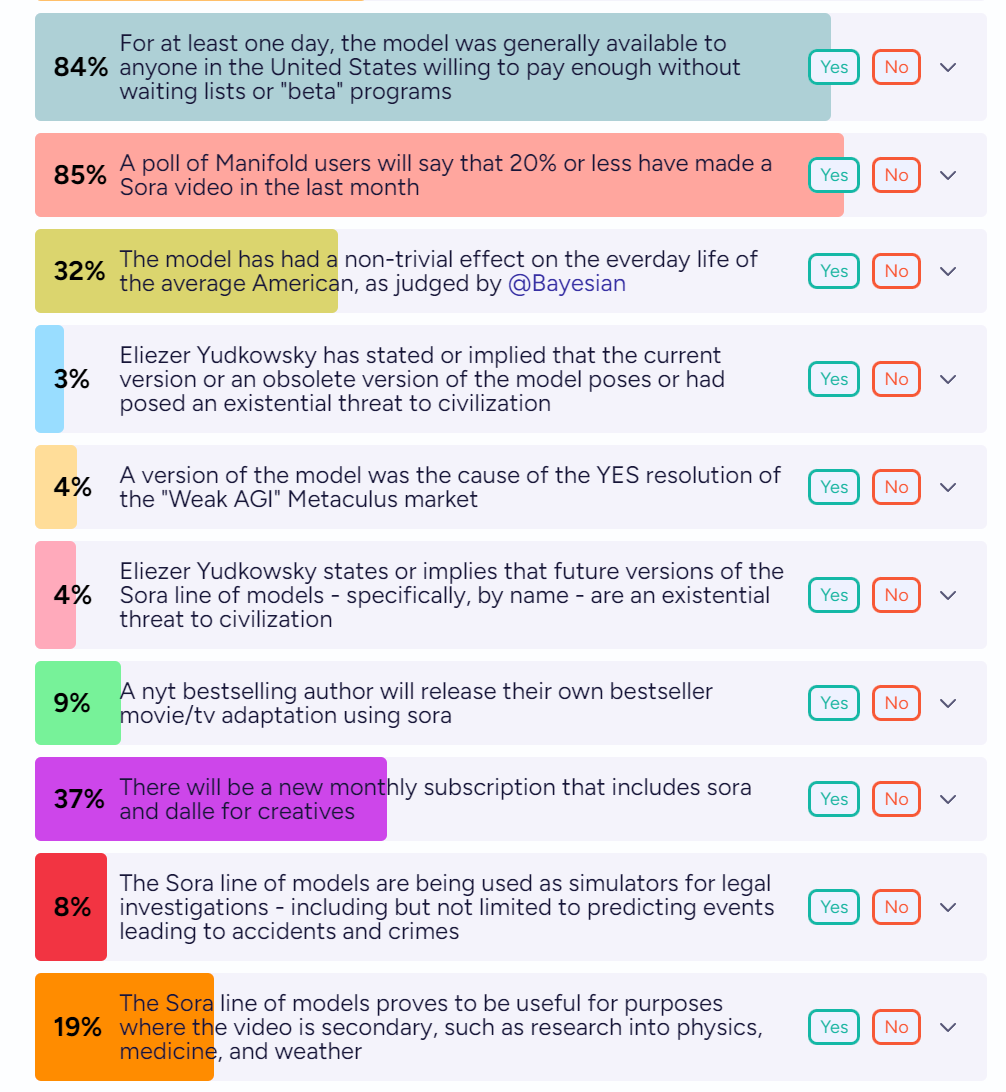
Cost is going to be a practical issue. $0.50 per minute is tiny for some purposes, but it is also a lot for others, especially if you cannot get good results zero-shot and have to do iterations and modifications, or if you are realistically only going to see it once.
I continue to think that text-to-video has a long way to go before it offers much mundane utility. Text should remain dominant, then multimodality with text including audio generation, then images, only then video. For a while, when we do get video, I expect it to largely in practice be based off of bespoke static images, real and otherwise, rather than the current text-to-video idea. The full thing will eventually get there, but I expect a (relatively, in AI timeline terms) long road, and this is a case where looking for anything at all loses out most often to looking for something specific.
But also, perhaps, I am wrong. I have been a video skeptic in many ways long before AI. There are some uses for ‘random cool video vaguely in this area of thing.’ And if AI video becomes a major use case, that seems mostly good, as it will be relatively easy to spot and otherwise less dangerous, and let’s face it, video is cool.
So prove me wrong, kids. Prove me wrong.
Obvious immediate use case seems to be stock footage or generic b roll. If you want a 10 second aerial shot of waves on a beach for your drug commercials voice-over I think Sora can already handle that. I don't know how relevant that will be in practice since I suspect there are already massive libraries of every kind of thing like that you could want available for quite cheap.
I wonder if a central use case for ‘random cool video vaguely in this area of thing’ would be porn. I mean, you can imagine the possibilities. Also wonder to what extent your point about “real people actually did this” also applies here. It’s been a while, for me, but I would think the lack of this would become an issue.